On the Use of Mobile Devices as Controllers for First-Person Navigation in Public Installations †



Abstract
:1. Introduction
2. Materials and Methods
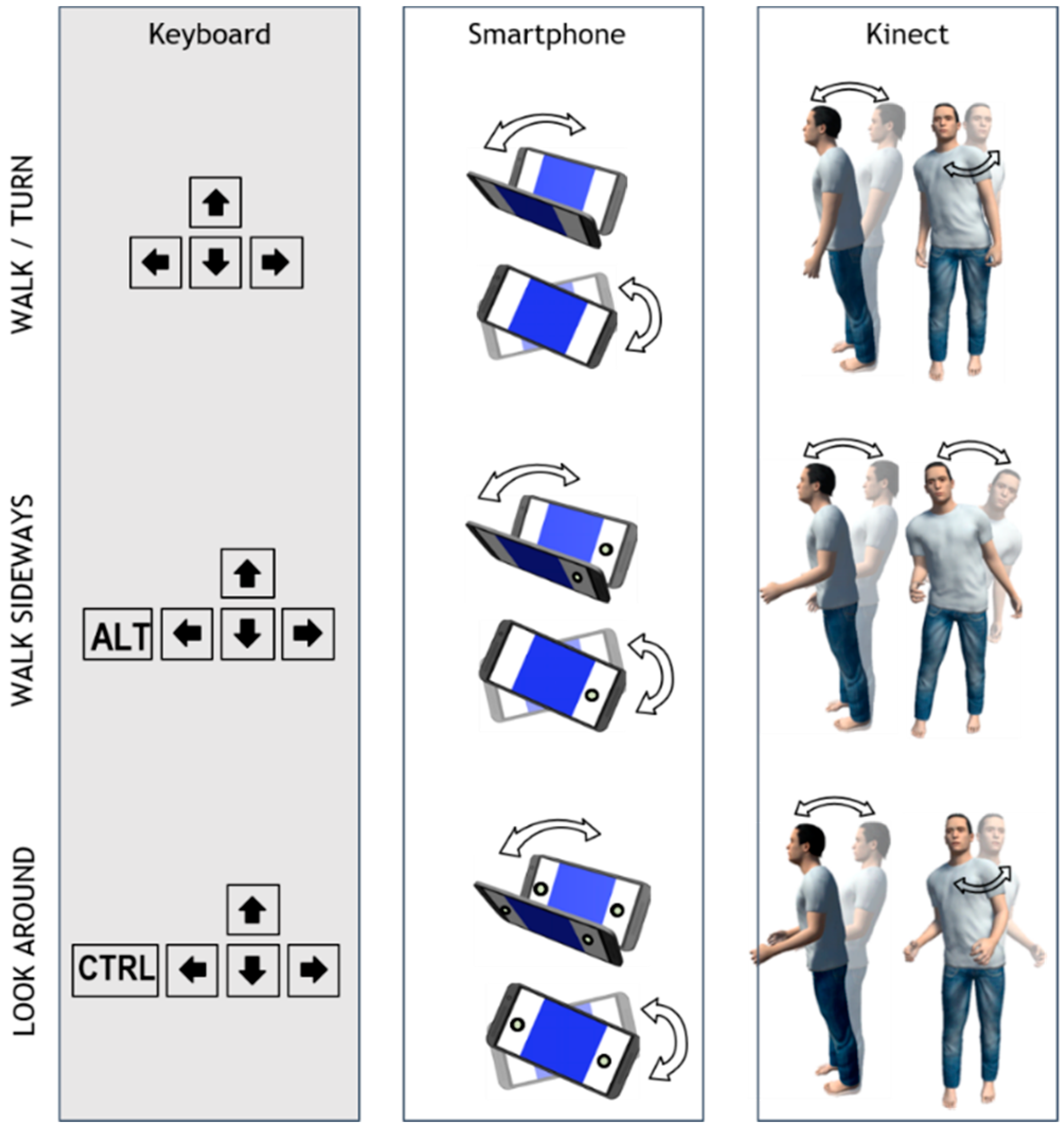
2.1. Interaction Techniques
- Walk/turn: Move forwards or backwards and turn to the left or right;
- Walk sideways (strafe): Move sideways; and
- Look around: Look up or down and turn to the left or right.
- The cursor keys of the keyboard are used;
- The user’s body is leaning forwards and backwards, while her shoulders have to rotate left and right in order to turn, for Kinect input;
- The smartphone device must be tilted forwards or backwards to move to that direction and rotated like a steering wheel to turn left or right, while held by both hands in a horizontal direction (landscape).
- The ALT key of the keyboard combined with the cursor keys is used;
- The user’s one arm (either left or right) is raised slightly by bending her elbow and the user’s body is leaning left and right to move to the respective side, for Kinect input;
- On the smartphone device, one button should be pressed (either left or right, as both edges of the screen work as buttons) and the device must be rotated like a steering wheel to walk sideways left or right.
- The CTRL key of the keyboard combined with the cursor keys is used: Up and down is used to move the viewpoint upwards or downwards, respectively, and left and right to rotate it;
- Both of the user’s arms are raised slightly, while the user’s body leans forwards or backwards to look down or up, respectively, and rotates her shoulders to turn to the left or right;
- The user presses both buttons of the smartphone device and tilts or rotates the device to turn the view to that direction.
- Walk fwd-back: Walk forwards or backwards;
- Rotate left-right: Rotate the viewpoint to the left or right;
- Look up-down: Rotate the viewpoint upwards or downwards; and
- Walk sideways: Walk to the left or right (strafe) without turning the viewing direction.
2.2. Equipment and Setting
- Familiarization: A simple scene that allows users to familiarize with each interaction technique. It displays a digitized version of the Stonehenge site.
- Buildings: An indoor and outdoor scene displaying abandoned buildings with rooms and corridors. Users’ task was to walk around a building, and to carefully maneuver their virtual body through narrow doors.
- Museum: A small interior scene featuring a digitized version of the Hallwyl Museum Picture Gallery. Users’ task was to walk through the hallways slowly and focus on particular displays.
2.3. Participants
2.4. Procedure
2.4.1. Comparative Study
2.4.2. Gesture Elicitation Study
2.5. Collected Data
3. Results
3.1. Comparative Study between Smartphone-Based and Kinect-Based 3D Navigation
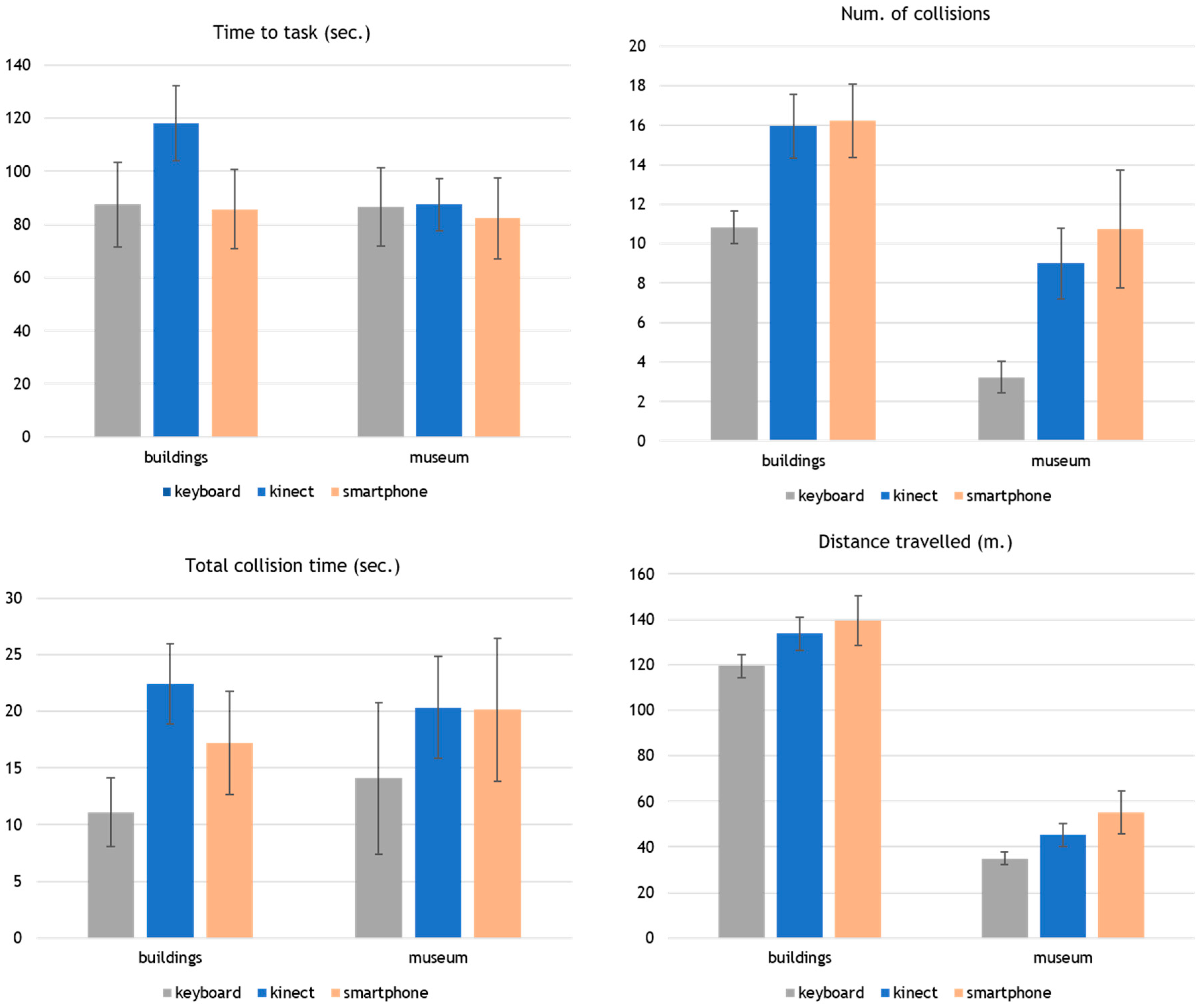
3.1.1. Time, Collisions, and Distance Travelled
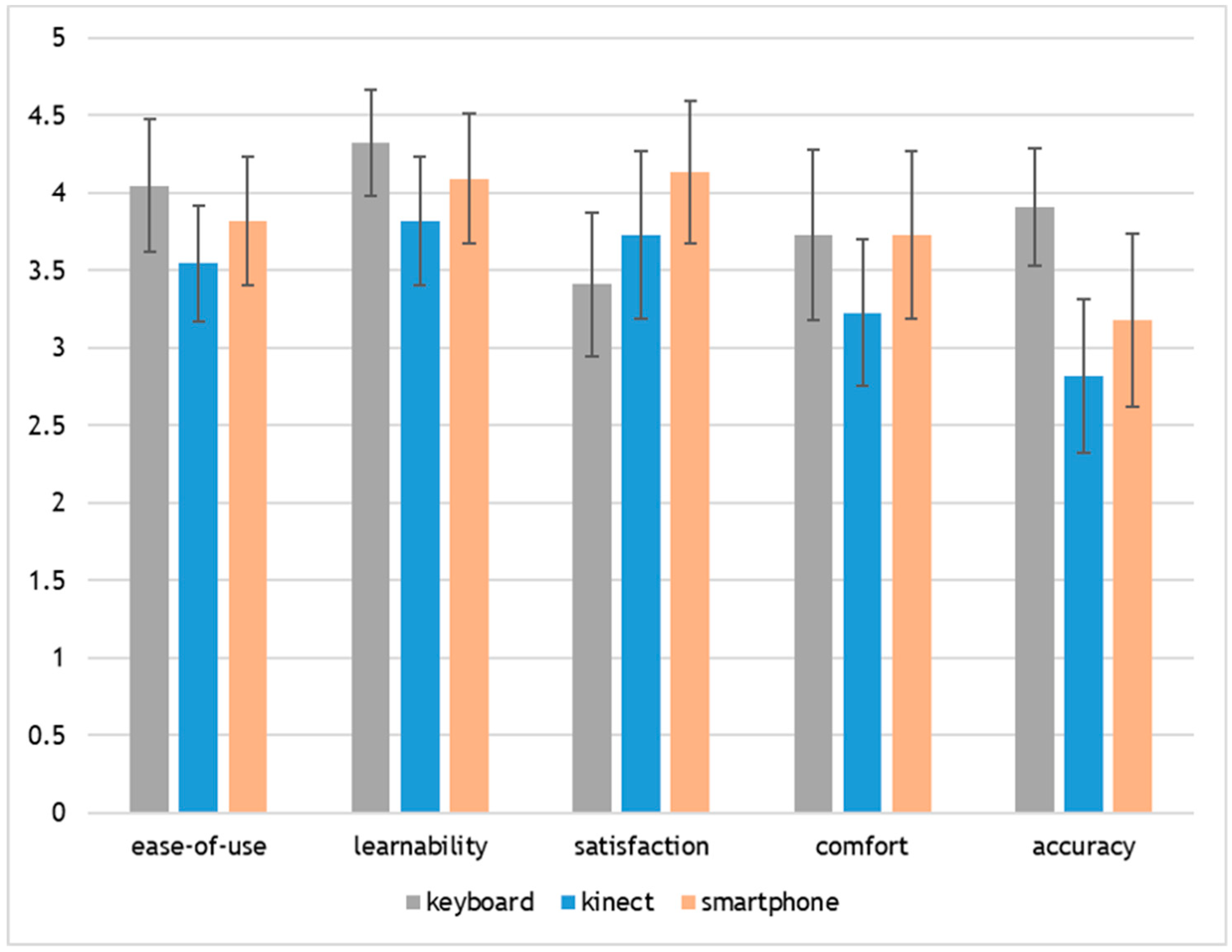
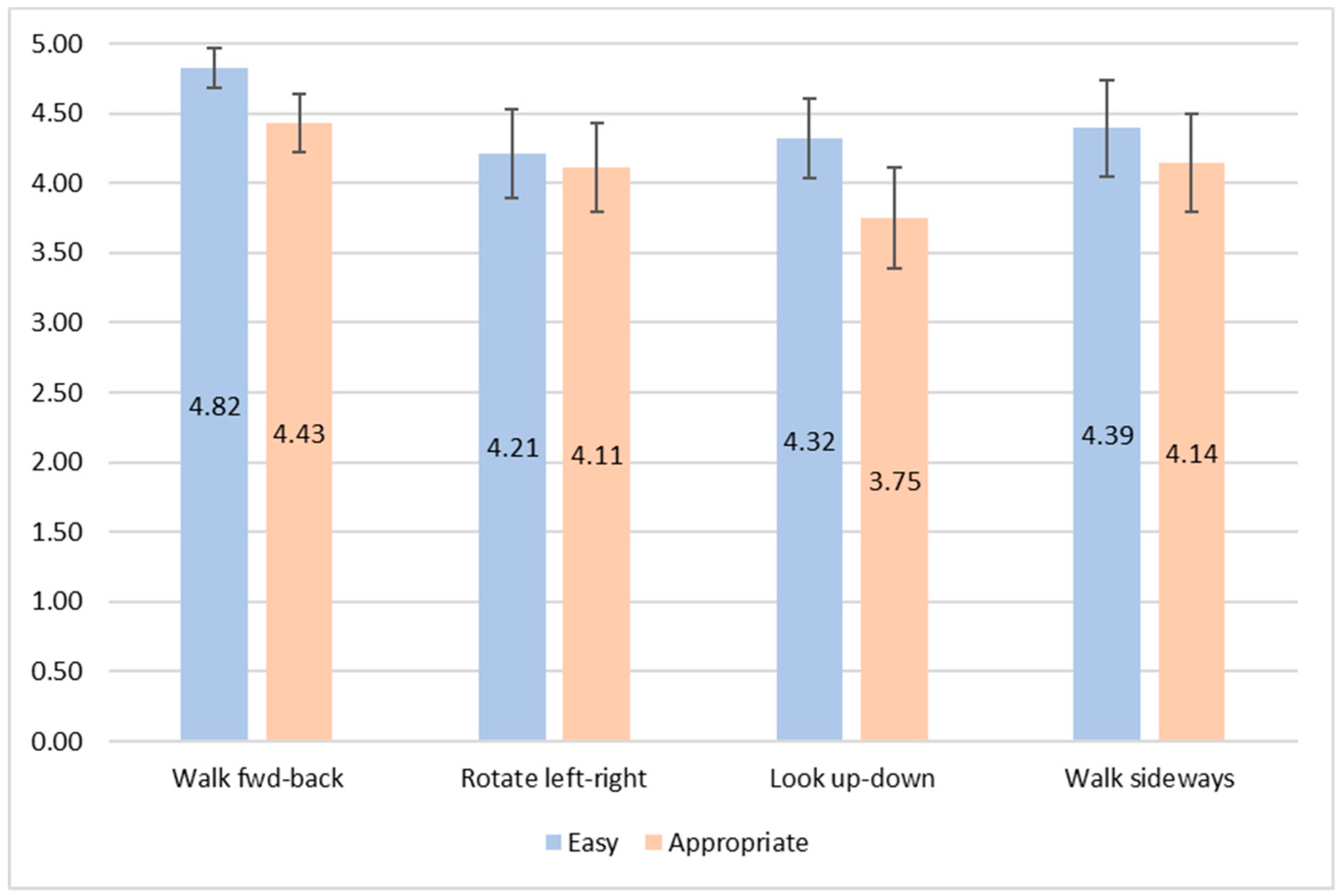
3.1.2. Subjective Ratings
3.1.3. User Comments and Observations
3.2. Gesture Elicitation Study for Smartphone Control
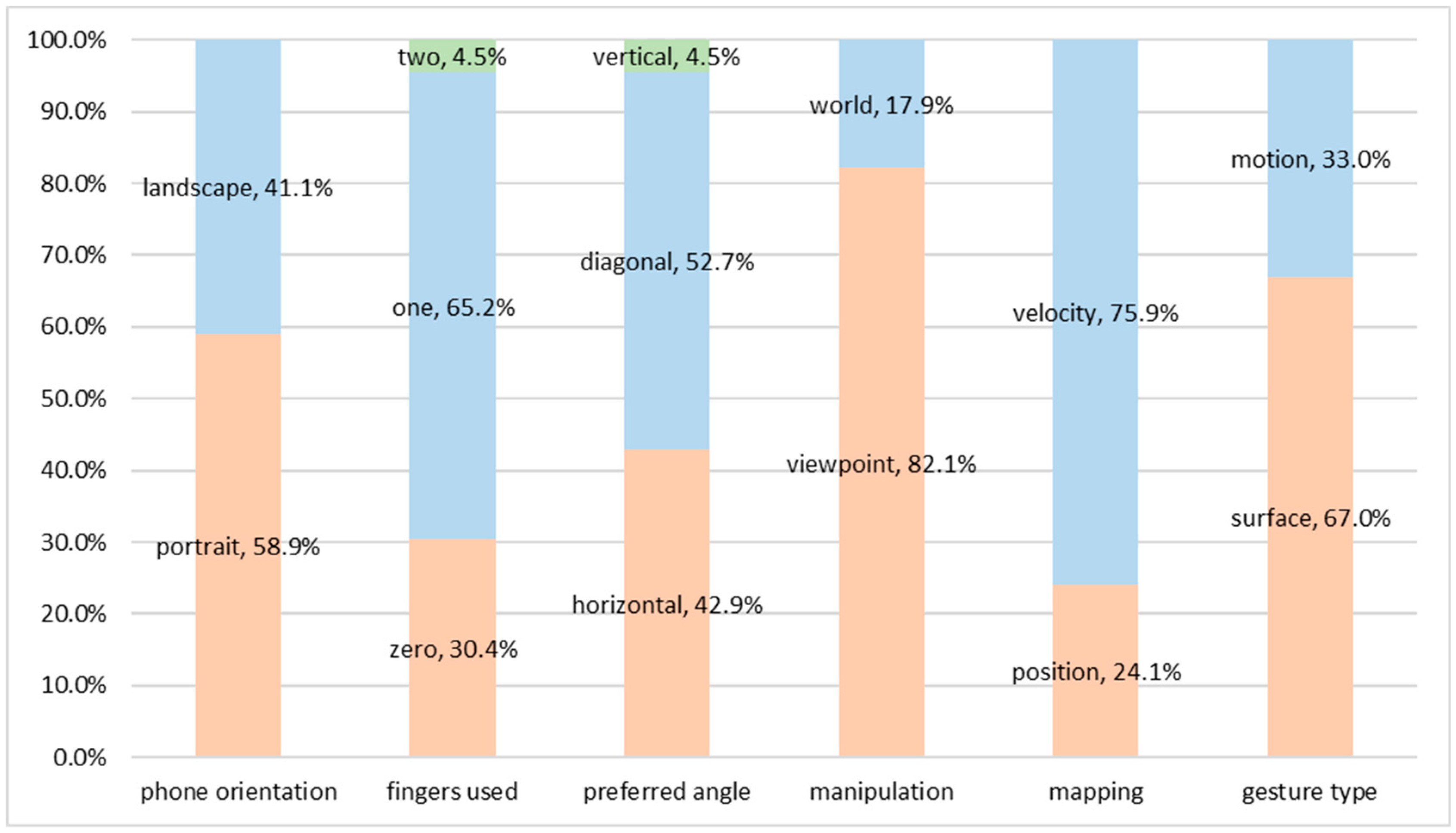
3.2.1. Taxonomy
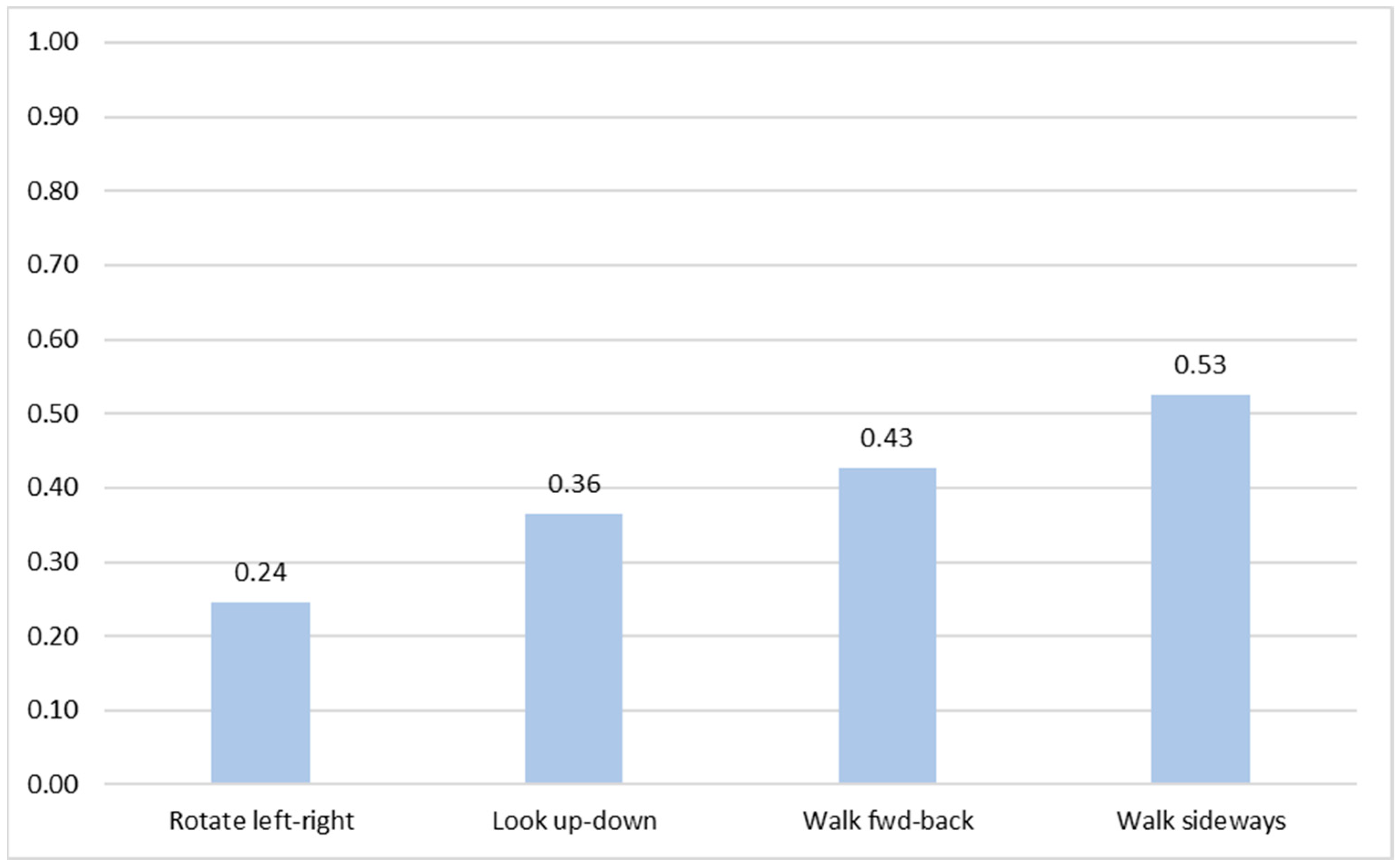
3.2.2. Agreement Scores
3.2.3. Subjective Ratings
3.2.4. Candidate Gestures
3.2.5. Comments and Observations
4. Discussion
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Appendix A
- (ease-of-use) I thought the technique was easy to use [1-strongly disagree to 5-strongly agree]
- (learnability) I learned the technique quickly [1-strongly disagree to 5-strongly agree]
- (satisfaction) I was satisfied with the use of the technique [1-strongly disagree to 5-strongly agree]
- (comfort) I felt comfortable using the technique [1-strongly disagree to 5-strongly agree]
- (accuracy) I could navigate with great accuracy using the technique [1-strongly disagree to 5-strongly agree]
- (easy) How easy was it for you to produce this gesture [1-very difficult to 5-very easy]
- (appropriate) How appropriate is your gesture for the task [1-not appropriate at all to 5-very appropriate]
References
- Kostakos, V.; Ojala, T. Public displays invade urban spaces. IEEE Pervasive Comput. 2013, 12, 8–13. [Google Scholar] [CrossRef]
- Hornecker, E.; Stifter, M. Learning from interactive museum installations about interaction design for public settings. In Proceedings of the 18th Australia conference on Computer-Human Interaction: Design: Activities, Artefacts and Environments, Sydney, Australia, 20–24 November 2006; pp. 135–142. [Google Scholar]
- Castro, B.P.; Velho, L.; Kosminsky, D. INTEGRARTE: Digital art using body interaction. In Proceedings of the Eighth Annual Symposium on Computational Aesthetics in Graphics, Visualization, and Imaging, Annecy, France, 4–6 June 2012. [Google Scholar]
- Häkkilä, J.; Koskenranta, O.; Posti, M.; He, Y. City Landmark as an Interactive Installation: Experiences with Stone, Water and Public Space. In Proceedings of the 8th International Conference on Tangible, Embedded and Embodied Interaction, Munich, Germany, 16–19 February 2014; pp. 221–224. [Google Scholar]
- Grammenos, D.; Drossis, G.; Zabulis, X. Public Systems Supporting Noninstrumented Body-Based Interaction. In Playful User Interfaces; Springer: Singapore, 2014; pp. 25–45. [Google Scholar] [Green Version]
- Krekhov, A.; Emmerich, K.; Babinski, M. Gestures from the Point of View of an Audience: Toward Anticipatable Interaction of Presenters with 3D Content. In Proceedings of the 2017 CHI Conference on Human Factors in Computing Systems, Denver, CO, USA, 6–11 May 2017; pp. 5284–5294. [Google Scholar]
- Bergé, L.P.; Perelman, G.; Raynal, M.; Sanza, C.; Serrano, M.; Houry-Panchetti, M.; Cabanac, R.; Dubois, E. Smartphone-Based 3D Navigation Technique for Use in a Museum Exhibit. In Proceedings of the Seventh International Conference on Advances in Computer-Human Interactions (ACHI 2014), Barcelona, Spain, 23–27 March 2014; pp. 252–257. [Google Scholar]
- Cristie, V.; Berger, M. Game Engines for Urban Exploration: Bridging Science Narrative for Broader Participants. In Playable Cities; Springer: Singapore, 2017; pp. 87–107. [Google Scholar]
- Darken, R.P.; Sibert, J.L. Wayfinding strategies and behaviors in large virtual worlds. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Vancouver, BC, Canada, 13–18 April 1996; Volume 96, pp. 142–149. [Google Scholar]
- Bowman, D.A.; Koller, D.; Hodges, L.F. Travel in Immersive Virtual Environments: An Evaluation of Viewpoint Motion Control Techniques Georgia Institute of Technology. In Proceedings of the 1997 Virtual Reality Annual International Symposium, Washington, DC, USA, 1–5 March 1997; pp. 45–52. [Google Scholar]
- Vosinakis, S.; Xenakis, I. A Virtual World Installation in an Art Exhibition: Providing a Shared Interaction Space for Local and Remote Visitors. In Proceedings of the Re-thinking Technology in Museums, Limerick, Ireland, 26–27 May 2011. [Google Scholar]
- Rufa, C.; Pietroni, E.; Pagano, A. The Etruscanning project: Gesture-based interaction and user experience in the virtual reconstruction of the Regolini-Galassi tomb. In Proceedings of the 2013 Digital Heritage International Congress, Marseille, France, 28 October–1 November 2013; pp. 653–660. [Google Scholar]
- Cho, N.; Shin, D.; Lee, D.; Kim, K.; Park, J.; Koo, M.; Kim, J. Intuitional 3D Museum Navigation System Using Kinect. In Information Technology Convergence; Springer: Dordrecht, The Netherlands, 2013; pp. 587–596. [Google Scholar]
- Roupé, M.; Bosch-Sijtsema, P.; Johansson, M. Interactive navigation interface for Virtual Reality using the human body. Comput. Environ. Urban Syst. 2014, 43, 42–50. [Google Scholar]
- Hernandez-Ibanez, L.A.; Barneche-Naya, V.; Mihura-Lopez, R. A comparative study of walkthrough paradigms for virtual environments using kinect based natural interaction. In Proceedings of the 22nd International Conference on Virtual System & Multimedia (VSMM), Kuala Lumpur, Malaysia, 17–21 October 2016; pp. 1–7. [Google Scholar]
- Guy, E.; Punpongsanon, P.; Iwai, D.; Sato, K.; Boubekeur, T. LazyNav: 3D ground navigation with non-critical body parts. In Proceedings of the 3DUI 2015, IEEE Symposium on 3D User Interfaces, Arles, France, 23–24 March 2015; pp. 43–50. [Google Scholar]
- Ren, G.; Li, C.; O’Neill, E.; Willis, P. 3D freehand gestural navigation for interactive public displays. IEEE Comput. Graph. Appl. 2013, 33, 47–55. [Google Scholar] [PubMed]
- Dias, P.; Parracho, J.; Cardoso, J.; Ferreira, B.Q.; Ferreira, C.; Santos, B.S. Developing and evaluating two gestural-based virtual environment navigation methods for large displays. In Lecture Notes in Computer Science; Springer: Singapore, 2015; Volume 9189, pp. 141–151. [Google Scholar]
- Kurdyukova, E.; Obaid, M.; André, E. Direct, bodily or mobile interaction? Comparing interaction techniques for personalized public displays. In Proceedings of the 11th International Conference on Mobile and Ubiquitous Multimedia (MUM’12), Ulm, Germany, 4–6 December 2012. [Google Scholar]
- Baldauf, M.; Adegeye, F.; Alt, F.; Harms, J. Your Browser is the Controller: Advanced Web-based Smartphone Remote Controls for Public Screens. In Proceedings of the 5th ACM International Symposium on Pervasive Displays, Oulu, Finland, 20–26 June 2016; pp. 175–181. [Google Scholar]
- Medić, S.; Pavlović, N. Mobile technologies in museum exhibitions. Turizam 2014, 18, 166–174. [Google Scholar] [CrossRef]
- Vajk, T.; Coulton, P.; Bamford, W.; Edwards, R. Using a mobile phone as a “Wii-like” controller for playing games on a large public display. Int. J. Comput. Games Technol. 2018, 2008. [Google Scholar] [CrossRef]
- Du, Y.; Ren, H.; Pan, G.; Li, S. Tilt & Touch: Mobile Phone for 3D Interaction. In Proceedings of the 13th international conference on Ubiquitous computing, Beijing, China, 17–21 September 2011; pp. 485–486. [Google Scholar]
- Shirazi, A.S.; Winkler, C.; Schmidt, A. Flashlight interaction: A study on mobile phone interaction techniques with large displays. In Proceedings of the 11th International Conference on Human-Computer Interaction with Mobile Devices and Services (MobileHCI ’09), Bonn, Germany, 15–18 September 2009. [Google Scholar]
- Joselli, M.; Da Silva, J.R.; Zamith, M.; Clua, E.; Pelegrino, M.; Mendonça, E.; Soluri, E. An architecture for game interaction using mobile. In Proceedings of the 4th International IEEE Consumer Electronic Society—Games Innovation Conference (IGiC 2012), Rochester, NY, USA, 7–9 September 2012; pp. 1–5. [Google Scholar]
- Liang, H.; Shi, Y.; Lu, F.; Yang, J.; Papangelis, K. VRMController: An input device for navigation activities in virtual reality environments. In Proceedings of the 15th ACM SIGGRAPH Conference on Virtual-Reality Continuum and Its Applications in Industry, Zhuhai, China, 3–4 December 2016; pp. 455–460. [Google Scholar]
- Wobbrock, J.O.; Aung, H.H.; Rothrock, B.; Myers, B.A. Maximizing the guessability of symbolic input. In Proceedings of the CHI ‘05 Extended Abstracts on Human Factors in Computing Systems, Portland, OR, USA, 2–7 April 2005; pp. 1869–1872. [Google Scholar]
- Du, G.; Degbelo, A.; Kray, C.; Painho, M. Gestural interaction with 3D objects shown on public displays: An elicitation study. Int. Des. Archit. J. 2018, 38, 184–202. [Google Scholar]
- Obaid, M.; Kistler, F.; Häring, M.; Bühling, R.; André, E. A Framework for User-Defined Body Gestures to Control a Humanoid Robot. Int. J. Soc. Robot. 2014, 6, 383–396. [Google Scholar] [CrossRef]
- Wobbrock, J.O.; Morris, M.R.; Wilson, A.D. User-defined gestures for surface computing Proceedings of the 27th international conference on Human factors in computing systems. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems (CHI’09), Boston, MA, USA, 4–9 April 2009; p. 1083. [Google Scholar]
- LaViola, J.J., Jr.; Kruijff, E.; McMahan, R.P.; Bowman, D.; Poupyrev, I.P. 3D User Interfaces: Theory and Practice; Addison-Wesley Professional: Boston, MA, USA, 2017. [Google Scholar]
- Ruiz, J.; Li, Y.; Lank, E. User-defined motion gestures for mobile interaction. In Proceedings of the SIGCHI Conference on Human Factors in Computing Systems, Vancouver, BC, Canada, 7–12 May 2011; pp. 197–206. [Google Scholar]
- Pazmino, P.J.; Lyons, L. An exploratory study of input modalities for mobile devices used with museum exhibits. In Proceedings of the 2011 Annual Conference on Human Factors in Computing Systems (CHI’11), Vancouver, BC, Canada, 7–12 May 2011; pp. 895–904. [Google Scholar]
- Burigat, S.; Chittaro, L. Navigation in 3D virtual environments: Effects of user experience and location-pointing navigation aids. Int. J. Hum. Comput. Stud. 2007, 65, 945–958. [Google Scholar] [CrossRef]
- Papaefthymiou, M.; Plelis, K.; Mavromatis, D.; Papagiannakis, G. Mobile Virtual Reality Featuring A Six Degrees of Freedom Interaction Paradigm in A Virtual Museum Application; Technical Report; FORTH-ICS/TR-462; FORTH: Crete, Greece, 2015. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dimension | Values | Description |
|---|---|---|
| phone orientation | portrait | User is holding the phone in vertical (portrait) orientation |
| landscape | User is holding the phone in horizontal (landscape) orientation | |
| fingers used | zero fingers | No touch actions are performed |
| one finger | A single touch or drag action is performed | |
| two fingers | An action that uses two fingers | |
| preferred angle | horizontal | User is holding the phone almost horizontally—parallel to the ground |
| diagonal | Holding the phone with an angle around 45° from the ground | |
| vertical | User is holding the phone almost vertically to the ground, facing the screen | |
| manipulation | viewpoint | User actions manipulate the viewpoint (camera) |
| world | User actions manipulate the whole scene | |
| mapping | position | The gesture directly controls the position of the viewpoint |
| velocity | The gesture controls the moving velocity of the viewpoint |
| Task | Candidate Gesture(s) | Description | Perc. of Agreement |
|---|---|---|---|
| Walk fwd-back | virtual joystick | Drag up or down to move forwards or backwards | 60.71% |
| Rotate left-right | virtual joystick | Drag left or right to rotate | 39.29% |
| tilt horizontal | Rotate device to the left or right to turn | 21.43% | |
| Look up-down | virtual joystick | Drag up or down to look in the respective direction | 50% |
| tilt vertical | Rotate device upwards or downwards | 32.14% | |
| Walk sideways | virtual joystick | Drag left or right to move sideways | 71.43% |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vosinakis, S.; Gardeli, A. On the Use of Mobile Devices as Controllers for First-Person Navigation in Public Installations. Information 2019, 10, 238. https://doi.org/10.3390/info10070238
Vosinakis S, Gardeli A. On the Use of Mobile Devices as Controllers for First-Person Navigation in Public Installations. Information. 2019; 10(7):238. https://doi.org/10.3390/info10070238
Chicago/Turabian StyleVosinakis, Spyros, and Anna Gardeli. 2019. "On the Use of Mobile Devices as Controllers for First-Person Navigation in Public Installations" Information 10, no. 7: 238. https://doi.org/10.3390/info10070238
APA StyleVosinakis, S., & Gardeli, A. (2019). On the Use of Mobile Devices as Controllers for First-Person Navigation in Public Installations. Information, 10(7), 238. https://doi.org/10.3390/info10070238