Traffic Sign Detection Method Based on Improved SSD




Abstract
1. Introduction
- Using the TT100K dataset [14] to complete the lightweight SSD model training, this model detects the traffic signs that are presented in the image and pinpoints their locations in the image and assigns them to the correct traffic categories.
- Cutting and adjusting the size of the alternative area of the traffic sign in the input image based on these coordinates as the input image for the next color detection.
- Converting the image from the RGB (red, green, blue) color space to the HSV (hue, saturation, value) space, and using the color detection algorithm based on the phase difference method to conduct color detection on the obtained image and connecting to the connected components to generate a binary image of the corresponding color.
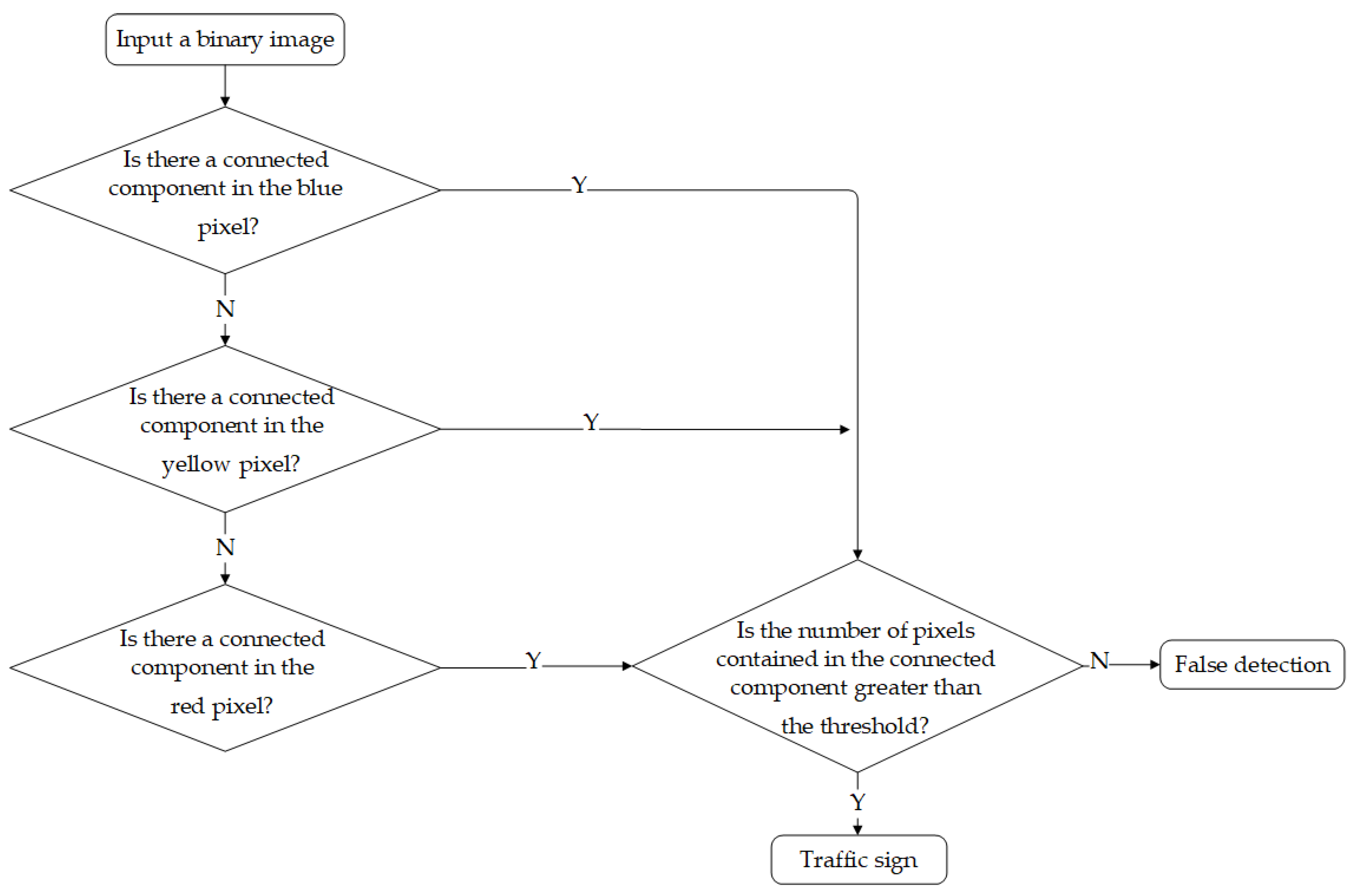
- Calculating the connected component of the binary image obtained in the previous step, and filtering the qualified detection results according to the maximum threshold of the connected component area.
2. Related Work
2.1. Traditional Traffic Sign Detection Algorithm
2.2. CNN-Based Traffic Sign Detection Algorithm
2.3. Traffic Sign Detection Algorithm Based on the Attention Mechanism
3. Proposed Method
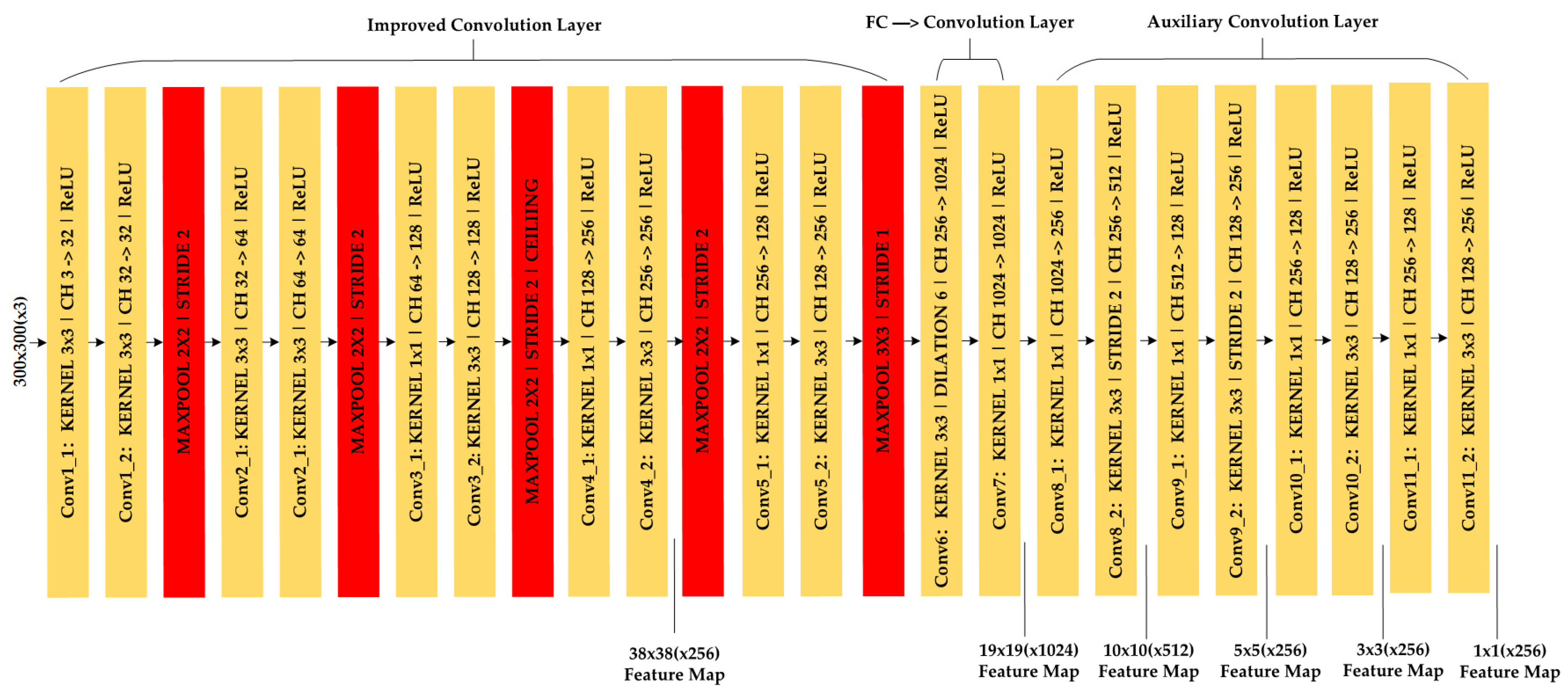
3.1. Lightweight SSD Network Structure
3.2. Color Detection Algorithm Based on the Phase Difference Method
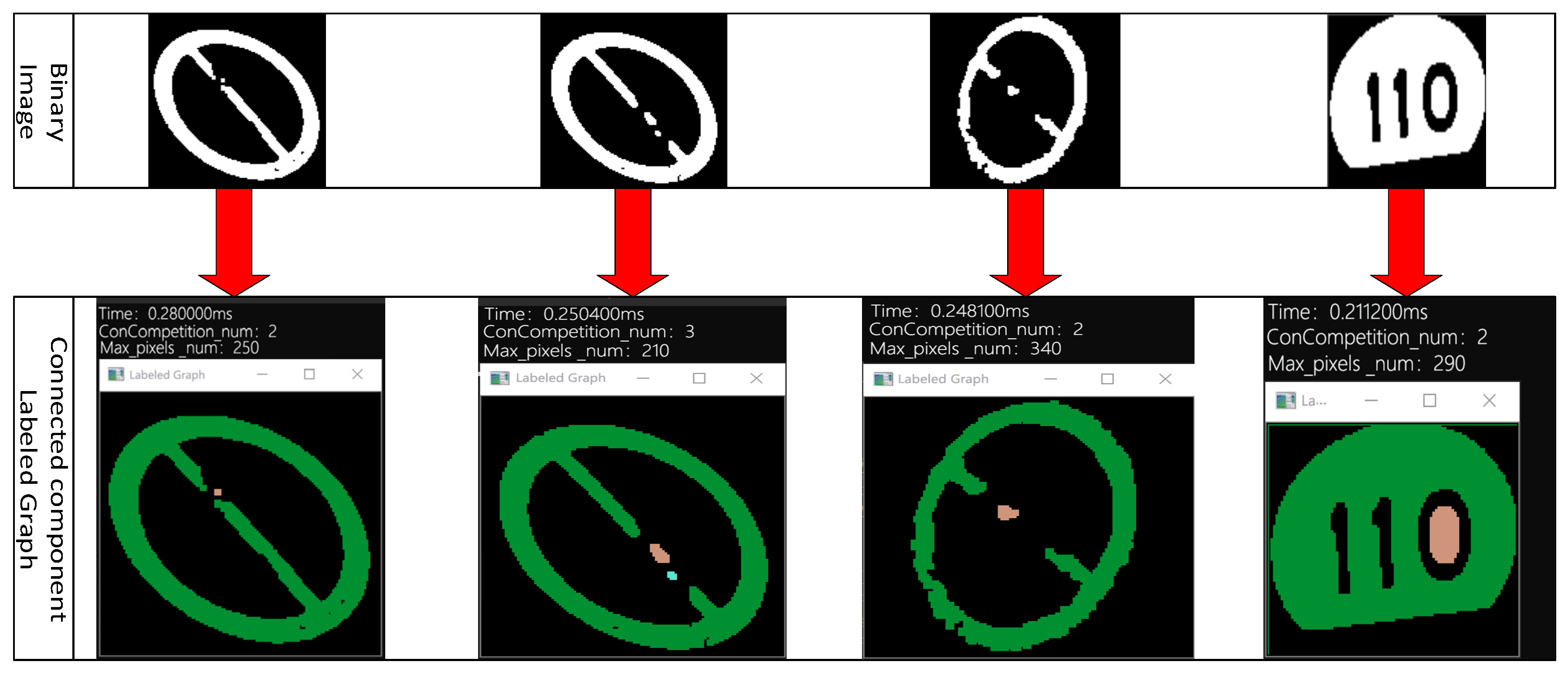
3.3. Connected Component Calculation Based on the Two-Pass Algorithm
| Algorithm 1: Two-Pass algorithm based on the four-neighboring method. |
| Input: Binary image Output: Connected component grouping
|
4. Experiment
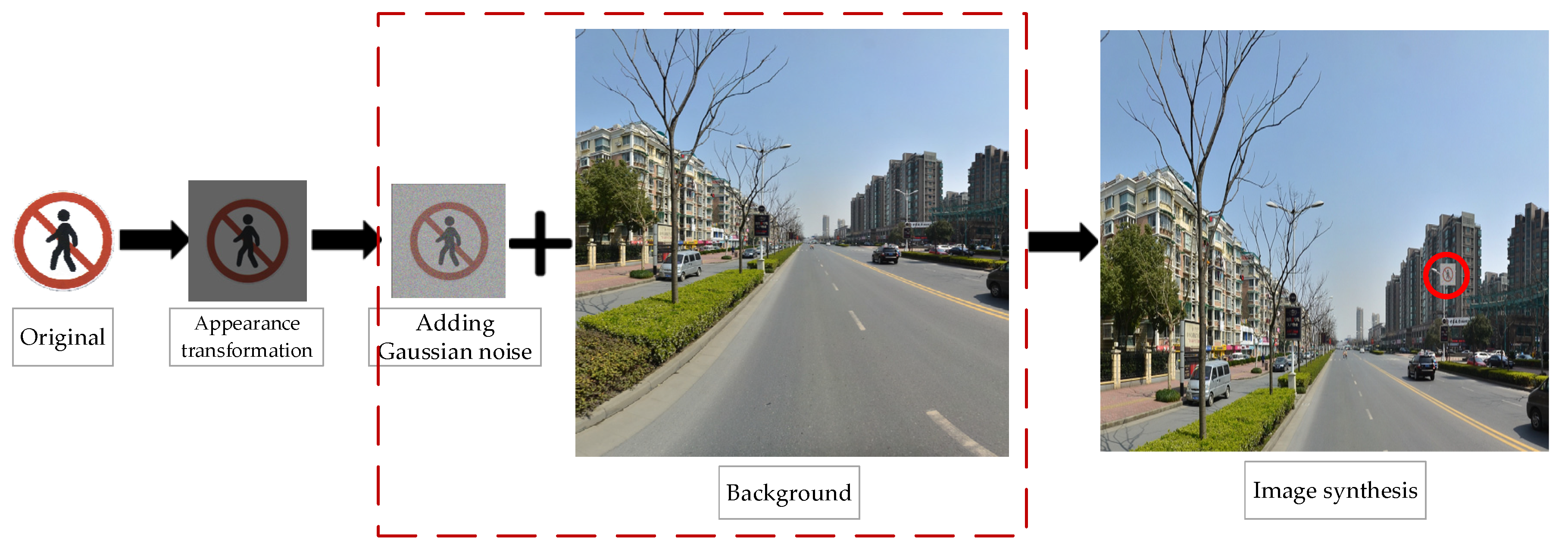
4.1. Datasets and Setting
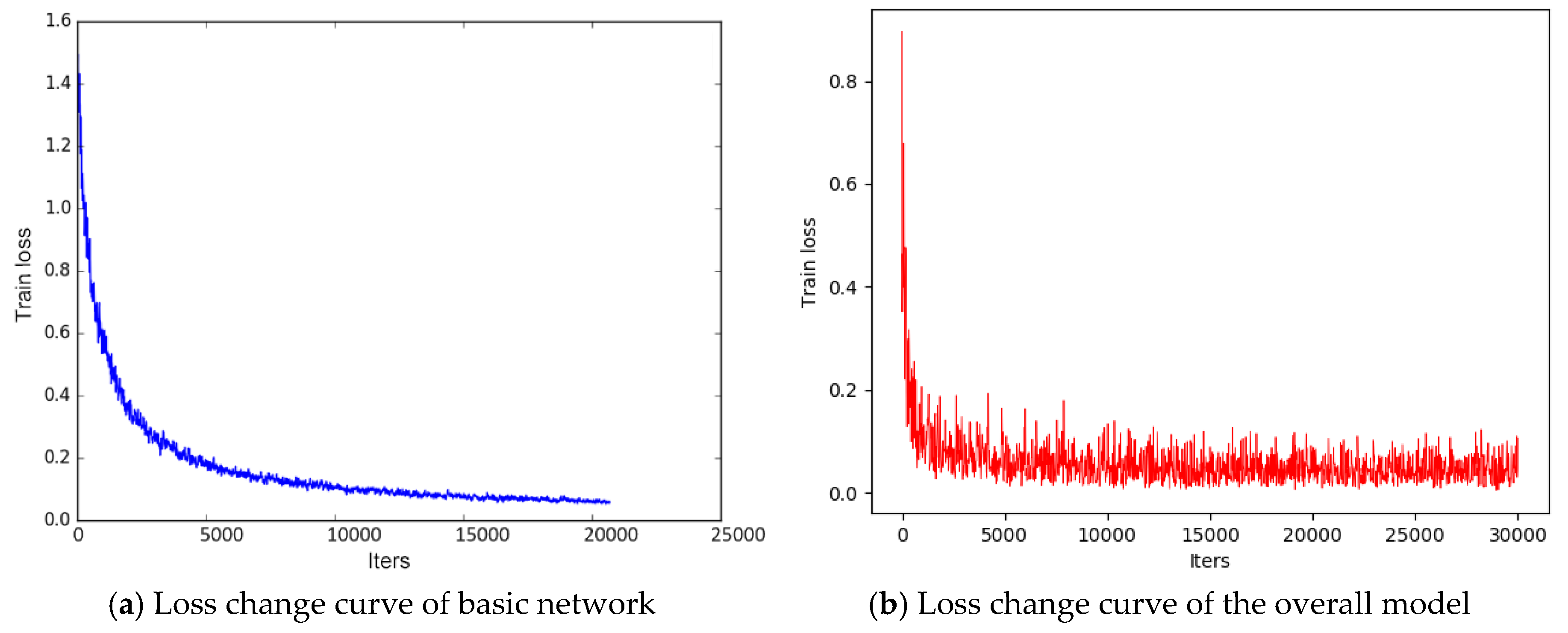
4.2. Experimental Results and Analysis
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Zhang, J.; Huang, Q.; Wu, H.; Liu, Y. A shallow network with combined pooling for fast traffic sign recognition. Information 2017, 8, 45. [Google Scholar] [CrossRef]
- Zhang, J.; Xie, Z.; Sun, J.; Zou, X.; Wang, J. A cascaded R-CNN with multiscale attention and imbalanced samples for traffic sign detection. IEEE Access 2020, 8, 29742–29754. [Google Scholar] [CrossRef]
- Ellahyani, A.; El Ansari, M.; El Jaafari, I. Traffic sign detection and recognition based on random forests. Appl. Soft Comput. 2016, 46, 805–815. [Google Scholar] [CrossRef]
- Yıldız, G.; Dizdaroğlu, B. Traffic Sign Detection via Color and Shape-Based Approach. In Proceedings of the International Informatics and Software Engineering Conference, Ankara, Turkey, 6 November 2019; pp. 1–5. [Google Scholar]
- Luo, H.; Yang, Y.; Tong, B.; Wu, F.; Fan, B. Traffic sign recognition using a multi-task convolutional neural network. IEEE Trans. Intell. Transp. Syst. 2017, 19, 1100–1111. [Google Scholar] [CrossRef]
- Hussain, S.; Abualkibash, M.; Tout, S. A survey of traffic sign recognition systems based on convolutional neural networks. In Proceedings of the IEEE International Conference on Electro/Information Technology, Rochester, MI, USA, 3–5 May 2018; pp. 570–573. [Google Scholar]
- Arcos-Garcia, A.; Alvarez-Garcia, J.A.; Soria-Morillo, L.M. Evaluation of deep neural networks for traffic sign detection systems. Neurocomputing 2018, 316, 332–344. [Google Scholar] [CrossRef]
- Kamal, U.; Tonmoy, T.I.; Das, S.; Hasan, M.K. Automatic traffic sign detection and recognition using SegU-Net and a modified Tversky loss function with L1-constraint. IEEE Trans. Intell. Transp. Syst. 2019, 21, 1467–1479. [Google Scholar] [CrossRef]
- Lee, H.S.; Kim, K. Simultaneous traffic sign detection and boundary estimation using convolutional neural network. IEEE Trans. Intell. Transp. Syst. 2018, 19, 1652–1663. [Google Scholar] [CrossRef]
- Yang, T.; Long, X.; Sangaiah, A.K.; Zheng, Z.; Tong, C. Deep detection network for real-life traffic sign in vehicular networks. Comput. Netw. 2018, 136, 95–104. [Google Scholar] [CrossRef]
- Yuan, Y.; Xiong, Z.; Wang, Q. VSSA-NET: Vertical spatial sequence attention network for traffic sign detection. IEEE Trans. Image Process. 2019, 28, 3423–3434. [Google Scholar] [CrossRef]
- Zhang, J.; Wang, W.; Lu, C.; Wang, J.; Sangaiah, A.K. Lightweight deep network for traffic sign classification. Ann. Telecommun. 2019, 75, 369–379. [Google Scholar] [CrossRef]
- Song, S.; Que, Z.; Hou, J.; Du, S.; Song, Y. An efficient convolutional neural network for small traffic sign detection. J. Syst. Archit. 2019, 97, 269–277. [Google Scholar] [CrossRef]
- Zhu, Z.; Liang, D.; Zhang, S.; Huang, X.; Li, B.; Hu, S. Traffic-sign detection and classification in the wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2110–2118. [Google Scholar]
- Le, T.T.; Tran, S.T.; Mita, S.; Nguyen, T.D. Real time traffic sign detection using color and shape-based features. In Asian Conference on Intelligent Information and Database Systems; Springer: Berlin/Heidelberg, Germany, 2010; pp. 268–278. [Google Scholar]
- Chen, T.; Lu, S. Accurate and efficient traffic sign detection using discriminative adaboost and support vector regression. IEEE Trans. Veh. Technol. 2015, 65, 4006–4015. [Google Scholar] [CrossRef]
- Zhang, J.; Huang, M.; Jin, X.; Li, X. A real-time chinese traffic sign detection algorithm based on modified YOLOv2. Algorithms 2017, 10, 127. [Google Scholar] [CrossRef]
- Ibrahem, H.; Salem, A.; Kang, H.S. Weakly Supervised Traffic Sign Detection in Real Time Using Single CNN Architecture for Multiple Purposes. In Proceedings of the IEEE International Conference on Consumer Electronics, Las Vegas, NV, USA, 4–6 January 2020; pp. 1–4. [Google Scholar]
- Nguyen, H. Fast Traffic Sign Detection Approach Based on Lightweight Network and Multilayer Proposal Network. J. Sens. 2020. [Google Scholar] [CrossRef]
- Zhang, H.; Qin, L.; Li, J.; Guo, Y.; Zhou, Y.; Zhang, J.; Xu, Z. Real-Time Detection Method for Small Traffic Signs Based on Yolov3. IEEE Access 2020, 8, 64145–64156. [Google Scholar] [CrossRef]
- Mnih, V.; Heess, N.; Graves, A. Recurrent models of visual attention. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 2204–2212. [Google Scholar]
- Tian, Y.; Gelernter, J.; Wang, X.; Li, J.; Yu, Y. Traffic sign detection using a multi-scale recurrent attention network. IEEE Trans. Intell. Transp. Syst. 2019, 20, 4466–4475. [Google Scholar] [CrossRef]
- Kastner, R.; Michalke, T.; Burbach, T.; Fritsch, J.; Goerick, C. Attention-based traffic sign recognition with an array of weak classifiers. In Proceedings of the IEEE Intelligent Vehicles Symposium, La Jolla, CA, USA, 21–24 June 2010; pp. 333–339. [Google Scholar]
- Zhang, J.; Hui, L.; Lu, J.; Zhu, Y. Attention-based neural network for traffic sign detection. In Proceedings of the International Conference on Pattern Recognition, Sousse, Tunisia, 21–23 December 2018; pp. 1839–1844. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Saravanan, G.; Yamuna, G.; Nandhini, S. Real time implementation of RGB to HSV/HSI/HSL and its reverse color space models. In Proceedings of the International Conference on Communication and Signal Processing, Apecmadras, India, 6–8 April 2016; pp. 462–466. [Google Scholar]
- Spagnolo, F.; Perri, S.; Corsonello, P. An Efficient Hardware-Oriented Single-Pass Approach for Connected Component Analysis. Sensors 2019, 19, 3055. [Google Scholar] [CrossRef]
- Zeng, Y.; Xu, X.; Fang, Y.; Zhao, K. Traffic sign recognition using deep convolutional networks and extreme learning machine. In International Conference on Intelligent Science and Big Data Engineering; Springer: Cham, Switzerland, 2015; pp. 272–280. [Google Scholar]
- Samir, S.; Emary, E.; El-Sayed, K.; Onsi, H. Optimization of a Pre-Trained AlexNet Model for Detecting and Localizing Image Forgeries. Information 2020, 11, 275. [Google Scholar] [CrossRef]
- Kim, K.H.; Hong, S.; Roh, B.; Cheon, Y.; Park, M. PVANet: Deep but lightweight neural networks for real-time object detection. arXiv 2016, arXiv:1608.08021. [Google Scholar]
- Song, Y.; Fan, R.; Huang, S.; Zhu, Z.; Tong, R. A three-stage real-time detector for traffic signs in large panoramas. Comput. Vis. Media 2019, 5, 403–416. [Google Scholar] [CrossRef]
- Cui, L.; Lv, P.; Jiang, X.; Gao, Z.; Zhou, B.; Zhang, L.; Shao, L.; Xu, M. Context-Aware Block Net for Small Object Detection. IEEE Trans. Cybern. 2020. [Google Scholar] [CrossRef] [PubMed]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Color | H | S | V |
|---|---|---|---|
| Yellow | |||
| Red | |||
| Blue |
| Network Model | AP | Recall | FPS | ||||||
|---|---|---|---|---|---|---|---|---|---|
| Warning Signs | Prohibition Signs | Mandatory Signs | mAP | Warning Signs | Prohibition Signs | Mandatory Signs | mR | ||
| Lightweight SSD | 0.68 | 0.72 | 0.73 | 0.71 | 0.74 | 0.76 | 0.77 | 0.76 | 32 |
| PVANet [30] | 0.67 | 0.74 | 0.72 | 0.71 | 0.76 | 0.78 | 0.83 | 0.78 | 27 |
| MSA_YOLOv3 [20] | 0.84 | 0.86 | 0.88 | 0.86 | 0.80 | 0.81 | 0.92 | 0.84 | 9 |
| CMA R-CNN [2] | - | - | - | 0.98 | - | - | - | 0.90 | 3 |
| TSD Net [31] | 0.52 | 0.44 | 0.61 | 0.52 | - | - | - | 0.65 | 60 |
| Faster-RCNN [14] | 0.55 | 0.57 | 0.47 | 0.53 | 0.54 | 0.56 | 0.58 | 0.56 | 7 |
| CAB-s Net [32] | 0.87 | 0.88 | 0.91 | 0.89 | - | - | - | - | 27 |
| Baseline SSD | 0.70 | 0.72 | 0.74 | 0.72 | 0.81 | 0.80 | 0.82 | 0.81 | 24 |
| Ours | 0.73 | 0.78 | 0.74 | 0.75 | 0.80 | 0.84 | 0.82 | 0.82 | 29 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
You, S.; Bi, Q.; Ji, Y.; Liu, S.; Feng, Y.; Wu, F. Traffic Sign Detection Method Based on Improved SSD. Information 2020, 11, 475. https://doi.org/10.3390/info11100475
You S, Bi Q, Ji Y, Liu S, Feng Y, Wu F. Traffic Sign Detection Method Based on Improved SSD. Information. 2020; 11(10):475. https://doi.org/10.3390/info11100475
Chicago/Turabian StyleYou, Shuai, Qiang Bi, Yimu Ji, Shangdong Liu, Yujian Feng, and Fei Wu. 2020. "Traffic Sign Detection Method Based on Improved SSD" Information 11, no. 10: 475. https://doi.org/10.3390/info11100475
APA StyleYou, S., Bi, Q., Ji, Y., Liu, S., Feng, Y., & Wu, F. (2020). Traffic Sign Detection Method Based on Improved SSD. Information, 11(10), 475. https://doi.org/10.3390/info11100475