1. Introduction
Research on content-based visual information retrieval started in the 1990s. Earlier retrieval systems concentrated on image data based on visual content, such as color, texture, and shape [
1]. In the early days, video retrieval systems only extended to image retrieval systems that segmented videos into shots and extracted keyframes from these shots. On the other hand, analyzing video content, which fully considers video temporality, has been an active research area for the past several years and is likely to attract even more attention in years to come [
1]. Video data can be used for commercial, educational, and entertainment purposes. Due to the decreasing cost of storage devices, higher transmission rates, and improved compression techniques, digital video is available in an ever-increasing rate. All of these popularized the use of video data for retrieval, browsing, and searching. Due to its vast volume, effective classification techniques are required for efficient retrieval, browsing, and searching of video data.
Video data conveys particular visual information. Due to its content richness, video outperforms any other multimedia presentation. Content-based retrieval systems process information contained in a video’s data and creates an abstraction of its content in terms of visual attributes. Any query operation deals with this abstraction rather than the entire data, hence the term ‘content-based’. Similar to the text-based retrieval system, a content-based image or video retrieval system has to interpret the contents of a document’s collection (i.e., images or video records) and rank them according to the level of their relevance to the query.
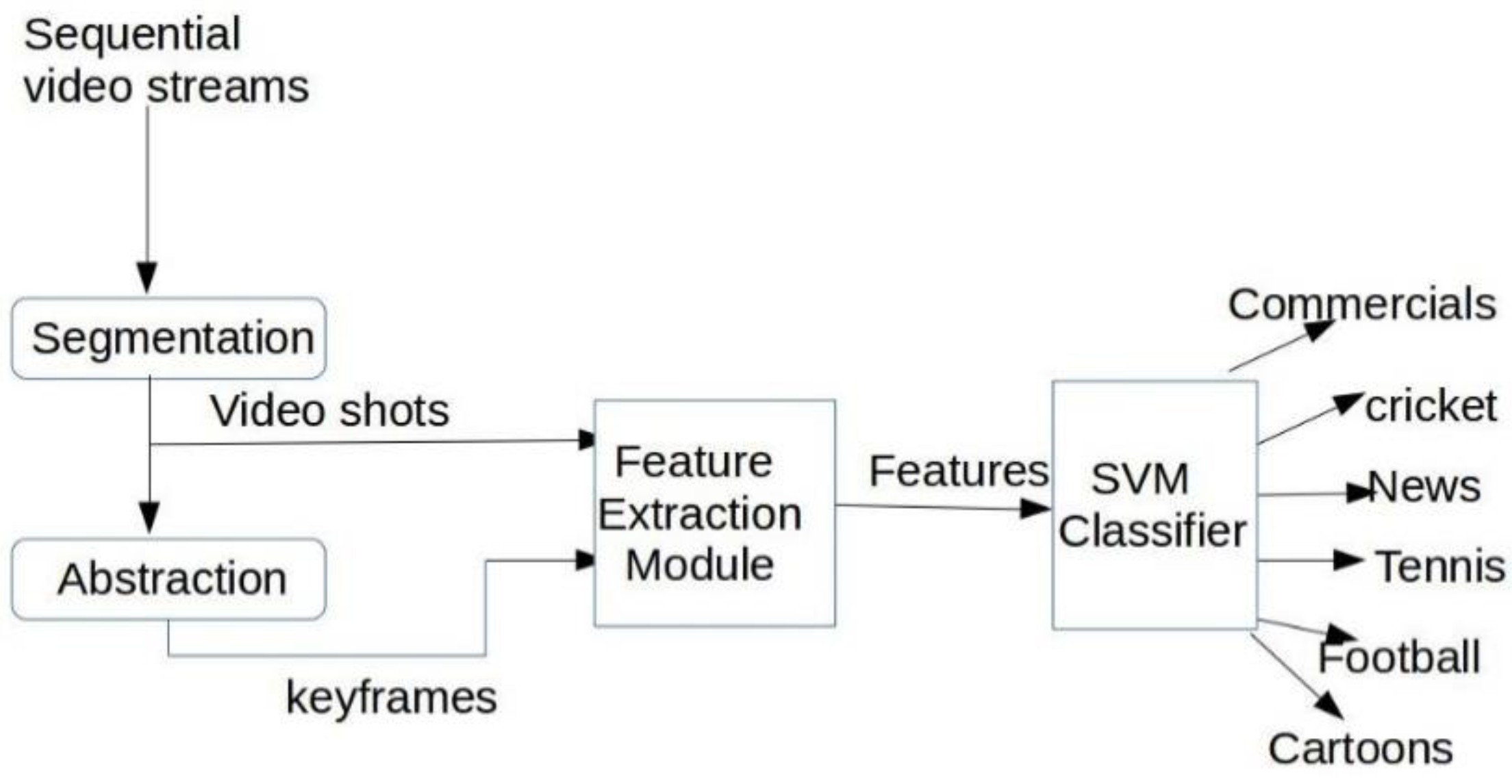
Considering the large volume, video data needs to be structured and indexed for efficient retrieval. Content-based image retrieval technologies can be extended to video retrieval as well. However, such extension is not straightforward. A video clip or a shot is a sequence of image frames. Therefore, indexing each frame as still images involves high redundancy and increased complexity. Before indexing can be done, we need to identify the structure of the video and decompose it into basic components. Then, indices can be built based on structural information and information from individual image frames. In order to achieve this, the video data has to be segmented into meaningful temporal units or segments called video shots. A shot consists of a sequence of frames recorded continuously and representing a continuous action in time and space. The video data is then represented as a set of feature attributes such as color, texture, shape, motion, and spatial layout.
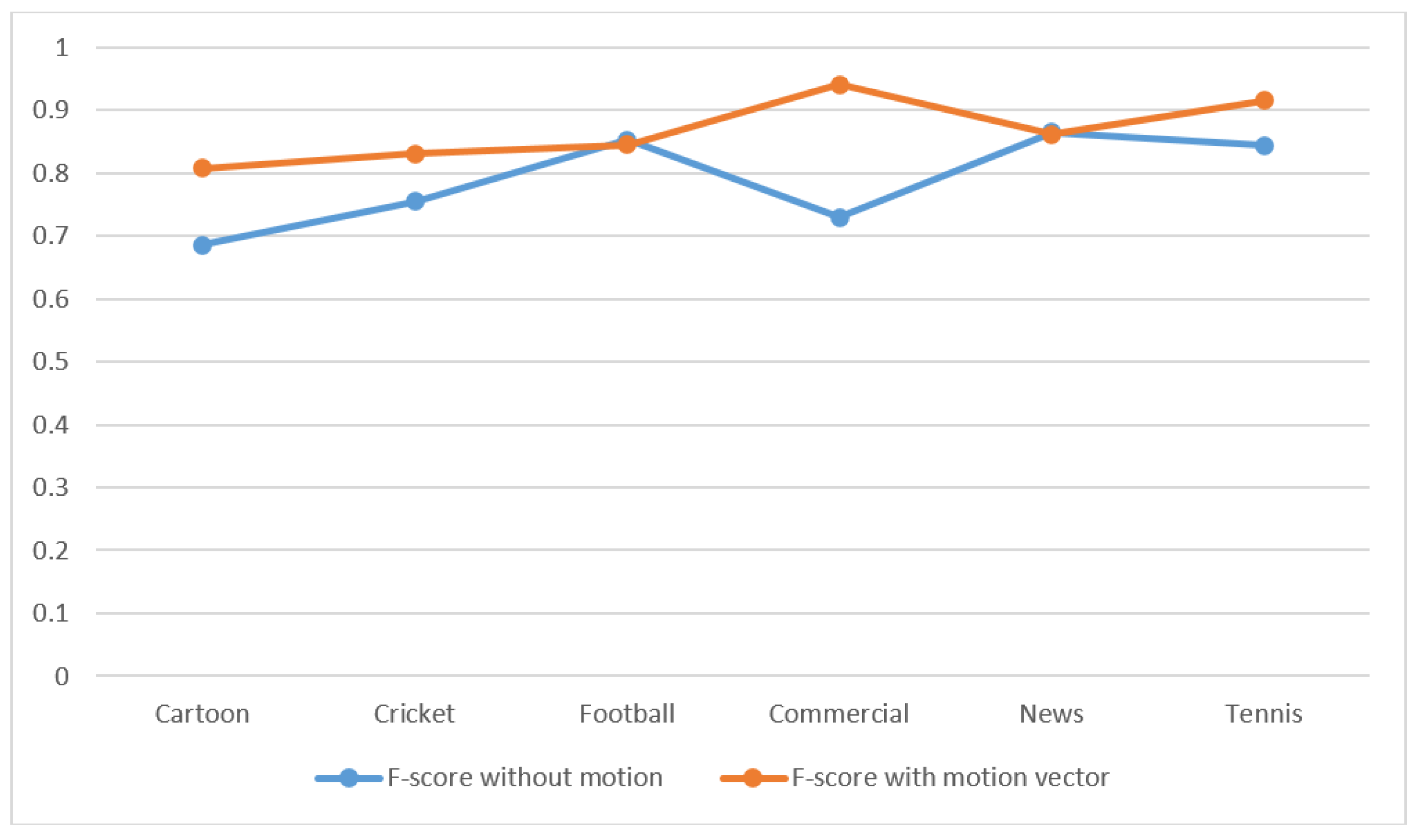
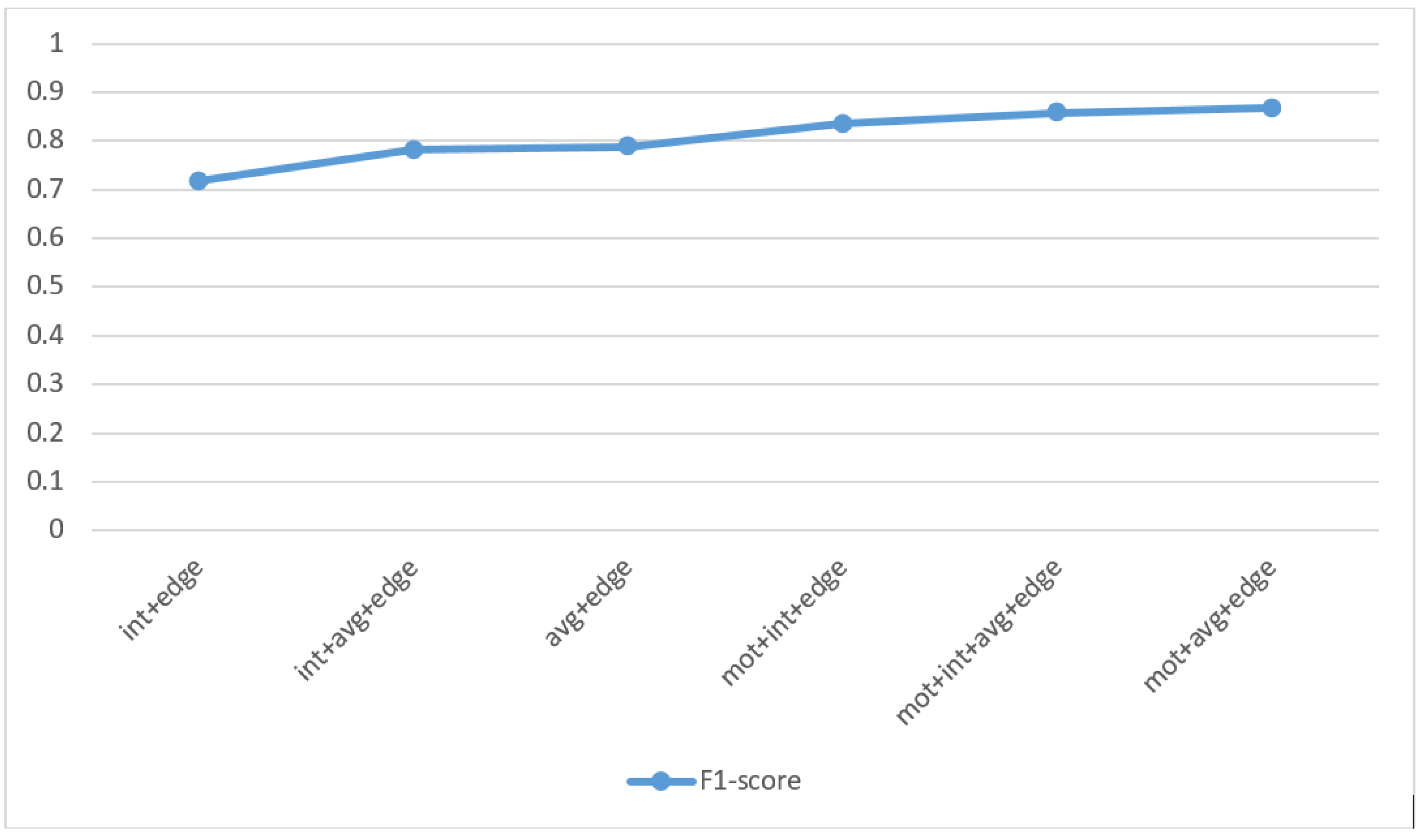
In this paper, we proposed an approach where spatio-temporal information was included with low-level features. During feature extraction, a group of frame descriptors was used to capture temporal information regarding video data and an edge histogram descriptor was used to obtain spatial information. Similarly, we associated a motion vector as a feature for capturing temporal information for efficient classification. All of these features were provided as inputs to the classifier.
The rest of the paper is organized as follows.
Section 2 presents the summary of the related works.
Section 3 contains methodology that includes segmentation, abstraction, feature extraction, and classification. Experimental results and comparison with state-of-the-art approaches are provided in
Section 4. Result s and analysis are given in
Section 5 and our concluding remarks are provided in
Section 6.
2. Related Works
In recent years, automatic content-based video classification has emerged as an important problem in the field of video analysis and multimedia database. To access the query-based video database, approaches typically require users to provide an example video clip or sketch and the system should give the similar clips. The search for similar clips can be made efficient if the video data is classified into different genres. To help the users find and retrieve clips that are more relevant to the query, techniques need to be developed to categorize the data into one of the predefined classes. Ferman and Tekalp [
2] employed a probabilistic framework to construct descriptors in terms of location, objects, and events. In our strategy, hidden Markov models (HMMs) and Bayesian belief networks (BBNs) were used at various stages to characterize content domains and extract relevant semantic information. A decision tree video indexing technique was considered in [
3] to classify videos in genres such as music, commercials, and sports. A combination of several classifiers can improve the performance of individual classifiers, as was the case in [
4].
Convolutional neural networks (CNNs) are used [
5] for large scale video classification. In such instances, the run time performance improves via CNN architecture, which process inputs at two spatial resolutions. In [
6], recurrent convolutional neural networks (RCNNs) were used for video classification tasks, which are good at learning relations from input sequences.
In [
7], the authors investigated low-level audio–visual features for video classification. The features included Mel-frequency cepstrum coefficients (MFCC) and MPEG-7 visual descriptors such as scalable color, color layout, and homogeneous structure. Visual descriptors such as histogram-oriented gradients (HOG), histogram of optical flow (HOF), and motion boundary histograms (MBH) were used for video classification in [
8]. Computational efficiency was achieved here for video classification using the bag-of-words pipeline. We placed more importance on computational efficiency than computational accuracy. In the proposed method, video classification was done using feature combinations of an edge-histogram, average histogram, and motion vector. This novel approach provided better results than the state-of-the-art methods.
The large size of the video files was a problem for efficient search for data and speedy retrieval of the relevant information required by the user. Therefore, videos were segmented into sequences of frames that represented continuous action in time and space. These sequences of frames are called video shots. The shot boundary detection algorithm is based on a comparison of color histograms of adjacent frames to detect those frames where image changes are significant. A shot boundary is hypothesized as follows: the distance between histograms of the current frame and the previous frame is higher than an absolute threshold. Many different shot detection algorithms have been proposed in order to automatically detect shot boundaries. The simplest way to measure the spatial similarity between the two frames ‘
fm’ and ‘
fn’ is via template matching. Another method to detect shot boundary is the histogram-based technique. The most popular metric for abrupt change or cut detection is finding the difference between the histograms of two consecutive frames. 2-D correlation coefficient techniques for video shot segmentation [
9] uses statistical measurements with the assistance of motion vectors and Discrete Cosine Transform (DCT) coefficients from the MPEG stream. Afterwards, the heuristic models of abrupt or transitional scene changes can be confirmed through these measurements.
The twin-comparison algorithm [
10] has been proposed to detect sharp cuts and gradual shot changes, which results in shot boundary detection based on a dual threshold approach. Another method used for shot boundary detection is the two-pass block-based adaptive threshold technique [
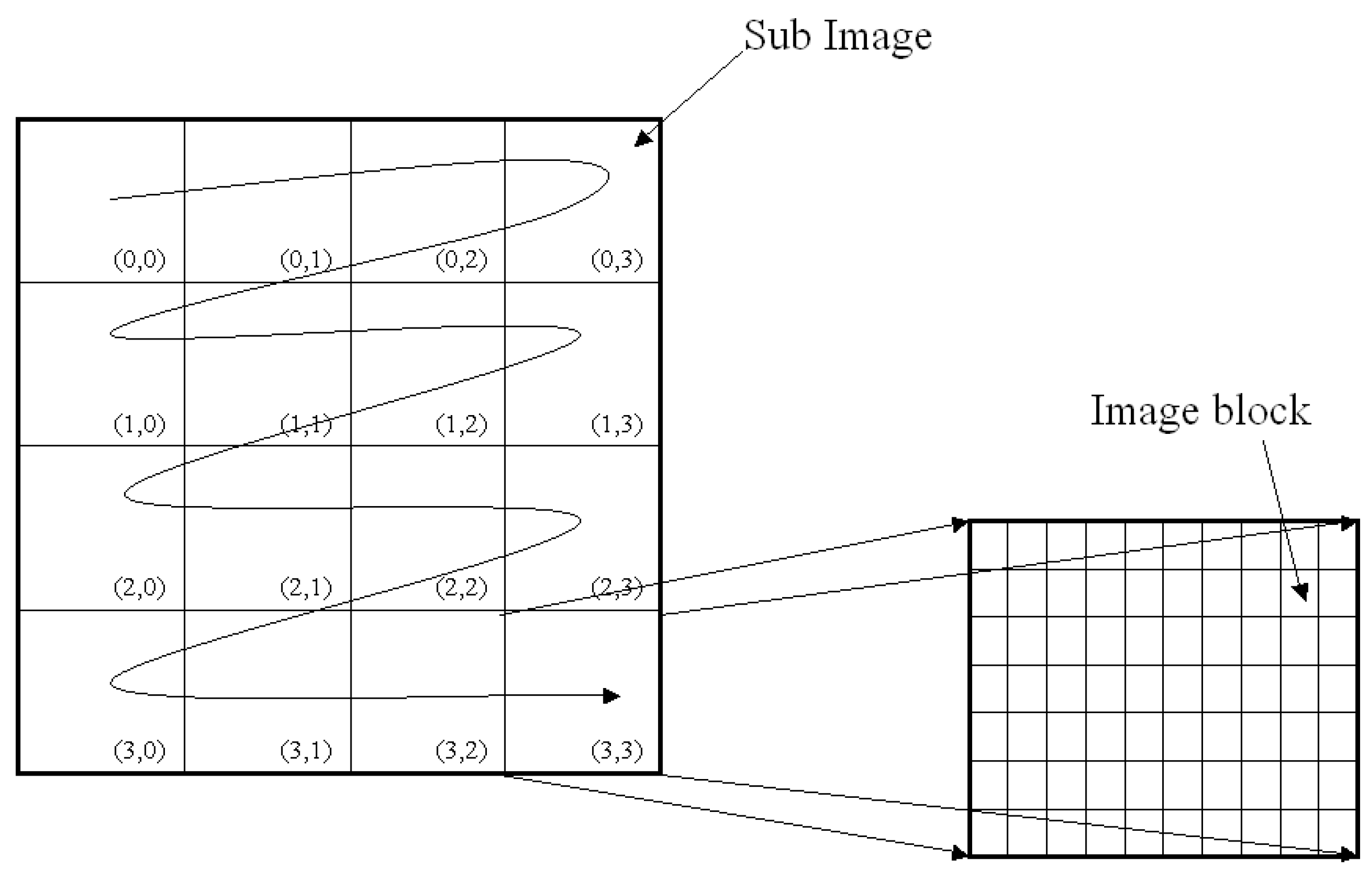
11]. Five important parts of the frame with different priorities were used here for shot boundary detection. The adaptive threshold method was used for efficient detection. In our work, we used two pass block-based adaptive threshold methods for shot boundary detection.
Keyframes are frames that best represent a shot. One of the most commonly used keyframe extraction methods is based on a temporal variation of low-level color features and motion information proposed by Lin et.al. [
12]. In this approach, frames in a shot are compared sequentially based on their histogram similarities. If a significant content change occurs, the current frame is selected as a keyframe. Such a process will be iterated until the last frame of the shot is reached. Another way of keyframe selection is through the clustering of video frames in a shot [
13]. This employs a partitioned clustering algorithm with cluster-validity analysis to select the optimal number of clusters for shots. The frame closest to the cluster centroid is chosen as the keyframe. The seek-spread strategy is also based on the idea of searching for representative keyframes sequentially [
14].
Feature extraction is the process of generating a set of descriptors or characteristic attributes from an image or video stream. Features taken into consideration can be broadly classified into frame level features and shot level features. Frame level features include color-based and texture-based features. Shot level features include the intersection histogram created from a group of frames. It also includes motion, defined as the temporal intensity change between successive frames, which is a unique character that distinguishes videos from other multimedia. By analyzing motion parameters, it is possible to distinguish between similar and different video shots or clips. In [
9], for video object retrieval, motion estimation was performed with the help of Fourier Transform and L2 norm distance. The total motion matrix (TMM) [
11] captures the total motion in terms of block-based measure by retaining the locality information of motion. It constructs 64-dimensional feature vector using the TMM, where each component represents the captured total spatial block motion of the entire frames in the video sequence. Motion features at pixel level is desirable to obtain motion information at a finer resolution. The pixel change ratio map (PCRM) [
15] is used to index video segments as the basis of motion content. PCRM indicates moving regions in particular video sequence.







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}