Making the Case for a P2P Personal Health Record



Abstract
1. Introduction
- -
- -
- -
- -
- -
- Maintain a complete health record;
- -
- Complement this record with data from other sources (e.g., home health devices or social media);
- -
- Share this data with the health provider of their choice;
- -
- Subscribe to the e-health services that match their health conditions.
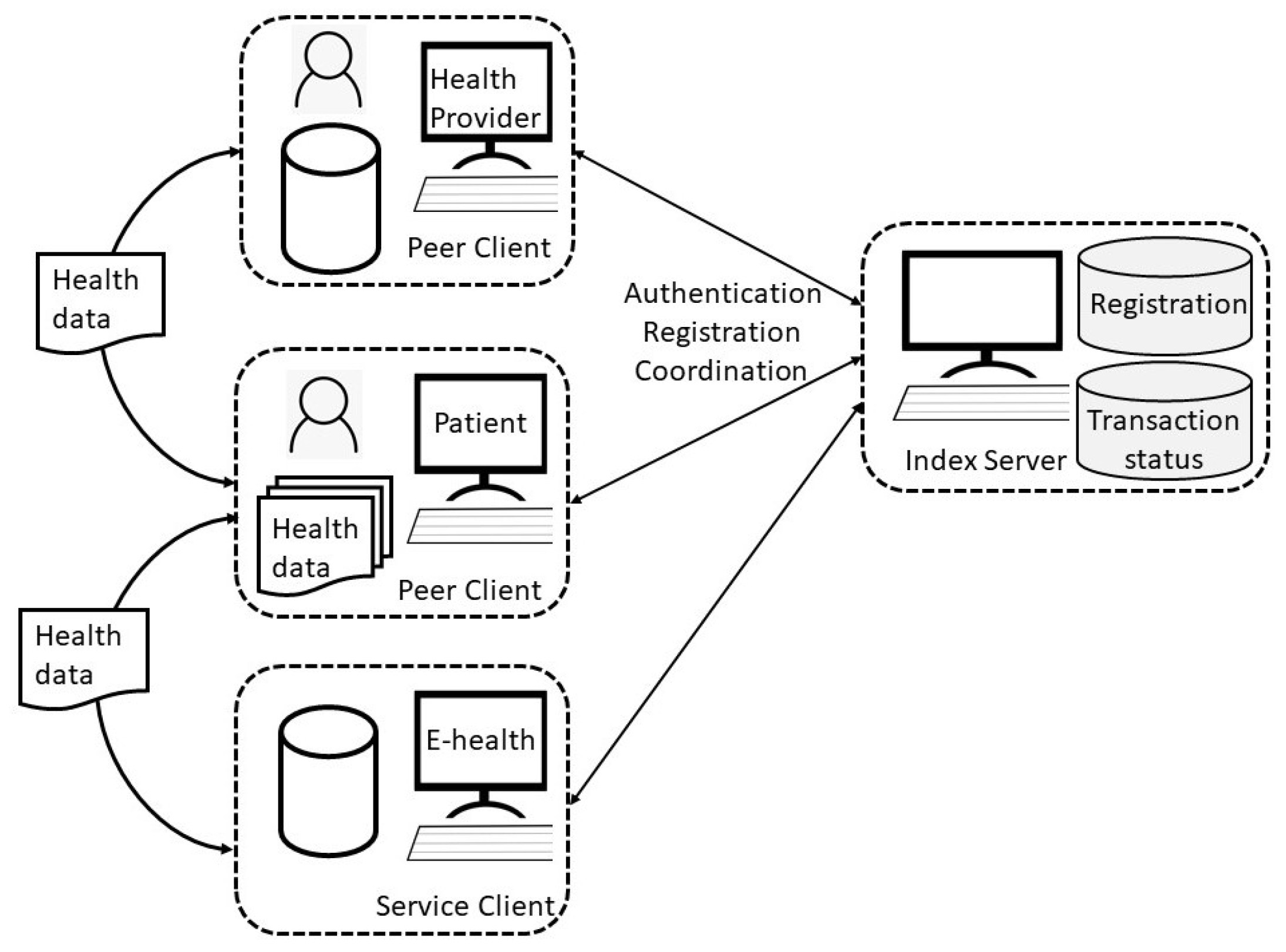
2. Background
3. Methods
- The ease of deployment of the architecture;
- Its ability to enforce privacy measures according to HIPAA or other health regulations through the index server;
- The fact that it represents a path of least resistance to change from the current institution-centric EHRs or HIEs.
3.1. Records
- -
- Individuals and their roles in the system (e.g., patient, provider, etc.);
- -
- Organizations, locations or devices;
- -
- Workflows (e.g., tasks or appointments);
- -
- Encounters between a patient and a health care provider;
- -
- Clinical information such as observations, conditions, and medications;
- -
- Financial information including billing.
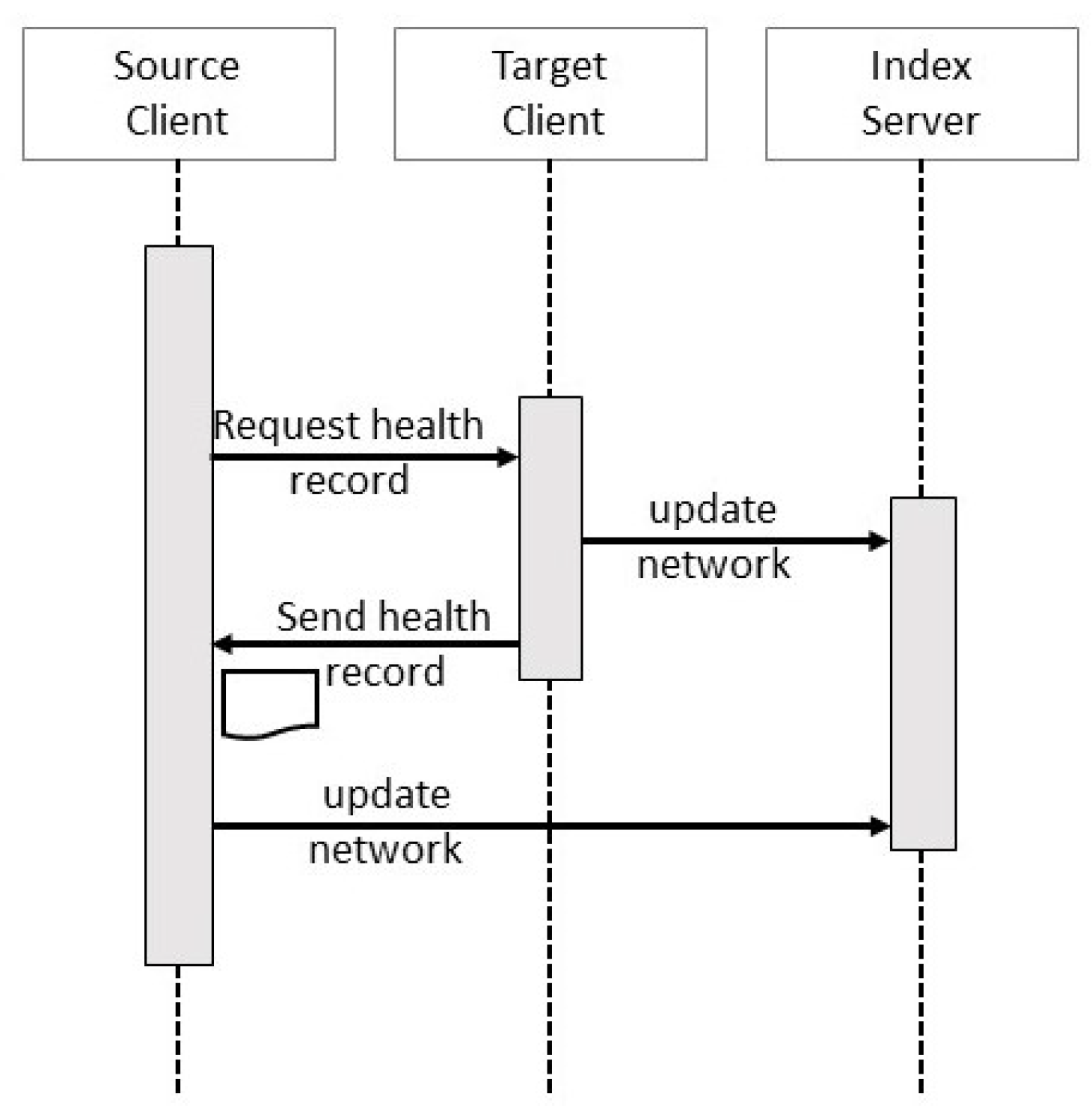
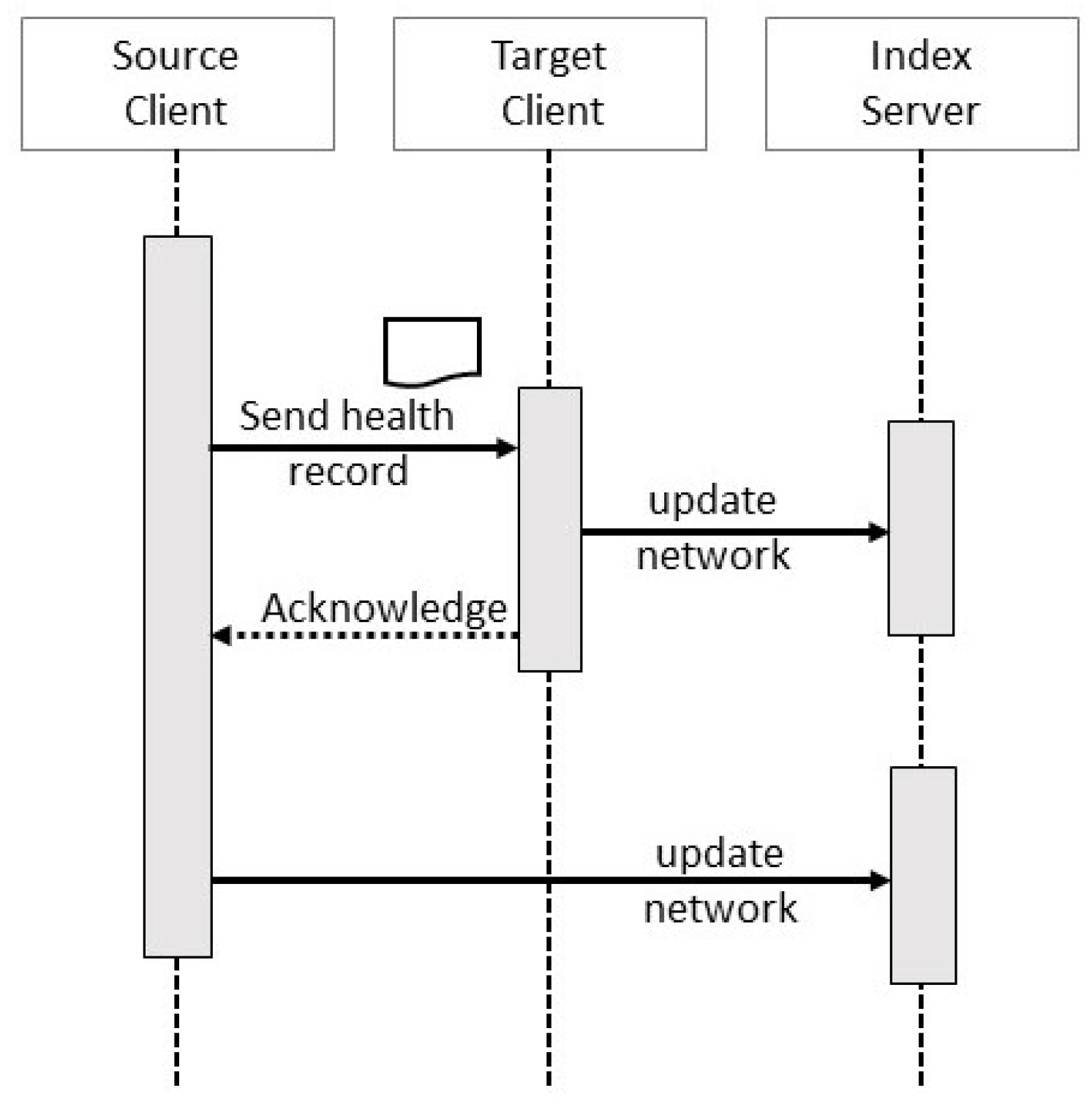
3.2. Transactions
3.3. Hypertension Predictor
3.3.1. Model Development
3.3.2. Model Deployment
4. Implementation and Results
4.1. Client Transactions
4.2. Service Transactions
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Ben-Assuli, O. Electronic health records, adoption, quality of care, legal and privacy issues and their implementation in emergency departments. Health Policy 2015, 119, 287–297. [Google Scholar] [CrossRef] [PubMed]
- The Office of the National Coordinator for Health Information Technology. Health IT Certification Program Overview, 2020. Available online: https://www.healthit.gov/sites/default/files/PUBLICHealthITCertificationProgramOverview.pdf (accessed on 26 October 2020).
- Health and Human Services Department. 2015 Edition Health Information Technology (Health IT) Certification Criteria, 2015 Edition Base Electronic Health Record (EHR) Definition, and ONC Health IT Certification Program Modifications; Federal Register; 2016. Available online: https://www.federalregister.gov/documents/2015/10/16/2015-25597/2015-edition-health-information-technology-health-it-certification-criteria-2015-edition-base (accessed on 26 October 2020).
- Epic Systems Corporation. Epic. Available online: https://www.epic.com/ (accessed on 26 October 2020).
- Cerner Corporation. Cerner. Available online: https://www.cerner.com/ (accessed on 26 October 2020).
- Medical Information Technology, Inc. Meditech. Available online: https://ehr.meditech.com/ (accessed on 26 October 2020).
- HL7 International. C-CDA (HL7 CDA R2 Implementation Guide: Consolidated CDA Templates for Clinical Notes—US Realm). 2019. Available online: http://www.hl7.org/implement/standards/product_brief.cfm?product_id=492/ (accessed on 26 October 2020).
- Health Level Seven International (HL7). Index—FHIR v4.0.1. 2019. Available online: https://www.hl7.org/fhir/ (accessed on 26 October 2020).
- Hersh, W.R.; Totten, A.M.; Eden, K.B.; Devine, B.; Gorman, P.; Kassakian, S.Z.; Woods, S.S.; Daeges, M.; Pappas, M.; McDonagh, M.S. Outcomes From Health Information Exchange: Systematic Review and Future Research Needs. JMIR Med. Inform. 2015, 3, e39. [Google Scholar] [CrossRef] [PubMed]
- Williams, C.; Mostashari, F.; Mertz, K.; Hogin, E.; Atwal, P. The Office Of The National Coordinator: The Strategy For Advancing The Exchange Of Health Information. Health Aff. 2012, 31, 527–536. [Google Scholar] [CrossRef] [PubMed]
- Johnson, C.; Pylypchuk, Y.; Patel, V. Methods Used to Enable Interoperability among U.S. Non-Federal Acute Care Hospitals in 2017; Office of the National Coordinator for Health Information Technology, 2018. Available online: https://www.healthit.gov/sites/default/files/page/2018-12/Methods-Used-to-Enable-Interoperability-among-U.S.-NonFederal-Acute-Care-Hospitals-in-2017_0.pdf (accessed on 26 October 2020).
- eHealth Exchange. Available online: https://ehealthexchange.org/ (accessed on 26 October 2020).
- European Commission. Exchange of Electronic Health Records across the EU. 2020. Available online: https://ec.europa.eu/digital-single-market/en/exchange-electronic-health-records-across-eu (accessed on 26 October 2020).
- Connecting Europe Facility. eHealth Digital Service Infrastructure. 2020. Available online: https://ec.europa.eu/cefdigital/wiki/display/EHOPERATIONS/eHDSI+Mission (accessed on 26 October 2020).
- Office of the National Coordinator for Health Information Technology. 2018 Report to Congress: Annual Update on the Adoption of a Nationwide System for the Electronic Use and Exchange of Health Information; 2018. Available online: https://www.healthit.gov/sites/default/files/page/2018-12/2018-HITECH-report-to-congress.pdf (accessed on 26 October 2020).
- Eric, H.; Shan, H.; Kevin, I.; Andy, K.; Katherine, L. A Framework for Cross-Organizational Patient Identity Managment. The Sequoia Project. 2015. Available online: https://sequoiaproject.org/wp-content/uploads/2015/11/The-Sequoia-Project-Framework-for-Patient-Identity-Management.pdf (accessed on 26 October 2020).
- Kruse, C.S.; Argueta, D.A.; Lopez, L.; Nair, A. Patient and Provider Attitudes Toward the Use of Patient Portals for the Management of Chronic Disease: A Systematic Review. J. Med. Internet Res. 2015, 17, e40. [Google Scholar] [CrossRef] [PubMed]
- Yocom, C.L. Health Information Technology: HHS Should Assess the Effectiveness of Its Efforts to Enhance Patient Access to and Use of Electronic Health Information; U.S. Goverment Accountabilty Office, 2017. Available online: https://www.gao.gov/assets/690/683388.pdf (accessed on 26 October 2020).
- Lye, C.T.; Forman, H.P.; Gao, R.; Daniel, J.G.; Hsiao, A.L.; Mann, M.K.; deBronkart, D.; Campos, H.O.; Krumholz, H.M. Assessment of US Hospital Compliance With Regulations for Patients’ Requests for Medical Records. JAMA Netw. Open 2018, 1, e183014. [Google Scholar] [CrossRef] [PubMed]
- Spil, T.; Klein, R. Personal health records success: Why Google Health failed and what does that mean for Microsoft HealthVault? In Proceedings of the 47th Hawaii International Conference on System Sciences, Waikoloa, HI, USA, 6–9 January 2014; pp. 2818–2827. [Google Scholar]
- Tang, P.C.; Ash, J.S.; Bates, D.W.; Overhage, J.M.; Sands, D.Z. Personal health records: Definitions, benefits, and strategies for overcoming barriers to adoption. J. Am. Med. Inform. Assoc. 2006, 13, 121–126. [Google Scholar] [CrossRef] [PubMed]
- Showell, C. Barriers to the use of personal health records by patients: A structured review. PeerJ 2017, 5, e3268. [Google Scholar] [CrossRef]
- Liu, L.S.; Shih, P.C.; Hayes, G.R. Barriers to the Adoption and Use of Personal Health Record Systems. In Proceedings of the iConference, Seattle, WA, USA, 8–11 February 2011; pp. 363–370. [Google Scholar] [CrossRef]
- NORC at the University of Chicago. Evaluation of the Personal Health Record Pilot for Medicare Fee-For Service Enrollees from South Carolina; Technical Report; U.S. Department of Health and Human Services: Bethesda, MD, USA, 2010.
- Schwartz, P.H.; Caine, K.; Alpert, S.A.; Meslin, E.M.; Carroll, A.E.; Tierney, W.M. Patient preferences in controlling access to their electronic health records: A prospective cohort study in primary care. J. Gen. Intern. Med. 2015, 30, S25–S30. [Google Scholar] [CrossRef]
- Tierney, W.M.; Alpert, S.A.; Byrket, A.; Caine, K.; Leventhal, J.C.; Meslin, E.M.; Schwartz, P.H. Provider responses to patients controlling access to their electronic health records: A prospective cohort study in primary care. J. Gen. Intern. Med. 2015, 30, S31–S37. [Google Scholar] [CrossRef][Green Version]
- Caine, K.; Tierney, W.M. Point and Counterpoint: Patient Control of Access to Data in Their Electronic Health Records. J. Gen. Intern. Med. 2015, 30, 38–41. [Google Scholar] [CrossRef]
- Park, Y.; Yoon, H.J. Understanding Personal Health Record and Facilitating its Market. Healthc. Inform. Res. 2020, 26, 248–250. [Google Scholar] [CrossRef] [PubMed]
- Sulieman, L.; Steitz, B.; Rosenbloom, S.T. Analysis of Employee Patient Portal Use and Electronic Health Record Access at an Academic Medical Center. Appl. Clin. Inform. 2020, 11, 433–441. [Google Scholar] [PubMed]
- Miled, Z.B.; Haas, K.; Black, C.M.; Khandker, R.K.; Chandrasekaran, V.; Lipton, R.; Boustani, M.A. Predicting dementia with routine care EMR data. Artif. Intell. Med. 2020, 102, 101771. [Google Scholar] [CrossRef] [PubMed]
- Ali, F.; El-Sappagh, S.; Islam, S.R.; Ali, A.; Attique, M.; Imran, M.; Kwak, K.S. An intelligent healthcare monitoring framework using wearable sensors and social networking data. Fut. Gen. Comp. Syst. 2020, 114, 23–43. [Google Scholar] [CrossRef]
- Ali, F.; El-Sappagh, S.; Islam, S.R.; Kwak, D.; Ali, A.; Imran, M.; Kwak, K.S. A smart healthcare monitoring system for heart disease prediction based on ensemble deep learning and feature fusion. Inf. Fus. 2020, 63, 208–222. [Google Scholar] [CrossRef]
- Mettler, T.; Eurich, M. A “design-pattern”-based approach for analyzing e-health business models. Health Policy Technol. 2012, 1, 77–85. [Google Scholar] [CrossRef]
- Kurose, J.F.; Ross, K.W. Computer Networking: A Top-Down Approach, 6th ed.; Pearson: Upper Saddle River, NJ, USA, 2012. [Google Scholar]
- Orlando, L.A.; Buchanan, A.H.; Hahn, S.E.; Christianson, C.A.; Powell, K.P.; Skinner, C.S.; Chesnut, B.; Blach, C.; Due, B.; Ginsburg, G.S.; et al. Development and validation of a primary care-based family health history and decision support program (MeTree). NC Med. J. 2013, 74, 287. [Google Scholar]
- Cohn, W.F.; Ropka, M.; Pelletier, S.; Barrett, J.; Kinzie, M.; Harrison, M.; Liu, Z.; Miesfeldt, S.; Tucker, A.; Worrall, B.; et al. Health Heritage©, a web-based tool for the collection and assessment of family health history: Initial user experience and analytic validity. Public Health Genom. 2010, 13, 477–491. [Google Scholar] [CrossRef]
- Omicini, A.; Denti, E. From tuple spaces to tuple centres. Sci. Comp. Programm. 2001, 41, 277–294. [Google Scholar] [CrossRef]
- Urovi, V.; Olivieri, A.C.; Bromuri, S.; Fornara, N.; Schumacher, M.I. A Peer to Peer Agent Coordination Framework for IHE Based Cross-community Health Record Exchange. In Proceedings of the 28th Annual ACM Symposium on Applied Computing, Coimbra, Portugal, 18–22 March 2013; pp. 1355–1362. [Google Scholar] [CrossRef]
- King, Z. P2HR, a Personalized Condition-Driven Person Health Record. Doctoral Thesis, Purdue University, West Lafayette, IN, USA, 2017. [Google Scholar]
- Kim, J.W.; Lee, A.R.; Kim, M.G.; Kim, I.K.; Lee, E.J. Patient-centric medication history recording system using blockchain. In Proceedings of the IEEE International Conference on Bioinformatics and Biomedicine (BIBM), San Diego, CA, USA, 18–21 November 2019; pp. 1513–1517. [Google Scholar]
- Hwang, K.; Dongarra, J.; Fox, G.C. Distributed and Cloud Computing: From Parallel Processing to the Internet of Things, 1st ed.; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2011. [Google Scholar]
- Mahy, P.; Matthews, J.R. Traversal Using Relays around NAT (TURN): Relay Extensions to Session Traversal Utilities for NAT (STURN); IETF, 2010; Available online: https://tools.ietf.org/html/rfc5766 (accessed on 26 October 2020).
- Gray, J. Notes on Data Base Operating Systems. In Operating Systems, an Advanced Course; Springer: London, UK, 1978; pp. 393–481. [Google Scholar]
- Lamport, L. The Part-time Parliament. Trans. Comput. Syst. 1998, 16, 133–169. [Google Scholar] [CrossRef]
- Castro, M.; Liskov, B. Practical Byzantine Fault Tolerance and Proactive Recovery. Trans. Comput. Syst. 2002, 20, 398–461. [Google Scholar] [CrossRef]
- Nakamoto, S. Bitcoin: A peer-to-peer electronic cash system. Technical Report, Manubot. 2019. Available online: https://git.dhimmel.com/bitcoin-whitepaper/ (accessed on 26 October 2020).
- Naik, A.R.; Keshavamurthy, B.N. Next level peer-to-peer overlay networks under high churns: A survey. Peer Peer Netw. Appl. 2020, 13, 905–931. [Google Scholar] [CrossRef]
- Mate, S.; Köpcke, F.; Toddenroth, D.; Martin, M.; Prokosch, H.U.; Bürkle, T.; Ganslandt, T. Ontology-based data integration between clinical and research systems. PLoS ONE 2015, 10, e0116656. [Google Scholar] [CrossRef] [PubMed]
- Garde, S.; Knaup, P.; Hovenga, E.J.; Heard, S. Towards semantic interoperability for electronic health records. Meth. Inf. Med. 2007, 46, 332–343. [Google Scholar]
- Spoladore, D. Ontology-based decision support systems for health data management to support collaboration in ambient assisted living and work reintegration. In Proceedings of the Working Conference on Virtual Enterprises, Vicenza, Italy, 18–20 September 2017; pp. 341–352. [Google Scholar]
- Spoladore, D.; Sacco, M. Semantic and dweller-based decision support system for the reconfiguration of domestic environments: RecAAL. Electronics 2018, 7, 179. [Google Scholar] [CrossRef]
- Riaño, D.; Real, F.; López-Vallverdú, J.A.; Campana, F.; Ercolani, S.; Mecocci, P.; Annicchiarico, R.; Caltagirone, C. An ontology-based personalization of health-care knowledge to support clinical decisions for chronically ill patients. J. Biomed. Inform. 2012, 45, 429–446. [Google Scholar]
- Health Level Seven International (HL7). HL7 FHIR Release 4. 2019. Available online: https://www.hl7.org/fhir/rdf.html#ontologies (accessed on 26 October 2020).
- World Health Organization. International Statistical Classification of Diseases and Related Health Problems 10th Revision. 2016. Available online: https://icd.who.int/browse10/2016/en (accessed on 26 October 2020).
- Haas, K.; Ben Miled, Z.; Mahoui, M. Medication Adherence Prediction Through Online Social Forums: A Case Study of Fibromyalgia. JMIR Med. Inform. 2019, 7, e12561. [Google Scholar] [CrossRef]
- Bender, D.; Sartipi, K. HL7 FHIR: An Agile and RESTful approach to healthcare information exchange. In Proceedings of the 26th IEEE International Symposium on Computer-Based Medical Systems, Porto, Portugal, 20–22 June 2013; pp. 326–331. [Google Scholar] [CrossRef]
- Center for Medicare & Medicaid Services. Blue Button 2.0; 2019. Available online: https://bluebutton.cms.gov/ (accessed on 26 October 2020).
- Mandel, J.C.; Kreda, D.A.; Mandl, K.D.; Kohane, I.S.; Ramoni, R.B. SMART on FHIR: A standards-based, interoperable apps platform for electronic health records. J. Am. Med. Inform. Assoc. 2016, 23, 899–908. [Google Scholar] [CrossRef]
- FIPS PUB 180-4: Secure Hash Standard (SHS). 2015. Available online: https://nvlpubs.nist.gov/nistpubs/FIPS/NIST.FIPS.180-4.pdf (accessed on 26 October 2020).
- Macedonia, M.R.; Zyda, M.J. A taxonomy for networked virtual environments. MultiMedia 1997, 4, 48–56. [Google Scholar] [CrossRef]
- Neumann, C.; Prigent, N.; Varvello, M.; Suh, K. Challenges in Peer-to-peer Gaming. Comput. Commun. Rev. 2007, 37, 79–82. [Google Scholar] [CrossRef]
- Russell, S.; Norvig, P. Artificial Intelligence: A Modern Approach, 3rd ed.; Pearson: Upper Saddle River, NJ, USA, 2010. [Google Scholar]
- Agency for Healthcare Research and Quality. Medical Expenditure Panel Survey; 2006. Available online: https://meps.ahrq.gov/mepsweb/ (accessed on 26 October 2020).
- Lucas, P. Bayesian Networks in Medicine: A Model-based Approach to Medical Decision Making. 2001. Available online: https://www.researchgate.net/profile/Peter_J_Lucas/publication/2386306_Bayesian_Networks_in_Medicine_a_Model-based_Approach_to_Medical_Decision_Making/links/00b49516dbf4c915ec000000.pdf (accessed on 26 October 2020).
- Bayes, T. LII. An essay towards solving a problem in the doctrine of chances. By the late Rev. Mr. Bayes, communicated by Mr. Price, in a letter to John Canton, MA and FRS. Philos. Trans. R. Soc. Lond. 1763, 53, 370–418. [Google Scholar]
- Agency for Healthcare Research and Quality. MEPS HC-181 2015 Medical Conditions; 2017. Available online: https://meps.ahrq.gov/data_stats/download_data/pufs/h181/h181doc.pdf (accessed on 26 October 2020).
- Google.com. Go. 2019. Available online: https://golang.org/ (accessed on 26 October 2020).
- MongoDB Inc. MongoDB Database. 2019. Available online: https://www.mongodb.com (accessed on 26 October 2020).
- Niemeyer, G. The MongoDB Driver for Go. 2019. Available online: https://github.com/globalsign/mgo (accessed on 26 October 2020).
- Mitre. Generic FHIR Server Implementation in GoLang. 2018. Available online: https://github.com/intervention-engine/fhir (accessed on 26 October 2020).
- Fielding, R.T. Architectural Styles and the Design of Network-based Software Architectures. Doctoral Thesis, University of California, Irvine, CA, USA, 2000. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ICD-9-CM Group | Meps Code | Feature |
|---|---|---|
| 410-414: Heart Disease | 410 | Acute Myocardial Infraction |
| 413 | Angina Pectoris | |
| 414 | Other forms of Ischemic Heart Disease | |
| 415-417: Heart Failure | 415 | Acute Pulmonary Heart Disease |
| 420-429: Circulatory System Diseases | 424 | Other Diseases of Endocardium |
| 425 | Cardiomyopathy | |
| 427 | Cardiac Dysrhythmis | |
| 428 | Heart Failure | |
| 429 | Ill-defined Descriptions and Complications of Heart Disease | |
| 430-438: Cardio Brain Hemorrhage, Stroke | 436 | Acute, but ill-defined, Cerebrovascular Disease |
| 440-449: Restricted Blood Flow | 440 | Atherosclerosis |
| 441 | Aortic Aneurysm and Dissection | |
| 442 | Other Aneurysm | |
| 443 | Other Peripheral Vascular Disease | |
| 444 | Arterial Embolism and Thrombosis | |
| 447 | Other Disorders of Arteries and Arterioles | |
| 451-459: Issues with Veins and Lymph System | 454 | Varicose Veins of Lower Extremities |
| 455 | Hemorrhoids | |
| 458 | Hypotension | |
| 459 | Other Disorders of Circulatory System | |
| 490-496: Chronic Respiratory Issues | 490 | Bronchitis, not specified as Acute or Chronic |
| 491 | Chronic Bronchitis | |
| 492 | Emphysema | |
| 493 | Asthma | |
| 496 | Chronic Airway Obstruction, not elsewhere classified | |
| 510-519: Secondary Respiratory Conditions | 511 | Pleurisy |
| 514 | Pulmonary Congestion and Hypostasis | |
| 518 | Other Diseases of Lung | |
| 519 | Other Diseases of Respiratory System |
| MEPS Feature | Description |
|---|---|
| SEX | Sex |
| RACE1VX | Race |
| AGELAST | Person’s age last time eligible |
| HIBPDX | High Blood pressure diagnosis |
| CHHDX | Coronary Heart Disease diagnosis |
| ANGIDX | Angina diagnosis |
| MIDX | Heart Attack (MI) Diagnosis |
| OHRTDX | Other Heart Disease Diagnosis |
| STRKDX | Stroke Diagnosis |
| EMPHDX | Emphysema Diagnosis |
| CHOLDX | High Cholesterol Diagnosis |
| DIABDX | Diabetes Diagnosis |
| ADSMOKE42 | SAQ: Currently Smoke |
| NOFAT53 | Restrict High Fat/Cholesterol |
| EXRCIS53 | Advised to exercise more |
| BMINDX53 | Adult Body Mass Index |
| POVCAT | Family Income as Percentage of Poverty Line |
| Performance Metric | Percentage (%) |
|---|---|
| Accuracy | 75.2 |
| Precision | 58.9 |
| Sensitivity | 66.3 |
| Specificity | 79.1 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Horne, W.C.; Ben Miled, Z. Making the Case for a P2P Personal Health Record. Information 2020, 11, 512. https://doi.org/10.3390/info11110512
Horne WC, Ben Miled Z. Making the Case for a P2P Personal Health Record. Information. 2020; 11(11):512. https://doi.org/10.3390/info11110512
Chicago/Turabian StyleHorne, William Connor, and Zina Ben Miled. 2020. "Making the Case for a P2P Personal Health Record" Information 11, no. 11: 512. https://doi.org/10.3390/info11110512
APA StyleHorne, W. C., & Ben Miled, Z. (2020). Making the Case for a P2P Personal Health Record. Information, 11(11), 512. https://doi.org/10.3390/info11110512