Unsupervised Anomaly Detection for Network Data Streams in Industrial Control Systems


Abstract
:1. Introduction
- It proposes an incremental anomaly detection method based on tree ensembles for data streams. This unsupervised approach introduces a tree growth procedure which can constantly incorporate new data information into the existing model.
- It introduces a tree mass weighting mechanism to ensure that the ensemble detection results could keep relatively stable before and after discarding some trees, avoiding that the positive feedback caused by deleting the tree affects the effectiveness of the method.
- The proposed method has a low time complexity and can efficiently detect anomalies of the data stream.
- Our method does not need to store all data, and it is particularly suitable for detecting outliers in an industrial control network, which has massive amounts of data.
2. Related Work
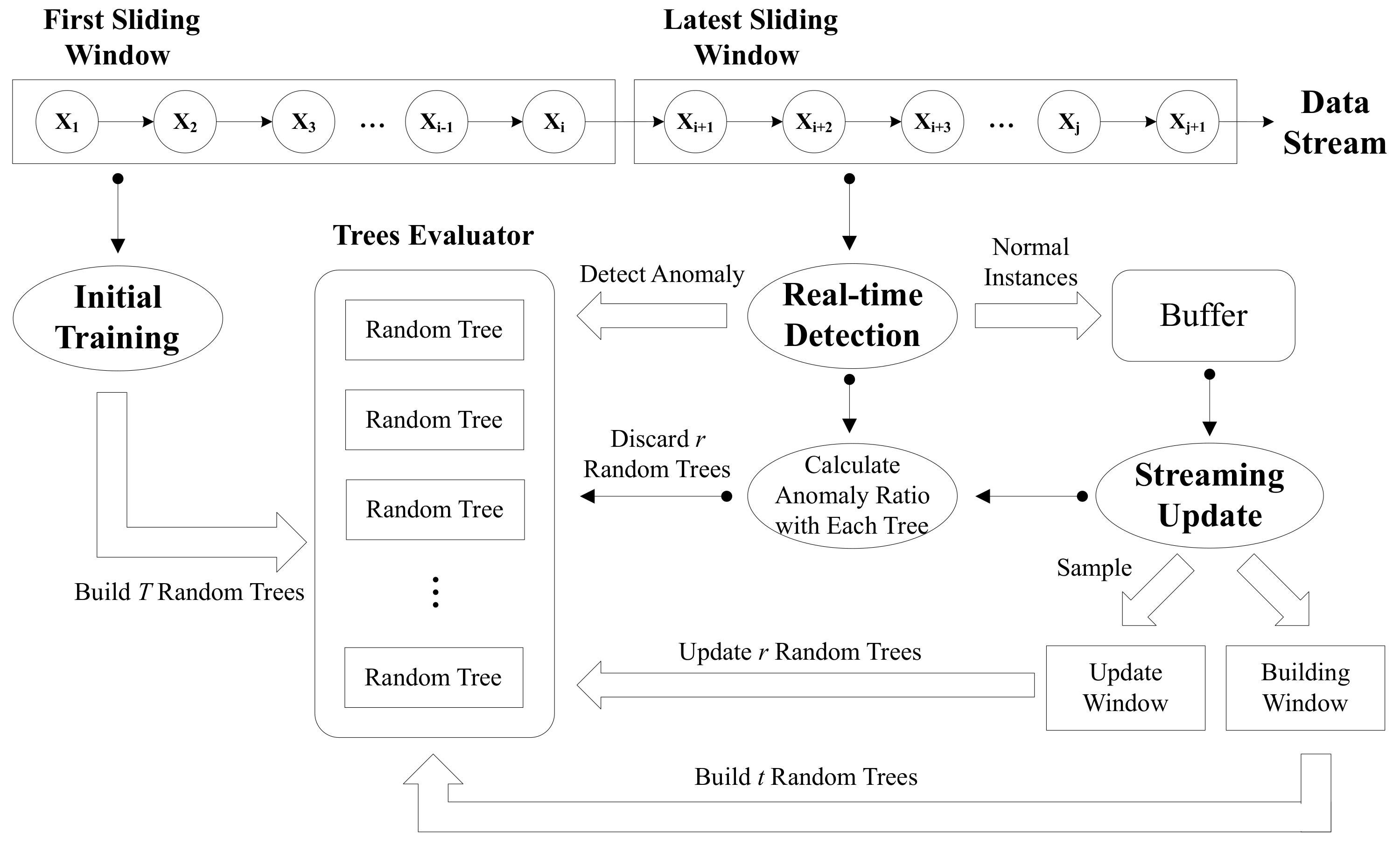
3. Unsupervised Anomaly Detection for a Network Data Stream
3.1. Initial Training
| Algorithm 1 |
|
3.2. Real-Time Detection
3.3. Streaming Update
3.3.1. Update Trigger
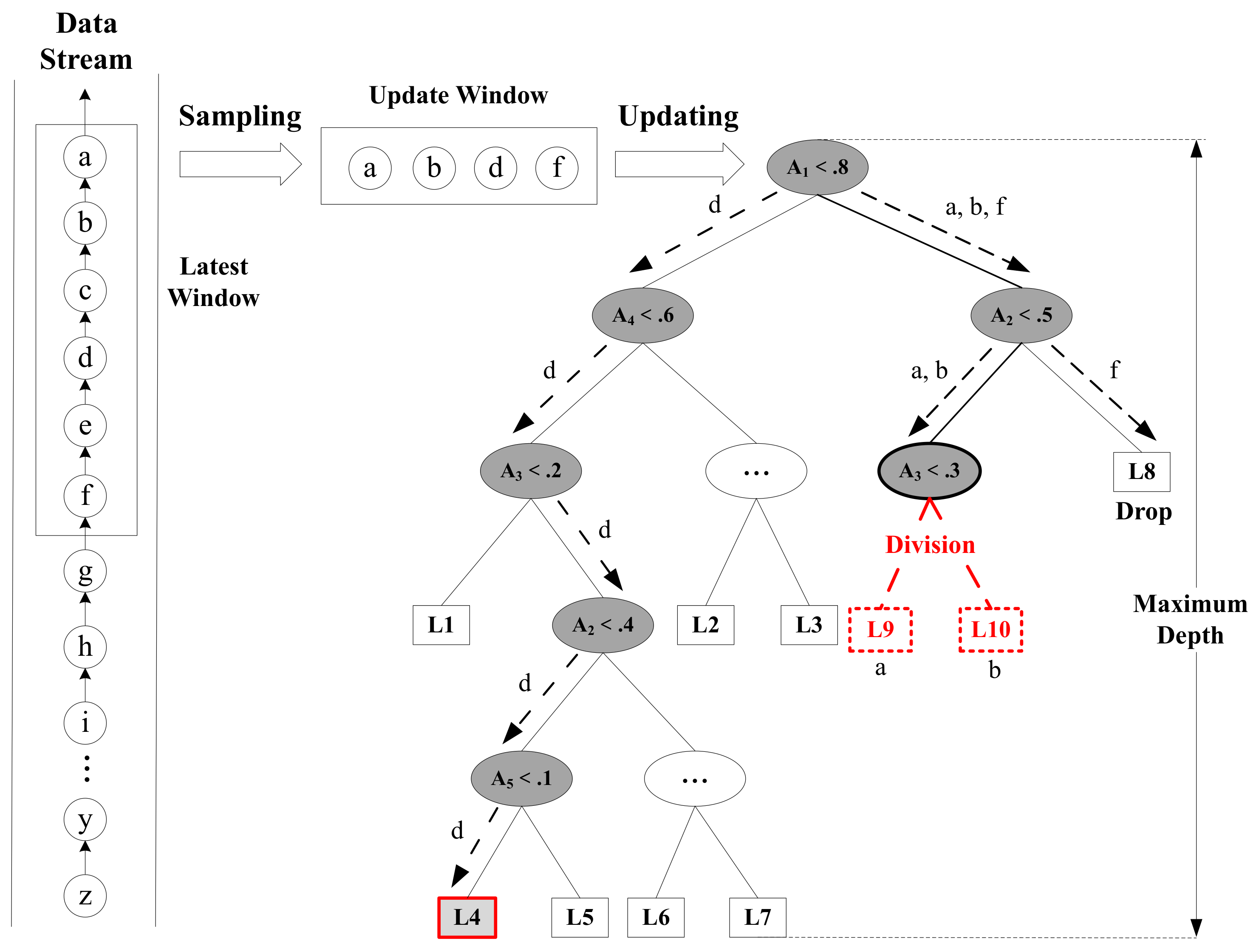
3.3.2. Online Growth of Trees
| Algorithm 2 Online Growth of Trees |
|
3.3.3. Mass Weighting
| Algorithm 3 Mass Weighting |
|
4. Experimental Evaluation
4.1. Evaluation Criteria
4.2. The SWaT Dataset
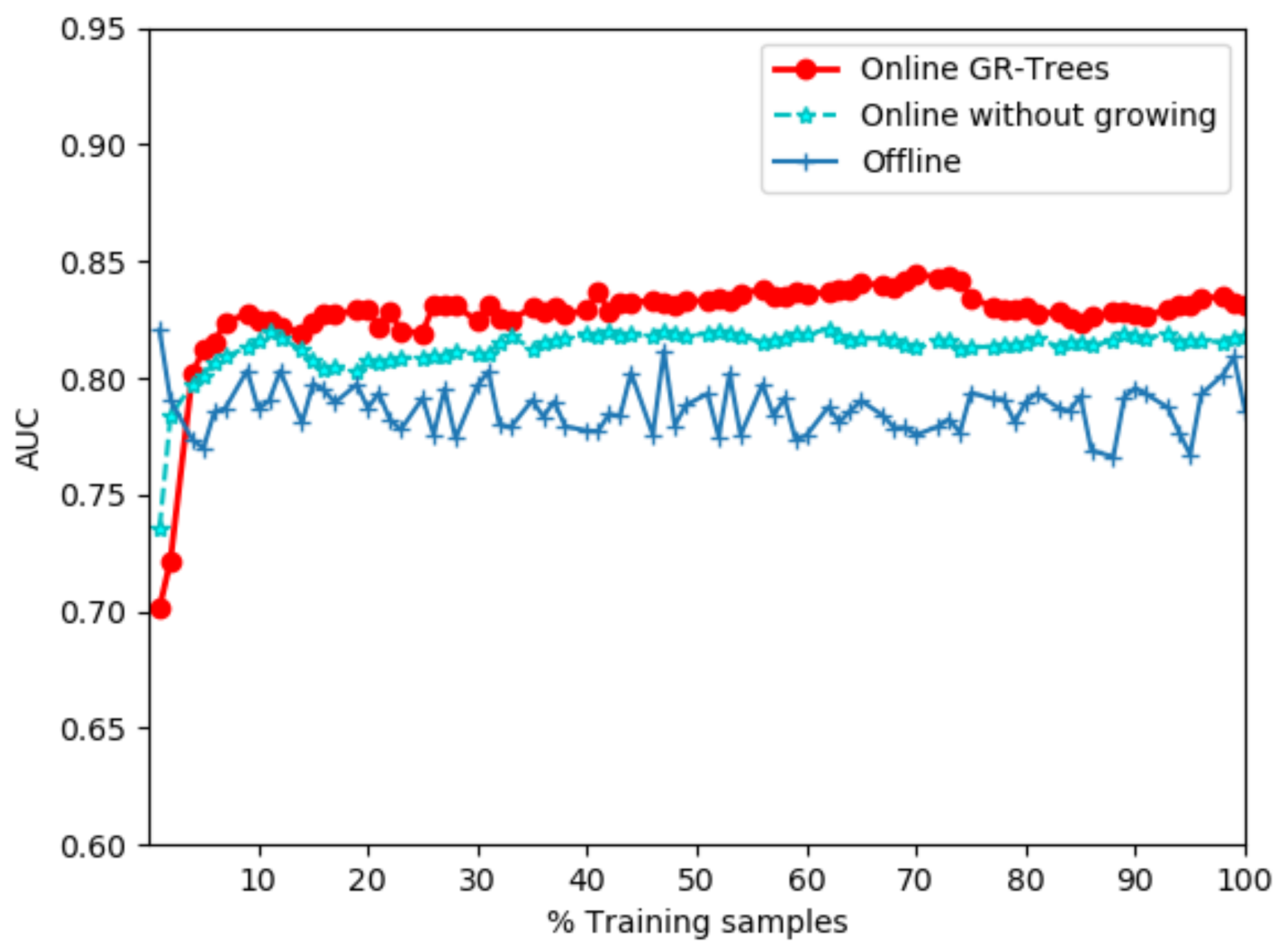
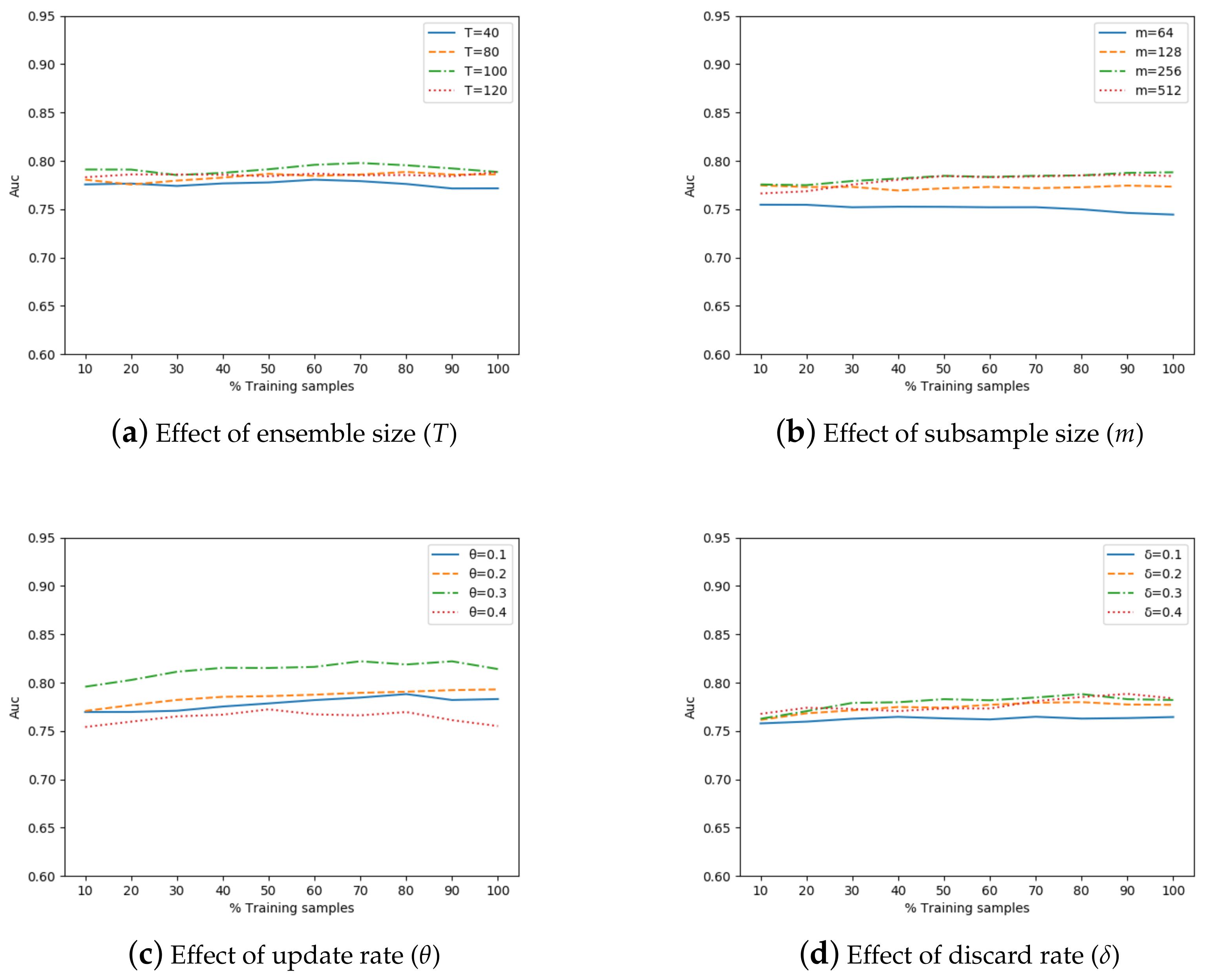
4.3. Results and Analysis
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Lee, J.; Bagheri, B.; Kao, H.A. Recent advances and trends of cyber-physical systems and big data analytics in industrial informatics. In Proceedings of the IEEE 12th International Conference on Industrial Informatics (INDIN), Porto Alegre, Brazil, 27–30 July 2014; pp. 1–6. [Google Scholar]
- Babcock, B.; Babu, S.; Datar, M.; Motwani, R.; Widom, J. Models and Issues in Data Stream Systems. In Proceedings of the Twenty-first ACM SIGMOD-SIGACT-SIGART Symposium on Principles of Database Systems, Madison, WI, USA, 3–5 June 2002; pp. 1–16. [Google Scholar] [CrossRef] [Green Version]
- Zhao, J.; Yang, G.; Mu, L.; Fan, T.; Yang, N.; Wang, S. Research on the application of the data stream technology in grid automation. Power Syst. Technol. 2011, 35, 6–11. [Google Scholar]
- Lim, L.; Misra, A.; Mo, T. Adaptive data acquisition strategies for energy-efficient, smartphone-based, continuous processing of sensor streams. Distrib. Parallel Databases 2012, 31, 1–31. [Google Scholar] [CrossRef] [Green Version]
- Jardine, W.; Frey, S.; Green, B.; Rashid, A. SENAMI: Selective non-invasive active monitoring for ICS intrusion detection. In Proceedings of the 2nd ACM Workshop on Cyber-Physical Systems Security and Privacy, Xi’an, China, 30 May 2016; pp. 23–34. [Google Scholar]
- Aggarwal, E.; Karimibiuki, M.; Pattabiraman, K.; Ivanov, A. CORGIDS: A correlation-based generic intrusion detection system. In Proceedings of the 2018 Workshop on Cyber-Physical Systems Security and PrivaCy, Beijing, China, 26 February 2018; pp. 24–35. [Google Scholar]
- Alzghoul, A.; Löfstrand, M. Increasing availability of industrial systems through data stream mining. Comput. Ind. Eng. 2011, 60, 195–205. [Google Scholar] [CrossRef]
- Muallem, A.; Shetty, S.; Pan, J.W.; Zhao, J.; Biswal, B. Hoeffding tree algorithms for anomaly detection in streaming datasets: A survey. J. Inf. Secur. 2017, 8, 339–361. [Google Scholar] [CrossRef] [Green Version]
- Saffari, A.; Leistner, C.; Santner, J.; Godec, M.; Bischof, H. On-line random forests. In Proceedings of the IEEE 12th International Conference on Computer Vision Workshops, ICCV Workshops, Kyoto, Japan, Kyoto, Japan, 27 September–4 October 2009; pp. 1393–1400. [Google Scholar]
- Tan, S.C.; Kai, M.T.; Fei, T.L. Fast Anomaly Detection for Streaming Data. In Proceedings of the 22nd International Joint Conference on Artificial Intelligence, Barcelona, Spain, 16–22 July 2011. [Google Scholar]
- Galar, M.; Fernandez, A.; Barrenechea, E.; Bustince, H.; Herrera, F. A review on ensembles for the class imbalance problem: Bagging-, boosting-, and hybrid-based approaches. IEEE Trans. Syst. 2011, 42, 463–484. [Google Scholar] [CrossRef]
- Barbosa, R.R.R.; Sadre, R.; Pras, A. Towards periodicity based anomaly detection in SCADA networks. In Proceedings of the 2012 IEEE 17th International Conference on Emerging Technologies & Factory Automation (ETFA 2012), Krakow, Poland, 17–21 September 2012; pp. 1–4. [Google Scholar]
- Ponomarev, S.; Atkison, T. Industrial control system network intrusion detection by telemetry analysis. IEEE Trans. Dependable Secur. Comput. 2015, 13, 252–260. [Google Scholar] [CrossRef]
- Kiss, I.; Genge, B.; Haller, P.; Sebestyén, G. Data clustering-based anomaly detection in industrial control systems. In Proceedings of the 2014 IEEE 10th International Conference on Intelligent Computer Communication and Processing (ICCP), Cluj-Napoca, Romania, 4–6 September 2014; pp. 275–281. [Google Scholar]
- WANG, D.; YANG, L. Stream Processing Method and Condition Monitoring Anomaly Detection for Big Data in Smart Grid. Autom. Electr. Power Syst. 2016, 2016, 18. [Google Scholar]
- Lin, L.; Su, J. Anomaly detection method for sensor network data streams based on sliding window sampling and optimized clustering. Saf. Sci. 2019, 118, 70–75. [Google Scholar] [CrossRef]
- Yang, Y.H.; Huang, H.Z.; Shen, Q.N.; Wu, Z.H.; Zhang, Y. Research on intrusion detection based on incremental GHSOM. Chin. J. comput. 2014, 37, 1216–1224. [Google Scholar]
- Golab, L.; Özsu, M.T. Issues in data stream management. ACM Sigmod Rec. 2003, 32, 5–14. [Google Scholar] [CrossRef]
- Knuth, D.E. Sorting and Searching, Art of Computer Programming, 2nd ed.; Addison Wesley Longman Publishing Co.: Redwood, CA, USA, 1988. [Google Scholar]
- Liu, F.T.; Kai, M.T.; Zhou, Z.H. Isolation Forest. In Proceedings of the 2008 Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; IEEE: Washington, DC, USA, 2008; pp. 995–1000. [Google Scholar]
- LI, X.; Gao, X.; Yan, B.; Chen, C.; Chen, B.; Li, J.; Xu, J. An Approach of Data Anomaly Detection in Power Dispatching Streaming Data Based on Isolation Forest Algorithm. Power Syst. Technol. 2019, 43, 1447. [Google Scholar] [CrossRef]
- Goh, J.; Adepu, S.; Junejo, K.N.; Mathur, A. A Dataset to Support Research in the Design of Secure Water Treatment Systems. In Proceedings of the 11th International Conference on Critical Information Infrastructures Security, Paris, France, 10–12 October 2016. [Google Scholar]
- Schneider, P.; Böttinger, K. High-Performance Unsupervised Anomaly Detection for Cyber-Physical System Networks. In Proceedings of the 2018 Workshop on Cyber-Physical Systems Security and PrivaCy, Toronto, ON, Canada, 19 October 2018. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Points | Dimension | Anomaly | AUC | ||
|---|---|---|---|---|---|---|
| GR-Trees | IF | HS-Trees | ||||
| Http | 567,497 | 3 | 0.4% | 0.9502 | 0.5318 | 0.9203 |
| Smtp | 95,156 | 3 | 0.03% | 0.8313 | 0.8255 | 0.8259 |
| ForestCover | 286,048 | 10 | 0.9% | 0.5814 | 0.5293 | 0.6046 |
| Shuttle | 49,097 | 9 | 7% | 0.8923 | 0.9395 | 0.8726 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, L.; Hu, M.; Kang, C.; Li, X. Unsupervised Anomaly Detection for Network Data Streams in Industrial Control Systems. Information 2020, 11, 105. https://doi.org/10.3390/info11020105
Liu L, Hu M, Kang C, Li X. Unsupervised Anomaly Detection for Network Data Streams in Industrial Control Systems. Information. 2020; 11(2):105. https://doi.org/10.3390/info11020105
Chicago/Turabian StyleLiu, Limengwei, Modi Hu, Chaoqun Kang, and Xiaoyong Li. 2020. "Unsupervised Anomaly Detection for Network Data Streams in Industrial Control Systems" Information 11, no. 2: 105. https://doi.org/10.3390/info11020105
APA StyleLiu, L., Hu, M., Kang, C., & Li, X. (2020). Unsupervised Anomaly Detection for Network Data Streams in Industrial Control Systems. Information, 11(2), 105. https://doi.org/10.3390/info11020105