Analysis and Identification of Possible Automation Approaches for Embedded Systems Design Flows


Abstract
:1. Introduction
2. Background
2.1. Models of Computation (MoC)
2.1.1. Synchronous (SY) MoC
2.1.2. Synchronous Dataflow (SDF) MoC
2.1.3. Scenario-Aware Dataflow (SADF) MoC
2.2. Frameworks Supporting Formal MoCs
2.2.1. Formal System Design (ForSyDe)
2.2.2. Ptolemy II
2.3. MoCs Perspective under Ptolemy II and ForSyDe
2.3.1. ForSyDe Overview
2.3.2. Ptolemy II Overview
2.4. Functional Programming Paradigm
2.5. Imperative Programming Paradigm
2.6. Related Works
3. Analysis and Identification of Possible Automation Approaches (AIPAA)
3.1. Problem Characterization Step
- Q1 -
- Does the problem have concurrent, or only sequential, processes?
- Q2 -
- Are the problem communication paths totally or partially ordered?
- Q3 -
- Is the problem a dataflow problem?
- Q4 -
- Are the inputs and processing cyclic?
- Q5 -
- Can a single clock be used to synchronize all the involved processes?
3.2. MoC Definition Step
3.3. Framework Selection Step
- License style: The framework license style must comply with the project requirements. It can vary from open source or freeware to a proprietary and paid license style;
- Included MoCs: The set of available MoCs can drastically differ when comparing frameworks. For example, SDF3 only supports SDF, SADF and CSDF, on the other hand, Simulink, ForSyDe or Ptolemy II supports a range of MoCs. The selected MoC, in Section 3.2, must be part in the framework supported MoC list;
- Capabilities: The frameworks varies on its capabilities, including system simulation and heterogeneous system modeling. In this sense, model simulation figures as an interesting feature for a framework to have;
- Interfaces: Frameworks differ on its modeling and simulation interfaces. It ranges from a script environment to a GUI. The simulation input and output interfaces varies from files, predefined or user inputted and must also be considered;
- Scalability: Towards scalable models, some frameworks are implemented based on programming languages and have interfaces that facilitates the modeling of large or distributed systems;
- Programming language paradigm: Frameworks are based on a wide range of programming languages, leading to a variation on its programming paradigm, for example, imperative or functional. Each paradigm has its own benefits. Functional can lead to a better model scalability and higher abstraction level, on the other hand, imperative paradigm facilitates new MoCs modeling due to inheritance capability.
3.4. Modeling and Simulation Step
3.5. Properties Verification Step
- For the SY MoC:
- PSY1
- signals synchronized and totally ordered;
- PSY2
- well-defined absent value for an event; and
- PSY3
- absence of zero-delay feedback, that is, for each loop-back, a delay must be implemented, avoiding algebraic loop. In SY MoC, there are some options to handle loop-backs [31]. The AIPAA method adopts the strategy of forbidden zero-delay loop-backs.
- For the SDF MoC:
- PSDF1
- buffer size determination based on a feasible schedule, that is, the buffers must be in accordance with token rates, so that there is nor data loss neither overflows;
- PSDF2
- system is non-terminating, that is, it cannot have deadlocks;
- PSDF3
- schedulability, that is, it must be possible to extract a valid single-core schedule as a finite sequence of actor firings; and
- PSDF4
- fixed model token rates. As SDF blocks have fixed token rates, the model also will not vary its rates.
- For the SADF MoC [13]:
- PSADF1
- Boundedness: this property is similar to the . The system model production and consumption token rates must be designed in a manner that the number of buffered tokens are bounded;
- PSADF2
- Absence of deadlocks: As SDF, the SADF must be also non-terminating, that is, it must not have deadlocks; and
- PSADF3
- Determinacy: the model performance depends on probabilistic choices that determine the sequence of scenarios selected by each detector. As discussed by Reference [14], in the performance SADF model a detector’s behavior is represented by a Markov chain. On the other hand, in the functional SADF model, representing the detector’s behavior as a Markov chain would violate the tagged signal model definition’s of functional process, since a Markov chain describes more than one behavior, that is, it is non-deterministic. In view of this, the functional model is used in the present work, where the detector’s behavior is dictated by a deterministic finite-state machine.
- For the SY MoC:
- VSY1
- Signals are synchronized and totally ordered.This property is MoC intrinsic for SY. As long as the system is modeled following the SY MoC abstraction, this property holds. It is important that the input signals are correctly ordered considering this property, not having unexpected model behaviors. This verification is carried out by explicit model analysis;
- VSY2
- Well-defined absent value for an event.This property is also MoC intrinsic for SY. The framework must handle the absent value for an event towards the maintenance of the perfect synchrony hypothesis; This verification is through explicit model analysis;
- VSY3
- For each loop-back, a delay must be implemented.The verification of this property must be through the model implementation code or interface analysis. First, it is necessary to check whether the model has any loop-back, and in positive case, check the existence of the at least one cycle delay in it. This verification is possible to be automated by using a regular expression checker.
- For the SDF MoC:
- VSDF1
- Buffer size determination based on feasible schedule.The verification of this property can be mathematically demonstrated, as presented by Reference [12]:
- (a)
- Find the model topology matrix ; and
- (b)
- Check if .
- VSDF2
- System is non-terminating.The absence of deadlocks is mathematically proven, as demonstrated by Reference [12]. To verify this property it is necessary to prove the existence of a periodic admissible sequential schedule (PASS), which can be done by performing the following:
- (a)
- Check whether the model holds . If not, the system has no PASS;
- (b)
- Find a positive integer vector q belonging to the null space ;
- (c)
- Create a list L containing all model blocks;
- (d)
- For each block , schedule a feasible one, just once;
- (e)
- If each node has been scheduled times, go to next feasible ; and
- (f)
- If no block in L can be scheduled, the system has a deadlock.
- VSDF3
- Schedulability analysis;For a model to be schedulable, property must hold. Moreover, the model graph must be connected [12]. This must be verified through model analysis.
- VSDF4
- Fixed model token rate.The fixed token rate property is verified by submitting the model to test cases. Different input values and signal sizes must be used to verify the model robustness.
- For the SADF MoC [13]:
- VSADF1
- The boundedness verification considers three aspects:
- (a)
- Boundedness in fixed scenarios case: In case all processes only operate in a fixed scenario, the system behaves as a SDF based model;
- (b)
- The boundedness of control channels: For each kernel k, controlled by a detector d, the inequality must hold for every scenario s in which k is inactive, where represents the duration of d to detect and send the scenario s to kernel k; represents how many cycles the k computation are executed in the scenario s; and is the duration of each k computation cycle; and
- (c)
- The effect of the scenario changes on boundedness: The number of tokens in channels between active processes after an iteration of the SADF model is the same as before. In this context, an iteration is the firing of each process p configured in a scenario s for times.
- VSADF2
- For all kernels’ scenarios combinations, there must have sufficient initial tokens in each cyclic dependency between processes such that every included process can fire a number of times equal to its repetition vector entry. Feedback loops can be considered as a cyclic dependency of a single process; and
- VSADF3
- The functionality non-determinism only occurs between multiple independent concurrent processes. If existing in a model, it leads to satisfying the diamond property. This property states that when two or more independent processes are concurrently enabled, the system functionality is not affected by the order that they are performed. This statement proof is fully described in Reference [13].
3.6. Directions to Implementation Details and System Implementation
- Division of the functionalities implemented in hardware and the ones in software, that is, hardware and software co-design;
- Communication interfaces, methods and protocols;
- Hardware architecture comprehending:
- (a)
- Necessary resources for example, memories, processors, power; and
- (b)
- Necessary units, such as arithmetic logic unit (ALU), floating point unit (FPU), graphics processing unit (GPU), or reconfigurable hardware (FPGA).
- Software architecture comprehending:
- (a)
- Implementation programming language; and
- (b)
- Programming frameworks and tool-chains to be used.
3.7. Analysis of Possible Automation Approaches
3.7.1. Proposed Automation to Properties Verification
- Req1
- The output signal length divided by its corresponding token rate must be equal to the number of model firing cycles, which is calculated by selecting the smaller division result among the input signal length and its token rates; and
- Req2
- The output signal length should be multiple of its corresponding token rate.
- propFixTr21: Fixed token rate property to be verified;
- c1 and c2: Input signals token rates;
- p: Output signal token rate;
- a1 and a2: Quickcheck automatic generated model test cases; and
- actor: The model to be tested.
| Listing 1: Quickcheck usage code example in Haskell/ForSyDe. |
 |
| Listing 2: SDF-based system model example code in Hakell/ForSyDe. |
 |
3.7.2. Automatic Code Generation
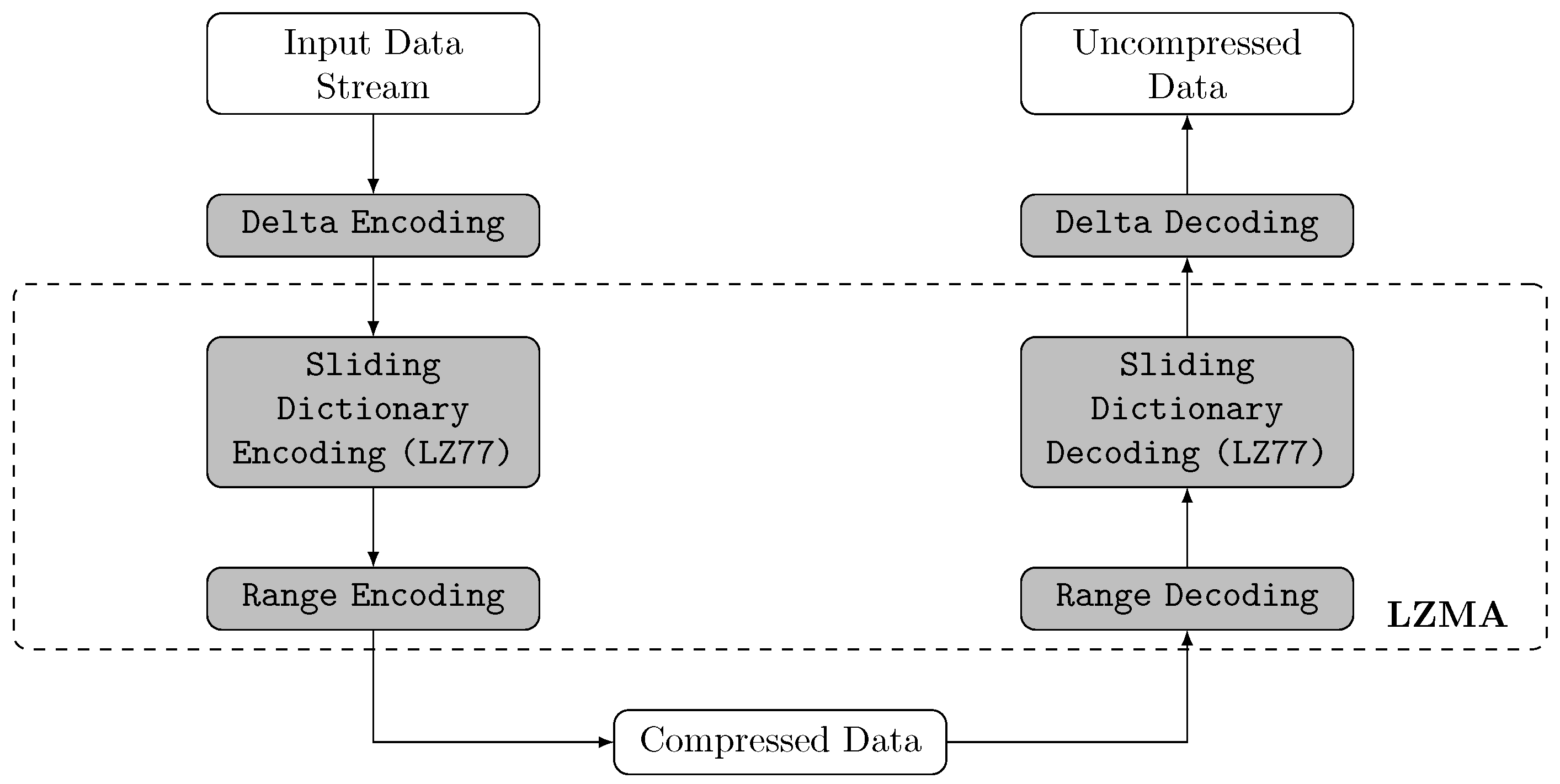
4. Case Study—Lempel-Ziv-Markov Chain Algorithm
4.1. Problem Characterization Step
4.1.1. Sliding Window Encoding (SWE)
- a distance representing the distance between the current byte and its match in the search window. It is equal to 0 if no match was found and it will be flushed in that case;
- a length representing the match length, that is, how many bytes on the look-ahead buffer were repeated on its match located in the search window. It is equal to 0 if no match was found; and
- a next symbol representing the next symbol in the look-ahead buffer to be processed.
4.1.2. Dictionary Structure
4.1.3. Output Format
4.1.4. Range Encoding (RE)
- Q1 -
- The problem has no concurrent processes, that is, the functions are sequentially executed;
- Q2 -
- The problem communication paths are partially ordered, that is, it is not possible to determine the sequence of tokens considering different data paths;
- Q3 -
- the model does not have any deadlock and will be finished only when there is no data in the input stream;
- Q4 -
- the processing of the input streams are cyclic and non-terminating; and
- Q5 -
- The functions cannot be synchronized by a clock, they depend on the data tokens outputted by other functions.
4.2. MoC Definition Step
4.3. Framework Selection Step
- License style: the present research work focus is on open source tools;
- Included MoCs: the framework must include the selected MoC, that is, SADF;
- Capabilities: the proposed design includes both modeling and simulation;
- Interfaces: this case study accepts inputs and output from an user interface or from files;
- Scalability: this case study targets model high scalability. In this sense, a text-based coding interface is better than a GUI;
- Programming language paradigm: towards a higher level of abstraction, Haskell, a pure functional programming language, was selected as the framework base language.
4.4. Modeling and Simulation Step
4.4.1. SADF LZMA Model Description
- is the match detector, which controls the scenarios from both kernels, and . In this sense, comprehends two scenarios, that is, and , as described in Table 2;
- -
- The input signal transmits the current status of ;
- -
- The scenarios, , are outputted to the signal , according to Table 3;
- -
- Although contains a single scenario, , the control channel is needed for detector to reach a system feasible schedule. To model this behavior, its output token rate can vary from 0 to 1;
- is the sliding window encoding kernel, which compresses the input stream by outputting processed tokens. Without loosing system main behavior and properties, the present modeling adapts the dictionary structure to a sliding window method based on the original LZ77 algorithm, aiming a simple model however preserving its behavior and properties.
- -
- The is an input signal, representing a stream to be compressed. Our model considers the input stream to be always finished with the NULL character;
- -
- The consumption token rate depends on the current scenario, as described in Table 3. It can vary from 0 to 1 . Each represents a character from the input stream;
- -
- The feedback signal carries tuples . In this context, represents the window dictionary, represents a package which is being processed, and models the latest four used distances vector;
- -
- is a signal which carries the produced tokens to ;
- -
- The production token rate can vary depending on the kernel scenario, from 0 to 1 , as described in Table 3. The possible formats are described in Table 4 and Table 5. The original LZMA encodes the variable , contained in format , with different number of bits and contents depending on the match distance value. Our model simplifies the variable encoding, assuming it to be an integer composed by 8 bits;
- -
- The control channel, signal , carries tokens comprehending the possible scenarios ; and
- -
- The signal carries Boolean values that are either , if a package was processed and is ready to be outputted, or otherwise.
- is the range encoding kernel, which performs a bit-wise compression of packages, outputting encrypted bytes to LZMA output stream. Although its token rates are all constants, its fire cycles are controlled by the detector ;
- -
- The input port, connected to the signal , has a fixed consumption token rate equals to ;
- -
- The input control port, connected to the signal , has a fixed consumption token rate of 1;
- -
- The output signal carries the LZMA output stream, composed by encrypted bytes produced by . The fixed output token rate is , consisting on a signal of bytes;
- -
- Signal carries tuples that contains the relevant variables for the range encoding, that is, . In this context, represents the considered range when encoding the next bit. represents the lower limit of the considered range for the next bit encoding. represents a processed value to be outputted to in the next range encoder token production;
- -
- Signal (dashed line in Figure 4) represents the bit probabilities updated at each compression cycle, in case the variable probability is configured. Although the fixed probability configuration has a reduction in the compression rate performance taking into account some cases where the bits patterns are often repeated, there is no loss of generality when considering fixed bit probabilities. In this sense, the present work assumes the range encoder configured to use fixed probability encoding; and
- -
- The initial token in the signal is the compressed file header, which includes LZMA configuration, dictionary size and decompressed file size.
4.4.2. LZMA Modeling with ForSyDe SADF MoC
- SWEData represents de kernel output token type, which can be derived to all the package types;
- SWEkScenario and REkScenario models the kernels and scenarios, respectively;
- RangeVars models the tokens contained in the feedback signal , which comprehends the current encoding , its value and the , representing a stored byte to be outputted when the next output token is produced;
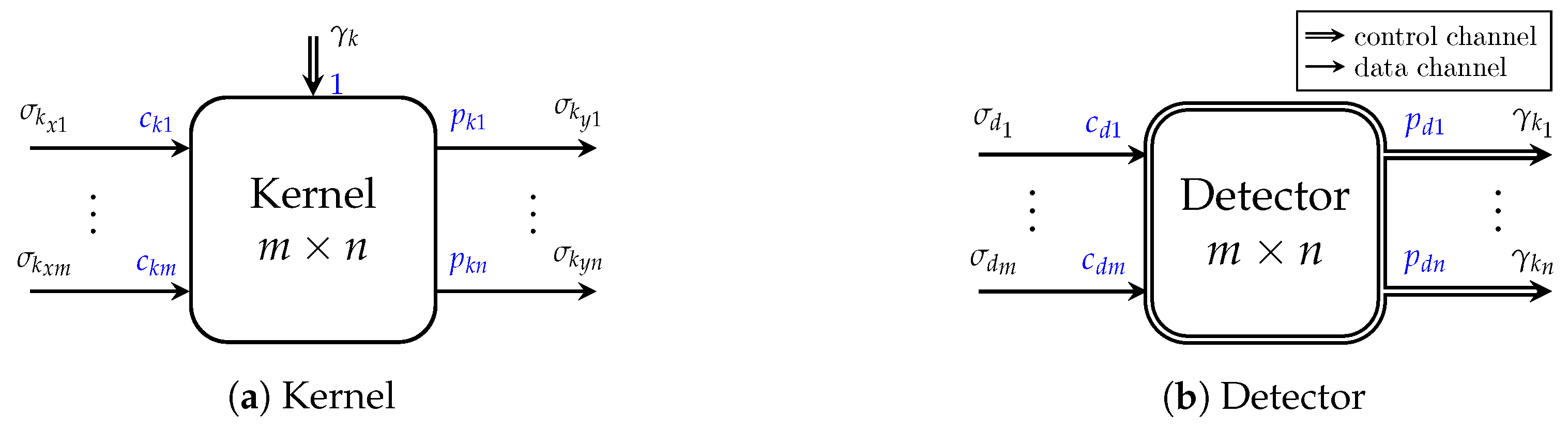
- matD models the detector using the ForSyDe process constructor detector12SADF, with one input port and two control output ports;
- sweK models kernel using the process constructor kernel23SADF, indicating it contains two data input ports and three data output ports; and
- rek represents the range encoder kernel , modeled using the process constructor kernel22SADF, indicating it contains two data input ports and two data output ports;
| Listing 3: LZMA model signatures and definitions in Haskell/ForSyDe. |
 |
- FDscenario represents the detector scenario, comprehending the output token rates of the control channels ports and the sent kernels scenarios. FDstate models the detector state, based on the kernel boolean output through ; and
- matStateTran represents the detector function to select the scenarios based on a Boolean input, and matStateOut outputs the and scenarios.
| Listing 4: LZMA detector model functions in Haskell/ForSyDe. |
 |
- sweSearch and sweFlush model the functions executed by sweK depending on its scenario, where:
- -
- sweSearch represents the scenario in which consumes a character from input signal when searching for a match; and
- -
- sweFlush models the output of a found package to signal .
| Listing 5: LZMA sliding window kernel main functions in Haskell/ForSyDe. |
 |
- encBit models the bit-wise processing of the tokens, updating the RangeVars variables;
- normRange models the normalization procedure, executed when the range reaches its lower limit and needs to be re-scaled, producing one byte that will be outputted to the signal, temporarily stored in Cache;
- normFinalRange and finalBytes models the final normalization cycles executed by ;
- rekStdBy models the standby state of kernel , while waiting for a token; and
- rekRead models the function to read a token and encrypt it to .
| Listing 6: LZMA range encoding kernel main functions in Haskell/ForSyDe. |
 |
| Listing 7: LZMA compression process network in Haskell/ForSyDe. |
 |
4.4.3. Model Simulation
| Listing 8: LZMA compression test processes. |
 |
| Listing 9: LZMA compression input example #1. |
 |
| Listing 10: LZMA compression input example #2. |
 |
| Listing 11: LZMA compression input example #3. |
 |
4.5. Properties Verification Step
- VSADF1
- BoundednessProperty verification—The three verification aspects are considered for the presented LZMA model:
- (a)
- The first aspect is used for verification of models where all the processes comprehend a single scenario. In the LZMA case, the kernel and detector do not operate in a single scenario, as described in Section 4.4.1. In this sense, this aspect is not applicable;
- (b)
- The LZMA kernel becomes inactive during the detector scenario . In this model, the range encoder fires a single time for each scenario selection (). For the model to be bounded, the duration has to be smaller than the duration between two scenarios detection by ;
- (c)
- The third aspect must be analyzed focusing on kernel and detector , as these are the only processes with multiple scenarios. The interface between these processes consists on a cyclic dependency with fixed and equal token rates, not representing an unboundedness risk. Regarding the boundedness of signal , the production token rate from output port is controlled by , and the consumption token rate from is always one. In scenario , will not produce any tokens in , and in scenario , will produce one token that will be promptly consumed by in the same iteration. In this context, the third boundedness aspect will always hold, as controls the system schedule, so that will not produce another token before consumes the last one.
- VSADF2
- Absence of deadlocksProperty verification—Analyzing the LZMA model, the included cyclic dependency are the feedback signals , and , in addition to the and processes cycle. Initial tokens were added to each of these cycles, satisfying the necessary consumption token rates. As a consequence, it is verified that the LZMA system holds this property.
- VSADF3
- DeterminacyProperty verification—The LZMA does not comprehend multiple independent concurrent processes, as the depends on and vice-versa. Besides, also depends on . As a consequence, the system holds the determinacy property.
4.6. Implementation Details and Implement System
5. Results and Discussion
5.1. Analysis Identifying Steps to be Automated
5.1.1. Properties Verification with the Tool Quickcheck
5.1.2. Automatic Code Generation
6. Conclusions
- problem characterization—to identify the relevant behaviors and characteristics of the target problem, defining intermediate functions that can represent the system processes and their relationships;
- MoC definition—based on problem characteristics, select a MoC to be used in the system design flow;
- framework selection—to define the formal-based framework for system modeling and simulation;
- model & simulate—to model the specified system, simulating it to verify its consistency;
- properties verification—to verify that the system model holds the defined MoC properties.
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Lee, E.A. CPS foundations. In Design Automation Conference; ACM Press: New York, NY, USA, 2010. [Google Scholar] [CrossRef]
- Edwards, S.; Lavagno, L.; Lee, E.; Sangiovanni-Vincentelli, A. Design of embedded systems: Formal models, validation, and synthesis. Proc. IEEE 1997, 85, 366–390. [Google Scholar] [CrossRef]
- Jantsch, A.; Sander, I. Models of computation and languages for embedded system design. IEE Proc. Comput. Digit. Tech. 2005, 152, 114. [Google Scholar] [CrossRef] [Green Version]
- Ptolemaeus, C. (Ed.) System Design, Modeling, and Simulation Using Ptolemy II. Available online: https://ptolemy.berkeley.edu/books/Systems/chapters/HeterogeneousModeling.pdf (accessed on 21 February 2020).
- Sander, I.; Jantsch, A.; Attarzadeh-Niaki, S.H. ForSyDe: System Design Using a Functional Language and Models of Computation. In Handbook of Hardware/Software Codesign; Springer: Amsterdam, The Netherlands, 2016; pp. 1–42. [Google Scholar] [CrossRef]
- Stuijk, S.; Geilen, M.; Basten, T. SDF3: SDF For Free. In Proceedings of the Sixth International Conference on Application of Concurrency to System Design (ACSD’06), Turku, Finland, 28–30 June 2006; pp. 276–278. [Google Scholar] [CrossRef]
- MathWorks. Simulink Documentation. 2019. Available online: https://www.mathworks.com/help/simulink/index.html (accessed on 21 February 2020).
- Horita, A.Y.; Bonna, R.; Loubach, D.S. Analysis and Comparison of Frameworks Supporting Formal System Development based on Models of Computation. In 16th International Conference on Information Technology-New Generations (ITNG 2019); Latifi, S., Ed.; Springer International Publishing: Cham, Switzerland, 2019; pp. 161–167. [Google Scholar]
- Jantsch, A. Models of Embedded Computation. In Embedded Systems Handbook; Chapter Models of Embedded Computation; CRC Press: Boca Raton, FL, USA, 2005. [Google Scholar]
- Lee, E.; Sangiovanni-Vincentelli, A. A framework for comparing models of computation. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 1998, 17, 1217–1229. [Google Scholar] [CrossRef] [Green Version]
- Benveniste, A.; Berry, G. The synchronous approach to reactive and real-time systems. Proc. IEEE 1991, 79, 1270–1282. [Google Scholar] [CrossRef] [Green Version]
- Lee, E.; Messerschmitt, D. Synchronous data flow. Proc. IEEE 1987, 75, 1235–1245. [Google Scholar] [CrossRef]
- Theelen, B.D.; Geilen, M.C.W.; Basten, T.; Voeten, J.P.M.; Gheorghita, S.V.; Stuijk, S. A scenario-aware data flow model for combined long-run average and worst-case performance analysis. In Proceedings of the MEMOCODE ’06 Fourth ACM and IEEE International Conference on Formal Methods and Models for Co-Design, Napa, CA, USA, 27–30 July 2006; pp. 185–194. [Google Scholar] [CrossRef]
- Bonna, R.; Loubach, D.S.; Ungureanu, G.; Sander, I. Modeling and Simulation of Dynamic Applications using Scenario-Aware Dataflow. ACM Trans. Des. Autom. Electron. Syst. 2019, 24, 5. [Google Scholar] [CrossRef]
- Association, T.M. Modelica Website. 2019. Available online: https://www.modelica.org/ (accessed on 21 February 2020).
- Open Source Modelica Consortium (OSMC). OpenModelica Website. 2019. Available online: https://openmodelica.org/ (accessed on 21 February 2020).
- Mathaikutty, D.; Patel, H.; Shukla, S.; Jantsch, A. EWD: A Metamodeling Driven Customizable multi-MoC System Modeling Framework. ACM Trans. Des. Autom. Electron. Syst. 2008, 12, 33:1–33:43. [Google Scholar] [CrossRef]
- Herrera, F.; Villar, E. A framework for heterogeneous specification and design of electronic embedded systems in SystemC. ACM Trans. Des. Autom. Electron. Syst. 2007, 12, 22. [Google Scholar] [CrossRef]
- Sander, I.; Jantsch, A. Formal system design based on the synchrony hypothesis, functional models, and skeletons. In Proceedings of the IEEE, Twelfth International Conference on VLSI Design, (Cat. No. PR00013), Goa, India, 7–10 January 1999. [Google Scholar] [CrossRef] [Green Version]
- University of California B.o. ICyPhy Home Page. 2018. Available online: https://ptolemy.berkeley.edu/projects/icyphy/ (accessed on 21 February 2020).
- Jantsch, A. Modeling Embedded Systems and SoC’s; Morgan Kaufmann: San Francisco, CA, USA, 2003. [Google Scholar]
- ForSyDe Group, K. ForSyDe Hackage Page. 2019. Available online: https://forsyde.github.io/tools.html (accessed on 30 April 2018).
- Turner, D.A. Some History of Functional Programming Languages. In Trends in Functional Programming; Loidl, H.W., Peña, R., Eds.; Springer Berlin Heidelberg: Berlin/Heidelberg, Germany, 2013; pp. 1–20. [Google Scholar]
- Haskell. The Haskell Purely Functional Programming Language Home Page. 2018. Available online: https://www.haskell.org (accessed on 21 February 2020).
- Scott, M.L. Programming Language Pragmatics, 3rd ed.; Morgan Kaufmann Publishers Inc.: San Francisco, CA, USA, 2009. [Google Scholar]
- MathWorks. Simulink Embedded Coder Website. 2019. Available online: https://www.mathworks.com/products/embedded-coder.html (accessed on 21 February 2020).
- Krizan, J.; Ertl, L.; Bradac, M.; Jasansky, M.; Andreev, A. Automatic code generation from Matlab/Simulink for critical applications. In Proceedings of the 2014 IEEE 27th Canadian Conference on Electrical and Computer Engineering (CCECE), Toronto, ON, Canada, 4–7 May 2014; pp. 1–6. [Google Scholar] [CrossRef]
- Pike, L.; Wegmann, N.; Niller, S.; Goodloe, A. Copilot: Monitoring embedded systems. Innov. Syst. Softw. Eng. 2013, 9. [Google Scholar] [CrossRef] [Green Version]
- Rash, J.L.; Hinchey, M.G.; Rouff, C.A.; Gračanin, D.; Erickson, J. A requirements-based programming approach to developing a NASA autonomous ground control system. Artif. Intell. Rev. 2006, 25, 285–297. [Google Scholar] [CrossRef]
- Seshia, S.A.; Hu, S.; Li, W.; Zhu, Q. Design Automation of Cyber-Physical Systems: Challenges, Advances, and Opportunities. IEEE Trans. Comput.-Aided Des. Integr. Circuits Syst. 2017, 36, 1421–1434. [Google Scholar] [CrossRef]
- Sander, I. System Modeling and Design Refinement in ForSyDe. Ph.D. Thesis, Royal Institute of Technology KTH, Stockholm, Sweden, 2003. [Google Scholar]
- Loubach, D.S. A runtime reconfiguration design targeting avionics systems. In Proceedings of the 2016 IEEE/AIAA 35th Digital Avionics Systems Conference (DASC), Sacramento, CA, USA, 25–29 September 2016; pp. 1–8. [Google Scholar] [CrossRef]
- Bourke, T.; Colaço, J.L.; Pagano, B.; Pasteur, C.; Pouzet, M. A Synchronous-Based Code Generator for Explicit Hybrid Systems Languages. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2015; pp. 69–88. [Google Scholar] [CrossRef]
- Grabmüeller, M.; Kleeblatt, D. Harpy. In Proceedings of the ACM SIGPLAN Workshop on Haskell Workshop-Haskell 07; ACM Press: New York, NY, USA, 2007. [Google Scholar] [CrossRef]
- Acosta, A. ForSyDe Tutorial Website. 2008. Available online: https://hackage.haskell.org/package/ForSyDe-3.1/src/doc/www/files/tutorial/tutorial.html (accessed on 21 February 2020).
- Pavlov, I. 7z Format. 2019. Available online: http://www.7-zip.org/7z.html (accessed on 21 February 2020).
- Standard Performance Evaluation Corporation (SPEC). 657.xz_s SPEC CPU 2017 Benchmark Description. 2019. Available online: http:/www.spec.org/cpu2017/Docs/benchmarks/657.xz_s.html (accessed on 21 February 2020).
- Ziv, J.; Lempel, A. A universal algorithm for sequential data compression. IEEE Trans. Inf. Theory 1977, 23, 337–343. [Google Scholar] [CrossRef] [Green Version]
- Martin, G.N. Range Encoding: An Algorithm for Removing Redundancy from a Digitized Message. Available online: https://pdfs.semanticscholar.org/3a46/423f866d53d4e0328faf365c4c9101f82577.pdf?_ga=2.221534352.907706746.1582276987-231942018.1567670099 (accessed on 21 February 2020).
- Leavline, E.J. Hardware Implementation of LZMA Data Compression Algorithm. Int. J. Appl. Inf. Syst. (IJAIS) 2013, 5, 51–56. [Google Scholar]
- Salomon, D. Data Compression: The Complete Reference; with contributions by Giovanni Motta and David Bryant; Springer: Berlin, Germany, 2007; p. 1092. [Google Scholar]
- Horita, A.Y.; Bonna, R.; Loubach, D.S. Lempel-Ziv-Markov Chain Algorithm Modeling using Models of Computation and ForSyDe. In Proceedings of the Aerospace technology Congress 2019 (FT2019), Stockholm, Sweden, 8–9 October 2019. [Google Scholar]
- Collin, L. XZ Utils. 2019. Available online: https://www.tukaani.org/xz/ (accessed on 21 February 2020).
- Zhao, X.; Li, B. Implementation of the LZMA compression algorithm on FPGA. In Proceedings of the 2017 International Conference on Electron Devices and Solid-State Circuits (EDSSC), Hsinchu, Taiwan, 18–20 October 2017; pp. 1–2. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Package Code [Base 2] | Package Name | Package Description |
|---|---|---|
| LIT | One byte encoded using an adaptive binary range coder | |
| MATCH | An LZ77 tuple describing sequence length and distance | |
| 1100 | SHORTREP | One-byte LZ77 tuple. Distance is equal to the last used |
| LONGREP[0] | An LZ77 tuple. Distance is equal to the last used | |
| LONGREP[1] | An LZ77 tuple. Distance is equal to the second last used | |
| LONGREP[2] | An LZ77 tuple. Distance is equal to the third last used | |
| LONGREP[3] | An LZ77 tuple. Distance is equal to the fourth last used |
| Scenarios | Rates [Kernel Scenario] | |
|---|---|---|
| 1 [Search] | 0 | |
| 1 [Flush] | 1 [Read] | |
| Scenarios | Rates | |
|---|---|---|
| Search | 1 | 0 |
| Flush | 0 | 1 |
| Package | Model | System Code |
|---|---|---|
| LIT | ||
| MATCH | ||
| SHORTREP | 1100 | |
| LONGREP[0] | ||
| LONGREP[1] | ||
| LONGREP[2] | ||
| LONGREP[3] |
| l Format | Range |
|---|---|
| bits | |
| bits | |
| bits |
| Token | S | S | F | S | … | |||||
|---|---|---|---|---|---|---|---|---|---|---|
| Running Processes | … | |||||||||
| Scenarios | … | |||||||||
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Horita, A.Y.; Loubach, D.S.; Bonna, R. Analysis and Identification of Possible Automation Approaches for Embedded Systems Design Flows. Information 2020, 11, 120. https://doi.org/10.3390/info11020120
Horita AY, Loubach DS, Bonna R. Analysis and Identification of Possible Automation Approaches for Embedded Systems Design Flows. Information. 2020; 11(2):120. https://doi.org/10.3390/info11020120
Chicago/Turabian StyleHorita, Augusto Y., Denis S. Loubach, and Ricardo Bonna. 2020. "Analysis and Identification of Possible Automation Approaches for Embedded Systems Design Flows" Information 11, no. 2: 120. https://doi.org/10.3390/info11020120