Albumentations: Fast and Flexible Image Augmentations

 , , and
, , and 
Abstract
1. Introduction
2. Background
2.1. Approaches to Image Augmentations
2.2. Performance Considerations
2.3. Augmentations of Complex Targets
3. Design Principles
3.1. Performance
3.2. Variety
3.3. Conciseness
3.4. Flexibility
3.5. High Open Source Development Standards
4. Key Features
4.1. Declarative Definition of Parameters
- import albumentations as A
- aug = A.RandomSizedCrop(min_max_height=(128, 256),
- height=224, width=224, p=0.3)
- image = cv2.imread("test.png")
- augmented_dict = aug(image=image)
- image_out = augmented_dict["image"]
4.2. Composition
- transform = A.Compose([
- A.OneOf([
- A.ShiftScaleRotate(..., p=0.5),
- A.ElasticTransform(..., p=0.5),
- A.OpticalDistortion(..., p=0.5),
- A.GridDistortion(..., p=0.5),
- A.NoOp()
- ]),
- A.RandomSizedCrop(..., p=0.3),
- A.ISONoise(p=0.5),
- A.OneOf([
- A.RandomBrightnessContrast(..., p=0.5),
- A.RandomGamma(..., p=0.5),
- A.NoOp()
- ]),
- A.OneOf([
- A.FancyPCA(..., p=0.5),
- A.RGBShift(..., p=0.5),
- A.HueSaturationValue(..., p=0.5),
- A.ToGray(p=0.2),
- A.NoOp()
- ]),
- A.ChannelDropout(p=0.5),
- A.RandomGridShuffle(p=0.3),
- A.RandomRotate90(p=0.5),
- A.Transpose(p=0.5)
- ])
4.3. Complex Target Support
4.3.1. Image and Mask Target Support
4.3.2. Bounding Box Support
- transform = A.Compose([...],
- bbox_params=A.BboxParams(format="coco", ...))
- ...
- data = transform(image=original_image,
- bboxes=original_bboxes, labels=original_labels)
4.3.3. Keypoint Support
- aug = A.Compose(
- [A.ShiftScaleRotate(..., always_apply=True)],
- keypoint_params=A.KeypointParams(format="xyas"))
- ...
- aug(image=original_image, keypoints = [[10,20,45,20], [30,40,70,30]])
4.3.4. Multiple Targets
4.4. Data-Dependent Augmentations
4.5. Serialization and Replay Mode
- transform = A.Compose([
- A.RandomCrop(...),
- A.OneOf([
- A.RGBShift(),
- A.HueSaturationValue()
- ]),
- ])
- A.save(transform, ’/tmp/transform.json’)
- loaded_transform = A.load(’/tmp/transform.json’)
4.6. Custom Augmentations
- def custom_aug_img(image, **kwargs):
- image_orig = image.copy()
- cv2.putText(image, "A", ...)
- cv2.circle(image, ...)
- return cv2.addWeighted(image_orig, 0.5, image, 0.5, 0)
- def custom_aug_mask(mask, **kwargs):
- cv2.putText(mask, "A", ...)
- cv2.circle(mask, ...)
- return mask
- custom_aug = A.Lambda(image=custom_aug_img, mask=custom_aug_mask)]
4.7. Performance
5. Evaluation
5.1. Benchmarks
5.2. Ablation Study
- No augmentations: After cropping and tile, no changes to the image were made.
- Light augmentations: Random horizontal flips, change of brightness, contrast, color, and random affine and perspective changes.
- Medium augmentations, an extended set of augmentations in addition to the Light scenario: Gaussian blur, sharpening, coarse dropout, removal of some buildings, and randomly generated fog.
- Hard augmentations, extending the Medium set with: Random rotation by 90 degrees, image grid shuffle, elastic transformations, gamma adjustments, and contrast-limited adaptive histogram equalization.
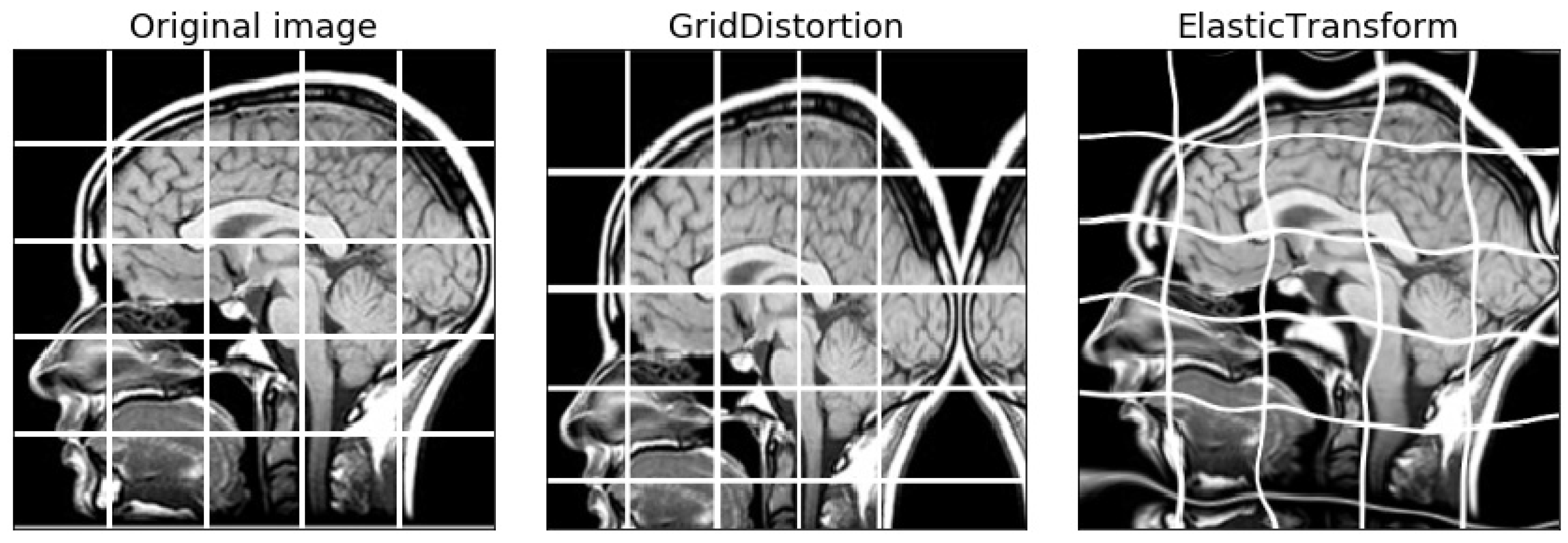
5.3. Visualization
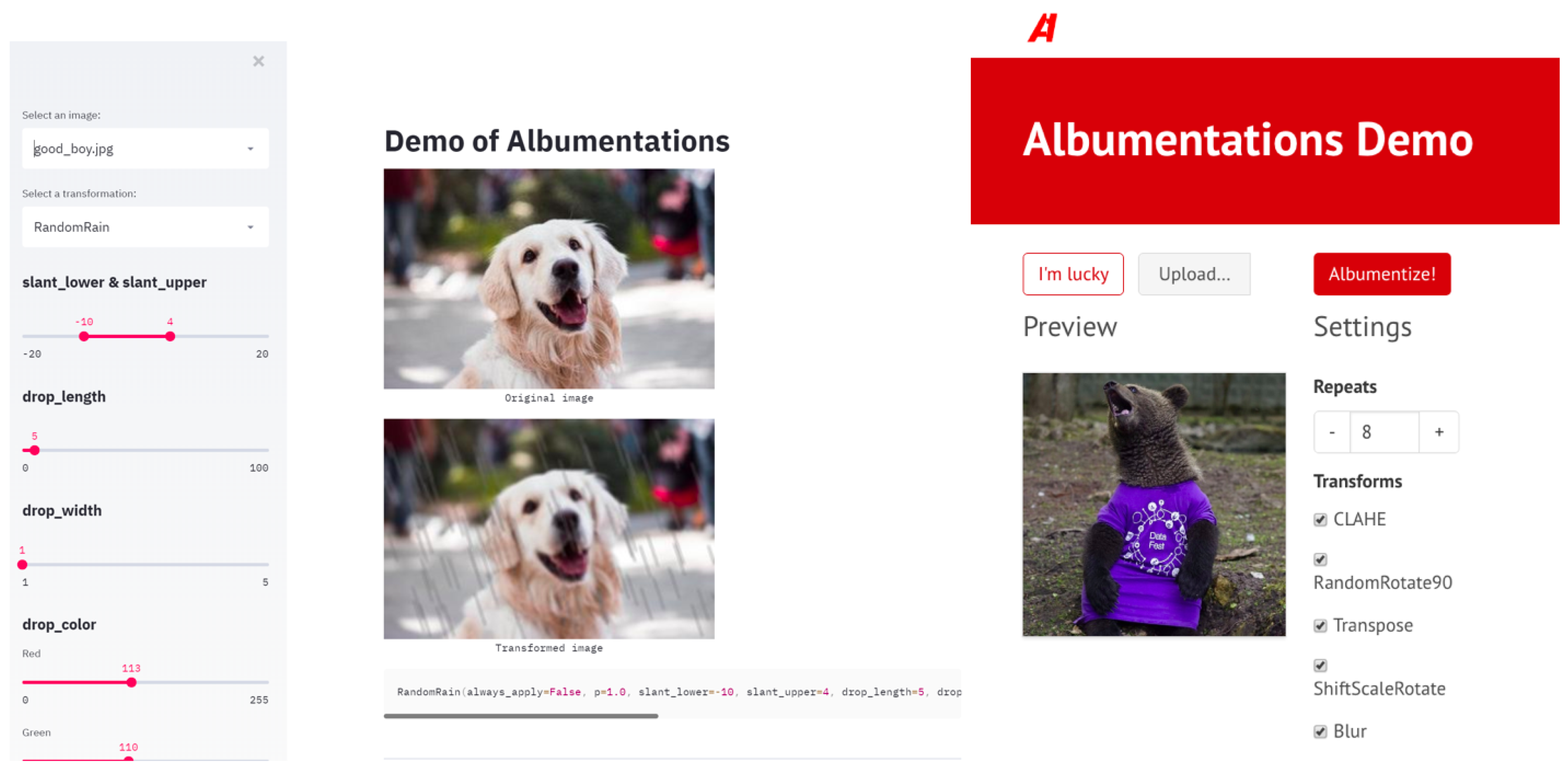
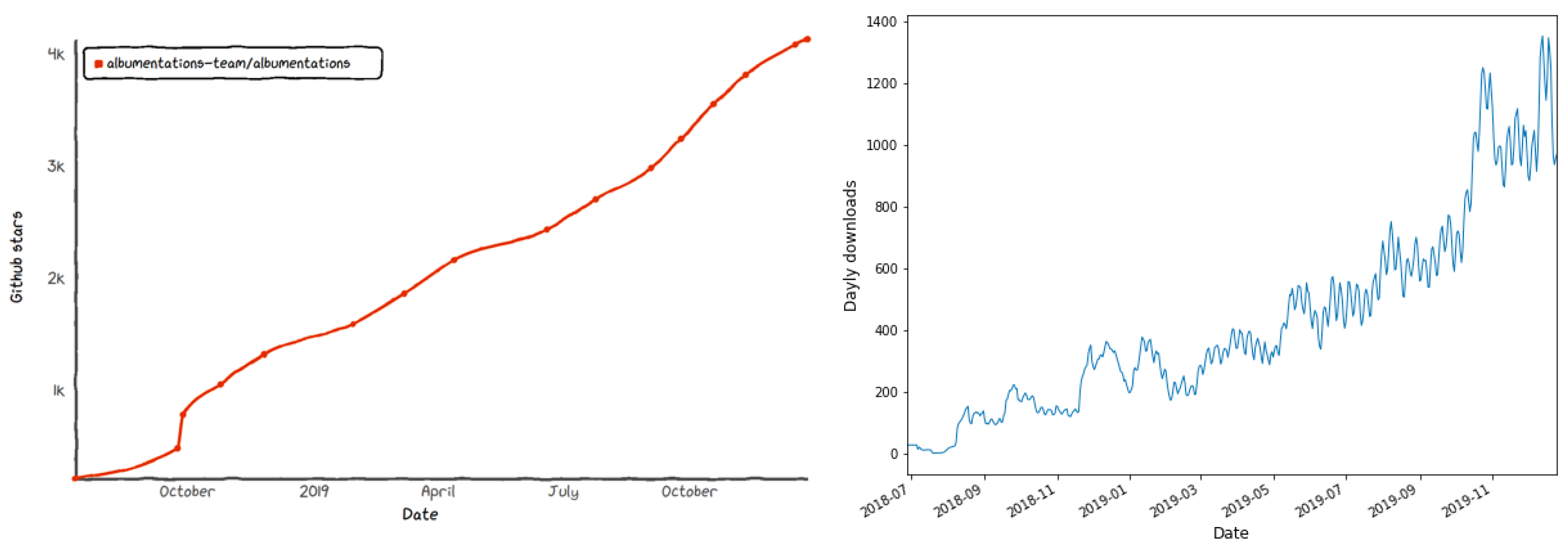
5.4. Adoption
6. Discussion and Future Work
Supplementary Materials
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Abbreviations
| API | Application Programming Interface |
| CPU | Central Processing Unit |
| GPU | Graphics Processing Unit |
| IoU | Intersection over Union |
| JSON | JavaScript Object Notation |
| LUT | Look-Up Table |
| PCA | Principal Component Analysis |
| PyPI | Python Package Index |
| RGB(A) | Red, Green, and Blue (Alpha) |
| SIMD | Single Instruction, Multiple Data |
| YAML | YAML Ain’t Markup Language |
References
- LeCun, Y.; Bengio, Y.; Hinton, G. Deep learning. Nature 2015, 521, 436–444. [Google Scholar] [CrossRef]
- Nowlan, S.J.; Hinton, G.E. Simplifying neural networks by soft weight-sharing. Neural Comput. 1992, 4, 473–493. [Google Scholar] [CrossRef]
- Hawkins, D.M. The problem of overfitting. J. Chem. Inf. Comput. Sci. 2004, 44, 1–12. [Google Scholar] [CrossRef] [PubMed]
- Kukačka, J.; Golkov, V.; Cremers, D. Regularization for deep learning: A taxonomy. arXiv 2017, arXiv:1710.10686. [Google Scholar]
- Mikołajczyk, A.; Grochowski, M. Data augmentation for improving deep learning in image classification problem. In Proceedings of the 2018 International Interdisciplinary PhD Workshop (IIPhDW), Swinoujście, Poland, 9–12 May 2018; pp. 117–122. [Google Scholar]
- Shorten, C.; Khoshgoftaar, T.M. A survey on image data augmentation for deep learning. J. Big Data 2019, 6, 60. [Google Scholar] [CrossRef]
- Liu, S.; Papailiopoulos, D.; Achlioptas, D. Bad Global Minima Exist and SGD Can Reach Them. arXiv 2019, arXiv:1906.02613. [Google Scholar]
- Bengio, Y.; Bastien, F.; Bergeron, A.; Boulanger-Lewandowski, N.; Breuel, T.; Chherawala, Y.; Cisse, M.; Côté, M.; Erhan, D.; Eustache, J.; et al. Deep learners benefit more from out-of-distribution examples. In Proceedings of the Fourteenth International Conference on Artificial Intelligence and Statistics, Ft. Lauderdale, FL, USA, 11–13 April 2011; pp. 164–172. [Google Scholar]
- Hendrycks, D.; Mu, N.; Cubuk, E.D.; Zoph, B.; Gilmer, J.; Lakshminarayanan, B. AugMix: A Simple Data Processing Method to Improve Robustness and Uncertainty. In Proceedings of the International Conference on Learning Representations (ICLR), Millennium Hall, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Hernández-García, A.; König, P. Further advantages of data augmentation on convolutional neural networks. In Proceedings of the International Conference on Artificial Neural Networks, Rhodes, Greece, 4–7 October 2018; pp. 95–103. [Google Scholar]
- Abadi, M.; Barham, P.; Chen, J.; Chen, Z.; Davis, A.; Dean, J.; Devin, M.; Ghemawat, S.; Irving, G.; Isard, M.; et al. Tensorflow: A system for large-scale machine learning. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16), Savannah, GA, USA, 2–4 November 2016; pp. 265–283. [Google Scholar]
- Chollet, F. Keras. 2015. Available online: https://keras.io (accessed on 21 February 2020).
- Paszke, A.; Gross, S.; Massa, F.; Lerer, A.; Bradbury, J.; Chanan, G.; Killeen, T.; Lin, Z.; Gimelshein, N.; Antiga, L.; et al. PyTorch: An imperative style, high-performance deep learning library. In Proceedings of the Advances in Neural Information Processing Systems, Vancouver, BC, Canada, 8–14 December 2019; pp. 8024–8035. [Google Scholar]
- Ratner, A.J.; Ehrenberg, H.; Hussain, Z.; Dunnmon, J.; Ré, C. Learning to compose domain-specific transformations for data augmentation. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 3236–3246. [Google Scholar]
- Lemley, J.; Bazrafkan, S.; Corcoran, P. Smart Augmentation Learning an Optimal Data Augmentation Strategy. IEEE Access 2017, 5, 5858–5869. [Google Scholar] [CrossRef]
- Cubuk, E.D.; Zoph, B.; Mane, D.; Vasudevan, V.; Le, Q.V. AutoAugment: Learning Augmentation Policies from Data. arXiv 2018, arXiv:1805.09501. [Google Scholar]
- Bradski, G. The OpenCV Library. Dr. Dobb’s J. Softw. Tools 2000. Available online: https://www.drdobbs.com/open-source/the-opencv-library/184404319 (accessed on 21 February 2020).
- Clark, A. Pillow. 2010. Available online: https://python-pillow.org/ (accessed on 21 February 2020).
- Ince, D.C.; Hatton, L.; Graham-Cumming, J. The case for open computer programs. Nature 2012, 482, 485. [Google Scholar] [CrossRef]
- Jung, A.B.; Wada, K.; Crall, J.; Tanaka, S.; Graving, J.; Yadav, S.; Banerjee, J.; Vecsei, G.; Kraft, A.; Borovec, J.; et al. Imgaug. 2019. Available online: https://github.com/aleju/imgaug (accessed on 31 December 2019).
- Bloice, M.D.; Roth, P.M.; Holzinger, A. Biomedical image augmentation using Augmentor. Bioinformatics 2019, 35, 4522–4524. [Google Scholar] [CrossRef]
- Casado-García, Á.; Domínguez, C.; García-Domínguez, M.; Heras, J.; Inés, A.; Mata, E.; Pascual, V. CLoDSA: A tool for augmentation in classification, localization, detection, semantic segmentation and instance segmentation tasks. BMC Bioinform. 2019, 20, 323. [Google Scholar] [CrossRef] [PubMed]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR 2009), Miami, FL, USA, 20–26 June 2009; pp. 248–255. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Howard, A.G. Some improvements on deep convolutional neural network based image classification. arXiv 2013, arXiv:1312.5402. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Wu, R.; Yan, S.; Shan, Y.; Dang, Q.; Sun, G. Deep image: Scaling up image recognition. arXiv 2015, arXiv:1501.02876. [Google Scholar]
- Litjens, G.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.A.; Ciompi, F.; Ghafoorian, M.; Van Der Laak, J.A.; Van Ginneken, B.; Sánchez, C.I. A survey on deep learning in medical image analysis. Med. Image Anal. 2017, 42, 60–88. [Google Scholar] [CrossRef]
- Ching, T.; Himmelstein, D.S.; Beaulieu-Jones, B.K.; Kalinin, A.A.; Do, B.T.; Way, G.P.; Ferrero, E.; Agapow, P.M.; Zietz, M.; Hoffman, M.M.; et al. Opportunities And Obstacles For Deep Learning In Biology And Medicine. J. R. Soc. Interface 2018, 15. [Google Scholar] [CrossRef]
- Rakhlin, A.; Shvets, A.; Iglovikov, V.; Kalinin, A.A. Deep Convolutional Neural Networks for Breast Cancer Histology Image Analysis. In Image Analysis and Recognition; Campilho, A., Karray, F., ter Haar Romeny, B., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 737–744. [Google Scholar]
- DeVries, T.; Taylor, G.W. Improved regularization of convolutional neural networks with cutout. arXiv 2017, arXiv:1708.04552. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond empirical risk minimization. In Proceedings of the International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Guo, H.; Mao, Y.; Zhang, R. Mixup as locally linear out-of-manifold regularization. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 3714–3722. [Google Scholar]
- Yun, S.; Han, D.; Oh, S.J.; Chun, S.; Choe, J.; Yoo, Y. Cutmix: Regularization strategy to train strong classifiers with localizable features. In Proceedings of the International Conference on Computer Vision (ICCV), Seoul, Korea, 27 October–2 November 2019. [Google Scholar]
- Graham, B. Fractional max-pooling. arXiv 2014, arXiv:1412.6071. [Google Scholar]
- Lee, H.; Hwang, S.J.; Shin, J. Rethinking Data Augmentation: Self-Supervision and Self-Distillation. arXiv 2019, arXiv:1910.05872. [Google Scholar]
- He, Z.; Xie, L.; Chen, X.; Zhang, Y.; Wang, Y.; Tian, Q. Data Augmentation Revisited: Rethinking the Distribution Gap between Clean and Augmented Data. arXiv 2019, arXiv:1909.09148. [Google Scholar]
- Tran, T.; Pham, T.; Carneiro, G.; Palmer, L.; Reid, I. A bayesian data augmentation approach for learning deep models. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 2797–2806. [Google Scholar]
- Lim, S.; Kim, I.; Kim, T.; Kim, C.; Kim, S. Fast AutoAugment. In Proceedings of the Advances in Neural Information Processing Systems (NeurIPS), Vancouver, BC, Canada, 8–14 December 2019; pp. 6665–6675. [Google Scholar]
- Ho, D.; Liang, E.; Chen, X.; Stoica, I.; Abbeel, P. Population Based Augmentation: Efficient Learning of Augmentation Policy Schedules. In Proceedings of the International Conference on Machine Learning, Boca Raton, FL, USA, 16–19 December 2019; pp. 2731–2741. [Google Scholar]
- Taylor, L.; Nitschke, G. Improving deep learning with generic data augmentation. In Proceedings of the 2018 IEEE Symposium Series on Computational Intelligence (SSCI), Bangalore, India, 18–21 November 2018; pp. 1542–1547. [Google Scholar]
- Joaquin, A.G.; Krzysztof Łęcki, J.L.S.P.M.S.A.W.; Zientkiewicz, M. Fast AI Data Preprocessing with NVIDIA DALI. Available online: https://devblogs.nvidia.com/fast-ai-data-preprocessing-with-nvidia-dali/ (accessed on 31 December 2019).
- Kalinin, A.A.; Allyn-Feuer, A.; Ade, A.; Fon, G.V.; Meixner, W.; Dilworth, D.; De Wet, J.R.; Higgins, G.A.; Zheng, G.; Creekmore, A.; et al. 3D Cell Nuclear Morphology: Microscopy Imaging Dataset and Voxel-Based Morphometry Classification Results. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 2272–2280. [Google Scholar]
- Parpulov, D.; Samorodov, A.; Makhov, D.; Slavnova, E.; Volchenko, N.; Iglovikov, V. Convolutional neural network application for cells segmentation in immunocytochemical study. In Proceedings of the 2018 Ural Symposium on Biomedical Engineering, Radioelectronics and Information Technology (USBEREIT), Yekaterinburg, Russia, 7–8 May 2018; pp. 87–90. [Google Scholar]
- Caicedo, J.C.; Goodman, A.; Karhohs, K.W.; Cimini, B.A.; Ackerman, J.; Haghighi, M.; Heng, C.; Becker, T.; Doan, M.; McQuin, C.; et al. Nucleus segmentation across imaging experiments: The 2018 Data Science Bowl. Nat. Methods 2019, 16, 1247–1253. [Google Scholar] [CrossRef] [PubMed]
- Kalinin, A.A.; Iglovikov, V.; Rakhlin, A.; Shvets, A. Medical Image Segmentation using Deep Neural Networks with Pre-trained Encoders. In Deep Learning Applications; Wani, M.A., Kantardzic, M., Sayed Mouchaweh, M., Eds.; Springer: Singapore, 2020. [Google Scholar]
- Cordts, M.; Omran, M.; Ramos, S.; Rehfeld, T.; Enzweiler, M.; Benenson, R.; Franke, U.; Roth, S.; Schiele, B. The cityscapes dataset for semantic urban scene understanding. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 3213–3223. [Google Scholar]
- Neuhold, G.; Ollmann, T.; Bulò, S.R.; Kontschieder, P. The Mapillary Vistas Dataset for Semantic Understanding of Street Scenes. In Proceedings of the International Conf. on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 5000–5009. [Google Scholar]
- Iglovikov, V.; Seferbekov, S.; Buslaev, A.; Shvets, A. TernausNetV2: Fully Convolutional Network for Instance Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Salt Lake City, UT, USA, 18–22 June 2018; pp. 233–237. [Google Scholar]
- Szegedy, C.; Toshev, A.; Erhan, D. Deep neural networks for object detection. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–8 December 2013; pp. 2553–2561. [Google Scholar]
- Guo, Y.; Liu, Y.; Oerlemans, A.; Lao, S.; Wu, S.; Lew, M.S. Deep learning for visual understanding: A review. Neurocomputing 2016, 187, 27–48. [Google Scholar] [CrossRef]
- Gu, J.; Wang, Z.; Kuen, J.; Ma, L.; Shahroudy, A.; Shuai, B.; Liu, T.; Wang, X.; Wang, G.; Cai, J.; et al. Recent advances in convolutional neural networks. Pattern Recognit. 2018, 77, 354–377. [Google Scholar] [CrossRef]
- Brito, J.J.; Li, J.; Moore, J.H.; Greene, C.S.; Nogoy, N.A.; Garmire, L.X.; Mangul, S. Enhancing rigor and reproducibility by improving software availability, usability, and archival stability. arXiv 2020, arXiv:2001.05127. [Google Scholar]
- Albumentations. Available online: https://github.com/albumentations-team/albumentations (accessed on 31 December 2019).
- Tiulpin, A. SOLT: Streaming over Lightweight Transformations. 2019. Available online: https://zenodo.org/record/3351977#.XlMrnEoRXIU (accessed on 21 February 2020). [CrossRef]
- Automold. Available online: https://github.com/UjjwalSaxena/Automold–Road-Augmentation-Library (accessed on 31 December 2019).
- APTOS 2019 Blindness Detection. Available online: https://www.kaggle.com/c/aptos2019-blindness-detection (accessed on 31 December 2019).
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 740–755. [Google Scholar]
- Everingham, M.; Eslami, S.A.; Van Gool, L.; Williams, C.K.; Winn, J.; Zisserman, A. The pascal visual object classes challenge: A retrospective. Int. J. Comput. Vis. 2015, 111, 98–136. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Maggiori, E.; Tarabalka, Y.; Charpiat, G.; Alliez, P. Can semantic labeling methods generalize to any city? the inria aerial image labeling benchmark. In Proceedings of the 2017 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Fort Worth, TX, USA, 23–28 July 2017; pp. 3226–3229. [Google Scholar]
- Iglovikov, V.I.; Rakhlin, A.; Kalinin, A.A.; Shvets, A.A. Paediatric bone age assessment using deep convolutional neural networks. In Deep Learning in Medical Image Analysis and Multimodal Learning for Clinical Decision Support; Springer: Cham, Switzerland, 2018; pp. 300–308. [Google Scholar]
- Van Der Walt, S.; Colbert, S.C.; Varoquaux, G. The NumPy array: A structure for efficient numerical computation. Comput. Sci. Eng. 2011, 13, 22. [Google Scholar] [CrossRef]
- Jung, A. Imgaug. 2017. Available online: https://github.com/aleju/imgaug (accessed on 21 February 2020).
- Paszke, A.; Gross, S.; Chintala, S.; Chanan, G.; Yang, E.; DeVito, Z.; Lin, Z.; Desmaison, A.; Antiga, L.; Lerer, A. Automatic differentiation in PyTorch. In Proceedings of the NIPS-W, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Munich, Germany, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019; pp. 5693–5703. [Google Scholar]
- Liu, L.; Jiang, H.; He, P.; Chen, W.; Liu, X.; Gao, J.; Han, J. On the variance of the adaptive learning rate and beyond. arXiv 2019, arXiv:1908.03265. [Google Scholar]
- Kolesnikov, S. Accelerated DL & RL. 2018. Available online: https://github.com/catalyst-team/catalyst (accessed on 21 February 2020).
- Albumentations Demo. Available online: https://albumentations-demo.herokuapp.com/ (accessed on 31 December 2019).
- Albumentations Demo. Available online: https://albumentations.ml (accessed on 31 December 2019).
- Shvets, A.A.; Rakhlin, A.; Kalinin, A.A.; Iglovikov, V.I. Automatic Instrument Segmentation in Robot-Assisted Surgery Using Deep Learning. In Proceedings of the 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA), Orlando, FL, USA, 17–20 December 2018; pp. 624–628. [Google Scholar]
- Shvets, A.A.; Iglovikov, V.I.; Rakhlin, A.; Kalinin, A.A. Angiodysplasia detection and localization using deep convolutional neural networks. In Proceedings of the 2018 17th IEEE International Conference on Machine Learning and Applications (ICMLA), Orlando, FL, USA, 17–20 December 2018; pp. 612–617. [Google Scholar]
- Rakhlin, A.; Tiulpin, A.; Shvets, A.A.; Kalinin, A.A.; Iglovikov, V.I.; Nikolenko, S. Breast tumor cellularity assessment using deep neural networks. In Proceedings of the IEEE International Conference on Computer Vision (ICCV) Workshops, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Kupyn, O.; Martyniuk, T.; Wu, J.; Wang, Z. DeblurGAN-v2: Deblurring (Orders-of-Magnitude) Faster and Better. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Ostyakov, P.; Nikolenko, S.I. Adapting Convolutional Neural Networks for Geographical Domain Shift. arXiv 2019, arXiv:1901.06345. [Google Scholar]
- Hasan, S.; Linte, C.A. U-NetPlus: A Modified Encoder-Decoder U-Net Architecture for Semantic and Instance Segmentation of Surgical Instrument. arXiv 2019, arXiv:1902.08994. [Google Scholar]
- Kuzin, A.; Fattakhov, A.; Kibardin, I.; Iglovikov, V.I.; Dautov, R. Camera Model Identification Using Convolutional Neural Networks. In Proceedings of the 2018 IEEE International Conference on Big Data (Big Data), Seattle, WA, USA, 10–13 December 2018; pp. 3107–3110. [Google Scholar] [CrossRef]
- Yang, F.; Sakti, S.; Wu, Y.; Nakamura, S. A Framework for Knowing Who is Doing What in Aerial Surveillance Videos. IEEE Access 2019, 7, 93315–93325. [Google Scholar] [CrossRef]
- Pytorch Ecosystem. Available online: https://pytorch.org/ecosystem/ (accessed on 31 December 2019).
- Open Data Science (ODS.ai). Available online: https://ods.ai (accessed on 31 December 2019).








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| A 0.4.2 | Imgaug 0.3.0 | Torchvision 0.4.1 | Keras 2.3.1 | Augmentor 0.2.6 | Solt 0.1.8 | |
|---|---|---|---|---|---|---|
| HorizontalFlip | 2183 | 1403 | 1757 | 1068 | 1779 | 1031 |
| VerticalFlip | 4217 | 2334 | 1538 | 4196 | 1541 | 3820 |
| Rotate | 456 | 368 | 163 | 32 | 60 | 116 |
| ShiftScaleRotate | 800 | 549 | 146 | 34 | - | - |
| Brightness | 2209 | 1288 | 405 | 211 | 403 | 2070 |
| Contrast | 2215 | 1387 | 338 | - | 337 | 2073 |
| BrightnessContrast | 2208 | 740 | 193 | - | 193 | 1060 |
| ShiftRGB | 2214 | 1303 | - | 407 | - | - |
| ShiftHSV | 468 | 443 | 61 | - | - | 144 |
| Gamma | 2281 | - | 730 | - | - | 925 |
| Grayscale | 5019 | 436 | 788 | - | 1451 | 4191 |
| RandomCrop64 | 173,877 | 3340 | 43,792 | - | 36,869 | 36,178 |
| PadToSize512 | 2906 | - | 553 | - | - | 2711 |
| Resize512 | 663 | 506 | 968 | - | 954 | 673 |
| RandomSizedCrop64_512 | 2565 | 933 | 1395 | - | 1353 | 2360 |
| Equalize | 759 | 457 | - | - | 684 | - |
| Augmentations | Train IoU | Valid IoU | Best Epoch | Data Time (sec/batch) | Model Time (sec/batch) |
|---|---|---|---|---|---|
| None | 84.67 | 73.89 | 45/100 | 0.09 | 0.6 |
| Light | 84.84 | 77.50 | 90/100 | 0.09 | 0.6 |
| Medium | 83.52 | 76.94 | 96/100 | 0.11 | 0.6 |
| Heavy | 79.78 | 78.34 | 95/100 | 0.13 | 0.6 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Buslaev, A.; Iglovikov, V.I.; Khvedchenya, E.; Parinov, A.; Druzhinin, M.; Kalinin, A.A. Albumentations: Fast and Flexible Image Augmentations. Information 2020, 11, 125. https://doi.org/10.3390/info11020125
Buslaev A, Iglovikov VI, Khvedchenya E, Parinov A, Druzhinin M, Kalinin AA. Albumentations: Fast and Flexible Image Augmentations. Information. 2020; 11(2):125. https://doi.org/10.3390/info11020125
Chicago/Turabian StyleBuslaev, Alexander, Vladimir I. Iglovikov, Eugene Khvedchenya, Alex Parinov, Mikhail Druzhinin, and Alexandr A. Kalinin. 2020. "Albumentations: Fast and Flexible Image Augmentations" Information 11, no. 2: 125. https://doi.org/10.3390/info11020125
APA StyleBuslaev, A., Iglovikov, V. I., Khvedchenya, E., Parinov, A., Druzhinin, M., & Kalinin, A. A. (2020). Albumentations: Fast and Flexible Image Augmentations. Information, 11(2), 125. https://doi.org/10.3390/info11020125