Towards Language Service Creation and Customization for Low-Resource Languages


Abstract
:1. Introduction
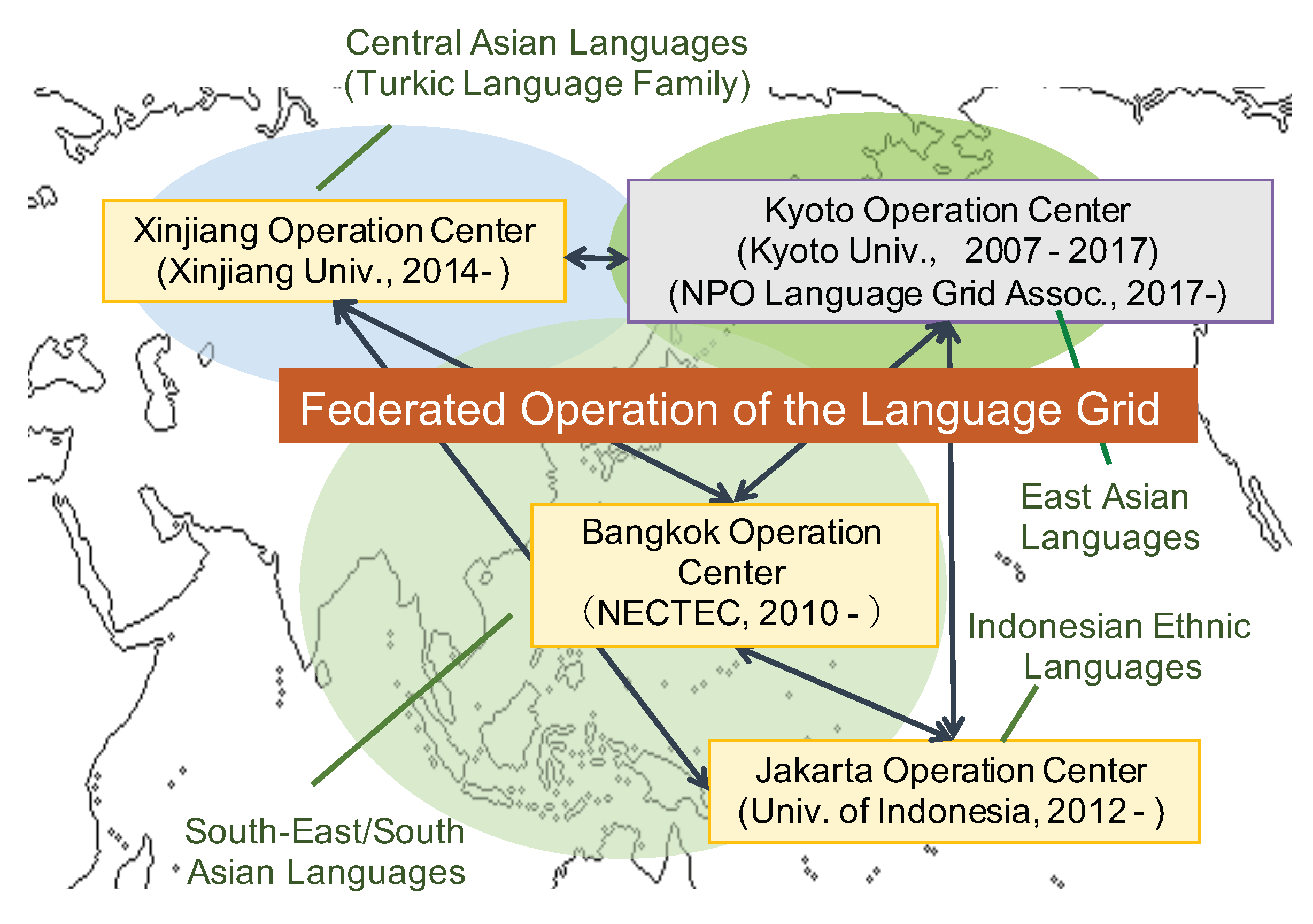
- We analyze the applicability of the Language Grid to low-resource languages. To enhance the sharing of low-resource language services, we established the federated operation of the Language Grid with three organizations in Bangkok, Jakarta, and Urumqi. As a result, the three federated operation centers have shared 49 language services, most of which are for low-resource languages, including southeast Asian languages, Indonesian languages, and Turkic languages. We confirm the potential of the Language Grid for low-resource language service sharing and show the necessity of enhancing language service creation by providing a general framework.
- We propose how to realize the framework based on the design concepts of automation and customization of language resource creation for low-resource languages. We then detail the requirements for the four service layers (service grid, atomic services, composite services, and application systems) in the proposed framework.
- We illustrate our proposed language service framework using a real-world case study of automating and customizing pivot-based bilingual dictionary induction services for low-resource Turkic languages and ethnic Indonesian languages.
2. Language Service Infrastructure: The Language Grid
- <translate> interface class: Translation, TranslationWithTemporalDictionary, BackTranslation, MultihopTranslation
- <search> interface class: BilingualDictionary, BilingualDictionaryWithLongestMatchSearch, ConceptDictionary, DialogCorpus, ParallelText, PictogramDictionary
- <parse> interface class: DependencyParse
- <identify> interface class: LanguageIdentification
- <analyze> interface class: MorphologicalAnalysis
- <tag> interface class: NamedEntityTagging
- <recognize> interface class: SpeechRecognition
- <speak> interface class: TextToSpeech
- <paraphrase> interface class: Paraphrase
- <calculate> interface class: SimilarityCalculation
3. Applicability of the Language Grid to Low-Resource Languages
4. Language Service Creation and Customization for Low-Resource Languages
4.1. Design Concept
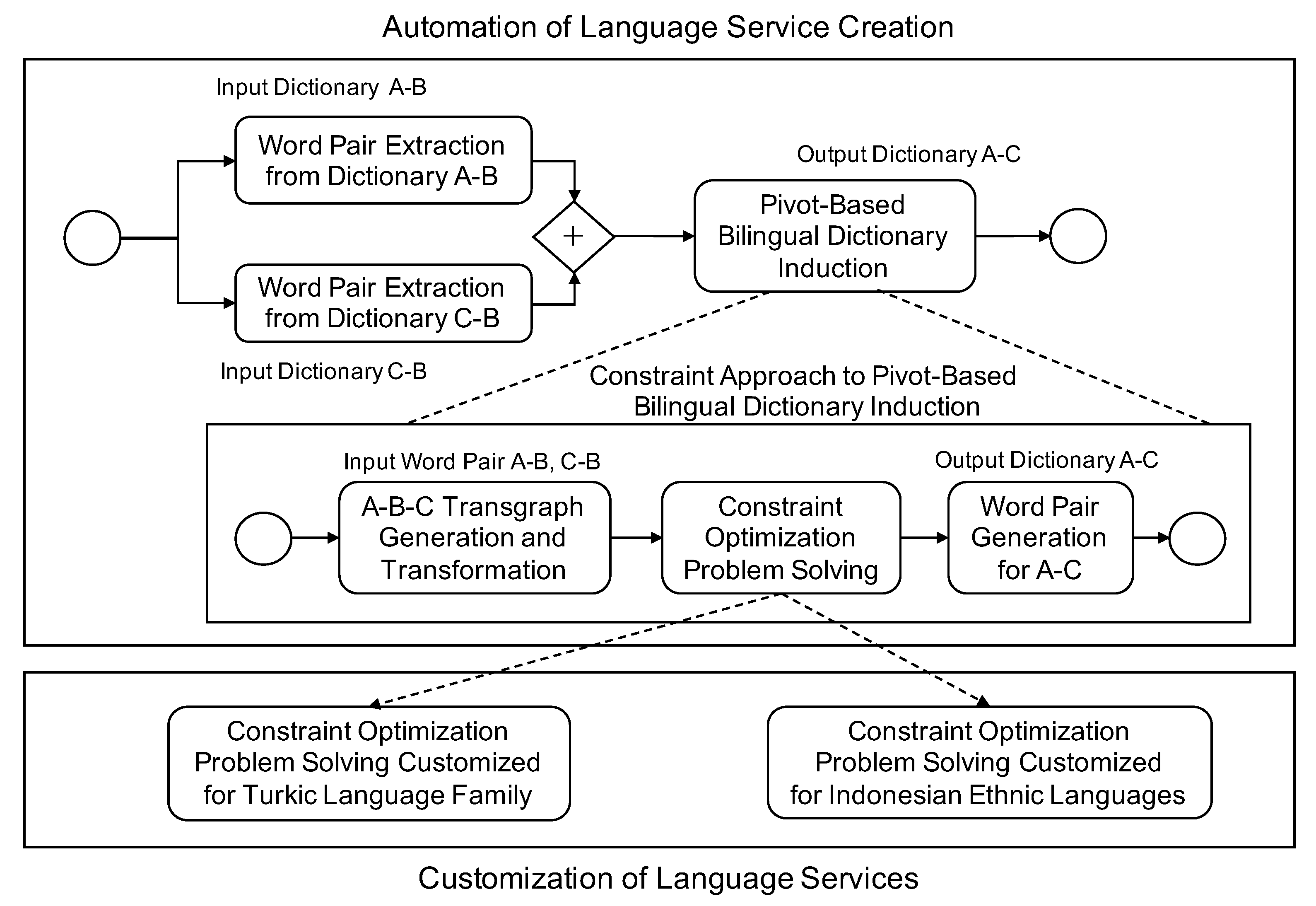
- Automation of low-resource language service creationThe framework must enable the automatic creation of new language resources for low-resource languages from available language resources. For example, Uyghur and Kazakh are two closely-related languages belonging to the Turkic language family, but no comprehensive bilingual dictionary between the two low-resource languages exists. However, the Uyghur–Kazakh bilingual dictionary can be automatically induced from the Chinese–Uyghur and Chinese–Kazakh dictionaries if we develop a pivot-based algorithm that considers language similarity [32,33]. The whole process can be developed as an automated pivot-based dictionary induction service workflow and employed in other comparable situations.
- Customization of low-resource language servicesThe framework must enable the customization of automation processes for language resource creation based on the features of different low-resource languages. Here, we consider an Indonesian ethnic language example which aims at inducing a new Malay–Minangkabau bilingual dictionary from existing Malay–Indonesian and Minangkabau–Indonesian dictionaries [34]. Since the situation is quite similar to the previous example, we can use the same automation process used in the Uyghur–Kazakh dictionary induction. However, the pivot-based algorithm must be customizable, since the second example has a different degree of language similarity.
4.2. Service Layers for Language Service Creation and Customization
5. Case Study: Bilingual Dictionary Induction for Low-Resource Languages
5.1. Automation of Bilingual Dictionary Induction for Turkic Languages
- Constraint 1: A pair of words, (a word i in language A) and (a word j in language C), in a transgraph can be a one-to-one pair candidate if they are connected via at least one pivot word.
- Constraint 2: Given a pair of words, and , in a transgraph, if they are a one-to-one pair, then they should be symmetrically connected through pivot words.
- Constraint 3: Given a pair of words, and , in a transgraph, if they are a one-to-one pair, then they should be unique, such that no other candidates involving and are one-to-one pairs.
- Constraint 4: In a transgraph, at least one one-to-one pair should be extracted.
5.2. Customization of Bilingual Dictionary Induction for Indonesian Ethnic Languages
6. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Nettle, D. Explaining global patterns of language diversity. J. Anthropol. Archaeol. 1998, 17, 354–374. [Google Scholar] [CrossRef] [Green Version]
- List of Wikipedias. Available online: https://meta.wikimedia.org/wiki/List_of_Wikipedias (accessed on 28 November 2019).
- LRE Map. Available online: http://lremap.elra.info (accessed on 28 November 2019).
- Calzolari, N.; Del Gratta, R.; Francopoulo, G.; Mariani, J.; Rubino, F.; Russo, I.; Soria, C. The LRE Map. harmonising community descriptions of resources. In Proceedings of the Eighth International Conference on Language Resources and Evaluation, Istanbul, Turkey, 23–25 May 2012; pp. 1084–1089. [Google Scholar]
- Google Translate. Available online: http://translate.google.com/ (accessed on 28 November 2019).
- Del Gratta, R.; Frontini, F.; Khan, A.F.; Mariani, J.; Soria, C. The LREMap for under-resourced languages. In Proceedings of the Workshop on Collaboration and Computing for Under-Resourced Languages in the Linked Open Data Era, Reykjavik, Iceland, 26 May 2014; p. 78. [Google Scholar]
- Zoph, B.; Yuret, D.; May, J.; Knight, K. Transfer learning for low-resource neural machine translation. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 1568–1575. [Google Scholar]
- Gu, J.; Hassan, H.; Devlin, J.; Li, V.O. Universal neural machine translation for extremely low resource languages. In Proceedings of the 2018 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long Papers), New Orleans, LA, USA, 1–6 June 2018; pp. 344–354. [Google Scholar]
- Tiedemann, J. Character-based pivot translation for under-resourced languages and domains. In Proceedings of the 13th Conference of the European Chapter of the Association for Computational Linguistics, Avignon, France, 23–27 April 2012; Association for Computational Linguistics: Stroudsburg, PA, USA, 2012; pp. 141–151. [Google Scholar]
- Farhath, F.; Theivendiram, P.; Ranathunga, S.; Jayasena, S.; Dias, G. Improving domain-specific SMT for low-resourced languages using data from different domains. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation, Miyazaki, Japan, 7–12 May 2018; pp. 3789–3794. [Google Scholar]
- Honnet, P.E.; Popescu-Belis, A.; Musat, C.; Baeriswyl, M. Machine translation of low-resource spoken dialects: Strategies for normalizing Swiss German. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation, Miyazaki, Japan, 7–12 May 2018; pp. 3781–3788. [Google Scholar]
- Alonso, H.M.; Schluter, N.; Søgaard, A. Multilingual projection for parsing truly low-resource languages. Trans. Assoc. Comput. Linguist. 2016, 4, 301–312. [Google Scholar]
- Garrette, D.; Mielens, J.; Baldridge, J. Real-world semi-supervised learning of POS-taggers for low-resource languages. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics, Volume 1 (Long Papers), Sofia, Bulgaria, 4–9 August 2013; pp. 583–592. [Google Scholar]
- Duong, L.; Cohn, T.; Bird, S.; Cook, P. A neural network model for low-resource universal dependency parsing. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 339–348. [Google Scholar]
- Lim, K.; Partanen, N.; Poibeau, T. Multilingual dependency parsing for low-resource languages: Case studies on North Saami and Komi-Zyrian. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation, Miyazaki, Japan, 7–12 May 2018; pp. 2230–2235. [Google Scholar]
- Gales, M.J.; Knill, K.M.; Ragni, A.; Rath, S.P. Speech recognition and keyword spotting for low-resource languages: BABEL project research at CUED. In Proceedings of the Workshop on Spoken Language Technologies for Under-Resourced Languages, St. Petersburg, Russia, 14–16 May 2014. [Google Scholar]
- Wang, H.; Ragni, A.; Gales, M.; Knill, K.; Woodland, P.; Zhang, C. Joint decoding of tandem and hybrid systems for improved keyword spotting on low resource languages. In Proceedings of the 16th Annual Conference of the International Speech Communication Association, Dresden, Germany, 6–10 September 2015; pp. 3660–3664. [Google Scholar]
- Adams, O.; Makarucha, A.; Neubig, G.; Bird, S.; Cohn, T. Cross-lingual word embeddings for low-resource language modeling. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics: Volume 1 (Long Papers), Valencia, Spain, 3–7 April 2017; pp. 937–947. [Google Scholar]
- Andrews, N.; Dredze, M.; Van Durme, B.; Eisner, J. Bayesian modeling of lexical resources for low-resource settings. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics: Volume 1 (Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 1029–1039. [Google Scholar]
- Irvine, A.; Klementiev, A. Using Mechanical Turk to annotate lexicons for less commonly used languages. In Proceedings of the NAACL HLT 2010 Workshop on Creating Speech and Language Data with Amazon’s Mechanical Turk, Los Angeles, CA, USA, 6 June 2010; Association for Computational Linguistics: Stroudsburg, PA, USA, 2010; pp. 108–113. [Google Scholar]
- De Vries, N.J.; Davel, M.H.; Badenhorst, J.; Basson, W.D.; De Wet, F.; Barnard, E.; De Waal, A. A smartphone- based ASR data collection tool for under-resourced languages. Speech Commun. 2014, 56, 119–131. [Google Scholar] [CrossRef]
- Fraisse, A.; Jenn, R.; Fishkin, S.F. Building multilingual parallel corpora for under-resourced languages using translated fictional texts. In Proceedings of the 3rd Workshop on Collaboration and Computing for Under-Resourced Languages: Sustaining Knowledge Diversity in the Digital Age, Miyazaki, Japan, 12 May 2018; pp. 39–43. [Google Scholar]
- Fraisse, A.; Zhang, Z.; Zhai, A.; Jenn, R.; Fisher Fishkin, S.; Zweigenbaum, P.; Favier, L.; Mustafa El Hadi, W. A sustainable and open access knowledge organization model to preserve cultural heritage and language diversity. Information 2019, 10, 303. [Google Scholar] [CrossRef] [Green Version]
- Ishida, T. The Language Grid: Service-Oriented Collective Intelligence for Language Resource Interoperability; Springer: Berlin, Germany, 2011. [Google Scholar]
- Murakami, Y.; Lin, D.; Ishida, T. Services Computing for Language Resources; Springer: Singapore, 2018. [Google Scholar]
- Murakami, Y.; Lin, D.; Tanaka, M.; Nakaguchi, T.; Ishida, T. Service Grid architecture. In The Language Grid: Service-oriented Collective Intelligence for Language Resource Interoperability; Springer: Berlin/Heidelberg, Germany, 2011; pp. 19–34. [Google Scholar]
- Ishida, T.; Murakami, Y.; Lin, D.; Nakaguchi, T.; Otani, M. Language service infrastructure on the Web: The Language Grid. Computer 2018, 51, 72–81. [Google Scholar] [CrossRef]
- Ishida, T.; Murakami, Y.; Lin, D. The Language Grid: Service-oriented approach to sharing language resources. In The Language Grid: Service-Oriented Collective Intelligence for Language Resource Interoperability; Springer: Berlin, Germany, 2011; pp. 3–17. [Google Scholar]
- Lin, D.; Murakami, Y.; Ishida, T. A framework for multi-language service design with the Language Grid. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation, Miyazaki, Japan, 7–12 May 2018; pp. 3276–3281. [Google Scholar]
- Murakami, Y.; Lin, D.; Ishida, T. Service-oriented architecture for interoperability of multilanguage services. In Towards the Multilingual Semantic Web; Springer: Berlin/Heidelberg, Germany, 2014; pp. 313–328. [Google Scholar]
- Murakami, Y.; Nakaguchi, T.; Lin, D.; Ishida, T. Federated grid architecture for language services. In Services Computing for Language Resources; Springer: Singapore, 2018; pp. 3–20. [Google Scholar]
- Wushouer, M.; Ishida, T.; Lin, D. A heuristic framework for pivot-based bilingual dictionary induction. In Proceedings of the 2013 International Conference on Culture and Computing, Kyoto, Japan, 16–18 September 2013; pp. 111–116. [Google Scholar]
- Wushouer, M.; Ishida, T.; Lin, D.; Hirayama, K. Bilingual dictionary induction as an optimization problem. In Proceedings of the Ninth International Conference on Language Resources and Evaluation, Reykjavik, Iceland, 26–31 May 2014; pp. 2122–2129. [Google Scholar]
- Nasution, A.H.; Murakami, Y.; Ishida, T. A generalized constraint approach to bilingual dictionary induction for low-resource language families. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2018, 17, 9. [Google Scholar] [CrossRef]
- Kaji, H.; Tamamura, S.; Erdenebat, D. Automatic construction of a Japanese-Chinese dictionary via English. In Proceedings of the Sixth International Conference on Language Resources and Evaluation, Marrakech, Morocco, 28–30 May 2008; pp. 699–706. [Google Scholar]
- Bond, F.; Ogura, K. Combining linguistic resources to create a machine-tractable Japanese-Malay dictionary. Lang. Resour. Eval. 2008, 42, 127–136. [Google Scholar] [CrossRef] [Green Version]
- István, V.; Shoichi, Y. Bilingual dictionary generation for low-resourced language pairs. In Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing, Singapore, 6–7 August 2009; Association for Computational Linguistics: Stroudsburg, PA, USA, 2009; Volume 2, pp. 862–870. [Google Scholar]
- Tanaka, K.; Umemura, K. Construction of a bilingual dictionary intermediated by a third language. In Proceedings of the 15th Conference on Computational Linguistics, Kyoto, Japan, 5–9 August 1994; Association for Computational Linguistics: Stroudsburg, PA, USA, 1994; Volume 1, pp. 297–303. [Google Scholar]
- Mann, G.S.; Yarowsky, D. Multipath translation lexicon induction via bridge languages. In Proceedings of the Second Meeting of the North American Chapter of the Association for Computational Linguistics on Language Technologies, Pittsburgh, PA, USA, 2–7 June 2001; Association for Computational Linguistics: Stroudsburg, PA, USA, 2001; pp. 1–8. [Google Scholar]
- Tanaka, R.; Murakami, Y.; Ishida, T. Context-based approach for pivot translation services. In Proceedings of the 21st International Joint Conference on Artificial intelligence, Pasadena, CA, USA, 11–17 July 2009; pp. 1555–1561. [Google Scholar]
- Matsuno, J.; Ishida, T. Constraint optimization approach to context based word selection. In Proceedings of the 22nd International Joint Conference on Artificial Intelligence, Barcelona, Spain, 16–22 July 2011; pp. 1846–1851. [Google Scholar]
- Wushouer, M.; Lin, D.; Ishida, T.; Hirayama, K. Pivot-based bilingual dictionary extraction from multiple dictionary resources. In 2014 Pacific Rim International Conference on Artificial Intelligence; Springer: Cham, Switzerland, 2014; pp. 221–234. [Google Scholar]
- Wushouer, M.; Lin, D.; Ishida, T.; Hirayama, K. A constraint approach to pivot-based bilingual dictionary induction. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2016, 15, 4. [Google Scholar] [CrossRef]
- Murakami, Y. Indonesia Language Sphere: An ecosystem for dictionary development for low-resource languages. J. Phys. Conf. Ser. 2019, 1192, 012001. [Google Scholar] [CrossRef]
- Nasution, A.H.; Murakami, Y.; Ishida, T. Designing a collaborative process to create bilingual dictionaries of Indonesian ethnic languages. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation, Miyazaki, Japan, 7–12 May 2018; pp. 3397–3404. [Google Scholar]



{kind=link}
{kind=link}
| Interface Method | String Translate (Language SourceLang, Language TargetLang, String Source) |
|---|---|
| Parameters | sourceLang: The source language targetLang: The target language source: The string to be translated |
| Return value | The translation result will be returned. |
| Description | The <translate> interface class is standardized for invoking a translation service in the Language Grid, following the translation setting identified by three parameters: The source language, the target language, and the string to be translated. The <translate> interface class can be used to invoke an atomic translation service when specified with the service endpoint URL for atomic translation (e.g., Translation), or a composite translation service when specified with the service endpoint URL for composite translation (e.g., TranslationWithTemporalDictionary). |
| Service endpoint examples | Examples of the service endpoint of Translation: GoogleTranslate and KyotoUJserver. https://langrid.org/service_manager/wsdl/kyoto1.langrid:GoogleTranslate https://langrid.org/service_manager/wsdl/kyoto1.langrid:KyotoUJServer An example of the service endpoint of TranslationWithTemporalDictionary. https://langrid.org/service_manager/wsdl/kyoto1.langrid:TranslationCombinedWithBilingualDictionary |
| Operation Center | Registered Language Services (Selected List) |
|---|---|
| Bangkok Language Grid Operation Center | Translation: ASEANMT (Indonesian–English), English–Tagalog Translation, ASEAN Machine Translation (English–Chinese, Brunei–English, English–Khmer, English–Laotian, Malaysia–English), Thai–Laotian Machine Translation, Parsit (English–Thai Machine Translation) ConceptDictionary: Asian WordNet (Bengali, Hindi, Indonesian, Japanese, Korean, Laotian, Mongolian, Burmese, Nepali, Singhalese, Sudanese, Thai, Vietnamese) LanguageIdentification: Data Extraction (Thai) PictogramDictionary: Thai Weaving Pattern with Impression TextToSpeech: Vaja6 API TTS (Thai, English) MorphologicalAnalysis: LexTo Word Segmentation (Thai) BilingualDictionary: LEXiTRON Bilingual Dictionary Service (English–Thai) |
| Jakarta Language Grid Operation Center | Translation: Indonesian–English Translation MorphologicalAnalysis: Indonesian Morphological Analysis, Indonesian POS Tagger SpeechRecognition: Indonesian Speech Recognition |
| Urumqi Language Grid Operation Center | Translation: Uyghur–Chinese Translator ParallelText: Kazakh–Chinese, Kyrgyz–Chinese, Uyghur–Chinese Parallel Text BilingualDictionary: Uyghur–Chinese Technological Terms Dictionary, Bilingual Dictionary (Kazakh–Chinese, Kyrgyz–Chinese, Uyghur–Chinese), Turkic Multilingual Dictionary (English, Turkmen, Uyghur, Kyrgyz, Kazakh, Turkish, Chinese, Azerbaijani, Uzbek, Tatar), Uyghur–Turkish–Chinese Dictionary |
| Service Layer | Description |
|---|---|
| Bottom Layer (Service Grid) | The service grid manages the requests to the infrastructure and invokes language services. In the context of low-resource language services, since it is difficult for one single organization or a small group of organizations to provide enough resources and services, the service grid must be realized in a distributed manner and must enable the coordination of interconnections of grids operated by different organizations. |
| Second Layer (Atomic Services) | In this layer, users create and register language services by wrapping language resources based on the service interface types. In the Language Grid, we have already defined over 20 types of standardized service interfaces. However, we need to deal with service interoperability if we consider a distributed service grid for low-resource languages, since different operators may have their own policies of providing services and the service ontology definitions. |
| Third Layer (Composite Services) | In the composite service layer, users create and use service workflows for realizing complicated functions like the example described in Figure 2. Due to the variety of the features exhibited by low-resource languages, the infrastructure must provide composite services with various granularities so that the users can make decisions on how to best balance the automation and customization for language service creation. |
| Top Layer (Application Systems) | In the application system layer, multilingual applications and intercultural collaboration tools for low-resource languages are developed by utilizing the composite services and provided to end-users. The usage of the composite services can be regarded as an evaluation method for the services provided through the infrastructure. The feedback from the real world can be used to improve existing composite services and design new services for low-resource languages. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, D.; Murakami, Y.; Ishida, T. Towards Language Service Creation and Customization for Low-Resource Languages. Information 2020, 11, 67. https://doi.org/10.3390/info11020067
Lin D, Murakami Y, Ishida T. Towards Language Service Creation and Customization for Low-Resource Languages. Information. 2020; 11(2):67. https://doi.org/10.3390/info11020067
Chicago/Turabian StyleLin, Donghui, Yohei Murakami, and Toru Ishida. 2020. "Towards Language Service Creation and Customization for Low-Resource Languages" Information 11, no. 2: 67. https://doi.org/10.3390/info11020067
APA StyleLin, D., Murakami, Y., & Ishida, T. (2020). Towards Language Service Creation and Customization for Low-Resource Languages. Information, 11(2), 67. https://doi.org/10.3390/info11020067