Web Radio Automation for Audio Stream Management in the Era of Big Data




Abstract
1. Introduction
1.1. Radio in an Evolving Ecosystem
1.2. Big Audio Data
1.3. Speaker Diarization
1.4. Research Aims
2. Materials and Methods
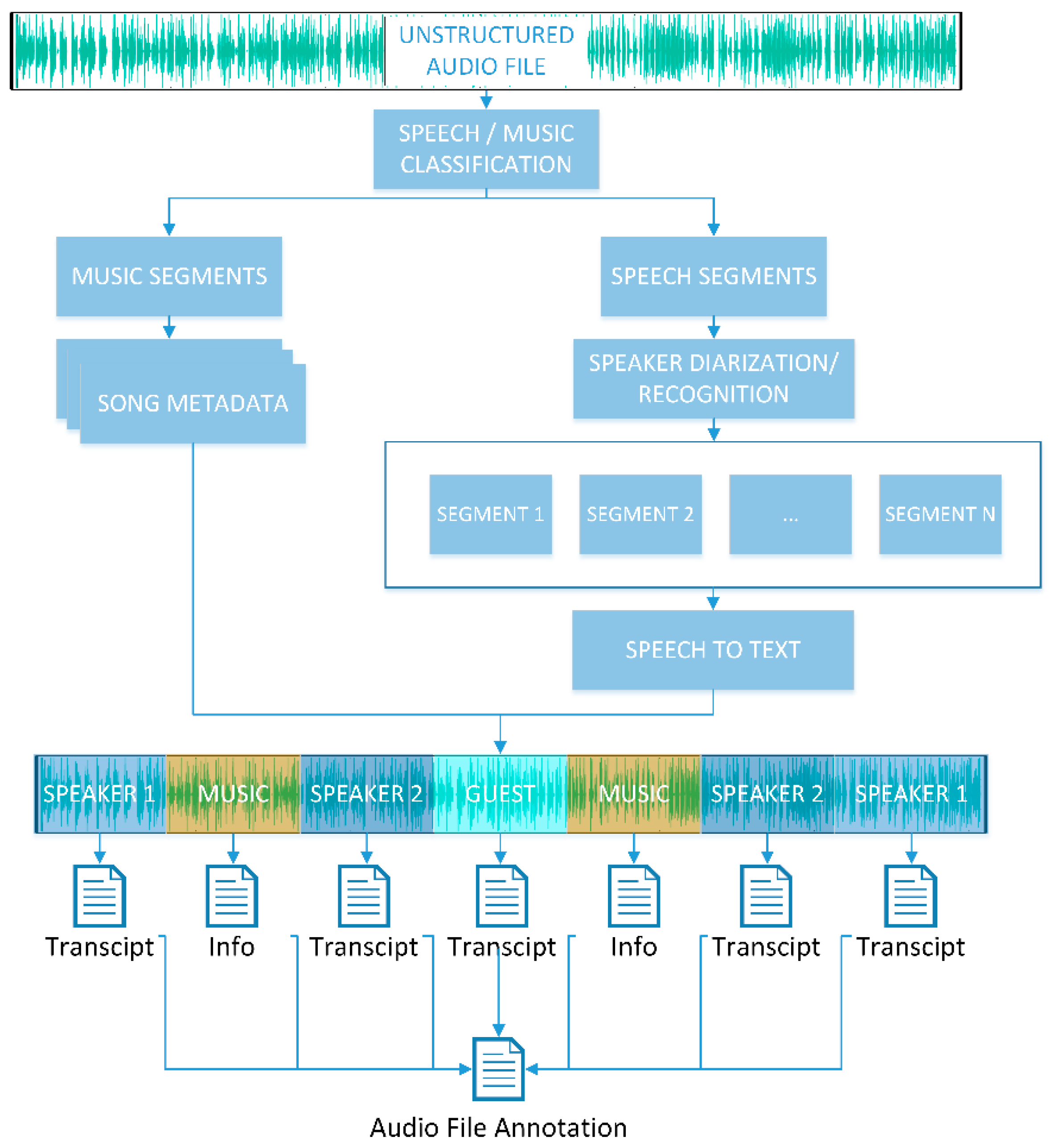
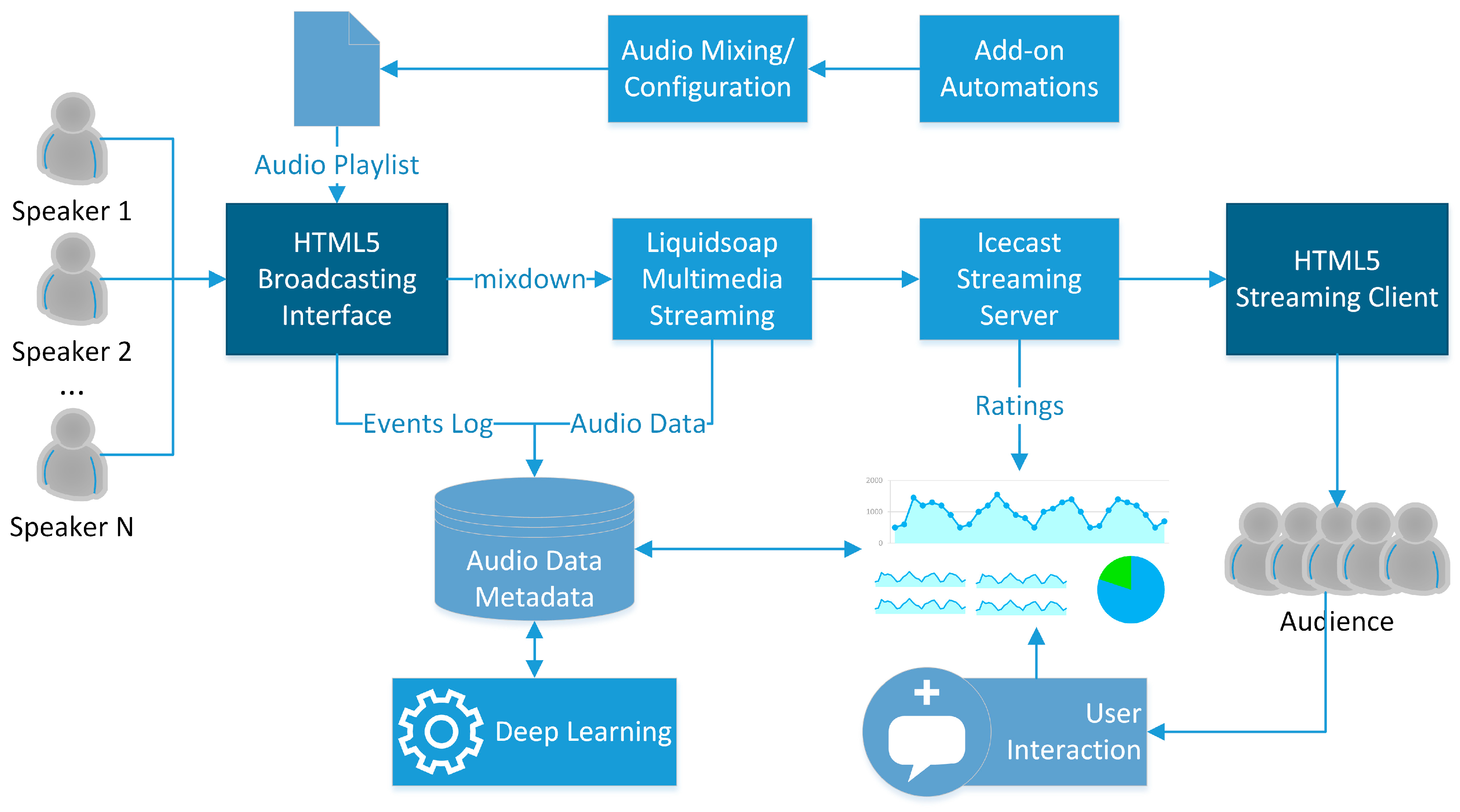
2.1. A Framework for Knowledge Extraction from Radio Content
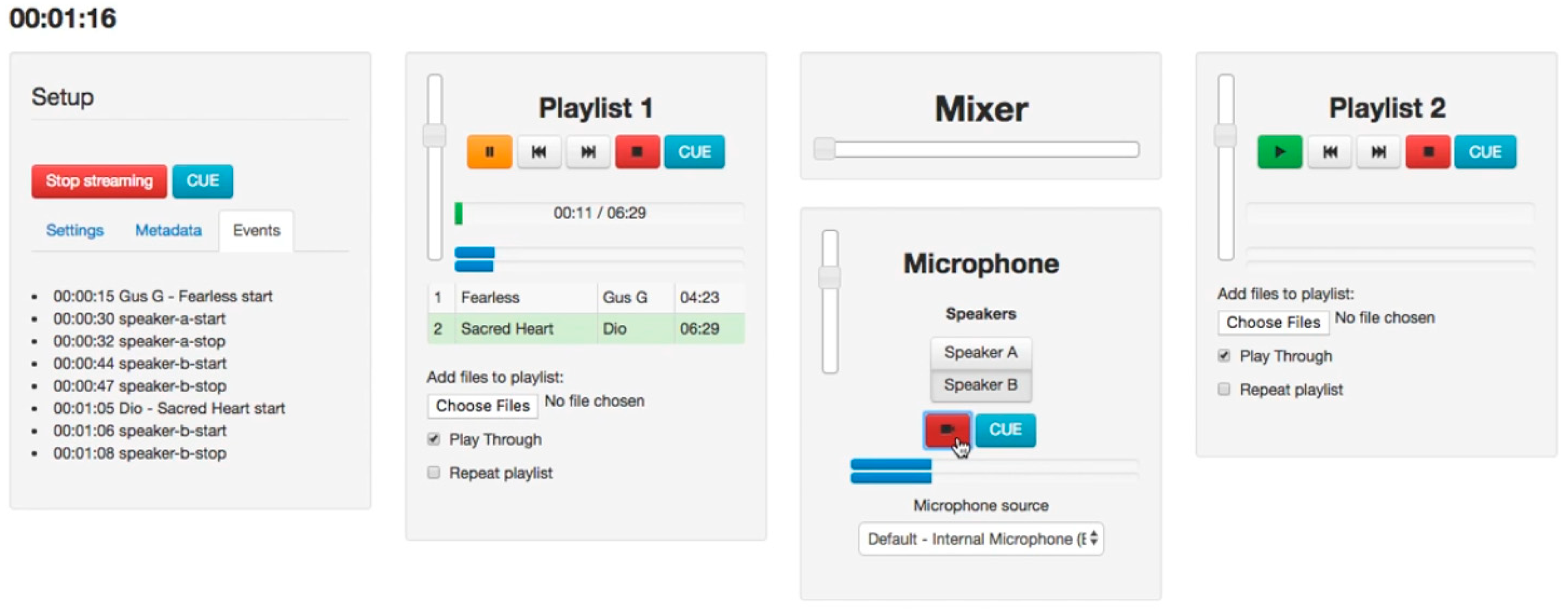
2.2. A Web Application for Live Radio Production and Annotation
2.3. Speaker Recognition with Convolutional Neural Networks
- Background Noise: Additive Gaussian White Noise (AGWN) was added to the existing audio files. This technique doubles the number of files used for training and helps generalization in noisy conditions.
- Dynamic Range: The audio files provided in the RAVDNESS database are not normalized. Machine learning models are vulnerable to overfitting to energy characteristics. In the training session, we used the existing audio files as well as normalized versions of them. This aims at making recognition performance robust to energy fluctuations, e.g., with the speaker moving farther and closer to the mic.
- Time Shift: Time shifting of audio segments is achieved by extracting features from heavily overlapping windows to increase the instances. This is similar to the different image cropping data augmentation technique that has been popularized in visual object detection. In our approach, 90% overlapping between successive observation windows was chosen.
2.4. Speaker Diarization
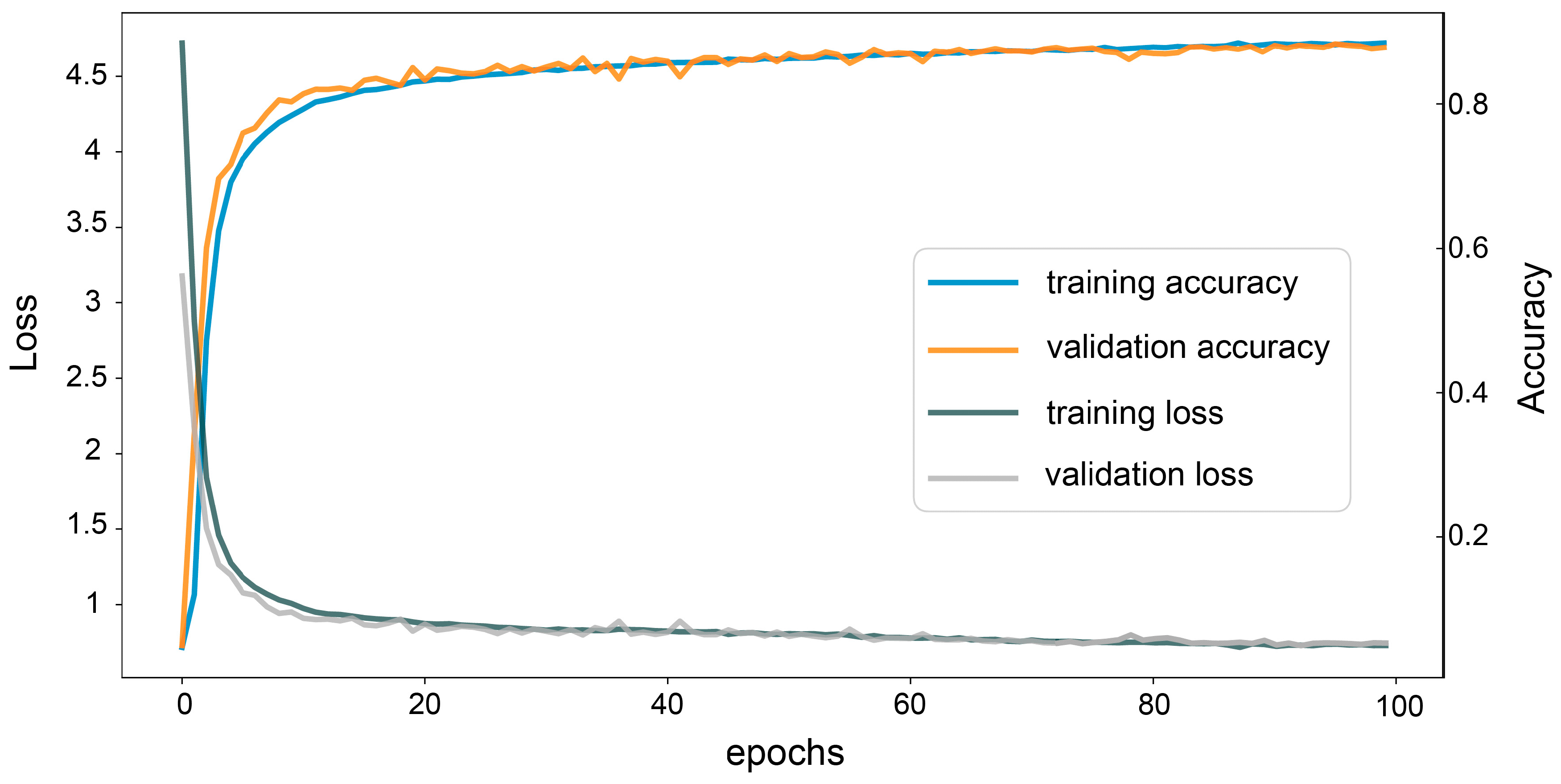
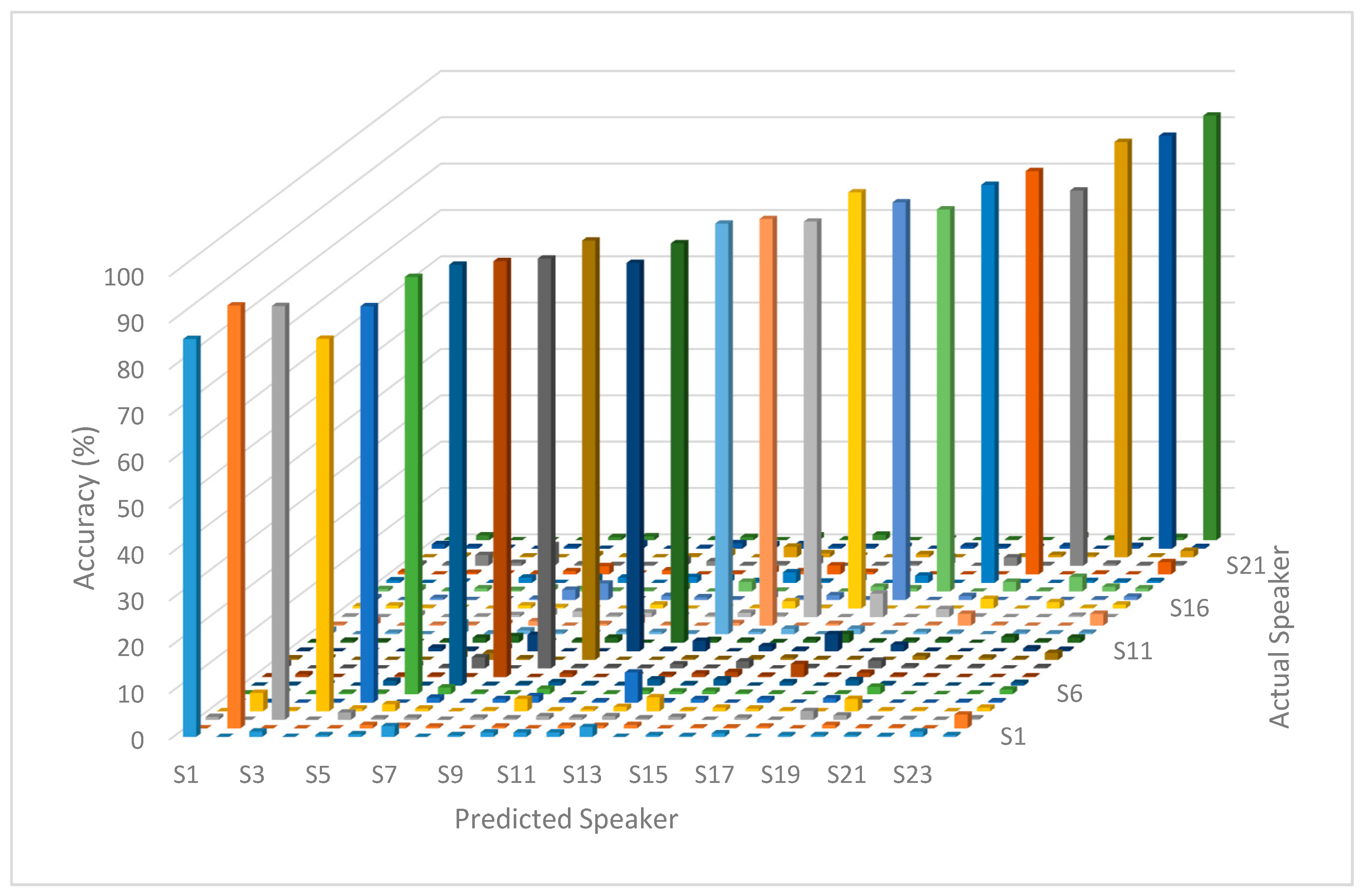
3. Results
4. Discussion
4.1. Conclusions
4.2. Limitations and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Kotsakis, R.; Kalliris, G.; Dimoulas, C. Investigation of broadcast-audio semantic analysis scenarios employing radio-programme-adaptive pattern classification. Speech Commun. 2012, 54, 743–762. [Google Scholar] [CrossRef]
- Kotsakis, R.; Kalliris, G.; Dimoulas, C. Investigation of salient audio-features for pattern-based semantic content analysis of radio productions. In Proceedings of the Audio Engineering Society Convention 132, Budapest, Hungary, 26–29 April 2012. [Google Scholar]
- Tsipas, N.; Vrysis, L.; Dimoulas, C; Papanikolaou, G. Efficient audio-driven multimedia indexing through similarity-based speech /music discrimination. Multimed. Tools Appl. 2017, 76, 25603–25621. [Google Scholar] [CrossRef]
- Dimoulas, C.A.; Symeonidis, A.L. Syncing Shared Multimedia through Audiovisual Bimodal Segmentation. IEEE Multimed. 2015, 22, 26–42. [Google Scholar] [CrossRef]
- Lopez-Otero, P.; Docio-Fernandez, L.; Garcia-Mateo, C. Ensemble audio segmentation for radio and television programmes. Multimed. Tools Appl. 2017, 76, 7421–7444. [Google Scholar] [CrossRef]
- Weerathunga, C.O.B.; Jayaratne, K.L.; Gunawardana, P.V.K.G. Classification of Public Radio Broadcast Context for Onset Detection. KL Jayaratne-GSTF J. Comput. (JoC) 2018, 7, 1–22. [Google Scholar]
- Yang, X.K.; Qu, D.; Zhang, W.L.; Zhang, W.Q. An adapted data selection for deep learning-based audio segmentation in multi-genre broadcast channel. Digit. Signal Process. 2018, 81, 8–15. [Google Scholar] [CrossRef]
- Dimoulas, C. Machine Learning. In The SAGE Encyclopedia of Surveillance, Security, and Privacy; Arrigo, B.A., Ed.; Sage Publications Inc.: California, CA, USA, 2018; pp. 591–592. [Google Scholar] [CrossRef]
- Vrysis, L.; Tsipas, N.; Dimoulas, C.; Papanikolaou, G. Crowdsourcing audio semantics by means of hybrid bimodal segmentation with hierarchical classification. J. Audio Eng. Soc. 2016, 64, 1042–1054. [Google Scholar] [CrossRef]
- Tsipas, N.; Vrysis, L.; Dimoulas, C.; Papanikolaou, G. Content-Based Music Structure Analysis using Vector Quantization. In Proceedings of the 138th AES Convention, Warsow, Poland, 7–10 May 2015. [Google Scholar]
- Tsipas, N.; Dimoulas, C.; Kalliris, G.; Papanikolaou, G. Collaborative annotation platform for audio semantics. In Proceedings of the 134th AES Convention, Rome, Italy, 4–7 May 2013; pp. 218–222. [Google Scholar]
- Baume, C.; Plumbley, M.; Frohlich, D.; Calic, J. PaperClip: A digital pen interface for semantic speech editing in radio production. J. Audio Eng. Soc. 2018, 66, 241–252. [Google Scholar] [CrossRef]
- Baume, C.; Plumbley, M.D.; Ćalić, J.; Frohlich, D. A Contextual Study of Semantic Speech Editing in Radio Production. Int. J. Hum.-Comput. Stud. 2018, 115, 67–80. [Google Scholar] [CrossRef]
- Jauert, P.; Ala-Fossi, M.; Föllmer, G.; Lax, S.; Murphy, K. The future of radio revisited: Expert perspectives and future scenarios for radio media in 2025. J. Radio Audio Media 2017, 24, 7–27. [Google Scholar] [CrossRef]
- Berry, R. Part of the establishment: Reflecting on 10 years of podcasting as an audio medium. Convergence 2016, 22, 661–671. [Google Scholar] [CrossRef]
- Mensing, D. Public radio at a crossroads: Emerging trends in US public media. J. Radio Audio Media 2017, 24, 238–250. [Google Scholar] [CrossRef]
- Edmond, M. All platforms considered: Contemporary radio and transmedia engagement. New Media Soc. 2015, 17, 1566–1582. [Google Scholar] [CrossRef]
- McHugh, S. How podcasting is changing the audio storytelling genre. Radio J.: Int. Stud. Broadcast Audio Media 2016, 14, 65–82. [Google Scholar] [CrossRef]
- Berry, R. Podcasting: Considering the evolution of the medium and its association with the word ‘radio’. Radio J.: Int. Stud. Broadcast Audio Media 2016, 14, 7–22. [Google Scholar] [CrossRef]
- Jędrzejewski, S. Radio in the new media environment. In Radio: Resilient Medium; Oliveira, M., Stachyra, G., Starkey, G., Eds.; Sunderland: Centre for Research in Media and Cultural Studies: London, UK, 2014; Volume 1, pp. 17–26. [Google Scholar]
- Uddin, M.F.; Gupta, N. Seven V’s of Big Data understanding Big Data to extract value. In Proceedings of the 2014 Zone 1 Conference of the American Society for Engineering Education, Bridgeport, CT, USA, 3–5 April 2014; pp. 1–5. [Google Scholar]
- O’Leary, D.E. Artificial intelligence and big data. IEEE Intell. Syst. 2013, 28, 96–99. [Google Scholar] [CrossRef]
- Sagiroglu, S.; Sinanc, D. Big data: A review. In Proceedings of the 2013 International Conference on Collaboration Technologies and Systems (CTS), San Diego, CA, USA, 20–24 May 2013; pp. 42–47. [Google Scholar]
- Gandomi, A.; Haider, M. Beyond the hype: Big data concepts, methods, and analytics. Int. J. Inf. Manag. 2015, 35, 137–144. [Google Scholar] [CrossRef]
- Barnaghi, P.; Sheth, A.; Henson, C. From data to actionable knowledge: Big data challenges in the web of things [Guest Editors’ Introduction]. IEEE Intell. Syst. 2013, 28, 6–11. [Google Scholar] [CrossRef]
- Han, Q.; Liang, S.; Zhang, H. Mobile cloud sensing, big data, and 5G networks make an intelligent and smart world. IEEE Netw. 2015, 29, 40–45. [Google Scholar] [CrossRef]
- Chandarana, P.; Vijayalakshmi, M. Big data analytics frameworks. In Proceedings of the 2014 International Conference on Circuits, Systems, Communication and Information Technology Applications (CSCITA), Mumbai, India, 4–5 April 2014; pp. 430–434. [Google Scholar]
- Qiu, J.; Wu, Q.; Ding, G.; Xu, Y.; Feng, S. A survey of machine learning for big data processing. EURASIP J. Adv. Signal Process. 2016, 2016, 67. [Google Scholar] [CrossRef]
- Najafabadi, M.M.; Villanustre, F.; Khoshgoftaar, T. M.; Seliya, N.; Wald, R.; Muharemagic, E. Deep learning applications and challenges in big data analytics. J. Big Data 2015, 2, 1. [Google Scholar] [CrossRef]
- Anguera, X.; Bozonnet, S.; Evans, N.; Fredouille, C.; Friedland, G.; Vinyals, O. Speaker diarization: A review of recent research. IEEE Trans. Audio Speech Lang. Process. 2012, 20, 356–370. [Google Scholar] [CrossRef]
- Moattar, M.H.; Homayounpour, M.M. A review on speaker diarization systems and approaches. Speech Commun. 2012, 54, 1065–1103. [Google Scholar] [CrossRef]
- Rouvier, M.; Dupuy, G.; Gay, P.; Khoury, E.; Merlin, T.; Meignier, S. An open-source state-of-the-art toolbox for broadcast news diarization. In Proceedings of the Interspeech, Lyon, France, 25–29 August 2013. [Google Scholar]
- Shum, S.; Dehak, N.; Glass, J. On the use of spectral and iterative methods for speaker diarization. In Proceedings of the Thirteenth Annual Conference of the International Speech Communication Association, Portland, OR, USA, 9–13 September 2012. [Google Scholar]
- Sell, G.; Garcia-Romero, D. Speaker diarization with PLDA i-vector scoring and unsupervised calibration. In Proceedings of the 2014 IEEE Spoken Language Technology Workshop (SLT), South Lake Tahoe, CA, USA, 7 December 2014; pp. 413–417. [Google Scholar]
- Shum, S.H.; Dehak, N.; Dehak, R.; Glass, J.R. Unsupervised methods for speaker diarization: An integrated and iterative approach. IEEE Trans. Audio, Speech Lang. Process. 2013, 21, 2015–2028. [Google Scholar] [CrossRef]
- Rouvier, M.; Meignier, S. A global optimization framework for speaker diarization. In Proceedings of the Odyssey, Singapore, 25–28 June 2012. [Google Scholar]
- Ferras, M.; Boudard, H. Speaker diarization and linking of large corpora. In Proceedings of the 2012 IEEE Spoken Language Technology Workshop (SLT), Miami, FL, USA, 2–5 December 2012; pp. 280–285. [Google Scholar]
- Garcia-Romero, D.; Snyder, D.; Sell, G.; Povey, D.; McCree, A. Speaker diarization using deep neural network embeddings. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 4930–4934. [Google Scholar]
- Snyder, D.; Garcia-Romero, D.; Sell, G.; McCree, A.; Povey, D.; Khudanpur, S. Speaker Recognition for Multi-speaker Conversations Using X-vectors. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 5796–5800. [Google Scholar]
- Yella, S. H.; Stolcke, A.; Slaney, M. Artificial neural network features for speaker diarization. In Proceedings of the 2014 IEEE Spoken Language Technology Workshop (SLT), South Lake Tahoe, CA, USA, 7–10 December 2014; pp. 402–406. [Google Scholar]
- Wang, Q.; Downey, C.; Wan, L.; Mansfield, P.A.; Moreno, I.L. Speaker diarization with lstm. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5239–5243. [Google Scholar]
- Lin, Q.; Yin, R.; Li, M.; Bredin, H.; Barras, C. LSTM based similarity measurement with spectral clustering for speaker diarization. In Proceedings of the Interspeech 2019, Graz, Austria, 15–19 September 2019. [Google Scholar]
- Sun, L.; Du, J.; Gao, T.; Lu, Y. D.; Tsao, Y.; Lee, C. H.; Ryant, N. A novel LSTM-based speech preprocessor for speaker diarization in realistic mismatch conditions. In Proceedings of the 2018 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018; pp. 5234–5238. [Google Scholar]
- Zhang, A.; Wang, Q.; Zhu, Z.; Paisley, J.; Wang, C. Fully supervised speaker diarization. In Proceedings of the ICASSP 2019—2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; pp. 6301–6305. [Google Scholar]
- Hagerer, G.; Pandit, V.; Eyben, F.; Schuller, B. Enhancing lstm rnn-based speech overlap detection by artificially mixed data. In Proceedings of the 2017 AES International Conference on Semantic Audio, Audio Engineering Society, Erlangen, Germany, 22–24 June 2017. [Google Scholar]
- Hrúz, M.; Zajíc, Z. Convolutional neural network for speaker change detection in telephone speaker diarization system. In Proceedings of the 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), New Orleans, LA, USA, 5–9 March 2017; pp. 4945–4949. [Google Scholar]
- Cyrta, P.; Trzciński, T.; Stokowiec, W. Speaker diarization using deep recurrent convolutional neural networks for speaker embeddings. In Proceedings of the International Conference on Information Systems Architecture and Technology, Szklarska Poręba, Poland, 17–19 September 2017; pp. 107–117. [Google Scholar]
- Vrysis, L.; Tsipas, N.; Thoidis, I.; Dimoulas, C. 1D/2D Deep CNNs vs. Temporal Feature Integration for General Audio Classification. J. Audio Eng. Soc. 2020, 68, 66–77. [Google Scholar] [CrossRef]
- Hoeg, W.; Lauterbach, T. Digital Audio Broadcasting; Wiley: Hoboken, NJ, USA, 2003. [Google Scholar]
- Baelde, D.; Beauxis, R.; Mimram, S. Liquidsoap: A high-level programming language for multimedia streaming. In Proceedings of the International Conference on Current Trends in Theory and Practice of Computer Science, Nový Smokovec, Slovakia, 22–28 January 2011; pp. 99–110. [Google Scholar]
- Dengler, B. Creating an internet radio station with icecast and liquidsoap. Linux J. 2017, 280, 1. [Google Scholar]
- Dalakas, A.; Tsipas, N.; Dimoulas, C.; Kalliris, G. Web radio automation and “big data” of audio (and audiovisual) semantic annotation. In Proceedings of the HELINA Conference on Acoustics, Patras, Greece, 8–9 October 2018. [Google Scholar]
- Kotsakis, R.; Dimoulas, C.; Kalliris, G.; Veglis, A. Emotional Prediction and Content Profile Estimation in Evaluating Audiovisual Mediated Communication. Int. J. Monit. Surveill. Technol. Res. (IJMSTR) 2014, 2, 62–80. [Google Scholar] [CrossRef]
- Kalliris, G.; Matsiola, M.; Dimoulas, C.; Veglis, A. Emotional aspects and quality of experience for multifactor evaluation of audiovisual content. Int. J. Monit. Surveill. Technol. Res. (IJMSTR) 2014, 2, 40–61. [Google Scholar] [CrossRef]
- Vryzas, N.; Kotsakis, R.; Liatsou, A.; Dimoulas, C. A.; Kalliris, G. Speech emotion recognition for performance interaction. J. Audio Eng. Soc. 2018, 66, 457–467. [Google Scholar] [CrossRef]
- Vryzas, N.; Vrysis, L.; Matsiola, M.; Kotsakis, R.; Dimoulas, C.; Kalliris, G. Continuous Speech Emotion Recognition with Convolutional Neural Networks. J. Audio Eng. Soc. 2020, 68, 14–24. [Google Scholar] [CrossRef]
- Oxholm, E.; Hansen, E. K.; Triantafyllidis, G. Auditory and Visual based Intelligent Lighting Design for Music Concerts. EAI Endorsed Trans. Creat. Technol. 2018, 5, e2. [Google Scholar] [CrossRef]
- Barthet, M.; Fazekas, G.; Sandler, M. Multidisciplinary perspectives on music emotion recognition: Implications for content and context-based models. In Proceedings of the 9th International Symposium on Computer Music Modeling and Retrieval (CMMR), London, UK, 19–22 June 2012; pp. 492–507. [Google Scholar]
- Livingstone, S.R.; Russo, F.A. The Ryerson Audio-Visual Database of Emotional Speech and Song (RAVDESS): A dynamic, multimodal set of facial and vocal expressions in North American English. PLoS ONE 2018, 13, e0196391. [Google Scholar] [CrossRef] [PubMed]
- Salamon, J.; Bello, J.P. Deep convolutional neural networks and data augmentation for environmental sound classification. IEEE Signal Process. Lett. 2017, 24, 279–283. [Google Scholar] [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the International Conference on Learning Representations (ICLR 2015), San Diego, CA, USA, 7–9 May 2015. [Google Scholar]
- Chollet, F. Keras: The Python Deep Learning Library; Astrophysics Source Code Library (ASCL): Leicester, UK, 2018. [Google Scholar]
- McFee, B.; Raffel, C.; Liang, D.; Ellis, D.P.; McVicar, M.; Battenberg, E.; Nieto, O. Librosa: Audio and music signal analysis in python. In Proceedings of the 14th python in science conference, Austin, TX, USA, 6–12 July 2015. [Google Scholar]
- Steinley, D.; Brusco, M.J. Initializing k-means batch clustering: A critical evaluation of several techniques. J. Classif. 2007, 24, 99–121. [Google Scholar] [CrossRef]
- Murtagh, F.; Legendre, P. Ward’s hierarchical agglomerative clustering method: Which algorithms implement Ward’s criterion? J. Classif. 2014, 31, 274–295. [Google Scholar] [CrossRef]
- Zhang, T.; Ramakrishnan, R.; Livny, M. BIRCH: An efficient data clustering method for very large databases. ACM Sigmod Rec. 1996, 25, 103–114. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Type | Hyperparameters |
|---|---|---|
| 1 | Convolutional 2D Layer | 16 filters Kernel size = (3,3) Strides = (1,1) |
| 2 | Max Pooling 2D Layer | Pool size = (2,2) |
| 3 | Dropout | Rate = 0.25 |
| 4 | Convolutional 2D Layer | 32 filters Kernel size = (3,3) Strides = (1,1) |
| 5 | Max Pooling 2D Layer | Pool size = (2,2) |
| 6 | Dropout | Rate = 0.25 |
| 7 | Convolutional 2D Layer | 64 filters Kernel size = (3,3) Strides = (1,1) |
| 8 | Dropout | Rate = 0.25 |
| 9 | Convolutional 2D Layer | 128 filters Kernel size = (3,3) Strides = (1,1) |
| 10 | Convolutional 2D Layer | 256 filters Kernel size = (3,3) Strides = (1,1) |
| 11 | Flatten Layer | |
| 12 | Dense Neural Network | Output weights = 64 Activation = ReLU L2 regularizer |
| 13 | Dense Neural Network | Output weights = 64 Activation = ReLU |
| 14 | Dropout | Rate = 0.25 |
| 15 | Dense Neural Network | Output weights = 24 Activation = Softmax |
| Clustering Algorithm | Accuracy (%) | ||
|---|---|---|---|
| 2 speakers | 3 speakers | 4 speakers | |
| Agglomerative | 95.98 | 81.7 | 78.12 |
| K-means | 90.4 | 85.83 | 81.81 |
| BIRCH | 96.72 | 87.22 | 82.33 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vryzas, N.; Tsipas, N.; Dimoulas, C. Web Radio Automation for Audio Stream Management in the Era of Big Data. Information 2020, 11, 205. https://doi.org/10.3390/info11040205
Vryzas N, Tsipas N, Dimoulas C. Web Radio Automation for Audio Stream Management in the Era of Big Data. Information. 2020; 11(4):205. https://doi.org/10.3390/info11040205
Chicago/Turabian StyleVryzas, Nikolaos, Nikolaos Tsipas, and Charalampos Dimoulas. 2020. "Web Radio Automation for Audio Stream Management in the Era of Big Data" Information 11, no. 4: 205. https://doi.org/10.3390/info11040205
APA StyleVryzas, N., Tsipas, N., & Dimoulas, C. (2020). Web Radio Automation for Audio Stream Management in the Era of Big Data. Information, 11(4), 205. https://doi.org/10.3390/info11040205