2.1. Problem Definition and Motivation
This paper investigates machine learning techniques and methodologies that will support multilingual semantic analysis of broadcasted content, deriving from European (and world-wide) radio organizations. The current work is an extension of previous/already published research that is continually elaborated [
1,
2,
3,
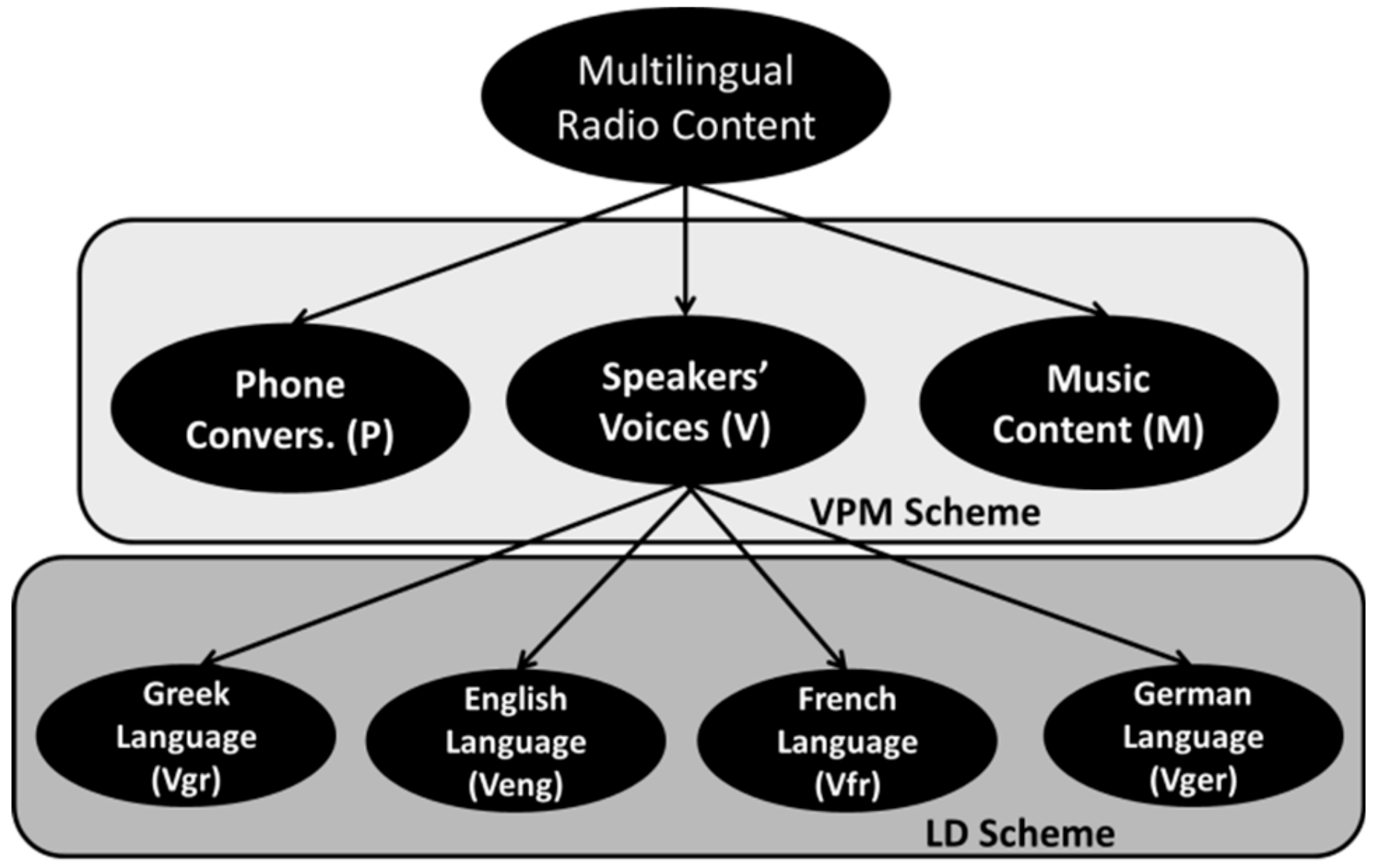
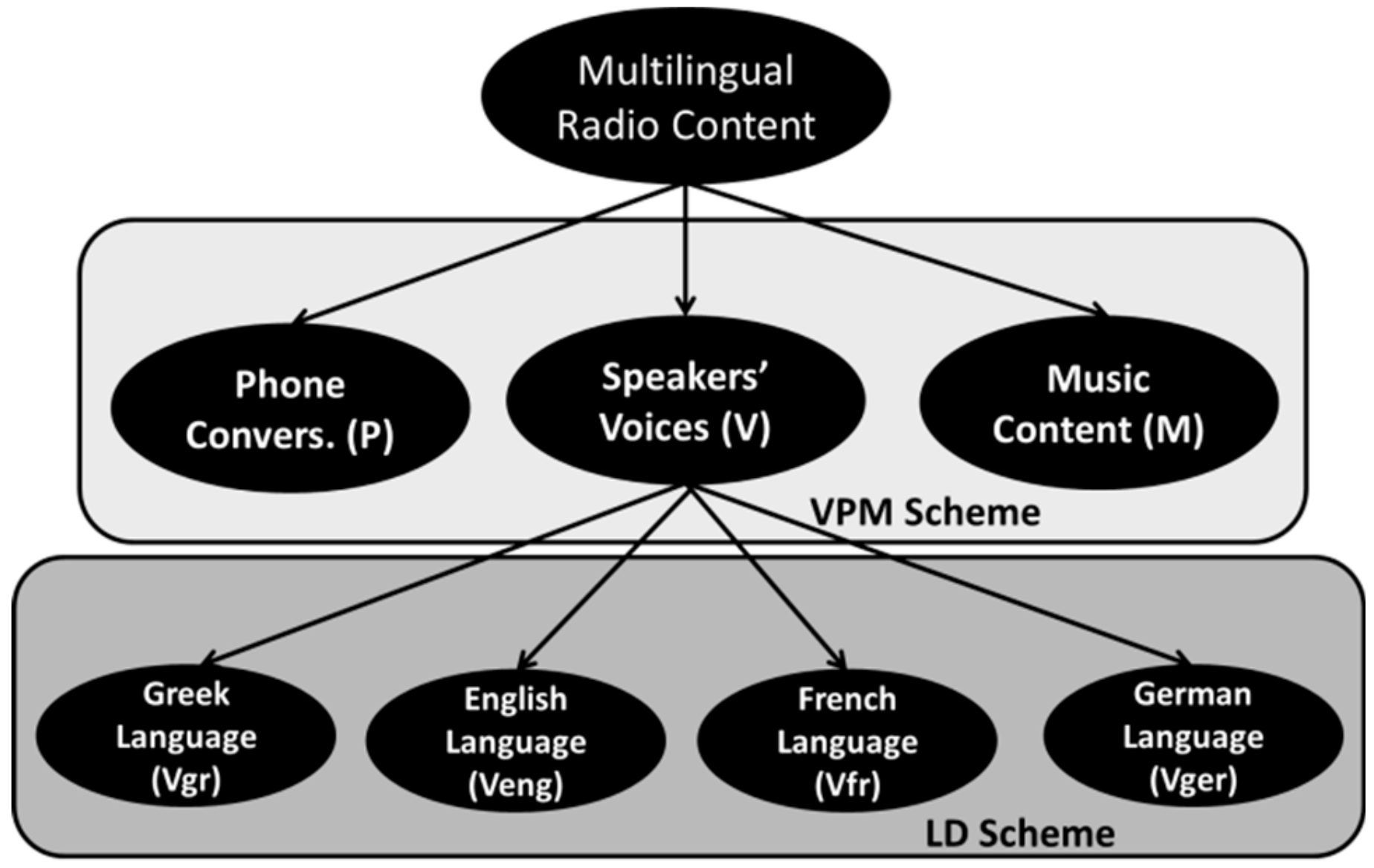
33], aiming at meeting the demands of users and industries for audio broadcasting content description and efficient post-management. Since the interconnectivity and spread of Web 2.0 is increasing (moving to Semantic Web 3.0 and beyond), more potential features are engaged for radio networks to continue to develop cross-border broadcasting. Given the achieved progress in separating the main patterns of the radio broadcasted streams (Voice, Phone, Music and main speakers, telephone conversations and music interferences (VPM) scheme) [
1,
2,
3], the proposed framework investigates language detection mechanisms, targeting the segmentation of spoken content at a linguistic level. Focused research was conducted in speaker diarization/verification problems or sentiment analysis via Gaussian Mixture Modeling with cepstral properties [
8,
17]. Moreover, innovative Deep Learning and Convolutional Neural Networks architectures are deployed in this direction [
4,
5,
35] with 2-D input features [
7,
15]. In addition, several experiments were conducted either on singing voices [
18] or in utterance level [
19]. Despite the progression in algorithmic level, many related efforts shifted to the development of mechanisms for archiving increased language material [
36,
37,
38,
39,
40]. Furthermore, though the first trials in resolving this problem are dated many years ago, nonetheless, the multicultural and differentiated linguistic nature of the radio industry deteriorates the possibility of achieving effective recognition scores. Therefore, new methodologies need to be developed for language identification demands.
The aforementioned task is quite demanding because of the diversity of audio patterns that appear in radio productions. Specifically, common radio broadcasting usually includes audio signals deriving from the main speakers’ voices (frequently, with strong overlapping), telephone dialogues (exposing distinctive characteristics that depend on the communication channel properties), music interferences (imposed with fade in/out transitions or background music), various SFX and radio jingles or even noise segments (ambient/environmental noise, pops and clicks, distortions, etc.) [
1,
2,
3,
33]. It has to be noted that broadcasted music content depends mainly on the presenters’ or audiences’ preferences and, consequently, may not be in accordance with the respective language of origin (i.e., a German radio broadcasting may include either German or English songs). The same applies to the corresponding live dialogues and comments that precede or follow music playback, making it rather inevitable to encounter multilingual terms. Most of all, it is not possible to ascribe universal linguistic labeling to the entire recording based on the main language of the associated program.
Taking the above aspects into consideration, and the experience gained from previous research, hierarchical classification approaches are best suited to resolve this task, allowing the initial, highly accurate VPM scheme to isolate non-voice segments, i.e., to exclude them from the subsequent language classification process. Furthermore, both theory and previous experimentation showed that supervised machine learning solutions outperform the accuracy of unsupervised/clustering methods, with the counterbalance of the need for time-accurate standardized semantic annotation, which is rather an old fashioned and time-consuming human-centric procedure [
1]. While large-scale labeled audio repositories are currently available to be involved in deep learning processes (e.g., audio books), again, past testing revealed that spontaneous speech and non-stopping sound of real-world radio streams do pose some distinctive features that would not be easily confronted with generic solutions. In fact, program-adaptive training solutions proved to be even more advantageous, since they provide adaptation and generalization mechanisms to the specific speakers, the jingles and the favorite music of each radio show [
1,
2,
3,
33]. In this context, the grouping of multiple shows with similar characteristics may also be feasible. Concerning the specific problem under study, it is further expected that speaker information can be associated with the different multi-lingual patterns, thus facilitating language recognition through similar adaptations (i.e., a speaker would have specific voicing and pronouncing features while speaking different languages, which could be more easily detected and associated).
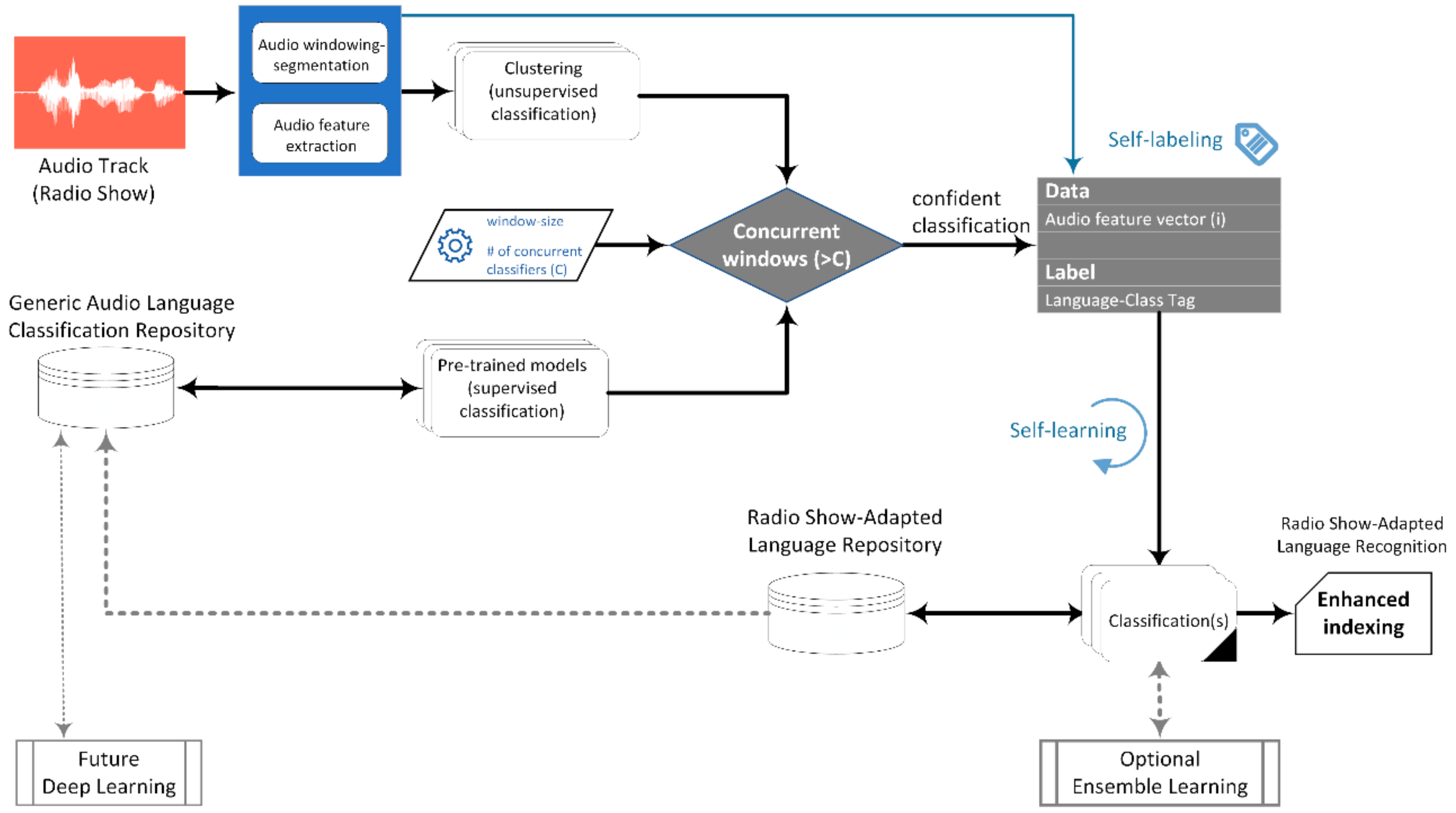
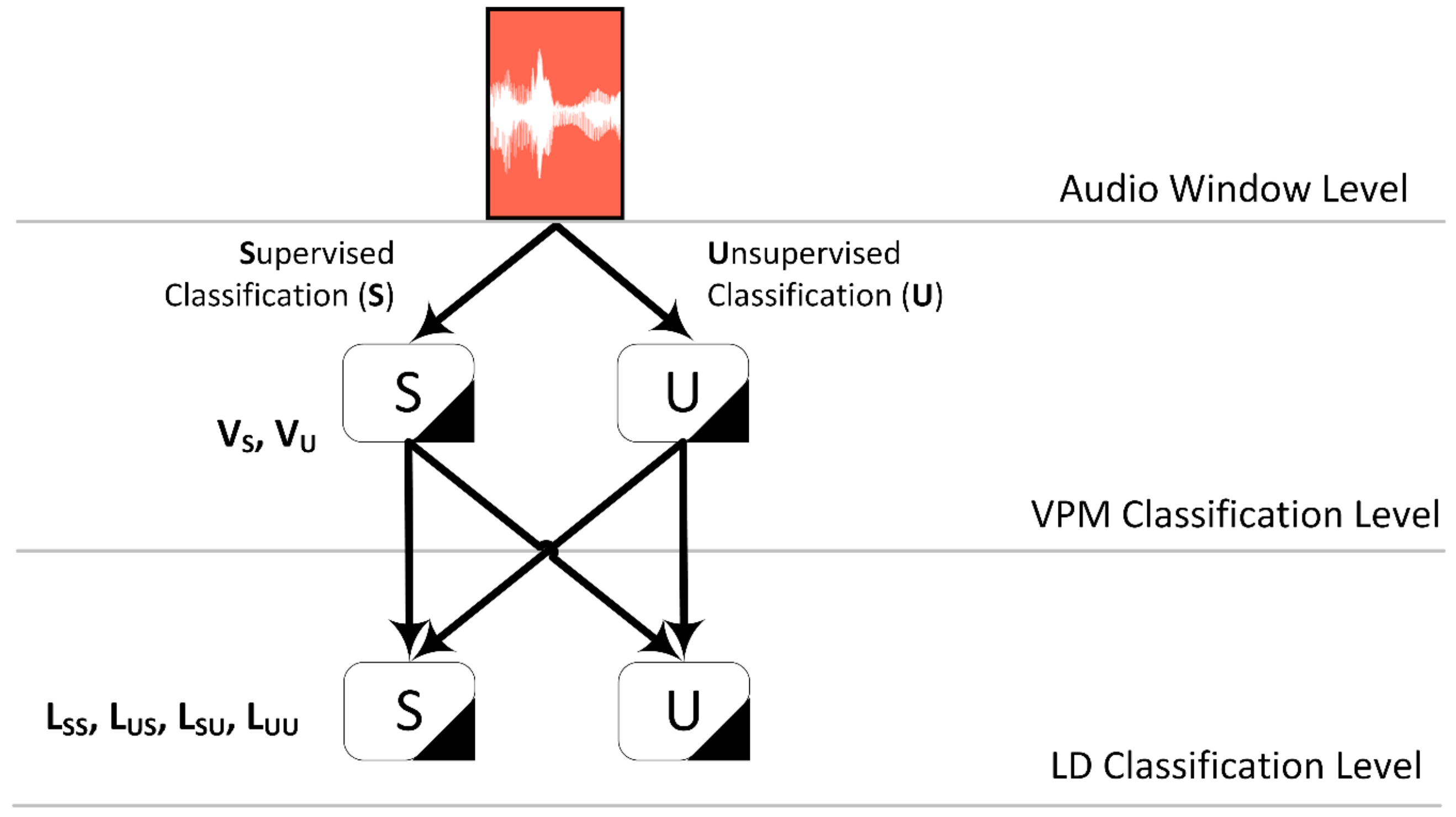
The idea and the motive behind the current work is the examination of whether it is possible to train such a language detection system with a small initial dataset. After that, following the strategy that is originally deployed in [
33], ensemble learning by means of late integration techniques could be applied [
41], combining multiple unsupervised and supervised modalities and with different time windowing configurations. Hence, with the only restriction that the initially trained model should be speaker-independent, matching labels between the different modalities would offer ground-truth data augmentation mechanism through semi-automated annotation (i.e., even by requiring users’ feedback to verify highly-confidence instances). Thereafter, sessions of semi-supervised learning [
42] could be iteratively deployed, thus offering the wanted gradual growth of both generic and program-adaptive repositories (the principle data-flow of this process is given in [
33], while more specific details on the current task are provided in the corresponding implementation sections).
Media organizations, communication researchers and news monitoring service providers could be benefited by such an information retrieval system. Distinct spoken words that are recognizable in a multilingual environment could accelerate the processes of content documentation, management, summarization, media analytics monitoring, etc. Classified audio files, subjected to transcription and/or translation, could be propelled to other media rather than radio. In addition, they might be used for automatic interpretation of worldwide radio streams. On the next level, the categorized and annotated data, extracted through the implementation of semantic analysis and filtering, could be exploited for content recommendations to users or journalists, enhancing their work while avoiding time-consuming personal quests in vast repositories. An additional outcome of this research, in its fully developed phase, could be the valuable provision of feedback to the radio producers themselves, through the analysis of their own used vocabulary, for instance, by using term-statistics on the frequency of foreign words in their dialogues. This user-centric metric approach could lead them to personal and professional improvements. In another context, it could give linguists significant content-related data on the path of a nation’s heritage, based on the alterations of the spoken language through the additions of foreign vocabulary.
2.6. Feature Engine—Feature Evaluation
After the completion of the segmentation step, the formulated datasets of the audio samples were subjected to the feature extraction procedure. Specifically, from each audio frame, an initial set of audio properties was extracted. In the current work, 56 features (
Table 2) were computed, taking into consideration previous experience, trial and error tests and bibliographic suggestions [
1,
2,
3,
4,
5,
6,
7,
8,
9,
10,
11], while the extraction process was conducted via the MIRToolbox specialized software in the Matlab environment [
43]. The audio properties include time-domain variables (number of peaks, RMS (Root Mean Square) energy, number of onsets, rhythmic parameters, zero-crossing rate, etc.), spectral characteristics (rolloff frequencies, brightness, spectral statistics, etc.) and cepstral features (Mel Frequency Cepstral Coefficients). A thorough description of the extracted feature set can be addressed in [
13,
14,
15,
22,
23,
24,
25,
26].
The values of the computed audio properties from each audio frame (100 ms, 500 ms, 1000 ms, 2000 ms) were combined to the respective annotations of
Table 1, in order to formulate the ground-truth database, which is necessary for the subsequent data mining experiments, and specifically for training the supervised machine learning models.
The extracted audio properties usually implicate different discriminative performance, with their efficiency and suitability to be strongly related to the specific task under investigation. For this reason, their impact is examined in the current work via an evaluation process, that algorithmically ranks the most powerful features of the 2-layer classification problem. Specifically, the “InfoGain Attribute Evaluation” method was utilized in the WEKA environment [
44], which estimates the importance of each property separately, by computing the related achieved information gain with entropy measures (for the correspondent classification scheme).
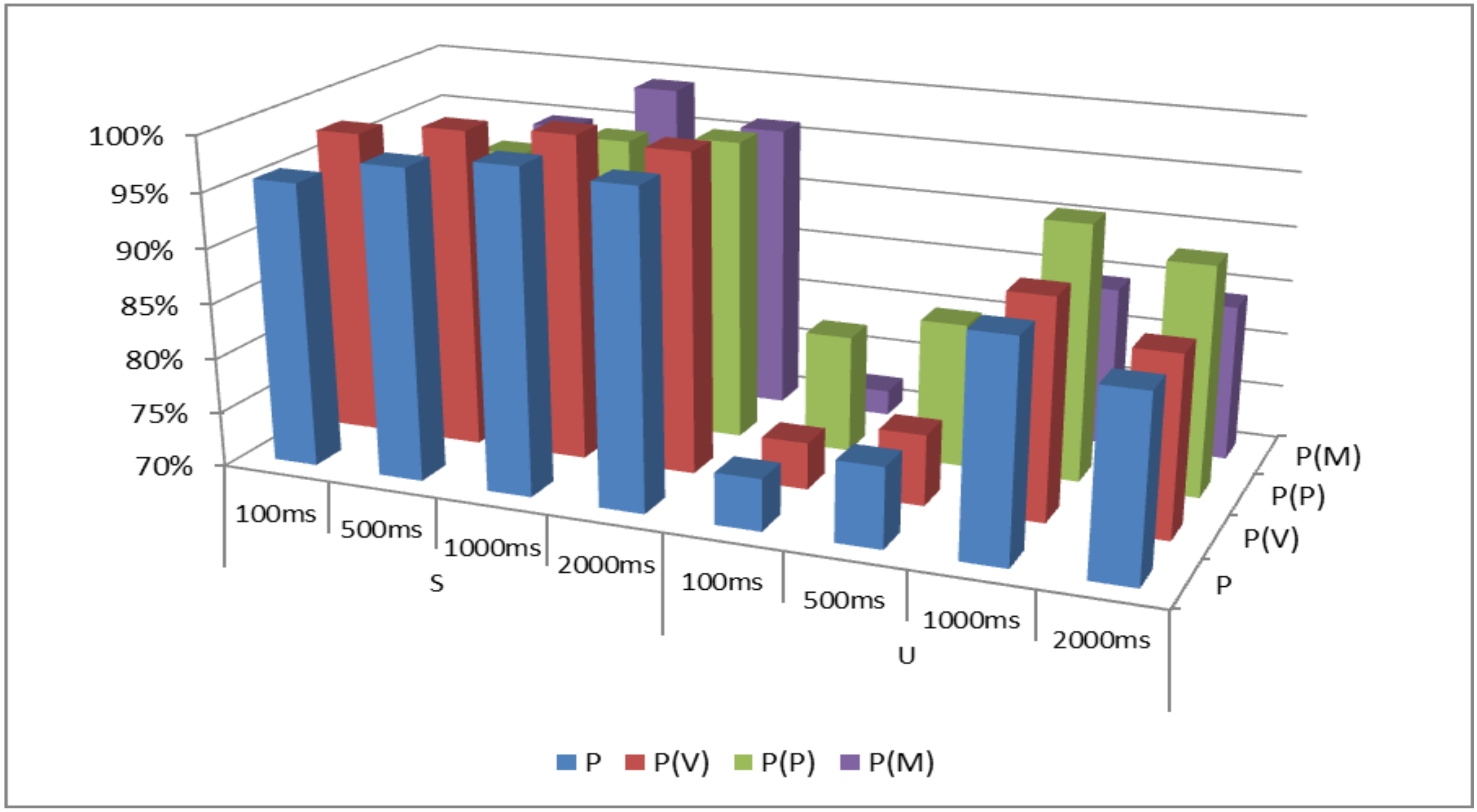
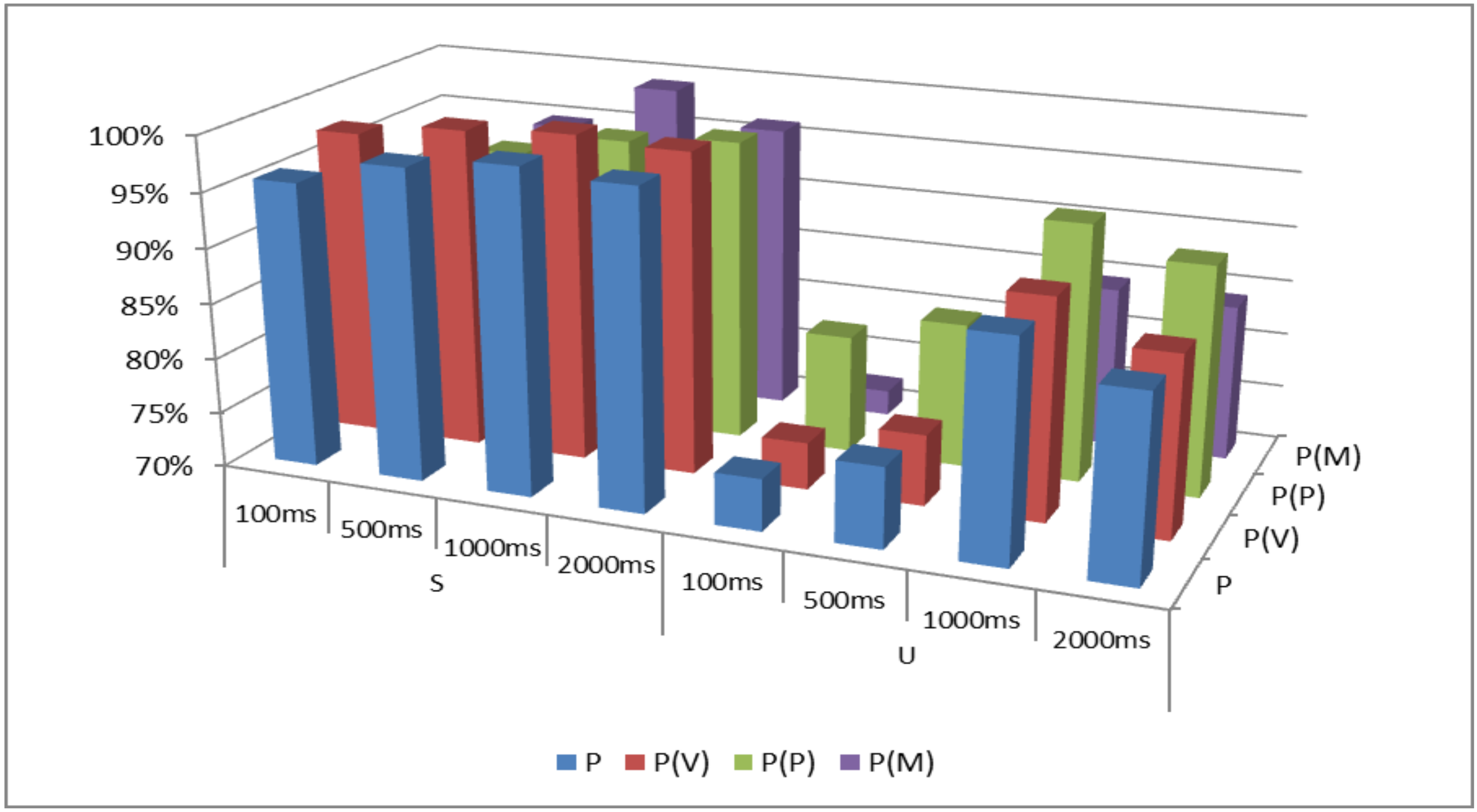
Table 3 presents the feature ranking that was formulated for the first discrimination scheme (VPM), with the implementation of the differentiated window length during the segmentation step. It has to be noted that
Table 3 exhibits only the first 10 properties that prevailed during the evaluation tests, while the hierarchy/ranking continues for the whole 56-dimensional feature set.
As
Table 3 presents, the feature ranking for the VPM discrimination scheme involves slight variations in relationship with the respective temporal lengths. The supremacy of the spectral properties is evident, since the associated features are placed in the first ranking positions, i.e., the brightness (for 3000 Hz, 4000 Hz and 8000 Hz threshold frequencies), the rolloff frequencies (for all threshold energies) and the spectral statistical values of centroid, spread, kurtosis and flatness. Furthermore, the high discriminative power of the cepstral coefficients (mfccs) in speech/non speech classification problems is validated, as these properties hold high order ranking in the feature hierarchy.
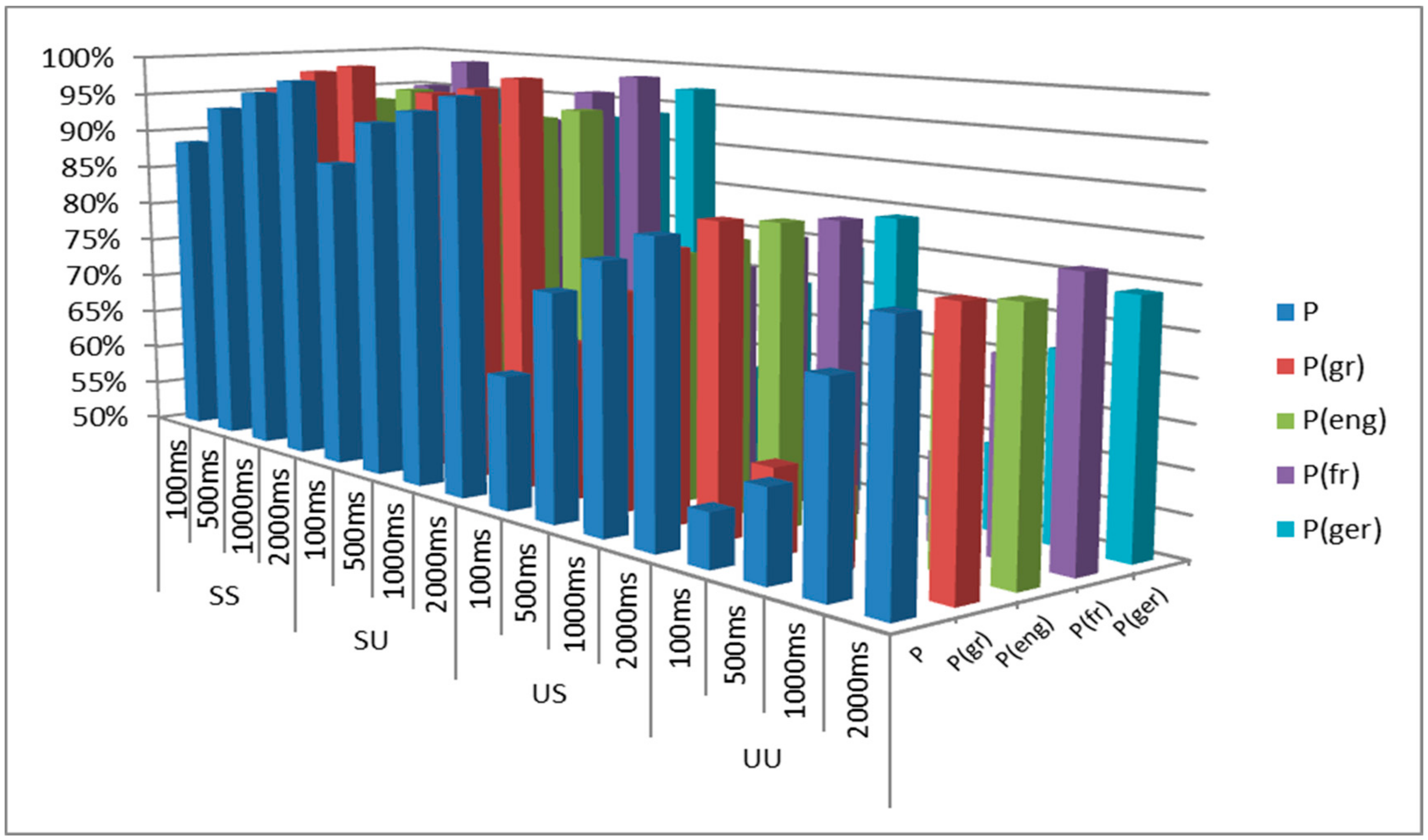
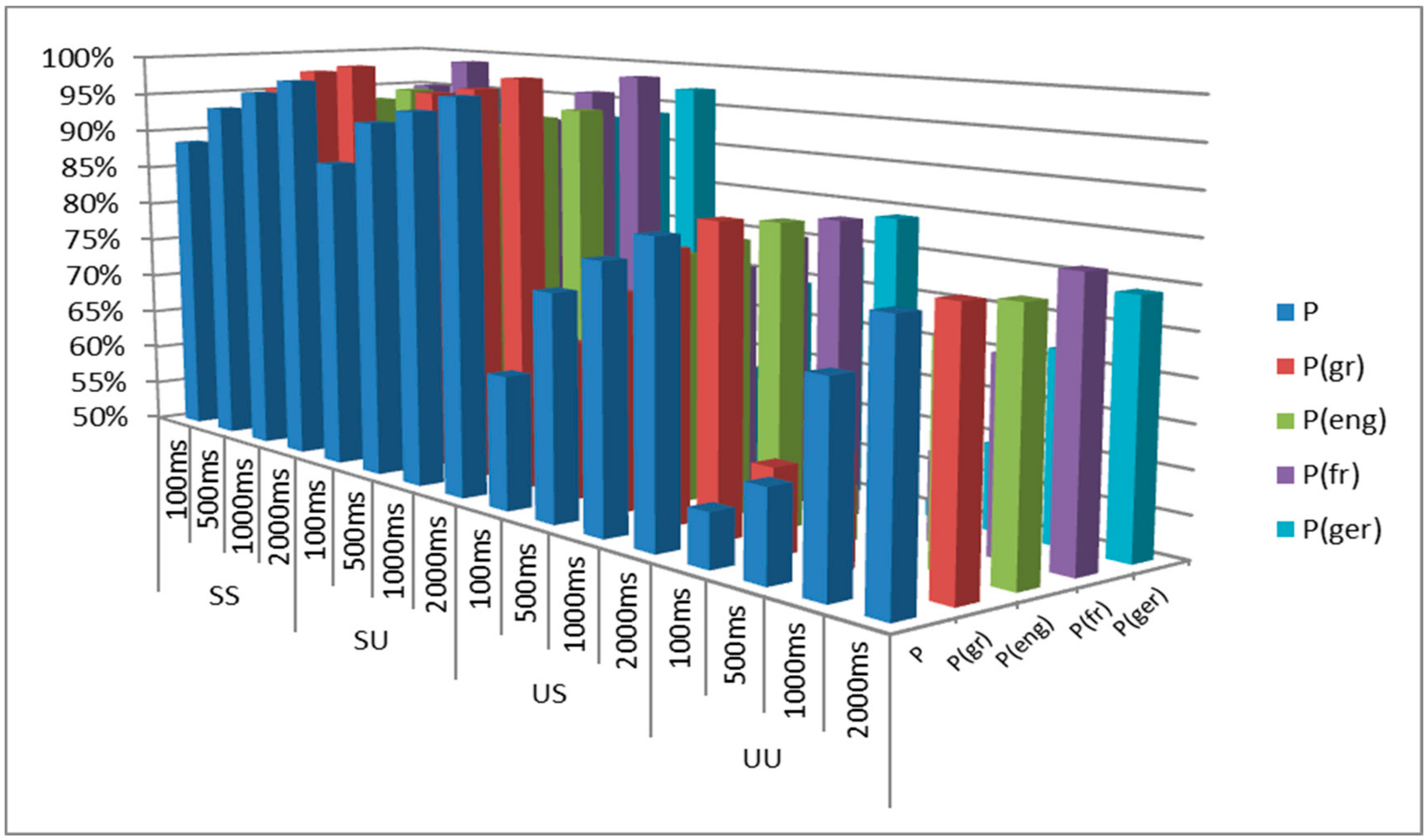
The extracted feature vector was also subjected to the evaluation process, on the basis of the second discrimination layer LD.
Table 4 presents the feature ranking that was formulated via the InfoGain Attribute algorithm. However, the hierarchy of LD scheme involves both spectral properties (brightness measures, rolloff frequencies, spectral centroid and spread) and temporal features (rms energy, zerocross, attacktime, flux, rhythm_clarity) in the first ten prevailing positions. Since the LD scheme is focused on the discrimination of (multilingual) voice signals, the prevalence of cepstral coefficients (mfccs) is somehow diminished, compared to their impact in the VPM classification layer.
The aforementioned feature rankings of
Table 3 and
Table 4 are based on the computation of entropy metrics, hence, they represent a comparative feature analysis (an initial indication of their impact) rather than a strict evaluation of their actual efficiency. Performance and suitability of the selected feature vector are derived from the discrimination rates of the subsequent machine learning experiments, in which all the attributes are simultaneously implicated/exploited in the classification process. Because of the investigatory nature of the current research along with the restricted sample size, the aforementioned hierarchy of audio properties cannot be generalized at this step, towards the extraction of solid conclusions, since potential differentiations could occur while moving to the augmented multilingual audio repository. Nevertheless, the feature ranking results can be useful toward combined, early and late temporal (feature) integration decision making, combining multiple modalities/machines.
The specific ranking was conducted entirely quantitatively, based on the used information evaluation algorithms. A potential explanation of the higher ranking of the spectral attributes might be found on the basis of the differentiated letters/phonemes distribution [
45,
46,
47,
48] in the various languages (for example, the increased energy containing “t” and “p” phonemes/utterances). The same effect can be explained on the fact that some languages favor explosive-like speech segments and/or instances. For instance, the rolloff_0.99 parameter (that is constantly first in all LD time-windows) efficiently detects such transients and their associated high spectra (not solely but in combination with other features). Again, the focus of the current paper and its investigative character does not leave room for other related experiments, beyond the provided ranking with the associated trial and error empirical observation and justification comments. In truth, it would be risky to attempt such an interpretation within the small-size audio dataset used, where slight variations in the recording conditions and the particularities of the different broadcasted streams could have a stronger effect than the speaker or the language attributes.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}