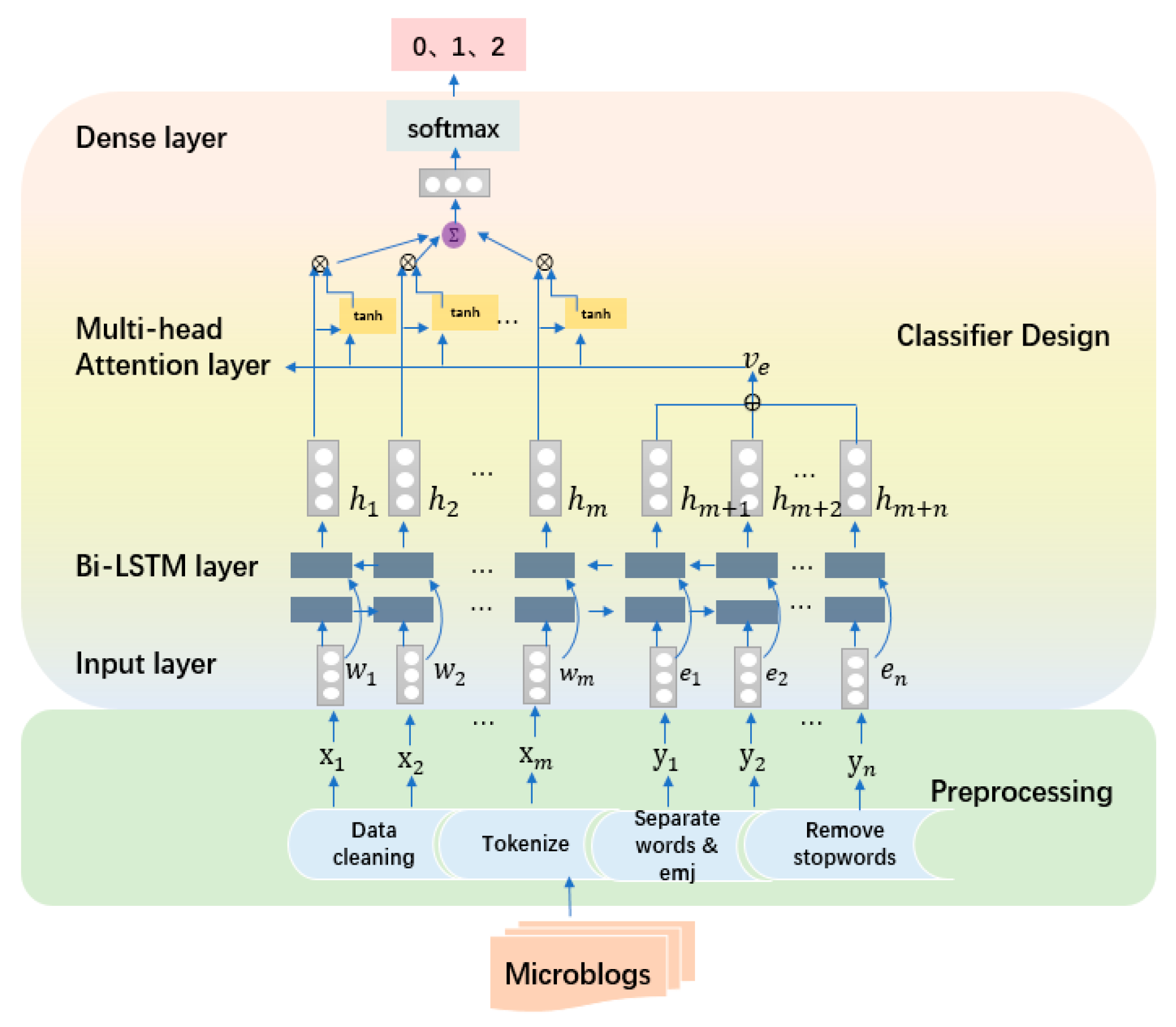
3.2. Classifier Design
One of the novelties of our method lies in the utilization of the BiLSTM network and multi-head attention mechanism combined with emoticons for enhancing the microblog sentiment analysis. Particularly, we divide the design part of the classifier into four layers, namely the input layer, BiLSTM layer, multi-head attention layer, and dense connection layer.
Input layer: the input layer generates the embedding of words and emojis. After the above-mentioned preprocessing, the input microblog data are expressed as: {, … ;, ...,}, where is the th word and is the th emoticon in microblog. After the words and emoticons are mapped to the corresponding embedding, the input layer is represented as {,…, … ; ,,..}, where represents the total number of words and emoticons in microblog, and is the feature dimension.
BiLSTM layer: LSTM is a variant of RNN, which can solve the problem of gradient disappearance by introducing input gate i, output gate o, forget gate f, and memory cell state. LSTM can improve the memory mechanism of neural network to receive input information and training data, which is very suitable for modeling time series data, like texts, due to the characteristics of its design. BiLSTM is a combination of forward LSTM and backward LSTM. The former deals with the sequence from left to right, while the latter deals with the sequence from right to left. The biggest advantage of this structure is that the sequence context information is fully considered. Next, we introduce the procedures of LSTM in detail.
An LSTM unit consists of three controlling gates, including an input gate
, a forget gate
, and an output gate
, as well as a memory cell state
, all of which affect the unit’s ability to store and update information. The input gate output a value between 0–1 based on the input
and
(see Equation (1)). When the output is 1, it means that the cell state information is completely retained, and when the output is 0, it is completely abandoned. Next, the input gate layer decides which values need update, and the tanh layer creates a new candidate value vector
, which can be added to the cell state. Subsequently, the two will be combined to update the cell state
finally, the output gate will determine the output value based on the cell state (See Equations (5) and (6)). Among them,
,
,
,
,
,
,
,
,
, and
,
,
are the internal training parameters in the LSTM,
is sigmoid activation function, and
denotes dot multiplication.
The above is the calculation process of LSTM. As we said earlier, BiLSTM includes forward LSTM and backward LSTM.
in BiLSTM, read the input from
to
to generate
and another
read the input from
to
in order to generate
:
The forward and reverse context representations generated by
and
are connected into a long vector, and the combined output is the representation of the current time to the input:
Finally, the output [] of the whole sentence is obtained, where and are utilized to represent the output of words and emoticons, respectively, in the hidden layer. In addition, we set all of the intermediate layers in BiLSTM to return the complete output sequence, thereby ensuring that the output of each hidden layer retains the long-distance information as much as possible.
Multi-head attention layer: attention is a mechanism for improving the effect of RNN-based models, and the calculation of attention is mainly divided into three steps. The first step is to use the attention function F to score query and key to get
. The two most common attention functions are additive attention and dot-product attention [
35]; in this article, we use the former. The second step is to use softmax function to normalize the scoring result
, so as to obtain the weight
The third step is to calculate attention, which is the weighted average of all values and weights
.
Figure 2 shows the flow chart of the attention mechanism.
Multi-head attention has improved the traditional attention mechanism, so that each head can extract the features of query and key in different subspaces. To be precise, these features come from Q and K, which are the projection of query and key in the subspace. The operation that is shown in
Figure 2 is performed once in each head, and a total of
times need to be performed. It should be noted that in the multi-head attention mechanism, the attention function could be the scaled dot-product function, which is the same as the traditional attention mechanism, except for the regulating scaling factor. In the experiment,
needs to be continuously debugged to determine the most suitable value for the task. Finally, the results that are returned in each head are concatenated and linearly converted to obtain multi-head attention.
Figure 3 shows the main idea. Next, we will combine the tasks in this article to explain, in detail, how we use the multi-head attention mechanism.
As we all know, each word contributes to the sentiment conveyance differently, and the effect of combining words with emoticons is also different. Therefore, in this paper, we propose scoring emoticons and words, and then weight the importance of each word in determining the emotional polarity of microblog.
First,
and
are the word embeddings corresponding to the words and emoticons in microblog, respectively, where
,
and
is the dimension of the word vector. The BiLSTM generates more abstract representations of word and emoji, namely
and
, given the word embedding of words and emoticons as input. Observing that many users will post multiple emojis in the same microblog or multiple identical emojis in a row, but only emoticons that are not repeated in blog post are extracted in our method, and the number of different emoticons is limited to no more than 5. All emojis are combined to obtain the emoticon representation:
The attention function that is used in this paper is additive attention [
36], which performs better in higher dimensions. We regard the output [
of words and
of emoticons in the BiLSTM hidden layers as the query and key in the attention mechanism to calculate the attentive scores, and perform a softmax normalization operation in order to obtain the weight
, which represents the importance of the t-
word combined with emoticons for sentiment analysis:
Among them,
are the weight matrices;
is the bias;
is the weight vector; and,
is the transpose of
. Accordingly, output of each head is:
When compared with the attention mechanism with only one head, multi-head attention allows for the model to jointly attend to information in different feature subspaces. It performs the attention function in parallel. Subsequently, we concatenate the results of every head in a linear manner, resulting in the final output of this layer.
where
,
are the parameter matrices that project
Q,
K, and
V to different representation subspaces, and
Q =
,
K =
V = [
.
Dense connection layer: finally, we send the vectors from the previous layer to the densely connected layer. We use the ReLu function as the activation function to complete the nonlinear conversion. At the last densely connected layer, we perform Softmax operation on the output of the previous layer, and finally obtain the sentiment classification of microblog.






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}











