Attention-Based SeriesNet: An Attention-Based Hybrid Neural Network Model for Conditional Time Series Forecasting

Abstract
1. Introduction
- We introduce the conditioning methods for CNN and RNN and propose a lightweight hidden state attention module (HSAM) on RNN layers.
- We have utilized the attention mechanisms in SeriesNet and present an attention-based SeriesNet combined CBAM [9] on convolutional layers and HSAM on RNN layers for time series forecasting.
- We used GRU and DDSTCNs instead of LSTM and DC-CNN of SeriesNet to reduce the parameters in neural network layers.
2. Related Work
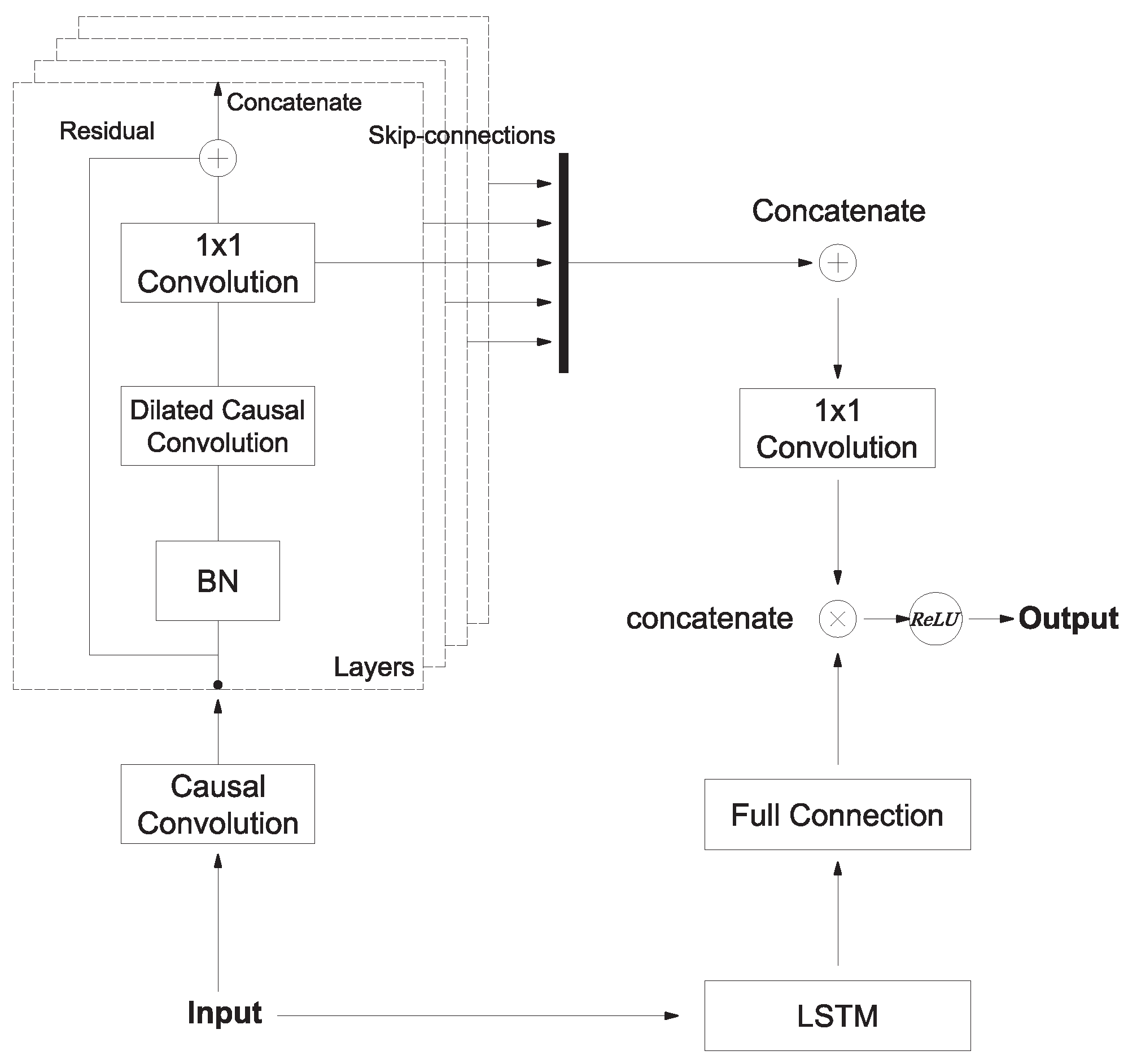
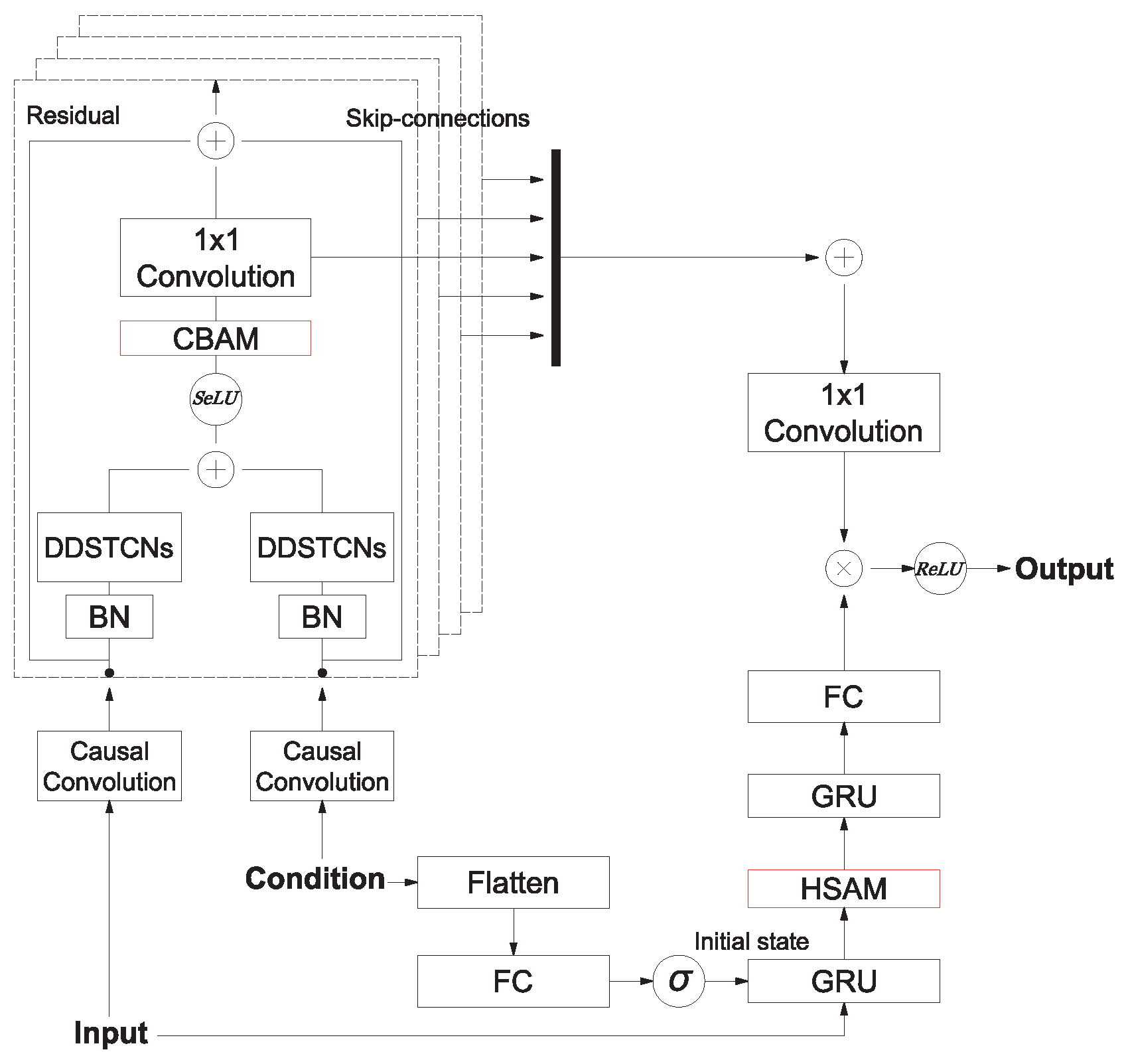
3. Structure of Attention-Based SeriesNet
3.1. Conditioning
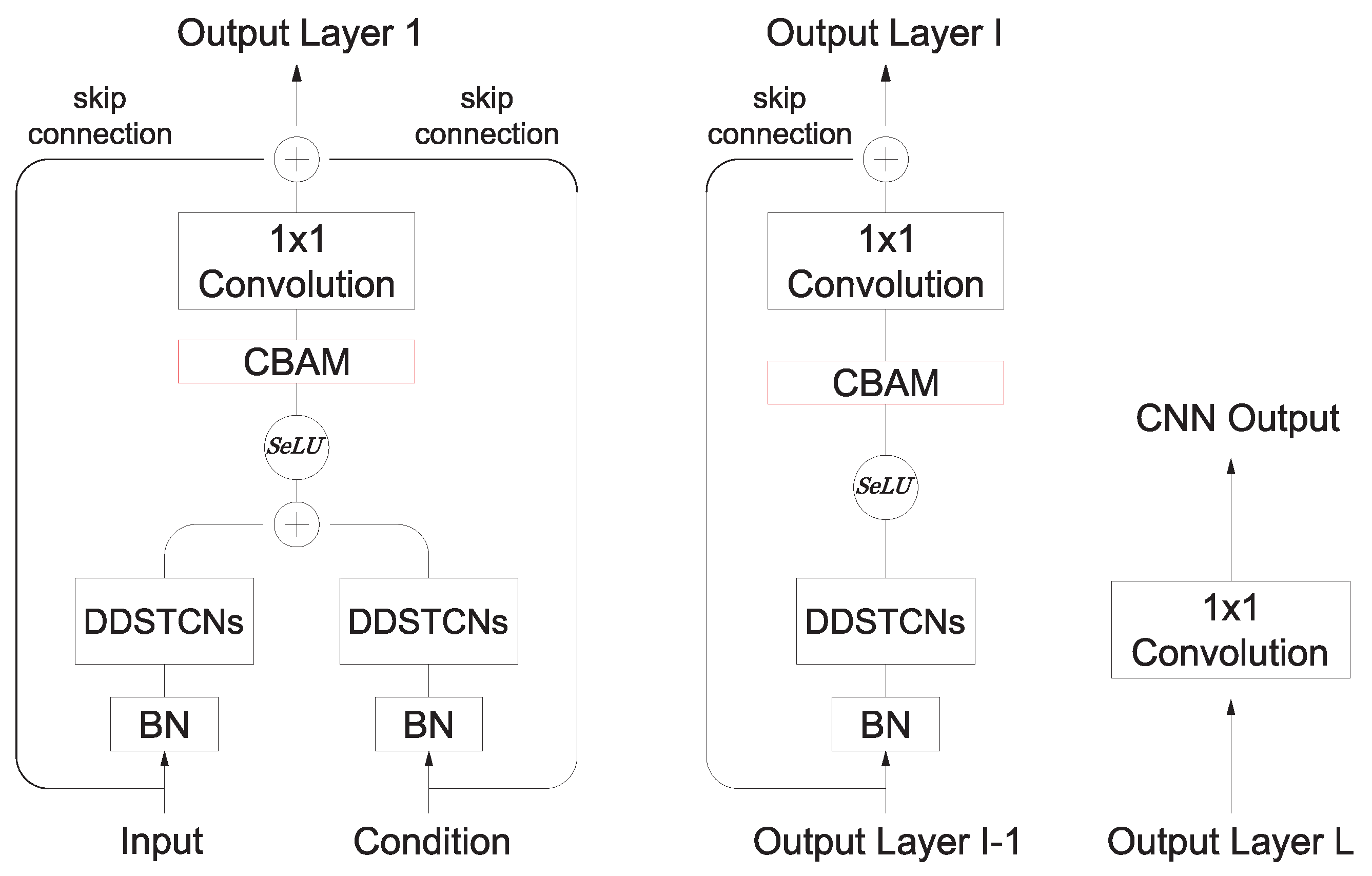
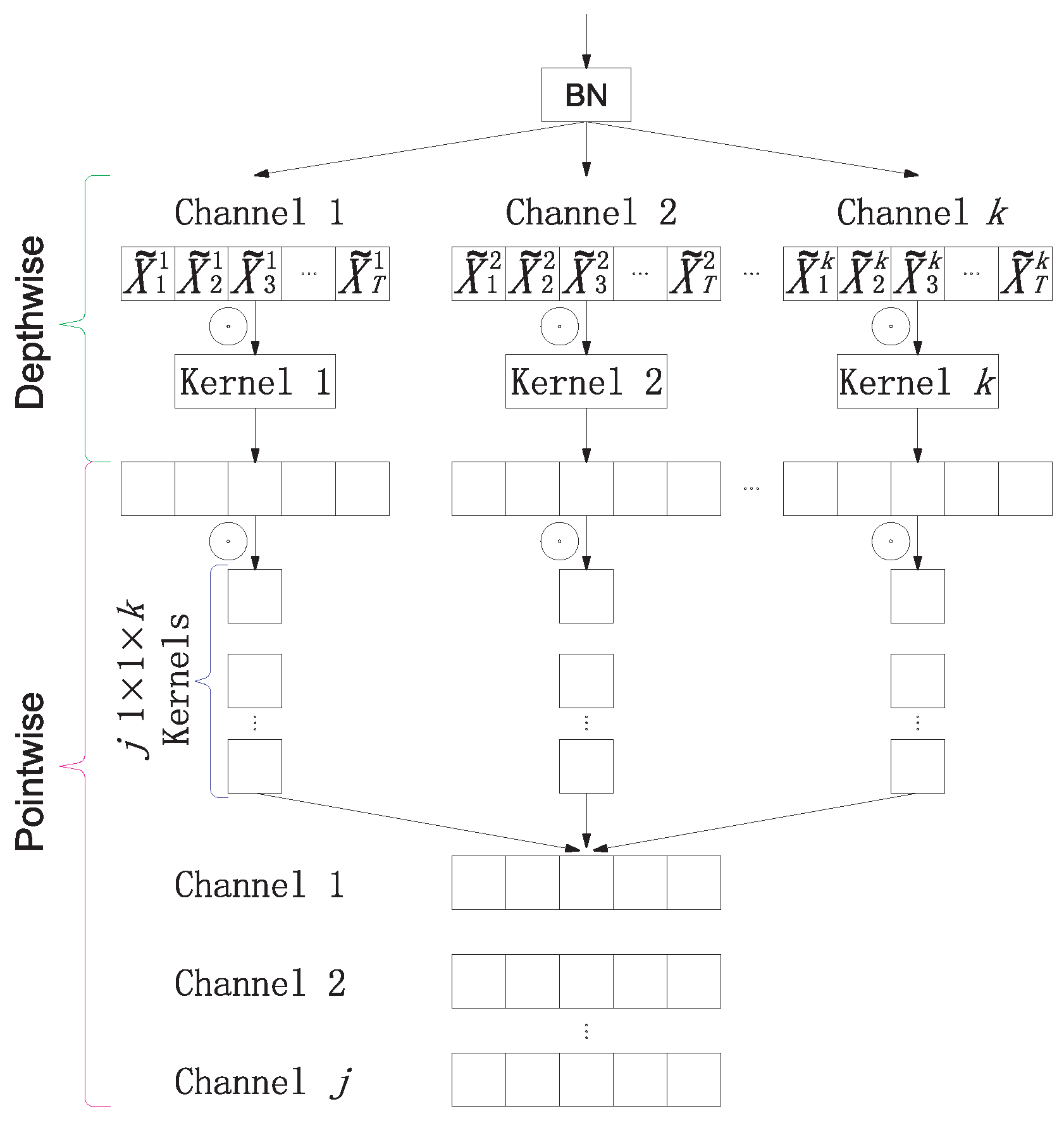
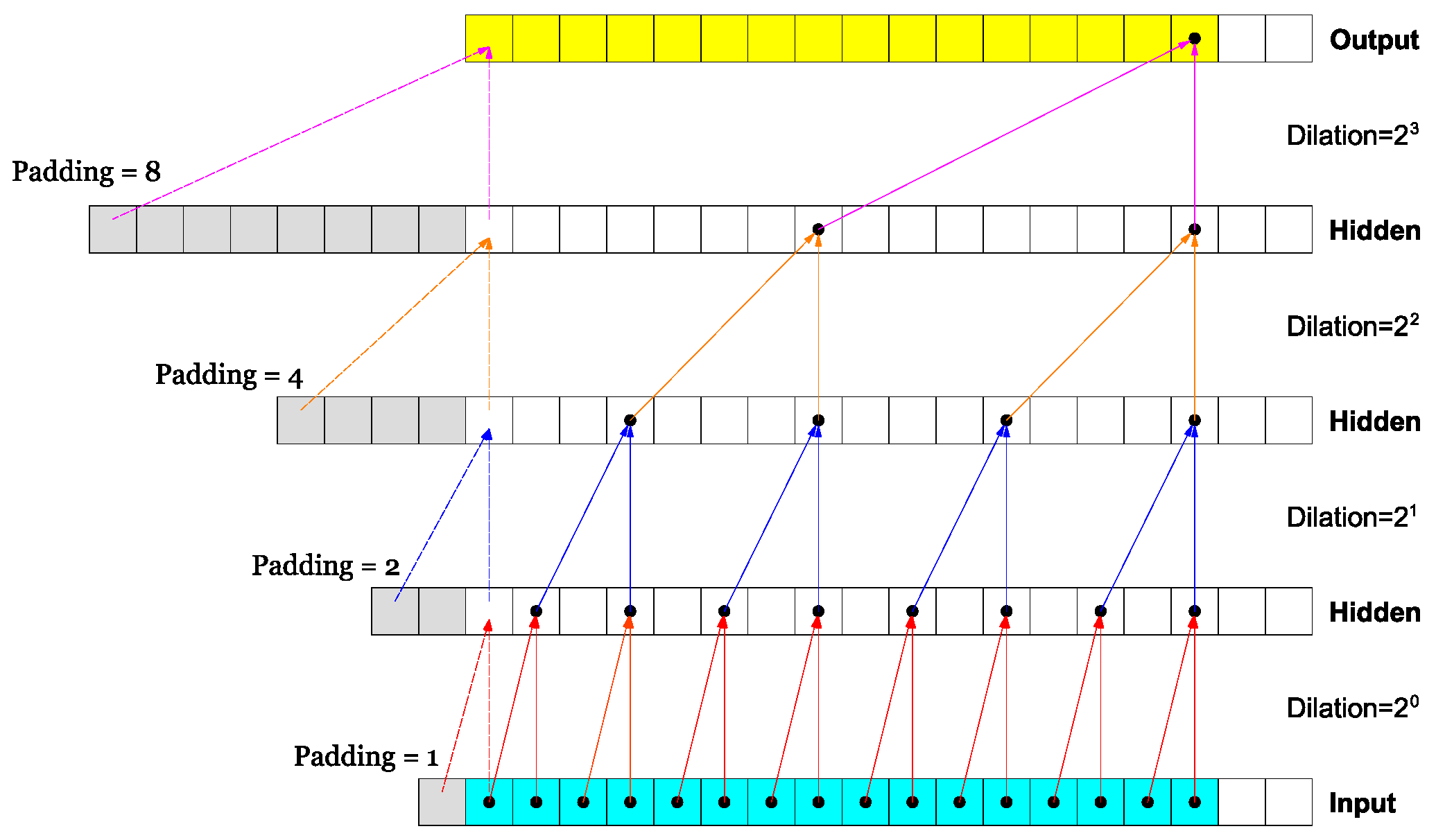
3.2. Dilated Depthwise Separable Temporal Convolutional Networks
3.3. Convolutional Block Attention Module
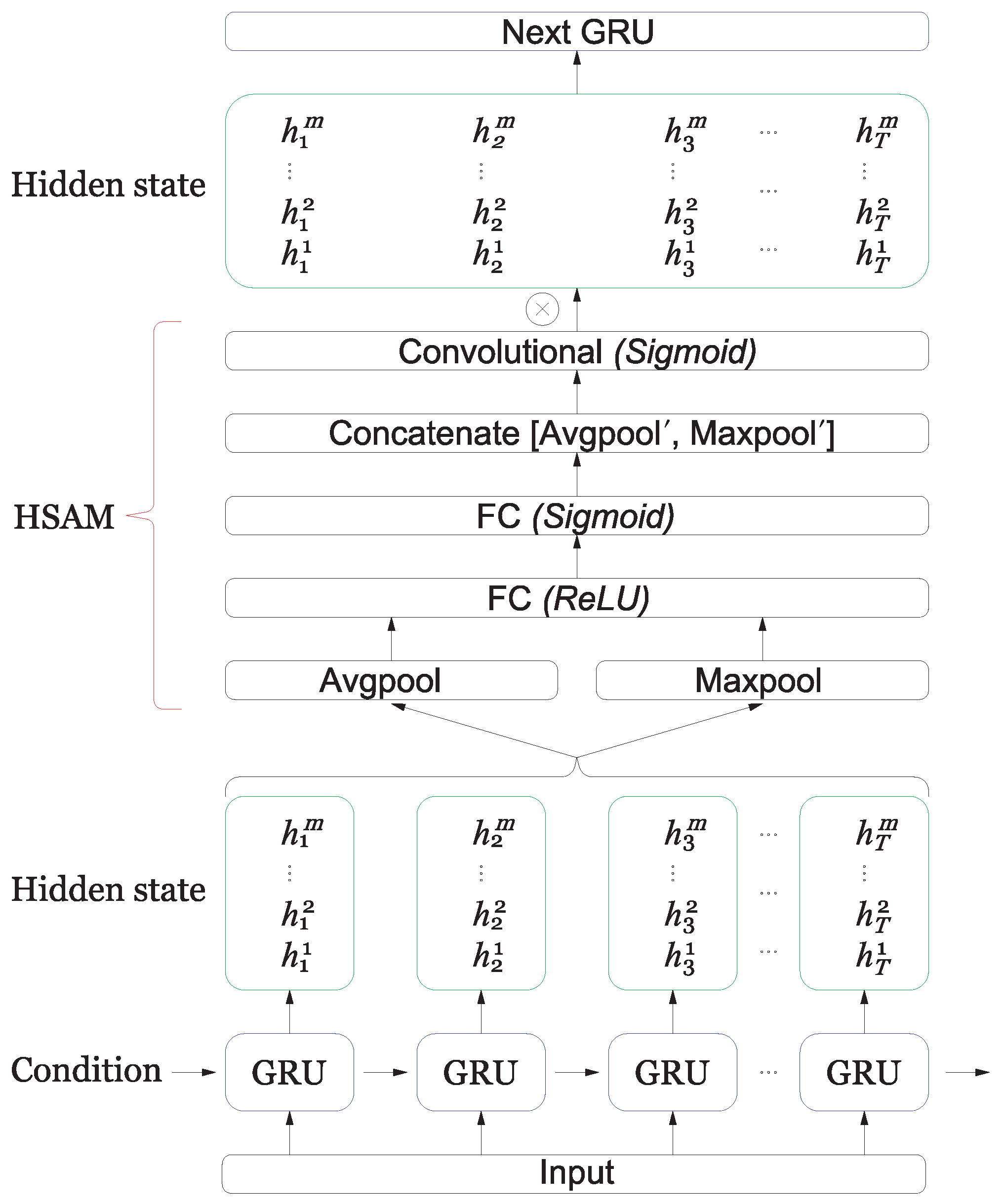
3.4. Hidden State Attention Module
4. Experiments
5. Conclusions
6. Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Shen, Z.; Zhang, Y.; Lu, J.; Xu, J.; Xiao, G. SeriesNet: A Generative Time Series Forecasting Model. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar]
- Borovykh, A.I.; Bohte, S.M.; Oosterlee, C.W. Dilated convolutional neural networks for time series forecasting. J. Comput. Financ. 2019, 22, 73–101. [Google Scholar] [CrossRef]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Chung, J.; Gulcehre, C.; Cho, K.; Bengio, Y. Empirical evaluation of gated recurrent neural networks on sequence modeling. arXiv 2014, arXiv:1412.3555v1. [Google Scholar]
- Nauta, M.; Bucur, D.; Seifert, C. Causal Discovery with Attention-Based Convolutional Neural Networks. Mach. Learn. Knowl. Extr. 2019, 1, 312–340. [Google Scholar] [CrossRef]
- Qin, Y.; Song, D.; Cheng, H.; Cheng, W.; Jiang, G.; Cottrell, G. A Dual-Stage Attention-Based Recurrent Neural Network for Time Series Prediction. In Proceedings of the 26th International Joint Conference on Artificial Intelligence (IJCAI’17); AAAI Press: Palo Alto, CA, USA, 2017; pp. 2627–2633. [Google Scholar]
- Yagmur, G.C.; Hamid, M.; Parantapa, G.; Eric, G.; Ali, A.; Vadim, S. Position-Based Content Attention for Time Series Forecasting with Sequence-to-Sequence RNNs. In Proceedings of the Neural Information Processing: 24th International Conference, ICONIP 2017, Guangzhou, China, 14–18 November 2017; pp. 533–544. [Google Scholar]
- Luong, T.; Pham, H.; Manning, C.D. Effective Approaches to Attention-based Neural Machine Translation. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 1412–1421. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.Y.; Kweon, I.S. CBAM: Convolutional Block Attention Module; Ferrari, V., Hebert, M., Sminchisescu, C., Weiss, Y., Eds.; ECCV 2018, Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2018; Volume 11211, pp. 3–19. [Google Scholar]
- Liu, C.; Hoi, S.C.H.; Zhao, P.; Sun, J. Online ARIMA algorithms for time series prediction. In Proceedings of the Thirtieth AAAI Conference on Artificial Intelligence (AAAI’16); AAAI Press: Palo Alto, CA, USA, 2016; pp. 1867–1873. [Google Scholar]
- Drucker, H.; Burges, C.J.C.; Kaufman, L.; Smola, A.; Vapnik, V. Support vector regression machines. In Proceedings of the 9th International Conference on Neural Information Processing Systems (NIPS’96); MIT Press: Cambridge, MA, USA, 1996; pp. 155–161. [Google Scholar]
- Mishra, M.; Srivastava, M. A view of Artificial Neural Network. In Proceedings of the 2014 International Conference on Advances in Engineering & Technology Research (ICAETR-2014), Unnao, India, 1–2 August 2014; pp. 1–3. [Google Scholar]
- Zeng, Y.; Zeng, Y.; Choi, B.; Wang, L. Multifactor-influenced energy consumption forecasting using enhanced back-propagation neural network. Energy 2017, 127, 381–396. [Google Scholar] [CrossRef]
- Hu, H.; Wang, L.; Peng, L.; Zeng, Y. Effective energy consumption forecasting using enhanced bagged echo state network. Energy 2020, 193, 116778. [Google Scholar] [CrossRef]
- Hu, H.; Wang, L.; Lv, S. Forecasting energy consumption and wind power generation using deep echo state network. Renew. Energy 2020, 154, 598–613. [Google Scholar] [CrossRef]
- Sherstinsky, A. Fundamentals of Recurrent Neural Network (RNN) and Long Short-Term Memory (LSTM) network. arXiv 2020, arXiv:1808.03314. [Google Scholar] [CrossRef]
- Pascanu, R.; Mikolov, T.; Bengio, Y. On the difficulty of training recurrent neural networks. Int. Conf. Int. Conf. Mach. Learn. 2013, 28, 1310–1318. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. Commun. ACM 2017, 60, 84–90. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. Int. Conf. Int. Conf. Mach. Learn. 2015, 37, 448–456. [Google Scholar]
- Van Den Oord, A.; Dieleman, S.; Zen, H.; Simonyan, K.; Vinyals, O.; Graves, A.; Kalchbrenner, N.; Senior, A.; Kavukcuoglu, K. Wavenet: A generative model for raw audio. arXiv 2016, arXiv:1609.03499. [Google Scholar]
- Borovykh, A.; Bohte, S.M.; Oosterlee, C.W. Conditional time series forecasting with convolutional neural networks. arXiv 2017, arXiv:1703.04691v5, 729–730. [Google Scholar]
- Philipperemy, R. Conditional RNN (Tensorflow Keras). GitHub Repository. 2020. Available online: https://github.com/philipperemy/cond_rnn (accessed on 4 June 2020).
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-Excitation Networks. In Proceedings of the 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 7132–7141. [Google Scholar]
- Klambauer, G.; Unterthiner, T.; Mayr, A.; Hochreiter, S. Self-Normalizing Neural Networks. arXiv 2017, arXiv:1706.02515. [Google Scholar]
- Abien, F.A. Deep Learning using Rectified Linear Units (ReLU). arXiv 2018, arXiv:1803.08375v2. [Google Scholar]
- Chollet, F. Xception: Deep Learning with Depthwise Separable Convolutions. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; pp. 1800–1807. [Google Scholar]
- Kingma, D.P.; Jimmy, B. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Tsironi, E.; Barros, P.; Weber, C.; Wermter, S. An analysis of Convolutional Long Short-Term Memory Recurrent Neural Networks for gesture recognition. Neurocomputing 2017, 268, 76–86. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Time Series | Time Range | Train Data | Validation Data | Test Data |
|---|---|---|---|---|
| S&P500 Index | 1950.01–2015.12 | 3297 | 320 | 320 |
| Shanghai Composite Index | 2004.01–2019.06 | 2430 | 280 | 280 |
| Tesla Stock Price | 2010.06–2017.03 | 1049 | 160 | 160 |
| NewYork temperature | 2016.01–2016.07 | 2430 | 320 | 320 |
| Weather in Szeged | 2006.04–2016.09 | 1700 | 240 | 240 |
| Type | Units/Filters | Size | Dilation Rate | Padding | Output | Complexity |
|---|---|---|---|---|---|---|
| Conv1D(Input) | 1 | 30 | 1 | causal | (50, 1) | 1500 |
| BN | (50, 1) | 0 | ||||
| DDSTCNs | 8 | 7 | 1 | causal/valid | (50, 8) | 750 |
| Conv1D(Condition) | 1 | 20 | 1 | causal | (50, 1) | 1000 |
| BN | (50, 1) | 0 | ||||
| DDSTCNs | 8 | 4 | 1 | causal/valid | (50, 8) | 600 |
| Add | (50, 8) | 0 | ||||
| SeLU | (50, 8) | 0 | ||||
| CBAM | (50, 8) | 956 | ||||
| Conv1D | 1 | 1 | 1 | same | (50, 1) | 400 |
| Add | (50, 1) | 0 | ||||
| BN | (50, 1) | 0 | ||||
| DDSTCNs | 8 | 7 | 2 | causal/valid | (50, 8) | 750 |
| SeLU | (50, 8) | 0 | ||||
| CBAM | (50, 8) | 956 | ||||
| Conv1D | 1 | 1 | 1 | same | (50, 1) | 400 |
| Add | (50, 1) | 0 | ||||
| ⋮ | ||||||
| BN | (50, 1) | 0 | ||||
| DDSTCNs | 8 | 7 | 16 | causal/valid | (50, 8) | 750 |
| SeLU | (50, 8) | 0 | ||||
| CBAM | (50, 8) | 956 | ||||
| Conv1D | 1 | 1 | 1 | same | (50, 1) | 400 |
| Add(Skip-Connection) | (50, 1) | 0 | ||||
| Conv1D | 1 | 1 | 1 | same | (50, 1) | 50 |
| Condition | (1, 20) | 1000 | ||||
| GRU(Input, Condition) | 20 | (50, 20) | 66,000 | |||
| HSAM | (50, 20) | 780 | ||||
| GRU | 20 | (50, 20) | 123,000 | |||
| FC | 1 | (50, 1) | 20 | |||
| Multiply | (50, 1) | 0 | ||||
| ReLU | (50, 1) | 0 | ||||
| Total | 204,480 |
| Type | Units/Filters | Size | Dilation Rate | Padding | Output | Complexity |
|---|---|---|---|---|---|---|
| Lambda_Mean(GRU) | (50, 1) | 0 | ||||
| FC | 20 | (50, 20) | 20 | |||
| ReLU | (50, 20) | 0 | ||||
| FC | 1 | (50, 1) | 20 | |||
| Lambda_Max(GRU) | (50, 1) | 0 | ||||
| FC | 20 | (50, 20) | 20 | |||
| ReLU | (50, 20) | 0 | ||||
| FC | 1 | (50, 1) | 20 | |||
| Concatenate | (50, 2) | 0 | ||||
| Conv1D | 1 | 7 | 1 | same | (50, 1) | 700 |
| Sigmoid | (50, 1) | 0 | ||||
| Multiply(GRU, Sigmoid) | (50, 20) | 0 | ||||
| Total | 780 |
| Type | Units/Filters | Size | Dilation Rate | Padding | Output | Complexity |
|---|---|---|---|---|---|---|
| GlobalAvgPooling1D(SeLU) | (1, 8) | 0 | ||||
| FC | 8 | (1, 8) | 64 | |||
| ReLU | (1, 8) | 0 | ||||
| FC | 8 | (1, 8) | 64 | |||
| GlobalMaxPooling1D(SeLU) | (1, 8) | 0 | ||||
| FC | 8 | (1, 8) | 64 | |||
| ReLU | (1, 8) | 0 | ||||
| FC | 8 | (1, 8) | 64 | |||
| Add | (1, 8) | 0 | ||||
| Sigmoid | (1, 8) | 0 | ||||
| Multiply1(SeLU, Sigmoid) | (50, 8) | 0 | ||||
| Lambda_Mean(Multiply1) | (50, 1) | 0 | ||||
| Lambda_Max(Multiply1) | (50, 1) | 0 | ||||
| Concatenate | (50, 2) | 0 | ||||
| Conv1D | 1 | 7 | 1 | same | (50, 1) | 700 |
| Sigmoid | (50, 1) | 0 | ||||
| Multiply2(Multiply1, Sigmoid) | (50, 8) | 0 | ||||
| Total | 956 |
| Time Series | A_SeriesNet | SeriesNet | WaveNet | SVR | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | ||||||
| S&P500 Index | 8.90 | 7.17 | 0.98 | 10.08 | 8.11 | 0.97 | 11.13 | 8.73 | 0.97 | 10.57 | 8.39 | 0.97 | 16.16 | 12.61 | 0.96 |
| Shanghai Composite Index | 56.69 | 36.49 | 0.98 | 71.96 | 55.50 | 0.97 | 80.52 | 60.10 | 0.97 | 79.29 | 50.17 | 0.97 | 82.25 | 63.19 | 0.97 |
| Tesla Stock Price | 4.56 | 3.36 | 0.97 | 4.82 | 3.68 | 0.96 | 5.50 | 4.36 | 0.95 | 5.59 | 4.38 | 0.95 | 4.74 | 3.36 | 0.96 |
| NewYork temperature | 1.63 | 1.20 | 0.97 | 1.68 | 1.22 | 0.97 | 1.76 | 1.25 | 0.96 | 1.72 | 1.25 | 0.97 | 1.79 | 1.23 | 0.96 |
| Weather in Szeged | 1.22 | 0.71 | 0.96 | 1.29 | 0.79 | 0.96 | 1.44 | 0.90 | 0.95 | 1.42 | 0.88 | 0.95 | 1.41 | 0.83 | 0.95 |
| Time Series | A_SeriesNet | SeriesNet | WaveNet | SVR | |
|---|---|---|---|---|---|
| S&P500 Index | 100.80 | 103.62 | 17.99 | 74.37 | 273.49 |
| Shanghai Composite Index | 92.72 | 94.42 | 18.73 | 76.10 | 237.40 |
| Tesla Stock Price | 61.90 | 64.69 | 36.36 | 41.37 | 124.97 |
| NewYork temperature | 99.78 | 101.38 | 17.80 | 74.73 | 107.08 |
| Weather in Szeged | 89.24 | 96.56 | 17.54 | 62.93 | 115.96 |
| Time Series | HSAM_ | HSAM_ | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| RMSE | MAE | RMSE | MAE | RMSE | MAE | RMSE | MAE | |||||
| S&P500 Index | 9.51 | 7.77 | 0.98 | 10.57 | 8.39 | 0.97 | 10.18 | 8.01 | 0.97 | 12.23 | 9.92 | 0.96 |
| Shanghai Composite Index | 78.44 | 48.49 | 0.97 | 79.29 | 50.17 | 0.97 | 80.46 | 54.74 | 0.97 | 92.83 | 66.70 | 0.96 |
| Tesla Stock Price | 5.02 | 3.89 | 0.96 | 5.59 | 4.38 | 0.95 | 6.24 | 4.63 | 0.94 | 6.29 | 5.00 | 0.94 |
| NewYork temperature | 1.68 | 1.23 | 0.97 | 1.72 | 1.25 | 0.97 | 1.73 | 1.27 | 0.97 | 1.76 | 1.28 | 0.97 |
| Weather in Szeged | 1.33 | 0.80 | 0.96 | 1.42 | 0.88 | 0.95 | 1.41 | 0.82 | 0.95 | 1.56 | 1.00 | 0.94 |
| Time Series | HSAM_ | HSAM_ | ||
|---|---|---|---|---|
| S&P500 Index | 81.94 | 74.37 | 167.42 | 145.09 |
| Shanghai Composite Index | 82.87 | 76.10 | 172.13 | 141.04 |
| Tesla Stock Price | 39.44 | 36.36 | 86.82 | 76.52 |
| NewYork temperature | 81.21 | 74.73 | 170.77 | 147.92 |
| Weather in Szeged | 66.20 | 62.93 | 125.95 | 117.07 |
| Type | Units/Filters | Size | Dilation Rate | Padding | Output | Complexity |
|---|---|---|---|---|---|---|
| Conv1D(Input) | 8 | 7 | 1 | causal | (50, 8) | 2800 |
| ReLU | (50, 8) | 0 | ||||
| Conv1D(Condition) | 8 | 7 | 1 | causal | (50, 8) | 2800 |
| ReLU | (50, 8) | 0 | ||||
| Add | (50, 8) | 0 | ||||
| Conv1D | 8 | 7 | 2 | causal | (50, 8) | 22,400 |
| ReLU | (50, 8) | 0 | ||||
| Add | (50, 8) | 0 | ||||
| ⋮ | ||||||
| Conv1D | 8 | 7 | 16 | causal | (50, 8) | 22,400 |
| ReLU | (50, 8) | 0 | ||||
| Add(Skip-Connection) | (50, 8) | 0 | ||||
| Conv1D | 1 | 1 | 1 | same | (50, 1) | 400 |
| Total | 95,600 | |||||
| Type | Units/Filters | Size | Dilation Rate | Padding | Output | Complexity |
|---|---|---|---|---|---|---|
| Condition | (1, 20) | 1000 | ||||
| GRU(Input, Condition) | 20 | (50, 20) | 66,000 | |||
| GRU | 20 | (50, 20) | 123,000 | |||
| FC | 1 | (50, 1) | 20 | |||
| Total | 190,020 |
| Type | Units/Filters | Size | Dilation Rate | Padding | Output | Complexity |
|---|---|---|---|---|---|---|
| Conv1D(Input) | 1 | 20 | 1 | causal | (50, 1) | 1000 |
| BN | (50, 1) | 0 | ||||
| Conv1D | 8 | 7 | 1 | causal | (50, 8) | 2800 |
| Conv1D(Condition) | 1 | 20 | 1 | causal | (50, 1) | 1000 |
| BN | (50, 1) | 0 | ||||
| Conv1D | 8 | 4 | 1 | causal | (50, 8) | 1600 |
| Add | (50, 8) | 0 | ||||
| Conv1D | 1 | 1 | 1 | same | (50, 1) | 400 |
| Add | (50, 1) | 0 | ||||
| BN | (50, 1) | 0 | ||||
| Conv1D | 8 | 7 | 2 | causal | (50, 8) | 2800 |
| Conv1D | 1 | 1 | 1 | same | (50, 1) | 400 |
| Add | (50, 1) | 0 | ||||
| ⋮ | ||||||
| BN | (50, 1) | 0 | ||||
| Conv1D | 8 | 7 | 16 | causal | (50, 8) | 2800 |
| Conv1D | 1 | 1 | 1 | same | (50, 1) | 400 |
| Add(Skip-Connection) | (50, 1) | 0 | ||||
| Conv1D | 1 | 1 | 1 | same | (50, 1) | 50 |
| Condition | (2, 20) | 2000 | ||||
| LSTM(Input, Condition) | 20 | (50, 20) | 88,000 | |||
| LSTM | 20 | (50, 20) | 164,000 | |||
| FC | 1 | (50, 1) | 20 | |||
| Multiply | (50, 1) | 0 | ||||
| ReLU | (50, 1) | 0 | ||||
| Total | 273,670 | |||||
| A_SeriesNet | SeriesNet | WaveNet | |||
|---|---|---|---|---|---|
| Complexity | 204,480 | 273,670 | 95,600 | 190,020 | 436,020 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Cheng, Y.; Liu, Z.; Morimoto, Y. Attention-Based SeriesNet: An Attention-Based Hybrid Neural Network Model for Conditional Time Series Forecasting. Information 2020, 11, 305. https://doi.org/10.3390/info11060305
Cheng Y, Liu Z, Morimoto Y. Attention-Based SeriesNet: An Attention-Based Hybrid Neural Network Model for Conditional Time Series Forecasting. Information. 2020; 11(6):305. https://doi.org/10.3390/info11060305
Chicago/Turabian StyleCheng, Yepeng, Zuren Liu, and Yasuhiko Morimoto. 2020. "Attention-Based SeriesNet: An Attention-Based Hybrid Neural Network Model for Conditional Time Series Forecasting" Information 11, no. 6: 305. https://doi.org/10.3390/info11060305
APA StyleCheng, Y., Liu, Z., & Morimoto, Y. (2020). Attention-Based SeriesNet: An Attention-Based Hybrid Neural Network Model for Conditional Time Series Forecasting. Information, 11(6), 305. https://doi.org/10.3390/info11060305