Privacy Preservation of Data-Driven Models in Smart Grids Using Homomorphic Encryption




Abstract
:1. Introduction
- Designing a secure and privacy-preserving deep neural network (DNN) model established on homomorphic encryption for smart grid applications.
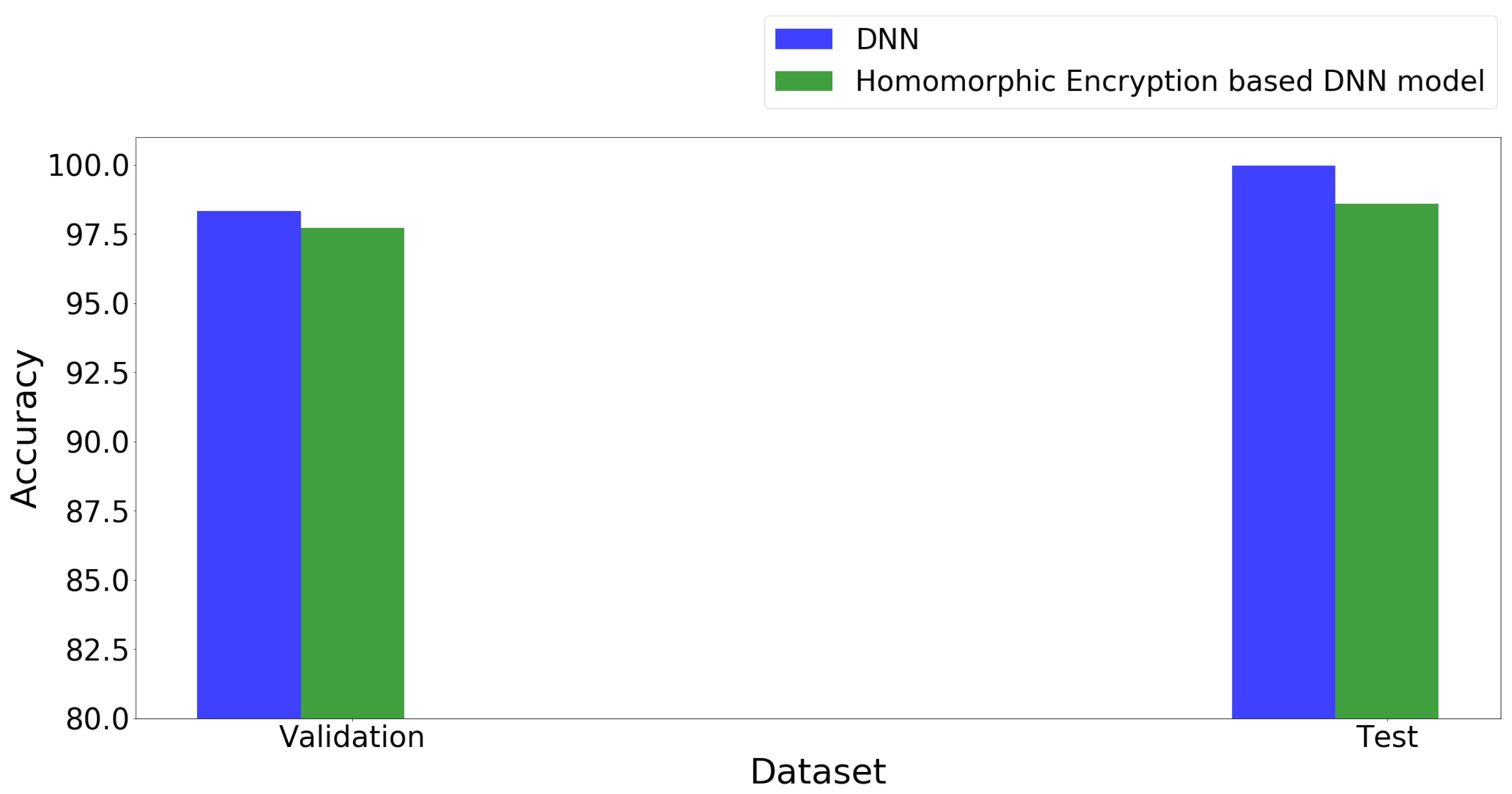
- Proposing a fault classification and localization model that has favorable accuracy when considering the fact that the model is trained on encrypted data. The encryption of the data before modeling accentuates the need for data privacy and security. The accuracy of the model trained on encrypted data is very close to the model trained on non-encrypted data.
- Proposing a load forecasting regression model such that the accuracy of the predictions using encrypted data is close to accuracy using non-encrypted data.
2. Background & Related Work
- Training Data Privacy: the privacy and security layer should be in place that no malicious agent can reverse engineer the training data from the model or the output.
- Model Input Privacy: the input data cannot be obtained by any third party, including the model creator; the input data owner is assumed as different than the model creator.
- Model Weights Privacy: the model parameters and weights cannot be obtained or inferred by a malicious party.
- Model Output Privacy: the output of the model cannot be observable by any third party, except for the owner of the data.
2.1. Training Data Privacy
2.2. Model Input Privacy and Model Output Privacy
- Federated Learning (FL) [18]: FL is machine learning on device. It can be made secure with the use of differentially private stochastic gradient descent.
- Homomorphic Encryption (HE) [19]: homomorphic encryption makes provision for the use of non-polynomial functions on encrypted data. With this capability of homomorphic encryption, it is possible to apply classical machine learning algorithms such as linear or logistic regression, naïve bayes, random forest, etc. and deep learning models on encrypted data for training and obtain predictions [20]. However, initial works such as CryptoNets [20] have a limitation of high latency. Additionally, the cryptonets do not support the popular activation functions (Relu and Sigmoid) and the pooling functions (Max Pooling). The limitations of the use of activation functions were later overcome in [21], which approximates the continuous functions of Sigmoid, Relu, and Tanh to lower degree polynomials that are based on Chebyshev polynomials. Their results indicated that the replacement of activation function with approximated lower degree polynomials adopts neural networks to be effectively used with homomorphic encryption.
- Secure Multiparty Computation (MPC) [22]: when multiple parties are involved, they can decide on functions to calculate outputs while using their private inputs. The inputs are not revealed or exposed. The concept of secure MPC has been successfully used in generative models and machine learning algorithms to protect the data from reverse engineering.
2.3. Model Weights Privacy
- Differentially private stochastic gradient descent
- Homomorphic Encryption
2.4. Related Work
- The data might come from multiple sources that use different secret keys for encryption. In such a case, the homomorphic encryption is not straight-forward. The solution to this will be MPC and HE.
- Additionally, developing deep learning models with homomorphic encryption may be hard when compared to developing shallow models. However, in this work, the developed deep learning models display high accuracy on testing.
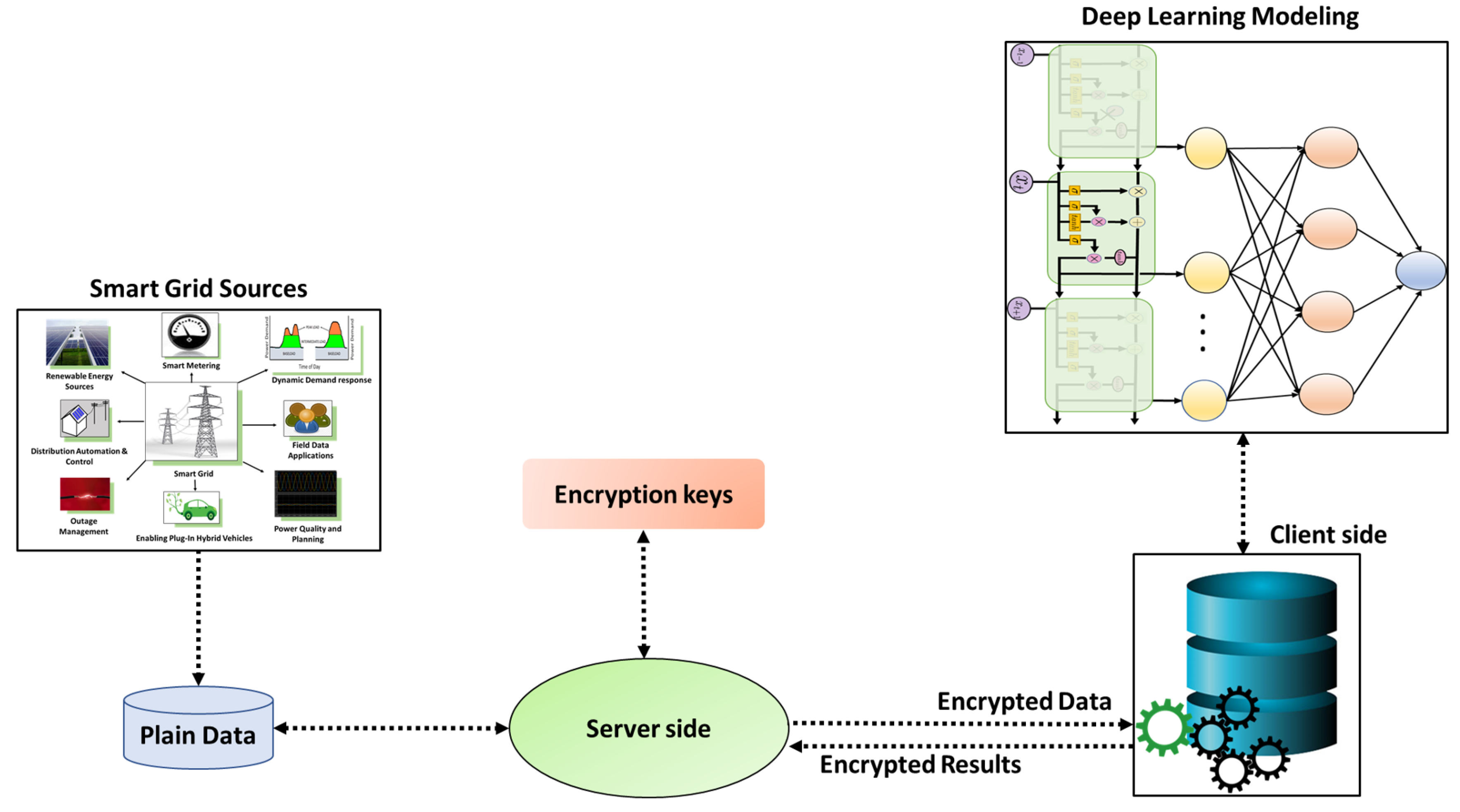
3. Proposed Methodology for Privacy-Preservation of Data-Driven Models
3.1. Data Description
3.1.1. Dataset 1
3.1.2. Dataset 2
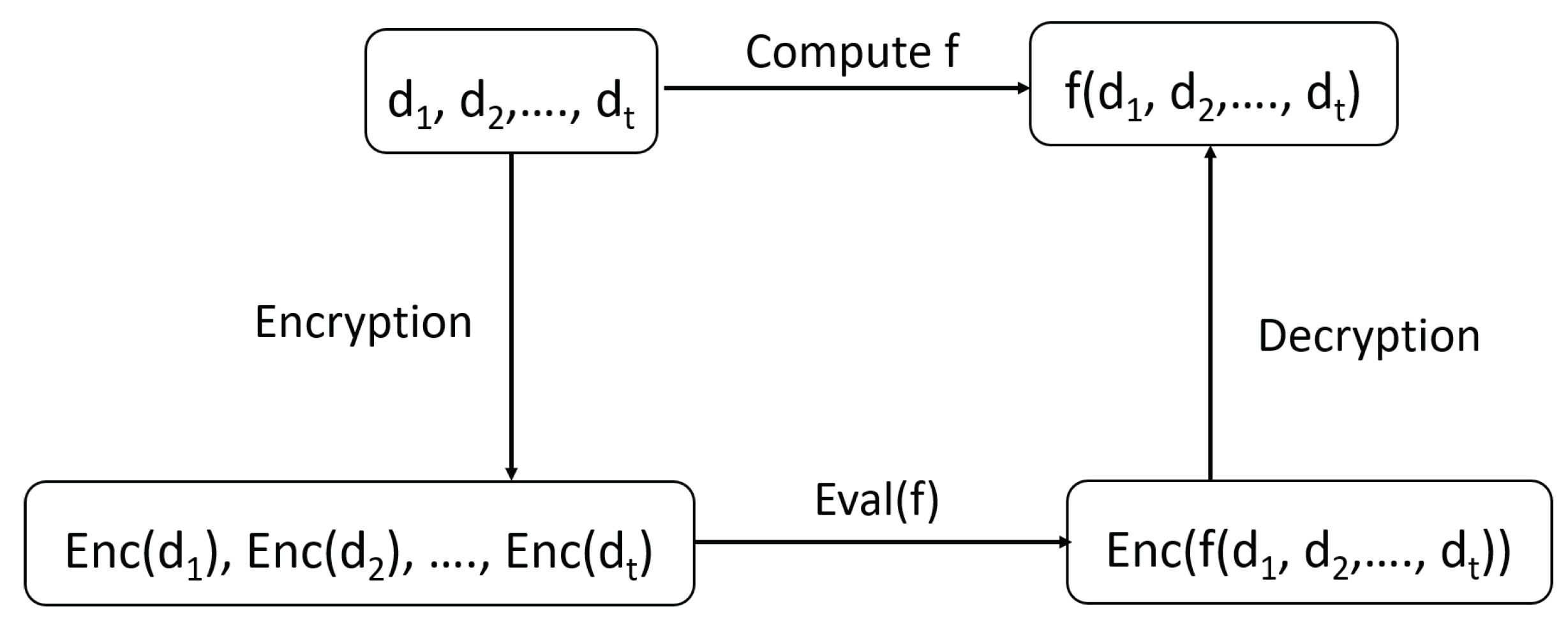
3.2. Homomorphic Encryption
- Computation of multisum between the encrypted inputs that are given to the neurons and the discretized weights at the respective neurons: the calculation of multisum uses homomorphic addition as basic operation.
- Extraction of the sign of the output at each neuron.
Encryption of the Data
| Algorithm 1 Encryption of Train Data |
|
| Algorithm 2 Decryption of Train Data |
|
| Algorithm 3 Encryption of Test Data |
|
| Algorithm 4 Decryption of Test Data |
|
- Securing data stored in cloud server.
- Enabling data analytics in regulated electric utilities.
- HE protects the systems against eavesdropping attacks after the data has reached the server. The HE potentially renders any data leaked through eavesdropping attacks or man-in-the-middle attacks indecipherable to attackers.
- HE can protect the data against unauthorized sharing.
4. Results
4.1. Case Study 1
4.2. Case Study 2 (a)
4.3. Case Study 2 (b)
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
Abbreviations
| DL | Deep Learning |
| DNN | Deep Neural Network |
| DPSGD | Differentially Private Stochastic Gradient Descent |
| DNN | Deep Neural Networks |
| FHE | Fully Homomorphic Encryption |
| FML | Federated Machine Learning |
| GPU | Graphics Processing Unit |
| HE | Homomorphic Encryption |
| LSTM | Long Short Term Memory |
| MAPE | Mean Absolute Percentage Error |
| ML | Machine Learning |
| MPC | Secure Multiparty Computation |
| NFLlib | Number Theoretic Transform based Fast Lattice Library |
| NN | Neural Networks |
| PATE | Private Aggregation of Teacher Ensembles |
| RMSE | Root Mean Square Error |
| UV | Ultraviolet |
References
- Tuballa, M.L.; Abundo, M.L. A review of the development of Smart Grid technologies. Renew. Sustain. Energy Rev. 2016, 59, 710–725. [Google Scholar] [CrossRef]
- Zhang, Y.; Huang, T.; Bompard, E.F. Big data analytics in smart grids: A review. Energy Inform. 2018, 1, 8. [Google Scholar] [CrossRef]
- Efthymiou, C.; Kalogridis, G. Smart grid privacy via anonymization of smart metering data. In Proceedings of the 2010 First IEEE International Conference on Smart Grid Communications, Gaithersburg, MD, USA, 4–6 October 2010; pp. 238–243. [Google Scholar]
- Raschka, S.; Mirjalili, V. Python Machine Learning: Machine Learning and Deep Learning with Python, Scikit-Learn, and TensorFlow 2; Packt Publishing Ltd.: Birmingham, UK, 2019. [Google Scholar]
- Li, H. Deep learning for natural language processing: Advantages and challenges. Natl. Sci. Rev. 2018, 5, 22–24. [Google Scholar] [CrossRef]
- Gjoreski, H.; Bizjak, J.; Gjoreski, M.; Gams, M. Comparing deep and classical machine learning methods for human activity recognition using wrist accelerometer. In Proceedings of the IJCAI 2016 Workshop on Deep Learning for Artificial Intelligence, New York, NY, USA, 9–15 July 2016; Volume 10. [Google Scholar]
- Global Smart Meter Total to Double by 2024 with Asia in the Lead. 2020. Available online: https://www.woodmac.com/news/editorial/global-smart-meter-total-h1-2019/ (accessed on 3 July 2020).
- Consulting, C. Big Data BlackOut: Are Utilities Powering Up Their Data Analytics? Available online: https://www.capgemini.com/wp-content/uploads/2017/07/big_data_blackout-_are_utilities_powering_up_their_data_analytics.pdf (accessed on 3 July 2020).
- Bost, R.; Popa, R.A.; Tu, S.; Goldwasser, S. Machine learning classification over encrypted data. In Proceedings of the Annual Network and Distributed System Security Symposium (NDSS), San Diego, CA, USA, 8–11 February 2015; Volume 4324, p. 4325. [Google Scholar]
- Rivest, R.L.; Adleman, L.; Dertouzos, M.L. On data banks and privacy homomorphisms. Found. Secur. Comput. 1978, 4, 169–180. [Google Scholar]
- Ajtai, M.; Dwork, C. A public-key cryptosystem with worst-case/average-case equivalence. In Proceedings of the Twenty-Ninth Annual ACM Symposium on Theory of Computing, El Paso, TX, USA, 4–6 May 1997; pp. 284–293. [Google Scholar]
- Gentry, C. Fully homomorphic encryption using ideal lattices. In Proceedings of the Forty-First Annual ACM Symposium on Theory of Computing, Bethesda, MD, USA, 31 May–2 June 2009; pp. 169–178. [Google Scholar]
- Gilad-Bachrach, R.; Dowlin, N.; Laine, K.; Lauter, K.; Naehrig, M.; Wernsing, J. Cryptonets: Applying neural networks to encrypted data with high throughput and accuracy. In Proceedings of the International Conference on Machine Learning, New York, NY, USA, 20–22 June 2016; pp. 201–210. [Google Scholar]
- Bourse, F.; Minelli, M.; Minihold, M.; Paillier, P. Fast homomorphic evaluation of deep discretized neural networks. In Annual International Cryptology Conference; Springer: Berlin/Heidelberg, Germany, 2018; pp. 483–512. [Google Scholar]
- Carlini, N.; Liu, C.; Erlingsson, Ú.; Kos, J.; Song, D. The secret sharer: Evaluating and testing unintended memorization in neural networks. In Proceedings of the 28th {USENIX} Security Symposium ({USENIX} Security 19), Santa Clara, CA, USA, 14–16 August 2019; pp. 267–284. [Google Scholar]
- Rajkumar, A.; Agarwal, S. A differentially private stochastic gradient descent algorithm for multiparty classification. In Proceedings of the Artificial Intelligence and Statistics, La Palma, Spain, 21–23 April 2012; pp. 933–941. [Google Scholar]
- Papernot, N.; Song, S.; Mironov, I.; Raghunathan, A.; Talwar, K.; Erlingsson, Ú. Scalable private learning with pate. arXiv 2018, arXiv:1802.08908. [Google Scholar]
- Smith, V.; Chiang, C.K.; Sanjabi, M.; Talwalkar, A.S. Federated multi-task learning. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 4424–4434. [Google Scholar]
- Takabi, H.; Hesamifard, E.; Ghasemi, M. Privacy preserving multi-party machine learning with homomorphic encryption. In Proceedings of the 29th Annual Conference on Neural Information Processing Systems (NIPS), Barcelona, Spain, 5–10 December 2016. [Google Scholar]
- Gilad-Bachrach, R.; Finley, T.W.; Bilenko, M.; Xie, P. Neural Networks for Encrypted Data. U.S. Patent 9,946,970, 17 April 2018. [Google Scholar]
- Hesamifard, E.; Takabi, H.; Ghasemi, M.; Wright, R.N. Privacy-preserving machine learning as a service. Proc. Priv. Enhancing Technol. 2018, 2018, 123–142. [Google Scholar] [CrossRef] [Green Version]
- Miyajima, H.; Shigei, N.; Miyajima, H.; Miyanishi, Y.; Kitagami, S.; Shiratori, N. New privacy preserving back propagation learning for secure multiparty computation. IAENG Int. J. Comput. Sci. 2016, 43, 270–276. [Google Scholar]
- Kim, H.; Kim, S.H.; Hwang, J.Y.; Seo, C. Efficient privacy-preserving machine learning for blockchain network. IEEE Access 2019, 7, 136481–136495. [Google Scholar] [CrossRef]
- Yang, Q.; Liu, Y.; Chen, T.; Tong, Y. Federated machine learning: Concept and applications. ACM Trans. Intell. Syst. Technol. (TIST) 2019, 10, 1–19. [Google Scholar] [CrossRef]
- Al-Rubaie, M.; Chang, J.M. Privacy-preserving machine learning: Threats and solutions. IEEE Secur. Priv. 2019, 17, 49–58. [Google Scholar] [CrossRef] [Green Version]
- Abadi, M.; Chu, A.; Goodfellow, I.; McMahan, H.B.; Mironov, I.; Talwar, K.; Zhang, L. Deep learning with differential privacy. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 308–318. [Google Scholar]
- Truex, S.; Baracaldo, N.; Anwar, A.; Steinke, T.; Ludwig, H.; Zhang, R.; Zhou, Y. A hybrid approach to privacy-preserving federated learning. In Proceedings of the 12th ACM Workshop on Artificial Intelligence and Security, Orlando, FL, USA, 13 November 2019; pp. 1–11. [Google Scholar]
- Kuri, S.; Hayashi, T.; Omori, T.; Ozawa, S.; Aono, Y.; Wang, L.; Moriai, S. Privacy preserving extreme learning machine using additively homomorphic encryption. In Proceedings of the 2017 IEEE Symposium Series on Computational Intelligence (SSCI), Honolulu, HI, USA, 27 November–1 December 2017; pp. 1–8. [Google Scholar]
- Ma, X.; Zhang, F.; Chen, X.; Shen, J. Privacy preserving multi-party computation delegation for deep learning in cloud computing. Inf. Sci. 2018, 459, 103–116. [Google Scholar] [CrossRef]
- Shokri, R.; Shmatikov, V. Privacy-preserving deep learning. In Proceedings of the 22nd ACM SIGSAC Conference on Computer and Communications Security, Denver, CO, USA, 12–16 October 2015; pp. 1310–1321. [Google Scholar]
- Van Dijk, M.; Gentry, C.; Halevi, S.; Vaikuntanathan, V. Fully homomorphic encryption over the integers. In Proceedings of the Annual International Conference on the Theory and Applications of Cryptographic Techniques, French Riviera, France, 30 May–3 June 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 24–43. [Google Scholar]
- Brenner, M.; Dai, W.; Halevi, S.; Han, K.; Jalali, A.; Kim, M.; Laine, K.; Malozemoff, A.; Paillier, P.; Polyakov, Y.; et al. A Standard API for RLWE-Based Homomorphic Encryption; Technical Report; HomomorphicEncryption.org: Redmond, WA, USA, 2017. [Google Scholar]
- Tsiounis, Y.; Yung, M. On the security of ElGamal based encryption. In International Workshop on Public Key Cryptography; Springer: Berlin/Heidelberg, Germany, 1998; pp. 117–134. [Google Scholar]
- Patel, N.; Oza, P.; Agrawal, S. Homomorphic Cryptography and Its Applications in Various Domains. In International Conference on Innovative Computing and Communications; Springer: Berlin/Heidelberg, Germany, 2019; pp. 269–278. [Google Scholar]
- El Makkaoui, K.; Ezzati, A.; Beni-Hssane, A. Securely adapt a Paillier encryption scheme to protect the data confidentiality in the cloud environment. In Proceedings of the International Conference on Big Data and Advanced Wireless Technologies, Blagoevgrad, Bulgaria, 10–11 November 2016; pp. 1–3. [Google Scholar]
- Halevi, S.; Shoup, V. Algorithms in helib. In Proceedings of the Annual Cryptology Conference, Santa Barbara, CA, USA, 17–21 August 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 554–571. [Google Scholar]
- Dai, W.; Sunar, B. CuHE: A homomorphic encryption accelerator library. In Proceedings of the International Conference on Cryptography and Information Security in the Balkans, Koper, Slovenia, 3–4 September 2015; Springer: Berlin/Heidelberg, Germany, 2015; pp. 169–186. [Google Scholar]
- Chillotti, I.; Gama, N.; Georgieva, M.; Izabachène, M. TFHE: Fast Fully Homomorphic Encryption Library, August 2016. Available online: https://tfhe.github.io/tfhe/ (accessed on 15 March 2012).
- Aguilar-Melchor, C.; Barrier, J.; Guelton, S.; Guinet, A.; Killijian, M.O.; Lepoint, T. NFLlib: NTT-based fast lattice library. In Proceedings of the Cryptographers’ Track at the RSA Conference, San Francisco, CA, USA, 29 February–4 March 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 341–356. [Google Scholar]
- Laine, K.; Player, R. Simple Encrypted Arithmetic Library-Seal (v2. 0); Technical Report; Microsoft Research: Redmond, WA, USA, 2016. [Google Scholar]
- Crockett, E.; Peikert, C. Λoλ: Functional Lattice Cryptography. In Proceedings of the 2016 ACM SIGSAC Conference on Computer and Communications Security, Vienna, Austria, 24–28 October 2016; pp. 993–1005. [Google Scholar]
- Polyakov, Y.; Rohloff, K.; Ryan, G.W. PALISADE Lattice Cryptography Library User Manual; Technical Report; Cybersecurity Research Center, New Jersey Institute ofTechnology (NJIT): Newark, NJ, USA, 2017. [Google Scholar]
- Takagi, T.; Peyrin, T. Advances in Cryptology–ASIACRYPT 2017. In Proceedings of the 23rd International Conference on the Theory and Applications of Cryptology and Information Security, Hong Kong, China, 3–7 December 2017; Springer: Berlin/Heidelberg, Germany, 2017; Volume 10625. [Google Scholar]
- Lattigo 1.3.1. 2020. Available online: http://github.com/ldsec/lattigo (accessed on 3 July 2020).
- Zainab, A.; Refaat, S.S.; Syed, D.; Ghrayeb, A.; Abu-Rub, H. Faulted Line Identification and Localization in Power System using Machine Learning Techniques. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 2975–2981. [Google Scholar]
- Li, W.; Deka, D.; Chertkov, M.; Wang, M. Real-Time Faulted Line Localization and PMU Placement in Power Systems Through Convolutional Neural Networks. IEEE Trans. Power Syst. 2019, 34, 4640–4651. [Google Scholar] [CrossRef] [Green Version]
- Dark Sky API—Weather Conditions. Available online: https://darksky.net/dev/ (accessed on 3 July 2020).
- Syed, D.; Refaat, S.S.; Abu-Rub, H.; Bouhali, O.; Zainab, A.; Xie, L. Averaging Ensembles Model for Forecasting of Short-term Load in Smart Grids. In Proceedings of the 2019 IEEE International Conference on Big Data (Big Data), Los Angeles, CA, USA, 9–12 December 2019; pp. 2931–2938. [Google Scholar]
- Brakerski, Z.; Gentry, C.; Vaikuntanathan, V. (Leveled) fully homomorphic encryption without bootstrapping. ACM Trans. Comput. Theory (TOCT) 2014, 6, 1–36. [Google Scholar] [CrossRef]
- Domingo-Ferrer, J. A provably secure additive and multiplicative privacy homomorphism. In International Conference on Information Security; Springer: Berlin/Heidelberg, Germany, 2002; pp. 471–483. [Google Scholar]
- Soykan, E.U.; Bilgin, Z.; Ersoy, M.A.; Tomur, E. Differentially Private Deep Learning for Load Forecasting on Smart Grid. In Proceedings of the 2019 IEEE Globecom Workshops (GC Wkshps), Waikoloa, HI, USA, 9–13 December 2019; pp. 1–6. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Implementation | Description |
|---|---|
| HELib [36] | the low-level library implements HE with faster evaluation time employing optimized Brakerski-Gentry-Vaikuntanathan (BGV) scheme with bootstrapping. |
| cuHE [37] | highly optimized GPU-accelerated library for Homomorphic encryption. |
| TFHE [38] | open source gate-by-gate bootstrapping library which evaluates homomorphic encryption of binary gates, negation, and MUX gate operations and performs computation over encrypted data. |
| NFLlib [39] | open-source Number Theoretic Transform based Fast Lattice Library which uses low-level processor functionalities. |
| SEAL [40] | an extensively employed open-source library from Microsoft that supports BGV and Cheon, Kim, Kim, and Song (CKKS) encryption schemes. |
| [41] | open-source Haskell library for functional lattice-based cryptography. |
| PALISADE [42] | open-source library for implementations of lattice-based encryption building blocks and HE scheme. |
| HeaAN [43] | open-source implementation of HE encryption scheme using approximate arithmetic of numbers. |
| Lattigo [44] | library for lattice-based cryptography and MPC, written in Golang (Go) language. |
| Model Name | DNN | HE + DNN |
|---|---|---|
| Accuracy on the validation dataset | 98.32 | 97.71 |
| Accuracy on the test dataset | 99.98 | 98.59 |
| Execution time (s) | 20.61 | 23.64 |
| The computational complexity of activation function | O(1) | O(1) |
| Model Name | Validation Dataset | Test Dataset | ||
|---|---|---|---|---|
| RMSE (MWh) | Coefficient of Variation (CV) (%) | RMSE (MWh) | CV (%) | |
| LR | 0.0248 | 7.49 | 0.0250 | 7.55 |
| HE + LR | 0.0352 | 10.63 | 0.0374 | 11.30 |
| Model Name | Testing Dataset | |
|---|---|---|
| RMSE (MWh) | Mean Absolute Percentage Error (MAPE) (%) | |
| LR | 28.18 | 2.007 |
| HE+LR | 31.65 | 6.15 |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Syed, D.; Refaat, S.S.; Bouhali, O. Privacy Preservation of Data-Driven Models in Smart Grids Using Homomorphic Encryption. Information 2020, 11, 357. https://doi.org/10.3390/info11070357
Syed D, Refaat SS, Bouhali O. Privacy Preservation of Data-Driven Models in Smart Grids Using Homomorphic Encryption. Information. 2020; 11(7):357. https://doi.org/10.3390/info11070357
Chicago/Turabian StyleSyed, Dabeeruddin, Shady S. Refaat, and Othmane Bouhali. 2020. "Privacy Preservation of Data-Driven Models in Smart Grids Using Homomorphic Encryption" Information 11, no. 7: 357. https://doi.org/10.3390/info11070357
APA StyleSyed, D., Refaat, S. S., & Bouhali, O. (2020). Privacy Preservation of Data-Driven Models in Smart Grids Using Homomorphic Encryption. Information, 11(7), 357. https://doi.org/10.3390/info11070357