Dimensionality Reduction for Human Activity Recognition Using Google Colab


Abstract
:1. Introduction
2. Problem Statement
3. Related Work
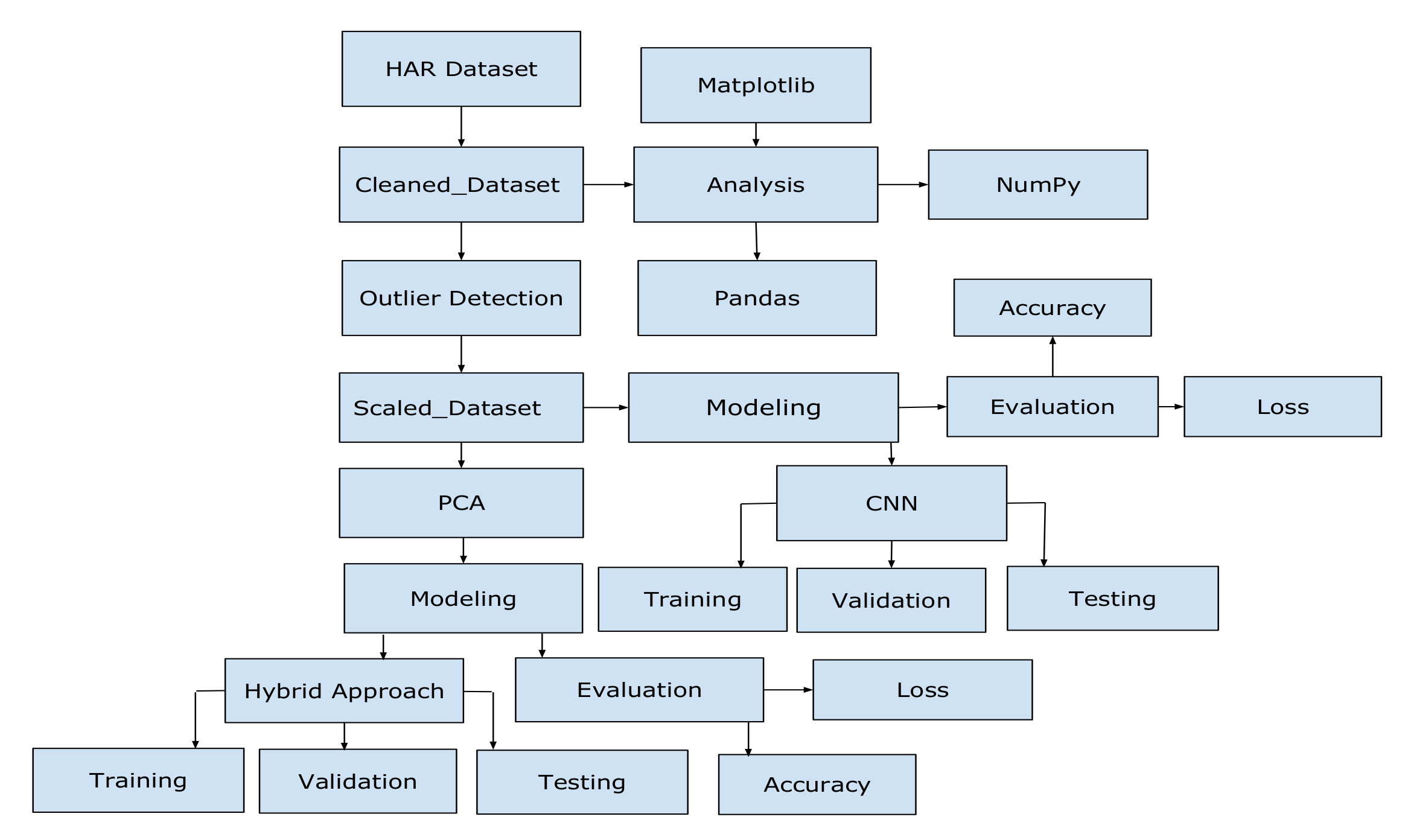
4. Proposed Methodology
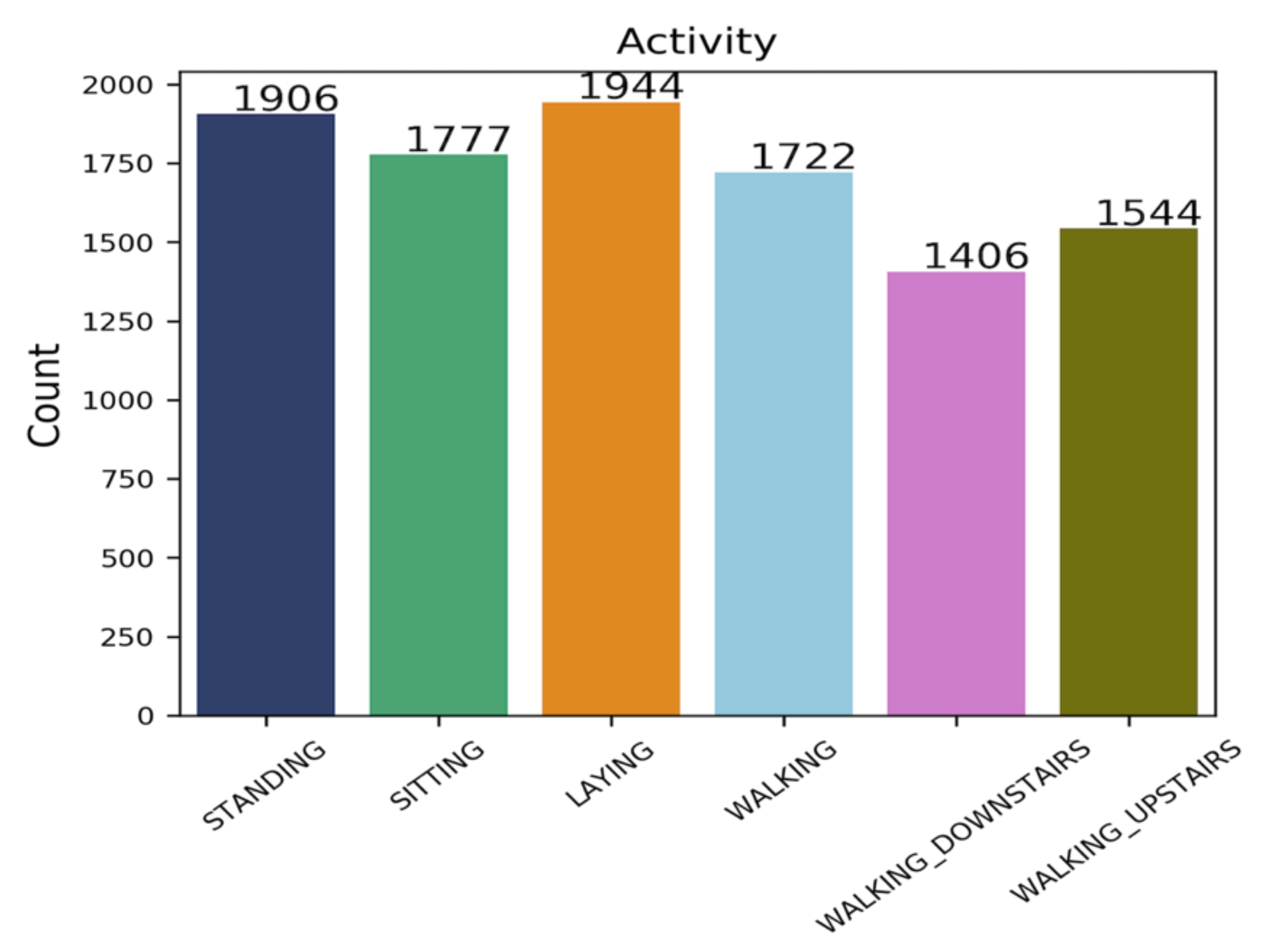
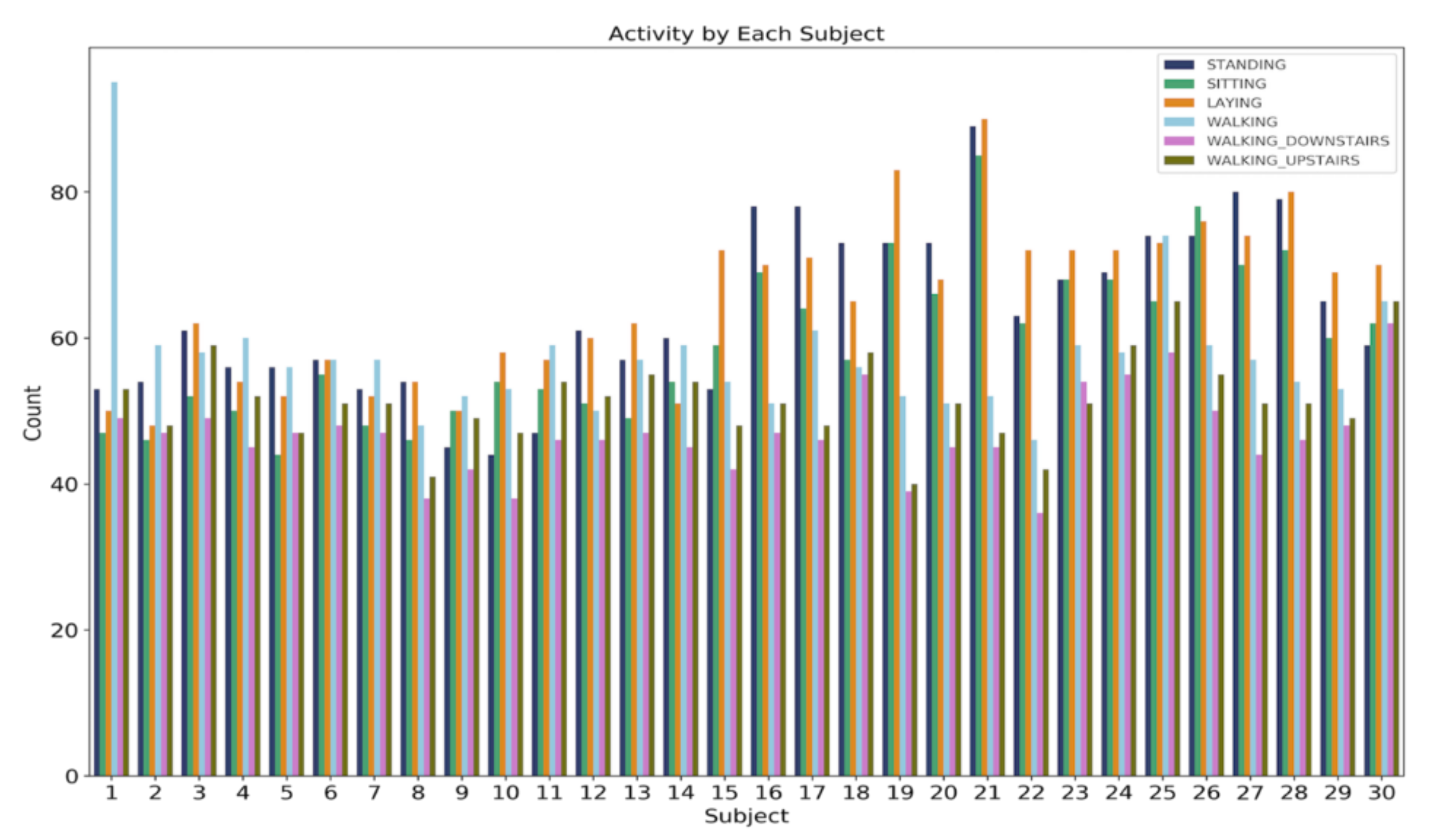
4.1. Dataset Information
4.2. Data Cleaning
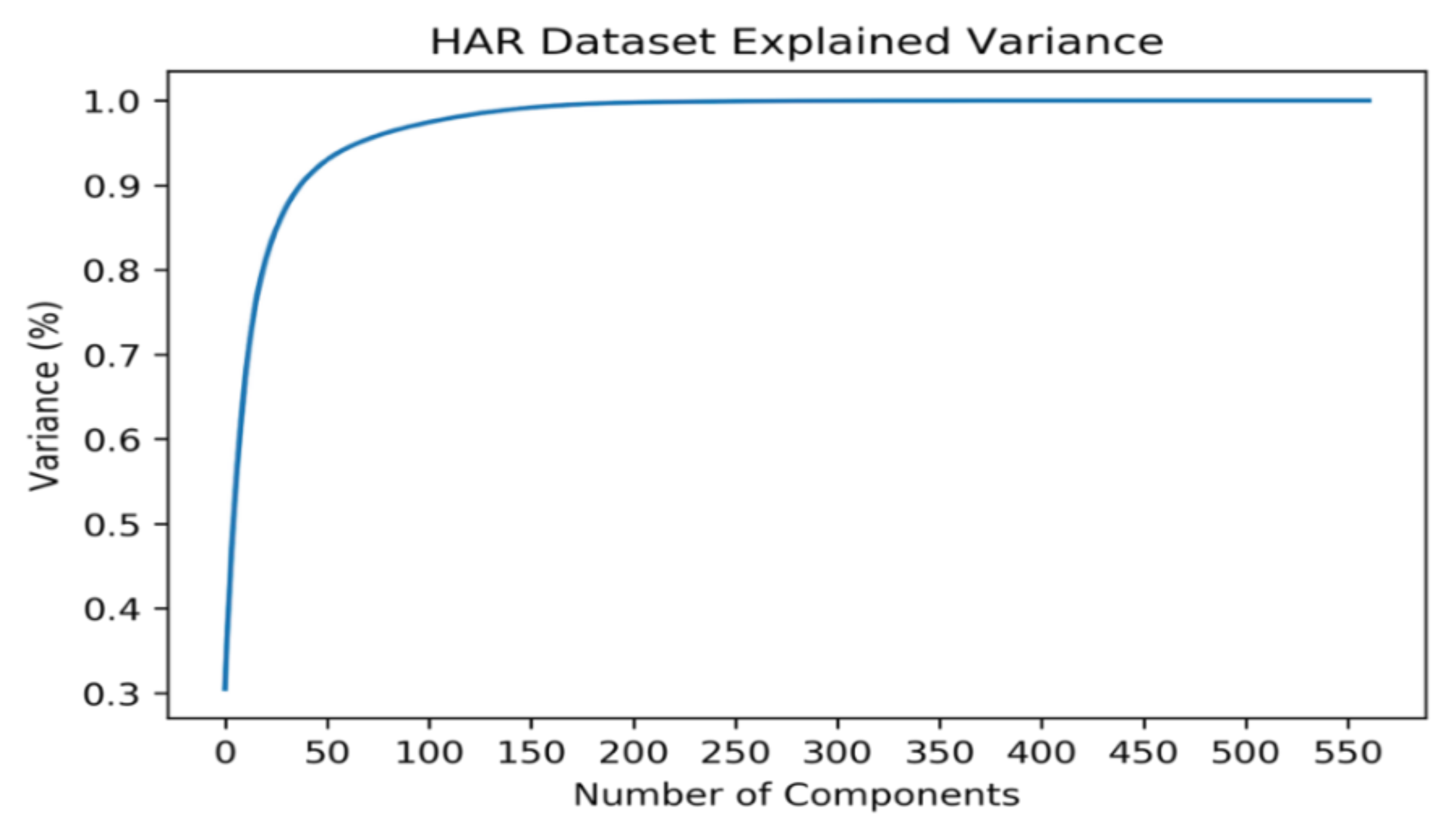
4.3. Applying PCA
4.4. Dataset Analysis
4.5. Google Colab
4.6. Keras
- Define our model: first, we create a Sequential model and add configured layers.
- Compile our model: after that, we specify loss function and optimizers and call the compile function on the model.
- Fit our model: in the next step, we call the fit function on the model and train the model on a sample of data.
- Make predictions: finally, we call functions named evaluate or predict and use the model to generate predictions on new data [34].
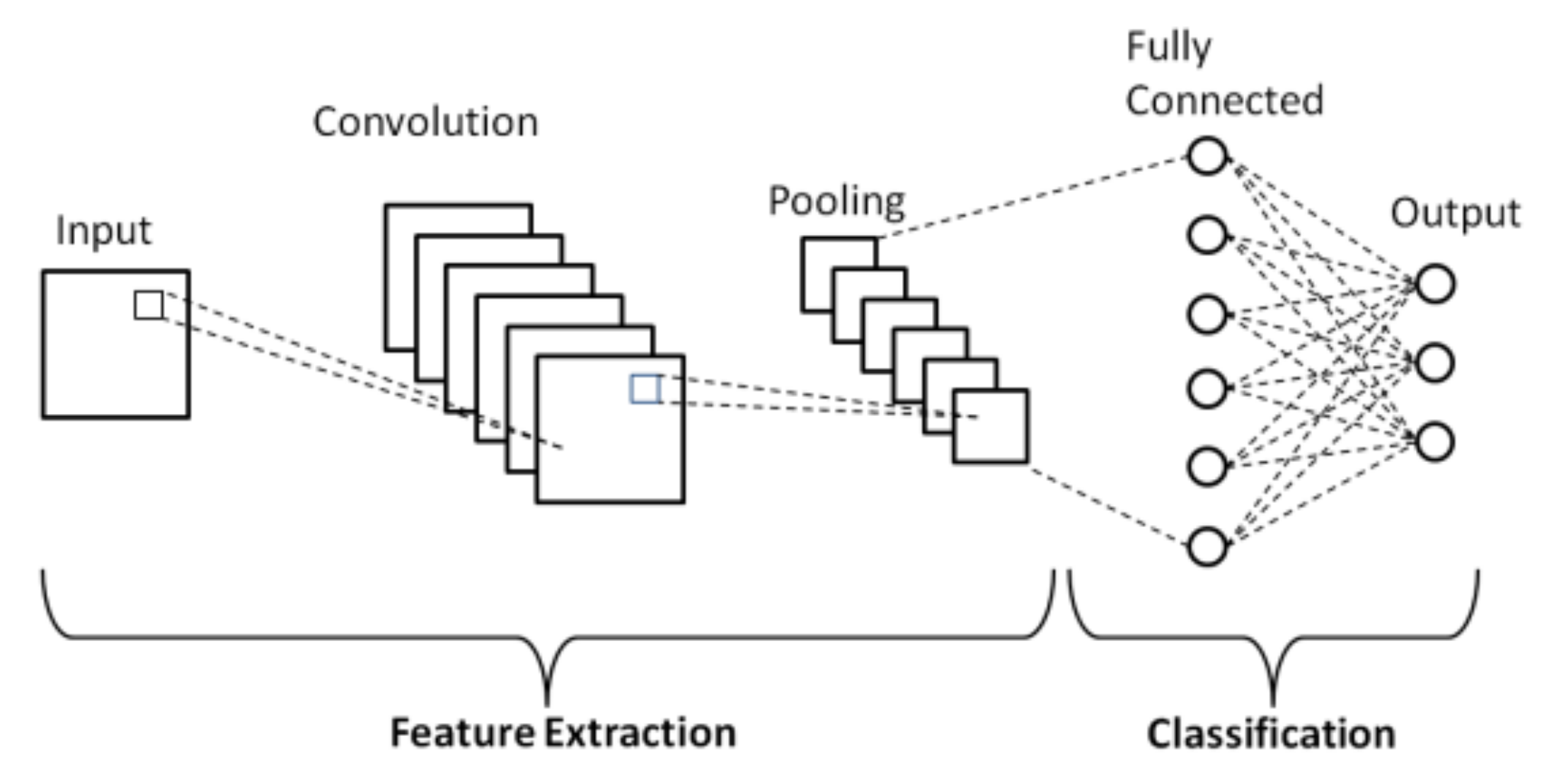
4.7. Convolutional Neural Network
- First is a convolution tool that splits the various features of the dataset for the analysis.
- Second is a fully connected layer that uses the output of the convolution layer to predict the best description for the activity.
- Convolutional layer: in this layer, a feature map is created to predict the class probabilities for each feature by applying a filter that scans the features.
- Pooling layer: this layer scales down the amount of information the convolutional layer generated for each feature and maintains only the most essential information.
- Fully connected input layer: this layer “flattens” the outputs generated by previous layers and turns them into a single vector that could be used as an input for the next layer.
- Fully connected layer: this layer predicts an accurate label. It does that by applying weights over the input generated by the feature analysis.
- Fully connected output layer: it generates the final probabilities for determining a class for the activity [35].
4.8. Training Parameters
- Number of Epochs: The number of epochs is a hyperparameter that defines the number of times that the learning algorithm works through the entire training dataset. One epoch means that each sample in the training dataset will have an opportunity to update the internal model parameters. An epoch consists of one or more batches. The number of epochs allow the learning algorithm to run until the error from the model has been sufficiently minimized [38].
- Dense Layer: a “dense” layer that takes that vector and generates probabilities for six target labels, using a “Softmax” activation function [39].
- Optimizer: we use the “adam” optimize, which adjusts learning rate throughout training.
- Loss function: we use a “categorical_crossentropy” loss function, a common choice for classification. The lower the score, the better the model is performing.
- Metrics: we use the “accuracy” metric to get an accuracy score when the model runs on the testing set.
5. Experimental Data Analysis
6. Experiment
6.1. Experimental Setup
6.2. Implementation of the Model
- True Positive (TP): how often the model correctly predicts the right activity.
- True Negative (TN): indicates how the model correctly predicts a person not doing that particular activity.
- False Positive (FP): how often the model predicts a person doing the particular activity when he/she is not actually doing that activity.
- False Negative (FN): indicates how often the model predicts a person not doing the particular activity when he/she is in fact doing that activity.
- Accuracy: accuracy is simply a proportion of observations correctly predicted to the total observations [40].
- Loss in CNN: loss is the quantitative measure of deviation or difference between the predicted output and the actual output. It measures the mistakes made by the network in predicting the output.
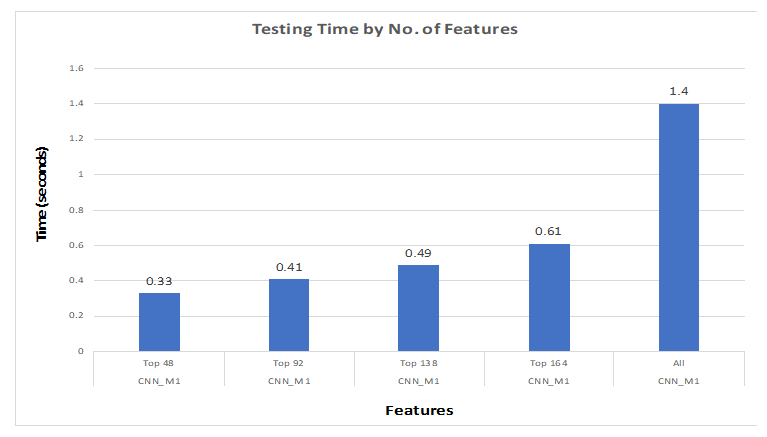
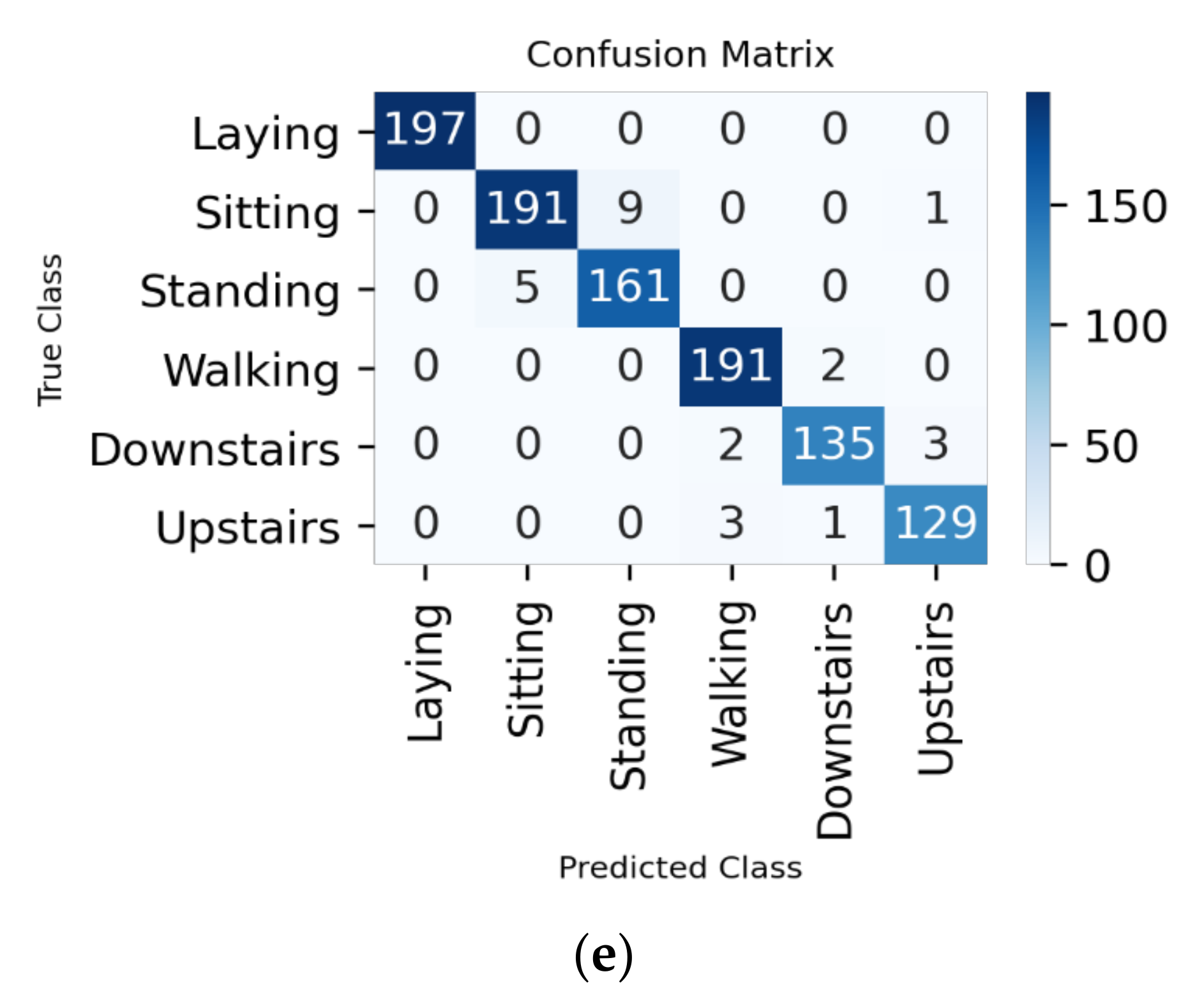
7. Implementation Details and Results
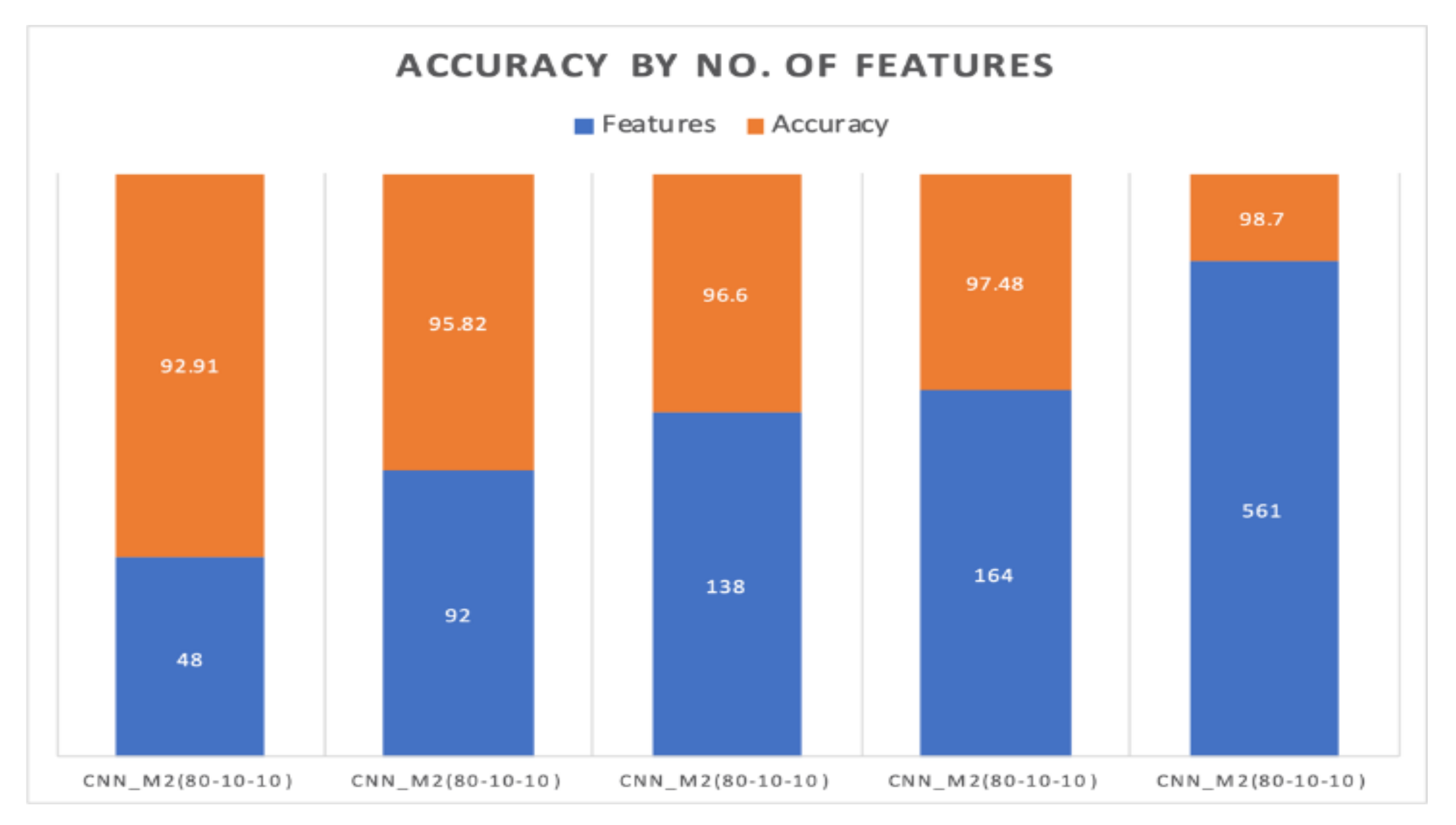
- Input Data: First, we have 7209 samples and 561 features of the dataset as an input to the CNN model. We have got those from the training part of the dataset.
- First 1D CNN Layer: The first layer defines a filter of kernel size 2. If we define one filter in the first layer, then it would allow the neural network to learn only one feature. This might not be enough; therefore, we have defined 128 filters. This allows us to train 128 different features on the first layer of the network. We get (560 × 128) neuron matrix as an output of the first neural network layer. The individual columns of the output matrix hold the weights of one single filter. With the defined kernel size and length of the input matrix, each filter will be containing 560 weights.
- Second 1D CNN Layer: The result we get from the first CNN will get fed into the second CNN layer. We will define 64 different filters to be trained on this level. The logic of the first layer applies here as well, so the output matrix will have a size of (559 × 64).
- Max Pooling Layer: Because we need to reduce the complexity of the output and prevent overfitting of the data, a pooling layer is often used after a CNN layer. In our work, we have chosen two as a pooling size. This means that the size of the output matrix is only half of the input matrix. The size of the matrix is (279 × 64).
- Flatten Layer: There is a ‘flatten’ layer in between the convolutional layer and the fully connected layer. A two-dimensional matrix (279 × 64) of features is transformed into a vector (17,856) by flattening. After that, the vector could be fed into a fully connected neural network classifier.
- Dense Layer: In this layer, the results of the convolutional layers are generally fed through one or more neural layers to generate a prediction.
- Fully Connected Layer with “Softmax” Activation: The final layer reduces the vector of height 64 to a vector of six since we have six classes that we want to predict. This reduction process is achieved by another matrix multiplication. We have used “Softmax” as the activation function and it enforces all six outputs of the neural network to sum up to one. Therefore, the output value will be representing the probability for each of the six classes [41].
- Input Data: First, we have 7209 samples and 164 features of the dataset as an input to the CNN model. We have got those from the training part of the dataset.
- First 1D CNN Layer: The first layer defines a filter of kernel size two. Here, we have defined 128 filters. This allows us to train 128 different features on the first layer of the network. We get (199 × 128) neuron matrix as an output of the first neural network layer. The individual columns of the output matrix hold the weights of one single filter. With the defined kernel size and length of the input matrix, each filter will contain 199 weights.
- Second 1D CNN layer: The result we get from the first CNN will be fed into the second CNN layer. We will define 64 different filters to be trained on this level. The logic of the first layer applies here as well, so the output matrix will have a size of (198 × 64).
- Max pooling layer: In this case, we have chosen two as a pooling size. This means that the size of the output matrix of this layer is only half of the input matrix. The size of the matrix is (99 × 64).
- Flatten Layer: A two-dimensional matrix (99 × 64) of features is transformed into a vector (6336) by flattening. After that, the vector could be fed into a fully connected neural network classifier.
- Dense Layer: In this layer, the results of the convolutional layers are generally fed through one or more neural layers to generate a prediction.
- Fully Connected Layer with “Softmax” Activation: The final layer reduces the vector of height 64 to a vector of 6 since we have 6 classes that we want to predict. This reduction process is achieved by another matrix multiplication. We have used “Softmax” as the activation function and it enforces all six outputs of the neural network to sum up to one. Therefore, the output value will represent the probability for each of the six classes [41].
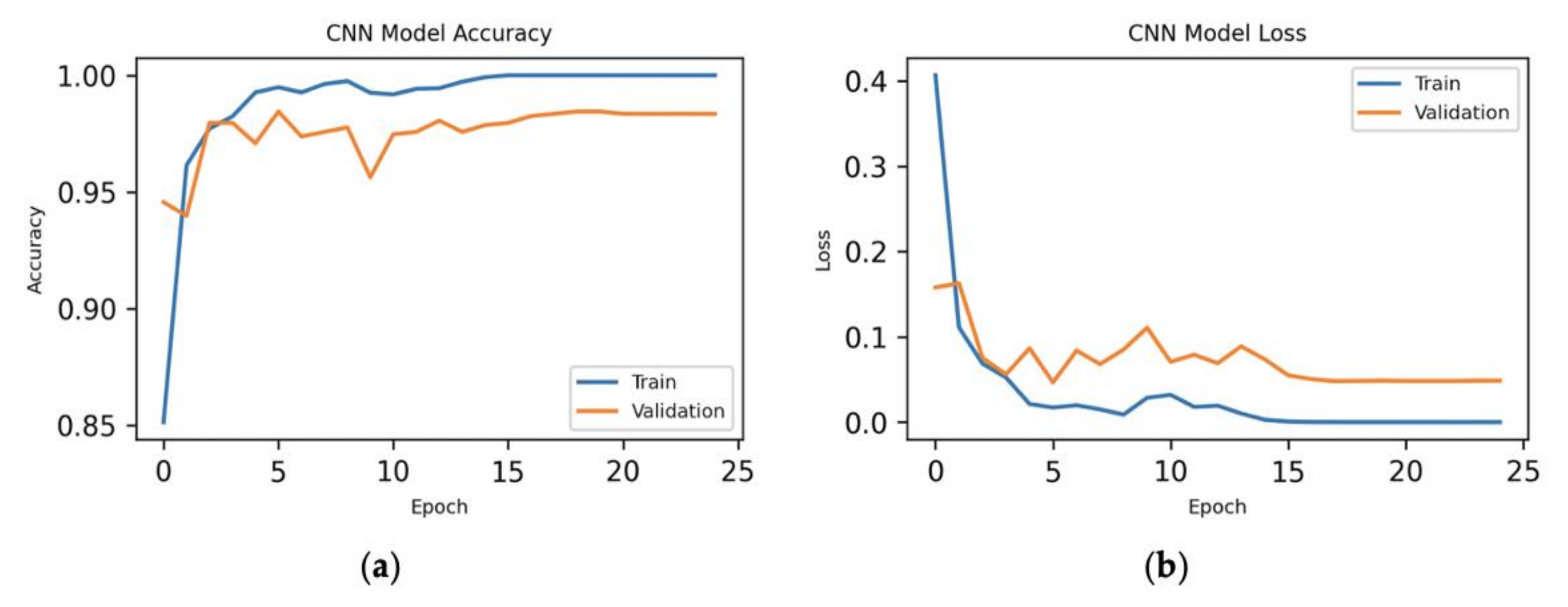
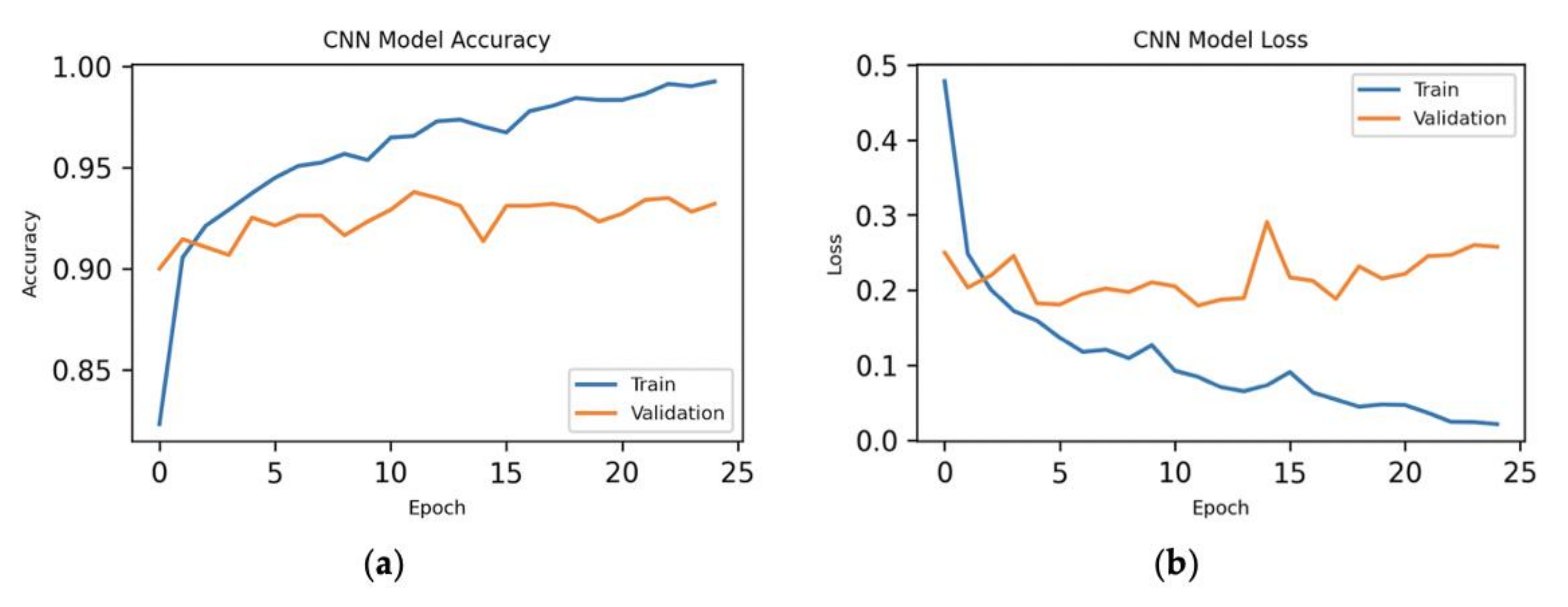
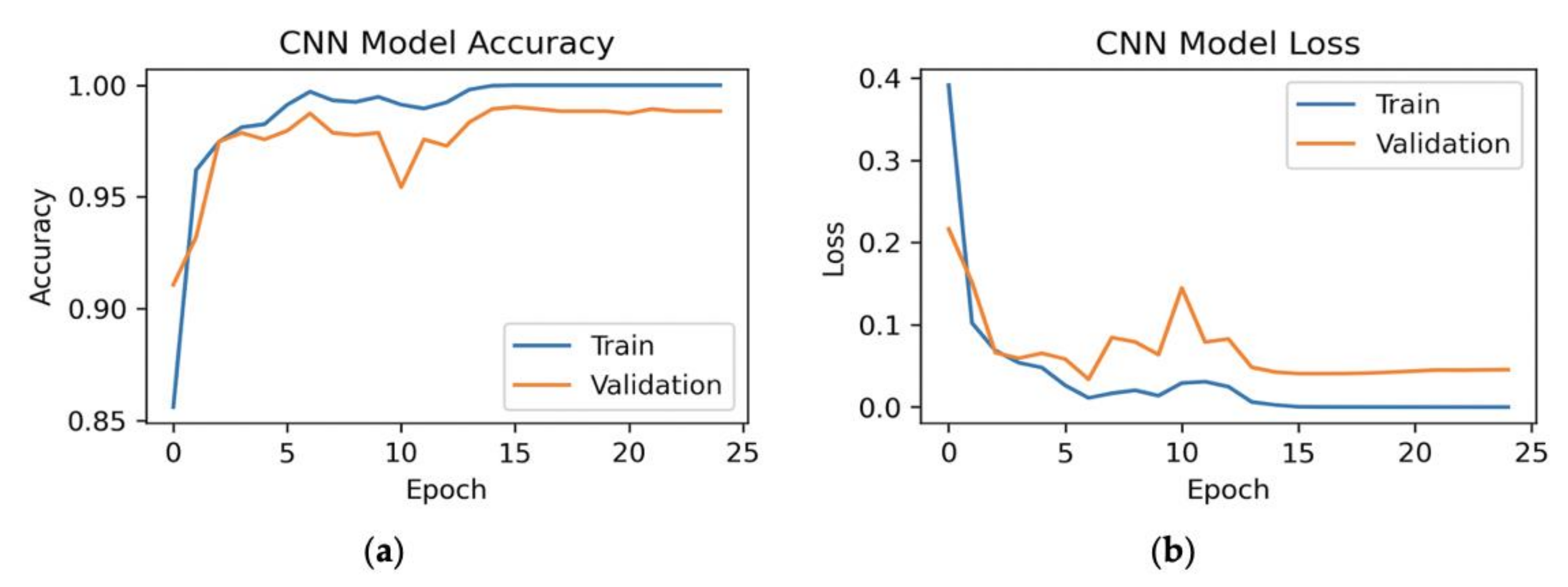
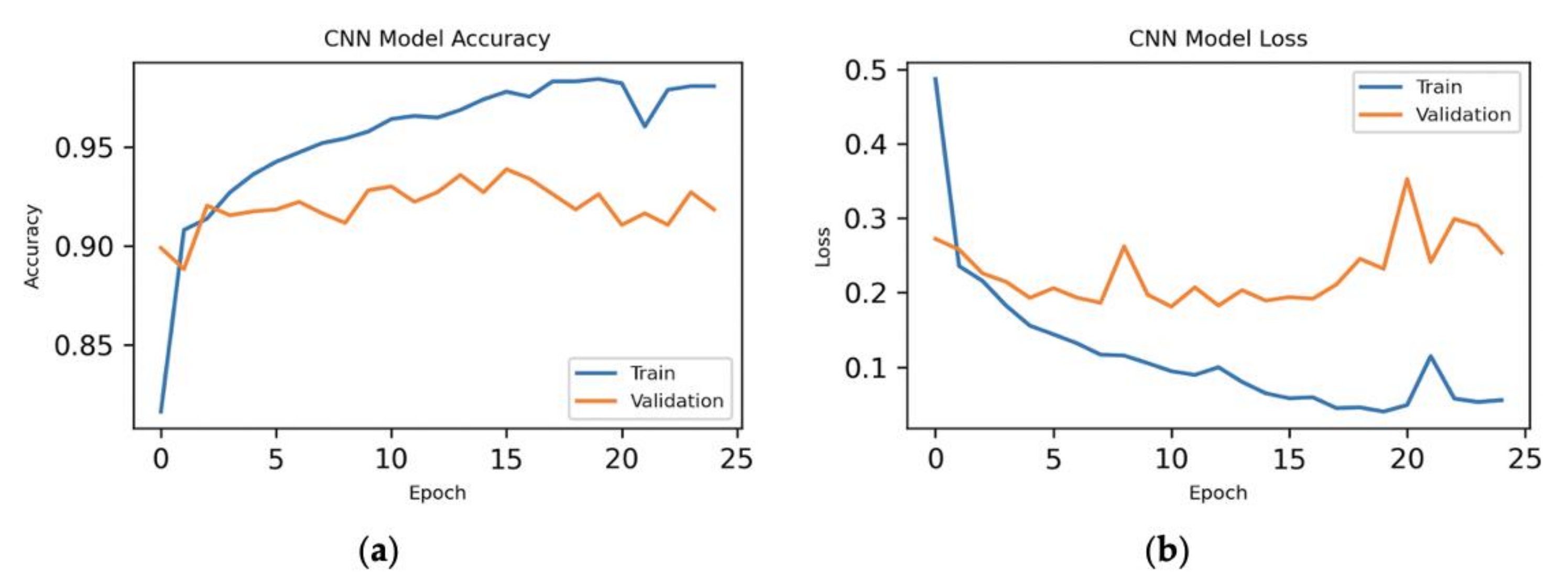
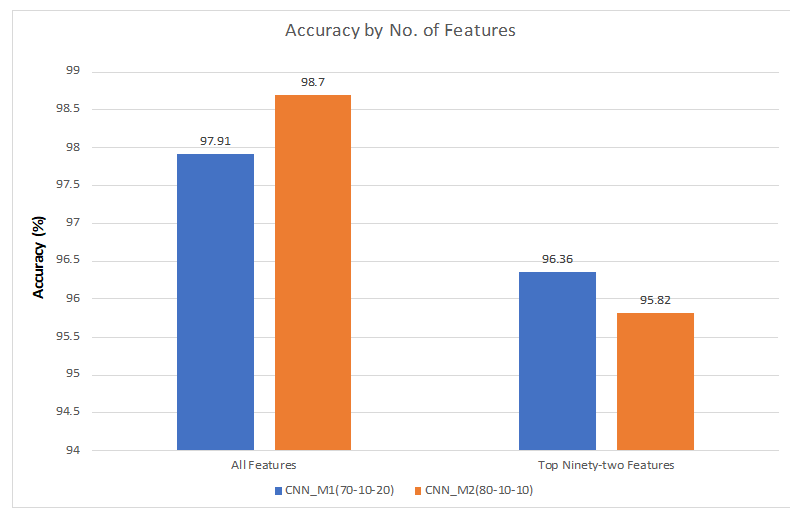
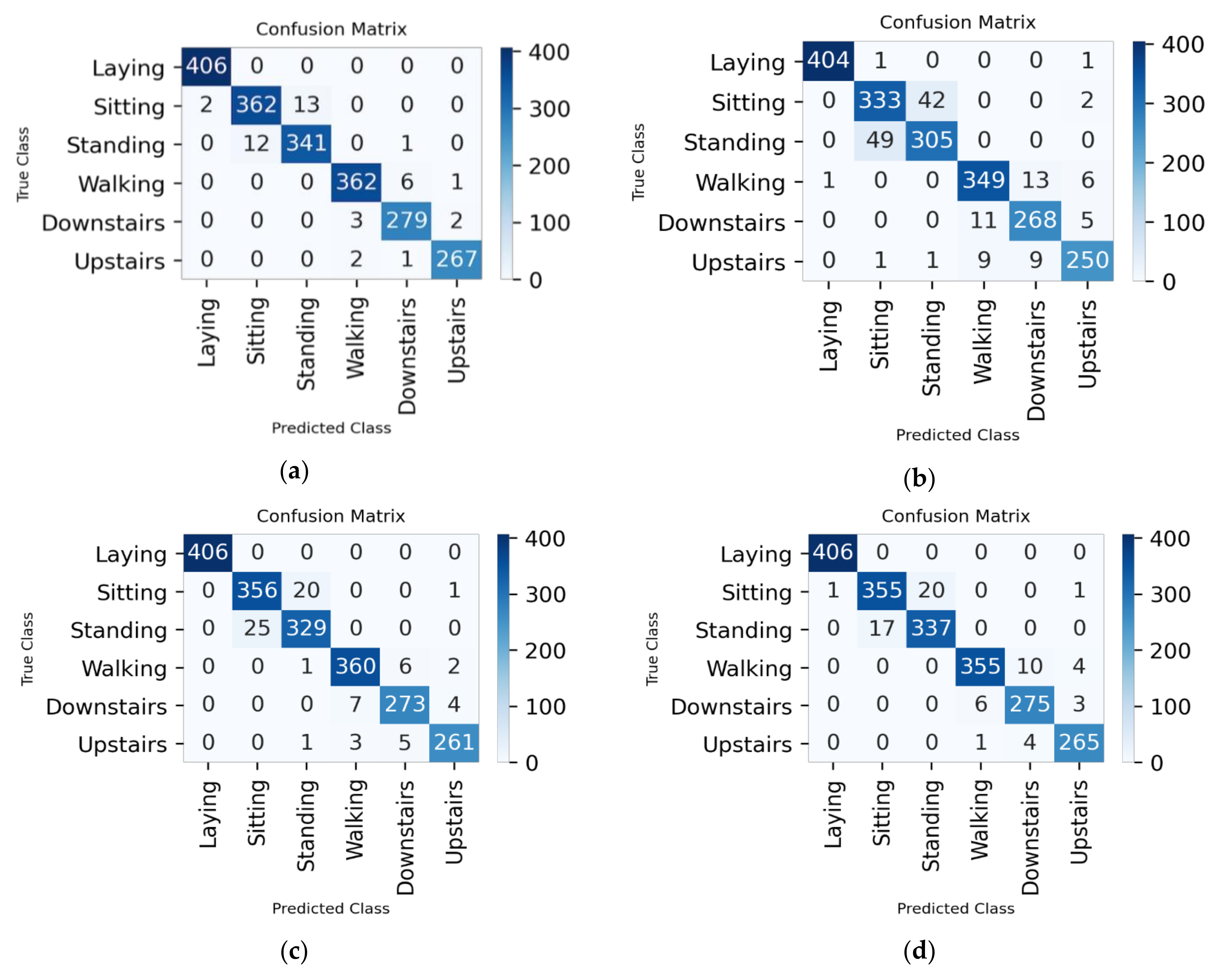
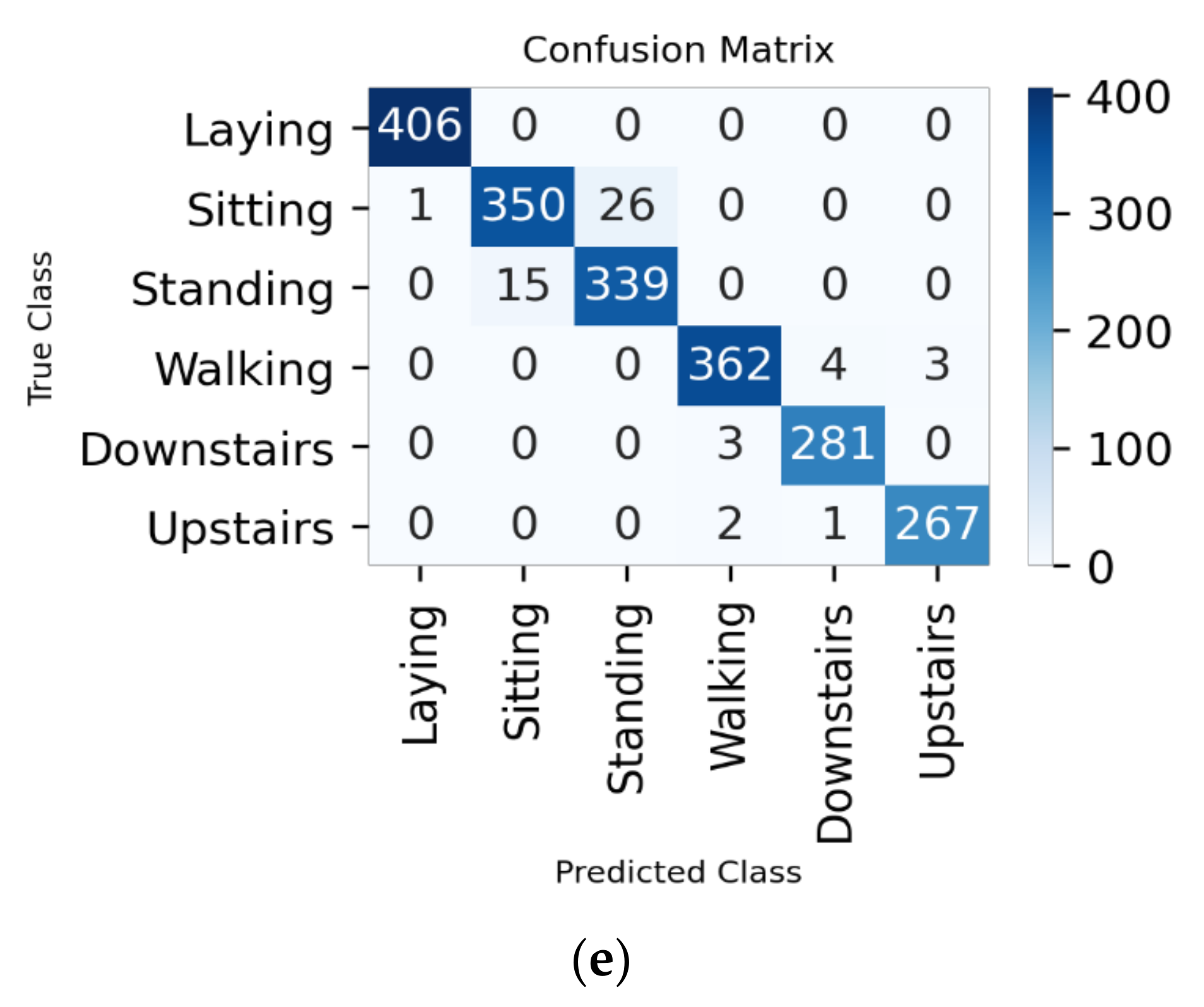
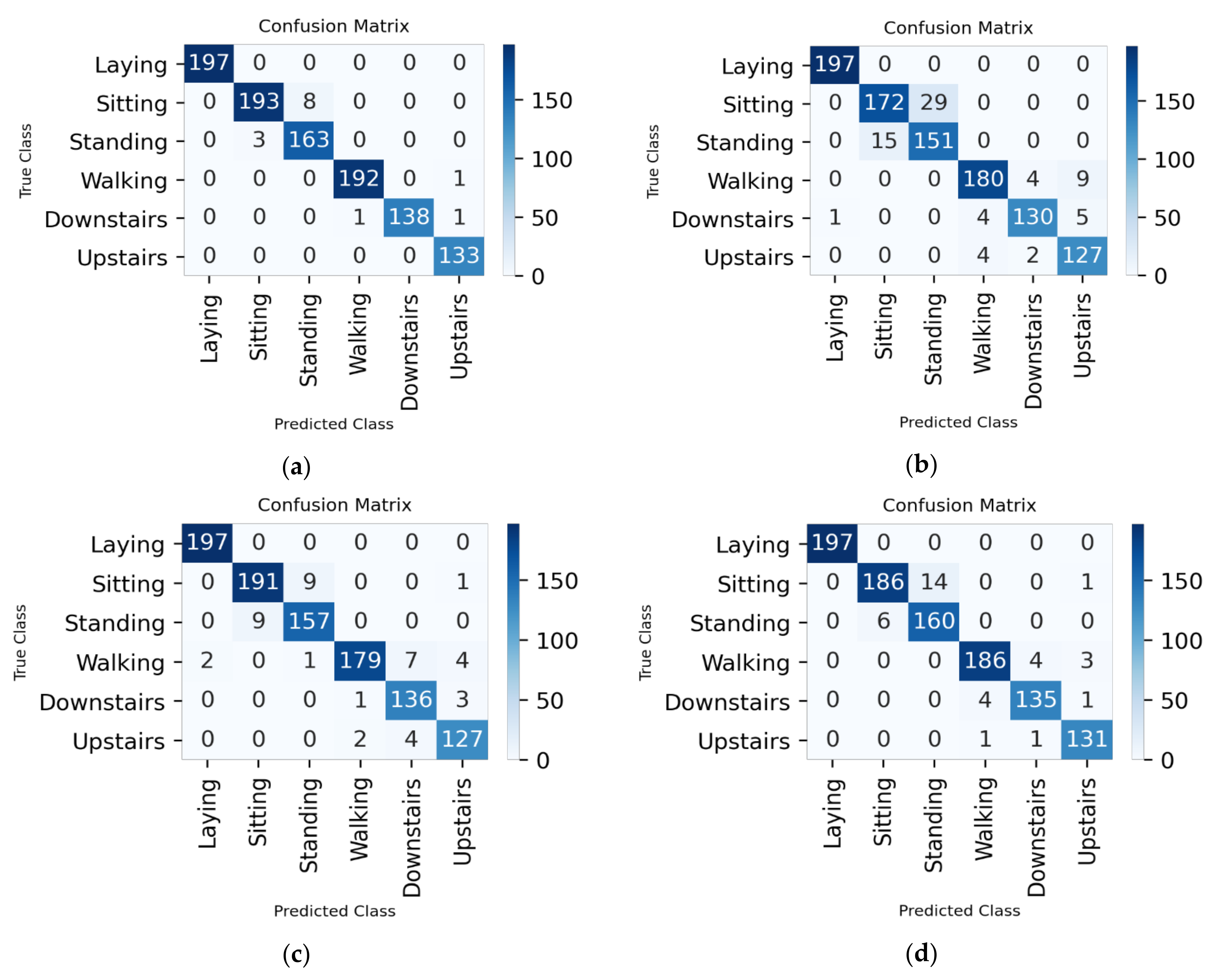
7.1. 70%–Training, 10%–Validation, 20%–Testing
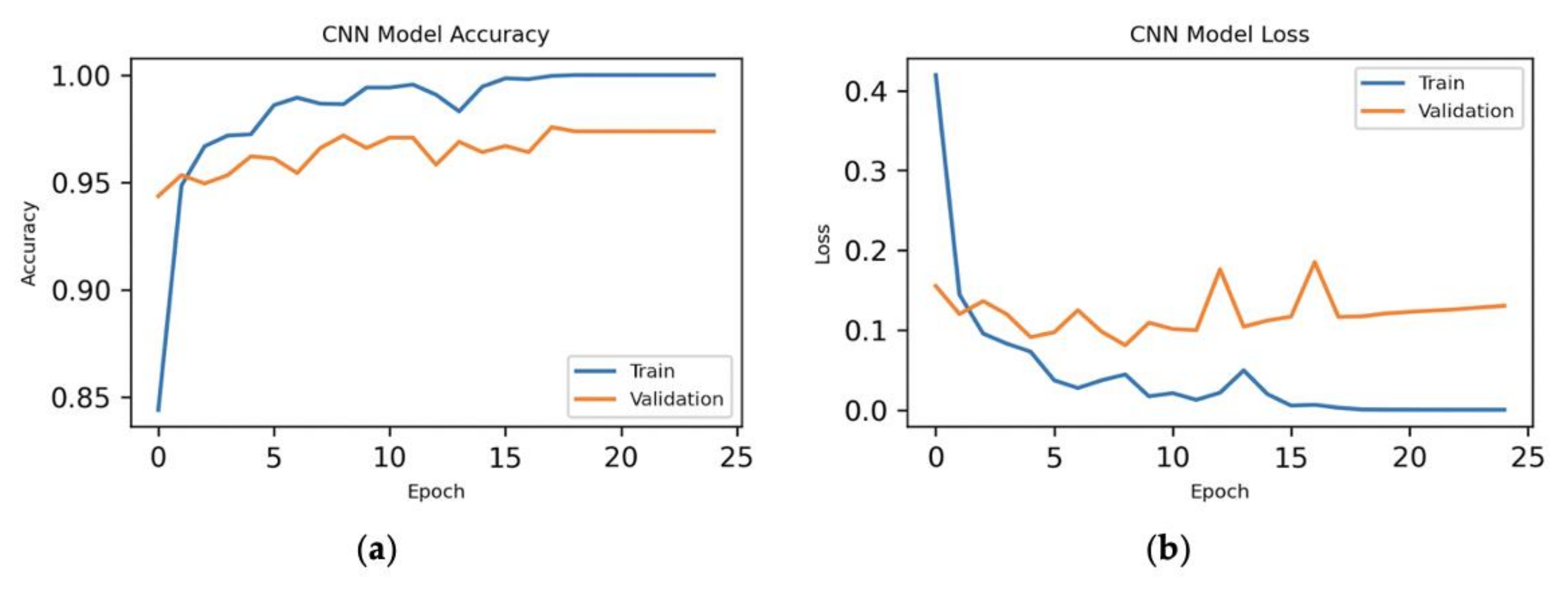
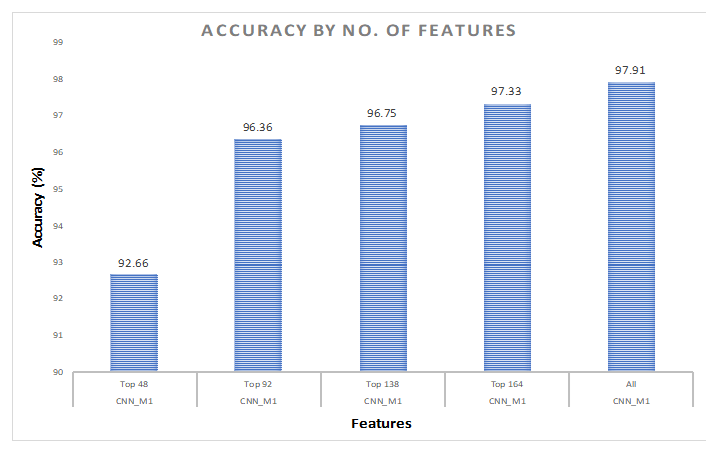
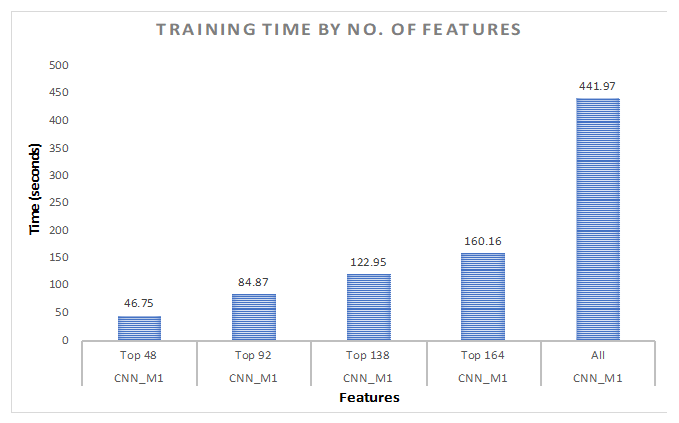
7.1.1. All Features
7.1.2. Hybrid Approach
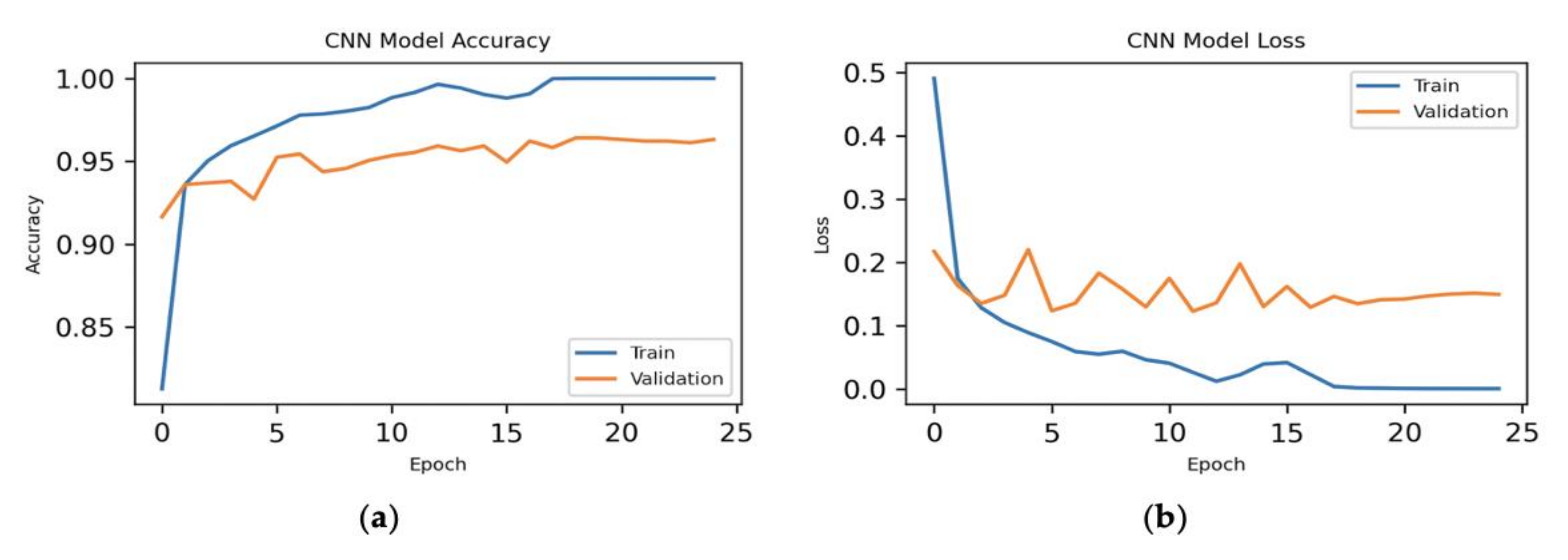
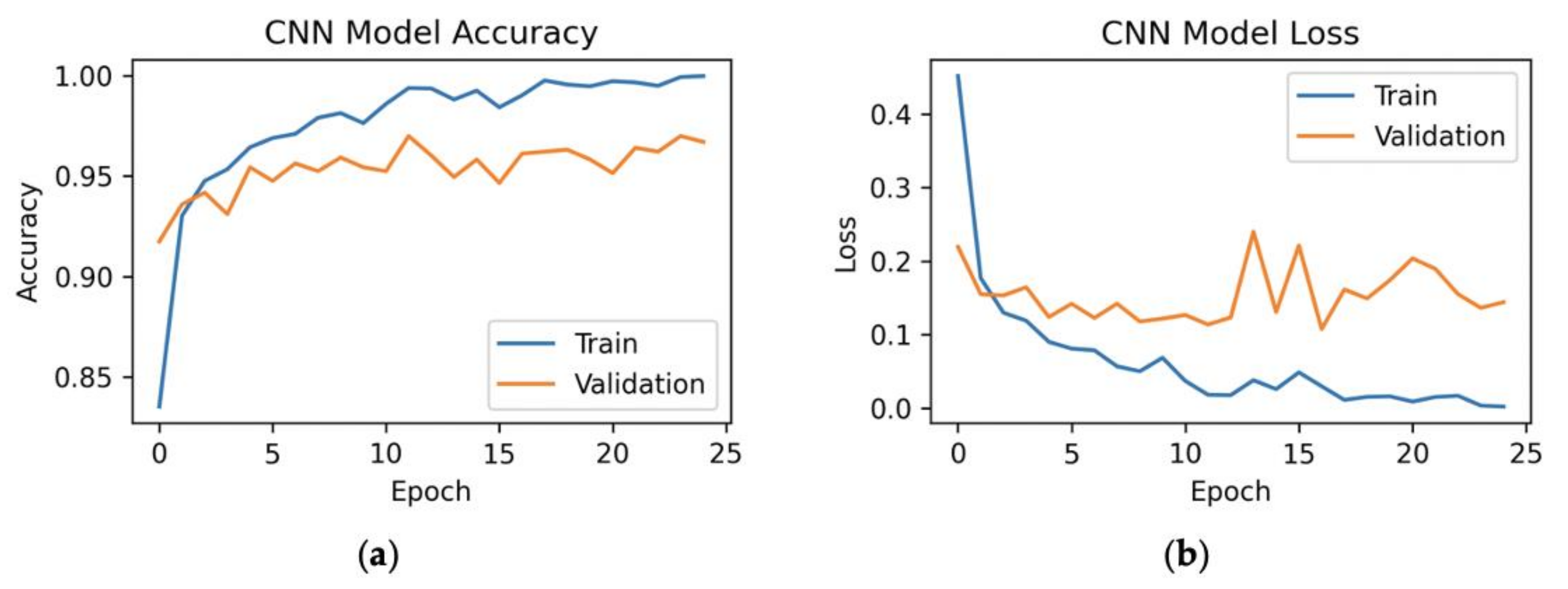
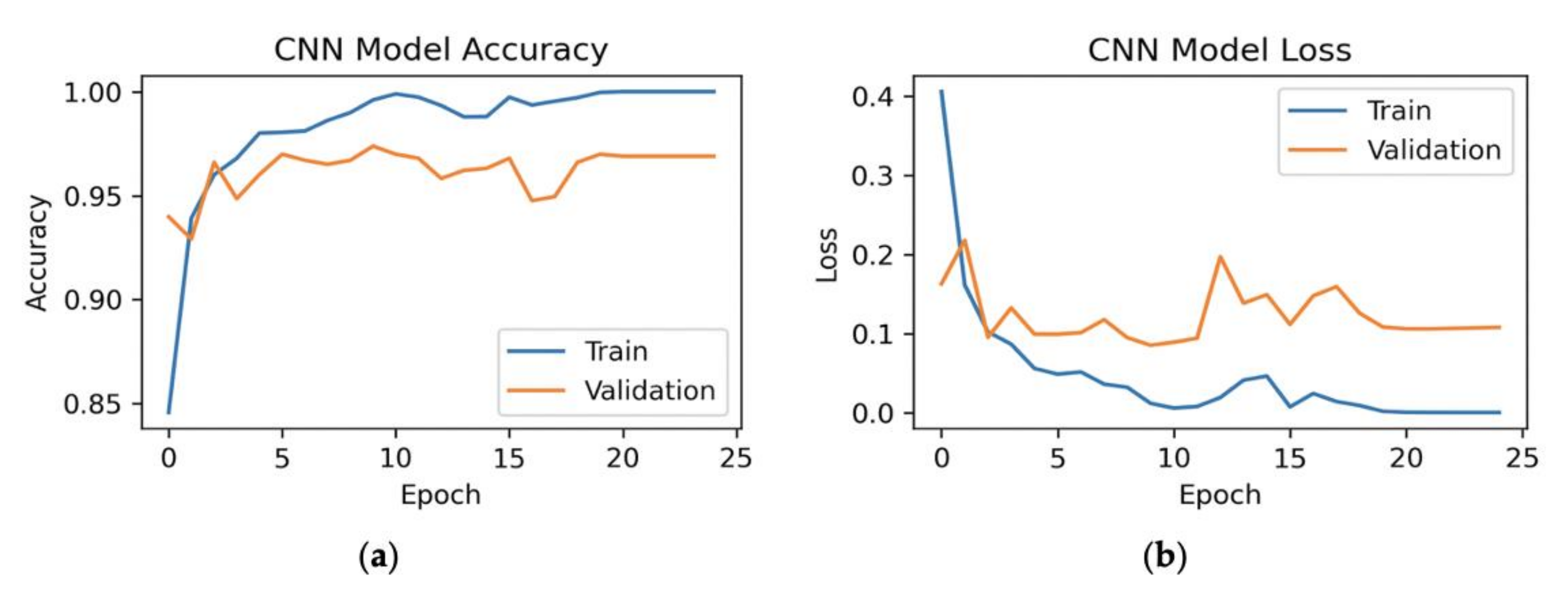
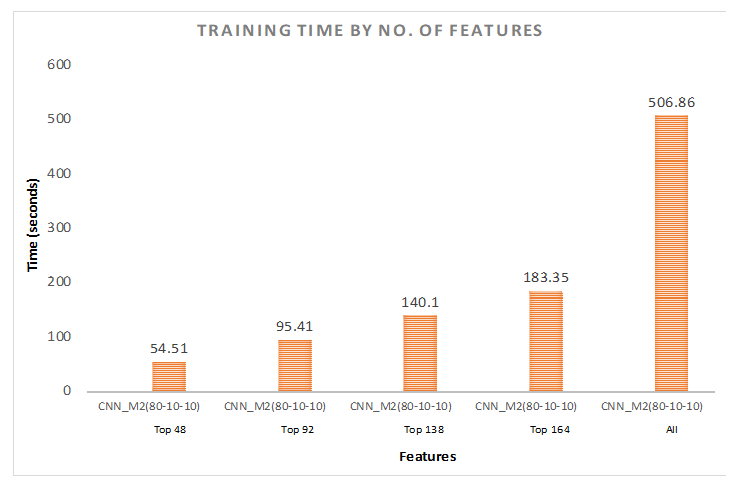
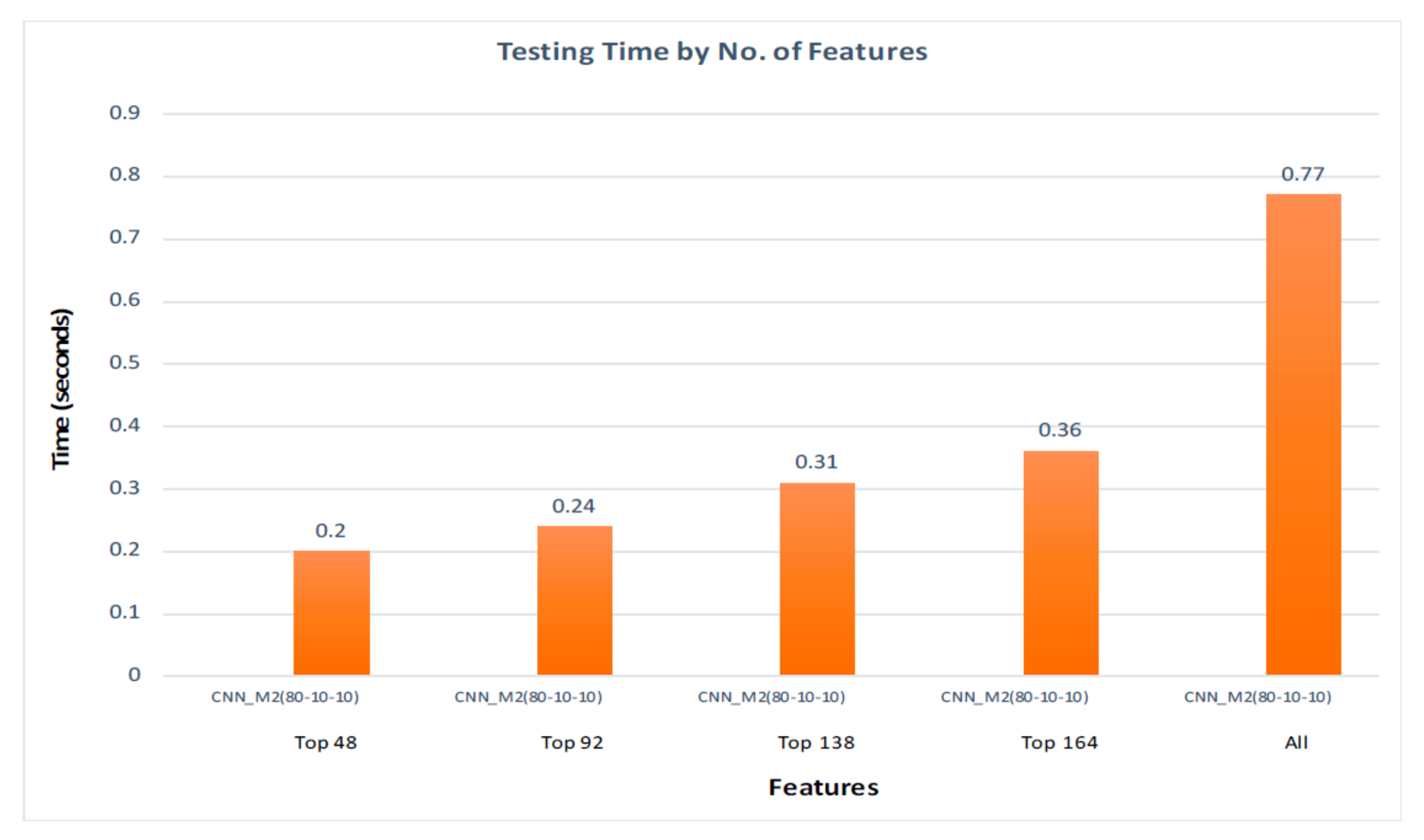
7.2. 80%–Training, 10%–Validation, 10%–Testing
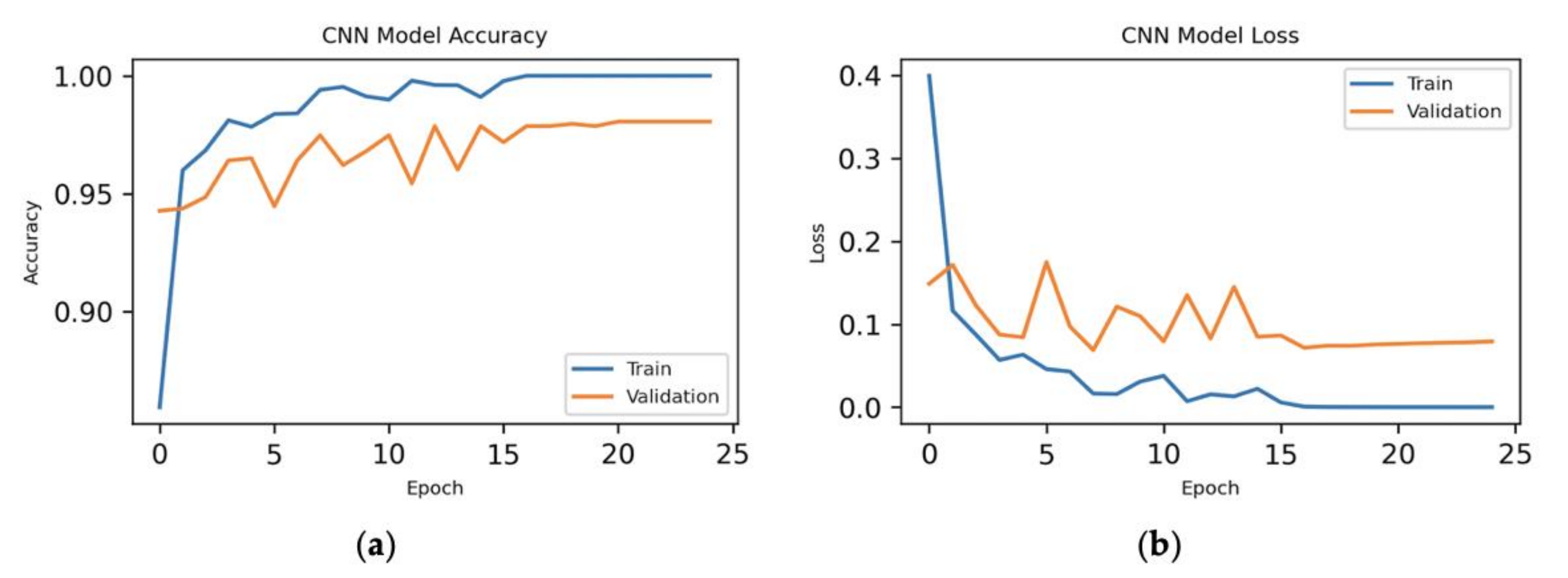
7.2.1. All Features
7.2.2. Hybrid Approach
8. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
Appendix A




References
- Brastein, O.M.; Olsson, R.; Skeie, N.O.; Lindblad, T. Human Activity Recognition by machine learning methods. In Proceedings of the Norsk IKT-Konferanse for Forskning Og Utdanning, Oslo, Norway, 27–29 November 2017. [Google Scholar]
- Roy, S.; Edan, Y. Investigating joint-action in short-cycle repetitive handover tasks: The role of giver versus receiver and its implications for human-robot collaborative system design. Int. J. Soc. Robot. 2018, 12, 973–988. [Google Scholar] [CrossRef]
- Wang, L.; Gao, R.; Váncza, J.; Krüger, J.; Wang, X.V.; Makris, S.; Chryssolouris, G. Symbiotic human-robot collaborative assembly. CIRP Ann. 2019, 68, 701–726. [Google Scholar] [CrossRef] [Green Version]
- Chen, Y.H.; Tsai, M.J.; Fu, L.C.; Chen, C.H.; Wu, C.L.; Zeng, Y.C. Monitoring elder’s living activity using ambient and body sensor network in smart home. In Proceedings of the 2015 IEEE International Conference on Systems, Man, and Cybernetics, Kowloon, Hong Kong, China, 9–12 October 2015; pp. 2962–2967. [Google Scholar]
- Spörri, J.; Kröll, J.; Fasel, B.; Aminian, K.; Müller, E. The Use of Body Worn Sensors for Detecting the Vibrations Acting on the Lower Back in Alpine Ski Racing. Front. Physiol. 2017, 8, 522. [Google Scholar] [CrossRef] [PubMed]
- Lee, W.; Cho, S.; Chu, P.; Vu, H.; Helal, S.; Song, W.; Jeong, Y.S.; Cho, K. Automatic agent generation for IoT-based smart house simulator. Neurocomputing 2016, 209, 14–24. [Google Scholar] [CrossRef]
- Ullah, M.; Ullah, H.; Khan, S.D.; Cheikh, F.A. Stacked Lstm Network for Human Activity Recognition Using Smartphone Data. In Proceedings of the 2019 8th European Workshop on Visual Information Processing (EUVIP), Roma, Italy, 28–31 October 2019; pp. 175–180. [Google Scholar]
- Ogbuabor, G.; La, R. Human activity recognition for healthcare using smartphones. In Proceedings of the 2018 10th International Conference on Machine Learning and Computing (ICMLC), Macau, China, 26–28 February 2018; pp. 41–46. [Google Scholar]
- Gjoreski, M.; Gjoreski, H.; Luštrek, M.; Gams, M. How accurately can your wrist device recognize daily activities and detect falls? Sensors 2016, 16, 800. [Google Scholar] [CrossRef] [PubMed]
- Lara, O.D.; Labrador, M.A. A survey on human activity recognition using wearable sensors. IEEE Commun. Surv. Tutor. 2012, 15, 1192–1209. [Google Scholar] [CrossRef]
- Avci, A.; Bosch, S.; Marin-Perianu, M.; Marin-Perianu, R.; Havinga, P. Activity recognition using inertial sensing for healthcare, wellbeing and sports applications: A survey. In Proceedings of the 23rd International Conference on Architecture of Computing Systems, Hannover, Germany, 22–25 February 2010; pp. 1–10. [Google Scholar]
- Alford, L. What men should know about the impact of physical activity on their health. Int. J. Clin. Pract. 2010, 64, 1731. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Kwak, T.; Song, A.; Kim, Y. The Impact of the PCA Dimensionality Reduction for CNN based Hyperspectral Image Classification. Korean J. Remote Sens. 2019, 35, 959–971. [Google Scholar]
- HAR Dataset. Available online: https://www.kaggle.com/uciml/human-activity-recognition-with-smartphones (accessed on 12 March 2020).
- Anguita, D.; Ghio, A.; Oneto, L.; Parra, X.; Reyes-Ortiz, J.L. A Public Domain Dataset for Human Activity Recognition Using Smartphones. In Proceedings of the 21st European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning (ESANN), Bruges, Belgium, 24–26 April 2013. [Google Scholar]
- Anguita, D.; Ghio, A.; Oneto, L.; Parra, X.; Reyes-Ortiz, J.L. Human activity recognition on smartphones using a multiclass hardware-friendly support vector machine. In 4th International Workshop on Ambient Assisted Living; Springer: Vitoria-Gasteiz, Spain, 2012; pp. 216–223. [Google Scholar]
- Anguita, D.; Ghio, A.; Oneto, L.; Parra, X.; Reyes-Ortiz, J.L. Energy Efficient Smartphone-Based Activity Recognition using Fixed-Point Arithmetic. J. UCS 2013, 19, 1295–1314. [Google Scholar]
- Reyes-Ortiz, J.L.; Ghio, A.; Parra, X.; Anguita, D.; Cabestany, J.; Catala, A. Human Activity and Motion Disorder Recognition: Towards smarter Interactive Cognitive Environments. In Proceedings of the 21st European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning (ESANN), Bruges, Belgium, 24–26 April 2013. [Google Scholar]
- Google. What is Colaboratory. Available online: https://colab.research.google.com/notebooks/intro.ipynb (accessed on 15 March 2020).
- Ray, S.; AlGhamdi, A.; Alshouiliy, K.; Agrawal, D.P. Selecting Features for Breast Cancer Analysis and Prediction. In Proceedings of the 6th International Conference on Advances in Computing and Communication Engineering (ICACCE), Las Vegas, NV, USA, 22–24 June 2020; pp. 1–6. [Google Scholar]
- Ahmed, N.; Rafiq, J.I.; Islam, M.R. Enhanced human activity recognition based on smartphone sensor data using hybrid feature selection model. Sensors 2020, 20, 317. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Sikder, N.; Chowdhury, M.S.; Arif, A.S.; Nahid, A.A. Human Activity Recognition Using Multichannel Convolutional Neural Network. In Proceedings of the 2019 5th International Conference on Advances in Electrical Engineering (ICAEE), Dhaka, Bangladesh, 26–28 September 2019; pp. 560–565. [Google Scholar]
- Gaur, S.; Gupta, G.P. Framework for Monitoring and Recognition of the Activities for Elderly People from Accelerometer Sensor Data Using Apache Spark. In ICDSMLA 2019; Springer: Singapore, 2020; pp. 734–744. [Google Scholar]
- Su, T.; Sun, H.; Ma, C.; Jiang, L.; Xu, T. HDL: Hierarchical Deep Learning Model based Human Activity Recognition using Smartphone Sensors. In Proceedings of the 2019 International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar]
- Reyes-Ortiz, J.L.; Oneto, L.; Samà, A.; Parra, X.; Anguita, D. Transition-aware human activity recognition using smartphones. Neurocomputing 2016, 171, 754–767. [Google Scholar] [CrossRef] [Green Version]
- UCI Machine Learning Repository. Smartphone-Based Recognition of Human Activities and Postural Transitions Data Set. Available online: http://archive.ics.uci.edu/ml/datasets/Smartphone-Based+Recognition+of+Human+Activities+and+Postural+Transitions (accessed on 10 March 2020).
- Brownlee, J. How to Remove Outliers for Machine Learning. Available online: https://machinelearningmastery.com/how-to-use-statistics-to-identify-outliers-in-data/ (accessed on 10 April 2020).
- Dhiraj, K. Anomaly Detection Using Isolation Forest in Python. Available online: https://blog.paperspace.com/anomaly-detection-isolation-forest/ (accessed on 10 April 2020).
- Lewinson, E. Outlier Detection with Isolation Forest. Available online: https://towardsdatascience.com/outlier-detection-with-isolation-forest-3d190448d45e (accessed on 10 April 2020).
- Brownlee, J. Scale Data with Outliers for ML. Available online: https://machinelearningmastery.com/robust-scaler-transforms-for-machine-learning/ (accessed on 15 May 2020).
- Sharma, A. Principal Component Analysis (PCA) in Python. Available online: https://www.datacamp.com/community/tutorials/principal-component-analysis-in-python (accessed on 21 May 2020).
- Magenta. Colab Notebooks. Available online: https://magenta.tensorflow.org/demos/colab/ (accessed on 25 May 2020).
- Tutorialspoint. Google Colab Introduction. Available online: http://www.tutorialspoint.com/google_colab/google_colab_introduction.htm (accessed on 25 May 2020).
- Google. Introduction to Keras. Available online: https://colab.research.google.com/drive/1R44RA5BRDEaNxQIJhTJzH_ekmV3Vb1yI#scrollTo=vAzCBQJn6E13 (accessed on 18 June 2020).
- MissingLink AI. CNN Architecture. Available online: https://missinglink.ai/guides/convolutional-neural-networks/convolutional-neural-network-architecture-forging-pathways-future/ (accessed on 10 June 2020).
- MissingLink AI. CNN in Keras. Available online: https://missinglink.ai/guides/keras/keras-conv1d-working-1d-convolutional-neural-networks-keras/ (accessed on 21 June 2020).
- Phung, V.H.; Rhee, E.J. A High-Accuracy Model Average Ensemble of Convolutional Neural Networks for Classification of Cloud Image Patches on Small Datasets. Appl. Sci. 2019, 9, 4500. [Google Scholar] [CrossRef] [Green Version]
- Brownlee, J. Epoch in Neural Network. Available online: https://machinelearningmastery.com/difference-between-a-batch-and-an-epoch/ (accessed on 12 July 2020).
- MissingLink AI. CNN in Keras. Available online: https://missinglink.ai/guides/convolutional-neural-networks/python-convolutional-neural-network-creating-cnn-keras-tensorflow-plain-python/ (accessed on 21 June 2020).
- Mtetwa, N.; Awukam, A.O.; Yousefi, M. Feature extraction and classification of movie reviews. In Proceedings of the 5th International Conference on Soft Computing & Machine Intelligence (ISCMI), Nairobi, Kenya, 21–22 November 2018. [Google Scholar]
- Ackermann, N. Introduction to 1D Convolutional Neural Networks. Available online: https://blog.goodaudience.com/introduction-to-1d-convolutional-neural-networks-in-keras-for-time-sequences-3a7ff801a2cf (accessed on 12 June 2020).
- Sinha, A. LSTM Networks. Available online: https://www.geeksforgeeks.org/understanding-of-lstm-networks/ (accessed on 21 March 2020).























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Frequency Domain | Time Domain |
|---|---|
| fBodyGyro-XYZ fBodyGyroMag fBodyGyroJerkMag | tBodyGyro-XYZ tBodyGyroJerk-XYZ tBodyGyroMag tBodyGyroJerkMag |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ray, S.; Alshouiliy, K.; Agrawal, D.P. Dimensionality Reduction for Human Activity Recognition Using Google Colab. Information 2021, 12, 6. https://doi.org/10.3390/info12010006
Ray S, Alshouiliy K, Agrawal DP. Dimensionality Reduction for Human Activity Recognition Using Google Colab. Information. 2021; 12(1):6. https://doi.org/10.3390/info12010006
Chicago/Turabian StyleRay, Sujan, Khaldoon Alshouiliy, and Dharma P. Agrawal. 2021. "Dimensionality Reduction for Human Activity Recognition Using Google Colab" Information 12, no. 1: 6. https://doi.org/10.3390/info12010006
APA StyleRay, S., Alshouiliy, K., & Agrawal, D. P. (2021). Dimensionality Reduction for Human Activity Recognition Using Google Colab. Information, 12(1), 6. https://doi.org/10.3390/info12010006