
Combating Fake News with Transformers: A Comparative Analysis of Stance Detection and Subjectivity Analysis




Abstract
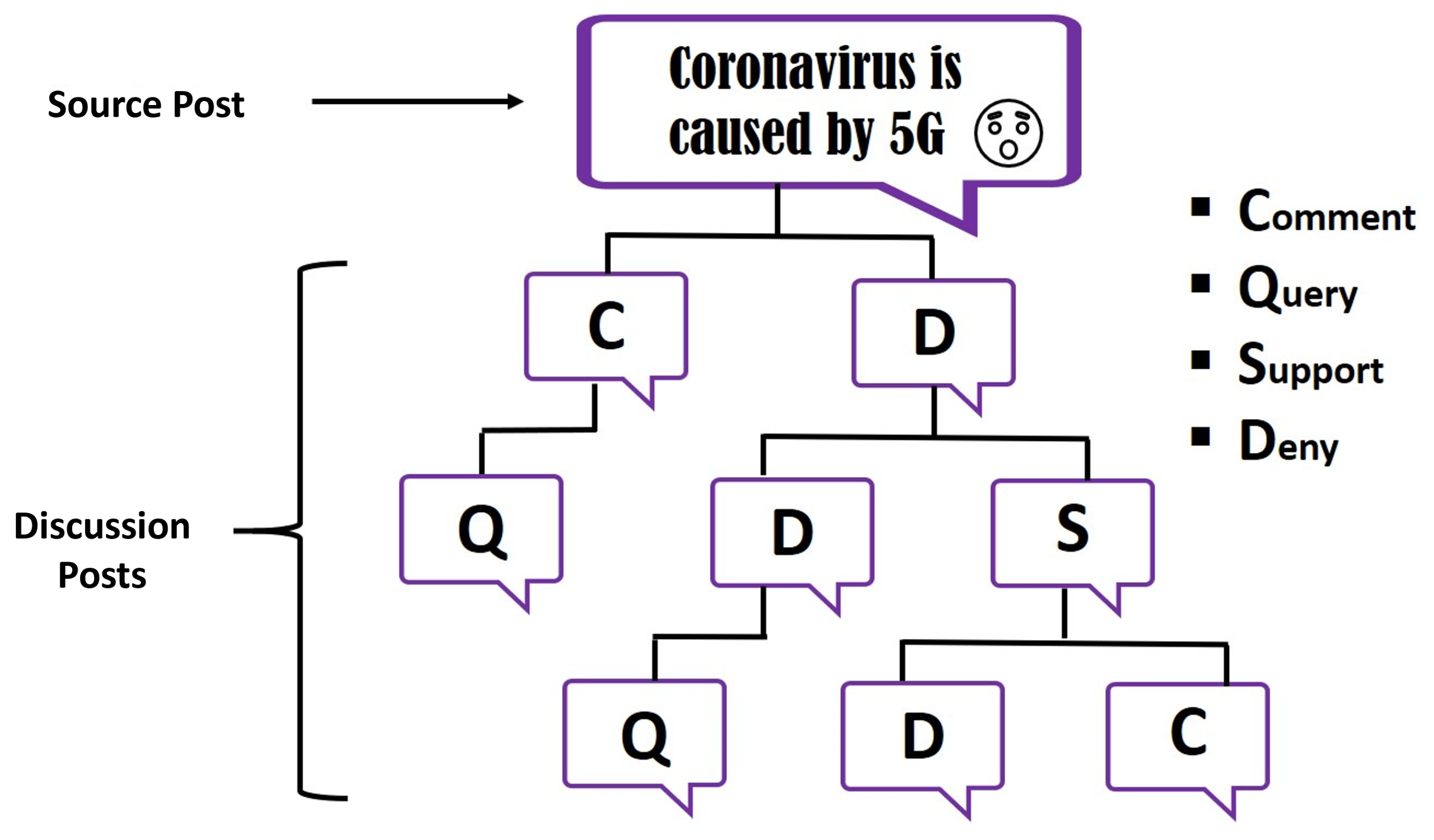
:1. Introduction
- : the author of the response supports the veracity of the rumour to which they are responding (e.g., “I’ve heard that also”).
- : the author of the response denies the veracity of the rumour to which they are responding (e.g., “That’s a lie”).
- : the author of the response asks for additional evidence in relation to the veracity of the rumour to which they are responding (e.g., “Really?”).
- : the author of the response makes their own comment without a clear contribution to assessing the veracity of the rumour to which they are responding (e.g., “True tragedy”).
- Related work on subjectivity analysis and stance detection;
- An overview of the deep-learning models’ architectures we fine-tuned and evaluated;
- A description of the selected datasets that were used for training and evaluation;
- A presentation and discussion of the obtained results.
2. Related Work
3. Methods
3.1. BERT
3.2. RoBERTa
- The model was trained for longer, with bigger batches, over more data;
- They removed the NSP objective;
- It was trained on longer sequences;
- The masking pattern applied to the training data was dynamically changed.
3.3. ELECTRA
4. Results
4.1. Experimental Set-Up
4.2. Datasets
4.2.1. SUBJ
4.2.2. SemEval 2019 Subtask 7A
4.3. Text Preprocessing
4.4. Hyperparameter Tuning
- Freezing the parameters of the model that achieved the highest F1-score in the validation set;
- Hyperparameter optimization (selecting the best hyperparameters).
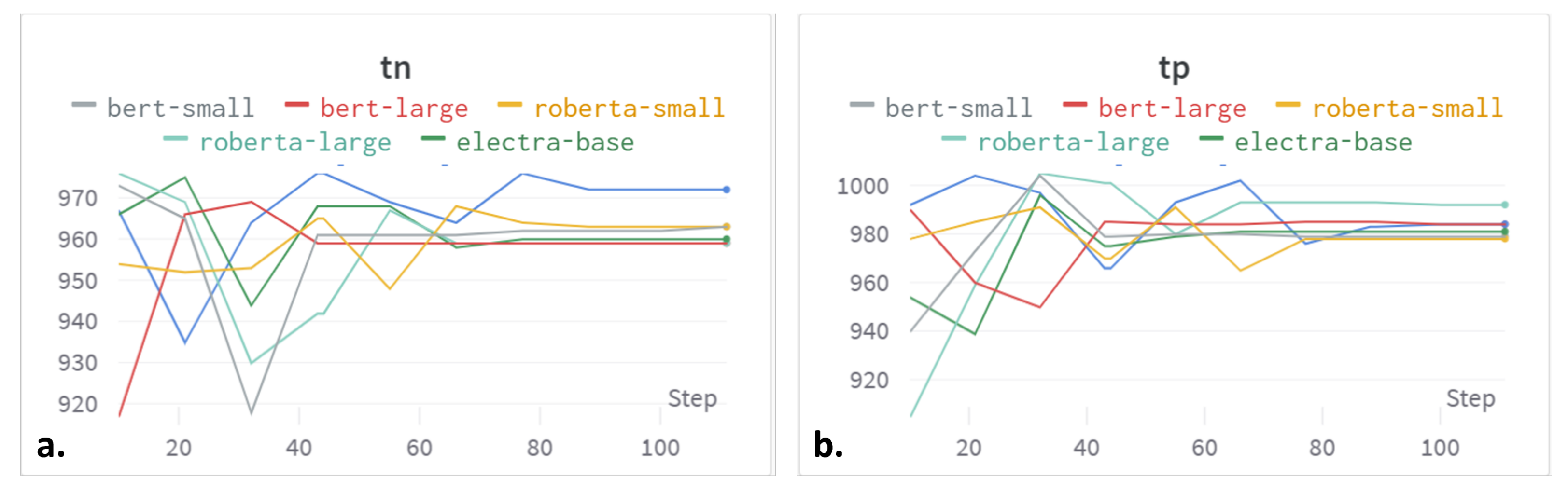
4.5. Performance
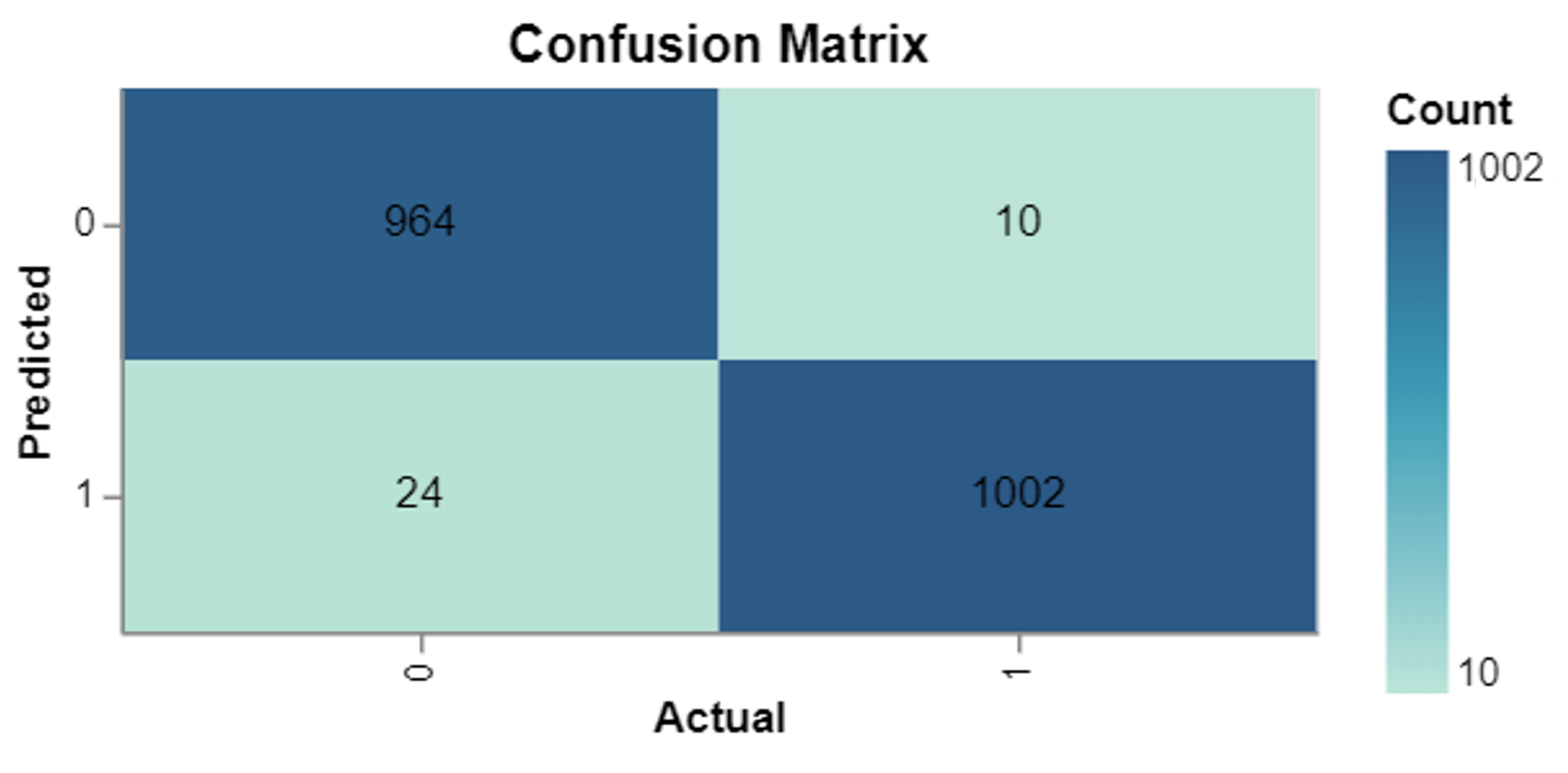
4.5.1. Subjectivity Analysis
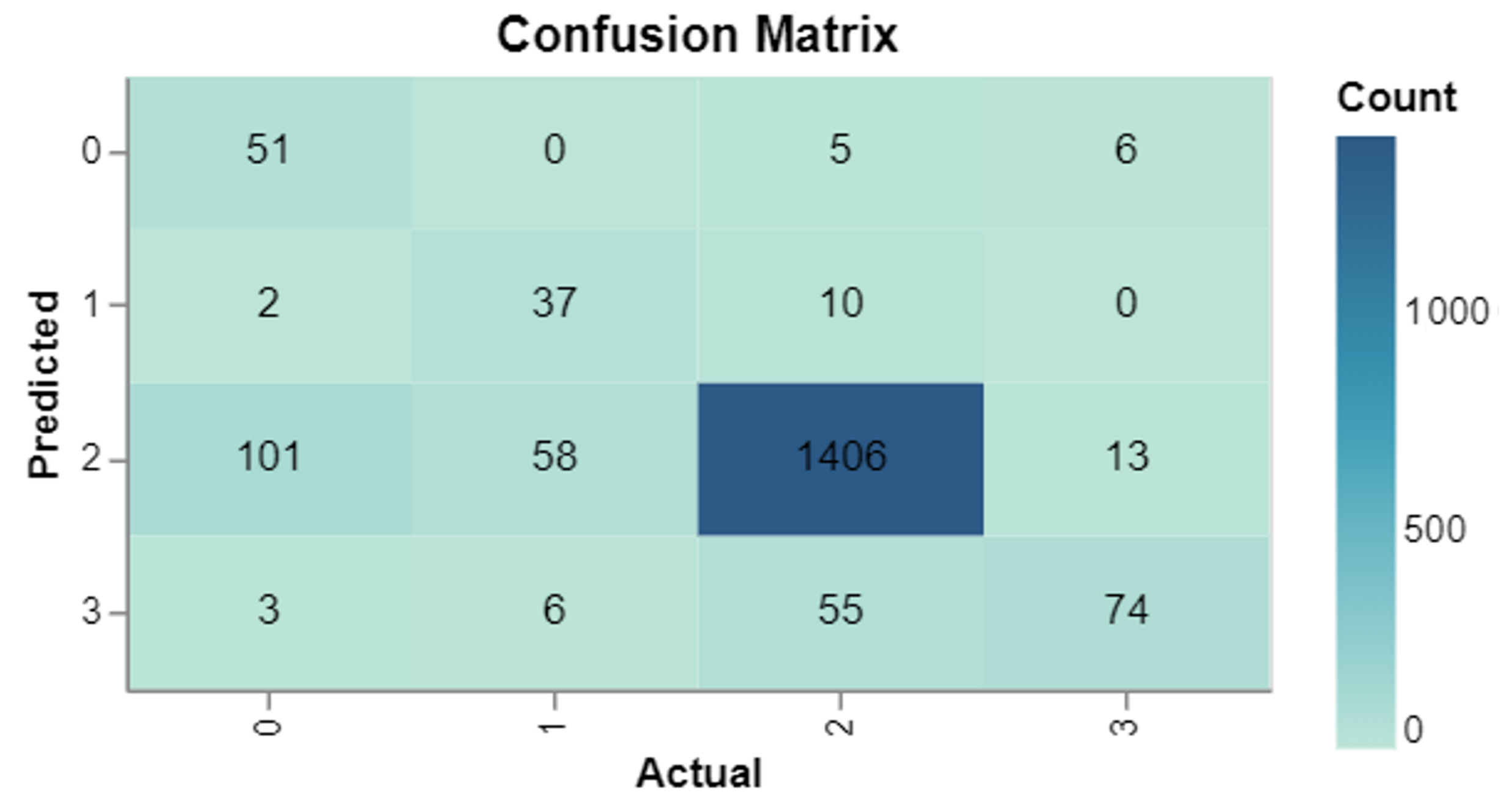
4.5.2. Stance Detection
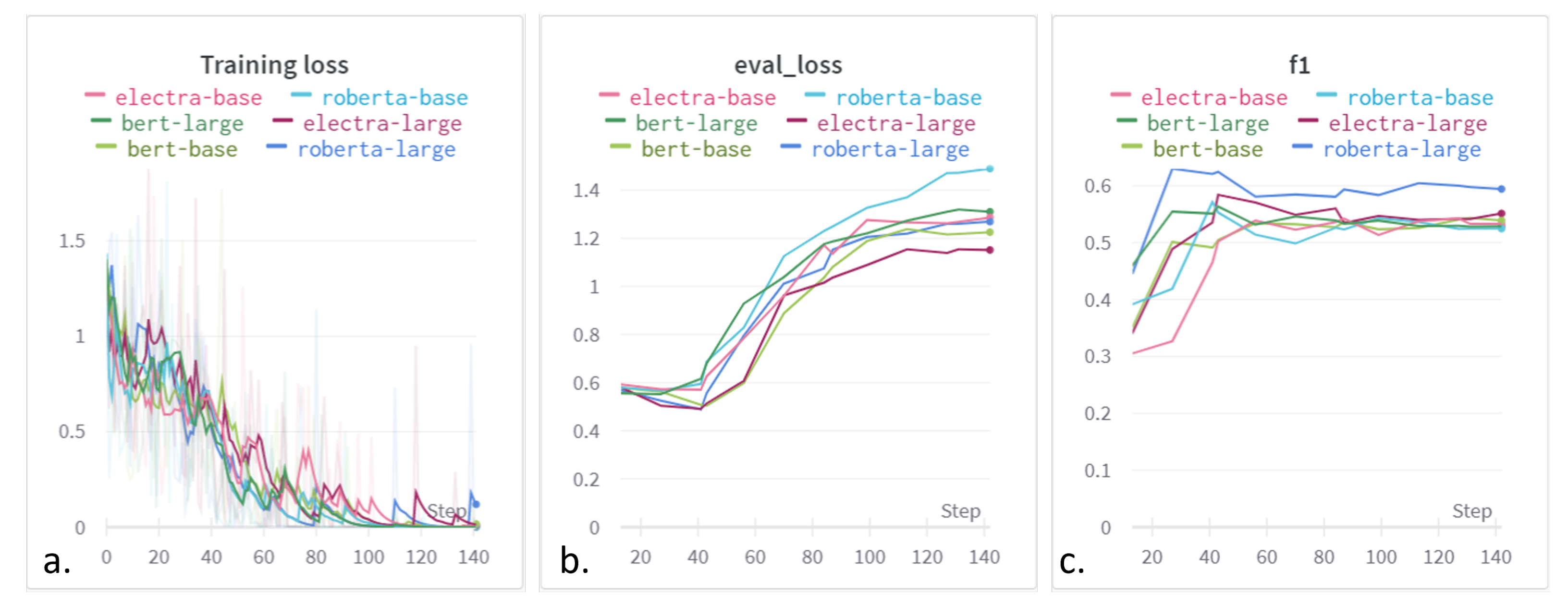
4.6. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Derczynski, L.; Bontcheva, K.; Liakata, M.; Procter, R.; Wong Sak Hoi, G.; Zubiaga, A. SemEval-2017 Task 8: RumourEval: Determining rumour veracity and support for rumours. In Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017), Vancouver, BC, Canada, 3–4 August 2017; pp. 69–76. [Google Scholar] [CrossRef] [Green Version]
- Toumanidis, L.; Heartfield, R.; Kasnesis, P.; Loukas, G.; Patrikakis, C. A Prototype Framework for Assessing Information Provenance in Decentralised Social Media: The EUNOMIA Concept. In E-Democracy—Safeguarding Democracy and Human Rights in the Digital Age; Katsikas, S., Zorkadis, V., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 196–208. [Google Scholar] [CrossRef]
- Williams Kirkpatrick, A. The spread of fake science: Lexical concreteness, proximity, misinformation sharing, and the moderating role of subjective knowledge. Public Underst. Sci. 2020, 30, 55–74. [Google Scholar] [CrossRef] [PubMed]
- Jeronimo, C.L.M.; Marinho, L.B.; Campelo, C.E.C.; Veloso, A.; da Costa Melo, A.S. Fake News Classification Based on Subjective Language. In Proceedings of the 21st International Conference on Information Integration and Web-based Applications & Services, Munich, Germany, 2–4 December 2019; pp. 15–24. [Google Scholar] [CrossRef]
- Vieira, L.L.; Jeronimo, C.L.M.; Campelo, C.E.C.; Marinho, L.B. Analysis of the Subjectivity Level in Fake News Fragments. In Proceedings of the Brazilian Symposium on Multimedia and the Web, São Luís, Brazil, 30 November–4 December 2020; pp. 233–240. [Google Scholar] [CrossRef]
- Mohammad, S.; Kiritchenko, S.; Sobhani, P.; Zhu, X.; Cherry, C. SemEval-2016 Task 6: Detecting Stance in Tweets. In Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016), San Diego, CA, USA, 16–17 June 2016; pp. 31–41. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All You Need. In Proceedings of the 31st International Conference on Neural Information Processing Systems, NIPS’17, Long Beach, CA, USA,, 4–9 December 2017; pp. 6000–6010. [Google Scholar] [CrossRef]
- Wang, S.; Manning, C. Fast dropout training. In Proceedings of the 30th International Conference on Machine Learning, Atlanta, GA, USA, 16–21 June 2013; pp. 118–126. [Google Scholar]
- Hinton, G.E.; Srivastava, N.; Krizhevsky, A.; Sutskever, I.; Salakhutdinov, R. Improving neural networks by preventing co-adaptation of feature detectors. arXiv 2012, arXiv:1207.0580. [Google Scholar]
- Pang, B.; Lee, L. A Sentimental Education: Sentiment Analysis Using Subjectivity Summarization Based on Minimum Cuts. In Proceedings of the 42nd Annual Meeting on Association for Computational Linguistics, Barcelona, Spain, 21–26 July 2004. [Google Scholar] [CrossRef] [Green Version]
- Zhao, H.; Lu, Z.; Poupart, P. Self-Adaptive Hierarchical Sentence Model. In Proceedings of the 24th International Conference on Artificial Intelligence, Buenos Aires, Argentina, 25–31 July 2015; pp. 4069–4076. [Google Scholar] [CrossRef]
- Cho, K.; van Merriënboer, B.; Bahdanau, D.; Bengio, Y. On the Properties of Neural Machine Translation: Encoder–Decoder Approaches. In Proceedings of the SSST-8, Eighth Workshop on Syntax, Semantics and Structure in Statistical Translation, Doha, Qatar, 25 October 2014; pp. 103–111. [Google Scholar] [CrossRef]
- Amplayo, R.K.; Lee, K.; Yeo, J.; won Hwang, S. Translations as Additional Contexts for Sentence Classification. arXiv 2018, arXiv:1806.05516. [Google Scholar]
- Radford, A.; Józefowicz, R.; Sutskever, I. Learning to Generate Reviews and Discovering Sentiment. arXiv 2017, arXiv:1704.01444. [Google Scholar]
- Krause, B.; Lu, L.; Murray, I.; Renals, S. Multiplicative LSTM for sequence modelling. arXiv 2017, arXiv:1609.07959. [Google Scholar]
- Cer, D.; Yang, Y.; Kong, S.; Hua, N.; Limtiaco, N.; St. John, R.; Constant, N.; Guajardo-Cespedes, M.; Yuan, S.; Tar, C.; et al. Universal Sentence Encoder for English. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 169–174. [Google Scholar] [CrossRef]
- Iyyer, M.; Manjunatha, V.; Boyd-Graber, J.; Daumé, H., III. Deep unordered composition rivals syntactic methods for text classification. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2015; pp. 1681–1691. [Google Scholar] [CrossRef]
- Bowman, S.R.; Angeli, G.; Potts, C.; Manning, C.D. A large annotated corpus for learning natural language inference. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; pp. 632–642. [Google Scholar] [CrossRef]
- Li, Q.; Zhang, Q.; Si, L. eventAI at SemEval-2019 Task 7: Rumor Detection on Social Media by Exploiting Content, User Credibility and Propagation Information. In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2019; pp. 855–859. [Google Scholar] [CrossRef] [Green Version]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Proceedings of the Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 5–10 December 2013; pp. 3111–3119. [Google Scholar] [CrossRef]
- Gorrell, G.; Kochkina, E.; Liakata, M.; Aker, A.; Zubiaga, A.; Bontcheva, K.; Derczynski, L. SemEval-2019 Task 7: RumourEval, Determining Rumour Veracity and Support for Rumours. In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2019; pp. 845–854. [Google Scholar] [CrossRef] [Green Version]
- Kochkina, E.; Liakata, M.; Augenstein, I. Turing at SemEval-2017 Task 8: Sequential Approach to Rumour Stance Classification with Branch-LSTM. In Proceedings of the 11th International Workshop on Semantic Evaluation (SemEval-2017), Vancouver, BC, Canada, 3–4 August 2017; pp. 475–480. [Google Scholar] [CrossRef]
- Fajcik, M.; Smrz, P.; Burget, L. BUT-FIT at SemEval-2019 Task 7: Determining the Rumour Stance with Pre-Trained Deep Bidirectional Transformers. In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2019; pp. 1097–1104. [Google Scholar] [CrossRef] [Green Version]
- Yang, R.; Xie, W.; Liu, C.; Yu, D. BLCU_NLP at SemEval-2019 Task 7: An Inference Chain-based GPT Model for Rumour Evaluation. In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2019; pp. 1090–1096. [Google Scholar] [CrossRef] [Green Version]
- Radford, A.; Narasimhan, K. Improving Language Understanding by Generative Pre-Training. 2018, in press. [Google Scholar]
- Ferreira, W.; Vlachos, A. Emergent: A novel data-set for stance classification. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; pp. 1163–1168. [Google Scholar] [CrossRef]
- Rajpurkar, P.; Jia, R.; Liang, P. Know What You Don’t Know: Unanswerable Questions for SQuAD. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; pp. 784–789. [Google Scholar] [CrossRef] [Green Version]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Clark, K.; Luong, M.T.; Le, Q.V.; Manning, C.D. ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators. arXiv 2020, arXiv:2003.10555. [Google Scholar]
- Zhu, Y.; Kiros, R.; Zemel, R.; Salakhutdinov, R.; Urtasun, R.; Torralba, A.; Fidler, S. Aligning Books and Movies: Towards Story-Like Visual Explanations by Watching Movies and Reading Books. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Los Alamitos, CA, USA, 7–13 December 2015; pp. 19–27. [Google Scholar] [CrossRef] [Green Version]
- Wang, A.; Singh, A.; Michael, J.; Hill, F.; Levy, O.; Bowman, S. GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding. In Proceedings of the 2018 EMNLP Workshop BlackboxNLP: Analyzing and Interpreting Neural Networks for NLP, Brussels, Belgium, 1 November 2018; pp. 353–355. [Google Scholar] [CrossRef] [Green Version]
- Caccia, M.; Caccia, L.; Fedus, W.; Larochelle, H.; Pineau, J.; Charlin, L. Language gans falling short. arXiv 2018, arXiv:1811.02549. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Kaplan, J.; McCandlish, S.; Henighan, T.; Brown, T.B.; Chess, B.; Child, R.; Gray, S.; Radford, A.; Wu, J.; Amodei, D. Scaling Laws for Neural Language Models. arXiv 2020, arXiv:2001.08361. [Google Scholar]
- Yang, Z.; Dai, Z.; Yang, Y.; Carbonell, J.; Salakhutdinov, R.R.; Le, Q.V. XLNet: Generalized Autoregressive Pretraining for Language Understanding. In Advances in Neural Information Processing Systems; Wallach, H., Larochelle, H., Beygelzimer, A., d’Alché-Buc, F., Fox, E., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2019; Volume 32. [Google Scholar]
- Yasunaga, M.; Ren, H.; Bosselut, A.; Liang, P.; Leskovec, J. QA-GNN: Reasoning with Language Models and Knowledge Graphs for Question Answering. arXiv 2021, arXiv:2104.06378. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Text | Label |
|---|---|
| Celebrities are talking about him on MTV and girls are fighting over him on Jerry springer. | Objective |
| Funny in a sick, twisted sort of way. | Subjective |
| If Oscar had a category called best bad film you thought was going to be really awful but wasn’t, guys would probably be duking it out with the queen of the damned for the honor. | Subjective |
| Colt seeks the repair of a femininity damaged by an earlier incest. | Objective |
| Set | Support | Deny | Query | Comment | Total |
|---|---|---|---|---|---|
| Twitter Train | 1004 | 415 | 464 | 3685 | 5568 |
| Reddit Train | 23 | 45 | 51 | 1015 | 1134 |
| Total Train | 1027 | 460 | 515 | 4700 | 6702 |
| Twitter Test | 141 | 92 | 62 | 771 | 1066 |
| Reddit Test | 16 | 54 | 31 | 705 | 806 |
| Total Test | 157 | 146 | 93 | 1476 | 1872 |
| Hyperparameter | Subjectivity Analysis | Stance Detection |
|---|---|---|
| Learning rate | 1 × 10 | 2 × 10 (1 × 10 for ELECTRA) |
| Adam | 1 × 10 | 1 × 10 |
| Adam | 0.9 | 0.9 |
| Adam | 0.999 | 0.999 |
| Dropout | 0.1 | 0.1 |
| Batch size | 16 | 8 |
| Max. sequence length | 128 | 128 |
| Model | Accuracy, % |
|---|---|
| AdaSent [11] | 95.50 |
| CNN+MCFA [13] | 94.80 |
| Byte mLSTM [14] | 94.60 |
| USE [16] | 93.90 |
| Fast Dropout [8] | 93.60 |
| BERT | 96.40 |
| BERT | 97.20 |
| RoBERTa | 97.10 |
| RoBERTa | 97.75 |
| ELECTRA | 97.05 |
| ELECTRA | 98.30 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kasnesis, P.; Toumanidis, L.; Patrikakis, C.Z. Combating Fake News with Transformers: A Comparative Analysis of Stance Detection and Subjectivity Analysis. Information 2021, 12, 409. https://doi.org/10.3390/info12100409
Kasnesis P, Toumanidis L, Patrikakis CZ. Combating Fake News with Transformers: A Comparative Analysis of Stance Detection and Subjectivity Analysis. Information. 2021; 12(10):409. https://doi.org/10.3390/info12100409
Chicago/Turabian StyleKasnesis, Panagiotis, Lazaros Toumanidis, and Charalampos Z. Patrikakis. 2021. "Combating Fake News with Transformers: A Comparative Analysis of Stance Detection and Subjectivity Analysis" Information 12, no. 10: 409. https://doi.org/10.3390/info12100409
APA StyleKasnesis, P., Toumanidis, L., & Patrikakis, C. Z. (2021). Combating Fake News with Transformers: A Comparative Analysis of Stance Detection and Subjectivity Analysis. Information, 12(10), 409. https://doi.org/10.3390/info12100409