
Tool to Retrieve Less-Filtered Information from the Internet



Abstract
1. Introduction
1.1. Motivation
1.2. Potential Vulnerabilities on Social Networks and Search Platforms: Echo Chambers and Filter Bubbles
1.3. Goal of the Study
2. Related Works
2.1. Overview
2.2. Escaping the Filter Bubble
2.3. Countermeasures to the Filter Bubble on Search Platforms
- reading from other sources to compare whether the information is true;
- clicking on things that are unrelated to what people like and what people usually click on or accessing some information that people might not agree on;
- resetting usernames and starting afresh; and
- reducing the use of social media and not depending on it.
- publicizing information about the filter bubble, the hidden algorithms, and the effect that these have on our online lives;
- providing the possibility of unfiltered searching, allowing the public to get unbiased information based on relevance and content quality; and
- switching to another search engine or service such as duckduckgo.com.
2.4. Metasearch Engine Mechanism
3. Approach
3.1. Overview
- less-biased search result retrieval with a pluralization of search algorithms,
- a limited number of presented search results,
- searches without search/access history,
- search results that do not track the user’s personal location or IP address, and
- a mobile-friendly interface useful for general users.
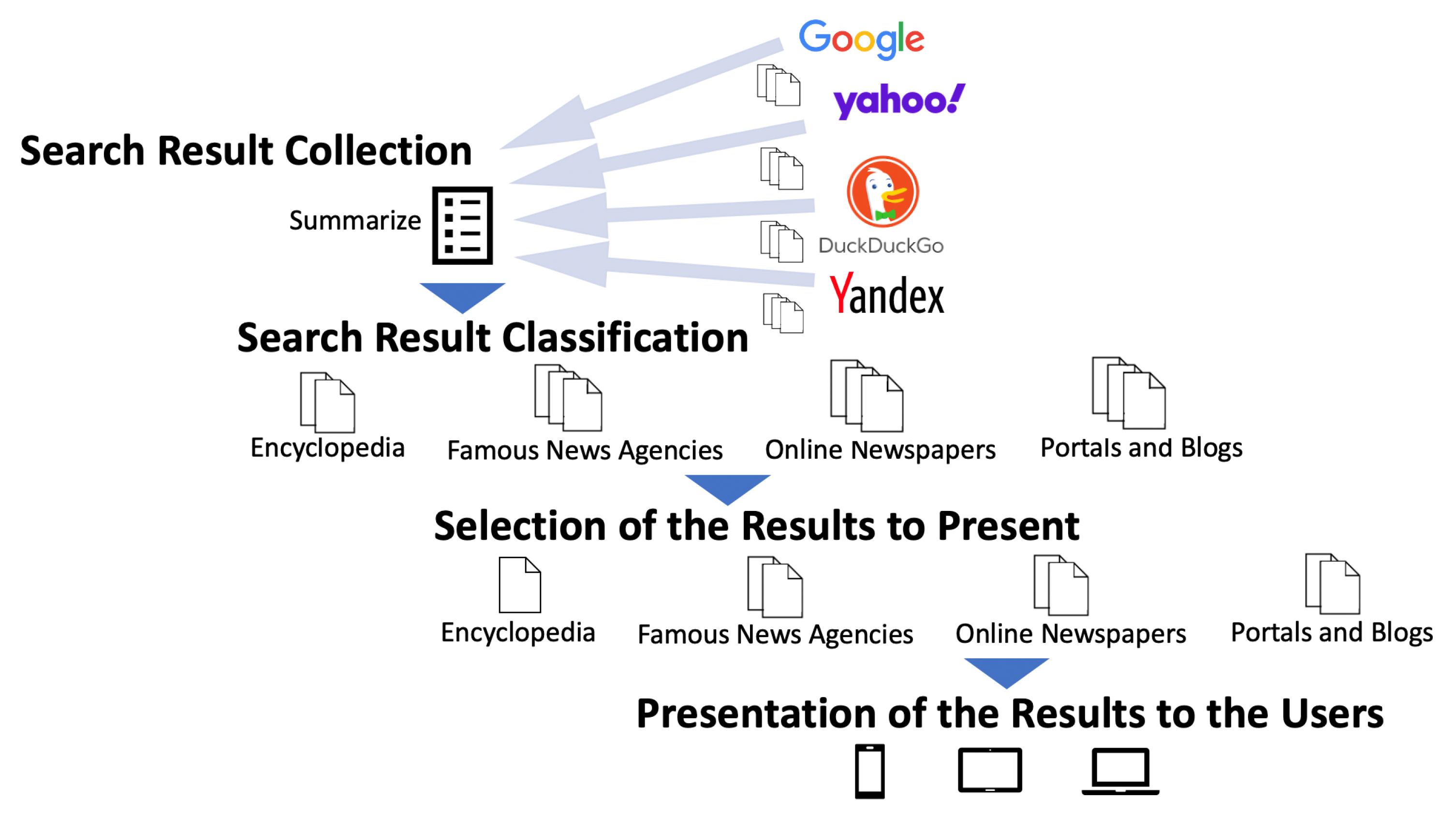
3.2. Utilizing Metasearch Engine Mechanism
3.3. Classification and Selection Processes
- Only textual data are used as result items;
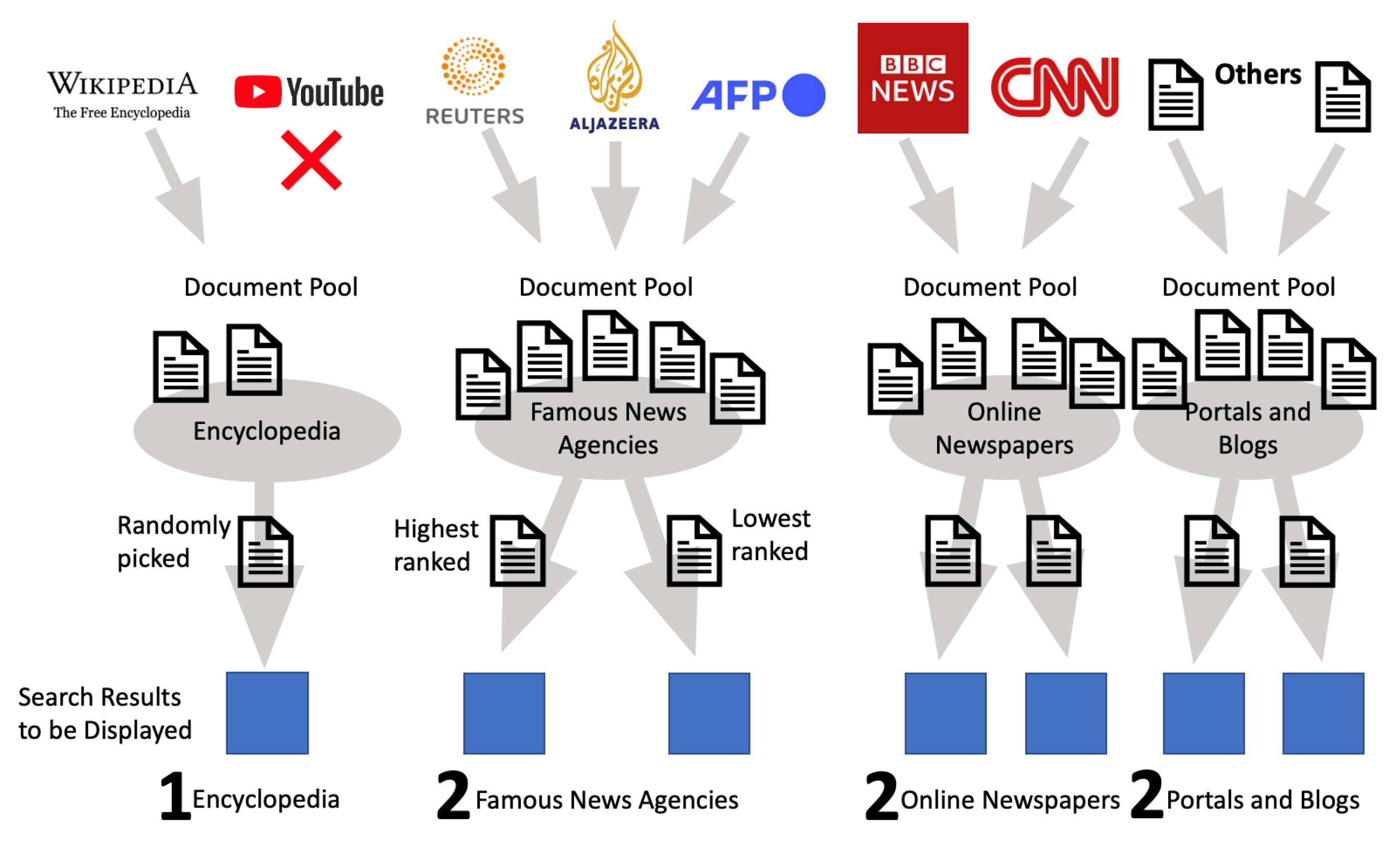
- Pages are classified into “Encyclopedias” (Wikipedia), “Famous News Agencies” (CNN (Cable News Network), BBC (British Broadcasting Corporation), RT (Russia Today), Al Jazeera, NHK (Japan Broadcasting Corporation), DW (Deutsche Welle), etc.), “Online Newspapers” (The Guardian, The New York Times, Financial Times, etc.) and “Portals and Blogs” by matching the URLs against the list of news agencies and newspapers, which were prepared in advance;
- The maximum number of returned result items to the user is no more than seven, including at least one encyclopedia and two of each other category;
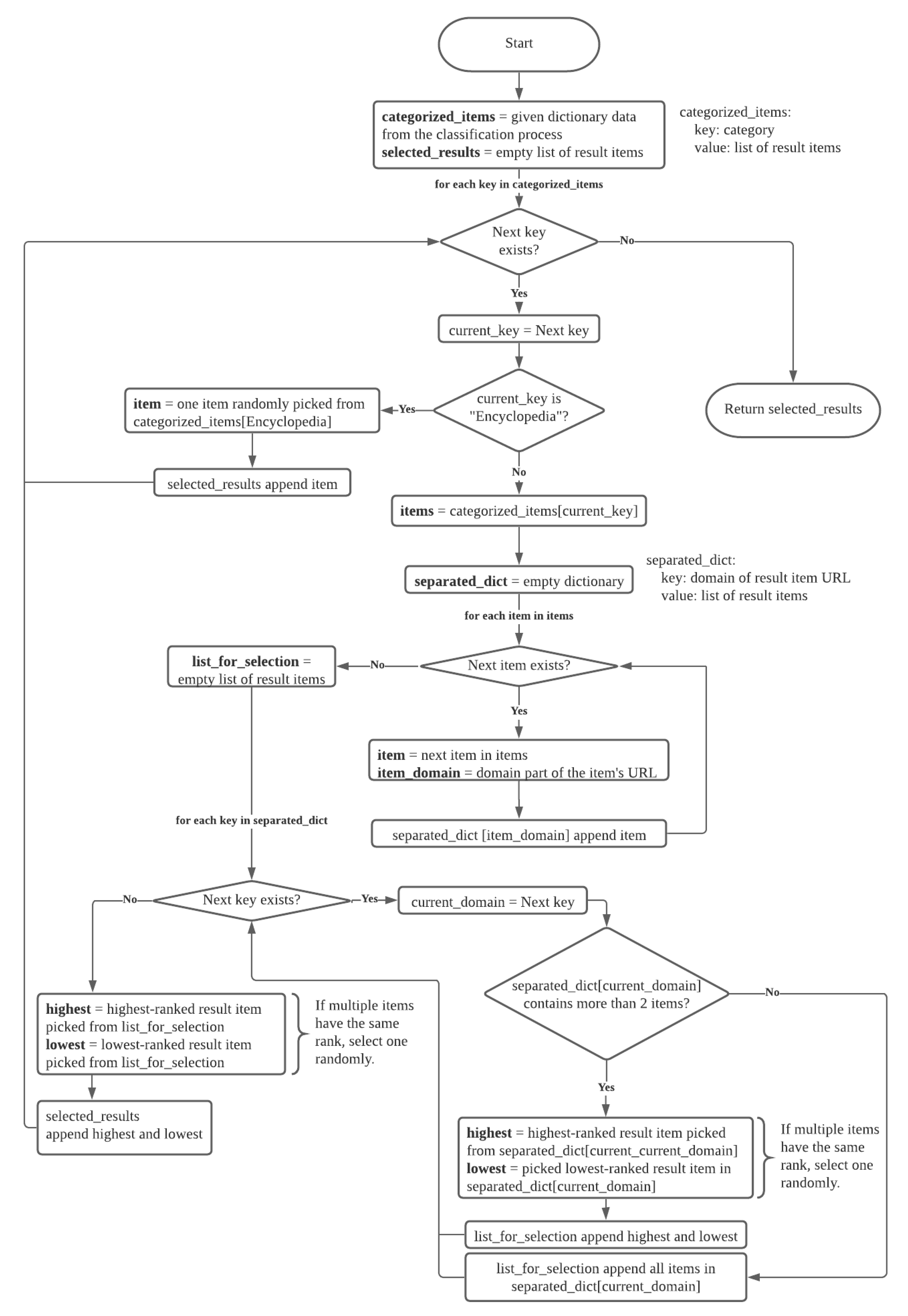
- The application preserves the ranks of result items from the search engine outcomes. If two or more result items have the same rank assigned by search engines, then they are ordered randomly;
- If there are more than two result items from the same source of search engine output, the two with the highest and lowest ranks are selected;
- No more than two representatives from each category are on the final list for the user. One result item has the highest rank, and the other has the lowest. This allows us to increase the chance for result items with different views to be presented to the end user.
4. Implementation
4.1. Overview
4.2. Compiling Search Results
4.2.1. Method with APIs: Retrieval from Google and Yandex
4.2.2. Retrieval Using Scraping: Yahoo! and DuckDuckGo
4.2.3. Process to Summarize Retrieved Results
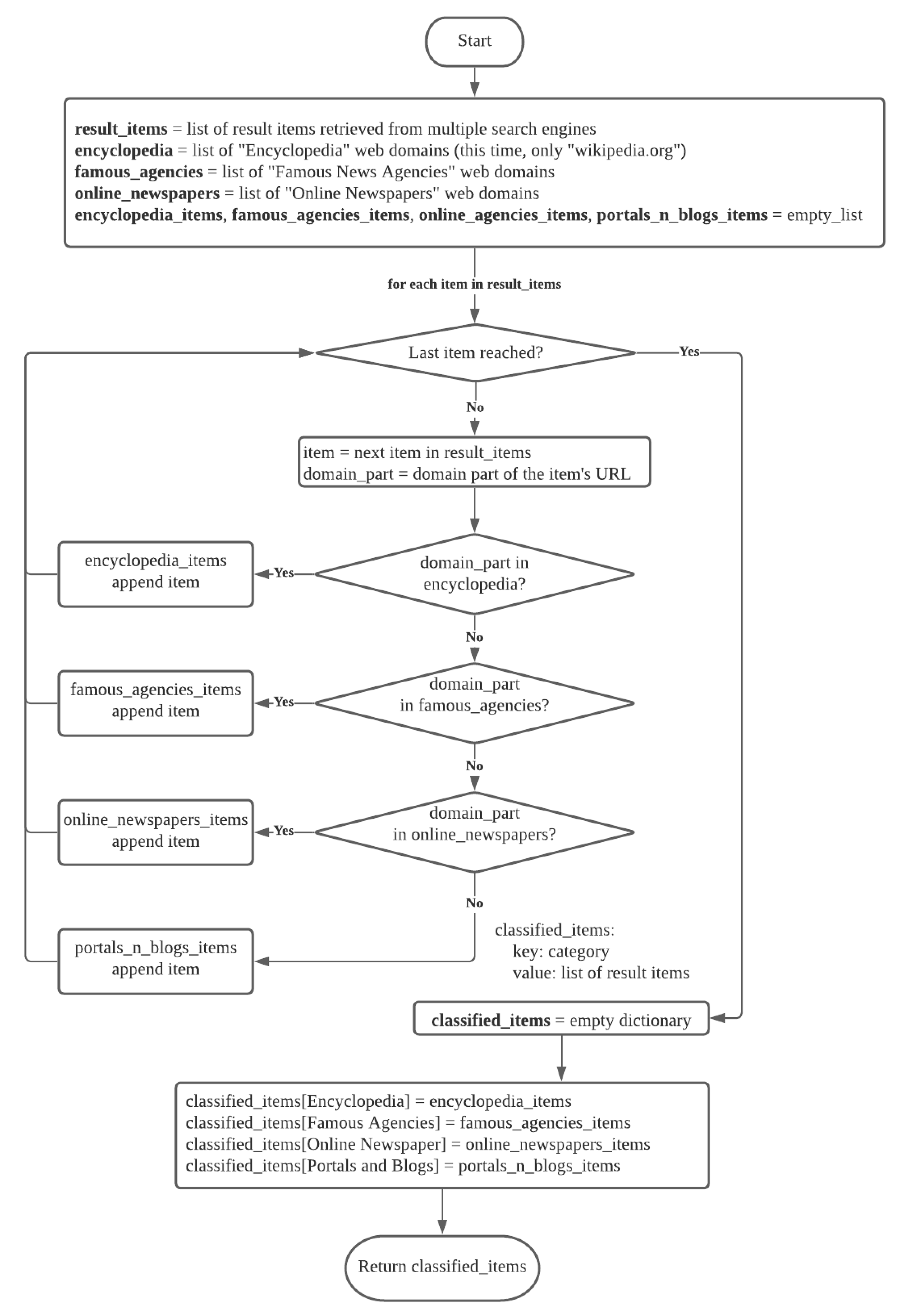
4.3. Classification of Retrieved Pages
| Listing 1. Pseudo-code of the classification process. |
 |
4.3.1. Creating the Set of URL Domains
- Remove the domain from the set if the organization or their website is no longer available;
- Renew the domain if it is no longer available but the same media is available in another domain; and
- Add additional domains if the particular media has a page written in another language.
4.3.2. Maintenance of the Set of URLs
4.4. Selection of Search Results
| Listing 2. Pseudo-code of the selection process. |
 |
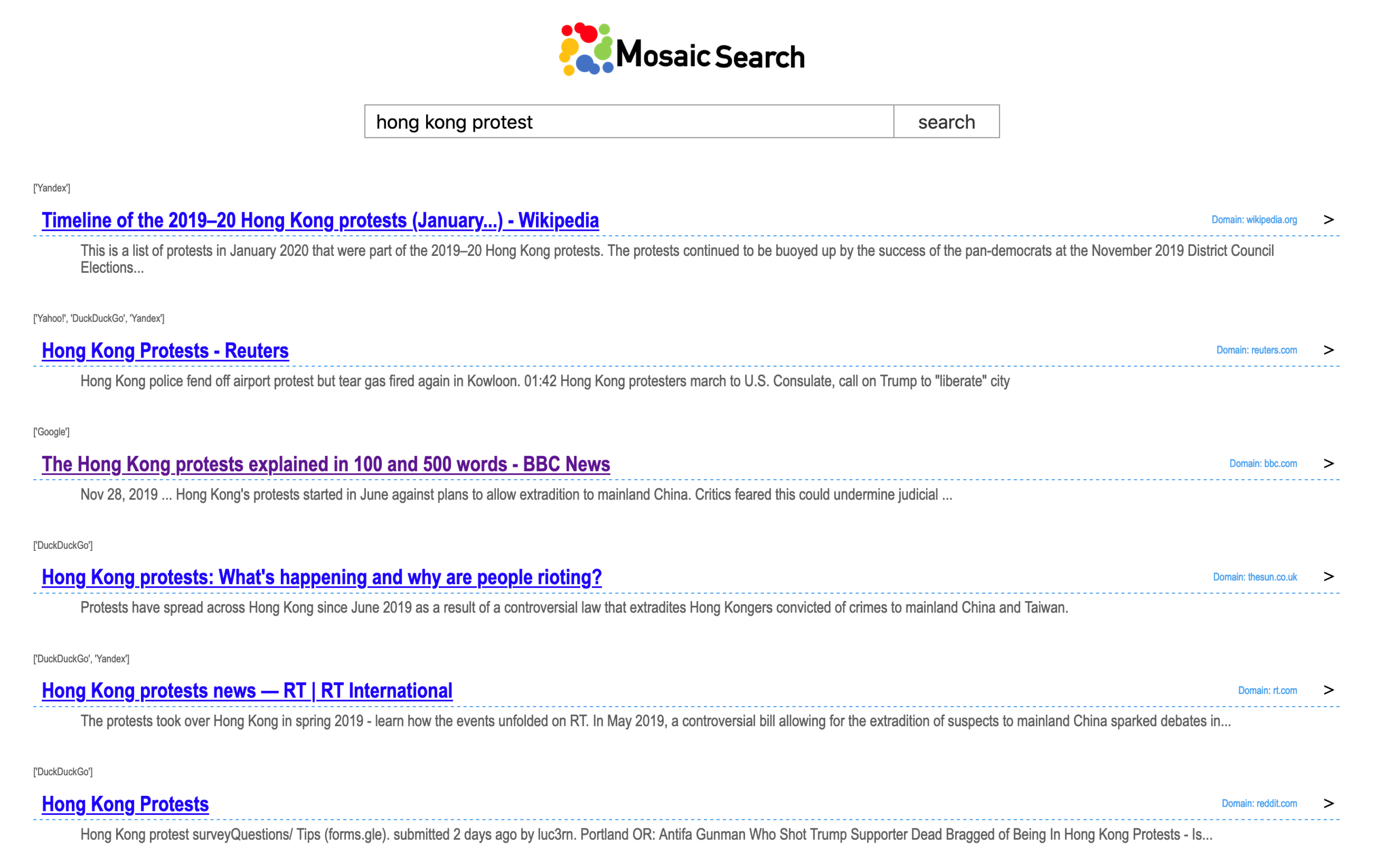
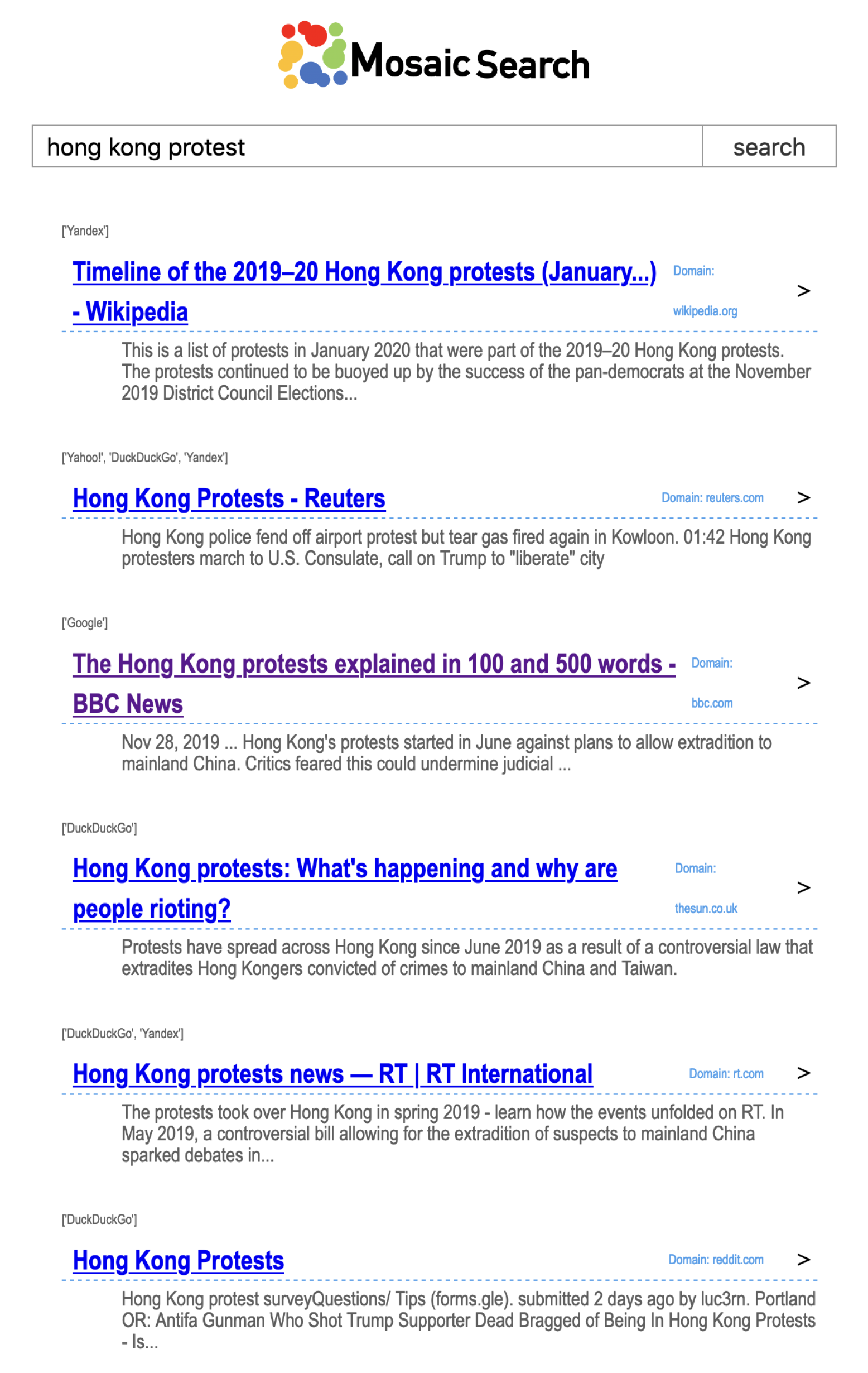
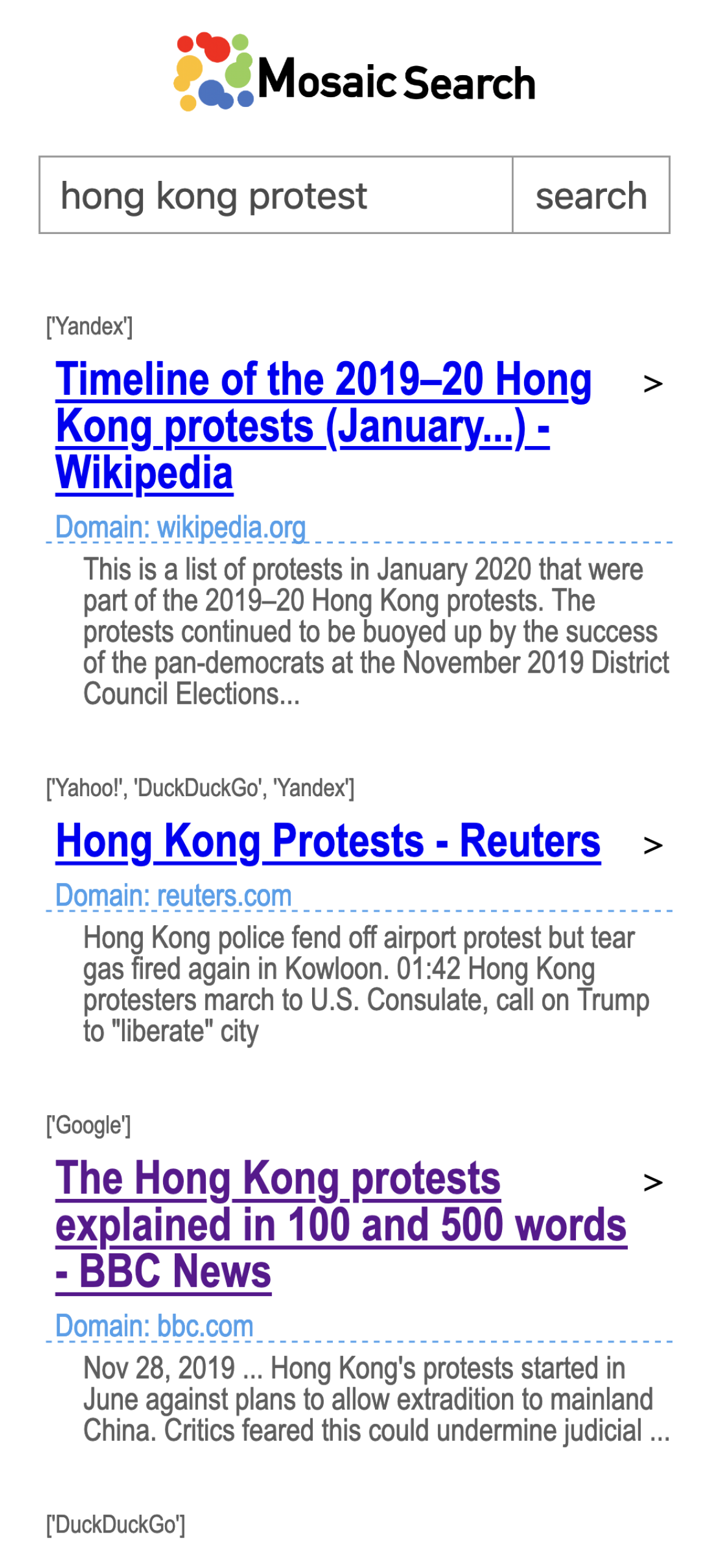
4.5. Presentation of the Selected Results
4.6. Implementation and Deployment of the Application in Practice
5. Evaluation and Analysis
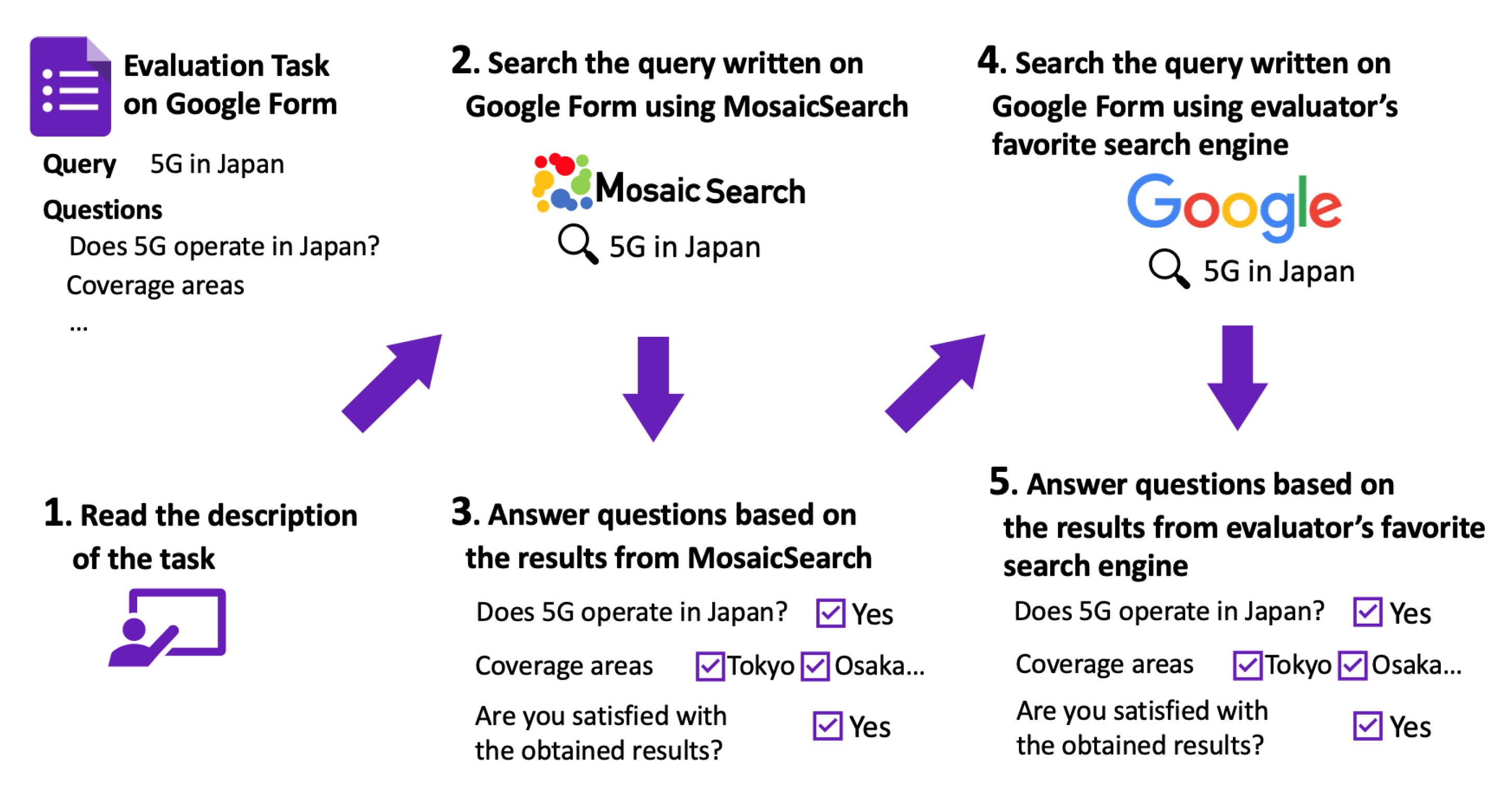
5.1. Method
5.1.1. Overview
5.1.2. Content of the Evaluation Task
5.1.3. Queries for the Evaluation
5.1.4. Set of Questions
5.1.5. Evaluation Period
5.2. Result and Analysis
5.2.1. Evaluators’ Backgrounds
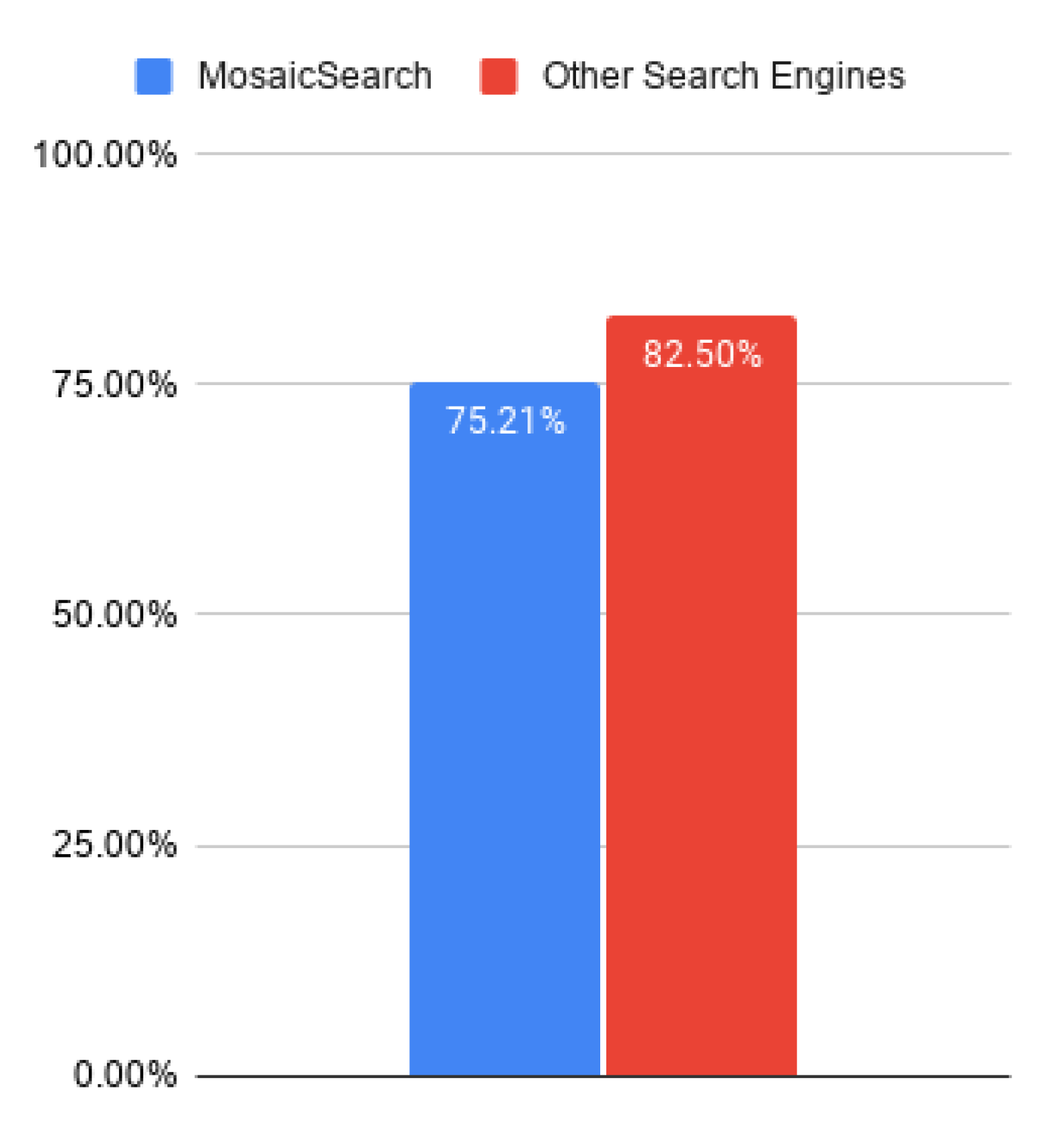
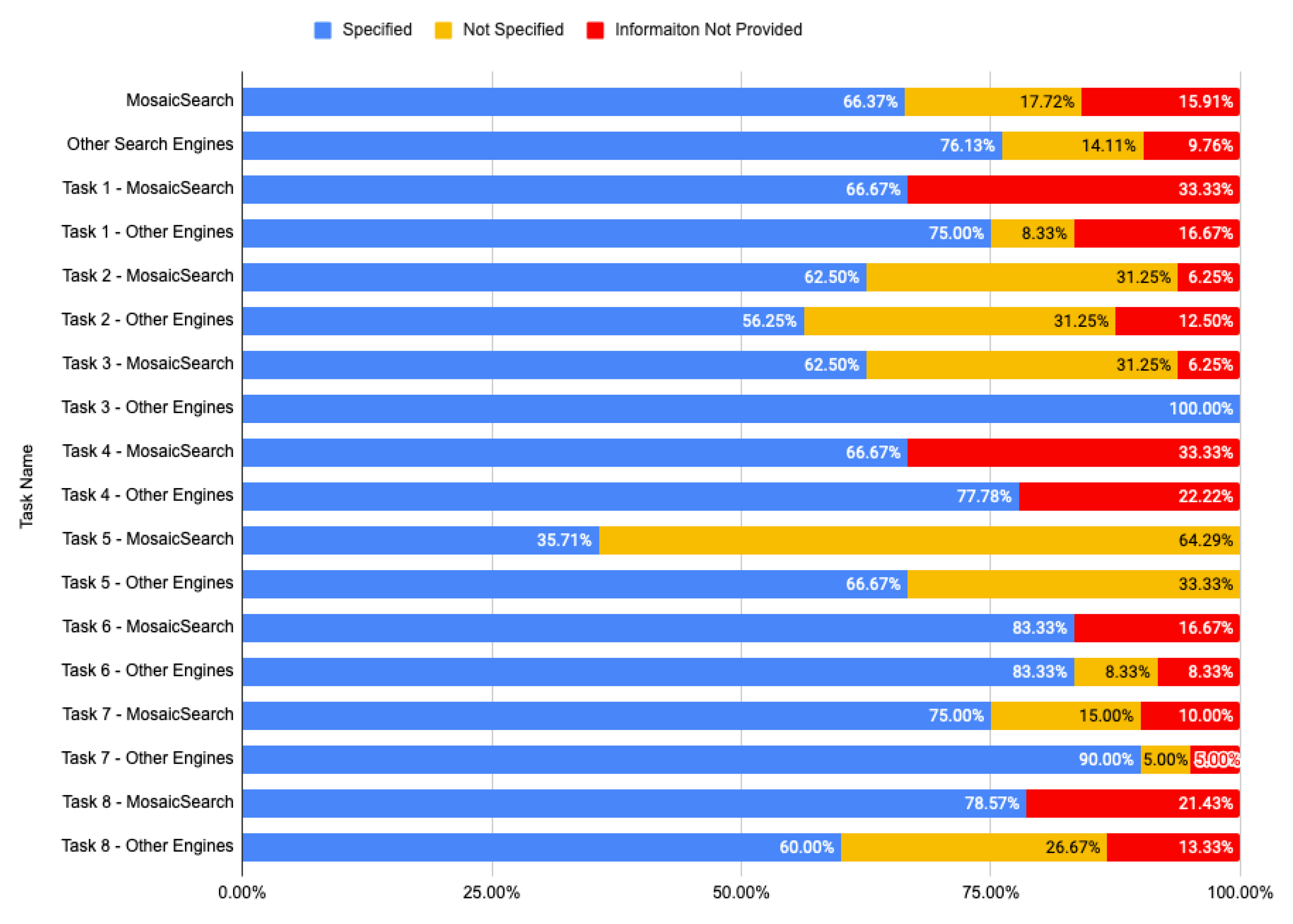
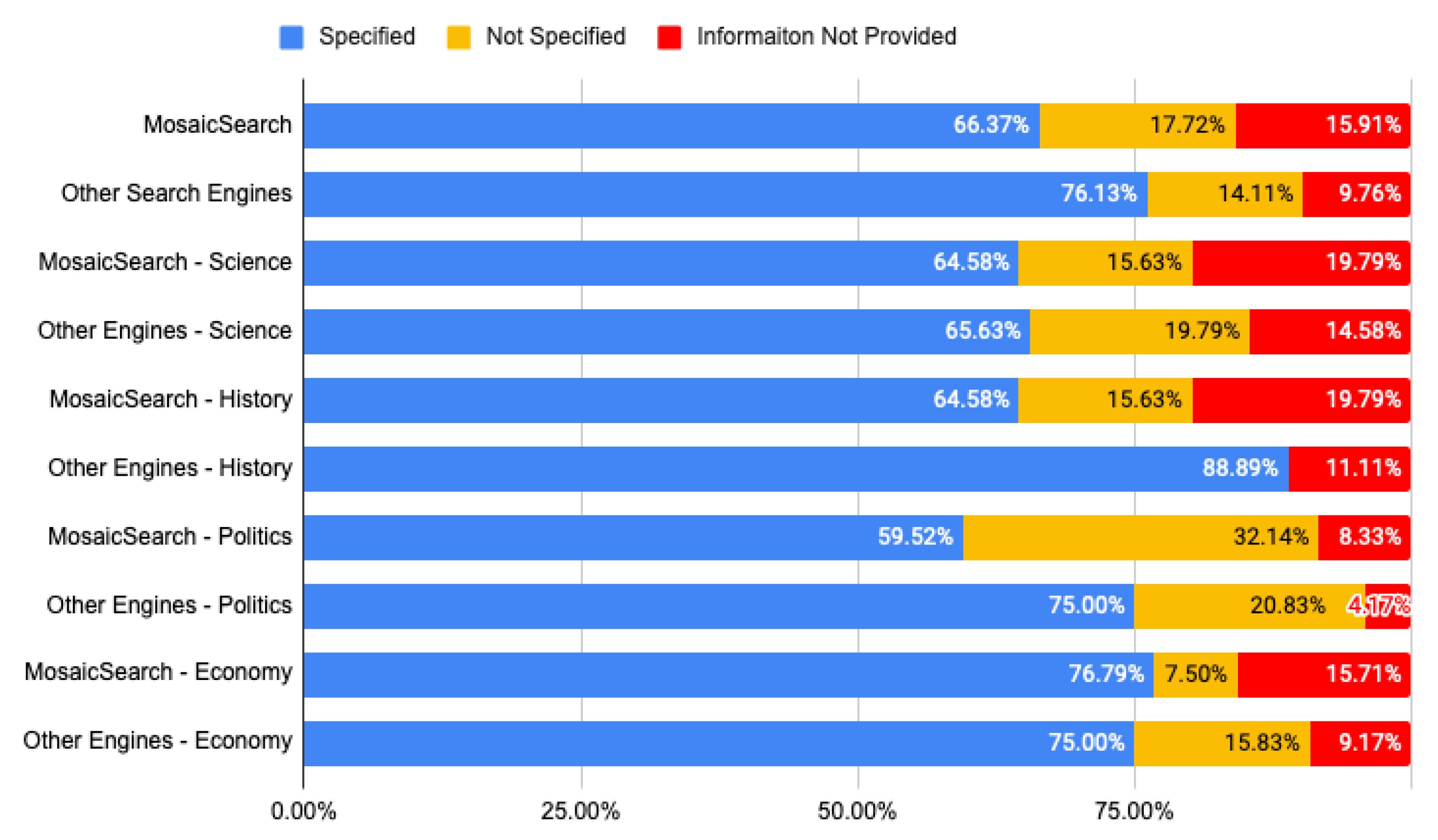
5.2.2. Collected Answers
6. Discussion
6.1. Advantages and Disadvantages of MosaicSearch
6.2. Possible Improvements as a Future Work
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| API | Application Programming Interface |
| CSS | Cascading Style Sheets |
| URL | Uniform Resource Locator |
| JSON | JavaScript Object Notation |
| XML | Extensible Markup Language |
References
- Shearer, E.; Grieco, E. Americans are wary of the role social media sites play in delivering the news. Pew Res. Cent. 2019, 2. Available online: https://mth101.com/wp-content/uploads/2019/10/FS19_Midterm-Articles.pdf (accessed on 3 February 2021).
- Newman, N. Executive Summary and Key Findings of the 2020 Report; Technical report; Reuters Institute for the Study of Journalism: Oxford, UK, 2020. [Google Scholar]
- Guess, A.; Nyhan, B.; Reifler, J. Selective exposure to misinformation: Evidence from the consumption of fake news during the 2016 US presidential campaign. Eur. Res. Counc. 2018, 9, 4. [Google Scholar]
- Silverman, C. This Analysis Shows How Viral Fake Election News Stories Outperformed Real News On Facebook. Available online: https://www.buzzfeednews.com/article/craigsilverman/viral-fake-election-news-outperformed-real-news-on-facebook (accessed on 27 December 2020).
- Epstein, R.; Robertson, R.E. The search engine manipulation effect (SEME) and its possible impact on the outcomes of elections. Proc. Natl. Acad. Sci. USA 2015, 112, E4512–E4521. [Google Scholar] [CrossRef]
- Eric, C.; Josh, W. Can Google Influence an Election? Available online: https://www.huffpost.com/entry/google-election-2012_b_1952725 (accessed on 27 December 2020).
- Dutton, W.H.; Reisdorf, B.; Dubois, E.; Blank, G. Search and politics: The uses and impacts of search in Britain, France, Germany, Italy, Poland, Spain, and the United States. Quello Cent. Work. Pap. 2017. [Google Scholar] [CrossRef]
- Hidehiko, F. Misinformation, Disinformation, and Media’s Counter News in the Age of Social Media. Available online: https://www.nhk.or.jp/bunken/english/research/domestic/20190801_5.html (accessed on 24 January 2021).
- Paresh, D. Google Workers Push to Stop Censored Search Engine Project Dragonfly Targeting China Users. Available online: https://www.japantimes.co.jp/news/2018/11/28/business/google-ranks-push-stop-censored-search-engine-project-dragonfly-targeting-china-users/ (accessed on 24 January 2021).
- D’Onfro, J. Google’s Sundar Pichai Was Grilled on Privacy, Data Collection, and China during Congressional Hearing. Available online: https://www.cnbc.com/2018/12/11/google-ceo-sundar-pichai-testifies-before-congress-on-bias-privacy.html (accessed on 27 December 2020).
- Romm, T. Amazon, Apple, Facebook and Google Grilled on Capitol Hill over Their Market Power. Available online: https://www.washingtonpost.com/technology/2020/07/29/apple-google-facebook-amazon-congress-hearing/ (accessed on 27 December 2020).
- Google Grilled on ad Business Dominance by U.S. Senate Panel. Available online: https://www.reuters.com/article/us-usa-tech-google-idUSKBN2661FF (accessed on 27 December 2020).
- Del Vicario, M.; Bessi, A.; Zollo, F.; Petroni, F.; Scala, A.; Caldarelli, G.; Stanley, H.E.; Quattrociocchi, W. The spreading of misinformation online. Proc. Natl. Acad. Sci. USA 2016, 113, 554–559. [Google Scholar] [CrossRef] [PubMed]
- Wingfield, N.; Isaac, M.; Benner, K. Google and Facebook Take Aim at Fake News Sites. Available online: https://www.nytimes.com/2016/11/15/technology/google-will-ban-websites-that-host-fake-news-from-using-its-ad-service.html (accessed on 27 December 2020).
- Fact-Checking on Facebook. Available online: https://www.facebook.com/business/help/2593586717571940?id=673052479947730 (accessed on 27 December 2020).
- Launching Our Voting Information Center on Facebook and Instagram. Available online: https://www.facebook.com/business/news/launching-our-voting-information-center-on-facebook-and-instagram (accessed on 27 December 2020).
- Nguyen, C.T. Echo Chambers and Epistemic Bubbles. Episteme 2020, 17, 141–161. [Google Scholar] [CrossRef]
- DiFranzo, D.; Gloria-Garcia, K. Filter bubbles and fake news. XRDS Crossroads ACM Mag. Stud. 2017, 23, 32–35. [Google Scholar] [CrossRef]
- Bruns, A. Echo chamber? What echo chamber? Reviewing the evidence. In Proceedings of the 6th Biennial Future of Journalism Conference (FOJ17), Cardiff, UK, 14–15 September 2017. [Google Scholar]
- Ćurković, M.; Košec, A. Bubble effect: Including internet search engines in systematic reviews introduces selection bias and impedes scientific reproducibility. BMC Med. Res. Methodol. 2018, 18, 130. [Google Scholar] [CrossRef] [PubMed]
- Holone, H. The filter bubble and its effect on online personal health information. Croat. Med. J. 2016, 57, 298. [Google Scholar] [CrossRef] [PubMed]
- Filter Bubble. Available online: https://dictionary.cambridge.org/ja/dictionary/english/filter-bubble (accessed on 27 December 2020).
- Indriani, S.S.; Prasanti, D.; Permana, R.S.M. Analysis of The Filter Bubble Phenomenon in The Use of Online Media for Millennial Generation (An Ethnography Virtual Study about The Filter Bubble Phenomenon). Nyimak J. Commun. 2020, 4, 199–209. [Google Scholar] [CrossRef]
- Nemoto, Y.; Klyuev, V. Mechanisms to Discover the Real News on the Internet. In Proceedings of the Fourteenth International Conference on Digital Society (ICDS2020), IARIA, Valencia, Spain, 21–25 November 2020; pp. 8–12. [Google Scholar]
- Klyuev, V. Finding the Real News in News Streams. In Proceedings of the 2019 Amity International Conference on Artificial Intelligence (AICAI), Dubai, United Arab Emirates, 4–6 February 2019; pp. 21–24. [Google Scholar]
- Amrollahi, A. Burst the Filter Bubble: Towards an Integrated Tool. In Proceedings of the Australasian Conference on Information Systems (30th: 2019), ACIS, Perth, Australia, 9–11 December 2019; pp. 12–20. [Google Scholar]
- Gao, M.; Do, H.J.; Fu, W.T. Burst your bubble! An intelligent system for improving awareness of diverse social opinions. In Proceedings of the 23rd International Conference on Intelligent User Interfaces, Tokyo, Japan, 7–11 March 2018; pp. 371–383. [Google Scholar]
- Orbach, M.; Bilu, Y.; Toledo, A.; Lahav, D.; Jacovi, M.; Aharonov, R.; Slonim, N. Out of the Echo Chamber: Detecting Countering Debate Speeches. arXiv 2020, arXiv:2005.01157. [Google Scholar]
- Foth, M.; Tomitsch, M.; Forlano, L.; Haeusler, M.H.; Satchell, C. Citizens breaking out of filter bubbles: Urban screens as civic media. In Proceedings of the 5th ACM International Symposium on Pervasive Displays, Oulu, Finland, 20–22 June 2016; pp. 140–147. [Google Scholar]
- Curkovic, M. The implications of using internet search Engines in Structured Scientific Reviews. Sci. Eng. Ethics 2019, 25, 645–646. [Google Scholar] [CrossRef] [PubMed]
- Haddaway, N.R.; Collins, A.M.; Coughlin, D.; Kirk, S. A rapid method to increase transparency and efficiency in web-based searches. Environ. Evid. 2017, 6, 1. [Google Scholar] [CrossRef]
- Prakash, S. Filter Bubble: How to burst your filter bubble. Int. J. Eng. Comput. Sci. 2016, 5, 18321–18325. [Google Scholar] [CrossRef]
- Lawrence, S.R.; Giles, C.L. Meta Search Engine. U.S. Patent No. 6,999,959, 14 February 2006. [Google Scholar]
- Mahmud, S.H.; Rabbi, M.F.; Guy-Fernand, K.N. An Agent-based Meta-Search Engine Architecture for Open Government Datasets Search. Communications 2016, 4, 21–25. [Google Scholar]
- Malhotra, D.; Rishi, O. IMSS-E: An intelligent approach to design of adaptive meta search system for E commerce website ranking. In Proceedings of the International Conference on Advances in Information Communication Technology & Computing, Bikaner, India, 12 November 2016; pp. 1–6. [Google Scholar]
- Desktop Search Engine Market Share Worldwide—October 2020. Available online: https://gs.statcounter.com/search-engine-market-share/desktop/worldwide/#monthly-202007-202007-bar (accessed on 27 December 2020).
- Search Engine Market Share. Available online: https://netmarketshare.com/search-engine-market-share.aspx (accessed on 27 December 2020).
- Microsoft and Yahoo Seal Web Deal. Available online: http://news.bbc.co.uk/2/hi/business/8174763.stm (accessed on 27 December 2020).
- Lewandowski, D. Living in a world of biased search engines. Online Inf. Rev. 2015, 39. [Google Scholar] [CrossRef]
- Richardson, L. Beautiful Soup Documentation. Available online: https://www.crummy.com/software/BeautifulSoup/bs4/doc/ (accessed on 27 December 2020).
- Southern, M. Over 25% of People Click the First Google Search Result. Available online: https://www.searchenginejournal.com/google-first-page-clicks/374516/ (accessed on 27 December 2020).
- Programmable Search Engine. Available online: https://developers.google.com/custom-search/docs/overview (accessed on 27 December 2020).
- Developer’s Guide. Available online: https://yandex.com/dev/xml/doc/dg/concepts/about.html/ (accessed on 27 December 2020).
- News Agencies. Available online: https://www.sciencedirect.com/topics/social-sciences/news-agencies (accessed on 20 November 2020).
- 2019 News Agencies Web Ranking. Available online: https://www.4imn.com/news-agencies/ (accessed on 20 November 2020).
- 2019 Newspaper Web Rankings. Available online: https://www.4imn.com/top200/ (accessed on 20 November 2020).
- International News Outlets. Available online: https://www.ohio.edu/global/international (accessed on 20 November 2020).
- Number of Smartphone Users from 2016 to 2021. Available online: https://www.statista.com/statistics/330695/number-of-smartphone-users-worldwide/ (accessed on 27 December 2020).
- Mobile Fact Sheet. Available online: https://www.pewresearch.org/internet/fact-sheet/mobile/ (accessed on 27 December 2020).
- Iqbal, M. Facebook Revenue and Usage Statistics. 2020. Available online: https://www.businessofapps.com/data/facebook-statistics/ (accessed on 27 December 2020).
- Lestari, D.M.; Hardianto, D.; Hidayanto, A.N. Analysis of user experience quality on responsive web design from its informative perspective. Int. J. Softw. Eng. Its Appl. 2014, 8, 53–62. [Google Scholar]
- Common Viewport Sizes for Mobile. Available online: https://www.icwebdesign.co.uk/common-viewport-sizes (accessed on 27 December 2020).
- Nemoto, Y. MosaicSearch Source Code. Available online: https://zenodo.org/record/4460978#.YBoH1nkRWUk (accessed on 3 February 2021).
- Kumar, B.S.; Prakash, J. Precision and relative recall of search engines: A comparative study of Google and Yahoo. Singap. J. Libr. Inf. Manag. 2009, 38, 124–137. [Google Scholar]
- Vaughan, L. New measurements for search engine evaluation proposed and tested. Inf. Process. Manag. 2004, 40, 677–691. [Google Scholar] [CrossRef]
- Hawking, D.; Craswell, N.; Bailey, P.; Griffihs, K. Measuring search engine quality. Inf. Retr. 2001, 4, 33–59. [Google Scholar] [CrossRef]
- Yuta, N.; Vitaly, K. Result of the MosaicSearch Performance Evaluation. Available online: https://doi.org/10.6084/m9.figshare.845654?noredirect (accessed on 3 February 2021).
- Li, L.; Shang, Y.; Zhang, W. Relevance Evaluation of Search Engines’ Query Results; Available online: http://www10.org/cdrom/posters/1017.pdf (accessed on 3 February 2021).
- Liu, Y.; Fu, Y.; Zhang, M.; Ma, S.; Ru, L. Automatic search engine performance evaluation with click-through data analysis. In Proceedings of the 16th international conference on World Wide Web, Banff, AB, Canada, 8–12 May 2007; pp. 1133–1134. [Google Scholar]
- Sharma, H.; Jansen, B.J. Automated evaluation of search engine performance via implicit user feedback. In Proceedings of the 28th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Salvador, Brazil, 15–19 August 2005; pp. 649–650. [Google Scholar]












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Search Engine | Market Share on Statscounter | Market Share on NetMarketShare | Owner Company | Country of Origin | API Availability | Scraping Difficulty |
|---|---|---|---|---|---|---|
| 86.86% | 69.80% | Google LLC | US | Available | Difficult | |
| Bing | 6.43% | 13.31% | Microsoft Corporation | US | Available | Difficult |
| Yahoo! | 2.84% | 2.11% | Yahoo! Inc. | US | Unavailable | Easy |
| Baidu | 0.68% | 12.53% | Baidu, Inc. | China | Unavailable | Difficult |
| Duck-DuckGo | 0.65% | 0.43% | Duck Duck Go, Inc. | US | Unavailable | Easy |
| Yandex | 0.62 (+0.63)% | 1.19% | Yandex LLC | Russia | Available | Difficult |
| Others | 1.28% | 0.63% | - | - | - | - |
| Category | Query |
|---|---|
| Science | 5G in Japan |
| Science | COVID-19 Vaccine |
| History | Conflict in Cyprus in 1967 |
| History | How big were reparation payments by Germany after the First World War? |
| Politics | Debate 2020 in USA |
| Politics | Yellow vests in France |
| Economy | World economy shrinking in 2020 |
| Economy | Unemployment rate in the world in 2020 |
| Queries | Questions | Options | |
|---|---|---|---|
| Num. | Question Content | ||
| 5G in Japan | 1 | Does 5G operate in Japan? | Yes/No |
| 2 | Coverage areas (multiple choice) | Tokyo/Osaka/Nagoya/Sapporo/Big Cities | |
| 3 | Date of the coverage of the whole Japan | Specified/Not specified | |
| 4 | Are you as the user satisfied with the obtained results of the search? | Yes/No | |
| 5 | Free way impression (write freely about the quality of the search results) | ||
| COVID-19 Vaccine | 1 | Countries developing this vaccine | Specified/Not specified |
| 2 | Countries registered developed vaccines | Specified/Not specified | |
| 3 | The possible side effects | Specified/Not specified | |
| 4 | Expected date of the vaccine availability in Japan | Specified/Not specified | |
| 5 | Are you as the user satisfied with the obtained results of the search? | Yes/No | |
| 6 | Free way impression (write freely about the quality of the search results) | ||
| Conflict in Cyprus in 1967 | 1 | Reasons for the conflict: explanation from both sides are provided | Yes/No |
| 2 | Casualties during the conflict | Specified/Not specified | |
| 3 | Duration of the conflict | Specified/Not specified | |
| 4 | Results of the conflict | Specified/Not specified | |
| 5 | Are you as the user satisfied with the obtained results of the search? | Yes/No | |
| 6 | Free way impression (write freely\about the quality of the search results) | ||
| How big were reparation payments by Germany after the First World War? | 1 | Absolute numbers | Specified/Not specified |
| 2 | Percentage to entire global GDP | Specified/Not specified | |
| 3 | Duration in years for payment | Specified/Not specified | |
| 4 | Are you as the user satisfied with the obtained results of the search? | Yes/No | |
| 5 | Free way impression (write freely about the quality of the search results) | ||
| Queries | Questions | Options | |
|---|---|---|---|
| Num. | Question Content | ||
| Debate 2020 in USA | 1 | The number of debates between candidates | Specified/Not specified |
| 2 | Winners in the debates | Specified/Not specified | |
| 3 | Specifics compared to the previous election campaign in 2016 | Specified/Not specified | |
| 4 | Publication expressing the sympathy to only one candidate | Exists/Not exists | |
| 5 | Are you as the user satisfied with the obtained results of the search? | Yes/No | |
| 6 | Free way impression (write freely about the quality of the search results) | ||
| Yellow vests in France | 1 | The history of this political movement | Specified/Not specified |
| 2 | The latest actions are described? | Yes, it’s described. /No, it’s not described. | |
| 3 | Response of the French government | Specified/Not specified | |
| 4 | Are you as the user satisfied with the obtained results of the search? | Yes/No | |
| 5 | Free way impression (write freely about the quality of the search results) | ||
| World economy shrinking in 2020 | 1 | Cause of the shrinking is explained? | Yes/No |
| 2 | Countries with the worse situations are named? | Yes/No | |
| 3 | Anti-crisis measures are described | Yes/No | |
| 4 | Recovery duration | Specified/Not specified | |
| 5 | Are you as the user satisfied with the obtained results of the search? | Yes/No | |
| 6 | Free way impression (write freely about the quality of the search results) | ||
| Unemployment rate in the world in 2020 | 1 | Unemployment rate in different countries, such as United States, China, or Turkey | Specified/Not specified |
| 2 | Reasons to increase unemployment | Specified/Not specified | |
| 3 | Actions to improve the situation | Specified/Not specified | |
| 4 | Are you as the user satisfied with the obtained results of the search? | Yes/No | |
| 5 | Free way impression (write freely about the quality of the search results) | ||
| Category | Query | Number of Submissions |
|---|---|---|
| Science | 5G in Japan | 4 |
| Science | COVID-19 Vaccine | 4 |
| History | Conflict in Cyprus in 1967 | 4 |
| History | How big were reparation payments by Germany after the First World War? | 3 |
| Politics | Debate 2020 in USA | 5 |
| Politics | Yellow vests in France | 4 |
| Economy | World economy shrinking in 2020 | 5 |
| Economy | Unemployment rate in the world in 2020 | 5 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Nemoto, Y.; Klyuev, V. Tool to Retrieve Less-Filtered Information from the Internet. Information 2021, 12, 65. https://doi.org/10.3390/info12020065
Nemoto Y, Klyuev V. Tool to Retrieve Less-Filtered Information from the Internet. Information. 2021; 12(2):65. https://doi.org/10.3390/info12020065
Chicago/Turabian StyleNemoto, Yuta, and Vitaly Klyuev. 2021. "Tool to Retrieve Less-Filtered Information from the Internet" Information 12, no. 2: 65. https://doi.org/10.3390/info12020065
APA StyleNemoto, Y., & Klyuev, V. (2021). Tool to Retrieve Less-Filtered Information from the Internet. Information, 12(2), 65. https://doi.org/10.3390/info12020065