
Semantic Mapping for Mobile Robots in Indoor Scenes: A Survey


Abstract
:1. Introduction
2. Definitions of Semantic Map
“A semantic map for a mobile robot is a map that contains, in addition to spatial information about the environment, assignments of mapped features to entities of known classes. Further knowledge about these entities, independent of the map contents, is available for reasoning in some knowledge base with an associated reasoning engine.”
where E is a mathematical description of the local environment, D is task domain, is a set of maps for E, and is a set of links.“A semantic map for E limited to D is a tuple ... is a structure, which represents knowledge about the relationships between entities, classes, and attributes, also known as common-sense knowledge about D. Generally, can be defined in an arbitrary way and has to allow for inference.”
3. Spatial Mapping
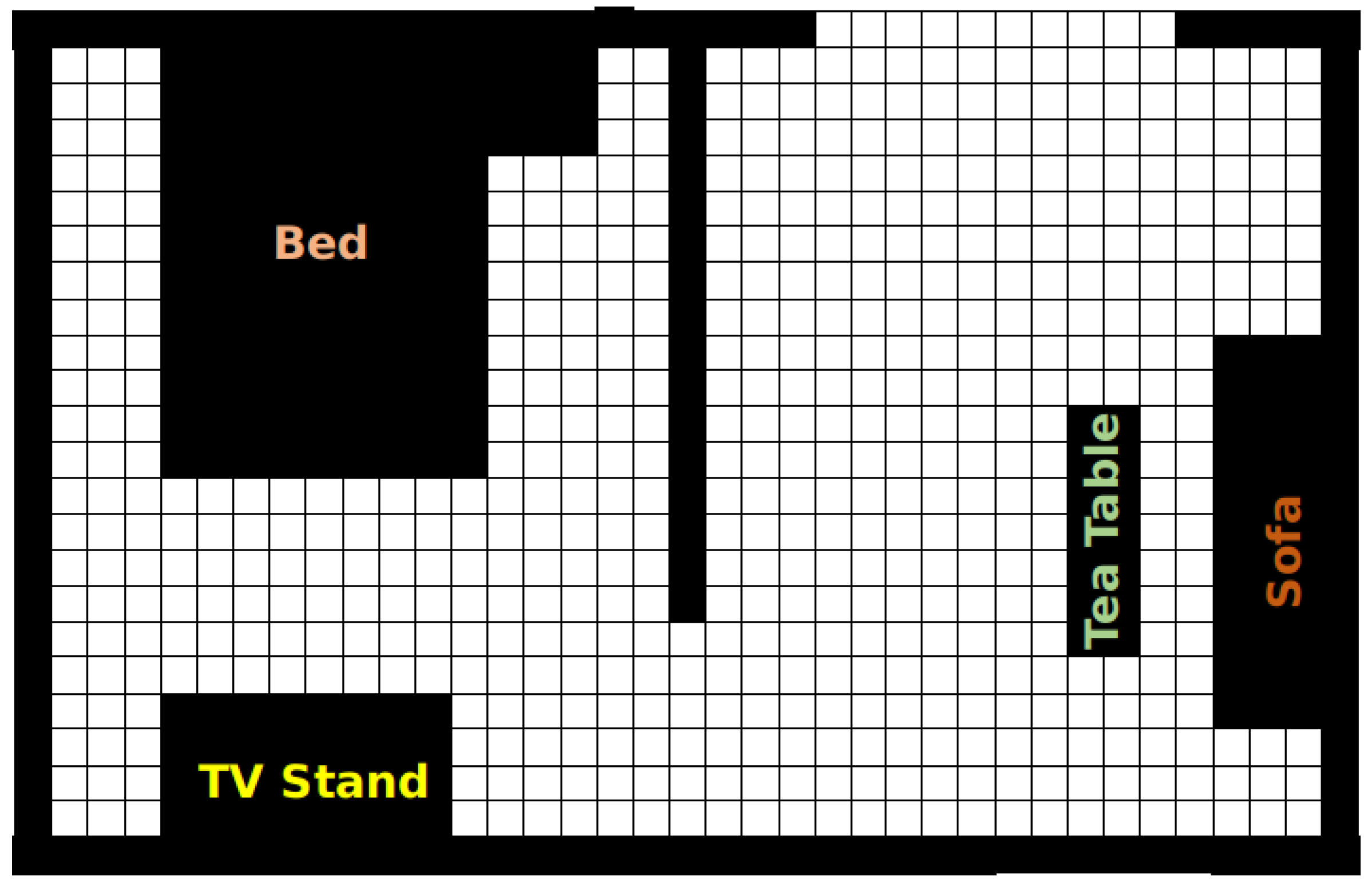
4. Acquisition of Semantic Information
4.1. Human Input
4.2. Sensor-Based Methods
4.3. Inference
5. Map Representation
6. Open Issues and Potential Directions
6.1. Heterogeneous Sensor Fusion
6.2. Dynamic Scenes and Open World
6.3. Cloud Robotics
6.4. Task-Oriented Map Representation
7. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Ding, H.; Yang, X.; Zheng, N.; Li, M.; Lai, Y.; Wu, H. Tri-Co Robot: A Chinese robotic research initiative for enhanced robot interaction capabilities. Natl. Sci. Rev. 2017, 5, 799–801. [Google Scholar] [CrossRef]
- Paulus, D.; Lang, D. Semantic Maps for Robotics. 2014. Available online: http://people.csail.mit.edu/gdk/iros-airob14/papers/Lang_finalSubmission_SemantiCmapsForRobots.pdf (accessed on 18 February 2021).
- Kostavelis, I.; Gasteratos, A. Semantic mapping for mobile robotics tasks: A survey. Robot. Auton. Syst. 2015, 66, 86–103. [Google Scholar] [CrossRef]
- Liu, Q.; Li, R.; Hu, H.; Gu, D. Extracting semantic information from visual data: A survey. Robotics 2016, 5, 8. [Google Scholar] [CrossRef] [Green Version]
- Cadena, C.; Carlone, L.; Carrillo, H.; Latif, Y.; Scaramuzza, D.; Neira, J.; Reid, I.; Leonard, J.J. Past, Present, and Future of Simultaneous Localization and Mapping: Toward the Robust-Perception Age. IEEE Trans. Robot. 2016, 32, 1309–1332. [Google Scholar] [CrossRef] [Green Version]
- Crespo, J.; Castillo, J.C.; Mozos, O.; Barber, R. Semantic Information for Robot Navigation: A Survey. Appl. Sci. 2020, 10, 497. [Google Scholar] [CrossRef] [Green Version]
- Galindo, C.; Saffiotti, A.; Coradeschi, S.; Buschka, P.; Fernandez-Madrigal, J.A.; González, J. Multi-hierarchical semantic maps for mobile robotics. In Proceedings of the 2005 IEEE/RSJ International Conference on Intelligent Robots and Systems, Edmonton, AB, Canada, 2–6 August 2005; pp. 2278–2283. [Google Scholar]
- Nüchter, A.; Hertzberg, J. Towards semantic maps for mobile robots. Robot. Auton. Syst. 2008, 56, 915–926. [Google Scholar] [CrossRef] [Green Version]
- Case, C.; Suresh, B.; Coates, A.; Ng, A.Y. Autonomous sign reading for semantic mapping. In Proceedings of the 2011 IEEE International Conference on Robotics and Automation, Shanghai, China, 9–13 May 2011; pp. 3297–3303. [Google Scholar]
- Li, G.; Zhu, C.; Du, J.; Cheng, Q.; Sheng, W.; Chen, H. Robot semantic mapping through wearable sensor-based human activity recognition. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, Saint Paul, MN, USA, 14–18 May 2012; pp. 5228–5233. [Google Scholar]
- Pronobis, A.; Jensfelt, P. Large-scale semantic mapping and reasoning with heterogeneous modalities. In Proceedings of the 2012 IEEE International Conference on Robotics and Automation, Saint Paul, MN, USA, 14–18 May 2012; pp. 3515–3522. [Google Scholar]
- Stückler, J.; Biresev, N.; Behnke, S. Semantic mapping using object-class segmentation of RGB-D images. In Proceedings of the 2012 IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura-Algarve, Portugal, 7–12 October 2012; pp. 3005–3010. [Google Scholar]
- Salas-Moreno, R.F.; Newcombe, R.A.; Strasdat, H.; Kelly, P.H.; Davison, A.J. SLAM++: Simultaneous Localisation and Mapping at the Level of Objects. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Portland, OR, USA, 23–28 June 2013. [Google Scholar]
- Bastianelli, E.; Bloisi, D.D.; Capobianco, R.; Cossu, F.; Gemignani, G.; Iocchi, L.; Nardi, D. On-line semantic mapping. In Proceedings of the 2013 16th International Conference on Advanced Robotics (ICAR), Montevideo, Uruguay, 25–29 November 2013; pp. 1–6. [Google Scholar]
- Hermans, A.; Floros, G.; Leibe, B. Dense 3D semantic mapping of indoor scenes from RGB-D images. In Proceedings of the 2014 IEEE International Conference on Robotics and Automation (ICRA), Hong Kong, China, 31 May–7 June 2014; pp. 2631–2638. [Google Scholar]
- Li, X.; Belaroussi, R. Semi-Dense 3D Semantic Mapping from Monocular SLAM. arXiv 2016, arXiv:1611.04144. [Google Scholar]
- Sünderhauf, N.; Dayoub, F.; McMahon, S.; Talbot, B.; Schulz, R.; Corke, P.; Wyeth, G.; Upcroft, B.; Milford, M. Place categorization and semantic mapping on a mobile robot. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 5729–5736. [Google Scholar]
- McCormac, J.; Handa, A.; Davison, A.; Leutenegger, S. SemanticFusion: Dense 3D semantic mapping with convolutional neural networks. In Proceedings of the 2017 IEEE International Conference on Robotics and Automation (ICRA), Singapore, 29 May–3 June 2017; pp. 4628–4635. [Google Scholar]
- Himstedt, M.; Maehle, E. Online semantic mapping of logistic environments using RGB-D cameras. Int. J. Adv. Robot. Syst. 2017, 14, 1729881417720781. [Google Scholar] [CrossRef] [Green Version]
- Himstedt, M.; Keil, S.; Hellbach, S.; Böhme, H.J. A Robust Graph Based Framework for Building Precise Maps from Laser Range Scans. Available online: https://www.tu-chemnitz.de/etit/proaut/ICRAWorkshopFactorGraphs/ICRA_Workshop_on_Robust_and_Multimodal_Inference_in_Factor_Graphs/Program_files/2%20-%20PreciseMaps%20Slides.pdf (accessed on 18 February 2021).
- Sünderhauf, N.; Pham, T.T.; Latif, Y.; Milford, M.; Reid, I. Meaningful maps with object-oriented semantic mapping. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 5079–5085. [Google Scholar]
- Ma, L.; Stückler, J.; Kerl, C.; Cremers, D. Multi-view deep learning for consistent semantic mapping with RGB-D cameras. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 598–605. [Google Scholar] [CrossRef] [Green Version]
- Kerl, C.; Sturm, J.; Cremers, D. Dense visual SLAM for RGB-D cameras. In Proceedings of the 2013 IEEE/RSJ International Conference on Intelligent Robots and Systems, Tokyo, Japan, 3–7 November 2013; pp. 2100–2106. [Google Scholar] [CrossRef] [Green Version]
- Xiang, Y.; Fox, D. DA-RNN: Semantic Mapping with Data Associated Recurrent Neural Networks. arXiv 2017, arXiv:1703.03098,. [Google Scholar]
- Zeng, Z.; Zhou, Y.; Jenkins, O.C.; Desingh, K. Semantic Mapping with Simultaneous Object Detection and Localization. In Proceedings of the 2018 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Madrid, Spain, 1–5 October 2018; pp. 911–918. [Google Scholar]
- Grinvald, M.; Furrer, F.; Novkovic, T.; Chung, J.J.; Cadena, C.; Siegwart, R.; Nieto, J. Volumetric Instance-Aware Semantic Mapping and 3D Object Discovery. IEEE Robot. Autom. Lett. 2019, 4, 3037–3044. [Google Scholar] [CrossRef] [Green Version]
- Narita, G.; Seno, T.; Ishikawa, T.; Kaji, Y. PanopticFusion: Online Volumetric Semantic Mapping at the Level of Stuff and Things. arXiv 2019, arXiv:1903.01177. [Google Scholar]
- Oleynikova, H.; Taylor, Z.; Fehr, M.; Siegwart, R.; Nieto, J. Voxblox: Incremental 3D Euclidean Signed Distance Fields for on-board MAV planning. In Proceedings of the 2017 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Vancouver, BC, Canada, 24–28 September 2017; pp. 1366–1373. [Google Scholar] [CrossRef] [Green Version]
- Qi, X.; Wang, W.; Yuan, M.; Wang, Y.; Li, M.; Xue, L.; Sun, Y. Building semantic grid maps for domestic robot navigation. Int. J. Adv. Robot. Syst. 2020, 17, 1729881419900066. [Google Scholar] [CrossRef] [Green Version]
- Cheng, J.; Sun, Y.; Meng, M.Q.H. Robust Semantic Mapping in Challenging Environments. Robotica 2020, 38, 256–270. [Google Scholar] [CrossRef]
- Durrant-Whyte, H.; Bailey, T. Simultaneous localization and mapping: Part I. IEEE Robot. Autom. Mag. 2006, 13, 99–110. [Google Scholar] [CrossRef] [Green Version]
- Bailey, T.S.; Durrantwhyte, H. Simultaneous localization and mapping (SLAM): Part II. IEEE Robot. Autom. Mag. 2006, 13, 108–117. [Google Scholar] [CrossRef] [Green Version]
- Grisetti, G.; Kummerle, R.; Stachniss, C.; Burgard, W. A Tutorial on Graph-Based SLAM. IEEE Intell. Transp. Syst. Mag. 2010, 2, 31–43. [Google Scholar] [CrossRef]
- Grisetti, G.; Stachniss, C.; Burgard, W. Improved Techniques for Grid Mapping With Rao-Blackwellized Particle Filters. IEEE Trans. Robot. 2007, 23, 34–46. [Google Scholar] [CrossRef] [Green Version]
- Nüchter, A.; Lingemann, K.; Hertzberg, J.; Surmann, H. 6D SLAM—3D mapping outdoor environments. J. Field Robot. 2007, 24, 699–722. [Google Scholar] [CrossRef] [Green Version]
- Lee, K.; Lee, S.J.; Kölsch, M.; Chung, W.K. Enhanced maximum likelihood grid map with reprocessing incorrect sonar measurements. Auton. Robot. 2013, 35, 123–141. [Google Scholar] [CrossRef]
- Huang, A.S.; Bachrach, A.; Henry, P.; Krainin, M.; Maturana, D.; Fox, D.; Roy, N. Visual Odometry and Mapping for Autonomous Flight Using an RGB-D Camera. In Robotics Research: The 15th International Symposium ISRR; Christensen, H.I., Khatib, O., Eds.; Springer International Publishing: Cham, Switzerland, 2017; pp. 235–252. [Google Scholar]
- Engel, J.; Schöps, T.; Cremers, D. LSD-SLAM: Large-Scale Direct Monocular SLAM. In Computer Vision—ECCV 2014; Fleet, D., Pajdla, T., Schiele, B., Tuytelaars, T., Eds.; Springer International Publishing: Cham, Switzerland, 2014; pp. 834–849. [Google Scholar]
- Whelan, T.; Salas-Moreno, R.F.; Glocker, B.; Davison, A.J.; Leutenegger, S. ElasticFusion: Real-time dense SLAM and light source estimation. Int. J. Robot. Res. 2016, 35, 1697–1716. [Google Scholar] [CrossRef] [Green Version]
- Mur-Artal, R.; Tardós, J.D. ORB-SLAM2: An Open-Source SLAM System for Monocular, Stereo, and RGB-D Cameras. IEEE Trans. Robot. 2017, 33, 1255–1262. [Google Scholar] [CrossRef] [Green Version]
- Lu, D.V.; Hershberger, D.; Smart, W.D. Layered Costmaps for Context-Sensitive Navigation. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Chicago, IL, USA, 14–18 September 2014. [Google Scholar]
- Mörwald, T.; Prankl, J.; Richtsfeld, A.; Zillich, M.; Vincze, M. BlLORT—The Blocks World Robotic Vision Toolbox. Available online: http://users.acin.tuwien.ac.at/mzillich/files/moerwald2010blort.pdf (accessed on 18 February 2021).
- Newcombe, R.A.; Izadi, S.; Hilliges, O.; Molyneaux, D.; Kim, D.; Davison, A.J.; Kohi, P.; Shotton, J.; Hodges, S.; Fitzgibbon, A. KinectFusion: Real-time dense surface mapping and tracking. In Proceedings of the 2011 10th IEEE International Symposium on Mixed and Augmented Reality, Basel, Switzerland, 26–29 October 2011; pp. 127–136. [Google Scholar]
- Freund, Y.; Schapire, R.E. Experiments with a New Boosting Algorithm. Available online: https://cseweb.ucsd.edu/~yfreund/papers/boostingexperiments.pdf (accessed on 18 February 2021).
- Cebollada, S.; Payá, L.; Flores, M.; Peidró, A.; Reinoso, O. A state-of-the-art review on mobile robotics tasks using artificial intelligence and visual data. Expert Syst. Appl. 2020, 114195. [Google Scholar] [CrossRef]
- Chen, L.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 40, 834–848. [Google Scholar] [CrossRef]
- Zhou, B.; Lapedriza, A.; Xiao, J.; Torralba, A.; Oliva, A. Learning Deep Features for Scene Recognition using Places Database. In Advances in Neural Information Processing Systems 27; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N.D., Weinberger, K.Q., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2014; pp. 487–495. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. In Advances in Neural Information Processing Systems 28; Cortes, C., Lawrence, N.D., Lee, D.D., Sugiyama, M., Garnett, R., Eds.; Curran Associates, Inc.: Red Hook, NY, USA, 2015; pp. 91–99. [Google Scholar]
- Karlsson, L. Conditional Progressive Planning under Uncertainty. Available online: https://www.researchgate.net/publication/2927504_Conditional_Progressive_Planning_under_Uncertainty (accessed on 18 February 2021).
- Fischler, M.A.; Bolles, R.C. Random Sample Consensus: A Paradigm for Model Fitting with Applications to Image Analysis and Automated Cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Lauritzen, S.L.; Richardson, T.S. Chain graph models and their causal interpretations. J. R. Stat. Soc. Ser. Stat. Methodol. 2002, 64, 321–348. [Google Scholar] [CrossRef]
- Mooij, J.M. libDAI: A Free and Open Source C++ Library for Discrete Approximate Inference in Graphical Models. J. Mach. Learn. Res. 2010, 11, 2169–2173. [Google Scholar]
- Yang, Z.; Shen, S. Monocular Visual–Inertial State Estimation With Online Initialization and Camera–IMU Extrinsic Calibration. IEEE Trans. Autom. Sci. Eng. 2017, 14, 39–51. [Google Scholar] [CrossRef]
- Kang, R.; Xiong, L.; Xu, M.; Zhao, J.; Zhang, P. VINS-Vehicle: A Tightly-Coupled Vehicle Dynamics Extension to Visual-Inertial State Estimator. In Proceedings of the 2019 IEEE Intelligent Transportation Systems Conference (ITSC), Auckland, New Zealand, 27–30 October 2019; pp. 3593–3600. [Google Scholar]
- Liu, H.; Yu, Y.; Sun, F.; Gu, J. Visual–Tactile Fusion for Object Recognition. IEEE Trans. Autom. Sci. Eng. 2017, 14, 996–1008. [Google Scholar] [CrossRef]
- Riazuelo, L.; Tenorth, M.; Di Marco, D.; Salas, M.; Gálvez-López, D.; Mösenlechner, L.; Kunze, L.; Beetz, M.; Tardós, J.D.; Montano, L.; et al. RoboEarth Semantic Mapping: A Cloud Enabled Knowledge-Based Approach. IEEE Trans. Autom. Sci. Eng. 2015, 12, 432–443. [Google Scholar] [CrossRef] [Green Version]



{kind=link}
{kind=link}
{kind=link}
| Reference | Topic | Year |
|---|---|---|
| Paulus and Lang [2] | Definition of Semantic Mapping | 2014 |
| Kostavelis and Gasteratos [3] | Semantic Mapping | 2015 |
| Liu et al. [4] | Semantic Information Extraction | 2016 |
| Cadena et al. [5] | History and Trends of SLAM | 2016 |
| Crespo et al. [6] | Semantic Navigation | 2020 |
| Reference | Sensors | SLAM methods | Acquisition Method | Content | Map Representation | Applications |
|---|---|---|---|---|---|---|
| [7] | sonar ring, laser, color camera | - | simplified instances and reference | object and room categories | two hierarchies | - |
| [8] | 3D laser range | 6D SLAM | reference and model matching | plain label and instance category | - | - |
| [9] | 2D laser and a camera | GMapping | text detection and OCR | room information | - | - |
| [10] | Hokuyo laser range and Wearable motion sensors | - | reference | furniture type | - | - |
| [11] | laser scans, cameras, odometer | EKF SLAM | instance recognition and inference and property classification | instance category, room category and geometric property | 4-layer architecture | reasoning about unexplored area |
| [12] | RGBD camera | - | 2D instance segmentation | instances category | - | - |
| [13] | Depth camera | SLAM++ | instance matching | instance category | - | augmented reality and relocalization |
| [14] | RGBD camera | - | human-robot interaction | * | world knowledge and domain knowledge | - |
| [15] | RGBD camera | - | dense scene segmentation | object category and background | - | - |
| [16] | RGB camera | LSD SLAM | CNN based 2D segmentation | object category and background | - | - |
| [17] | RGBD camera | GMapping | place classification | scene category | - | behave in human rules |
| [18] | RGBD camera | KinectFusion | CNN based 2D segmentation | object category and background | - | - |
| [19] | RGBD camera | graph-based SLAM [20] | CNN and SVM | object category | - | - |
| [21] | RGBD camera | ORB SLAM | SSD | object category | - | - |
| [22] | RGBD camera | DVO SLAM [23] | CNN-based semantic segmentation | object category and background | - | - |
| [24] | RGBD camera | Kinect Fusion | FCN sementic segmentation | object category and background | - | - |
| [25] | RGBD camera | ORB SLAM | Faster RCNN | object category and poses | - | - |
| [26] | RGBD camera | - | Mask R-CNN | object category | - | - |
| [27] | RGBD camera | voxblox [28] | PSPNet and Mask-RCNN | object category and background | - | - |
| [29] | Sonar and stereo camera | - | R-FCN | object category | - | semantic navigation |
| [30] | RGBD camera | ORB SLAM | CRF-RNN semantic segmentation | object category | - | - |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Han, X.; Li, S.; Wang, X.; Zhou, W. Semantic Mapping for Mobile Robots in Indoor Scenes: A Survey. Information 2021, 12, 92. https://doi.org/10.3390/info12020092
Han X, Li S, Wang X, Zhou W. Semantic Mapping for Mobile Robots in Indoor Scenes: A Survey. Information. 2021; 12(2):92. https://doi.org/10.3390/info12020092
Chicago/Turabian StyleHan, Xiaoning, Shuailong Li, Xiaohui Wang, and Weijia Zhou. 2021. "Semantic Mapping for Mobile Robots in Indoor Scenes: A Survey" Information 12, no. 2: 92. https://doi.org/10.3390/info12020092