
Hybrid System Combination Framework for Uyghur–Chinese Machine Translation


Abstract
1. Introduction
2. Related Work
3. Methods
- First Layer: A set of translation hypotheses from systems that are collected for the combination in the consequent layers.
- Second Layer: The outputs from the first layer are combined with the help of the multi-source-based approach and the voting-based approach in the second layer. Here, we combine the system’s translated outputs through the multi-source-based system combination method, which described in Section 3.1. Moreover, we combine the system’s translated outputs through the voting-based system combination, which is described in Section 3.2.
- Third Layer: A hybrid system combination framework will combine the outputs of the previous two combination models to improve the translation quality. For system combination, the proposed hybrid framework chooses the words among the best sentences, which are generated by the various system combination models.
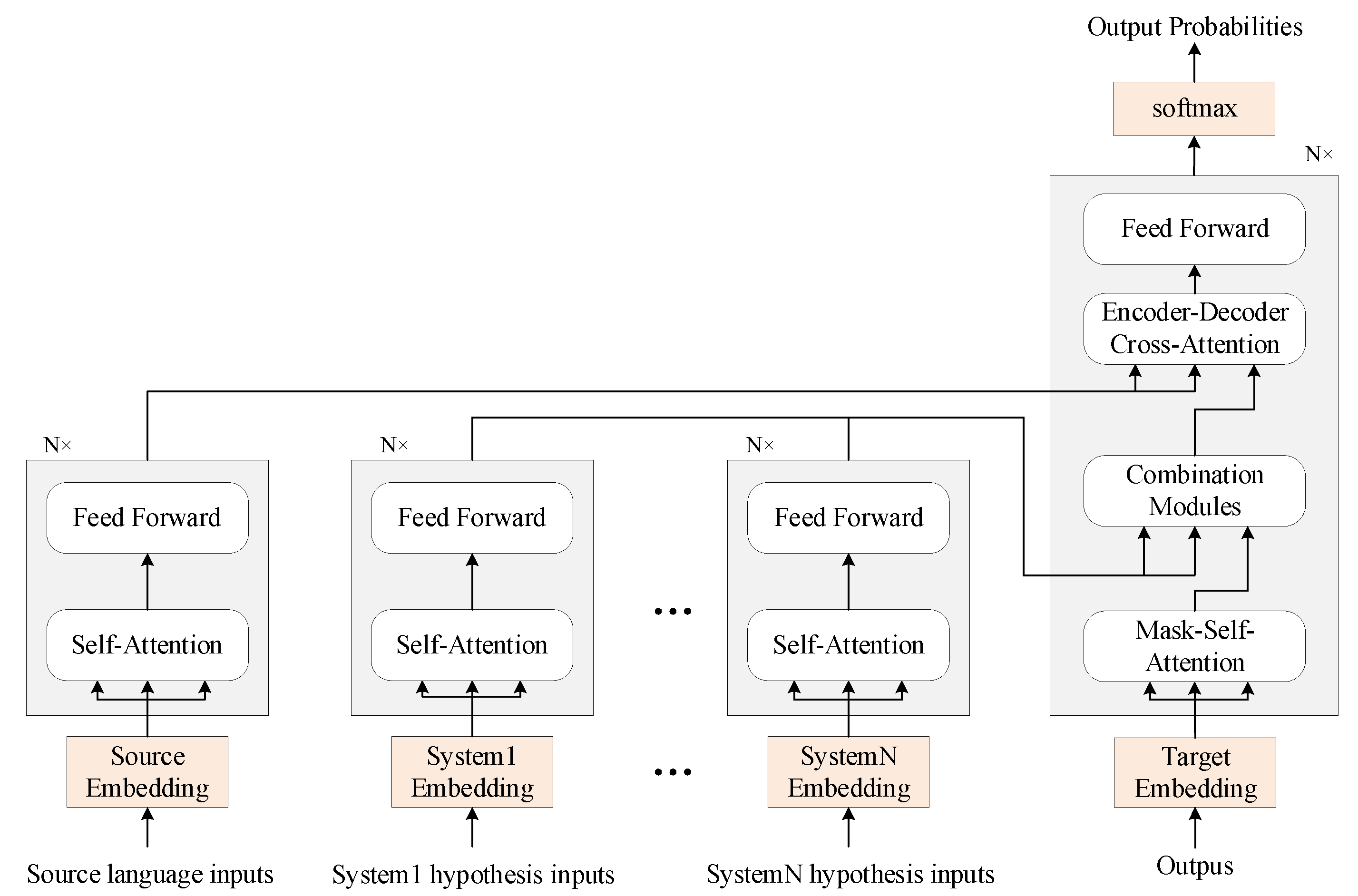
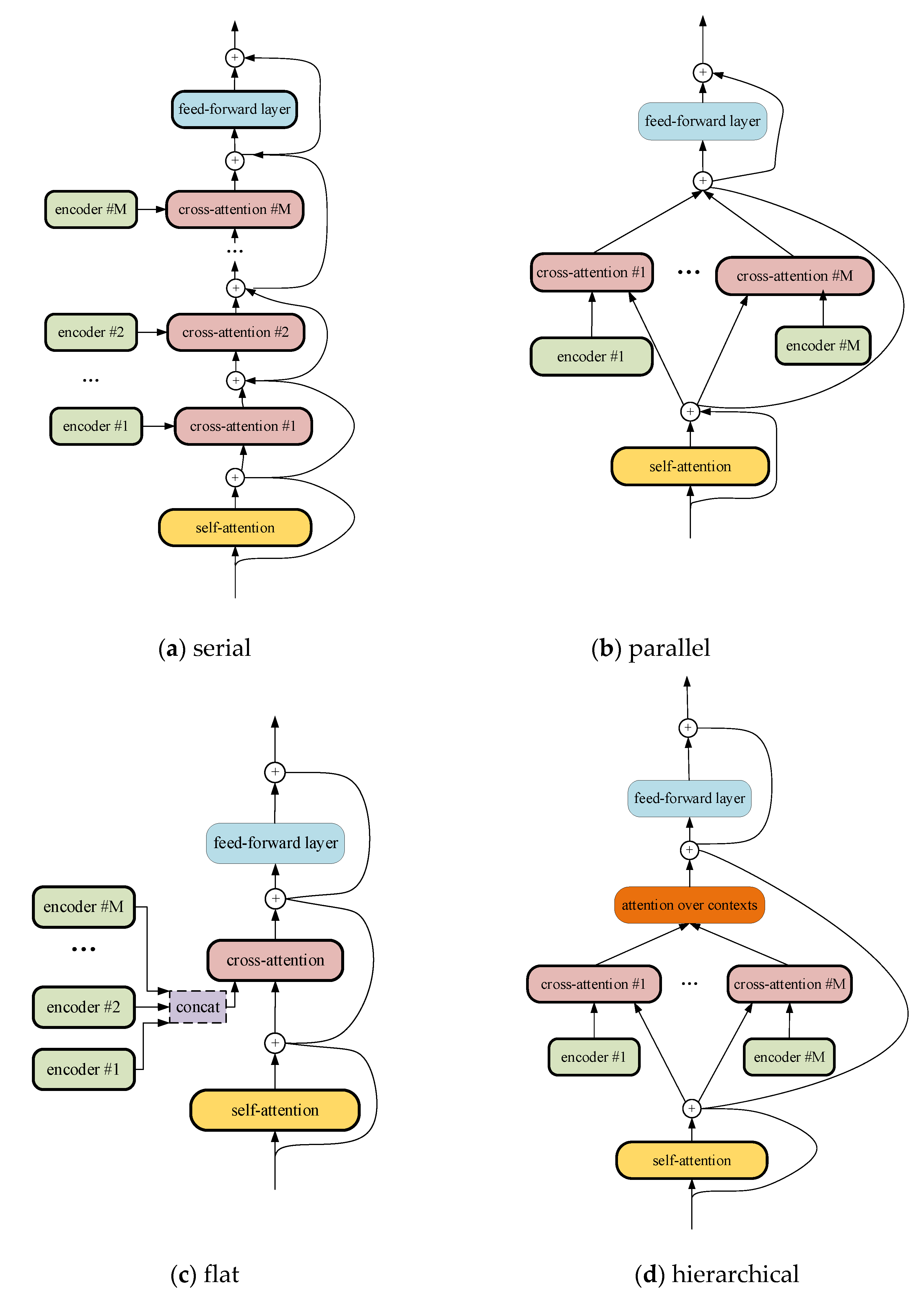
3.1. Multi-Source-Based System Combination Model
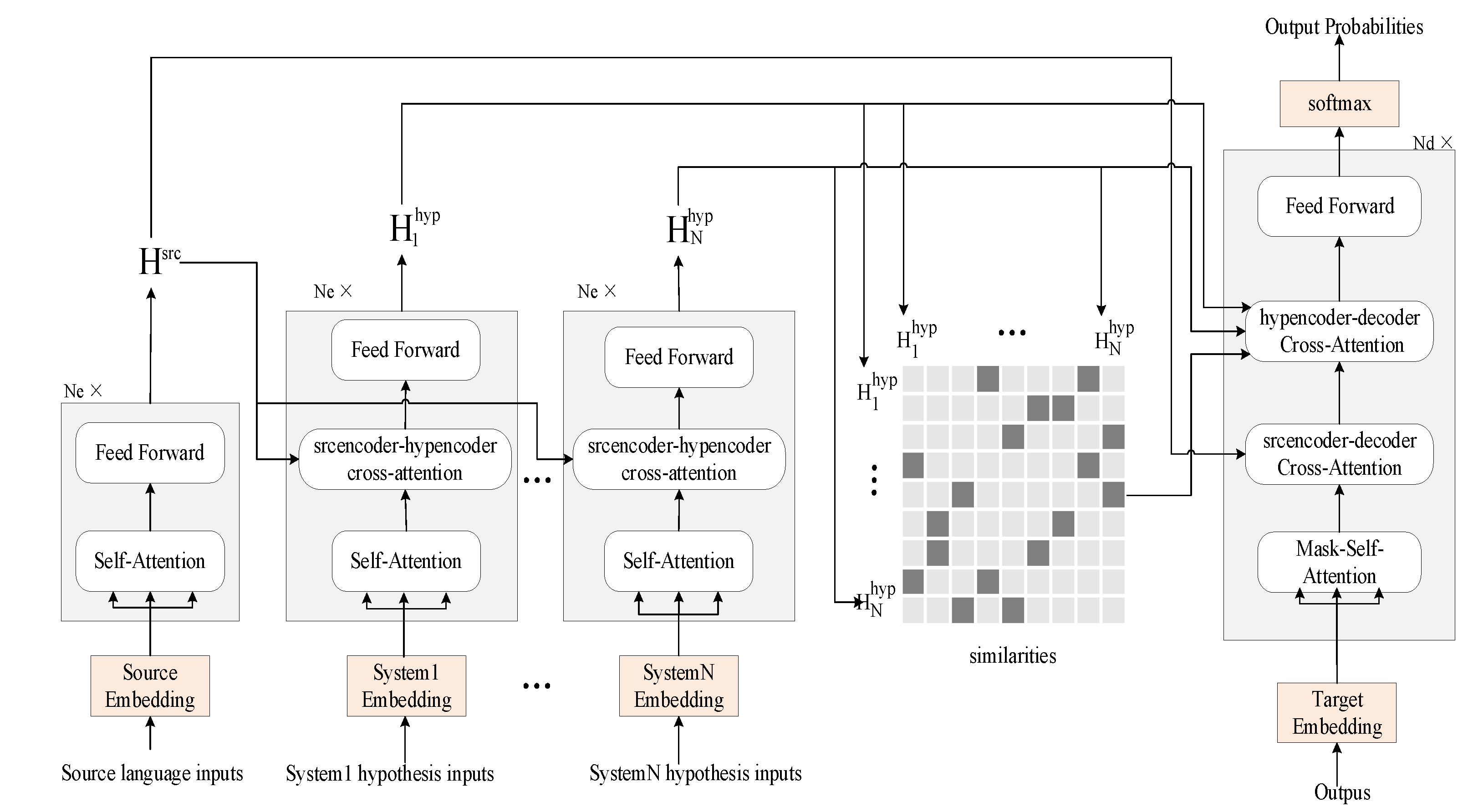
3.2. Voting-Based System Combination Model
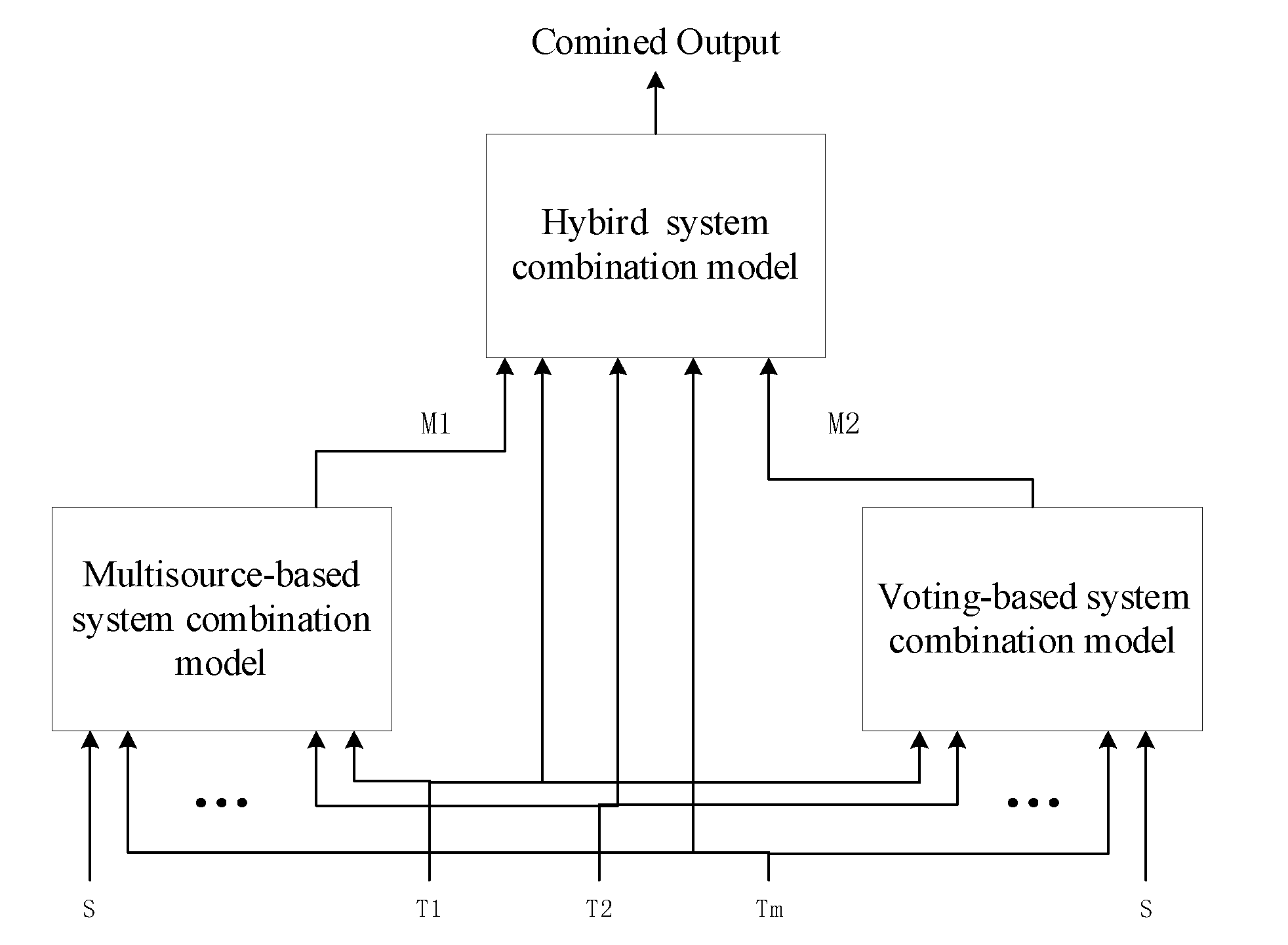
3.3. Hybrid System Combination Framework
4. Experiments
4.1. Data Preparation
- Merge the training set of the CWMT2017 and CWMT2019, and remove the duplicate sentences;
- Pre-process the raw data, such as Uyghur words tokenization, Chinese words segmentation, and remove the sentences longer than 80 words;
- Divide the pre-processed training data into two parts, then reciprocally train the MT system on one half and translate the source sentences of the other half into target translations. The translated sentences as well as the gold target reference are utilized to train the MUSC and VOSC.
- When training all neural network models including the single systems or system combination models, we used byte pair encoding (BPE) [12] with 30K merges to segment words into subword units both for the Uyghur and Chinese sentences.
4.2. Experiment Setup
- Firstly, three heterogeneous systems with different performance were selected to observe the effect of system combination;
- Secondly, three heterogeneous systems with similar performance were selected to observe the effect of system combination;
- Finally, three systems with similar performance derived from one model were selected to observe the effect of system combination.
- PBMT: It is the indispensable phrase-based SMT system still remaining used in Uyghur–Chinese machine translation. We trained the system with a 4-gram language model using modified Kneser–Ney smoothing using SRILM on the target portion of the bilingual training data [49]. The model learns the word alignments with grow-diag-final and heuristics from the parallel training corpus using GIZA++ [50];
- HPMT: It is a hierarchical phrase-based SMT system, which uses the same default setting and the language model as PBMT. The training and decoding of PBMT and HPMT are both based on the open-sourced Moses toolkit [51]. Due to HPMT using hierarchical phrases which consist of both words and sub-phrases, it has a stronger ability of reordering while preserving the strength of PBMT;
- RNN-based NMT: It is a recurrent neural network based on encoder–decoder architectures [3]. Here, we used the RNN with an attention mechanism. The weight of the sum is referred to as attention scores and allows the network to focus on different parts of the input sequences as it generates the output sequences;
- Transformer-based NMT: TNMT has obtained state-of-the-art performance on Uyghur–Chinese machine translation, which predicts target sentences from left-to-right using a self-attention mechanism [5];
- Transformer-based NMT (1–3): we trained three Transformer-based NMT with three random seeds, which are three inputs for system combination in our experiment.
4.3. Training Details
4.4. Experimental Results
4.4.1. Results of Combination Modules
4.4.2. Results on Heterogeneous Systems with Different Performance
4.4.3. Results on Heterogeneous Systems with Similar Performance
4.4.4. Results on Homogeneous Systems with Similar Performance
4.4.5. Result of Hybrid Framework
4.5. Case Study
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Koehn, P.; Och, F.J.; Marcu, D. Statistical Phrase-Based Translation. In Proceedings of the Conference Combining Human Language Technology Conference Series and the North American Chapter of the Association for Computational Linguistics Conference Series (HLT-NAACL 2003), Edmonton, AB, Canada, 27 May–1 June 2003; pp. 48–54. [Google Scholar]
- Chiang, D. A hierarchical phrase-based model for statistical machine translation. In Proceedings of the 43rd Annual Meeting on Association for Computational Linguistics—ACL ’05, Ann Arbor, MI, USA, 25–30 June 2005; pp. 263–270. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. In Proceedings of the 27th International Conference on Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 3104–3112. [Google Scholar]
- Gehring, J.; Auli, M.; Grangier, D.; Yarats, D.; Dauphin, Y.N. Convolutional sequence to sequence learning. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 1243–1252. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. arXiv 2017, arXiv:1706.03762. [Google Scholar]
- Koehn, P.; Knowles, R. Six Challenges for Neural Machine Translation. In Proceedings of the First Workshop on Neural Machine Translation, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 28–39. [Google Scholar]
- Bentivogli, L.; Bisazza, A.; Cettolo, M.; Federico, M. Neural versus Phrase-Based Machine Translation Quality: A Case Study. In Proceedings of the 2016 Conference on Empirical Methods in Natural Language Processing (EMNLP2016), Austin, TX, USA, 1–5 November 2016; pp. 257–267. [Google Scholar]
- Dunder, I.; Seljan, S.; Pavlovski, M. Automatic Machine Translation of Poetry and a Low-Resource Language Pair. In Proceedings of the 43rd International Convention on Information, Communication and Electronic Technology (MI-PRO2020), Opatija, Croatia, 28 September–2 October 2020; pp. 1034–1039. [Google Scholar]
- Martindale, M.; Carpuat, M.; Duh, K.; McNamee, P. Identifying fluently inadequate output in neural and statistical machine translation. In Proceedings of the Machine Translation Summit XVII Volume 1: Research, MTSummit 2019, Dublin, Ireland, 19–23 August 2019; pp. 233–243. [Google Scholar]
- Tu, Z.; Liu, Y.; Shang, L.; Liu, X.; Li, H. Neural machine translation with reconstruction. In Proceedings of the 31st AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; pp. 3097–3103. [Google Scholar]
- Seljan, S.; Dunder, I. Automatic Quality Evaluation of Machine-Translated Output in Sociological-Philosophical-Spiritual Domain. In Proceedings of the 10th Iberian Conference on Information Systems and Technologies (CISTI), Agueda, Aveiro, Portugal, 17–20 June 2015; pp. 128–131. [Google Scholar]
- Sennrich, R.; Haddow, B.; Birch, A. Neural Machine Translation of Rare Words with Subword Units. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 1715–1725. [Google Scholar]
- Tu, Z.; Lu, Z.; Liu, Y.; Liu, X.; Li, H. Modeling Coverage for Neural Machine Translation. In Proceedings of the 54th Annual meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; Volume 1, pp. 76–85. [Google Scholar]
- Abudukelimu, H.; Yang, L.; Maosong, S.U.N. Performance comparison of neural machinetranslation systems in Uyghur-Chinese translation. J. Tsinghua Univ. Sci. Technol. 2017, 57, 878–883. [Google Scholar]
- Zhou, L.; Hu, W.; Zhang, J.; Zong, C.; Barzilay, R.; Kan, M.-Y. Neural System Combination for Machine Translation. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 31 July–4 August 2017; pp. 378–384. [Google Scholar]
- Zhou, L.; Zhang, J.; Kang, X.; Zong, C. Deep Neural Network--based Machine Translation System Combination. ACM Trans. Asian Low-Resour. Lang. Inf. Process. 2020, 19, 1–19. [Google Scholar] [CrossRef]
- Huang, X.; Zhang, J.; Tan, Z.; Wong, D.F.; Luan, H.; Xu, J.; Sun, M.; Liu, Y. Modeling Voting for System Combination in Machine Translation. In Proceedings of the 29th International Joint Conference on Artificial Intelligence, 2020, Yokohama, Japan, 11–17 July 2020; pp. 3694–3701. [Google Scholar]
- Kong, J.; Yang, Y.; Zhou, X.; Wang, L.; Li, X. Research for Uyghur-Chinese Neural Machine Translation. In Constructive Side-Channel Analysis and Secure Design; Springer International Publishing: Berlin/Heidelberg, Germany, 2016; Volume 10102, pp. 141–152. [Google Scholar]
- Zhang, S.; Mahmut, G.; Wang, D.; Hamdulla, A. Memory-augmented Chinese-Uyghur neural machine translation. In Proceedings of the 2017 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Kuala Lumpur, Malaysia, 12–15 December 2017; pp. 1092–1096. [Google Scholar]
- Pan, Y.; Li, X.; Yang, Y.; Dong, R. Multi-Source Neural Model for Machine Translation of Agglutinative Language. Future Internet 2020, 12, 96. [Google Scholar] [CrossRef]
- Zhang, X.; Li, X.; Yang, Y.; Wang, L.; Dong, R. Analysis of Bi-directional Reranking Model for Uyghur-Chinese Neural Machine Translation. Beijing Da Xue Xue Bao 2020, 56, 31–38. [Google Scholar]
- Wang, Y.; Li, X.; Yang, Y.; Anwar, A.; Dong, R. Research of Uyghur-Chinese Machine Translation System Combination Based on Semantic Information. In Proceedings of the 8th CCF International Conference on Natural Language Processing and Chinese Computing (NLPCC2019), Dunhuang, China, 9–14 October 2019; Springer International Publishing: Berlin/Heidelberg, Germany, 2019; pp. 497–507. [Google Scholar]
- Frederking, R.; Nirenburg, S. Three heads are better than one. In Proceedings of the fourth conference on Applied natural language processing, Stuttgart, Germany, 13–15 October 1994; pp. 95–100. [Google Scholar]
- Bangalore, B.; Bordel, G.; Riccardi, G. Computing consensus translation from multiple machine translation systems. In Proceedings of the IEEE Workshop on Automatic Speech Recognition and Understanding, Madonna di Campiglio, Italy, 9–13 December 2001; pp. 351–354. [Google Scholar]
- Rosti, A.-V.; Matsoukas, S.; Schwartz, R. Improved word-level system combination for machine translation. In Proceedings of the 45th Annual Meeting of the Association of Computational Linguistics, Prague, Czech Republic, 24–29 June 2007; pp. 312–319. [Google Scholar]
- Ma, W.-Y.; McKeown, K. Phrase-level system combination for machine translation based on target-to-target decoding. In Proceedings of the 10th Biennial Conference of the Association for Machine Translation in the Ameri-cas (AMTA), San Diego, CA, USA, 28 October–1 November 2012. [Google Scholar]
- Zhu, J.; Yang, M.; Li, S.; Zhao, T.; Che, W.; Han, Q.; Wang, H.; Jing, W.; Peng, S.; Lin, J.; et al. Sentence-Level Paraphrasing for Machine Translation System Combination. In Proceedings of the Yong Computer Scientists and Educators (ICYCSEE2016), Harbin, China, 20–22 August 2016; pp. 612–620. [Google Scholar]
- Ma, W.-Y.; McKeown, K. System Combination for Machine Translation through Paraphrasing. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing (EMNLP2015), Lisbon, Portugal, 17–21 September 2015; pp. 1053–1058. [Google Scholar]
- Freitag, M.; Huck, M.; Ney, H. Jane: Open Source Machine Translation System Combination. In Proceedings of the Demonstrations at the 14th Conference of the European Chapter of the Association for Computational Linguistics (EACL2014), Gothenburg, Sweden, 26–30 April 2014; pp. 29–32. [Google Scholar]
- Barrault, L. Many: Open Source Machine Translation System Combination. Prague Bull. Math. Linguist. 2010, 93, 147–155. [Google Scholar] [CrossRef]
- Heafield, K.; Lavie, A. Combining Machine Translation Output with Open Source: The Carnegie Mellon Multi-Engine Machine Translation Scheme. Prague Bull. Math. Linguist. 2010, 93, 27–36. [Google Scholar] [CrossRef][Green Version]
- Matusov, E.; Ueffing, N.; Ney, H. Computing consensus translation for multiple machine translation systems using enhanced hypothesis alignment. In Proceedings of the 11th Conference of the European Chapter of the Association for Computational Linguistics (EACL2006), Trento, Italy, 3–7 April 2006; pp. 33–40. [Google Scholar]
- Rosti, A.-V.; Ayan, N.F.; Xiang, B.; Matsoukas, S.; Schwartz, R.; Dorr, B. Combining outputs from multiple machine translation systems. In Proceedings of the Human Language Technologies 2007: The Conference of the North American Chapter of the Association for Computational Linguistics; Proceedings of the Main Conference, Rochester, NY, USA, 22–27 April 2007; pp. 228–235. [Google Scholar]
- Feng, Y.; Liu, Y.; Mi, H.; Liu, Q.; Lu, Y. Lattice-based system combination for statistical machine translation. In Proceedings of the 2009 Conference on Empirical Methods in Natural Language Processing Volume 3—EMNLP ’09, Singapore, 6–7 August 2009; pp. 1105–1113. [Google Scholar]
- Rosti, A.-V.I.; Zhang, B.; Matsoukas, S.; Schwartz, R. Incremental hypothesis alignment for building confusion networks with application to machine translation system combination. In Proceedings of the Third Workshop on Statistical Machine Translation, Columbus, OH, USA, 15–20 June 2008; pp. 183–186. [Google Scholar]
- Freitag, M.; Peter, J.-T.; Peitz, S.; Feng, M.; Ney, H. Local System Voting Feature for Machine Translation System Combination. In Proceedings of the EMNLP2015 Tenth Workshop on Statistical Machine Translation (WMT2015), Lisbon, Portugal, 17–21 September 2015; pp. 467–476. [Google Scholar]
- Freitag, M.; Ney, H.; Yvon, F. Investigations on Machine Translation System Combination. Ph.D. Thesis, Rheinisch-Westfälische Technische Hochschule Aachen University, Aachen, Germany, 2017. [Google Scholar]
- Zoph, B.; Knight, K. Multi-Source Neural Translation. In Proceedings of the Annual Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies (NAACL-HLT’16), San Diego, CA, USA, 12–17 June 2016; pp. 30–34. [Google Scholar]
- He, X.; Yang, M.; Gao, J.; Nguyen, P.; Moore, R. Indirect-HMM-based hypothesis alignment for combining outputs from machine translation systems. In Proceedings of the Conference on Empirical Methods in Natural Language Processing (EMNLP2008), Honolulu, HI, USA, 25–27 October 2008; pp. 98–107. [Google Scholar]
- Banik, D.; Ekbal, A.; Bhattacharyya, P.; Bhattacharyya, S.; Platos, J. Statistical-based system combination approach to gain advantages over different machine translation systems. Heliyon 2019, 5, e02504. [Google Scholar] [CrossRef]
- Banik, D.; Ekbal, A.; Bhattacharyya, P.; Bhattacharyya, S. Assembling translations from multi-engine machine translation outputs. Appl. Soft Comput. 2019, 78, 230–239. [Google Scholar] [CrossRef]
- Marie, B.; Fujita, A. A smorgasbord of features to combine phrase-based and neural machine translation. In Proceedings of the 13th Conference of the Association for Machine Translation in the Americas (AMTA2018), Boston, MA, USA, 17–21 March 2018; pp. 111–124. [Google Scholar]
- Rikters, M. Hybrid Machine Translation by Combining Output from Multiple Machine Translation Systems. Balt. J. Mod. Comput. 2019, 7, 301–341. [Google Scholar] [CrossRef]
- Chen, B.; Zhang, M.; Li, H.; Aw, A. A comparative study of hypothesis alignment and its improvement for machine translation system combination. In Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP, Singapore, 2–7 August 2009; pp. 941–948. [Google Scholar]
- Libovický, J.; Helcl, J. Attention Strategies for Multi-Source Sequence-to-Sequence Learning. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (ACL2017), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 196–202. [Google Scholar]
- Libovický, J.; Helcl, J.; Mareček, D. Input Combination Strategies for Multi-Source Transformer Decoder. In Proceedings of the Third Conference on Machine Translation: Research Papers, Brussels, Belgium, 31 October–1 November 2018; pp. 253–260. [Google Scholar]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W.-J. Bleu: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics (ACL2002), Philadelphia, PA, USA, 7–12 July 2002; pp. 311–318. [Google Scholar]
- Koehn, P. Statistical Significance Tests for Machine Translation Evaluation. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing (EMNLP2004), Barcelona, Spain, 25–26 July 2004; pp. 388–395. [Google Scholar]
- Stolcke, A. SRILM-an extensible language modeling toolkit. In Proceedings of the 7th international conference on spoken language processing, Denver, CO, USA, 16–20 September 2002; pp. 901–904. [Google Scholar]
- Och, F.J. Giza++: Training of Statistical Translation Models. Available online: http://www.statmt.org/moses/giza/GIZA++.html (accessed on 30 January 2001).
- Koehn, P.; Hoang, H.; Birch, A.; Callison-Burch, C.; Federico, M.; Bertoldi, N.; Cowan, B.; Shen, W.; Moran, C.; Zens, R. Moses: Open source toolkit for statistical machine translation. In Proceedings of the 45th Annual Meeting of the Association for Computational Linguistics Companion Volume Proceedings of the Demo and Poster Sessions, Prague, Czech Republic, 25–27 June 2007; pp. 177–180. [Google Scholar]
- Ott, M.; Edunov, S.; Baevski, A.; Fan, A.; Gross, S.; Ng, N.; Grangier, D.; Auli, M. fairseq: A Fast, Extensible Toolkit for Sequence Modeling. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics (Demonstrations), Minneapolis, MN, USA, 2–7 June 2019; pp. 48–53. [Google Scholar]
- Helcl, J.; Libovický, J. Neural Monkey: An Open-source Tool for Sequence Learning. Prague Bull. Math. Linguist. 2017, 107, 5–17. [Google Scholar] [CrossRef]
- Zhang, J.; Ding, Y.; Shen, S.; Cheng, Y.; Sun, M.; Luan, H.; Liu, Y. Thumt: An open source toolkit for neural machine translation. arXiv 2017, arXiv:1706.06415. [Google Scholar]
- Tan, Z.; Zhang, J.; Huang, X.; Chen, G.; Wang, S.; Sun, M.; Luan, H.; Liu, Y. THUMT: An Open-Source Toolkit for Neural Machine Translation. In Proceedings of the 14th Conference of the Association for Machine Translation in the Americas (AMTA 2020), Orlando, FL, USA, 8–12 September 2020; pp. 116–122. [Google Scholar]
- Isozaki, H.; Hirao, T.; Duh, K.; Sudoh, K.; Tsukada, H. Automatic evaluation of translation quality for distant language pairs. In Proceedings of the 2010 Conference on Empirical Methods in Natural Language Processing (EMNLP2010), Cambridge, MA, USA, 9–11 October 2010; pp. 944–952. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| src | قاتناش ساقچىلىرى شوپۇرلارغا تەييار چۆپ ، مانتا ، تۇخۇم شورپىسى قاتارلىق يىمەكلەرنى ئەكىلىپ بەردى . |
| Tsrc | The traffic police brought the driver instant noodles, steamed buns, egg soup and other food. |
| hyp1 | 交警 方便面, 司机、 鸡蛋 汤 يىمەكلەرنى 等 物资. |
| Thyp1 | Traffic police instant noodles يىمەكلەرنى and other supplies. |
| hyp2 | 交警 方便面, 、 鸡蛋 汤 等 يىمەكلەرنى 送来 了. |
| Thyp2 | Traffic police, instant noodles, egg soup and so on يىمەكلەرنى brought. |
| hyp3 | 交警 给 司机 送 了 方便货, 洗菜、 鸡蛋、 鸡蛋 等 食品. |
| Thyp3 | Traffic police to the driver to send convenient goods, wash vegetables, eggs, eggs and other food. |
| tgt | 交警 为 司机 送来 了 方便面、 包子、 鸡蛋 汤 等 食物. |
| System Type | Set | #Sentences | #Tokens | |
|---|---|---|---|---|
| Uyghur | Chinese | |||
| Single MT Systems | Train | 239,711 | 4,497,220 | 4,174,631 |
| Dev | 1000 | 25,217 | 25,262 | |
| MUSC | Train | 239,763 | 4,498,108 | 4,171,378 |
| Dev | 1000 | 25,217 | 25,262 | |
| VOSC | Train | 239,763 | 4,498,108 | 4,171,378 |
| Dev | 1000 | 25,217 | 25,262 | |
| Test Set | 1000 | 23,202 | 21,559 |
| # | System Type | DEV | TEST |
|---|---|---|---|
| 1 | PBMT | 27.45 | 34.78 |
| 2 | HPMT | 27.77 | 34.89 |
| 3 | RNMT | 28.44 | 35.24 |
| 4 | TNMT | 39.03 | 46.71 |
| 5 | TNMT-1 | 39.00 | 46.47 |
| 6 | TNMT-2 | 39.27 | 46.43 |
| 7 | TNMT-3 | 39.28 | 46.61 |
| # | Strategies | DEV |
|---|---|---|
| 1 | PBMT | 27.45 |
| 2 | HPMT | 27.77 |
| 3 | RNMT | 28.44 |
| 4 | MUSC(Serial) | 28.66 |
| 5 | MUSC(Parallel) | 28.51 |
| 6 | MUSC(Flat) | 27.35 |
| 7 | MUSC(Hierarchical) | 28.78 |
| System | DEV | TEST | Increase Rate |
|---|---|---|---|
| PBMT | 27.45 | 34.78 | X |
| HPMT | 27.77 | 34.89 | X |
| TNMT | 39.03 | 46.71 | X |
| MUSC-1 | 39.00 | 46.47 | −9.29% |
| VOSC-1 | 39.27 | 46.43 | −1.46% |
| System | DEV | TEST | Increase Rate |
|---|---|---|---|
| PBMT | 27.45 | 34.78 | X |
| HPMT | 27.77 | 34.89 | X |
| RNMT | 28.44 | 35.24 | X |
| MUSC-2 | 29.06 | 36.47 | +3.49% |
| VOSC-2 | 31.73 | 39.65 | +12.51% |
| System | DEV | TEST | Increase Rate |
|---|---|---|---|
| TNMT-1 | 39.00 | 46.47 | X |
| TNMT-2 | 39.27 | 46.43 | X |
| TNMT-3 | 39.28 | 46.61 | X |
| MUSC-3 | 36.36 | 43.52 | −6.63% |
| VOSC-3 | 39.63 | 47.19 | +1.24% |
| Systems | VOSC-2 | VOSC-3 |
|---|---|---|
| PBMT + HPMT + RNMT | 39.65 | 31.66 |
| TNMT-1 + TNMT-2 + TNMT-3 | 47.29 | 47.19 |
| Systems | MUSC | VOSC | HBSC |
|---|---|---|---|
| PBMT + HPMT + TNMT | 42.37 | 46.03 | 46.38 |
| PBMT + HPMT + RNMT | 36.47 | 39.65 | 40.13 |
| TNMT-1 + TNMT-2 + TNMT-3 | 43.52 | 47.19 | 47.25 |
| PBMT + HPMT + RNMT + TNMT | 36.79 | 44.56 | 44.86 |
| PBMT + HPMT + RNMT + TNMT + TNMT-1 | 40.14 | 46.75 | 47.18 |
| PBMT + HPMT + RNMT + TNMT + TNMT-1 + TNMT-2 | 44.54 | 47.33 | 47.48 |
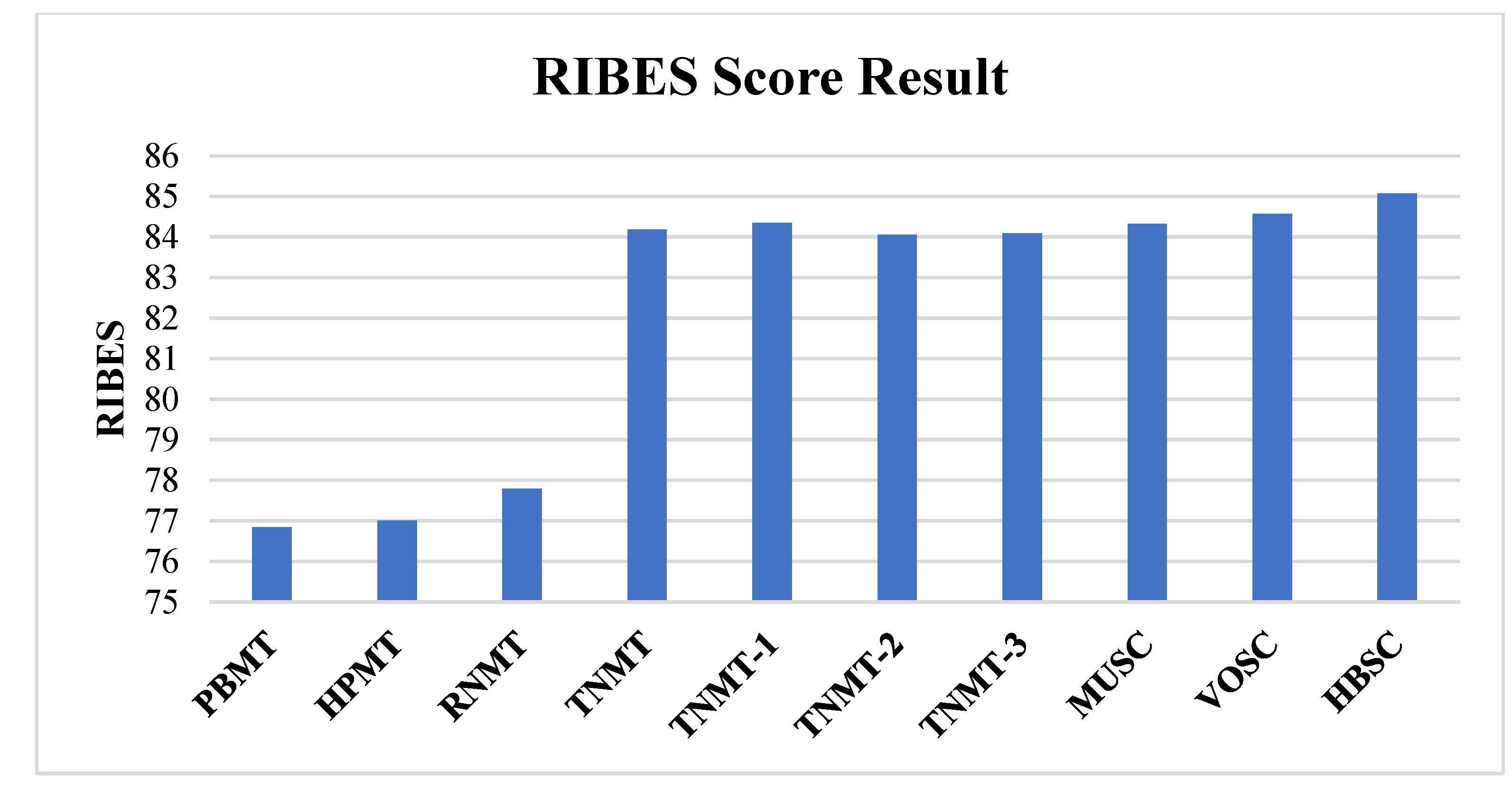
| PBMT + HPMT + RNMT + TNMT + TNMT-1 + TNMT-2 + TNMT-3 | 44.84 | 47.76 | 48.42 |
| src | بۇ يىللىق ئىشقا ئورۇنلاشتۇرۇش سىياسىتىدىكى يەنە بىر ئالاھىدىلىك سىياسەت بىلەن ئىش ئورنىنى ماسلاشتۇرۇش بولۇپ ، ئىش ئورنى كۆلىمى ئۆتكەن يىللاردىكىدىن زور دەرىجىدە ئاشقان. |
| Ref | 今年 就业 政策 的 另 一个 特点 是 政策 与 岗位 配套 出台 , 就业 岗位 的 规模 数量 大大 超过 了 往年. |
| Tsrc | Another characteristic of this year’s employment policy is that the policy and job matching are issued, and the number of jobs has greatly exceeded that of previous years. |
| PBMT | 今年 的 就业 政策 的 还有 一个 特点 和 就业 岗位 政策 协调 , 在 岗位 面积 比 往年 大幅 增长. |
| TPBMT | This year’s employment policy still has a characteristic and employment post policy is coordinated, in post area is larger than in previous years. |
| HPMT | 今年 的 就业 政策 还有 一个 特点 和 政策 协调 岗位 , 是 去年 的 岗位 面积 比 往年 大幅 增长. |
| THPMT | This year’s employment policy still has a characteristic and policy coordination post, it is last year’s post area to increase substantially than in previous years. |
| RNMT | 今年 就业 政策 的 还有 一个 特点 , 在 岗位 上 协调 协调 , 岗位 规模 也 大大提高. |
| TRNMT | The employment policy still has a characteristic this year, coordinate coordinate on post, post scale is also raised greatly. |
| TNMT | 今年 就业 政策 的 另 一个 特点 是 协调 政策 和 岗位 , 岗位 规模 比 去年 大. |
| TTNMT | Another feature of this year’s employment policy is the coordination of policies and jobs, which are larger than last year’s. |
| TNMT-1 | 今年 就业 政策 的 另 一个 特点 是 政策 和 岗位 的 协调 , 岗位 面积 比 往年 大幅 增长. |
| TTNMT-1 | Another feature of this year’s employment policy is the coordination of policies and posts, and the number of posts has increased significantly compared with previous years. |
| TNMT-2 | 今年 就业 政策 的 另 一个 特点 就是 政策 和 岗位 协调 , 岗位 面积 比 往年 大幅 增加. |
| TTNMT-2 | Another feature of this year’s employment policy is the coordination between policies and posts, and the number of posts has increased significantly compared with previous years. |
| TNMT-3 | 今年 就业 政策 的 另 一个 特点 是 政策 与 岗位 对接 , 岗位 面积 比 往年 大幅 提升. |
| TTNMT-3 | Another feature of this year’s employment policy is the matching of policies with posts. The number of posts has increased significantly compared with previous years. |
| MUSC | 今年 就业 政策 的 另 一个 特点 就是 政策 和 岗位 上 的 协调 , 岗位 规模 比 往年 大幅 提升. |
| TMUSC | Another feature of this year’s employment policy is the coordination between policies and jobs, with the number of jobs increased significantly compared with previous years. |
| VOSC | 今年 就业 政策 的 另 一个 特点 就是 政策 协调 , 岗位 面积 比 往年 大幅 增加. |
| TVOSC | Another feature of this year’s employment policy is policy coordination. The number of jobs has increased significantly compared with previous years. |
| HBSC | 今年 就业 政策 的 另 一个 特点 就是 政策 和 岗位 协调, 岗位 规模 比 往年 大幅 增加. |
| THBSC | Another feature of this year’s employment policy is the coordination between policies and posts, and the number of posts has increased significantly compared with previous years. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, Y.; Li, X.; Yang, Y.; Anwar, A.; Dong, R. Hybrid System Combination Framework for Uyghur–Chinese Machine Translation. Information 2021, 12, 98. https://doi.org/10.3390/info12030098
Wang Y, Li X, Yang Y, Anwar A, Dong R. Hybrid System Combination Framework for Uyghur–Chinese Machine Translation. Information. 2021; 12(3):98. https://doi.org/10.3390/info12030098
Chicago/Turabian StyleWang, Yajuan, Xiao Li, Yating Yang, Azmat Anwar, and Rui Dong. 2021. "Hybrid System Combination Framework for Uyghur–Chinese Machine Translation" Information 12, no. 3: 98. https://doi.org/10.3390/info12030098
APA StyleWang, Y., Li, X., Yang, Y., Anwar, A., & Dong, R. (2021). Hybrid System Combination Framework for Uyghur–Chinese Machine Translation. Information, 12(3), 98. https://doi.org/10.3390/info12030098