
Colvis—A Structured Annotation Acquisition System for Data Visualization


Abstract
1. Introduction
1.1. Wording
1.2. Motivations
- The first aim is the retrieval of annotations relevant for the analysts. We describe existing methods of retrieval in Section 2. We believe that there is a need for analysts to retrieve annotations based on the type of pattern identified by the annotators. A generic task that illustrates our point could be: “Find all annotations speaking of the entities that stand out from the trend within the dataset.” We also believe that an annotation should be attached to its related data, rather than to a view. An analyst would thus be able to retrieve annotations not just on their original view, but also under various conditions described in Section 5.2.
- We assume that an efficient annotation system provides incentives for analysts to look at the data from various points of view, rather than sticking to similar cognitive patterns. To the best of our knowledge, this aim is simply not addressed by existing systems, at least not openly. There is a seemingly prohibitive stumbling block to this end: increasing the variety of annotations requires an objective way to assess them. If one manages to address this issue, the system should still provide incentives for analysts to go beyond their “comfort zone”.
- The evaluation of data visualization has always been a problem difficult to tackle [1]. We believe that annotations offer an additional measurement of the quality of visualizations: if a visualization musters a significant amount of annotations, analyzing them objectively will allow us to understand what kind of insights it can provide. If we apply this method to a wide range of visualizations, we could even establish a ground truth to help designers select sets of complementary data visualizations.
1.3. Contributions
- A proposal for a full-featured annotation system;
- A design rationale, grounded in our observations, for the annotation interface;
- Technical details of the implementation of the interface with web technologies, including how to recover data from visualizations built through common data visualization libraries;
- A description of two use cases where the interface is being used, demonstrating how it can address the issues raised in Section 1.2.
2. Previous Work
2.1. The Structure of an Annotation
2.2. Annotation Systems
2.3. The Classification Framework
- The “insight on data” dimension determines if the annotation speaks of the data, or if it assesses the visualization altogether. A sizable amount of annotations left during the study were commenting the visualizations—whether the participants liked it, whether they could discover information faster, etc.—rather than fostering knowledge about the data displayed. This current study led us to add an additional level to this dimension, inspired by Curcio’s “read beyond the data” [11]: some annotations definitely refer to the data, but only rely on external sources of knowledge rather than addressing what is displayed on the visualization. Such annotations are usually “explanatory replies” to hypotheses formulated by other annotators.
- The “co-reference” dimension determines whether the annotation is referring to a previous one left by the same analyst, as the setting of the study did not allow participants to see each other’s annotations. This option being available to annotators in this study, we simply renamed this dimension “reference”.
- The “multiple observations” dimension states whether there exists several observations within an annotation. The previous study suggested that while the first three dimensions apply to the annotation itself, the next three dimensions speak of the content of the annotation—the observations. Each observation would thus have distinct levels of interpretation, detected patterns, and data units, as seen in Figure 1.
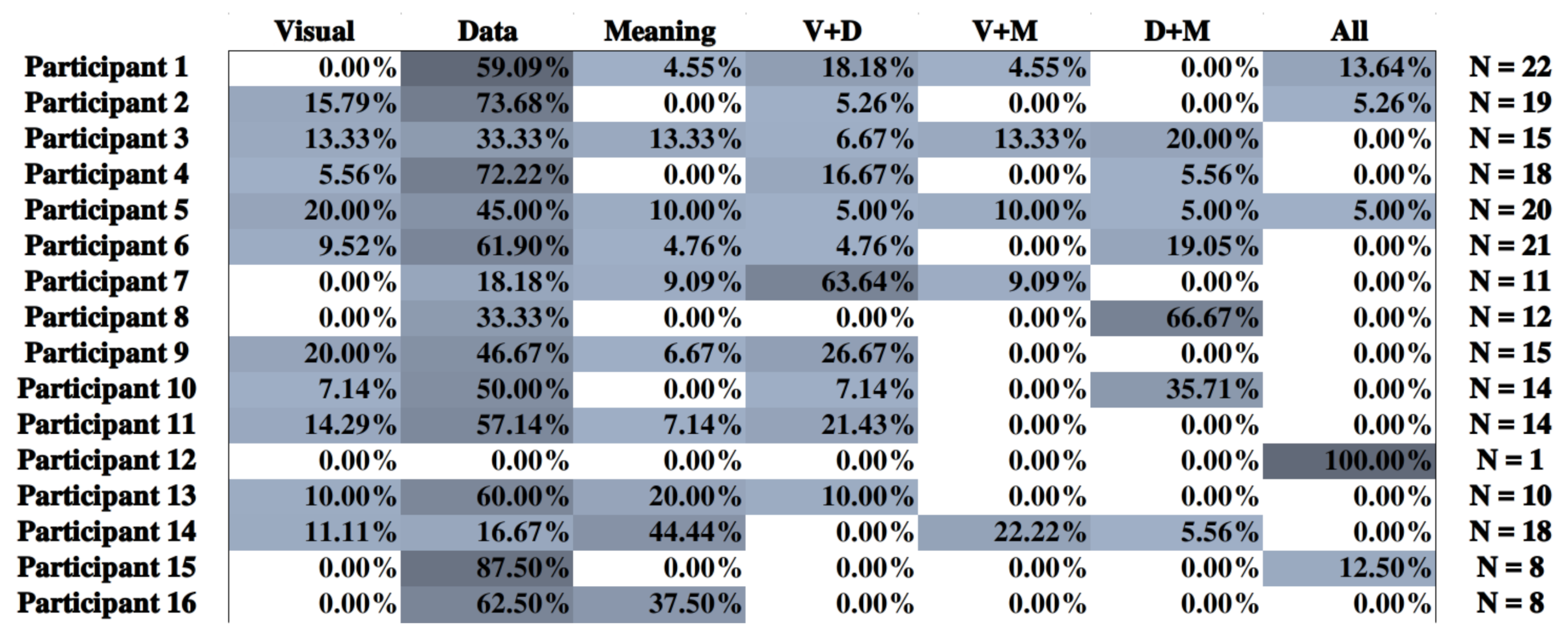
- The “level of interpretation” describes how far the analyst went to understand the data. There are three possible levels of interpretation: “visual”, where the analysis focuses on visual objects (“there are more red dots at the left of the graph”), “data”, where the analysis relies on their understanding of the data (“most institutional websites are discovered by direct links”), and “meaning”, where the analysis goes beyond factual data to form a hypothesis or a statement (“it seems that most users were receptive to our last e-mail campaign”). It is possible for an observation to rely on several levels (“the red dots massed at the left of the graph imply that most institutional websites are discovered by direct links, meaning that users were receptive to our last e-mail campaign”). This dimension did not undergo any change during this study.
- The “data units” are all segments of data that the observation involves. We distinguish units by their scope—either single in the case of individual datum or aggregated if several are involved—and their role—either subject if this unit is what the observation chiefly speaks about or complement if the observation uses the unit to compare the subject. Further considerations are mentioned in the discussion of this article regarding changes to this dimension.
- The “detected patterns” dimension consists of three possible types of patterns observed by the analyst: either a small subset of the data compared to the rest, in which case he points out a “singularity”; or two subsets of relatively similar scope, in which case he denotes a “duality”; or the whole dataset, and he makes a “plurality”. With this study, we renamed the last pattern “generality”, as it conveys more accurately the meaning of this pattern.
3. Design of the Interface
3.1. Design Rationale
- It should implement the classification framework that we presented in Section 3.4;
- It should be usable by analysts who do not know that framework;
- It should encourage analysts to explore the full extent of the classification framework;
- It should adapt to existing systems rather than require specific development.
3.2. Technical Considerations
3.3. JSON Specification
3.4. Annotation Interface
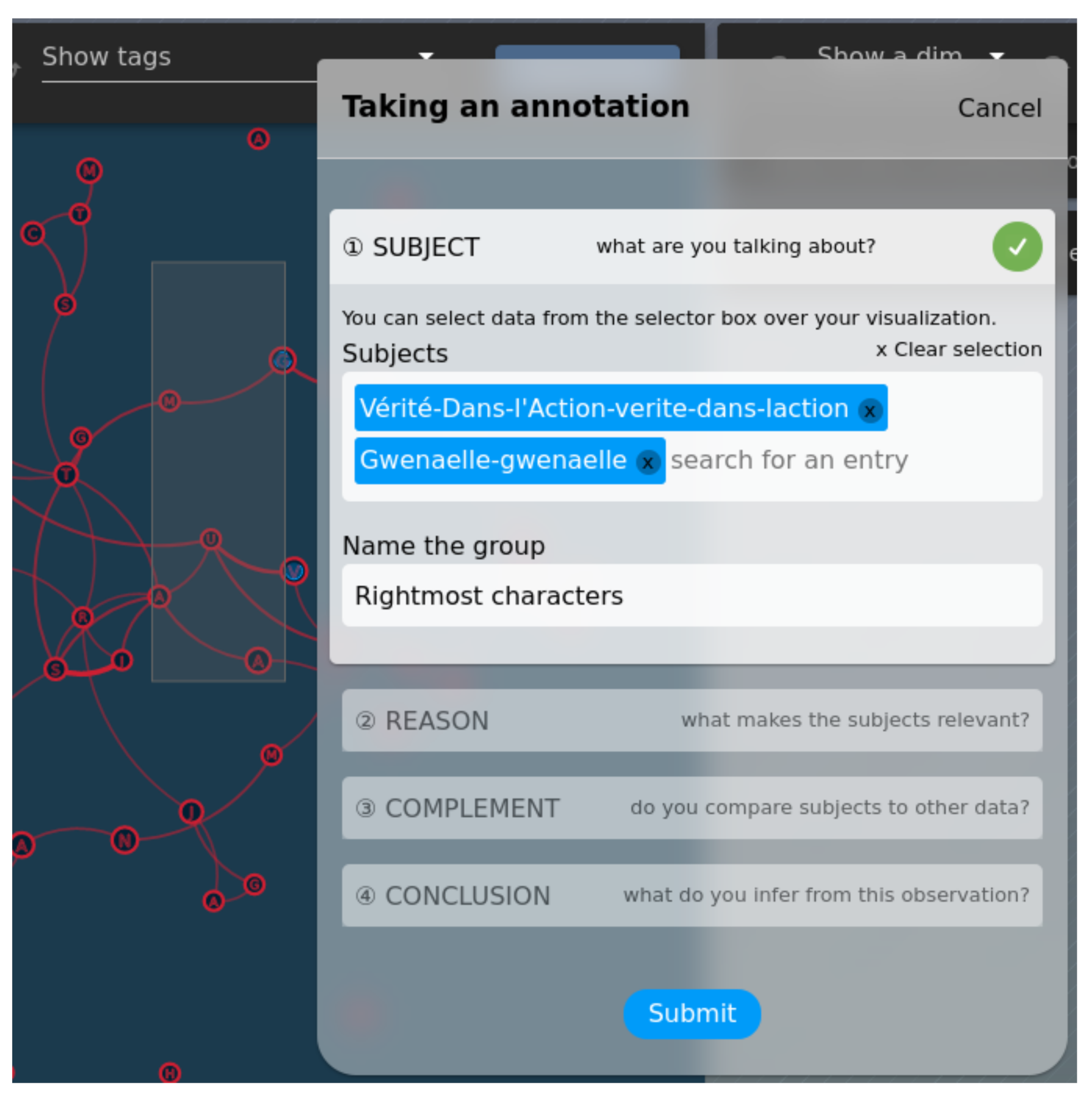
- Subject allows analysts to select data binders they want to speak about. The interface proposes several methods: the analysts can use a rectangular selection directly on the visualization in order to select “visual” entities, use an autocomplete field to browse through the list of all data binders, or refer to a previous group from a prior annotation. If more than a single element is selected, the analysts are prompted to provide a “name” for the selected group of elements, allowing further annotations to refer to it. Furthermore, if the analyst selects a data binder that belongs to a combination with groupedSelection, all related products are also selected on the visualization. Figure 5 illustrates both the rectangular selection and the ability to name the set of selected data.
- Reason allows analysts to explain what makes the subject interesting, using a set of pre-selected verbs. The analysts can choose between “stand out” or “is similar”. The latter requires a complement (see third step). Once they have chosen a verb, the analysts can leave a comment to further precise why the subject either stands out, or is similar to a complement. The list of products is displayed, at this step, to help formulate a comment.
- Complement allows analysts to select potential complements, “opposed” or “compared” to the subject. The selection method is similar to that of the first step. All “named groups” can be retrieved in both the first and third step, regardless of their origin. This design choice allows analysts to refer to these groups sometimes as subjects, and sometimes as complements alike.
- Meaning offers analysts to freely write a conclusion to their selection, along with free tags to help sort annotations.
- All annotations relate to the data, general comments are not possible within the interface. The value of the dimension “insight on data” is always “true”.
- Answering another annotation is allowed within Colvis. If an annotation is written as a reply, then its “co-reference” value is set to “true”, and to “false” otherwise.
- Multiple observations are not possible per se. The system requires analysts to split them into separate annotations. The value of the dimension “multiple observations” is therefore “false”.
4. Use Cases
4.1. Vasco
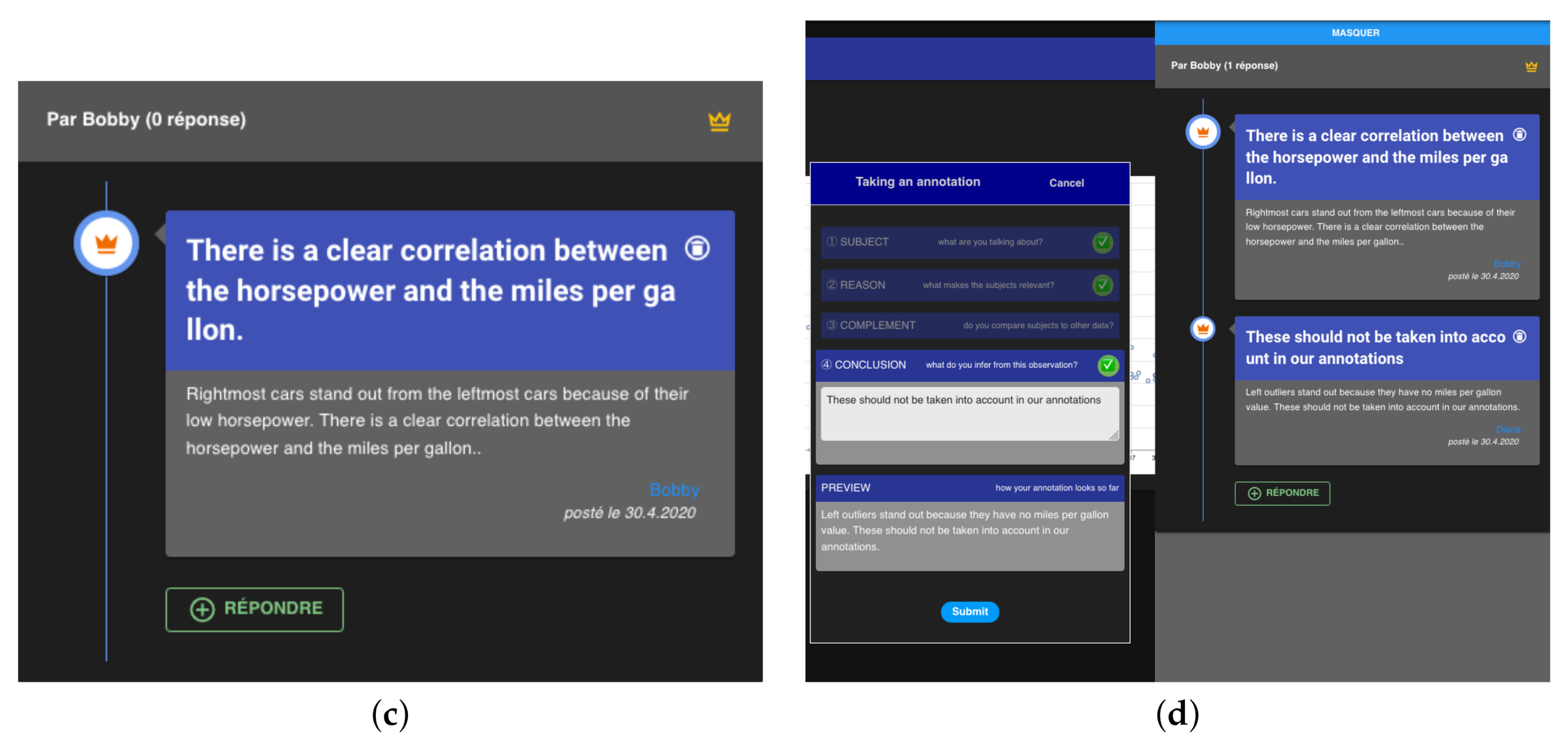
- “Rightmost cars stand out from the leftmost cars because of their low horsepower. There is a clear correlation between the horsepower and the miles per galleon”. “Rightmost cars” is an aggregated subject data units of “car” nature. The verb “stand out” and the presence of a complement data unit indicates a “duality” pattern’. “Leftmost cars” is an aggregated complement data units of “car” nature. The selection—made through the autofill field—indicates a “visual” level of interpretation. Finally, the presence of a conclusion points to an additional “meaning” level of interpretation.
- “Left outliers stand out because they have no miles per galleon value. These should not be taken into account in our annotations.” “Left outliers” is the sole data unit, with a subject role, an aggregated scope and from the “car” nature. The verb “stand out” without a complement data unit indicates a “singularity”. There too, the units were selected through the autofill fields, implying a “visual” level of interpretation. The presence of a conclusion also points to a “meaning” level of interpretation.
4.2. premDAT: An Online Community for Tabletop Roleplaying Games
- The combination between characters and dimensions produces a score varying from 1 (weak) to 5 (strong). It is encoded as a sequential color scale for both nodes and edges, and only one can be displayed at a time depending on the state of the visualization. A secondary combination between characters and dimensions can be displayed by filling the nodes, allowing a comparison between both selected dimensions.
- The combination between characters and tags is a boolean stating whether the character possesses that tag. It is encoded as little dot next to a node, that can be shown or hidden.
- The combination between two characters is a similarity score ranging from 1 to 100. It is encoded as edges (links) between both nodes.
5. Discussion and Further Work
5.1. Limitations
- Usability issues. Initial pilot tests with six users already found a few usability issues that relate to the name and the mandatory/optional nature of each step. These issues are not fundamental and we expect to fix them in further work.
- Representing annotations for further retrieval through textual means is not optimal: the resulting text is bland and repetitive, and the interface might benefit from isotypes to display the dimensions of the annotation in a more attractive fashion. Figure 9 shows sketches of isotypes that could replace, or at least enhance textual representations of annotations.
- Another situation where the interface currently fails is the presence of several views on the same page. Creating a specification for each view would prove inconvenient. Further works could lead to a more efficient way to this end, by avoiding the repetition of the most redundant aspects of the specification.
- Using the two text areas at their disposal, annotators might be tempted to formulate their annotation by relying on graphical artifacts, such as positions and colors of data points, etc. These references lose their sense if the view changes too much, thus making parts of the annotation void of sense.
- As it stands now, Colvis allows the selection of DOM elements, yet some visualizations rely on a single DOM element whose shape describes several “data points,” such as typical line charts. The ability to select only a subset of a DOM element has yet to be implemented, but we believe this could be easily achieved by leveraging scales from the D3 library and some SVG properties, such as the getTotalLength and getPointAtLength methods.
- Finally, due to the amount of data transferred between Colvis and its parent application, it is unlikely that our system would fit the needs of a visualization containing several thousands data points. Keeping track of such large amount of points would require grouping techniques that are yet to be developed.
5.2. Relations between the Interface and Our End Goals
- User-centric, where individuals are likely to attract more attention than usual tasks-driven platforms (i.e., social platforms);
- Data-centric, where analysts will focus on items (i.e., database platforms);
- Visualization-centric, where most interactions happen directly on the visualization;
- and Pattern-centric, where expert analysts would search for specific patterns in the annotations.
5.3. Extending the Classification Framework
- Health level, an ordinal dimension that ranges from “fine” to “dead.” Encoded by colored cells.
- Presence, a boolean that states whether the character appears in the session. Encoded by black cells.
- Notes, free text to provide more explanations regarding a session and a character. Encoded by a circle within a cell.
- “Meng is the only one who dies.” Meng is a subject single data unit. The annotation provides a singularity detected pattern and a data level of interpretation. “Dies” is a reference to the product “health level” between both natures of the dataset: we turn this into a notable feature. There is no explicit mention of an explanatory data unit.
- “Fernand doesn’t get hit, high level of health during the first half of the story.” Fernand is a subject data unit. As no mention of any other character is made, the annotation shows a singularity. “High level of health” is a reference to “high level,” whose particularity is “being high,” and “the first half of the story” is an explanatory data unit.
5.4. User Evaluation
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| i. sing. | Implicit Singularity (pattern) |
| e. sing. | Explicit Singularity (pattern) |
| sScope | Subject’s scope (data unit) |
| cScope | Complement’s scope (data unit) |
References
- Plaisant, C. The challenge of information visualization evaluation. In Proceedings of the Working Conference on Advanced Visual Interfaces, AVI 2004, Gallipoli, Italy, 25–28 May 2004; Costabile, M.F., Ed.; ACM Press: New York, NY, USA, 2004; pp. 109–116. [Google Scholar] [CrossRef]
- Vanhulst, P.; Evéquoz, F.; Tuor, R.; Lalanne, D. A Descriptive Attribute-Based Framework for Annotations in Data Visualization. In Computer Vision, Imaging and Computer Graphics Theory and Applications—13th International Joint Conference, VISIGRAPP 2018, Funchal, Madeira, Portugal, 27–29 January 2018, Revised Selected Papers; Bechmann, D., Chessa, M., Cláudio, A.P., Imai, F.H., Kerren, A., Richard, P., Telea, A.C., Trémeau, A., Eds.; Communications in Computer and Information Science; Springer: New York, NY, USA, 2018; Volume 997, pp. 143–166. [Google Scholar] [CrossRef]
- Willett, W.; Heer, J.; Hellerstein, J.M.; Agrawala, M. CommentSpace: Structured support for collaborative visual analysis. In Proceedings of the International Conference on Human Factors in Computing Systems, CHI 2011, Vancouver, BC, Canada, 7–12 May 2011; Tan, D.S., Amershi, S., Begole, B., Kellogg, W.A., Tungare, M., Eds.; ACM: New York, NY, USA, 2011; pp. 3131–3140. [Google Scholar] [CrossRef]
- Gotz, D.; Zhou, M.X. Characterizing users’ visual analytic activity for insight provenance. Inf. Vis. 2009, 8, 42–55. [Google Scholar] [CrossRef]
- Schmidt, C.; Rosenthal, P.; Schumann, H. Annotations as a Support for Knowledge Generation—Supporting Visual Analytics in the Field of Ophthalmology. In VISIGRAPP 2018, Proceedings of the 13th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications—Volume 3: IVAPP, Funchal, Madeira, Portugal, 27–29 January 2018; Telea, A.C., Kerren, A., Braz, J., Eds.; SciTePress: Setúbal, Portugal, 2018; pp. 264–272. [Google Scholar] [CrossRef]
- Zhao, J.; Glueck, M.; Breslav, S.; Chevalier, F.; Khan, A. Annotation Graphs: A Graph-Based Visualization for Meta-Analysis of Data Based on User-Authored Annotations. IEEE Trans. Vis. Comput. Graph. 2017, 23, 261–270. [Google Scholar] [CrossRef] [PubMed]
- Heer, J.; Shneiderman, B. Interactive dynamics for visual analysis. Commun. ACM 2012, 55, 45–54. [Google Scholar] [CrossRef]
- Munzner, T. Visualization Analysis and Design; A.K. Peters Visualization Series; A K Peters: Wellesley, MA, USA, 2014. [Google Scholar]
- Bertin, J. Sémiologie Graphique: Les Diagrammes, les Réseaux, les Cartes; Gauthier-VillarsMouton & Cie: Paris, France, 1967; p. 399. [Google Scholar]
- Friel, S.N.; Curcio, F.R.; Bright, G.W. Making Sense of Graphs: Critical Factors Influencing Comprehension and Instructional Implications. J. Res. Math. Educ. 2001, 32, 124–158. [Google Scholar] [CrossRef]
- Curcio, F.R. Comprehension of Mathematical Relationships Expressed in Graphs. J. Res. Math. Educ. 1987, 18, 382–393. [Google Scholar] [CrossRef]
- Boy, J.; Rensink, R.A.; Bertini, E.; Fekete, J. A Principled Way of Assessing Visualization Literacy. IEEE Trans. Vis. Comput. Graph. 2014, 20, 1963–1972. [Google Scholar] [CrossRef] [PubMed]
- Mahyar, N.; Sarvghad, A.; Tory, M. Note-taking in co-located collaborative visual analytics: Analysis of an observational study. Inf. Vis. 2012, 11, 190–204. [Google Scholar] [CrossRef]
- Sanderson, R.; Ciccarese, P.; Young, B. Web Annotation Data Model. W3C Recommendation, W3C. 2017. Available online: https://www.w3.org/TR/2017/REC-annotation-model-20170223/ (accessed on 29 March 2021).
- Viégas, F.B.; Wattenberg, M.; van Ham, F.; Kriss, J.; McKeon, M.M. ManyEyes: A Site for Visualization at Internet Scale. IEEE Trans. Vis. Comput. Graph. 2007, 13, 1121–1128. [Google Scholar] [CrossRef] [PubMed]
- Lu, S. D3-Annotation. 2017. Available online: https://d3-annotation.susielu.com/ (accessed on 29 March 2021).
- Bostock, M.; Ogievetsky, V.; Heer, J. D3 Data-Driven Documents. IEEE Trans. Vis. Comput. Graph. 2011, 17, 2301–2309. [Google Scholar] [CrossRef] [PubMed]
- Mathisen, A.; Horak, T.; Klokmose, C.N.; Grønbæk, K.; Elmqvist, N. InsideInsights: Integrating Data-Driven Reporting in Collaborative Visual Analytics. Comput. Graph. Forum 2019, 38, 649–661. [Google Scholar] [CrossRef]
- Rädle, R.; Nouwens, M.; Antonsen, K.; Eagan, J.R.; Klokmose, C.N. Codestrates: Literate Computing with Webstrates. In Proceedings of the 30th Annual ACM Symposium on User Interface Software and Technology, UIST 2017, Quebec City, QC, Canada, 22–25 October 2017; Gajos, K., Mankoff, J., Harrison, C., Eds.; ACM: New York, NY, USA, 2017; pp. 715–725. [Google Scholar] [CrossRef]
- Satyanarayan, A.; Wongsuphasawat, K.; Heer, J. Declarative interaction design for data visualization. In Proceedings of the 27th Annual ACM Symposium on User Interface Software and Technology, UIST’14, Honolulu, HI, USA, 5–8 October 2014; Benko, H., Dontcheva, M., Wigdor, D., Eds.; ACM: New York, NY, USA, 2014; pp. 669–678. [Google Scholar] [CrossRef]
- Wongsuphasawat, K.; Moritz, D.; Anand, A.; Mackinlay, J.D.; Howe, B.; Heer, J. Towards a general-purpose query language for visualization recommendation. In Proceedings of the Workshop on Human-In-the-Loop Data Analytics, HILDA@SIGMOD 2016, San Francisco, CA, USA, 26 June–1 July 2016; Binnig, C., Fekete, A.D., Nandi, A., Eds.; ACM: New York, NY, USA, 2016; p. 4. [Google Scholar] [CrossRef]
- Wongsuphasawat, K.; Qu, Z.; Moritz, D.; Chang, R.; Ouk, F.; Anand, A.; Mackinlay, J.D.; Howe, B.; Heer, J. Voyager 2: Augmenting Visual Analysis with Partial View Specifications. In Proceedings of the 2017 CHI Conference on Human Factors in Computing Systems, Denver, CO, USA, 6–11 May 2017; Mark, G., Fussell, S.R., Lampe, C., Schraefel, M.C., Hourcade, J.P., Appert, C., Wigdor, D., Eds.; ACM: New York, NY, USA, 2017; pp. 2648–2659. [Google Scholar] [CrossRef]
- Yu, B.; Silva, C.T. FlowSense: A Natural Language Interface for Visual Data Exploration within a Dataflow System. IEEE Trans. Vis. Comput. Graph. 2020, 26, 1–11. [Google Scholar] [CrossRef] [PubMed]
- Sykes, J.A. English grammar as a sentence model for conceptual modelling using NIAM. In Information System Concepts: Towards a Consolidation of Views, Proceedings of the IFIP International Working Conference on Information System Concepts (ISCO 1995), Marburg, Germany, 28–30 March 1995; Falkenberg, E.D., Hesse, W., Olivé, A., Eds.; IFIP Conference Proceedings; Springer US: Boston, MA, USA, 1995; Volume 26, pp. 161–176. [Google Scholar]
- Chipana, M.L.; Verma, H.; Evéquoz, F.; Vanhulst, P.; Lalanne, D. Vasco: Interactive tool for early-exploration of data. In Proceedings of the 31st Conference on l’Interaction Homme-Machine: Adjunct, IHM 2019, Grenoble, France, 10–13 December 2019; ACM: New York, NY, USA, 2019; pp. 4:1–4:7. [Google Scholar] [CrossRef]
- Satyanarayan, A.; Heer, J. Lyra: An Interactive Visualization Design Environment. Comput. Graph. Forum 2014, 33, 351–360. [Google Scholar] [CrossRef]













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Interface: Step | Interface: Options | Classification |
|---|---|---|
| 1. Subject | Selecting a single element | Data unit (subject single data unit) |
| Selecting several elements | Data unit (subject aggregated data unit) | |
| Selecting with rectangle | Level of interpretation (visual) | |
| Selecting with autofill | Level of interpretation (data) | |
| 2. Verb | “stands out” | Patterns (singularity) |
| “stands out” + complement | Patterns (duality) | |
| “is similar” + complement | Patterns (duality) | |
| No verb | Patterns (generality) | |
| 3. Complement | Selecting element(s) | Data unit (complement single data unit or aggregated, as in step 1) |
| Patterns ((e. sing.) if (sScope) =\= (cScope), else duality) | ||
| No selection | Patterns ((i. sing.) if sScope is smaller than 80% of total units) | |
| Selecting with rectangle | Level of interpretation (visual) | |
| Selecting with autofill | Level of interpretation (data) | |
| 4. Meaning | Typing a conclusion | Level of interpretation (meaning) |
| Free | Structured | |
|---|---|---|
| Total | 204 | 186 |
| Related to data | 117 | 178 |
| Beyond data | 66 | 4 |
| References | 83 | 26 |
| Multiple | 28 * | 15 |
| Three levels of interpretation | 2 | 64 |
| At least “meaning” level of interpretation ** | 100 | 145 |
| Generalities | 15 | 6 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Vanhulst, P.; Tuor, R.; Évéquoz, F.; Lalanne, D. Colvis—A Structured Annotation Acquisition System for Data Visualization. Information 2021, 12, 158. https://doi.org/10.3390/info12040158
Vanhulst P, Tuor R, Évéquoz F, Lalanne D. Colvis—A Structured Annotation Acquisition System for Data Visualization. Information. 2021; 12(4):158. https://doi.org/10.3390/info12040158
Chicago/Turabian StyleVanhulst, Pierre, Raphaël Tuor, Florian Évéquoz, and Denis Lalanne. 2021. "Colvis—A Structured Annotation Acquisition System for Data Visualization" Information 12, no. 4: 158. https://doi.org/10.3390/info12040158
APA StyleVanhulst, P., Tuor, R., Évéquoz, F., & Lalanne, D. (2021). Colvis—A Structured Annotation Acquisition System for Data Visualization. Information, 12(4), 158. https://doi.org/10.3390/info12040158