
Vectorization of Floor Plans Based on EdgeGAN

Abstract
1. Introduction
- (1)
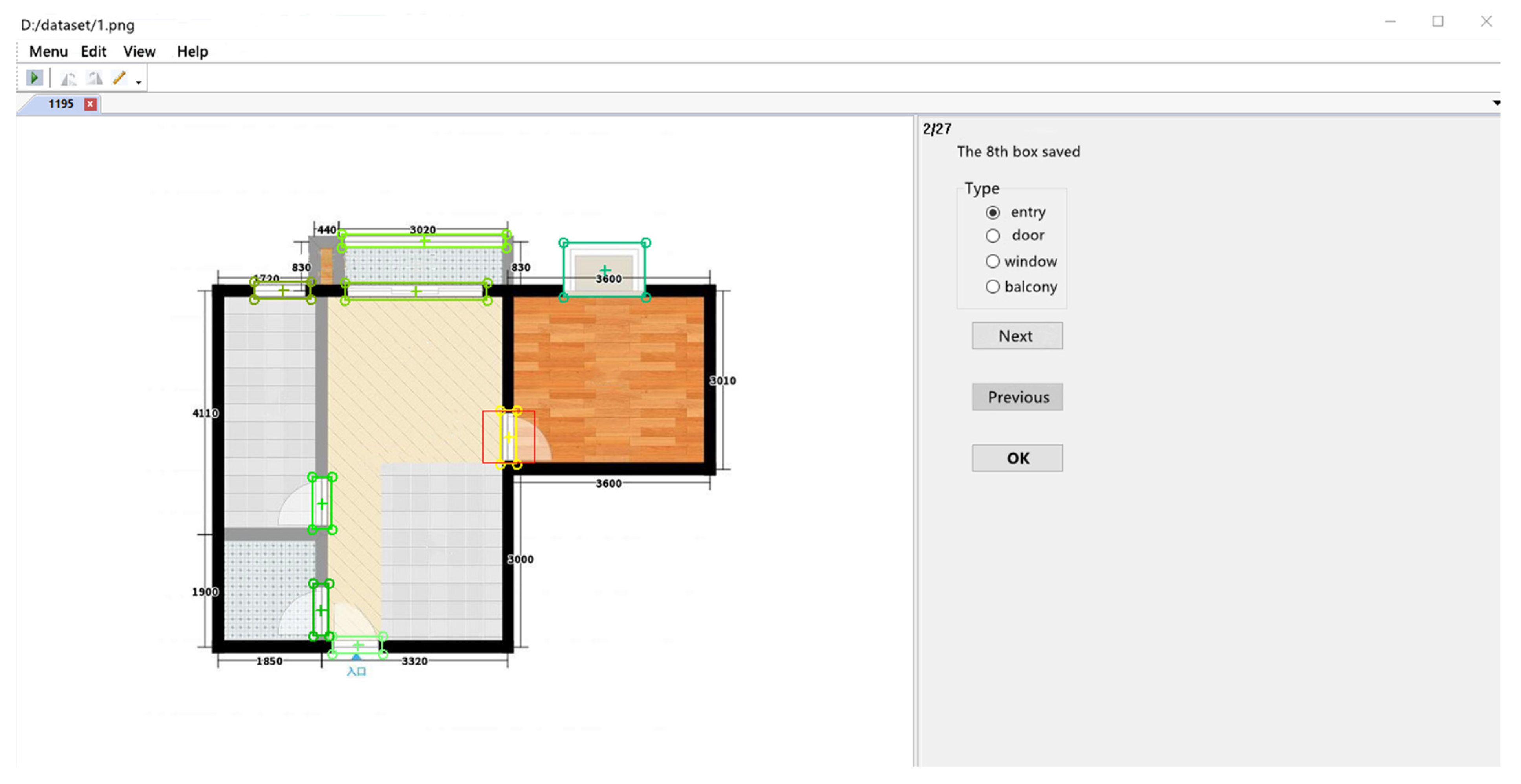
- A colorful and larger dataset called ZSCVFP is established. Unlike current public datasets, which only contain black and white FPs without decorative disturbance or style variation, such as CVC-FP [14] and CubiCasa5K [35], ZSCVFP’s FPs are drawn with decorative disturbance in different styles, thereby causing difficulty in the extraction of primitives. The ground truth annotations in the form of points and lines, together with the corresponding images, are provided. Furthermore, ZSCVFP has a total of 10,800 samples. This number is higher than the 121 and 5000 samples of CVC-FP and CubiCasa5K, respectively.
- (2)
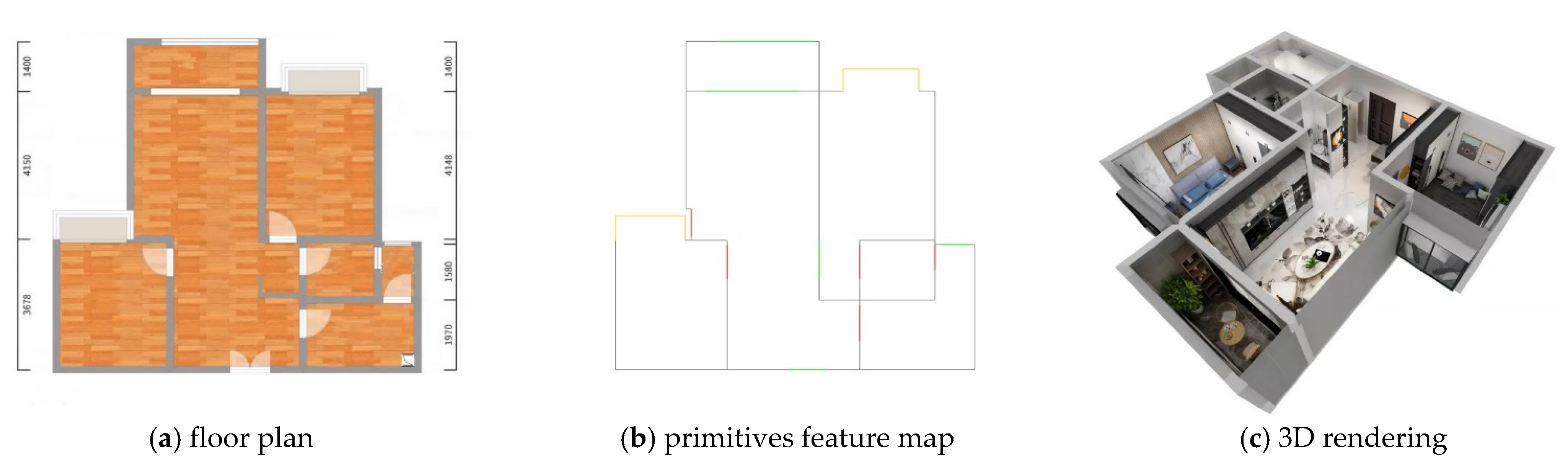
- VFP is formulated as an image translation task innovatively, and EdgeGAN based on pix2pix is designed for the new task. EdgeGAN projects the FPs into the primitive space. Each channel of the primitive feature map (PFM) only contains some lines that represent one category of primitives. A self-supervising term is added to the generative loss of EdgeGAN to enhance the quality of PFM. Unlike conventional pipelines (even if some modules are replaced with deep-learning methods) that consist of a series of carefully designed algorithms, EdgeGAN obtains the FVG in an end-to-end manner. EdgeGAN is about 15 times as fast as the conventional pipeline. To the best knowledge of the authors, this study is the first to apply GAN in VFP.
- (3)
- Four criteria, which are sufficient conditions for a fully connected graph, are given to inspect the connectivity of subspaces segmented from the PFM. The connective inspection can provide auxiliary information for the designers to adjust the FVG.
- (4)
- The graph neural network (GNN) is used to predict the categories of subspaces segmented from the PFM. Given that GNN treats the adjacent matrix of the connective graph as weights directly, it can utilize global layout information and achieve higher accuracy than other common classifying methods.
2. Problem Description
Framework Based on EdgeGAN
- (1)
- Design a to obtain the PFM that is robust with decorative disturbances in variant styles;
- (2)
- Search for efficient criteria to inspect whether is fully connected;
- (3)
- Design a GNN to predict the category of subspaces.
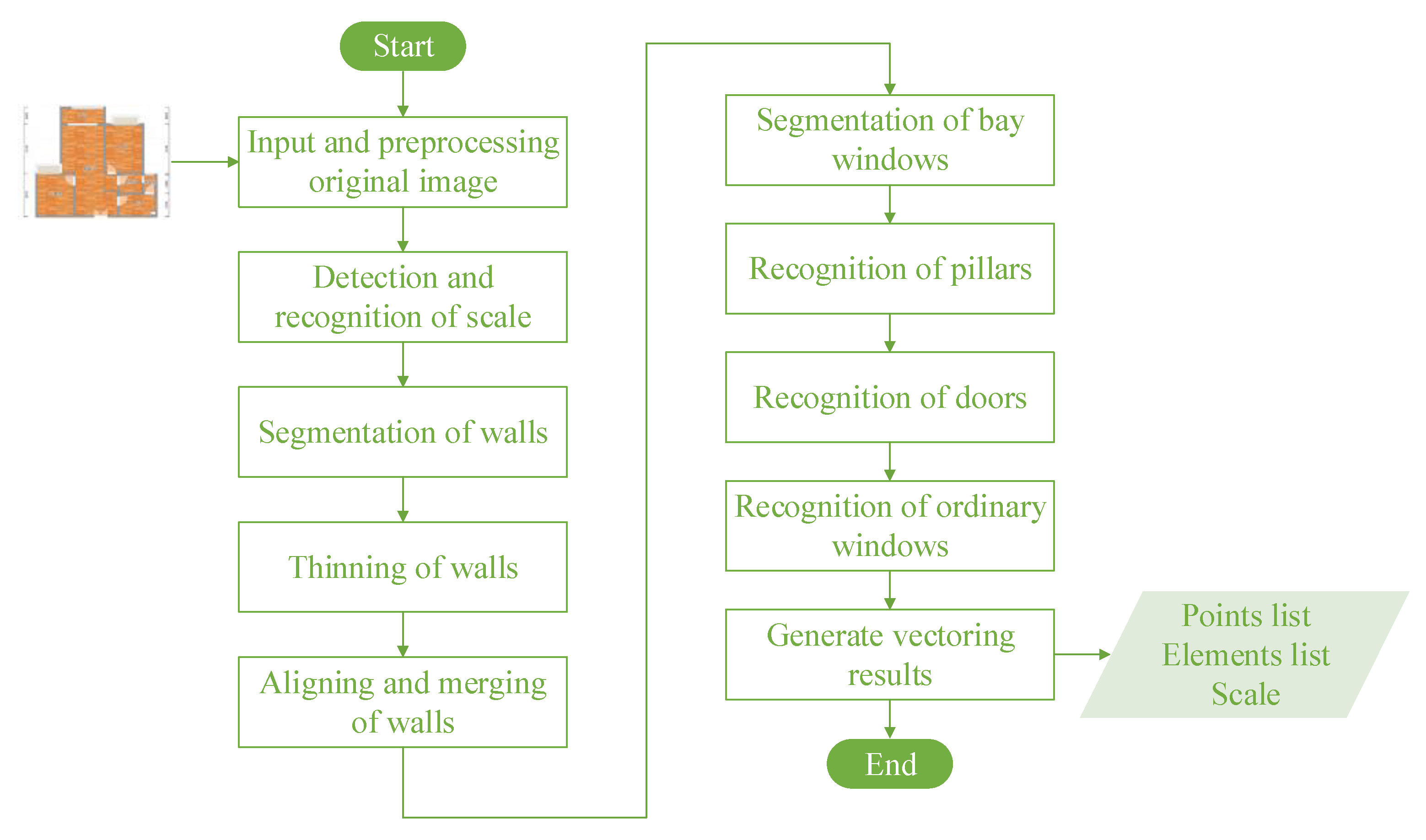
3. Methods
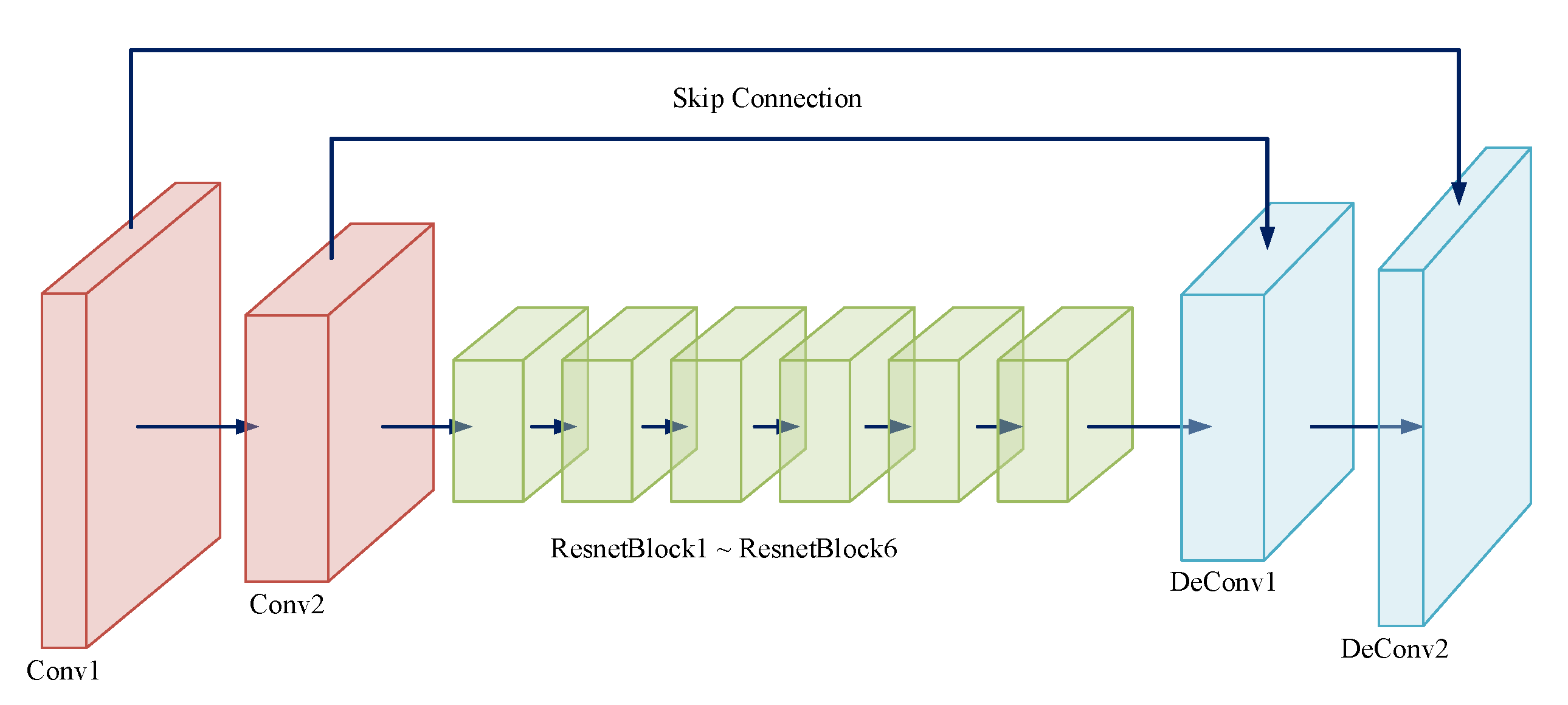
3.1. EdgeGAN
3.2. Criteria for Connective Inspection
- (1)
- if ; if ; otherwise ;
- (2)
- ;
- (3)
- , that is, is symmetrical.
- (1)
- There is a door on the external door at least, i.e., ;
- (2)
- The number of doors on the external doors is often less than 2, i.e., ;
- (3)
- Each subspace except those with special architectural functionality (for example, the regions for air condition and pipe) has at least one door, that is, and , where ;
- (4)
- is a connected graph, that is, .
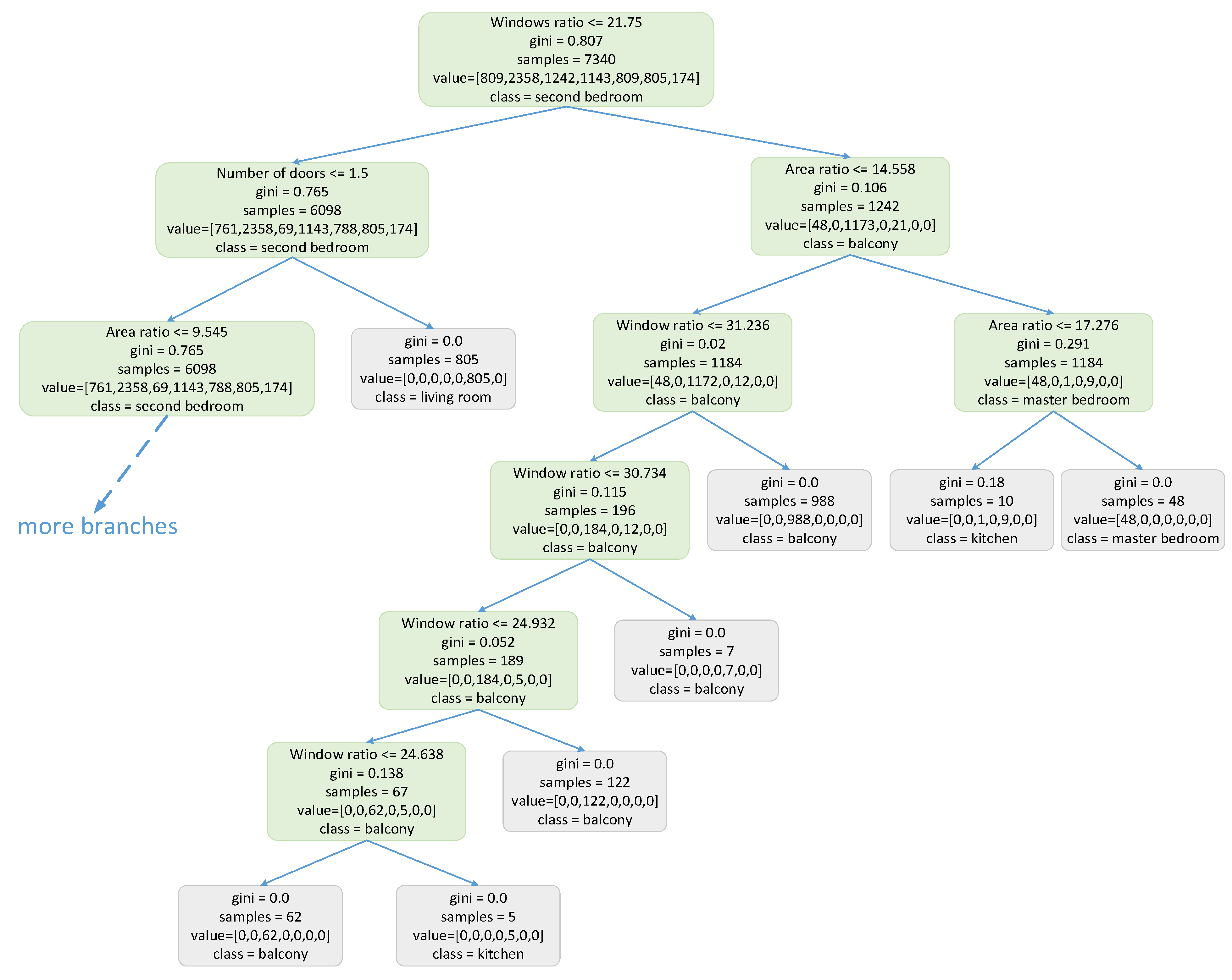
3.3. Classifying of Subspaces Based on GNN
4. Experimental Results and Discussion
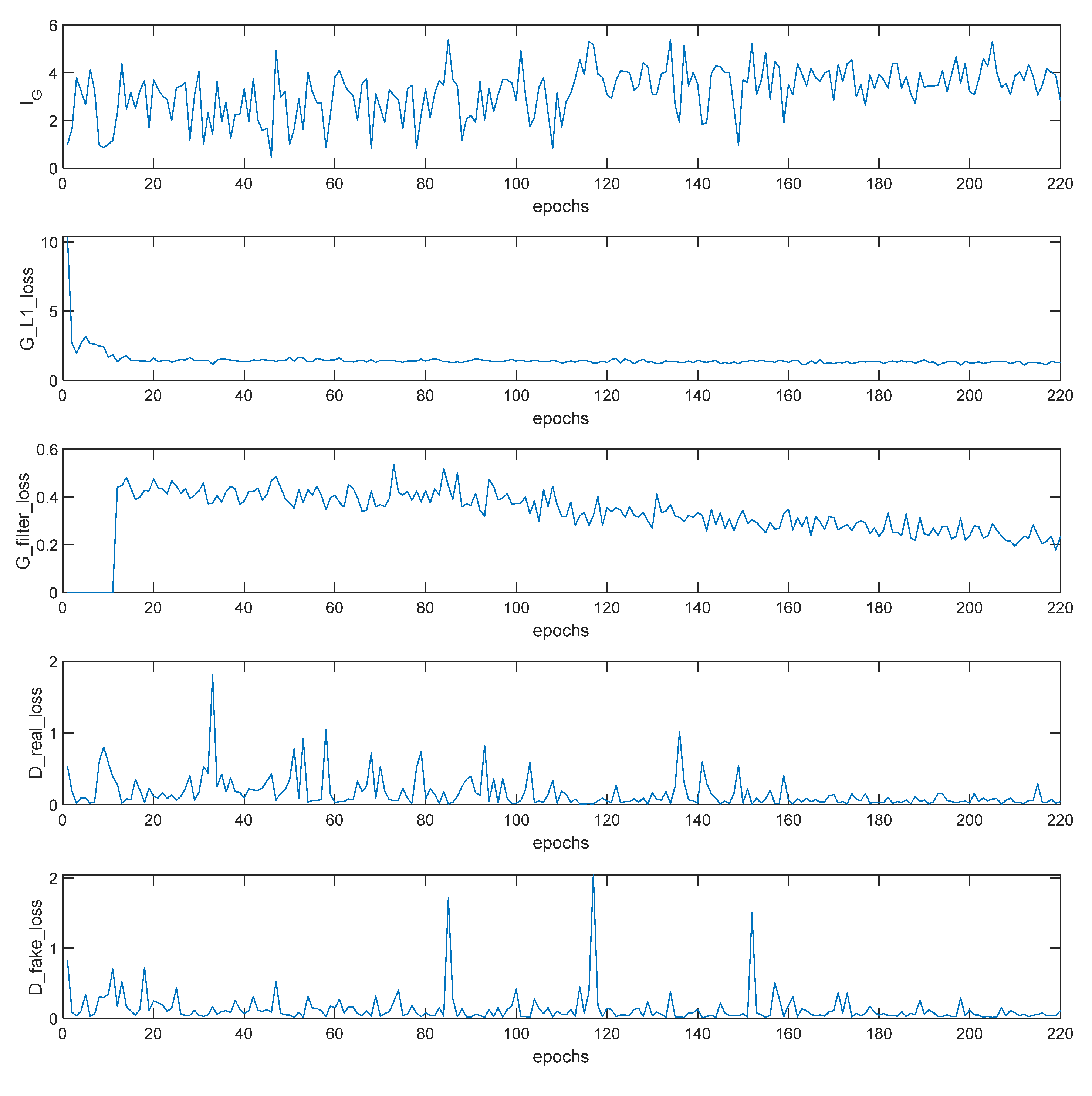
4.1. EdgeGAN
- (1)
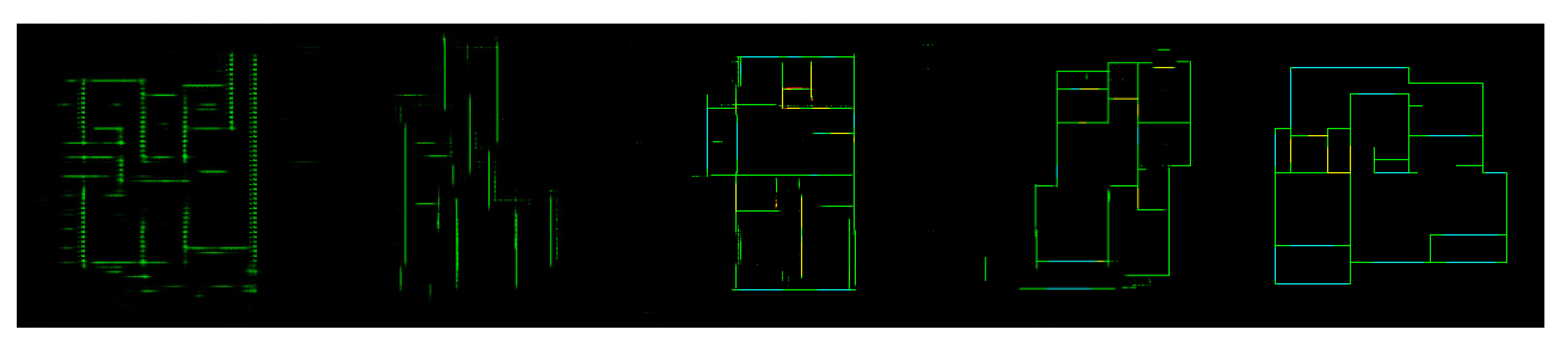
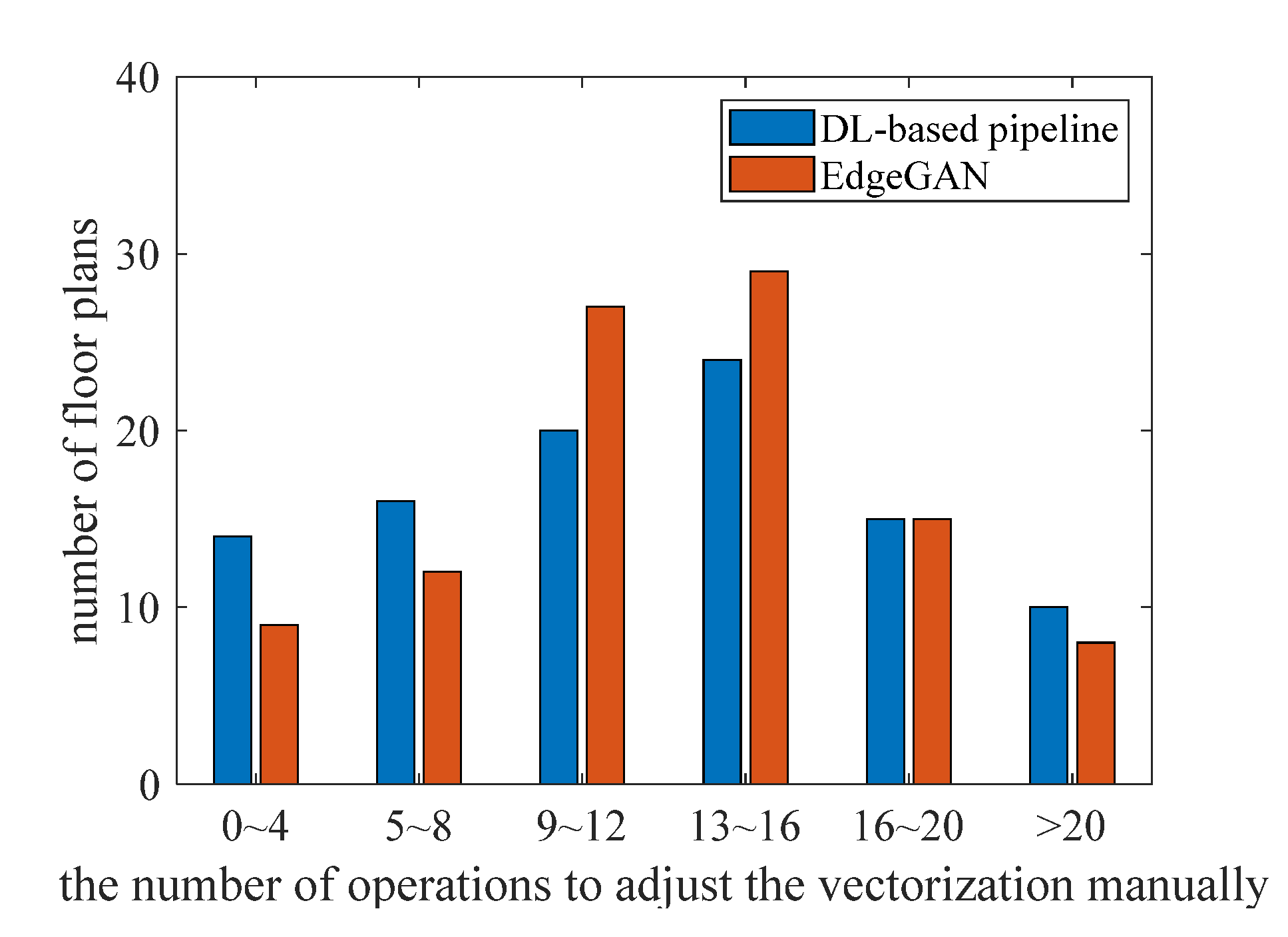
- Level 1: The generated images are free from noisy points and have high-quality lines, and the recognition accuracy of primitives is close to the conventional pipeline. The proportion of level 1 is approximately 40%. These images can be used to obtain vector graphics with a few manual adjustments, similar to the conventional pipeline. Figure 10 compares the number of adjusting operations that are counted by a decoration designer on 100 FPs with level 1 results. Although the results of EdgeGAN satisfy the requirements of the application, its performance is still slightly weaker than that of the DL-based pipeline. The mean value of operations of the DL-based pipeline (16.50) is close to that of EdgeGAN (16.67). However, the standard deviation of EdgeGAN (8.34) is much larger than that of the DL-based pipeline (4.4628), which means that the latter is more stable. Moreover, 30 PFMs generated by the DL-based pipeline need less than eight operations, while only 21 PFMs by EdgeGAN, which means that the former has a higher rate of excellence. The results of EdgeGAN. Considering that the pseudo-ground truth annotations themselves are obtained on the basis of the conventional pipeline and suffer from inaccuracy, the results are reasonable. The performance of EdgeGAN can be improved if it is training on a larger and higher quality dataset.
- (2)
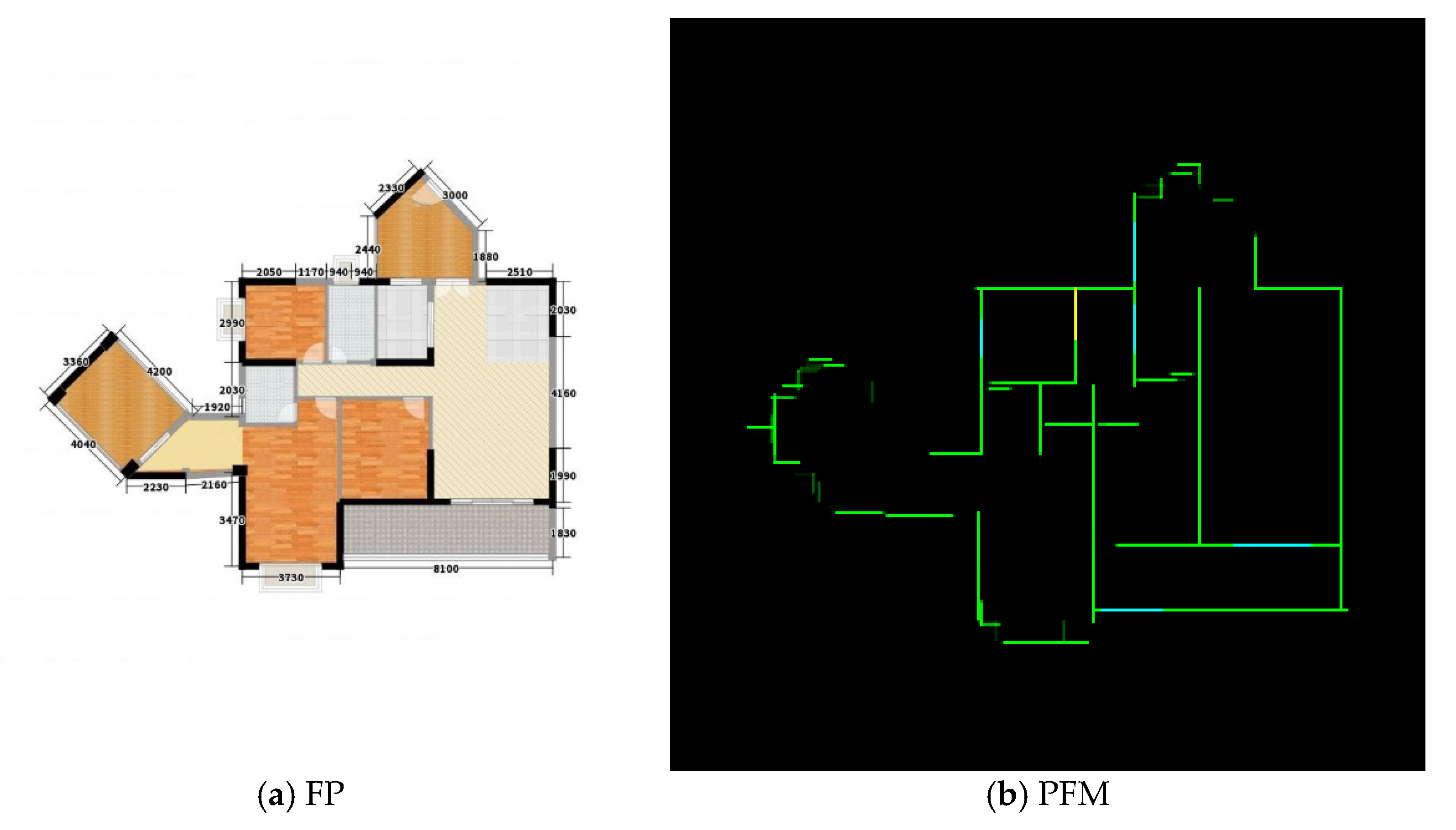
- Level 2: In addition to inaccurate primitives, some noisy points, broken lines, redundancy lines, or unaligned lines are presented in the generated images, as shown in the lines in the main body of Figure 11. The proportion of level 2 is approximately 55%. The self-supervising loss can relieve but cannot eliminate this phenomenon. Some postprocessing methods are necessary to address these problems. Solving this problem by using the EdgeGAN itself is direct but still challenging.
- (3)
- Level 3: Serious defects in quality or accuracy with a proportion of approximately 5% are observed in the sloping walls in Figure 11. The reason is that the number of samples with sloping walls is less than 100, which is much less than horizontal and vertical walls.
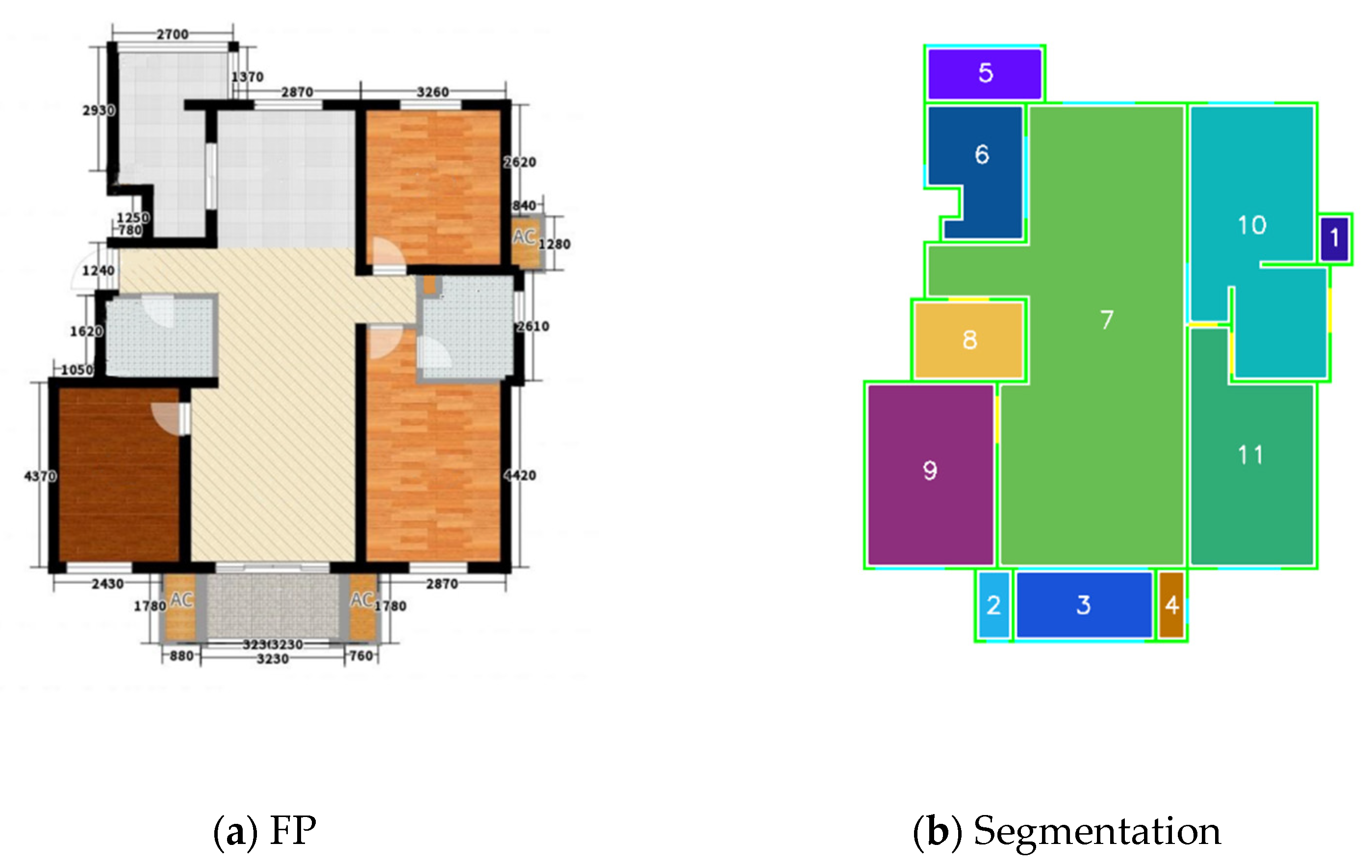
4.2. Connectivity of Subspaces
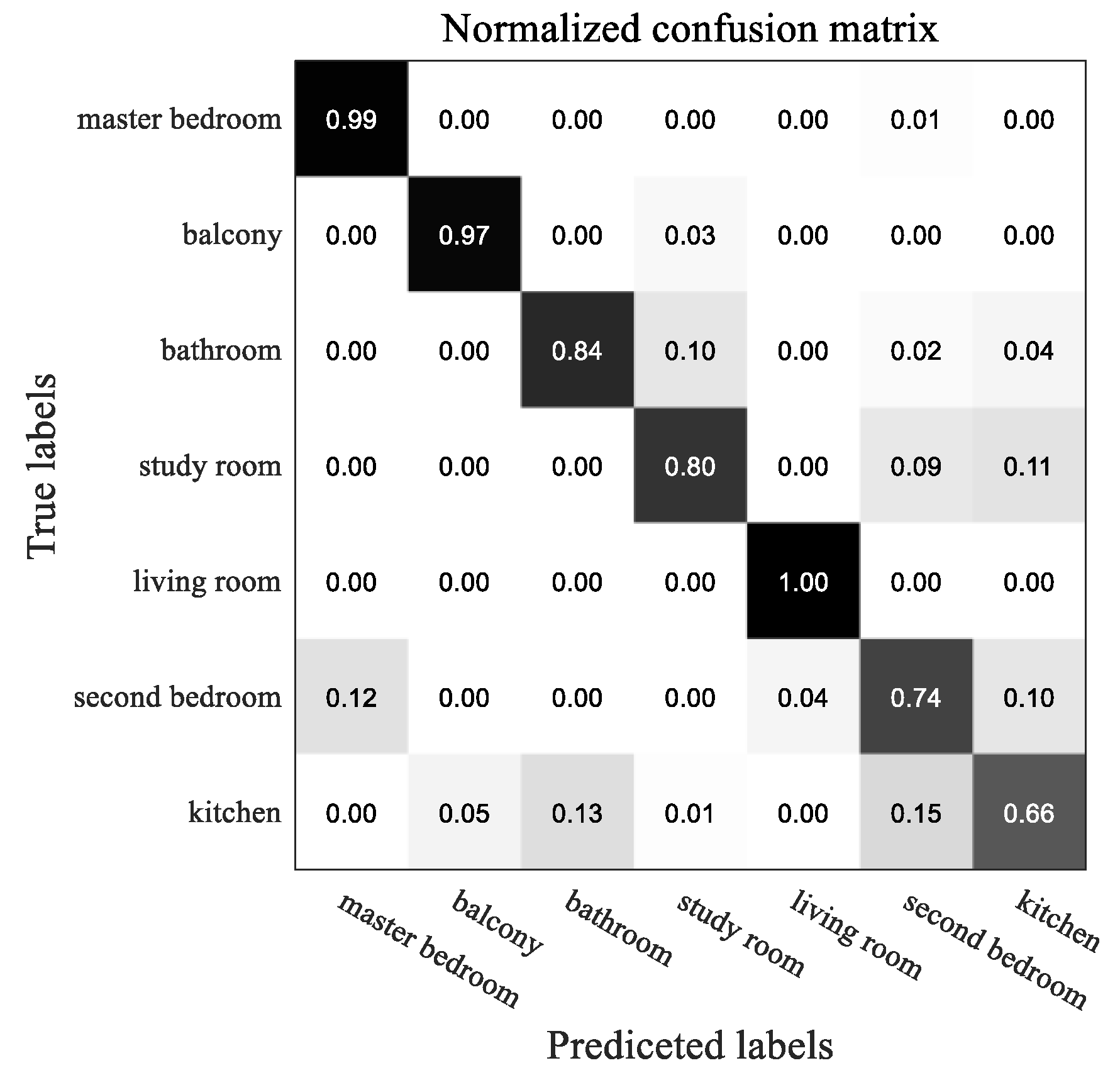
4.3. Classifying of Subspaces Based on GNN
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Conflicts of Interest
Abbreviations
| FP | floor plans |
| VFP | vectorization of floor plans |
| FVG | floor vector graph |
| PFM | primitive feature map |
| SCG | subspace connective graph |
| GAN | generative adversarial network |
| GNN | graph neural network |
| EdgeGAN | edge extraction GAN |
| ZSCVFP | private dataset established by us |
References
- Lewis, R.; Séquin, C. Generation of 3D building models from 2D architectural plans. Comput. Aided Des. 1998, 30, 765–779. [Google Scholar] [CrossRef]
- Gimenez, L.; Hippolyte, J.-L.; Robert, S.; Suard, F.; Zreik, K. Review: Reconstruction of 3D building information models from 2D scanned plans. J. Build. Eng. 2015, 2, 24–35. [Google Scholar] [CrossRef]
- Lu, T.; Tai, C.-L.; Su, F.; Cai, S. A new recognition model for electronic architectural drawings. Comput. Aided Des. 2005, 37, 1053–1069. [Google Scholar] [CrossRef]
- Lu, T.; Tai, C.-L.; Bao, L.; Su, F.; Cai, S. 3D Reconstruction of Detailed Buildings from Architectural Drawings. Comput. Aided Des. Appl. 2005, 2, 527–536. [Google Scholar] [CrossRef]
- Lu, T.; Yang, H.; Yang, R.; Cai, S. Automatic analysis and integration of architectural drawings. Int. J. Doc. Anal. Recognit. 2006, 9, 31–47. [Google Scholar] [CrossRef]
- Zhu, J. Research on 3D Building Reconstruction from 2D Vector Floor Plan Based on Structural Components Recognition. Master’s Thesis, Tsinghua University, Beijing, China, 2013. [Google Scholar]
- Jiang, Z. Research on Floorplan Image Recognition Based on Shape and Edge Features. Master’s Thesis, Harbin Institute of Technology, Harbin, China, 2016. [Google Scholar]
- Gimenez, L.; Robert, S.; Suard, F.; Zreik, K. Automatic reconstruction of 3D building models from scanned 2D floor plans. Autom. Constr. 2016, 63, 48–56. [Google Scholar] [CrossRef]
- Tombre, K.; Tabbone, S.; Pelissier, L.; Lamiroy, B.; Dosch, P. Text/Graphics Separation Revisited. In International Workshop on Document Analysis Systems; Springer: Berlin/Heidelberg, Germany, 2002; pp. 200–211. [Google Scholar]
- Ahmed, S.; Weber, M.; Liwicki, M.; Dengel, A. Text/Graphics Segmentation in Architectural Floor Plans. In Proceedings of the 2011 International Conference on Document Analysis and Recognition, Beijing, China, 18–21 September 2011; pp. 734–738. [Google Scholar]
- Ahmed, S.; Liwicki, M.; Weber, M.; Dengel, A. Automatic Room Detection and Room Labeling from Architectural Floor Plans. In Proceedings of the 10th IAPR International Workshop on Document Analysis Systems, Gold Coast, Australia, 27–29 March 2012; pp. 339–343. [Google Scholar]
- Smith, R. An overview of the Tesseract OCR engine. In Proceedings of the Ninth International Conference on Document Analysis and Recognition (ICDAR 2007), Curitiba, Brazil, 23–26 September 2007; Volume 2, pp. 629–633. [Google Scholar]
- Long, S.; He, X.; Yao, C. Scene Text Detection and Recognition: The Deep Learning Era. Int. J. Comput. Vis. 2021, 129, 161–184. [Google Scholar] [CrossRef]
- Dodge, S.; Xu, J.; Stenger, B. Parsing floor plan images. In Proceedings of the 2017 Fifteenth IAPR International Conference on Machine Vision Applications (MVA), Nagoya, Japan, 8–12 May 2017; pp. 358–361. [Google Scholar]
- Liu, C.; Wu, J.; Kohli, P.; Furukawa, Y. Raster-to-Vector: Revisiting Floorplan Transformation. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2214–2222. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Jian, S. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 39, 1137–1149. [Google Scholar] [CrossRef]
- Bochkovskiy, A.; Wang, C.-Y.; Liao, H.-Y.M. YOLOv4: Optimal Speed and Accuracy of Object Detection. arXiv 2020, arXiv:2004.10934v1. [Google Scholar]
- Duan, K.; Bai, S.; Xie, L.; Qi, H.; Huang, Q.; Tian, Q. CenterNet: Object Detection with Keypoint Triplets. arXiv 2019, arXiv:1904.08189v1. [Google Scholar]
- Law, H.; Deng, J. CornerNet: Detecting Objects as Paired Keypoints. arXiv 2019, arXiv:1808.01244v2. [Google Scholar]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the International Conference on Medical Image Computing and Computer-Assisted Intervention, Cham, Switzerland, 5–9 October 2015; pp. 234–241. [Google Scholar]
- Goodfellow, I.J.; Pouget-abadie, J.; Mirza, M.; Xu, B.; Warde-farley, D. Generative Adversarial Nets. arXiv 2014, arXiv:1406.2661v1. [Google Scholar]
- Sandelin, F. Semantic and Instance Segmentation of Room Features in Floor Plans Using Mask R-CNN. Master’s Thesis, Uppsala University, Uppsala, Sweden, 2019. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. arXiv 2014, arXiv:1411.1784v1. [Google Scholar]
- Odena, A.; Olah, C.; Shlens, J. Conditional Image Synthesis with Auxiliary Classifier GANs. In Proceedings of the International Conference on Machine Learning, ICML 2017, Sydney, Australia, 6–11 August 2017; Volume 6, pp. 4043–4055. [Google Scholar]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein GAN. arXiv 2017, arXiv:1701.07875v3. [Google Scholar]
- Gulrajani, I.; Ahmed, F.; Arjovsky, M.; Dumoulin, V.; Courville, A. Improved Training of Wasserstein GANs. arXiv 2017, arXiv:1704.00028v3. [Google Scholar]
- Isola, P.; Zhu, J.-Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 5967–5976. [Google Scholar]
- Creswell, A.; White, T.; Dumoulin, V.; Arulkumaran, K.; Sengupta, B.; Bharath, A.A. Generative Adversarial Networks: An Overview. IEEE Signal Process. Mag. 2018, 35, 53–65. [Google Scholar] [CrossRef]
- Hong, Y.; Hwang, U.; Yoo, J.; Yoon, S. How Generative Adversarial Networks and Their Variants Work. ACM Comput. Surv. 2019, 52, 1–43. [Google Scholar] [CrossRef]
- Wang, T.C.; Liu, M.Y.; Zhu, J.Y.; Tao, A.; Kautz, J.; Catanzaro, B. High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs. In Proceedings of the IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 8798–8807. [Google Scholar]
- Wang, T.; Liu, M.; Zhu, J.; Liu, G.; Tao, A.; Kautz, J.; Catanzaro, B. Video-to-Video Synthesis. arXiv 2018, arXiv:1808.06601v2. [Google Scholar]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation Using Cycle-Consistent Adversarial Networks. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2242–2251. [Google Scholar]
- Yi, Z.; Zhang, H.; Tan, P.; Gong, M. DualGAN: Unsupervised Dual Learning for Image-to-Image Translation. In Proceedings of the 2017 IEEE International Conference on Computer Vision (ICCV), Venice, Italy, 22–29 October 2017; pp. 2868–2876. [Google Scholar]
- Kim, T.; Cha, M.; Kim, H.; Kwon, J.; Jiwon, L. Learning to Discover Cross-Domain Relations with Generative Adversarial Networks. arXiv 2017, arXiv:1703.05192. [Google Scholar]
- Kalervo, A.; Ylioinas, J.; Häikiö, M.; Karhu, A.; Kannala, J. CubiCasa5K: A Dataset and an Improved Multi-task Model for Floorplan Image Analysis. arXiv 2019, arXiv:1904.01920. [Google Scholar]
- Facebook. Available online: https://Pytorch.Org/ (accessed on 13 October 2020).
- Nvidia. Available online: https://Developer.Nvidia.Com/Zh-Cn/Cuda-Toolkit (accessed on 25 June 2020).
- Li, H. Statistical Learning Method; Tsinghua Press: Beijing, China, 2019. [Google Scholar]
- Zambaldi, V.; Raposo, D.; Santoro, A.; Bapst, V. Relational Deep Reinforcement Learning. arXiv 2018, arXiv:1806.01830v2. [Google Scholar]
- Kim, Y.; Kim, S.; Kim, T.; Kim, C. CNN-Based Semantic Segmentation Using Level Set Loss. In Proceedings of the 2019 IEEE Winter Conference on Applications of Computer Vision (WACV), Waikoloa Village, HI, USA, 8–10 January 2019; pp. 1752–1760. [Google Scholar]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Training Set | Test Set | |
|---|---|---|
| master bedroom | 809 | 200 |
| balcony | 1242 | 315 |
| bathroom | 1143 | 287 |
| study room | 174 | 46 |
| living room | 809 | 200 |
| second bedroom | 2358 | 587 |
| kitchen | 805 | 200 |
| Method | C4.5 | ID3 | BP | CART | GNN |
|---|---|---|---|---|---|
| Accuracy | 74.82% | 75.49% | 79.13% | 79.66% | 84.35% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dong, S.; Wang, W.; Li, W.; Zou, K. Vectorization of Floor Plans Based on EdgeGAN. Information 2021, 12, 206. https://doi.org/10.3390/info12050206
Dong S, Wang W, Li W, Zou K. Vectorization of Floor Plans Based on EdgeGAN. Information. 2021; 12(5):206. https://doi.org/10.3390/info12050206
Chicago/Turabian StyleDong, Shuai, Wei Wang, Wensheng Li, and Kun Zou. 2021. "Vectorization of Floor Plans Based on EdgeGAN" Information 12, no. 5: 206. https://doi.org/10.3390/info12050206
APA StyleDong, S., Wang, W., Li, W., & Zou, K. (2021). Vectorization of Floor Plans Based on EdgeGAN. Information, 12(5), 206. https://doi.org/10.3390/info12050206