1. Introduction
Audio forensics [
1] is an important branch of multimedia security, which can be used to evaluate the authenticity of digital audio. Many audio forensics methods have been proposed for various speech operations in addition to common audio forgeries, such as double compression [
2,
3], pitch shifting [
4,
5,
6], device source [
7,
8,
9], replaying [
10] and the detection of the operation type and sequence of digital speech [
11]. Fake-quality detection is a very important part of the field of audio forensics, such as in [
12], in which the authors recompressed low bit rate audio into high bit rate audio. Generally, a higher bit rate indicates better audio quality. Since increasing the bit rate will cause recompression, the authors in [
12] proposed a fake-quality detection algorithm based on double compression tracing. As far as we know, however, there are no studies related to stereo-faking detection, which also belongs to the category of fake quality. Although fake stereo audio detection remains an unstudied field, there are many similar works in the audio field, such as audio forensics, speech recognition and speaker recognition.
In audio forensics, Mascia et al. [
13] proposed a forensic algorithm that uses MFCC/LMSC features to detect the recording environment. The algorithm provides support for forensic analysts in verifying the authenticity of audio content. Vijayasenan et al. [
14] proposed a forensic algorithm to study the effect of a wireless channel on physical parameter prediction, based on speech data. Speech data from 207 speakers, along with the corresponding speaker’s height and weight, were collected. A Bag of Words (BoW) representation, based on the log magnitude spectrum, was used for features. Support vector regression (SVR) predicted the physical parameters of the speaker from the BoW representation. The proposed system was able to achieve a Root Mean Square Error (RMSE) of 6.6 cm for height estimation, and 8.9 kg for weight estimation for clean speech. Hadoltikar et al. [
15] proposed a forensic algorithm for recording device identification, aiming to optimize the MFCC parameters in device identification in an audio recording. Zhao and Malik [
16] proposed a forensic algorithm for the identification of the acoustic environment (acoustic reverberation and background noise are usually used to characterize the acoustic environment). Inverse filtering was used to estimate the reverberation component, and particle filtering was used to estimate background noise from the audio recording. A multi-class support vector machine (SVM) classifier was used for acoustic environment identification (AEI). The experimental results show that the proposed system can successfully identify a recording environment for both regular and blind AEI. Jiang et al. [
17] proposed a mobile phone identifier, called Weighted SVM with Weighted Majority Voting (WSVM-WMV), for a closed-set mobile phone identification task. By using Mel-frequency cepstral coefficients (MFCCs) and linear-frequency cepstral coefficients (LFCCs) as the feature vectors, the proposed identifier can improve identification accuracy from 92.42% to 97.86% and from 90.44% to 98.33%, respectively, as compared with the traditional SVM identifier, in identifying a set of 21 mobile phones.
In speech recognition, Mitra et al. [
18] proposed an automatic speech recognition (ASR) algorithm, which improves the recognition accuracy of the automatic speech recognition system through the modulation of the medium duration speech amplitude (MMeDuSA) function. Athanaselis et al. [
19] discussed the improvement of speech recognition in the presence of noise when a parametric method of signal enhancement is used. Subramanian et al. [
20] proposed a method to optimize only a location-guided target speech extraction module along with a speech recognition module with ASR error minimization criteria. Fan et al. [
21] proposed a gated recurrent fusion (GRF) method with a joint training framework for robust end-to-end ASR. Compared with the traditional method, the proposed method can reduce the relative character error rate (CER) by 10.04%, using only enhanced functions.
In speaker recognition, Toruk et al. [
22] proposed a speaker recognition system based on time-delay neural networks (TDNNs). Compared with the traditional GMM speaker recognition system, its equal error rate (EER) value is improved. However, the relative improvement in the TDNN decreases while the test data duration decreases. Huang [
23] proposed speaker characterization using four different data augmentation methods and time-delay neural networks and long–short-term memory neural networks (TDNN-LSTMs). The proposed methods outperform the baselines of both the i-vector and the x-vector. Jagiasi et al. [
24] proposed a text-independent and language-independent speaker recognition system that was implemented using dense and convolutional neural networks and explored a system that uses MFCCs along with a DNN and CNN as the models for building a speaker recognition system. Desai et al. [
25] found that adding watermarking technology to the speaker’s audio can effectively protect the authenticity of the speaker’s audio while ensuring its quality. Watermarking technology is 100% efficient in identifying an attack and verifying the authenticity of the speaker.
Stereo faking is one of many audio-quality-faking techniques and aims to convert mono audio into stereo. Mono audio is a single channel of sound, perceived as coming from one position. Stereo audio is the reproduction of sound using two or more independent audio channels in a way that creates the impression of sound from various directions, as in natural hearing. Stereo audio has almost completely replaced mono due to its superior audio quality. Until the 1960s to 1970s, and even earlier, due to the limitations of recording equipment, most audio recordings and movie soundtracks were monophonic, and their auditory effects were poor. To improve audio quality, one can create an artificial stereo audio from its mono version. With the development of audio editing tools, the quality of stereo audio can be very close to real stereo audio. This technique, however, is also manipulated by some criminals for illegal gain. Since 2010, there have been many complaints about fake stereo audio quality, most of which are from music websites and apps. For example, people can buy their favorite songs online. Often, these songs are in stereo format. The legitimate interests of consumers will be violated if the purchased songs are fake stereo created from mono audio.
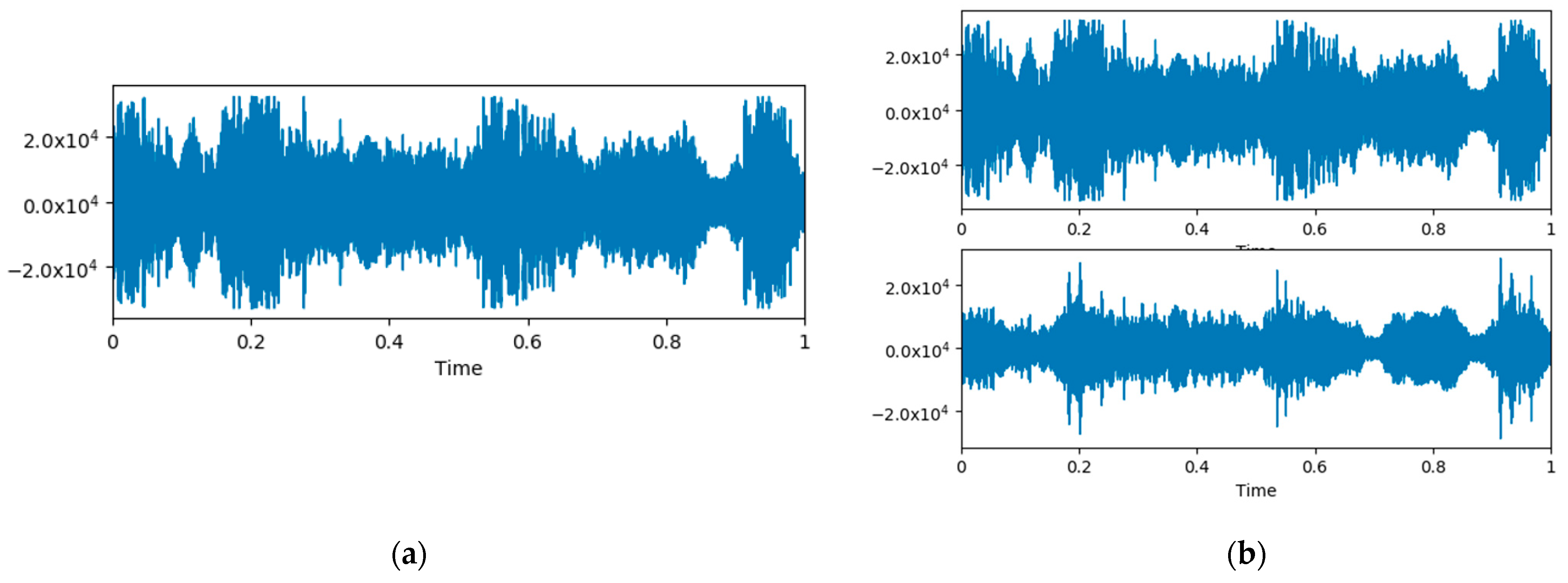
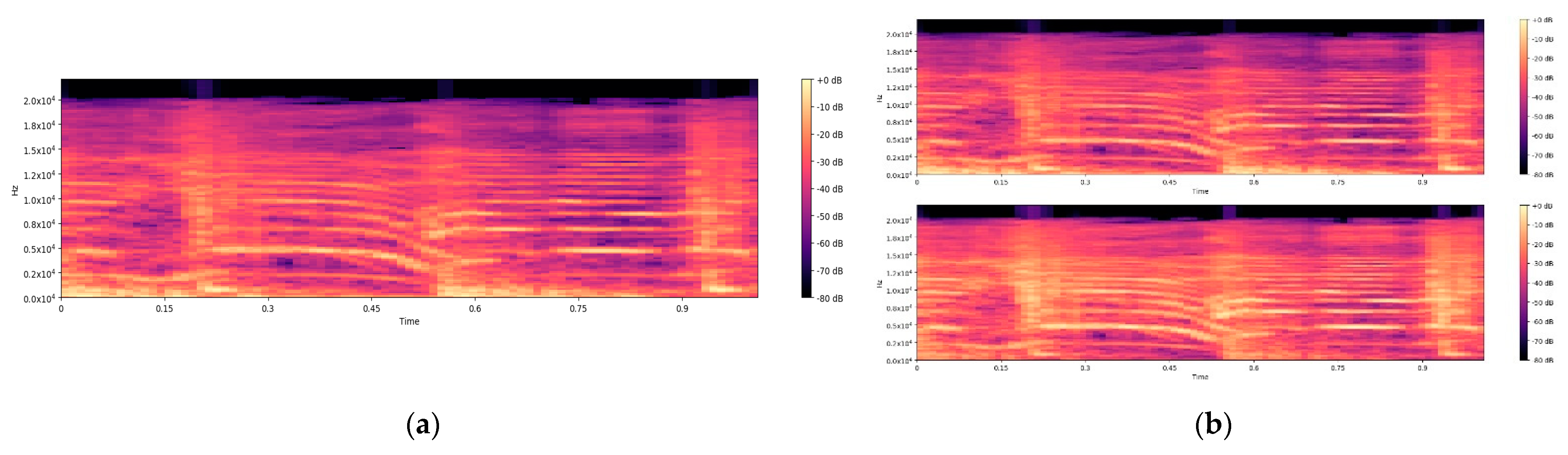
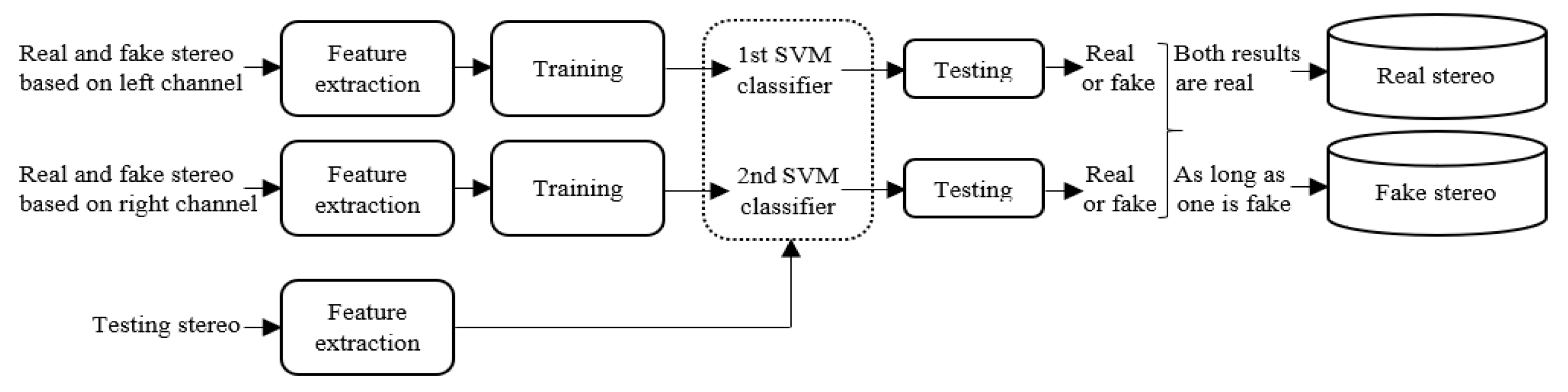
As shown in
Figure 1 and
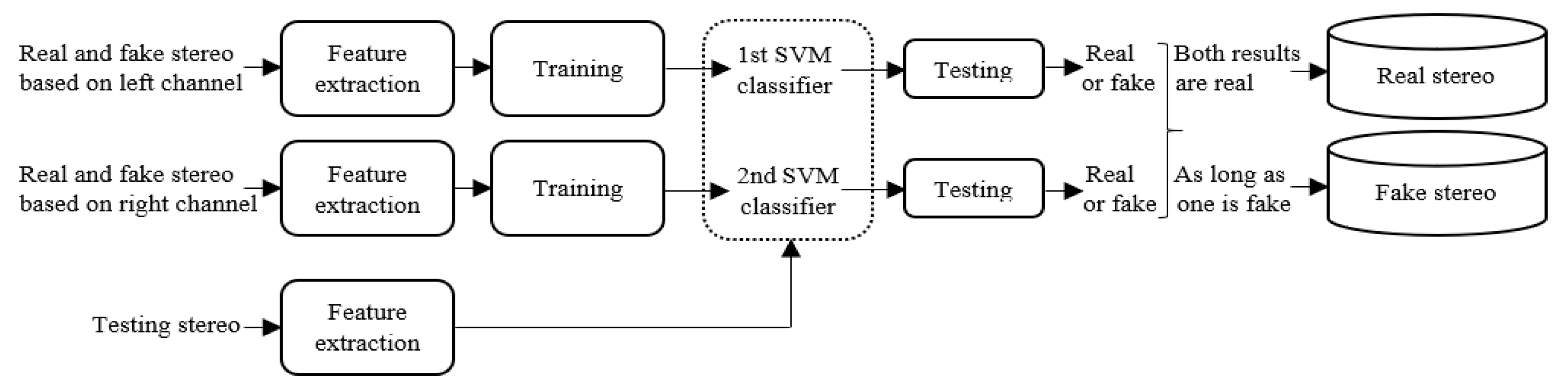
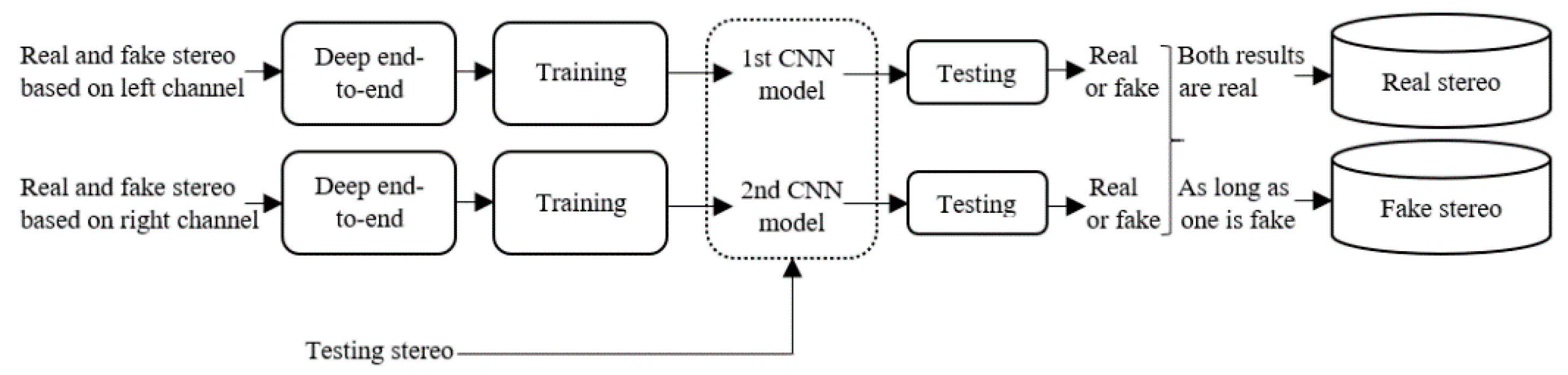
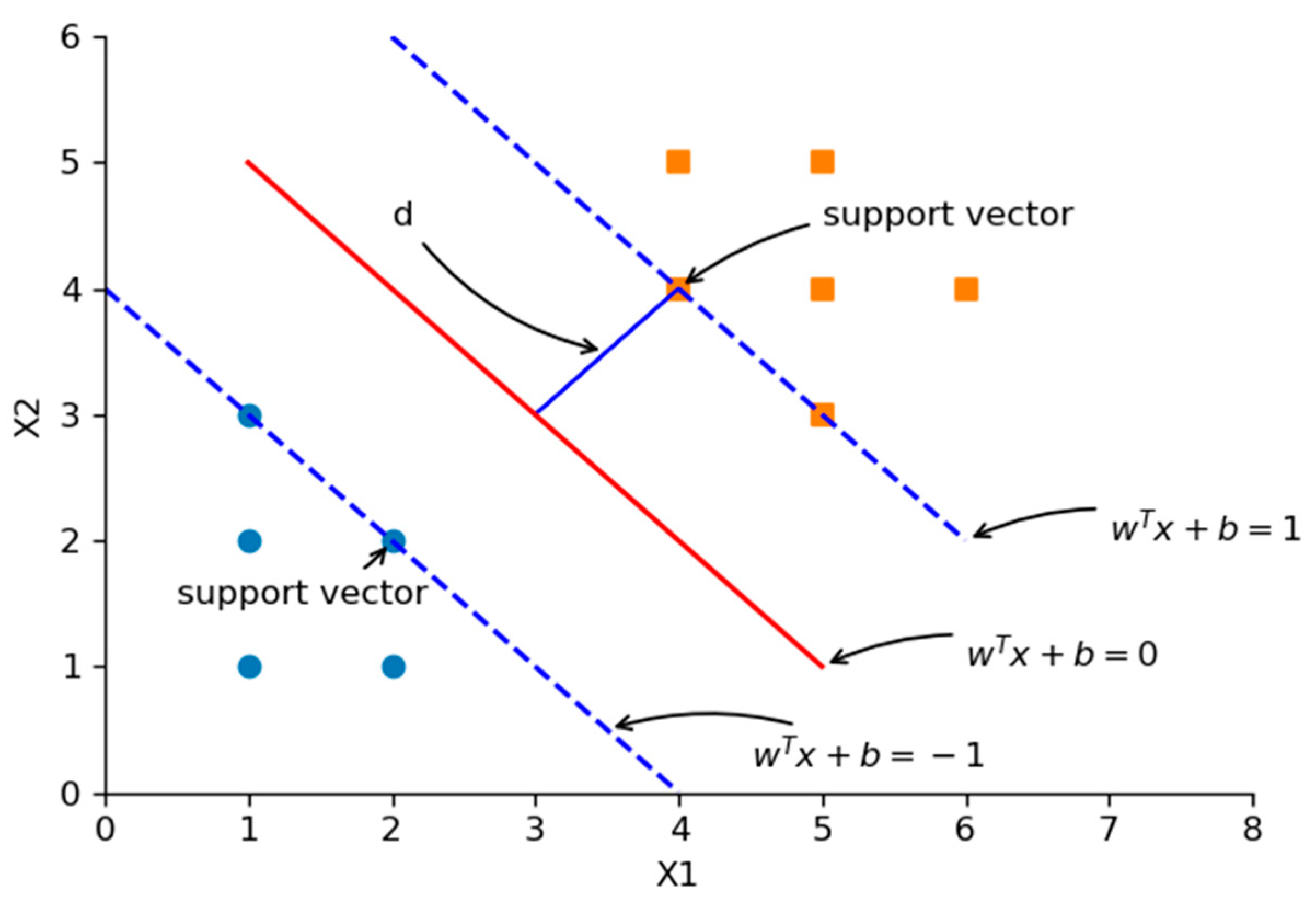
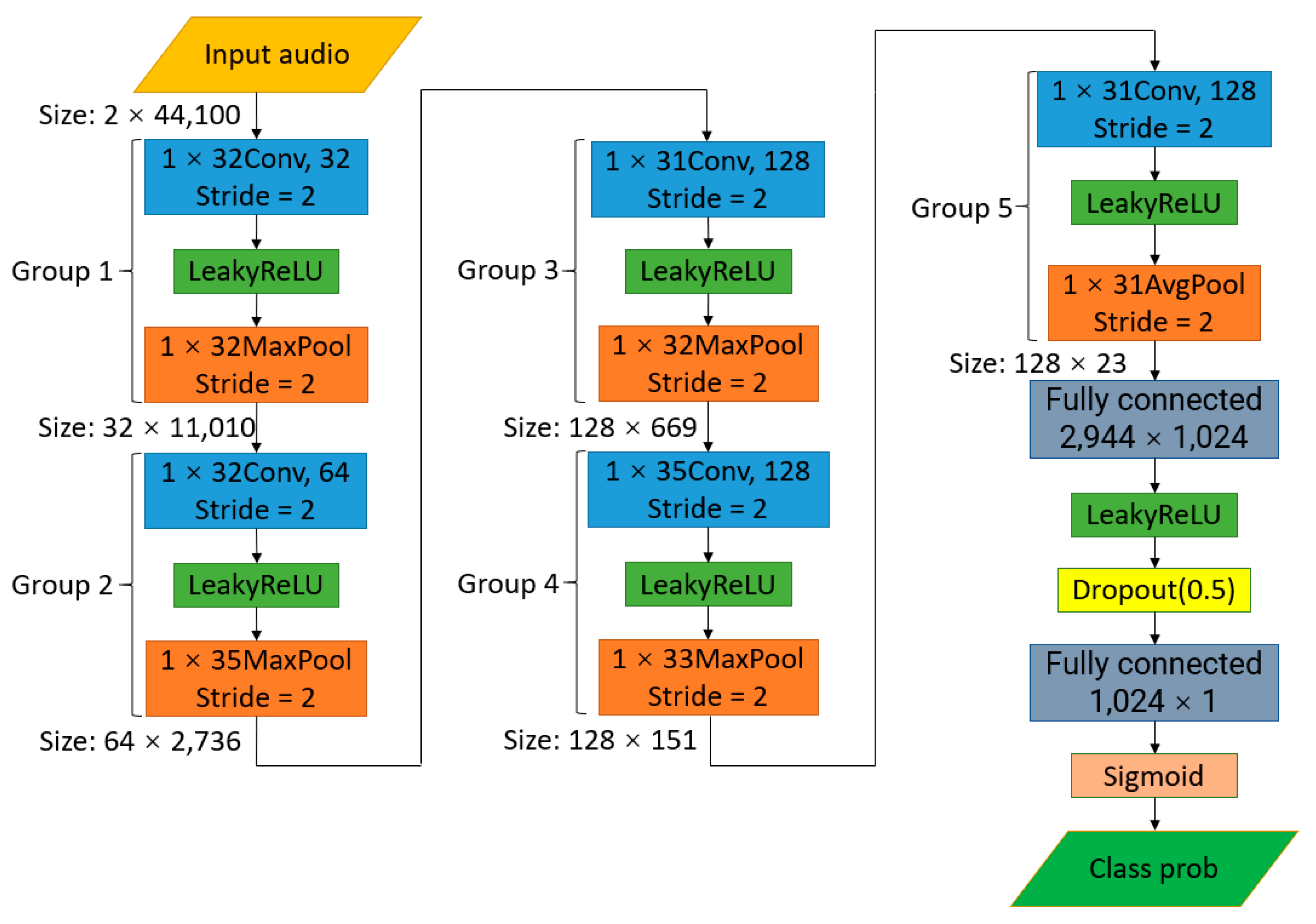
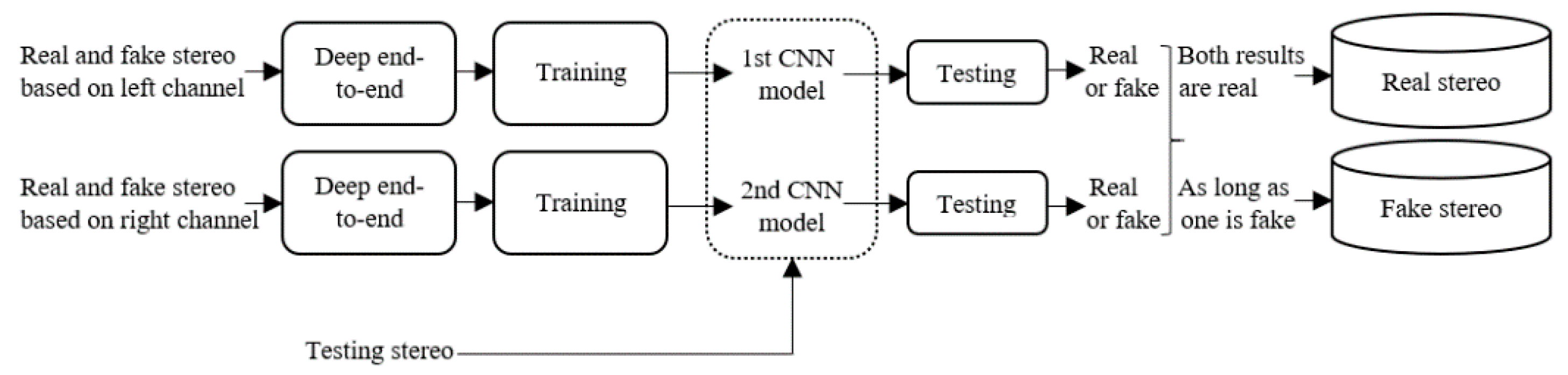
Figure 2, it is difficult to distinguish fake stereo audio from authentic stereo with a waveform or spectrogram, when the mono audio, which is the source of the fake stereo audio, is not given. However, when we listen to fake stereo audio, we can often feel a significant decline in perceived quality. Hence, it is necessary to design a detection algorithm for fake stereo audio. The detection strategy we adopt is to extract the acoustic features of each channel of stereo audio and combine and feed them to the classifier for recognition. In this work, a corpus for fake stereo audio detection is created from two real stereo datasets. Then, we propose two effective algorithms for detecting fake stereo audio: using (1) the combination of Mel-frequency cepstral coefficients (MFCCs) features and support vector machines (SVMs) (2) the combination of a five-layer convolutional neural network (CNN) and a three-layer fully connected, because SVMs and CNNs have been widely used in audio forensics, speech recognition and other acoustic fields. Wu H. et al. [
4] proposed the use of a combination of MFCC features and an SVM classifier to detect electronic disguised voices. Reis et al. [
26] used an SVM classifier for audio authentication. Lin et al. [
27] used a convolutional neural network to detect audio recapture with high accuracy. Giuseppe Ciaburro [
28] used convolutional neural networks to identify the sounds of underground garages. The purpose was to detect sounds to identify dangerous situations and activate automatic alarms to draw attention to the surveillance of the area. This method returned high accuracy in identifying car accidents in underground parking lots. Considering the information of audio sources and channels, eight various classification models are trained. The main contributions of this paper are as follows:
To our knowledge, this is the first forensic work to identify fake stereo audio in the field of fake quality forensics;
We provide a corpus for fake stereo audio detection. We have collected a large number of samples from the two most widely used fields (music and film recording) as datasets;
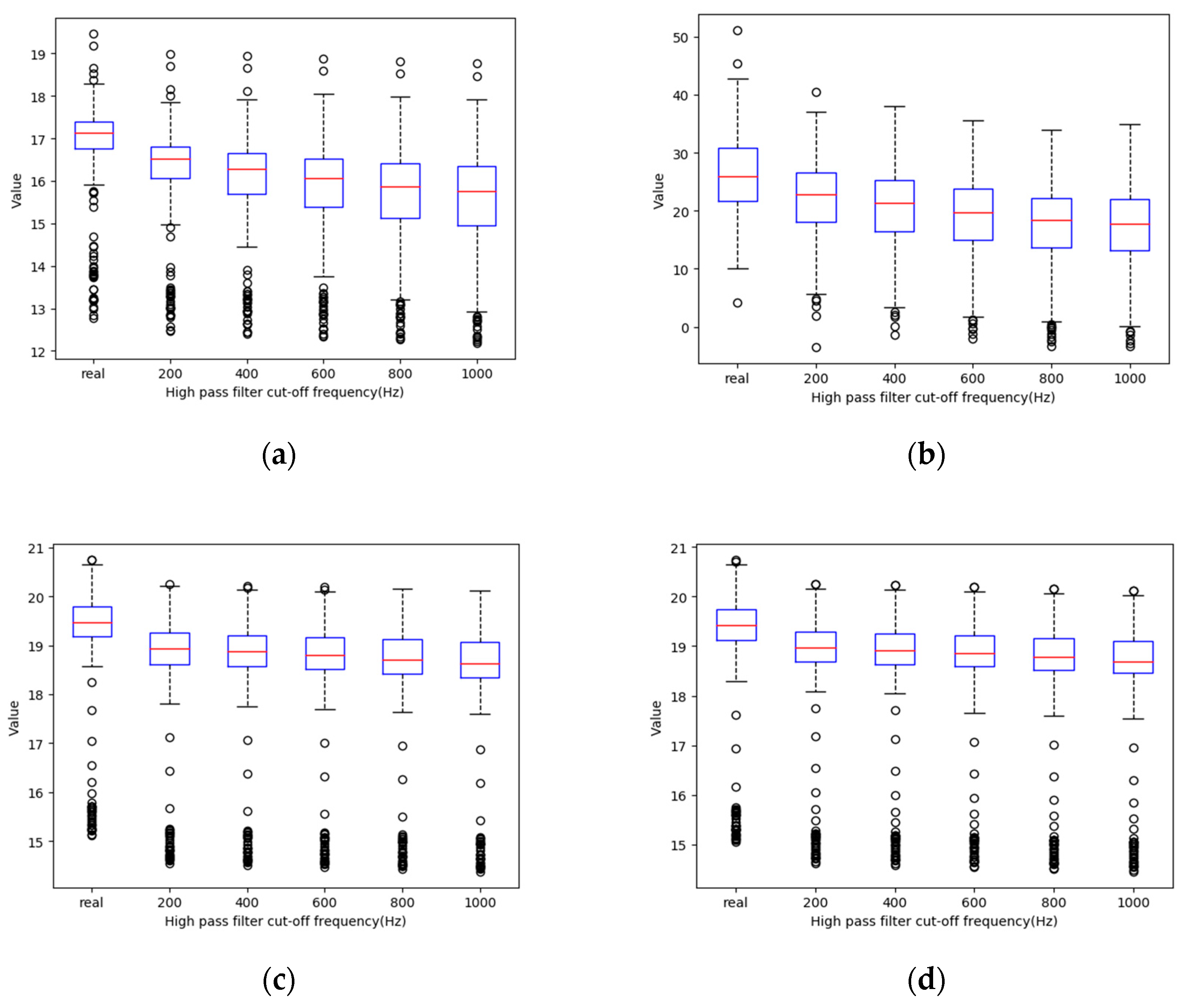
After studying the method of stereo forgery, we found that the cut-off frequency of different high-pass filters has little effect on the sound quality but can greatly affect the detection effect of the model. The detection algorithm we put forward based on this point has strong robustness, and can detect fake stereo audios with different cut-off frequencies of high-pass filters.
The rest of this paper is organized as follows. In
Section 2, the detail of the fake stereo corpus is given.
Section 3 describes an identification algorithm based on MFCC features and SVM classification.
Section 4 describes an end-to-end deep algorithm for identifying fake stereo audio. In
Section 5, we present the experimental results in various cases. Finally, the conclusions are given in
Section 6.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}