
Improving Imbalanced Land Cover Classification with K-Means SMOTE: Detecting and Oversampling Distinctive Minority Spectral Signatures



Abstract
:1. Introduction
- Improve the ability to handle high-dimensional datasets, in cases such as Multi-spectral TS composites high-dimensionality increases the complexity of the problem and creates a strain on computational power [7].
- Improve class separability, as the production of an accurate LULC map can be hindered by the existence of classes with similar spectral signatures, making these classes difficult to distinguish [8].
- Resilience to mislabelled LULC patches, as the use of photo-interpreted training data poses a threat to the quality of any LULC map produced with this strategy, since factors such as the minimum mapping unit tend to cause the overlooking of small-area LULC patches and generates noisy training data that may reduce the prediction accuracy of a classifier [9].
- Dealing with rare land cover classes, due to the varying levels of area coverage for each class. In this case using a purely random sampling strategy will amount to a dataset with a roughly proportional class distribution as the one on the multi/hyperspectral image. On the other hand, the acquisition of training datasets containing balanced class frequencies is often unfeasible. This causes an asymmetry in class distribution, where some classes are frequent in the training dataset, while others have little expression [10,11].
- Cost-sensitive solutions. Introduces a cost matrix to the learning phase with misclassification costs attributed to each class. Minority classes will have a higher cost than majority classes, forcing the algorithm to be more flexible and adapt better to predict minority classes.
- Algorithmic level solutions. Specific classifiers are modified to reinforce the learning on minority classes. Consists on the creation or adaptation of classifiers.
- Resampling solutions. Rebalances the dataset’s class distribution by removing majority class instances and/or generating artificial minority instances. This can be seen as an external approach, where the intervention occurs before the learning phase, benefitting from versatility and independency from the classifier used.
- Undersampling methods, which rebalance class distribution by removing instances from the majority classes.
- Oversampling methods, which rebalance datasets by generating new artificial instances belonging to the minority classes.
- Hybrid methods, which are a combination of both oversampling and undersampling, resulting in the removal of instances in the majority classes and the generation of artificial instances in the minority classes.
- Propose a cluster-based multiclass oversampling method appropriate for LULC classification and compare its performance with the remaining oversamplers in a multiclass context with seven benchmark LULC classification datasets. Allows us to check the oversamplers’ performance across benchmark LULC datasets.
- Introducing a cluster-based oversampling algorithm within the remote sensing domain, as well as comparing its performance with the remaining oversamplers in a multiclass context.
- Make available to the remote sensing community the implementation of the algorithm in a Python library and the experiment’s source code.
2. Imbalanced Learning Approaches
2.1. Non-Informed Resampling Methods
2.2. Heuristic Methods
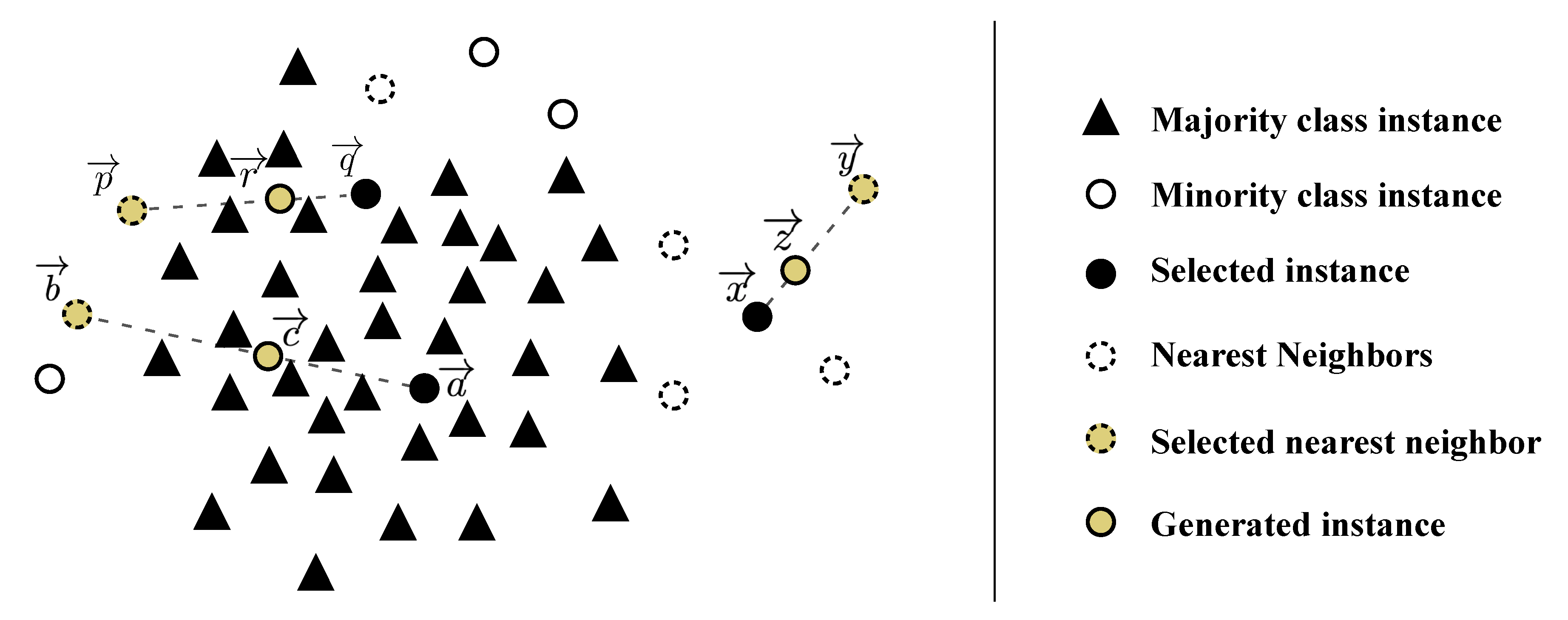
- Generation of noisy instances due to the selection of the k nearest neighbors. In the event an instance (or a small number thereof) is not noisy but is isolated from the remaining clusters, known as the “small disjuncts problem” [45], much like sample from Figure 2, the selection of any nearest neighbor of the same class will have a high likelihood of producing a noisy sample.
- Generation of nearly duplicated instances. Whenever the linear interpolation is done between two instances that are close to each other, the generated instance becomes very similar to its parents and increases the risk of overfitting. G-SMOTE [41] attempts to address both the k nearest neighbor selection mechanism problem as well as the generation of nearly duplicated instances problem.
- Generation of noisy instances due to the use of instances from two different minority class clusters. Although an increased k could potentially avoid the previous problem, it can also lead to the generation of artificial data between different minority clusters, as depicted Figure 2 with the generation of point using minority class instances and . Cluster-based oversampling methods attempt to address this problem.
3. Methodology
3.1. Datasets
- Data collection of publicly available hyperspectral scenes. The original hyperspectral scenes and ground truth data were collected from a single publicly available data repository available here (http://www.ehu.eus/ccwintco/index.php?title=Hyperspectral_Remote_Sensing_Scenes (accessed on 29 June 2021)).
- Conversion of each hyperspectral scene to a structured dataset and removal of instances with no associated LULC class. This was done to reshape the dataset from into a conventional dataframe of shape , where , h, w and b represent the ground truth, height, width and number of bands in the scene, respectively. The pixels without ground truth information were discarded from further analysis.
- Stratified random sampling to maintain similar class proportions on a sample of 10% of each dataset. This was done by computing the relative class frequencies in the original hyperspectral scene (minus the class representing no ground truth availability) and retrieving a sample that ensured the original relative class frequencies remained unchanged.
- Removal of instances belonging to a class with frequency lower than 20 or higher than 1000. This was done to maintain the datasets to a practicable size due to computational constraints, while conserving the relative LULC class frequencies and data distribution.
- Data normalization using the MinMax scaler. This ensured all features (i.e., bands) were in the same scale. In this case, the data were rescaled between 0 and 1.
3.1.1. Botswana
3.1.2. Pavia Center and University
3.1.3. Kennedy Space Center
3.1.4. Salinas and Salinas-A
3.1.5. Indian Pines
3.2. Machine Learning Algorithms
3.3. Evaluation Metrics
- The G-mean consists of the geometric mean of and Sensitivity (also known as Recall). For multiclass problems, The G-mean is expressed as:
- F-score is the harmonic mean of Precision and Recall. The F-score for the multi-class case can be calculated using their average per class values [54]:
- Overall Accuracy is the number of correctly classified instances divided by the total amount of instances. Having c as the label of the various classes, Accuracy is given by the following formula:
3.4. Experimental Procedure
3.5. Software Implementation
4. Results and Discussion
4.1. Results
4.2. Statistical Analysis
4.3. Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Classifier | Metric | NONE | ROS | SMOTE | B-SMOTE | K-SMOTE |
|---|---|---|---|---|---|---|---|
| Botswana | LR | Accuracy | 0.92 | 0.917 | 0.92 | 0.921 | 0.927 |
| Botswana | LR | F-score | 0.913 | 0.909 | 0.913 | 0.914 | 0.921 |
| Botswana | LR | G-mean | 0.952 | 0.95 | 0.952 | 0.952 | 0.956 |
| Botswana | KNN | Accuracy | 0.875 | 0.862 | 0.881 | 0.869 | 0.889 |
| Botswana | KNN | F-score | 0.859 | 0.85 | 0.873 | 0.859 | 0.879 |
| Botswana | KNN | G-mean | 0.924 | 0.918 | 0.93 | 0.923 | 0.933 |
| Botswana | RF | Accuracy | 0.873 | 0.884 | 0.877 | 0.877 | 0.890 |
| Botswana | RF | F-score | 0.865 | 0.877 | 0.872 | 0.87 | 0.883 |
| Botswana | RF | G-mean | 0.925 | 0.933 | 0.929 | 0.928 | 0.936 |
| PC | LR | Accuracy | 0.954 | 0.955 | 0.955 | 0.95 | 0.956 |
| PC | LR | F-score | 0.944 | 0.947 | 0.947 | 0.941 | 0.948 |
| PC | LR | G-mean | 0.968 | 0.972 | 0.972 | 0.966 | 0.973 |
| PC | KNN | Accuracy | 0.926 | 0.92 | 0.923 | 0.924 | 0.926 |
| PC | KNN | F-score | 0.915 | 0.909 | 0.913 | 0.913 | 0.915 |
| PC | KNN | G-mean | 0.953 | 0.955 | 0.957 | 0.954 | 0.957 |
| PC | RF | Accuracy | 0.938 | 0.941 | 0.94 | 0.938 | 0.942 |
| PC | RF | F-score | 0.928 | 0.932 | 0.931 | 0.928 | 0.933 |
| PC | RF | G-mean | 0.959 | 0.964 | 0.965 | 0.961 | 0.965 |
| KSC | LR | Accuracy | 0.904 | 0.905 | 0.905 | 0.899 | 0.909 |
| KSC | LR | F-score | 0.868 | 0.873 | 0.874 | 0.862 | 0.877 |
| KSC | LR | G-mean | 0.928 | 0.932 | 0.932 | 0.924 | 0.934 |
| KSC | KNN | Accuracy | 0.855 | 0.859 | 0.862 | 0.857 | 0.865 |
| KSC | KNN | F-score | 0.808 | 0.819 | 0.827 | 0.81 | 0.826 |
| KSC | KNN | G-mean | 0.893 | 0.901 | 0.906 | 0.895 | 0.905 |
| KSC | RF | Accuracy | 0.86 | 0.859 | 0.863 | 0.859 | 0.868 |
| KSC | RF | F-score | 0.817 | 0.815 | 0.826 | 0.816 | 0.832 |
| KSC | RF | G-mean | 0.898 | 0.899 | 0.905 | 0.898 | 0.907 |
| SA | LR | Accuracy | 0.979 | 0.981 | 0.983 | 0.979 | 0.984 |
| SA | LR | F-score | 0.976 | 0.979 | 0.982 | 0.977 | 0.982 |
| SA | LR | G-mean | 0.985 | 0.988 | 0.990 | 0.987 | 0.989 |
| SA | KNN | Accuracy | 0.987 | 0.979 | 0.982 | 0.983 | 0.988 |
| SA | KNN | F-score | 0.986 | 0.979 | 0.981 | 0.982 | 0.987 |
| SA | KNN | G-mean | 0.992 | 0.989 | 0.99 | 0.991 | 0.993 |
| SA | RF | Accuracy | 0.98 | 0.983 | 0.984 | 0.979 | 0.985 |
| SA | RF | F-score | 0.979 | 0.982 | 0.983 | 0.978 | 0.984 |
| SA | RF | G-mean | 0.987 | 0.988 | 0.989 | 0.986 | 0.990 |
| PU | LR | Accuracy | 0.905 | 0.897 | 0.897 | 0.891 | 0.904 |
| PU | LR | F-score | 0.89 | 0.894 | 0.894 | 0.888 | 0.898 |
| PU | LR | G-mean | 0.932 | 0.947 | 0.947 | 0.942 | 0.949 |
| PU | KNN | Accuracy | 0.895 | 0.867 | 0.865 | 0.873 | 0.895 |
| PU | KNN | F-score | 0.891 | 0.868 | 0.868 | 0.874 | 0.891 |
| PU | KNN | G-mean | 0.94 | 0.935 | 0.936 | 0.936 | 0.941 |
| PU | RF | Accuracy | 0.912 | 0.908 | 0.907 | 0.908 | 0.911 |
| PU | RF | F-score | 0.909 | 0.906 | 0.906 | 0.908 | 0.909 |
| PU | RF | G-mean | 0.946 | 0.946 | 0.948 | 0.948 | 0.949 |
| Salinas | LR | Accuracy | 0.990 | 0.990 | 0.989 | 0.990 | 0.990 |
| Salinas | LR | F-score | 0.985 | 0.986 | 0.985 | 0.985 | 0.986 |
| Salinas | LR | G-mean | 0.992 | 0.993 | 0.992 | 0.992 | 0.993 |
| Salinas | KNN | Accuracy | 0.970 | 0.967 | 0.969 | 0.967 | 0.970 |
| Salinas | KNN | F-score | 0.959 | 0.957 | 0.960 | 0.957 | 0.960 |
| Salinas | KNN | G-mean | 0.977 | 0.978 | 0.981 | 0.976 | 0.981 |
| Salinas | RF | Accuracy | 0.984 | 0.983 | 0.983 | 0.983 | 0.985 |
| Salinas | RF | F-score | 0.979 | 0.979 | 0.977 | 0.978 | 0.980 |
| Salinas | RF | G-mean | 0.989 | 0.989 | 0.989 | 0.989 | 0.990 |
| IP | LR | Accuracy | 0.687 | 0.681 | 0.68 | 0.678 | 0.692 |
| IP | LR | F-score | 0.662 | 0.663 | 0.659 | 0.659 | 0.674 |
| IP | LR | G-mean | 0.798 | 0.801 | 0.798 | 0.797 | 0.807 |
| IP | KNN | Accuracy | 0.644 | 0.602 | 0.589 | 0.557 | 0.632 |
| IP | KNN | F-score | 0.593 | 0.591 | 0.603 | 0.56 | 0.604 |
| IP | KNN | G-mean | 0.757 | 0.764 | 0.782 | 0.751 | 0.781 |
| IP | RF | Accuracy | 0.742 | 0.747 | 0.747 | 0.74 | 0.752 |
| IP | RF | F-score | 0.673 | 0.704 | 0.713 | 0.701 | 0.714 |
| IP | RF | G-mean | 0.806 | 0.826 | 0.835 | 0.831 | 0.838 |
References
- Drusch, M.; Del Bello, U.; Carlier, S.; Colin, O.; Fernandez, V.; Gascon, F.; Hoersch, B.; Isola, C.; Laberinti, P.; Martimort, P.; et al. Sentinel-2: ESA’s Optical High-Resolution Mission for GMES Operational Services. Remote Sens. Environ. 2012, 120, 25–36. [Google Scholar] [CrossRef]
- Fritz, S.; See, L.; Perger, C.; McCallum, I.; Schill, C.; Schepaschenko, D.; Duerauer, M.; Karner, M.; Dresel, C.; Laso-Bayas, J.C.; et al. A global dataset of crowdsourced land cover and land use reference data. Sci. Data 2017, 4, 1–8. [Google Scholar] [CrossRef] [Green Version]
- Khatami, R.; Mountrakis, G.; Stehman, S.V. A meta-analysis of remote sensing research on supervised pixel-based land-cover image classification processes: General guidelines for practitioners and future research. Remote Sens. Environ. 2016, 177, 89–100. [Google Scholar] [CrossRef] [Green Version]
- Wulder, M.A.; Coops, N.C.; Roy, D.P.; White, J.C.; Hermosilla, T. Land cover 2.0. Int. J. Remote Sens. 2018, 39, 4254–4284. [Google Scholar] [CrossRef] [Green Version]
- Gavade, A.B.; Rajpurohit, V.S. Systematic analysis of satellite image-based land cover classification techniques: Literature review and challenges. Int. J. Comput. Appl. 2019, 1–10. [Google Scholar] [CrossRef]
- Kaur, H.; Pannu, H.S.; Malhi, A.K. A Systematic Review on Imbalanced Data Challenges in Machine Learning: Applications and Solutions. ACM Comput. Surv. 2019, 52. [Google Scholar] [CrossRef] [Green Version]
- Stromann, O.; Nascetti, A.; Yousif, O.; Ban, Y. Dimensionality Reduction and Feature Selection for Object-Based Land Cover Classification based on Sentinel-1 and Sentinel-2 Time Series Using Google Earth Engine. Remote Sens. 2020, 12, 76. [Google Scholar] [CrossRef] [Green Version]
- Alonso-Sarria, F.; Valdivieso-Ros, C.; Gomariz-Castillo, F. Isolation Forests to Evaluate Class Separability and the Representativeness of Training and Validation Areas in Land Cover Classification. Remote Sens. 2019, 11, 3000. [Google Scholar] [CrossRef] [Green Version]
- Pelletier, C.; Valero, S.; Inglada, J.; Champion, N.; Marais Sicre, C.; Dedieu, G. Effect of Training Class Label Noise on Classification Performances for Land Cover Mapping with Satellite Image Time Series. Remote Sens. 2017, 9, 173. [Google Scholar] [CrossRef] [Green Version]
- Wang, R.; Zhang, J.; Chen, J.W.; Jiao, L.; Wang, M. Imbalanced Learning-based Automatic SAR Images Change Detection by Morphologically Supervised PCA-Net. IEEE Geosci. Remote Sens. Lett. 2019, 16, 554–558. [Google Scholar] [CrossRef] [Green Version]
- Feng, W.; Huang, W.; Bao, W. Imbalanced Hyperspectral Image Classification with an Adaptive Ensemble Method Based on SMOTE and Rotation Forest with Differentiated Sampling Rates. IEEE Geosci. Remote Sens. Lett. 2019, 1–5. [Google Scholar] [CrossRef]
- Chawla, N.V.; Japkowicz, N.; Kotcz, A. Editorial: Special issue on learning from imbalanced data sets. ACM SIGKDD Explor. Newsl. 2004, 6, 1. [Google Scholar] [CrossRef]
- Abdi, L.; Hashemi, S. To Combat Multi-Class Imbalanced Problems by Means of Over-Sampling Techniques. IEEE Trans. Knowl. Data Eng. 2016, 28, 238–251. [Google Scholar] [CrossRef]
- Maxwell, A.E.; Warner, T.A.; Fang, F. Implementation of machine-learning classification in remote sensing: An applied review. Int. J. Remote Sens. 2018, 39, 2784–2817. [Google Scholar] [CrossRef] [Green Version]
- Fernández, A.; López, V.; Galar, M.; del Jesus, M.J.; Herrera, F. Analysing the classification of imbalanced data-sets with multiple classes: Binarization techniques and ad-hoc approaches. Knowl. Based Syst. 2013, 42, 97–110. [Google Scholar] [CrossRef]
- Luengo, J.; García-Gil, D.; Ramírez-Gallego, S.; García, S.; Herrera, F. Imbalanced Data Preprocessing for Big Data. In Big Data Preprocessing; Springer International Publishing: Cham, Switzerland, 2020; pp. 147–160. [Google Scholar] [CrossRef]
- García, S.; Ramírez-Gallego, S.; Luengo, J.; Benítez, J.M.; Herrera, F. Big data preprocessing: Methods and prospects. Big Data Anal. 2016, 1, 9. [Google Scholar] [CrossRef] [Green Version]
- Haixiang, G.; Yijing, L.; Shang, J.; Mingyun, G.; Yuanyue, H.; Bing, G. Learning from Class-Imbalanced Data. Expert Syst. Appl. 2017, 73, 220–239. [Google Scholar] [CrossRef]
- Douzas, G.; Bacao, F.; Fonseca, J.; Khudinyan, M. Imbalanced learning in land cover classification: Improving minority classes’ prediction accuracy using the geometric SMOTE algorithm. Remote Sens. 2019, 11, 3040. [Google Scholar] [CrossRef] [Green Version]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic Minority Over-sampling Technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Douzas, G.; Bacao, F.; Last, F. Improving imbalanced learning through a heuristic oversampling method based on k-means and SMOTE. Inf. Sci. 2018, 465, 1–20. [Google Scholar] [CrossRef] [Green Version]
- Japkowicz, N. Concept-learning in the presence of between-class and within-class imbalances. In Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2001; Volume 2056, pp. 67–77. [Google Scholar] [CrossRef]
- Jo, T.; Japkowicz, N. Class imbalances versus small disjuncts. ACM SIGKDD Explor. Newsl. 2004, 6, 40–49. [Google Scholar] [CrossRef]
- Han, H.; Wang, W.Y.; Mao, B.H. Borderline-SMOTE: A New Over-Sampling Method in Imbalanced Data Sets Learning. In International Conference on Intelligent Computing; Springer: Berlin/Heidelberg, Germany, 2005; pp. 878–887. [Google Scholar] [CrossRef]
- Blagus, R.; Lusa, L. Class prediction for high-dimensional class-imbalanced data. BMC Bioinform. 2010, 11, 523. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Mellor, A.; Boukir, S.; Haywood, A.; Jones, S. Exploring issues of training data imbalance and mislabelling on random forest performance for large area land cover classification using the ensemble margin. ISPRS J. Photogramm. Remote Sens. 2015, 105, 155–168. [Google Scholar] [CrossRef]
- Shao, Y.H.; Chen, W.J.; Zhang, J.J.; Wang, Z.; Deng, N.Y. An efficient weighted Lagrangian twin support vector machine for imbalanced data classification. Pattern Recognit. 2014, 47, 3158–3167. [Google Scholar] [CrossRef]
- Lee, T.; Lee, K.B.; Kim, C.O. Performance of Machine Learning Algorithms for Class-Imbalanced Process Fault Detection Problems. IEEE Trans. Semicond. Manuf. 2016, 29, 436–445. [Google Scholar] [CrossRef]
- Huang, C.; Li, Y.; Loy, C.C.; Tang, X. Learning deep representation for imbalanced classification. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 5375–5384. [Google Scholar] [CrossRef]
- Cui, Y.; Jia, M.; Lin, T.Y.; Song, Y.; Belongie, S. Class-balanced loss based on effective number of samples. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 9260–9269. [Google Scholar] [CrossRef] [Green Version]
- Dong, Q.; Gong, S.; Zhu, X. Class Rectification Hard Mining for Imbalanced Deep Learning. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1869–1878. [Google Scholar] [CrossRef] [Green Version]
- Sharififar, A.; Sarmadian, F.; Minasny, B. Mapping imbalanced soil classes using Markov chain random fields models treated with data resampling technique. Comput. Electron. Agric. 2019, 159, 110–118. [Google Scholar] [CrossRef]
- Hounkpatin, K.O.; Schmidt, K.; Stumpf, F.; Forkuor, G.; Behrens, T.; Scholten, T.; Amelung, W.; Welp, G. Predicting reference soil groups using legacy data: A data pruning and Random Forest approach for tropical environment (Dano catchment, Burkina Faso). Sci. Rep. 2018, 8, 1–16. [Google Scholar] [CrossRef] [PubMed]
- Krawczyk, B. Learning from imbalanced data: Open challenges and future directions. Prog. Artif. Intell. 2016, 5, 221–232. [Google Scholar] [CrossRef] [Green Version]
- Ferreira, M.P.; Wagner, F.H.; Aragão, L.E.; Shimabukuro, Y.E.; de Souza Filho, C.R. Tree species classification in tropical forests using visible to shortwave infrared WorldView-3 images and texture analysis. ISPRS J. Photogramm. Remote Sens. 2019, 149, 119–131. [Google Scholar] [CrossRef]
- Feng, W.; Huang, W.; Ye, H.; Zhao, L. Synthetic minority over-sampling technique based rotation forest for the classification of unbalanced hyperspectral data. In Proceedings of the International Geoscience and Remote Sensing Symposium (IGARSS), Valencia, Spain, 22–27 July 2018; pp. 2651–2654. [Google Scholar] [CrossRef]
- Jozdani, S.E.; Johnson, B.A.; Chen, D. Comparing Deep Neural Networks, Ensemble Classifiers, and Support Vector Machine Algorithms for Object-Based Urban Land Use/Land Cover Classification. Remote Sens. 2019, 11, 1713. [Google Scholar] [CrossRef] [Green Version]
- Bogner, C.; Seo, B.; Rohner, D.; Reineking, B. Classification of rare land cover types: Distinguishing annual and perennial crops in an agricultural catchment in South Korea. PLoS ONE 2018, 13. [Google Scholar] [CrossRef] [Green Version]
- Zhu, M.; Wu, B.; He, Y.N.; He, Y.Q. Land Cover Classification Using High Resolution Satellite Image Based On Deep Learning. ISPRS Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2020, XLII-3/W10, 685–690. [Google Scholar] [CrossRef] [Green Version]
- Cenggoro, T.W.; Isa, S.M.; Kusuma, G.P.; Pardamean, B. Classification of imbalanced land-use/land-cover data using variational semi-supervised learning. In Proceedings of the 2017 International Conference on Innovative and Creative Information Technology: Computational Intelligence and IoT, ICITech 2017, Salatiga, Indonesia, 2–4 November 2018; pp. 1–6. [Google Scholar] [CrossRef]
- Douzas, G.; Bacao, F. Geometric SMOTE a geometrically enhanced drop-in replacement for SMOTE. Inf. Sci. 2019, 501, 118–135. [Google Scholar] [CrossRef]
- Ma, L.; Fan, S. CURE-SMOTE algorithm and hybrid algorithm for feature selection and parameter optimization based on random forests. BMC Bioinform. 2017, 18, 169. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Douzas, G.; Bacao, F. Self-Organizing Map Oversampling (SOMO) for imbalanced data set learning. Expert Syst. Appl. 2017, 82, 40–52. [Google Scholar] [CrossRef]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008; pp. 1322–1328. [Google Scholar] [CrossRef] [Green Version]
- Holte, R.C.; Acker, L.; Porter, B.W. Concept Learning and the Problem of Small Disjuncts. IJCAI 1989, 89, 813–818. [Google Scholar]
- Santos, M.S.; Abreu, P.H.; García-Laencina, P.J.; Simão, A.; Carvalho, A. A new cluster-based oversampling method for improving survival prediction of hepatocellular carcinoma patients. J. Biomed. Inform. 2015, 58, 49–59. [Google Scholar] [CrossRef] [Green Version]
- Baumgardner, M.F.; Biehl, L.L.; Landgrebe, D.A. 220 Band AVIRIS Hyperspectral Image Data Set: June 12, 1992 Indian Pine Test Site 3. Purdue Univ. Res. Repos. 2015. [Google Scholar] [CrossRef]
- Nelder, J.A.; Wedderburn, R.W. Generalized linear models. J. R. Stat. Soc. Ser. A 1972, 135, 370–384. [Google Scholar] [CrossRef]
- Cover, T.; Hart, P. Nearest neighbor pattern classification. IEEE Trans. Inf. Theory 1967, 13, 21–27. [Google Scholar] [CrossRef]
- Liaw, A.; Wiener, M. Classification and regression by randomForest. R News 2002, 2, 18–22. [Google Scholar]
- Olofsson, P.; Foody, G.M.; Stehman, S.V.; Woodcock, C.E. Making better use of accuracy data in land change studies: Estimating accuracy and area and quantifying uncertainty using stratified estimation. Remote Sens. Environ. 2013, 129, 122–131. [Google Scholar] [CrossRef]
- Pontius, R.G.; Millones, M. Death to Kappa: Birth of quantity disagreement and allocation disagreement for accuracy assessment. Int. J. Remote Sens. 2011. [Google Scholar] [CrossRef]
- Jeni, L.A.; Cohn, J.F.; De La Torre, F. Facing imbalanced data—Recommendations for the use of performance metrics. In Proceedings of the 2013 Humaine Association Conference on Affective Computing and Intelligent Interaction, ACII 2013, Geneva, Switzerland, 2–5 September 2013; pp. 245–251. [Google Scholar] [CrossRef] [Green Version]
- He, H.; Garcia, E.A. Learning from Imbalanced Data. IEEE Trans. Knowl. Data Eng. 2009, 21, 1263–1284. [Google Scholar] [CrossRef]
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Lemaître, G.; Nogueira, F.; Aridas, C.K. Imbalanced-learn: A Python Toolbox to Tackle the Curse of Imbalanced Datasets in Machine Learning. J. Mach. Learn. Res. 2017, 18, 1–5. [Google Scholar]
- Demšar, J. Statistical comparisons of classifiers over multiple data sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]
- Friedman, M. The use of ranks to avoid the assumption of normality implicit in the analysis of variance. J. Am. Stat. Assoc. 1937, 32, 675–701. [Google Scholar] [CrossRef]
- Wilcoxon, F. Individual comparisons by ranking methods. In Breakthroughs in Statistics; Springer: Berlin/Heidelberg, Germany, 1992; pp. 196–202. [Google Scholar]






| Dataset | Features | Instances | Min. Instances | Maj. Instances | IR | Classes |
|---|---|---|---|---|---|---|
| Botswana | 145 | 288 | 20 | 41 | 2.05 | 11 |
| Pavia Centre | 102 | 3898 | 278 | 879 | 3.16 | 7 |
| Kennedy Space Center | 176 | 497 | 23 | 80 | 3.48 | 11 |
| Salinas A | 224 | 535 | 37 | 166 | 4.49 | 6 |
| Pavia University | 103 | 2392 | 89 | 679 | 7.63 | 8 |
| Salinas | 224 | 4236 | 91 | 719 | 7.9 | 15 |
| Indian Pines | 220 | 984 | 21 | 236 | 11.24 | 11 |
| Classifier | Hyperparameters | Values |
|---|---|---|
| LR | maximum iterations | 10,000 |
| KNN | # neighbors | 3, 5, 8 |
| RF | maximum depth | None, 3, 6 |
| # estimators | 50, 100, 200 | |
| Oversampler | ||
| K-means SMOTE | # neighbors | 3, 5 |
| # clusters (as % of number of instances) | 1 *, 0.1, 0.3, 0.5, 0.7, 0.9 | |
| Exponent of mean distance | auto, 2, 5, 7 | |
| IR threshold | auto, 0.5, 0.75, 1.0 | |
| SMOTE | # neighbors | 3, 5 |
| BORDERLINE SMOTE | # neighbors | 3, 5 |
| Classifier | Metric | NONE | ROS | SMOTE | B-SMOTE | K-SMOTE |
|---|---|---|---|---|---|---|
| LR | Accuracy | 0.906 ± 0.039 | 0.904 ± 0.04 | 0.904 ± 0.04 | 0.901 ± 0.04 | 0.909 ± 0.038 |
| LR | F-score | 0.891 ± 0.041 | 0.893 ± 0.042 | 0.893 ± 0.042 | 0.890 ± 0.042 | 0.898 ± 0.04 |
| LR | G-mean | 0.936 ± 0.025 | 0.940 ± 0.025 | 0.940 ± 0.025 | 0.937 ± 0.025 | 0.943 ± 0.024 |
| KNN | Accuracy | 0.879 ± 0.043 | 0.865 ± 0.048 | 0.867 ± 0.05 | 0.862 ± 0.054 | 0.881 ± 0.045 |
| KNN | F-score | 0.859 ± 0.05 | 0.853 ± 0.049 | 0.861 ± 0.047 | 0.851 ± 0.053 | 0.866 ± 0.048 |
| KNN | G-mean | 0.919 ± 0.03 | 0.920 ± 0.029 | 0.926 ± 0.027 | 0.918 ± 0.03 | 0.927 ± 0.027 |
| RF | Accuracy | 0.898 ± 0.032 | 0.901 ± 0.031 | 0.900 ± 0.031 | 0.898 ± 0.032 | 0.905 ± 0.031 |
| RF | F-score | 0.879 ± 0.041 | 0.885 ± 0.037 | 0.887 ± 0.036 | 0.883 ± 0.037 | 0.891 ± 0.036 |
| RF | G-mean | 0.930 ± 0.024 | 0.935 ± 0.022 | 0.937 ± 0.021 | 0.935 ± 0.021 | 0.939 ± 0.02 |
| Classifier | Metric | p-Value | Significance |
|---|---|---|---|
| LR | Accuracy | 9.80 × 10−3 | TRUE |
| LR | F-score | 2.30 × 10−3 | TRUE |
| LR | G-mean | 9.80 × 10−4 | TRUE |
| KNN | Accuracy | 4.30 × 10−3 | TRUE |
| KNN | F-score | 4.30 × 10−3 | TRUE |
| KNN | G-mean | 3.00 × 10−3 | TRUE |
| RF | Accuracy | 5.50 × 10−3 | TRUE |
| RF | F-score | 2.90 × 10−3 | TRUE |
| RF | G-mean | 1.80 × 10−4 | TRUE |
| Dataset | NONE | ROS | SMOTE | B-SMOTE |
|---|---|---|---|---|
| Botswana | 3.1 × 102 | 3.9 × 103 | 3.9 × 103 | 3.9 × 103 |
| Pavia Centre | 3.1 × 102 | 3.9 × 103 | 1.2 × 102 | 3.9 × 103 |
| Kennedy Space Center | 3.1 × 102 | 3.9 × 103 | 2.7 × 102 | 3.9 × 103 |
| Salinas A | 3.1 × 102 | 3.9 × 103 | 1.2 × 102 | 3.9 × 103 |
| Pavia University | 3.1 × 102 | 3.9 × 103 | 3.9 × 103 | 3.9 × 103 |
| Salinas | 3.1 × 102 | 5.50 × 102 | 2.7 × 102 | 3.9 × 103 |
| Indian Pines | 3.1 × 102 | 3.9 × 103 | 7.8 × 103 | 3.9 × 103 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Fonseca, J.; Douzas, G.; Bacao, F. Improving Imbalanced Land Cover Classification with K-Means SMOTE: Detecting and Oversampling Distinctive Minority Spectral Signatures. Information 2021, 12, 266. https://doi.org/10.3390/info12070266
Fonseca J, Douzas G, Bacao F. Improving Imbalanced Land Cover Classification with K-Means SMOTE: Detecting and Oversampling Distinctive Minority Spectral Signatures. Information. 2021; 12(7):266. https://doi.org/10.3390/info12070266
Chicago/Turabian StyleFonseca, Joao, Georgios Douzas, and Fernando Bacao. 2021. "Improving Imbalanced Land Cover Classification with K-Means SMOTE: Detecting and Oversampling Distinctive Minority Spectral Signatures" Information 12, no. 7: 266. https://doi.org/10.3390/info12070266
APA StyleFonseca, J., Douzas, G., & Bacao, F. (2021). Improving Imbalanced Land Cover Classification with K-Means SMOTE: Detecting and Oversampling Distinctive Minority Spectral Signatures. Information, 12(7), 266. https://doi.org/10.3390/info12070266