Change detection (CD) in remote sensing images is essentially the detection of change information of the ground’s surface at different time phases [
1]. The models of CD based on full supervision and semi-supervision [
2,
3,
4] are used in many fields, such as urban planning, land use, coverage, vegetation change, disaster monitoring, map updating, and ecological environment protection. Along with the continuous development and upgrading of remote sensing satellite technology, researchers can obtain high-resolution remote sensing data. Compared with synthetic aperture radar (SAR) images, high-resolution remote sensing images have greater and richer semantic information. Therefore, high-resolution remote sensing images have emerged as an essential statistics supply in the challenging task of CD. Researchers designed networks to extract change maps with abundant information from high-resolution remote sensing images.
A core step of remote sensing image CD is the construction and analysis of difference maps. In traditional networks, the methods of CD are divided into pixel level and object level [
5]. The pixel-based methods use pixels as the basis of analysis. The difference maps of multi-temporal remote sensing images are usually obtained by directly comparing corresponding pixel values. However, pixel-level CD methods [
6,
7] only use the feature information of a single pixel, ignoring the spatial and spectral information of neighboring pixels, which easily leads to “salt and pepper” noise and incomplete expression in the change region. The object-level CD methods synthesize the spatial and spectral characteristics around the pixel, combine the homogeneous pixels to form the object, and then compare the features of spectral, shape, texture, and spatial context neighborhood based on the object [
8,
9,
10]. However, these methods not only have high complexity in feature extraction but also have poor robustness in capturing images.
Deep learning can automatically, and at multiple levels, extract abstract features of complex objects that have been shown to be an effective means of feature learning. In 2012, deep learning methods won first place in the ImageNet Challenge. Since then, CD research based on deep learning has been developing. Models with fully convolutional network (FCN) [
11] structures are widely used in remote sensing CD tasks [
12,
13] to extract better features in pictures. U-Net [
14] has achieved certain results in CD. Subsequently, Siamese networks have been used and have become a popular and even standard CD method in this field [
15,
16,
17]. With the continuous innovation of the three networks mentioned above in this field of CD, the CD model is constantly optimized and improved. For example, based on deep belief networking, Gong et al. [
18] proposed a creative method of SAR image CD in 2015. In this method, the neural network is trained to generate CD difference maps directly from two images. The process of generating difference maps is omitted to avoid the influence of rough difference maps on CD results. Wang et al. [
19] proposed an end-to-end network to deal with high-dimensional problems, which can extract rich information from hyperspectral images. In 2018, the proposed CDNet [
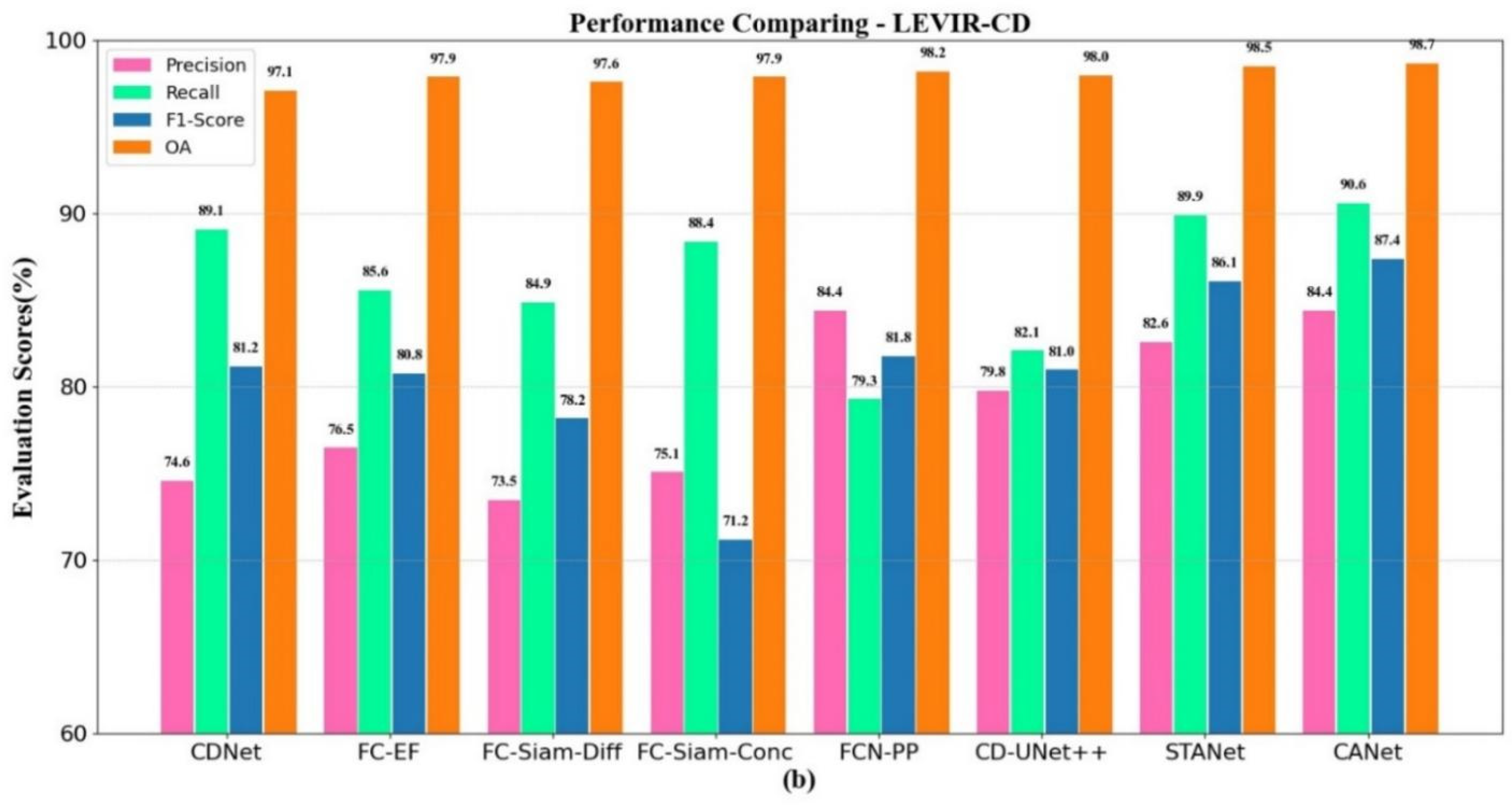
12] combined SLAM based on multi-sensor fusion and fast density 3D reconstruction to roughly register image pairs, and then used deep learning methods for pixel-wise CD in street scenes. FC-EF [
15] proposes three fully convolutional structures for the CD of registered image pairs. This method uses jump joins to supplement local refinements of spatial details, resulting in accurate boundary change maps that can detect RGB and multispectral images. FC-Siam-diff [
15] and FC-Siam-conc [
15] are derived from the FC-EF model. FCN-PP [
20], an FCN with pyramid pooling, has been proposed for landslide detection. It consists of a U-shaped structure for learning the deep-level features of input images and a pyramid pooling layer for expanding the receptive field. In addition, pyramid pooling can overcome the shortcomings of global pooling. STANet [
16] added BAM and PAM attention modules based on the Siamese network to make the CD network have suitable results. CD-UNet++ [
21] proposed an end-to-end CNN structure for the CD of high-resolution satellite images and proposed a new UNet++ model, which can achieve deep supervision and capture subtle changes in complex changed scenes. In their method, deep supervision enhances the characterization and identification performance of shallow features. DASNet [
17] used an attention mechanism to extract features and obtain better feature representation. In 2021, NestNet [
22] proposed an effective remote sensing CD method based on UNet++ [
23]. The model can automatically extract features from input images and perform feature fusion on two images from different periods.
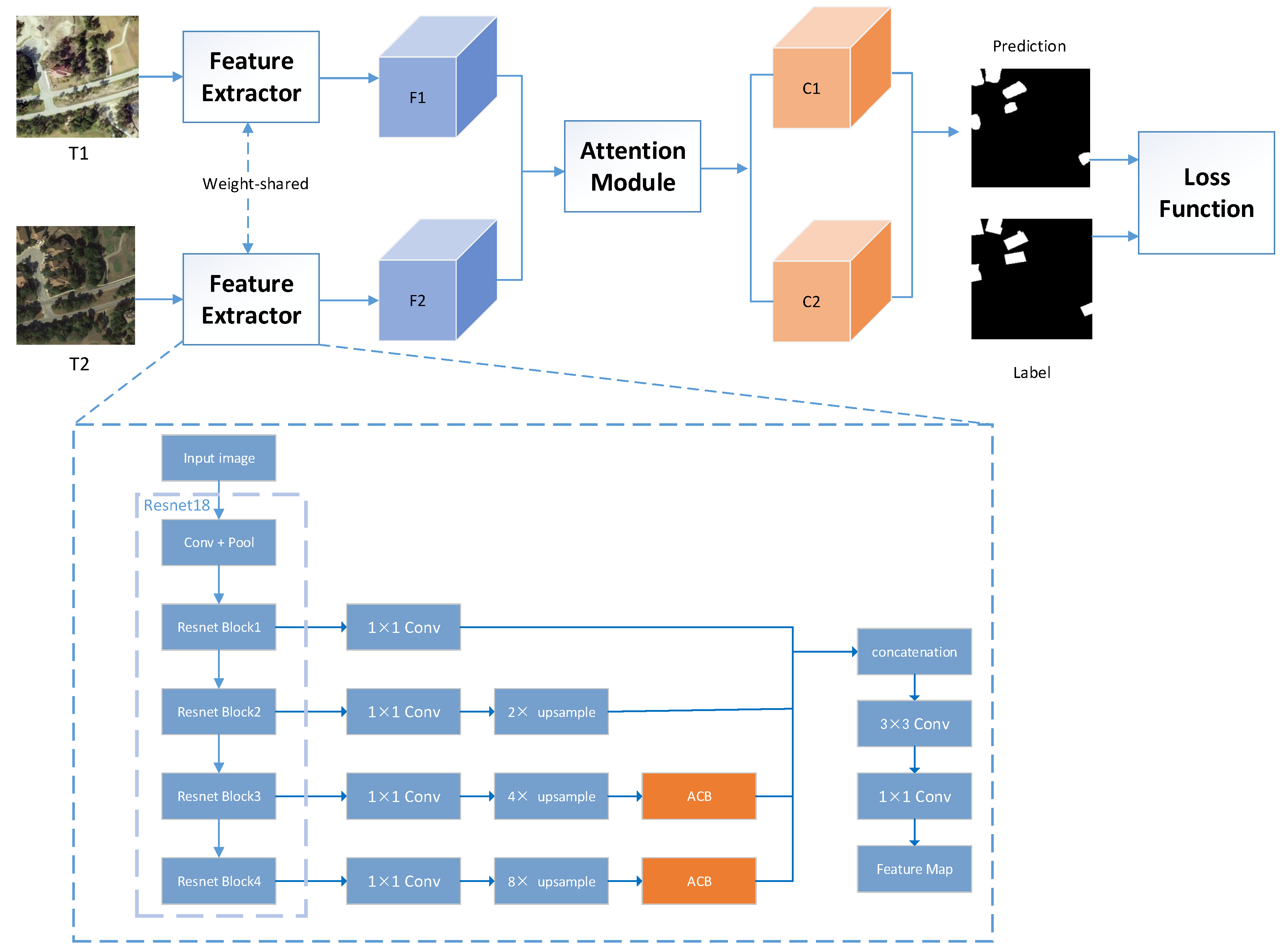
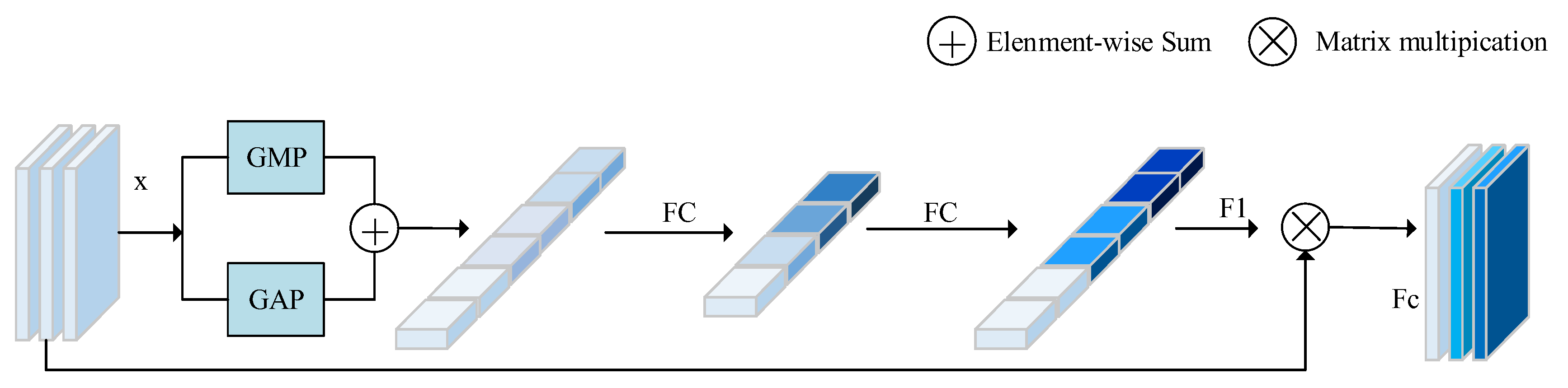
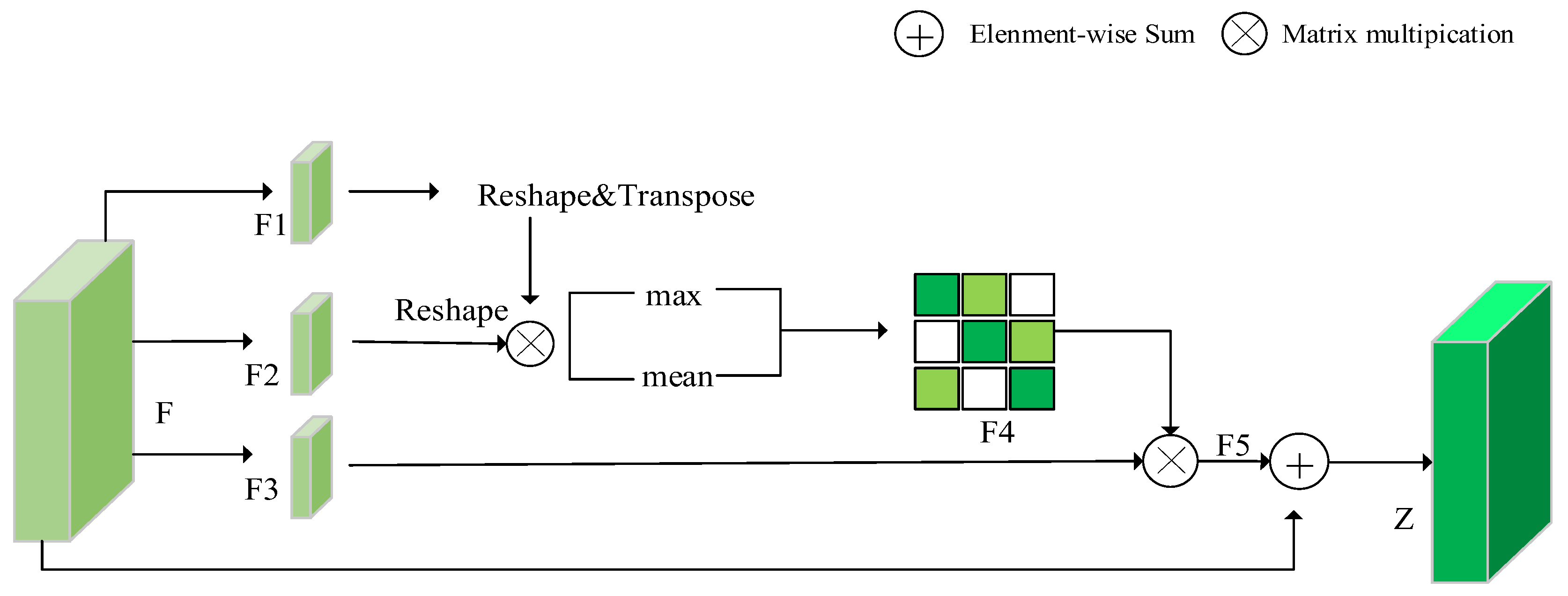
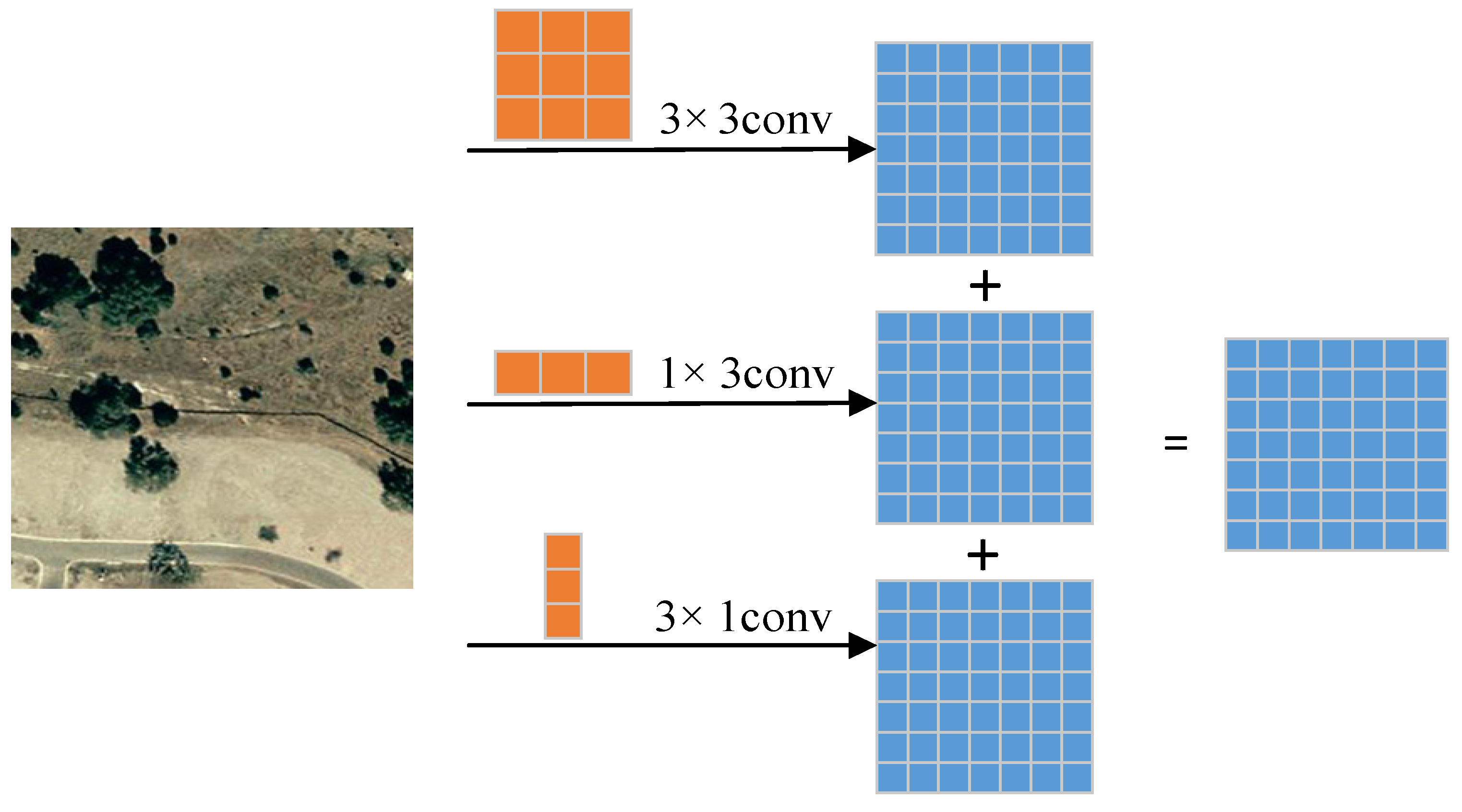
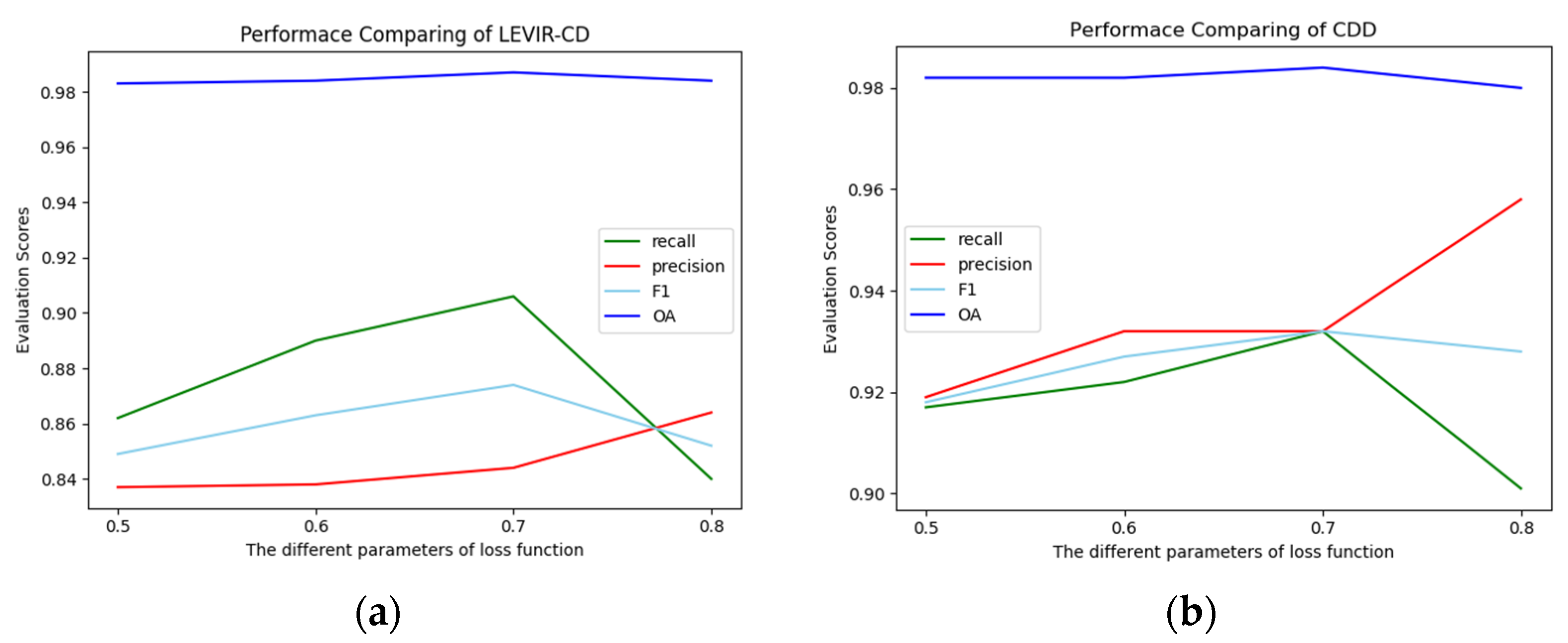
There are common problems with the abovementioned CD models. First, continuous down-sampling will cause position information to deviate, which may lead to the missed detection of small targets. Second, the extracted features from the model are usually sensitive to noise, shadow, and other factors due to the lack of features that can clearly distinguish the changed regions from the unchanged regions. Inspired by [
16,
24], we designed a new CD network architecture. An asymmetric convolution block (ACB) can enhance the robustness of a network model, enable a network to repeatedly extract the features of the central area, as well as increase the weight of the area, and does not introduce a lot of parameters and computation. Simultaneously, ACB improves the sensitivity and accuracy of a CANet by enhancing the activation of features in key areas. In addition, many researchers [
25,
26,
27] note that the combination of spatial attention and channel attention in a certain way not only makes the network pay attention to the areas of interest but also effectively enhances the performance of feature identification. Hence, we propose a combined attention mechanism, including channel attention, position attention, and spatial attention. This mechanism is used to obtain more refined image features to strengthen the performance of the model in identifying changes and improve its ability to recognize pseudo changes. The CANet is characterized by its suitable performance. Experiments on two datasets provided by [
16,
28] prove the effectiveness of this method. The main contributions of this article are as follows:
We propose a combined attention mechanism, which leverages spatial, channel, and position information to discriminate fine features, so as to obtain rich information of detected objects. The application of this mechanism improves the detection performance of small targets:
The rest of this article is structured as follows.
Section 2 mainly describes the network structure we propose in greater detail.
Section 3 introduces datasets, experimental settings, and evaluation indicators.
Section 4 precisely analyzes the experimental results.
Section 5 is the conclusion and contains directions for future work.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}