


BARI: An Affordable Brain-Augmented Reality Interface to Support Human–Robot Collaboration in Assembly Tasks





Abstract
:1. Introduction
2. Background
- Facilitated robot programming;
- Real-time support for control and navigation;
- Improved safety;
- Communication of the robot’s intention;
- Increased expressiveness.
3. Material and Methods
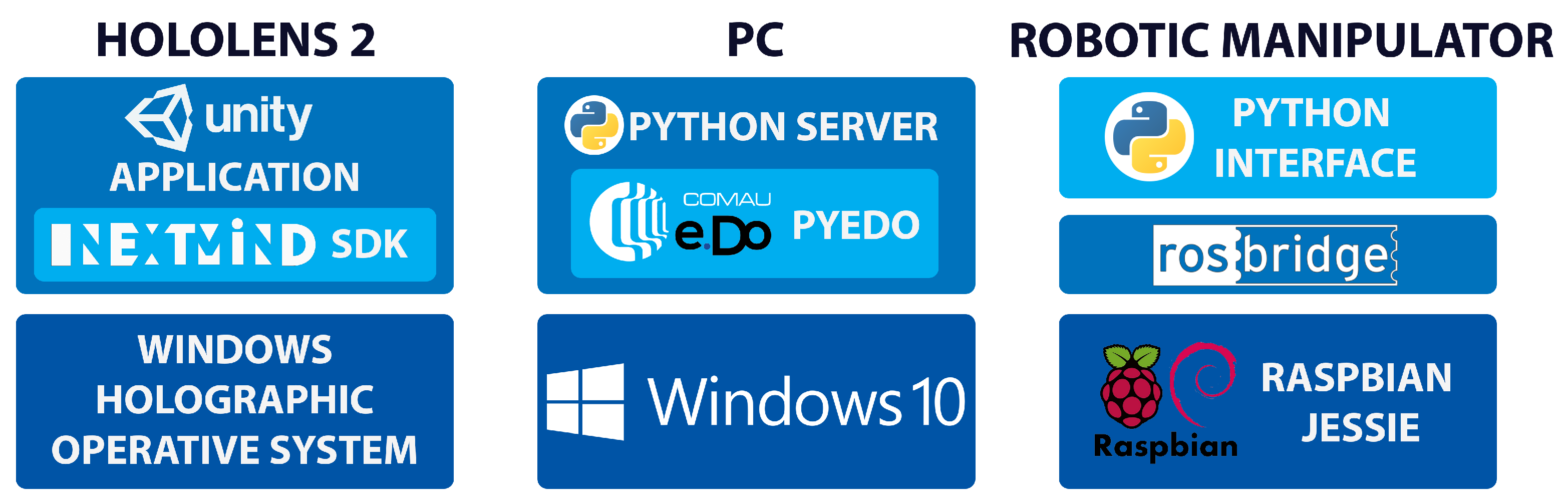
3.1. Hardware Architecture
3.2. Software Layers
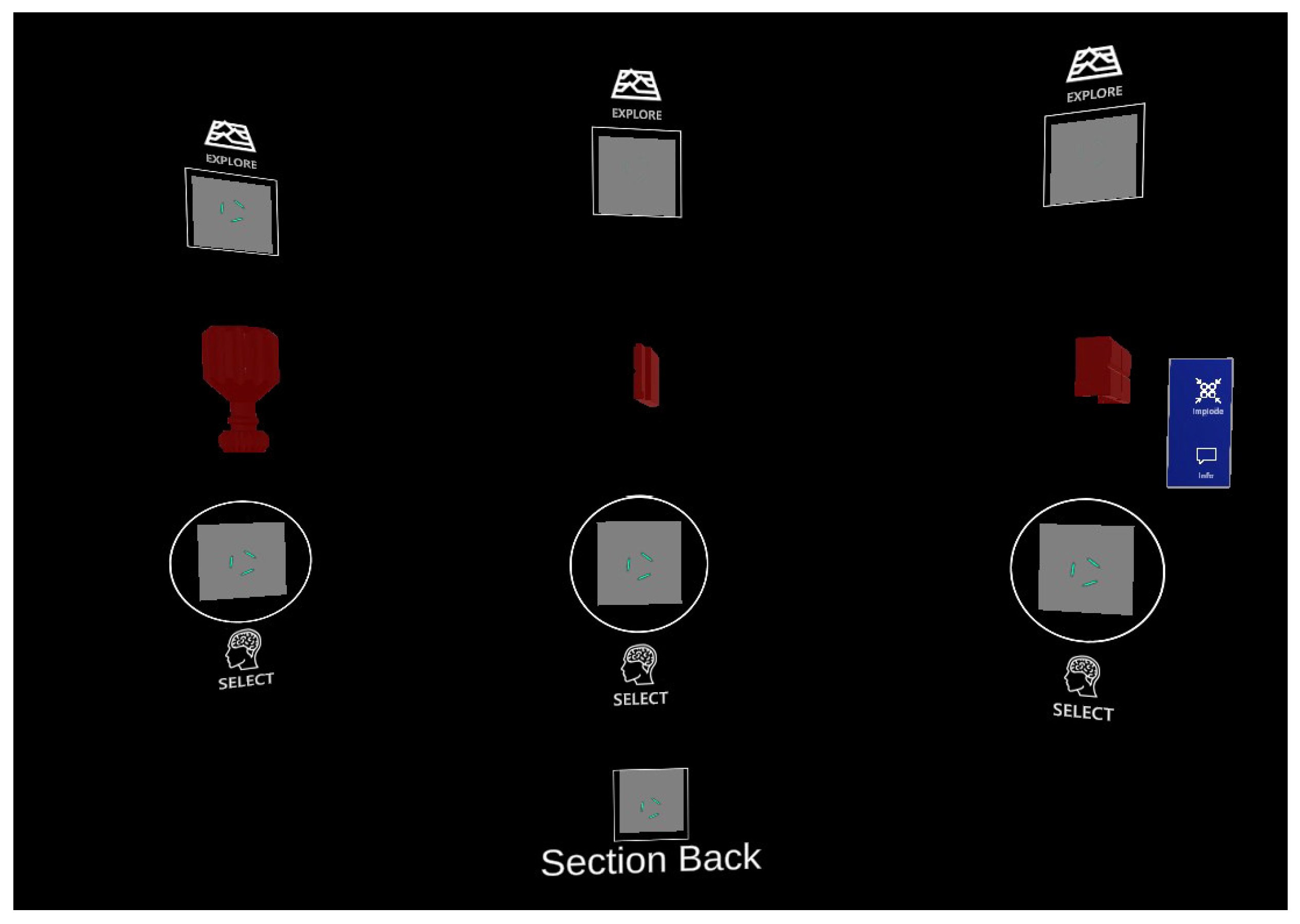
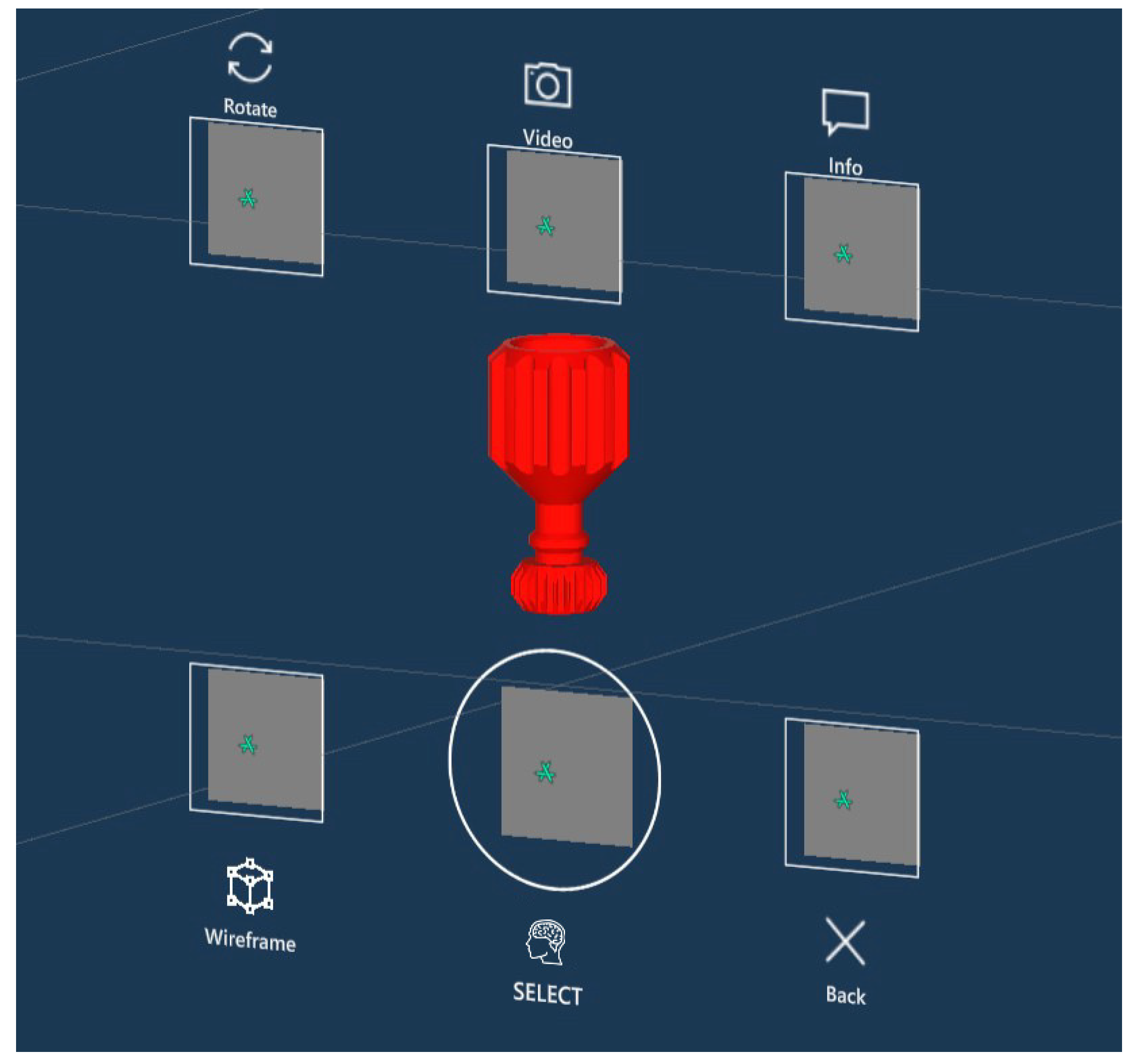
3.3. User Interface
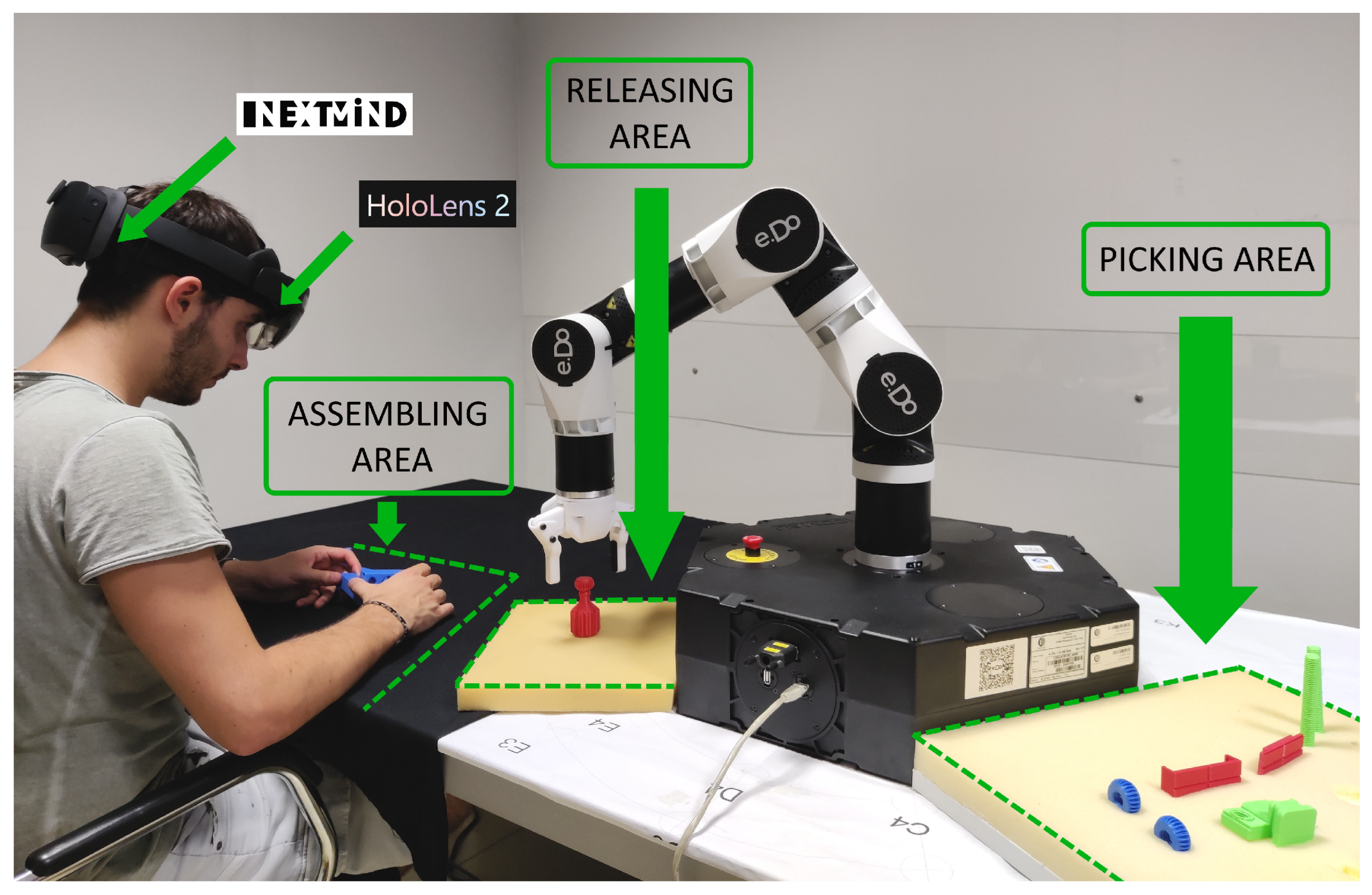
3.4. Tasks
- Research of information: Users had to visually identify and select a specified component of the vise in the AR interface (in particular, in the exploded view of the vise) and select its info panel. Users had to identify the weight and size of the component;
- Assembly of the vise: Users had to select all the components in a well-defined sequence using the corresponding NeuroTags. After selections, e.DO was in charge of picking components and placing them in a pre-set position, thus allowing the users to assemble the vise.
4. System Evaluation
4.1. User Test
- Welcome and device sanitization;
- Device setup (users first wore the NextMind and then the HoloLens 2);
- Calibration (the NextMind has to be calibrated in order to obtain the best performance; this step is also needed to check the contact point between the electrodes and the scalp);
- Training (a simple tutorial application was developed in order to familiarize users with the BCI);
- Virtual plane definition (users had to define, by gestures, a virtual plane where the vise is represented when assembled);
- Operative tasks (users performed the two tasks described in Section 3.4);
- Compilation of two questionnaires (the SUS questionnaire was used to assess usability, whereas the NASA-TLX evaluated the global workload).
4.2. Results
5. Discussion
5.1. Results Analysis
5.2. Limitations
5.3. Improvements and Future Work
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AGV | automated/automatic guided vehicle |
| AR | augmented reality |
| BCI | brain computer interface |
| CSP | common spatial patterns |
| DOAJ | directory of open access journals |
| DOF | degree of freedom |
| EEG | electroencephalogram |
| FMRI | functional magnetic resonance imaging |
| GWL | global work load |
| HCI | human–computer interaction |
| HMD | head-mounted display |
| HRC | human–robot collaboration |
| MDPI | Multidisciplinary Digital Publishing Institute |
| MI | motor imagery |
| SSVEP | steady-state visual evoked potential |
| UI | user interface |
| VR | virtual reality |
References
- Müller, R.; Vette, M.; Geenen, A. Skill-based dynamic task allocation in Human-Robot-Cooperation with the example of welding application. Procedia Manuf. 2017, 11, 13–21. [Google Scholar] [CrossRef]
- Pacaux-Lemoine, M.P.; Flemisch, F. Layers of shared and cooperative control, assistance and automation. Cogn. Technol. Work. 2019, 21, 579–591. [Google Scholar] [CrossRef]
- Habib, L.; Pacaux-Lemoine, M.P.; Millot, P. Adaptation of the level of automation according to the type of cooperative partner. In Proceedings of the IEEE International Conference on Systems, Man, and Cybernetics (SMC), Banff, AB, Canada, 5–8 October 2017; pp. 864–869. [Google Scholar]
- Schneemann, F.; Diederichs, F. Action prediction with the jordan model of human intention: A contribution to cooperative control. Cogn. Technol. Work. 2019, 21, 579–591. [Google Scholar] [CrossRef]
- Azuma, R.T. A survey of augmented reality. Presence Teleoperators Virtual Environ. 1997, 6, 355–385. [Google Scholar] [CrossRef]
- De Pace, F.; Manuri, F.; Sanna, A.; Fornaro, C. A systematic review of Augmented Reality interfaces for collaborative industrial robots. Comput. Ind. Eng. 2020, 149, 106806. [Google Scholar] [CrossRef]
- Matheson, E.; Minto, R.; Zampieri, E.G.G.; Faccio, M.; Rosati, G. Human–Robot Collaboration in Manufacturing Applications: A Review. Robotics 2019, 8, 100. [Google Scholar] [CrossRef]
- Nicolas-Alonso, L.F.; Gomez-Gil, J. Brain Computer Interfaces, a Review. Sensors 2012, 12, 1211–1279. [Google Scholar] [CrossRef]
- Mridha, M.F.; Das, S.C.; Kabir, M.M.; Lima, A.A.; Islam, M.R.; Watanobe, Y. Brain-Computer Interface: Advancement and Challenges. Sensors 2021, 21, 5746. [Google Scholar] [CrossRef]
- Microsoft HoloLens 2 Web Site. Available online: https://www.microsoft.com/en-us/hololens/ (accessed on 1 June 2022).
- The NextMind Web Site. Available online: https://www.next-mind.com/ (accessed on 1 June 2022).
- Brooke, J. Sus: A “quick and dirty” usability. In Usability Evaluation in Industry; Jordan, P.W., Thomas, B., McClelland, I.L., Weerdmeester, B., Eds.; CRC Press: London, UK, 1996; pp. 189–194. [Google Scholar]
- The NASA-TLX Web Site. Available online: https://humansystems.arc.nasa.gov/groups/tlx/ (accessed on 1 June 2022).
- Billinghurst, M.; Grasset, R.; Looser, J. Designing augmented reality interfaces. SIGGRAPH Comput. Graph. 2005, 39, 17–22. [Google Scholar] [CrossRef]
- Lamberti, F.; Manuri, F.; Paravati, G.; Piumatti, G.; Sanna, A. Using Semantics to Automatically Generate Speech Interfaces for Wearable Virtual and Augmented Reality Applications. IEEE Trans. Hum. Mach. Syst. 2017, 47, 152–164. [Google Scholar] [CrossRef]
- Suzuki, R.; Karim, A.; Xia, T.; Hedayati, H.; Marquardt, N. Augmented Reality and Robotics: A Survey and Taxonomy for AR-enhanced Human-Robot Interaction and Robotic Interfaces. In Proceedings of the Conference on Human Factors in Computing Systems (CHI), New Orleans, LA, USA, 30 April–5 May 2022; pp. 1–33. [Google Scholar]
- Irimia, D.C.; Ortner, R.; Krausz, G.; Guger, C.; Poboroniuc, M.S. BCI application in robotics control. IFAC Proc. Vol. 2012, 45, 1869–1874. [Google Scholar] [CrossRef]
- Cohen, O.; Druon, S.; Lengagne, S.; Mendelsohn, A.; Malach, R.; Kheddar, A.; Friedman, D. fMRI-based robotic embodiment: Controlling a humanoid robot by thought using real-time fMRI. Presence 2014, 23, 229–241. [Google Scholar] [CrossRef]
- Tang, J.; Zhou, Z.; Liu, Y. A 3D visual stimuli based P300 brain-computer interface: For a robotic arm control. In Proceedings of the International Conference on Artificial Intelligence, Automation and Control Technologies (AIACT), Wuhan, China, 7–9 April 2017; pp. 1–6. [Google Scholar]
- Chamola, V.; Vineet, A.; Nayyar, A.; Hossain, E. Brain-computer interface-based humanoid control: A review. Sensors 2020, 20, 3620. [Google Scholar] [CrossRef] [PubMed]
- Lenhardt, A.; Ritter, H. An augmented-reality based brain-computer interface for robot control. In Proceedings of the International Conference on Neural Information Processing, Vancouver, BC, Canada, 6–11 December 2010; pp. 58–65. [Google Scholar]
- Faller, J.; Leeb, R.; Pfurtscheller, G.; Scherer, R. Avatar Navigation in Virtual and Augmented Reality Environments Using an SSVEP BCI. In Proceedings of the 1st International Conference on Apllied Bionics and Biomechanics (ICABB), Venice, Italy, 14–16 October 2010; pp. 1–4. [Google Scholar]
- Kato, H.; Billinghurst, M. Marker tracking and hmd calibration for a video-based augmented reality conferencing system. In Proceedings of the 2nd IEEE and ACM International Workshop on Augmented Reality (IWAR), San Francisco, CA, USA, 20–21 October 1999; pp. 85–94. [Google Scholar]
- Mercier, J. Contribution to the Study of the Use of Brain-Computer Interfaces in Virtual and Augmented Reality. Ph.D. Thesis, INSA de Rennes, Rennes, France, 2015. [Google Scholar]
- Martens, N.; Jenke, R.; Abu-Alqumsan, M.; Kapeller, C.; Hintermüller, C.; Guger, C.; Peer, A.; Buss, M. Towards robotic re-embodiment using a Brain-and-Body-Computer Interface. In Proceedings of the IEEE/RSJ International Conference on Intelligent Robots and Systems, Vilamoura, Algarve, Portugal, 7–12 October 2012; pp. 5131–5132. [Google Scholar]
- Zeng, H.; Wang, Y.; Wu, C.; Song, A.; Liu, J.; Ji, P.; Xu, B.; Zhu, L.; Li, H.; Wen, P. Closed-loop hybrid gaze brain-machine interface based robotic arm control with augmented reality feedback. Front. Neurorobotics 2017, 11, 60. [Google Scholar] [CrossRef] [PubMed]
- Si-Mohammed, H.; Petit, J.; Jeunet, C.; Argelaguet, F.; Spindler, F.; Evain, A.; Roussel, N.; Casiez, G.; Lécuyer, A. Towards BCI-based interfaces for augmented reality: Feasibility, design and evaluation. IEEE Trans. Vis. Comput. Graph. 2020, 26, 1608–1621. [Google Scholar] [CrossRef] [PubMed]
- Kim, S.; Lee, S.; Kang, H.; Kim, S.; Ahn, M. P300 Brain–Computer Interface-Based Drone Control in Virtual and Augmented Reality. Sensors 2021, 21, 5765. [Google Scholar] [CrossRef]
- Borges, L.R.; Martins, F.R.; Naves, E.L.; Bastos, T.F.; Lucena, V.F. Multimodal system for training at distance in a virtual or augmented reality environment for users of electric-powered wheelchairs. IFAC-PapersOnLine 2016, 49, 156–160. [Google Scholar] [CrossRef]
- Da Col, S.; Kim, E.; Sanna, A. Human performance and mental workload in augmented reality: Brain computer interface advantages over gestures. Brain-Comput. Interfaces 2022, 1–15. [Google Scholar] [CrossRef]
- e.DO Website. Available online: https://edo.cloud/ (accessed on 1 June 2022).
- The Unity Web Site. Available online: https://unity.com/ (accessed on 1 June 2022).
- The Vise Web Site. Available online: https://www.thingiverse.com/thing:2064269 (accessed on 1 June 2022).
- Bangor, A.; Kortum, P.; Miller, J. Determining what individual SUS scores mean: Adding an adjective rating scale. J. Usability Stud. 2009, 4, 114–123. [Google Scholar]
- Sauro, J. 5 Ways to Interpret a SUS Score, 19 September 2018. Available online: https://measuringu.com/interpret-sus-score/ (accessed on 8 September 2022).
- Grier, R.A. How High is High? A Meta-Analysis of NASA-TLX Global Workload Scores. Proc. Hum. Factors Ergon. Soc. Annu. Meet. 2015, 59, 1727–1731. [Google Scholar] [CrossRef]
- Manuri, F.; Sanna, A.; Bosco, M.; Pace, F. A Comparison of Three Different NeuroTag Visualization Media: Brain Visual Stimuli by Monitor, Augmented and Virtual Reality Devices. In Proceedings of the AHFE International Conference on Human Interaction & Emerging Technologies (IHIET 2022): Artificial Intelligence & Future Applications, New York, NY, USA, 24–28 July 2022; Ahram, T., Taiar, R., Eds.; AHFE Open Access. AHFE International: New York, NY, USA, 2022; Volume 68. [Google Scholar]
- Kohli, V.; Tripathi, U.; Chamola, V.; Rout, B.K.; Kanhere, S.S. A review on Virtual Reality and Augmented Reality use-cases of Brain Computer Interface based applications for smart cities. Microprocess. Microsystems 2022, 88, 104392. [Google Scholar] [CrossRef]
- Gang, P.; Hui, J.; Stirenko, S.; Gordienko, Y.; Shemsedinov, T.; Alienin, O.; Kochura, Y.; Gordienko, N.; Rojbi, A.; López Benito, J.R.; et al. User-driven intelligent interface on the basis of multimodal augmented reality and brain-computer interaction for people with functional disabilities. In Proceedings of the Future of Information and Communication Conference, Singapore, 5–6 April 2018; Springer: Cham, Switzerland, 2018; pp. 612–631. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| User | SUS Score | Grade | Adjective Rating |
|---|---|---|---|
| 1 | 62.5 | D | Okay |
| 2 | 67.5 | D | Okay |
| 3 | 92.5 | A+ | Best Imaginable |
| 4 | 77.5 | B+ | Good |
| 5 | 72.5 | C+ | Good |
| 6 | 75.0 | B | Good |
| 7 | 82.5 | A | Excellent |
| 8 | 70.0 | C | Good |
| 9 | 77.5 | B+ | Good |
| 10 | 80.0 | A− | Good |
| Mean | 75.75 | B | Good |
| Standard Deviation | 7.98 |
| Users | Individual Scores (Weighted) | ||||||
|---|---|---|---|---|---|---|---|
| Mental | Physical | Temporal | Performance | Effort | Frustration | Mean | |
| 1 | 70 | 40 | 150 | 120 | 210 | 60 | 43.33 |
| 2 | 135 | 135 | 300 | 25 | 150 | 0 | 49.67 |
| 3 | 105 | 10 | 180 | 20 | 45 | 0 | 24.00 |
| 4 | 0 | 60 | 60 | 45 | 45 | 45 | 17.00 |
| 5 | 45 | 70 | 60 | 135 | 30 | 50 | 26.00 |
| 6 | 50 | 0 | 260 | 200 | 120 | 60 | 46.00 |
| 7 | 350 | 0 | 240 | 45 | 180 | 5 | 54.67 |
| 8 | 325 | 0 | 90 | 80 | 225 | 35 | 50.33 |
| 9 | 260 | 150 | 45 | 125 | 130 | 0 | 47.33 |
| 10 | 110 | 10 | 105 | 175 | 150 | 20 | 38.00 |
| Diagnostic Subscores | Overall | ||||||
| GSR | 161.11 | 67.86 | 149.00 | 97.00 | 128.50 | 39,29 | 39.63 |
| Users | Individual Scores (Weighted) | ||||||
|---|---|---|---|---|---|---|---|
| Mental | Physical | Temporal | Performance | Effort | Frustration | Mean | |
| 1 | 130 | 20 | 120 | 120 | 130 | 130 | 43.33 |
| 2 | 90 | 300 | 320 | 50 | 225 | 0 | 65.67 |
| 3 | 105 | 5 | 140 | 25 | 40 | 0 | 21.00 |
| 4 | 40 | 140 | 120 | 100 | 100 | 0 | 33.33 |
| 5 | 195 | 0 | 340 | 320 | 135 | 30 | 68.00 |
| 6 | 80 | 0 | 40 | 250 | 60 | 30 | 30.67 |
| 7 | 285 | 0 | 380 | 15 | 500 | 70 | 83.33 |
| 8 | 375 | 0 | 120 | 100 | 195 | 40 | 55.33 |
| 9 | 350 | 0 | 40 | 120 | 260 | 110 | 58.67 |
| 10 | 0 | 5 | 180 | 120 | 255 | 240 | 53.33 |
| Diagnostic Subscores | Overall | ||||||
| GSR | 183.33 | 94.00 | 180.00 | 122.00 | 190.00 | 92.86 | 51.27 |
| User | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | Mean |
|---|---|---|---|---|---|---|---|---|---|---|---|
| T1 | 04:05 | 00:57 | 00:55 | 00:45 | 01:39 | 00:30 | 01:03 | 00:43 | 00:23 | 00:37 | 01:10 |
| T2 | 17:36 | 14:02 | 12:57 | 13:02 | 13:04 | 12:08 | 11:56 | 12:21 | 11:14 | 12:02 | 13:02 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sanna, A.; Manuri, F.; Fiorenza, J.; De Pace, F. BARI: An Affordable Brain-Augmented Reality Interface to Support Human–Robot Collaboration in Assembly Tasks. Information 2022, 13, 460. https://doi.org/10.3390/info13100460
Sanna A, Manuri F, Fiorenza J, De Pace F. BARI: An Affordable Brain-Augmented Reality Interface to Support Human–Robot Collaboration in Assembly Tasks. Information. 2022; 13(10):460. https://doi.org/10.3390/info13100460
Chicago/Turabian StyleSanna, Andrea, Federico Manuri, Jacopo Fiorenza, and Francesco De Pace. 2022. "BARI: An Affordable Brain-Augmented Reality Interface to Support Human–Robot Collaboration in Assembly Tasks" Information 13, no. 10: 460. https://doi.org/10.3390/info13100460
APA StyleSanna, A., Manuri, F., Fiorenza, J., & De Pace, F. (2022). BARI: An Affordable Brain-Augmented Reality Interface to Support Human–Robot Collaboration in Assembly Tasks. Information, 13(10), 460. https://doi.org/10.3390/info13100460