1. Introduction
Humans’ trust in the recommendations by artificial intelligence [
1] (even with knowledge engineered expert systems) has required explanations in human understandable terms [
2,
3,
4,
5]. Even in heterogeneous robot–human teams, robots delivering explanations of their decisions are crucial to humans [
6]. For instance, in the domain of power systems applications, experts mistrust the results of machine learning when they do not understand the outputs [
7], which is an issue that has been ameliorated by applying Explainable AI (XAI). It could be argued that machine learning (ML) was fuelled by the need to decrease the cost of transferring human expertise into decision support systems and reducing the high cost of knowledge engineering and deploying such systems [
8].
“It is obvious that the interactive approach to knowledge acquisition cannot keep pace with the burgeoning demand for expert systems; Feigenbaum terms this the ‘bottleneck problem’. This perception has stimulated the investigation of machine learning as a means of explicating knowledge”.
From early reviews on the progress of ML, the understandability (then named comprehensibility) of the classification delivered by learned models was considered vital [
10].
“A definite loss of any communication abilities is contrary to the spirit of AI. AI systems are open to their user who must understand them”.
There is so much to gain from incorporating Human-In-the-Loop Learning (HILL) into ML tasks. Early research identified validation or new knowledge elicitation [
12,
13,
14,
15] as advantages for Human-In-the Loop Machine Learning (HITL-ML). Today, the partnership between the fast heuristic search for classifiers, leveraging of visual analytics for ML [
16], and HITL-ML has received the name of Interactive Machine Learning (IML) [
17,
18] because not only are datasets the source of knowledge, but IML also captures the experience of human experts [
19]. The characteristics of IML that we emphasise here are that humans are assigned tasks in the learning loop [
13,
15] with specific roles, typically as experts, iteratively and incrementally updating the model, in a setting where the user interface is particularly important in influencing how the learning takes place [
18]. We should point out that IML within the terminology of visual analytics [
20] also has received the name of visualisation for model understanding, and in particular, visualisation for iterative steering model construction [
16].
However, the immense progress in ML to tackle accuracy has resulted in the deployment of classifiers in enormous data sets and diverse domains. Supervised learning is part of many sophisticated integration applications, but the extraordinary predictive power and the superb accuracy have sacrificed the transparency and interpretability of the predictions. There is a revived interest in considering other criteria besides predictive accuracy [
21,
22], particularly in domains such as medicine [
23], credit scoring [
24], churn prediction [
25], and bio-informatics [
26].
Deep learning (considered a sub-area of machine learning [
27]) offers Convolutional Neural Networks (CNNs) as supervised learning techniques that are regarded as superior for object classification, face recognition, and automatic handwriting understanding [
27]. Similarly, Support Vector Machines (SVMs) are considered immensely potent for pattern recognition [
28]. CNNs, ensembles [
29], and SVMs output models that are considered “black box” models, since they are difficult to interpret by domain experts [
21,
30]. Thus, delivering understandable classification models is an urgent research topic [
21,
22]. The most common approach is to follow the production of accurate black-box models with methods to extract explanations [
31,
32]. There are two lines of work for delivering explainable models. The first line builds interpretable surrogate models that learn to closely reproduce the output of the black-box model while regulating aspects such as cluster size for explanation [
33,
34]. The second path is to produce an explanation for the classification of a specific instance [
35] or to identify cases belonging to a subset of the feature space where descriptions are suitable [
36] and trustworthy [
37]. However, there are strong arguments that suggest that real interpretable models must be learned from the beginning [
34,
38].
Learning decision trees from data is one of the pioneer methods that produces understandable models [
21,
39]. Decision tree learning is now ubiquitous in big data, statistics, data mining, and ML. It is listed first among the top 10 most-used algorithms in data mining [
40] is C4.5 [
41] (a method based on a recursive approach incorporated into CLS [
42] and ID3 [
43]). Another representative of decision-tree learning is CART (Classification and Regression Trees) [
44], and it also appears among the top 10 algorithms in data mining.
Earlier [
45], we incorporated HITL-ML and used visualisation with parallel coordinates [
46] to interactively build accurate and interpretable models with explainable outputs. We reviewed earlier evaluations of HITL-ML in machine learning tasks [
45]. In particular, we provided an in-depth evaluation [
45] of the WEKA [
14] package for IML. Since the three fundamental aspects of IML are users, data, and interface [
47], in this paper, we turn our attention to the interface and evaluate it with users who could play the primary roles of data scientists (but not domain experts) [
48]. We have now incorporated parallel coordinates for the exploration of datasets and HITL-ML into a software prototype for the deployment of decision-tree classifiers (DTCs).
In this paper, we discuss how this prototype exhibits improvements over numerous other HITL-ML systems. We emphasise that our prototype not only achieves high accuracy [
49] but enables (1) understanding of learnt classifiers, (2) exploration and insight into datasets, and (3) meaningful exploration by humans. In particular, we present here how parallel coordinates can provide a visualisation of specific rules and support an operator’s interaction with the dataset even further to scrutinise specific rules. This enables the construction of characterisation and discrimination rules [
50], which focus on one class above the others. We will show that users gain understanding through visualisation [
24], presenting the experimental design, survey questions and results [
51] of a detailed usability study for HITL-ML. We note that despite the increased interest in explainable outcomes from machine learning, a recent study [
52] has found that from more than 600 publications between 2014 and 2020, one out of three exclusively use anecdotal evidence for their findings. The same study found that only one in five papers ever provided a case study. Thus, our contribution is not only the inclusion of a detailed user case study and the interface of our prototype, but the case study itself provides a model for a systematic evaluation of tools and systems for IML.
The paper is organised as follows. In
Section 2, we review salient HITL-ML systems where learning classifiers involves dataset visualisations. We highlight the advantages of using parallel coordinates, noting that our review of HITL-ML systems reveals that there is almost no experimental evaluation of the effectiveness of HITL-ML. So far, the largest study was our reproduction [
45] with 50 users, while the original WEKA
UserClassifier paper reported a study with only five participants [
14].
Section 3 explains our algorithms and system for HITL-ML. We proceed in
Section 4 to provide the details of our study that consists of three experiments. Then,
Section 5 reports on our own experiments with over 100 users on our proposed system. We highlight how our system overcomes a number of the shortcomings of the HITL-ML systems we reviewed in
Section 2.
2. Dataset Visualisations for Involving Experts in Classifier Construction
Perhaps the earliest system to profit from the interpretability of decision trees for HITL-ML was the second version [
53] of
PCB [
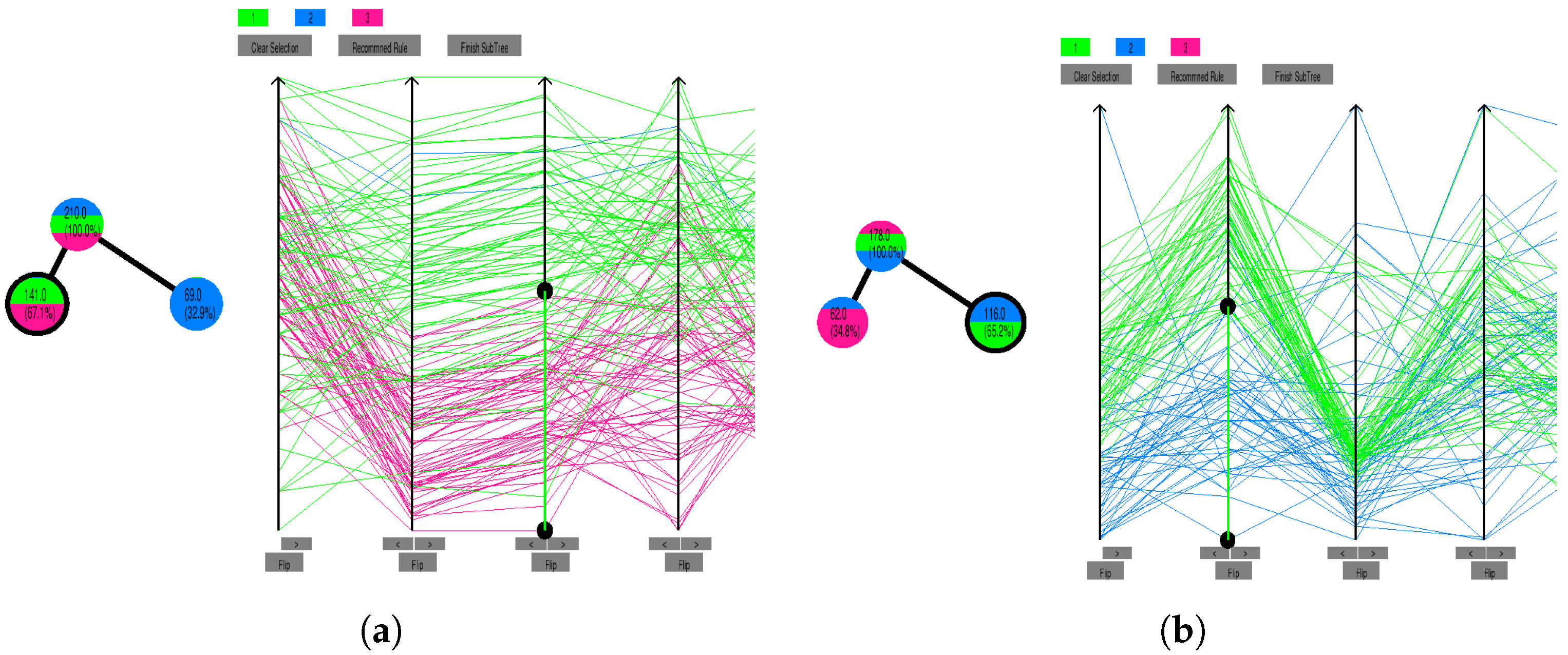
12], which introduced a coloured bar to illustrate an attribute. This bar is constructed by sorting the dataset on the attribute in question, representing each instance as a pixel (in the bar), which was coloured corresponding to its class. This allows a user to visually recognise clusters of a class on any one attribute. A DTC is visualised by showing bars with cuts to represent a split on an attribute. Each level of the tree can then be shown as a subset of an attribute bar with splits. A user participates in the learning the tree using this visualisation by themselves specifying where on a bar to split an attribute. The HITL-ML process has some algorithmic support to offer suggestions for splits and to finish subtrees. This type of visualisation appears particularly effective at showing a large dataset in a way that does not take much screen real estate.
However, the bar representation removes important human domain knowledge. For instance, all capability to see actual values of attributes (or the magnitude of value differences) disappears. This prevents experts from incorporating their knowledge. Moreover, the bar representation restricts classification rules to tests consisting of strictly univariate splits. There is no visualisation of attribute relationships (correlations, inverse correlations, or oblique correlations).
We discard bars, and inspired by the Nested Cavities (NC) algorithm [
54,
55], which is an approach to IML, we adopt parallel coordinates [
46]. A parallel-coordinates visualisation draws a parallel axis for each attribute of the dataset. An instance of the dataset is then shown as a poly-line that crosses each axis at the normalised value for that attribute. Unlike most other visualisation techniques, parallel coordinates scale, and they are not restricted to datasets with a small number of dimensions. Parallel coordinates with 400 dimensions have been used [
56] (Figure 14.21). More attributes are displayed by packing their axis on the side. However, decisions being based on over 100 variables are hardly interpretable and understandable [
56]. Our method is an improvement over the NC algorithm [
57]. Moreover, our prototype uses ML metrics to recommend attributes (and their order) in a visualisation. The operator still can select their preferred number of parallel axes to display.
The construction of classifiers with NC is similar to decision trees, because both approaches follow conditional focusing [
58] (Figure 8.3) and recursive refinement [
43] (p. 152, Chaper 4)that results in a decision tree structure [
59] (p. 407). However, to the best of our knowledge, there are no user-focussed evaluations of IML with NC.
Other researchers have attempted star-coordinates for dataset visualisation and decision-tree construction [
60,
61]. With star-coordinates, each attribute is drawn as an axis on a 2D plane starting from the centre of the screen and projected outwards. Initially, all axes are evenly spaced so that they form a star shape. To map an instance onto the plane, all attribute values are first normalised (using linear scaling; that is
). Following this, the position of that instance on each axis is calculated. The final position of the instance is the average position from each axis. The user can interact with the visualisation by stretching and moving each axis, which recalculates the position of all the points displayed. However, star-coordinates displays suffer similar drawbacks as bar visualisations: users are unable to find subsets of predictive attributes, or ways to discriminate classes. In star-coordinates, the location for visualisation of an instance depends on the value of all attributes, making it impossible to identify boundaries between classes provided by a few (or even single) attributes. In contrast, with parallel coordinates, such separations are readily apparent.
With star coordinates, experts cannot explore and interchange attributes with other attributes, even if aware of subsets of predictive attributes. Users can only chose a projection emphasising influential attributes, losing any insight of one attribute’s interaction with other attributes. There is no natural interaction with the star-coordinates visualisation where a user can also determine exactly what attribute(s) are contributing the most to the position of a point in the visualisation.
PaintingClass [
61] extends
StarClass [
60] so the expert can use visualisations of categorical attributes with parallel coordinates. However, the restriction persists for numerical attributes.
PaintingClass uses parallel coordinates for categorical attributes where categorical values are evenly distributed along the axis as they appear in the dataset. This produces a visualisation with unintended bias. Because
PaintingClass does not provide any machine learning support, and building the classifier is completely human-driven, it could be argued that it is not HITL-ML.
iVisClassifier [
62] profits from parallel coordinates, but to reduce the attributes presented to the user, the dataset is presented only after using linear discriminant analysis (LDA) for feature reduction. The visualisation uses only the top LDA vectors. However, using this new LDA feature blocks the user’s understanding of the visualisation since each LDA feature is a vector of coefficients over all the original attributes (or dimensions). Heat-maps are displayed in an attempt to help interpret component features, but they could possibly only have some semantics in the particular application of front-human-portrait face-recognition. A similar approach [
20,
63] uses techniques to visualise the high-dimensional feature space in two dimensions, so a human can draw a piece-wise linear boundary split in the 2D visualisation and iteratively construct the decision-tree classifier. This approach claims that some feature semantics are preserved, but it does not offer any user evaluation of this claim, neither when it comes to understandability nor accuracy.
As opposed to the earlier proposals, some empirical evaluation is reported in WEKA’s
UserClassifier [
14].
UserClassifier is an IML system for DTCs that shows a scatter plot of only two attributes at a time (the user can pivot which two attributes appear in the visualisation). A display of small bars for each attribute provides some assistance for attribute relevance. The attribute bar presents the distribution of classes when sorted by that attribute. The user can review the current tree as a node-link diagram in one display, select, and expand a node. WEKA’s
UserClassifier is the only one reporting usability studies, and it involved only five participants [
14]. Later, it was evaluated with 50 university students who had completed 7 weeks of material on machine learning and DTCs [
45]. This study confirmed a number of limitations of WEKA’s
UserClassifier. For instance, the type of interaction (on the dataset and on the model) are restrictive in a number of ways.
The visualisation displays only two attributes at a time; this is critically restrictive.
The space to display region bars is minuscule, impeding users’ observation of differences to decide which two attributes to display.
Despite the immense literature on techniques for splitting a node to grow and construct a decision tree, the system does not provide any split-suggestion to the user.
Unless users depart from the attribute visualisation window (losing context of the current splitting task), the tree under construction is not visible.
Visualisation techniques (such as colour, or size) are not used. So, the user cannot inspect any properties of a node or an edge nor any relationship between a node and the dataset under analysis.
In summary, these issues limit a human’s ability to gain a broader understanding of the datasets and of the classifiers. Nevertheless, we point out that a comparison of decision trees built by humans against decision trees built by machines resulted in humanly-built trees being superior in many aspects over those built by machines [
64]. In that research [
64], the technique for human-centred IML was parallel coordinates, which reinforces our approach to include this in our prototype and its evaluation.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}