
A Systematic Literature Review and Meta-Analysis of Studies on Online Fake News Detection


Abstract
1. Introduction
- The discovery of a variety of sources in research on the detection of online fake news can help researchers make better decisions by identifying appropriate AI approaches for detecting fake news online.
- The examination of publication bias in establishing the reliability of the main conclusions of research on detection methods.
- The identification of studies that contribute most to the heterogeneity of the detection studies.
2. Related Works
3. Materials and Methods
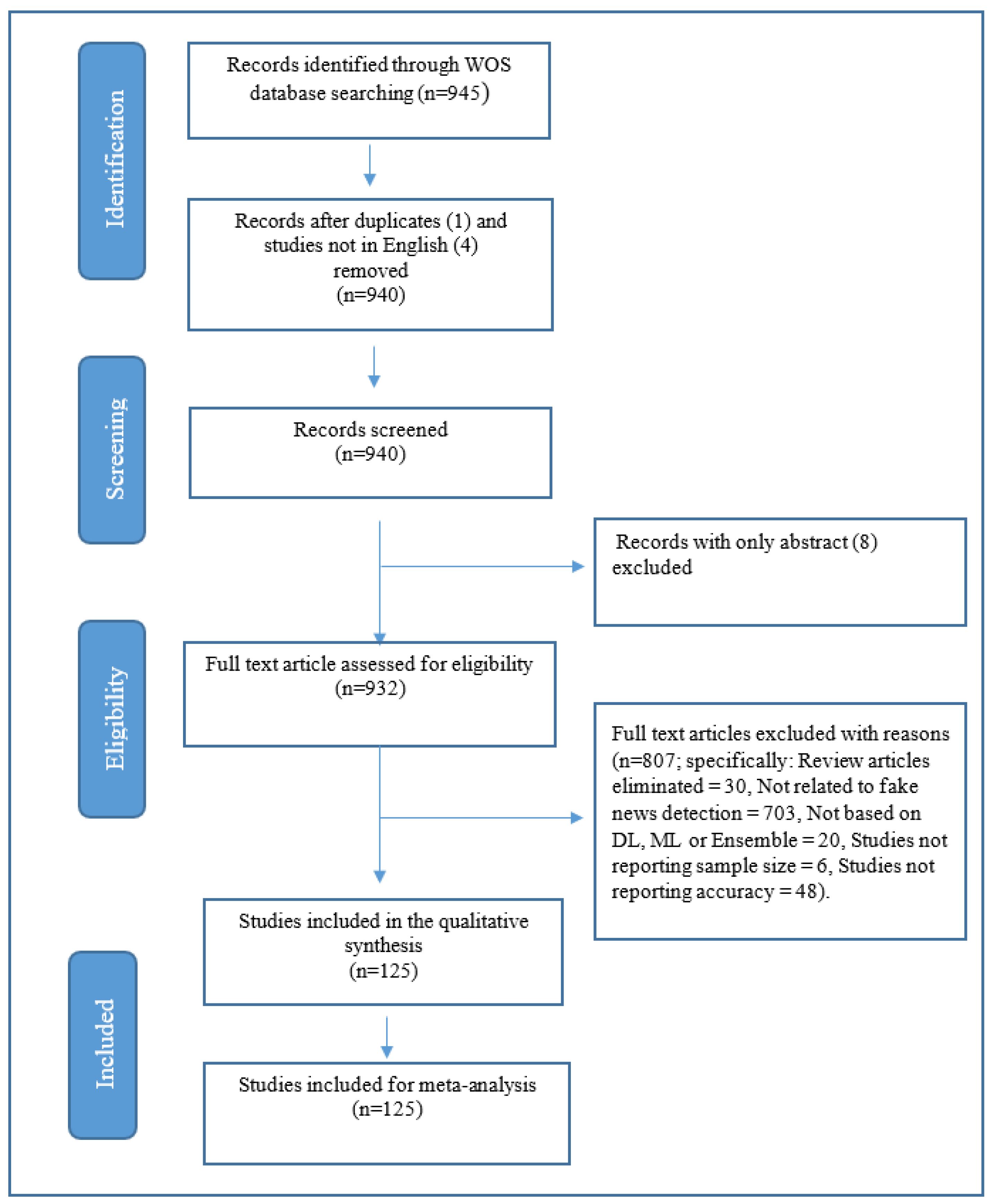
3.1. Literature Search Strategy
3.2. Inclusion and Exclusion Criteria
3.3. Quality Assessment and Data Extraction
3.4. Data Synthesis and Statistical Analysis
4. Results
4.1. Meta-Analysis Summary
4.2. Subgroup Analysis
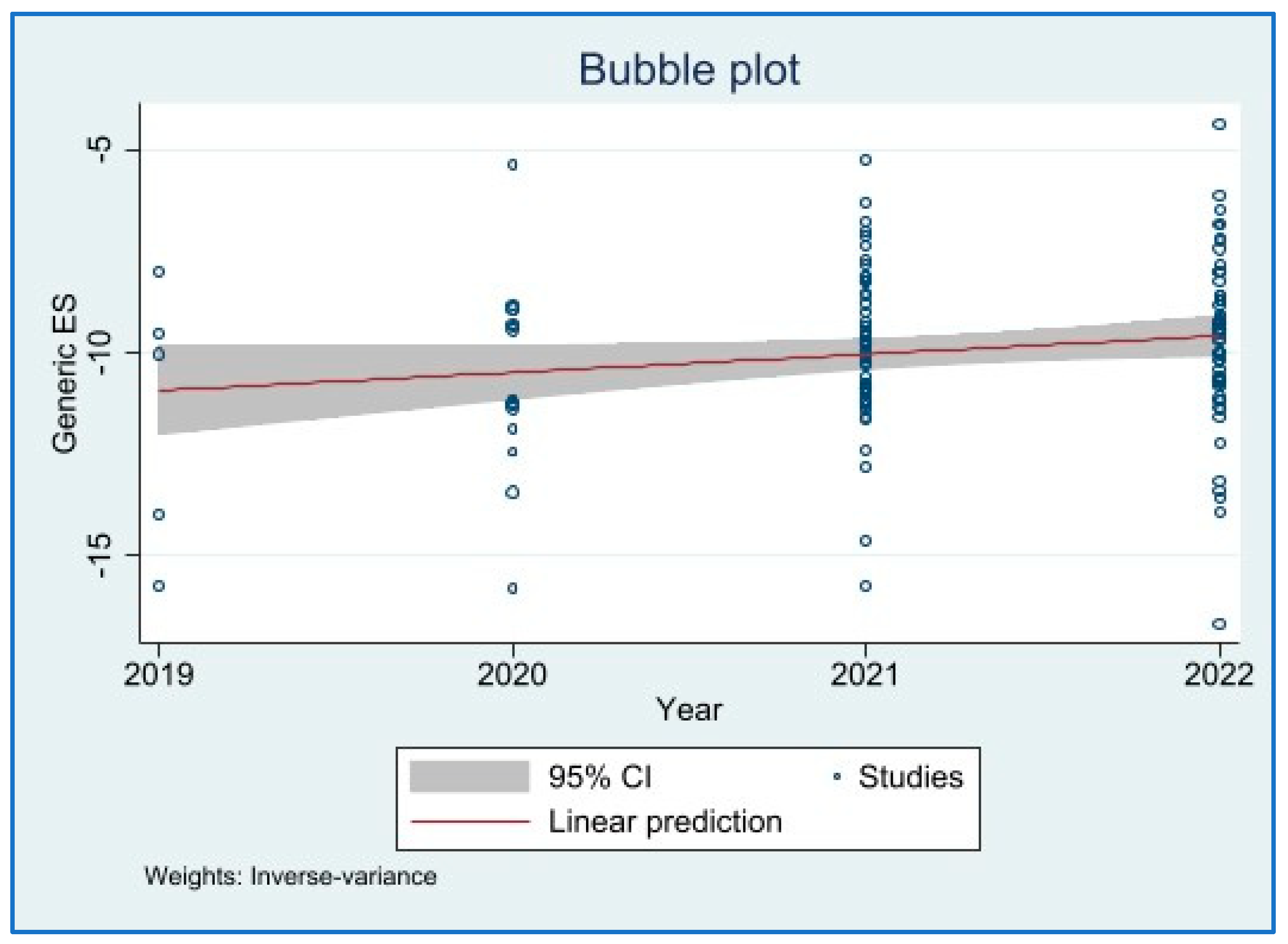
4.3. Meta-Regression
4.4. Publication Bias
4.5. Descriptive Statistics of Primary Studies
5. Conclusions
- Deep learning was the most widely used approach, with the CNN method most commonly employed due to its most effective architecture for accurate and efficient detection.
- The most used method in machine learning is RF. It is capable of handling hundreds of input variables and performs well on large datasets. Additionally, RF calculates the relative value of every feature and creates an incredibly accurate classifier.
- The sample sizes used by each study to establish detection accuracy varied significantly. The sample size and the accuracy of the fake news detection method are strongly negatively correlated. This underscores how crucial it is to use a large number of samples when testing fake news detection methods. Further, the sample size utilized to determine the detection accuracy was a major contributor to heterogeneity.
- The findings of the study revealed the existence of heterogeneity and revealed a trivial publication bias, demonstrating the effectiveness of the inclusion and exclusion criteria in reducing bias.
- Finally, the meta-analysis results revealed that the efficacy of the various proposed approaches from the included primary studies was sufficient for the detection of online fake news.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kaplan, A.M.; Haenlein, M. Users of the world, unite! The challenges and opportunities of Social Media. Bus. Horiz. 2010, 53, 59–68. [Google Scholar] [CrossRef]
- Allcott, H.; Gentzkow, M. Social media and fake news in the 2016 election. J. Econ. Perspect. 2017, 31, 211–236. [Google Scholar] [CrossRef]
- McNair, B. Fake News: Falsehood, Fabrication and Fantasy in Journalism; Routledge: London, UK, 2017. [Google Scholar]
- Ni, S.; Li, J.; Kao, H.-Y. MVAN: Multi-View Attention Networks for Fake News Detection on Social Media. IEEE Access 2021, 9, 106907–106917. [Google Scholar] [CrossRef]
- Parikh, S.B.; Atrey, P.K. Media-rich fake news detection: A survey. In Proceedings of the Conference on Multimedia Information Processing And Retrieval (MIPR), Miami, FL, USA, 10–12 April 2018; IEEE: New York, NY, USA, 2018; pp. 436–441. [Google Scholar]
- Shu, K.; Sliva, A.; Wang, S.; Tang, J.; Liu, H. Fake news detection on social media: A data mining perspective. ACM SIGKDD Explor. Newsl. 2017, 19, 22–36. [Google Scholar] [CrossRef]
- Mahid, Z.I.; Manickam, S.; Karuppayah, S. Fake news on social media: Brief review on detection techniques. In Proceedings of the 2018 Fourth International Conference on Advances in Computing, Communication & Automation (ICACCA), Subang Jaya, Malaysia, 26–28 October 2018; IEEE: New York, NY, USA, 2019; pp. 1–5. [Google Scholar]
- Zafarani, R.; Zhou, X.; Shu, K.; Liu, H. Fake news research: Theories, detection strategies, and open problems. In Proceedings of the 25th International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; ACM: New York, NY, USA, 2019; pp. 3207–3208. [Google Scholar]
- Rafique, A.; Rustam, F.; Narra, M.; Mehmood, A.; Lee, E.; Ashraf, I. Comparative analysis of machine learning methods to detect fake news in an Urdu language corpus. PeerJ Comput. Sci. 2022, 8, e1004. [Google Scholar] [CrossRef]
- Zhang, X.; Ghorbani, A.A. An overview of online fake news: Characterization, detection, and discussion. Inf. Process. Manag. 2020, 57, 102025. [Google Scholar] [CrossRef]
- Galende, B.A.; Hernández-Peñaloza, G.; Uribe, S.; García, F.Á. Conspiracy or Not? A Deep Learning Approach to Spot It on Twitter. IEEE Access 2022, 10, 38370–38378. [Google Scholar] [CrossRef]
- Raza, S.; Ding, C. Fake news detection based on news content and social contexts: A transformer-based approach. Int. J. Data Sci. Anal. 2022, 13, 335–362. [Google Scholar] [CrossRef]
- Choi, J.; Ko, T.; Choi, Y.; Byun, H.; Kim, C.-K. Dynamic graph convolutional networks with attention mechanism for rumor detection on social media. PLoS ONE 2021, 16, e0256039. [Google Scholar]
- Bangyal, W.H.; Qasim, R.; Ahmad, Z.; Dar, H.; Rukhsar, L.; Aman, Z.; Ahmad, J. Detection of fake news text classification on COVID-19 using deep learning approaches. Comput. Math. Methods Med. 2021, 2021, 5514220. [Google Scholar] [CrossRef]
- Salem, F.K.A.; Al Feel, R.; Elbassuoni, S.; Ghannam, H.; Jaber, M.; Farah, M. Meta-learning for fake news detection surrounding the Syrian war. Patterns 2021, 2, 100369. [Google Scholar] [CrossRef] [PubMed]
- Kausar, S.; Tahir, B.; Mehmood, M.A. ProSOUL: A framework to identify propaganda from online Urdu content. IEEE Access 2020, 8, 186039–186054. [Google Scholar] [CrossRef]
- Khan, T.; Michalas, A. Seeing and Believing: Evaluating the Trustworthiness of Twitter Users. IEEE Access 2021, 9, 110505–110516. [Google Scholar] [CrossRef]
- Panagiotou, N.; Saravanou, A.; Gunopulos, D. News Monitor: A Framework for Exploring News in Real-Time. Data 2021, 7, 3. [Google Scholar] [CrossRef]
- Qasem, S.N.; Al-Sarem, M.; Saeed, F. An ensemble learning based approach for detecting and tracking COVID19 rumors. Comput. Mater. Contin. 2021, 70, 1721–1747. [Google Scholar]
- Truică, C.-O.; Apostol, E.-S. MisRoBÆRTa: Transformers versus Misinformation. Mathematics 2022, 10, 569. [Google Scholar] [CrossRef]
- Elhadad, M.K.; Li, K.F.; Gebali, F. Detecting misleading information on COVID-19. IEEE Access 2020, 8, 165201–165215. [Google Scholar] [CrossRef]
- Collins, B.; Hoang, D.T.; Nguyen, N.T.; Hwang, D. Trends in combating fake news on social media–a survey. J. Inf. Telecommun. 2021, 5, 247–266. [Google Scholar] [CrossRef]
- Choraś, M.; Demestichas, K.; Giełczyk, A.; Herrero, Á.; Ksieniewicz, P.; Remoundou, K.; Urda, D.; Woźniak, M. Advanced Machine Learning techniques for fake news (online disinformation) detection: A systematic mapping study. Appl. Soft Comput. 2021, 101, 107050. [Google Scholar] [CrossRef]
- Varlamis, I.; Michail, D.; Glykou, F.; Tsantilas, P. A Survey on the Use of Graph Convolutional Networks for Combating Fake News. Future Internet 2022, 14, 70. [Google Scholar] [CrossRef]
- Shahid, W.; Jamshidi, B.; Hakak, S.; Isah, H.; Khan, W.Z.; Khan, M.K.; Choo, K.-K.R. Detecting and Mitigating the Dissemination of Fake News: Challenges and Future Research Opportunities. IEEE Trans. Comput. Soc. Syst. 2022, 1–14. [Google Scholar] [CrossRef]
- Khan, S.; Hakak, S.; Deepa, N.; Dev, K.; Trelova, S. Detecting COVID-19 related Fake News using feature extraction. Front. Public Health 2022, 1967. [Google Scholar] [CrossRef]
- Lozano, M.G.; Brynielsson, J.; Franke, U.; Rosell, M.; Tjörnhammar, E.; Varga, S.; Vlassov, V. Veracity assessment of online data. Decis. Support Syst. 2020, 129, 113132. [Google Scholar] [CrossRef]
- Field, A.P.; Gillett, R. How to do a meta-analysis. Br. J. Math. Stat. Psychol. 2010, 63, 665–694. [Google Scholar] [CrossRef] [PubMed]
- Tembhurne, J.V.; Almin, M.M.; Diwan, T. Mc-DNN: Fake News Detection Using Multi-Channel Deep Neural Networks. Int. J. Semant. Web Inf. Syst. IJSWIS 2022, 18, 1–20. [Google Scholar] [CrossRef]
- Awan, M.J.; Yasin, A.; Nobanee, H.; Ali, A.A.; Shahzad, Z.; Nabeel, M.; Zain, A.M.; Shahzad, H.M.F. Fake news data exploration and analytics. Electronics 2021, 10, 2326. [Google Scholar] [CrossRef]
- Sharma, D.K.; Garg, S. IFND: A benchmark dataset for fake news detection. Complex Intell. Syst. 2021, 1–21. [Google Scholar] [CrossRef]
- Ghayoomi, M.; Mousavian, M. Deep transfer learning for COVID-19 fake news detection in Persian. Expert Syst. 2022, 39, e13008. [Google Scholar] [CrossRef]
- Do, T.H.; Berneman, M.; Patro, J.; Bekoulis, G.; Deligiannis, N. Context-aware deep Markov random fields for fake news detection. IEEE Access 2021, 9, 130042–130054. [Google Scholar] [CrossRef]
- Kumari, R.; Ashok, N.; Ghosal, T.; Ekbal, A. What the fake? Probing misinformation detection standing on the shoulder of novelty and emotion. Inf. Process. Manag. 2022, 59, 102740. [Google Scholar] [CrossRef]
- Ying, L.; Yu, H.; Wang, J.; Ji, Y.; Qian, S. Fake news detection via multi-modal topic memory network. IEEE Access 2021, 9, 132818–132829. [Google Scholar] [CrossRef]
- Vicario, M.D.; Quattrociocchi, W.; Scala, A.; Zollo, F. Polarization and fake news: Early warning of potential misinformation targets. ACM Trans. Web TWEB 2019, 13, 1–22. [Google Scholar] [CrossRef]
- Stitini, O.; Kaloun, S.; Bencharef, O. Towards the Detection of Fake News on Social Networks Contributing to the Improvement of Trust and Transparency in Recommendation Systems: Trends and Challenges. Information 2022, 13, 128. [Google Scholar] [CrossRef]
- Fayaz, M.; Khan, A.; Bilal, M.; Khan, S.U. Machine learning for fake news classification with optimal feature selection. Soft Comput. 2022, 1–9. [Google Scholar] [CrossRef]
- Islam, N.; Shaikh, A.; Qaiser, A.; Asiri, Y.; Almakdi, S.; Sulaiman, A.; Moazzam, V.; Babar, S.A. Ternion: An Autonomous Model for Fake News Detection. Appl. Sci. 2021, 11, 9292. [Google Scholar] [CrossRef]
- Hansrajh, A.; Adeliyi, T.T.; Wing, J. Detection of online fake news using blending ensemble learning. Sci. Program. 2021, 2021, 3434458. [Google Scholar] [CrossRef]
- Elsaeed, E.; Ouda, O.; Elmogy, M.M.; Atwan, A.; El-Daydamony, E. Detecting Fake News in Social Media Using Voting Classifier. IEEE Access 2021, 9, 161909–161925. [Google Scholar] [CrossRef]
- Verma, P.K.; Agrawal, P.; Amorim, I.; Prodan, R. WELFake: Word embedding over linguistic features for fake news detection. IEEE Trans. Comput. Soc. Syst. 2021, 8, 881–893. [Google Scholar] [CrossRef]
- Biradar, S.; Saumya, S.; Chauhan, A. Combating the infodemic: COVID-19 induced fake news recognition in social media networks. Complex Intell. Syst. 2022, 1–13. [Google Scholar] [CrossRef]
- Kanagavalli, N.; Priya, S.B. Social Networks Fake Account and Fake News Identification with Reliable Deep Learning. Intell. Autom. Soft Comput. 2022, 33, 191–205. [Google Scholar] [CrossRef]
- Galli, A.; Masciari, E.; Moscato, V.; Sperlí, G. A comprehensive Benchmark for fake news detection. J. Intell. Inf. Syst. 2022, 59, 237–261. [Google Scholar] [CrossRef] [PubMed]
- Sadeghi, F.; Bidgoly, A.J.; Amirkhani, H. Fake news detection on social media using a natural language inference approach. Multimed. Tools Appl. 2022, 81, 33801–33821. [Google Scholar] [CrossRef]
- Fouad, K.M.; Sabbeh, S.F.; Medhat, W. Arabic fake news detection using deep learning. CMC-Comput. Mater. Contin. 2022, 71, 3647–3665. [Google Scholar] [CrossRef]
- Nassif, A.B.; Elnagar, A.; Elgendy, O.; Afadar, Y. Arabic fake news detection based on deep contextualized embedding models. Neural Comput. Appl. 2022, 34, 16019–16032. [Google Scholar] [CrossRef] [PubMed]
- Lee, J.-W.; Kim, J.-H. Fake Sentence Detection Based on Transfer Learning: Applying to Korean COVID-19 Fake News. Appl. Sci. 2022, 12, 6402. [Google Scholar] [CrossRef]
- Jang, Y.; Park, C.-H.; Lee, D.-G.; Seo, Y.-S. Fake News Detection on Social Media: A Temporal-Based Approach. CMC-Comput. Mater. Contin. 2021, 69, 3563–3579. [Google Scholar] [CrossRef]
- Aslam, N.; Ullah Khan, I.; Alotaibi, F.S.; Aldaej, L.A.; Aldubaikil, A.K. Fake detect: A deep learning ensemble model for fake news detection. Complexity 2021, 2021, 5557784. [Google Scholar] [CrossRef]
- Moher, D.; Liberati, A.; Tetzlaff, J.; Altman, D.G.; the Prisma Group. Preferred reporting items for systematic reviews and meta-analyses: The PRISMA statement. Ann. Intern. Med. 2009, 151, 264–269. [Google Scholar] [CrossRef]
- Mikolajewicz, N.; Komarova, S.V. Meta-analytic methodology for basic research: A practical guide. Front. Physiol. 2019, 10, 203. [Google Scholar] [CrossRef]
- van Enst, W.A.; Scholten, R.J.; Whiting, P.; Zwinderman, A.H.; Hooft, L. Meta-epidemiologic analysis indicates that MEDLINE searches are sufficient for diagnostic test accuracy systematic reviews. J. Clin. Epidemiol. 2014, 67, 1192–1199. [Google Scholar] [CrossRef]
- Rice, D.B.; Kloda, L.A.; Levis, B.; Qi, B.; Kingsland, E.; Thombs, B.D. Are MEDLINE searches sufficient for systematic reviews and meta-analyses of the diagnostic accuracy of depression screening tools? A review of meta-analyses. J. Psychosom. Res. 2016, 87, 7–13. [Google Scholar] [CrossRef] [PubMed]
- Adeliyi, T.T.; Ogunsakin, R.E.; Adebiyi, M.; Olugbara, O. A meta-analysis of channel switching approaches for reducing zapping delay in internet protocol television. Indones. J. Electr. Eng. Comput. Sci. 2021, 22, 2502–4752. [Google Scholar] [CrossRef]
- Olugbara, C.T.; Letseka, M.; Ogunsakin, R.E.; Olugbara, O.O. Meta-analysis of factors influencing student acceptance of massive open online courses for open distance learning. Afr. J. Inf. Syst. 2021, 13, 5. [Google Scholar]
- Moher, D.; Shamseer, L.; Clarke, M.; Ghersi, D.; Liberati, A.; Petticrew, M.; Shekelle, P.; Stewart, L.A. Preferred reporting items for systematic review and meta-analysis protocols (PRISMA-P) 2015 statement. Syst. Rev. 2015, 4, g7647. [Google Scholar] [CrossRef] [PubMed]
- Borenstein, M.; Hedges, L.V.; Higgins, J.P.; Rothstein, H.R. A basic introduction to fixed-effect and random-effects models for meta-analysis. Res. Synth. Methods 2010, 1, 97–111. [Google Scholar] [CrossRef] [PubMed]
- Ogunsakin, R.E.; Olugbara, O.O.; Moyo, S.; Israel, C. Meta-analysis of studies on depression prevalence among diabetes mellitus patients in Africa. Heliyon 2021, 7, e07085. [Google Scholar] [CrossRef]
- Veroniki, A.A.; Jackson, D.; Viechtbauer, W.; Bender, R.; Bowden, J.; Knapp, G.; Kuss, O.; Higgins, J.P.; Langan, D.; Salanti, G. Methods to estimate the between-study variance and its uncertainty in meta-analysis. Res. Synth. Methods 2016, 7, 55–79. [Google Scholar] [CrossRef]
- Jarrahi, A.; Safari, L. Evaluating the effectiveness of publishers’ features in fake news detection on social media. Multimed. Tools Appl. 2022, 1–27. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, L.; Yang, Y.; Lian, T. SemSeq4FD: Integrating global semantic relationship and local sequential order to enhance text representation for fake news detection. Expert Syst. Appl. 2021, 166, 114090. [Google Scholar] [CrossRef]
- Abdelminaam, D.S.; Ismail, F.H.; Taha, M.; Taha, A.; Houssein, E.H.; Nabil, A. Coaid-deep: An optimized intelligent framework for automated detecting COVID-19 misleading information on twitter. IEEE Access 2021, 9, 27840–27867. [Google Scholar] [CrossRef]
- Seddari, N.; Derhab, A.; Belaoued, M.; Halboob, W.; Al-Muhtadi, J.; Bouras, A. A Hybrid Linguistic and Knowledge-Based Analysis Approach for Fake News Detection on Social Media. IEEE Access 2022, 10, 62097–62109. [Google Scholar] [CrossRef]
- Madani, Y.; Erritali, M.; Bouikhalene, B. Using artificial intelligence techniques for detecting COVID-19 epidemic fake news in Moroccan tweets. Results Phys. 2021, 25, 104266. [Google Scholar] [CrossRef]
- Endo, P.T.; Santos, G.L.; de Lima Xavier, M.E.; Nascimento Campos, G.R.; de Lima, L.C.; Silva, I.; Egli, A.; Lynn, T. Illusion of Truth: Analysing and Classifying COVID-19 Fake News in Brazilian Portuguese Language. Big Data Cogn. Comput. 2022, 6, 36. [Google Scholar] [CrossRef]
- Ying, L.; Yu, H.; Wang, J.; Ji, Y.; Qian, S. Multi-Level Multi-Modal Cross-Attention Network for Fake News Detection. IEEE Access 2021, 9, 132363–132373. [Google Scholar] [CrossRef]
- Ke, Z.; Li, Z.; Zhou, C.; Sheng, J.; Silamu, W.; Guo, Q. Rumor detection on social media via fused semantic information and a propagation heterogeneous graph. Symmetry 2020, 12, 1806. [Google Scholar] [CrossRef]
- Wu, L.; Rao, Y.; Nazir, A.; Jin, H. Discovering differential features: Adversarial learning for information credibility evaluation. Inf. Sci. 2020, 516, 453–473. [Google Scholar] [CrossRef]
- Abonizio, H.Q.; de Morais, J.I.; Tavares, G.M.; Barbon Junior, S. Language-independent fake news detection: English, Portuguese, and Spanish mutual features. Future Internet 2020, 12, 87. [Google Scholar] [CrossRef]
- Singh, B.; Sharma, D.K. Predicting image credibility in fake news over social media using multi-modal approach. Neural Comput. Appl. 2021, 1–15. [Google Scholar] [CrossRef]
- Amer, E.; Kwak, K.-S.; El-Sappagh, S. Context-Based Fake News Detection Model Relying on Deep Learning Models. Electronics 2022, 11, 1255. [Google Scholar] [CrossRef]
- Thaher, T.; Saheb, M.; Turabieh, H.; Chantar, H. Intelligent detection of false information in Arabic tweets utilizing hybrid harris hawks based feature selection and machine learning models. Symmetry 2021, 13, 556. [Google Scholar] [CrossRef]
- Gereme, F.; Zhu, W.; Ayall, T.; Alemu, D. Combating fake news in “low-resource” languages: Amharic fake news detection accompanied by resource crafting. Information 2021, 12, 20. [Google Scholar] [CrossRef]
- Kiruthika, N.; Thailambal, D.G. Dynamic Light Weight Recommendation System for Social Networking Analysis Using a Hybrid LSTM-SVM Classifier Algorithm. Opt. Mem. Neural Netw. 2022, 31, 59–75. [Google Scholar] [CrossRef]
- Ma, K.; Tang, C.; Zhang, W.; Cui, B.; Ji, K.; Chen, Z.; Abraham, A. DC-CNN: Dual-channel Convolutional Neural Networks with attention-pooling for fake news detection. Appl. Intell. 2022, 1–16. [Google Scholar] [CrossRef] [PubMed]
- Ahmed, B.; Ali, G.; Hussain, A.; Baseer, A.; Ahmed, J. Analysis of Text Feature Extractors using Deep Learning on Fake News. Eng. Technol. Appl. Sci. Res. 2021, 11, 7001–7005. [Google Scholar] [CrossRef]
- Tashtoush, Y.; Alrababah, B.; Darwish, O.; Maabreh, M.; Alsaedi, N. A Deep Learning Framework for Detection of COVID-19 Fake News on Social Media Platforms. Data 2022, 7, 65. [Google Scholar] [CrossRef]
- Tang, C.; Ma, K.; Cui, B.; Ji, K.; Abraham, A. Long text feature extraction network with data augmentation. Appl. Intell. 2022, 1–16. [Google Scholar] [CrossRef]
- Upadhyay, R.; Pasi, G.; Viviani, M. Vec4Cred: A model for health misinformation detection in web pages. Multimed. Tools Appl. 2022, 1–20. [Google Scholar] [CrossRef]
- Rohera, D.; Shethna, H.; Patel, K.; Thakker, U.; Tanwar, S.; Gupta, R.; Hong, W.-C.; Sharma, R. A Taxonomy of Fake News Classification Techniques: Survey and Implementation Aspects. IEEE Access 2022, 10, 30367–30394. [Google Scholar] [CrossRef]
- Al-Yahya, M.; Al-Khalifa, H.; Al-Baity, H.; Al Saeed, D.; Essam, A. Arabic fake news detection: Comparative study of neural networks and transformer-based approaches. Complexity 2021, 2021, 5516945. [Google Scholar] [CrossRef]
- Mertoğlu, U.; Genç, B. Automated fake news detection in the age of digital libraries. Inf. Technol. Libr. 2020, 39. [Google Scholar] [CrossRef]
- Xing, J.; Wang, S.; Zhang, X.; Ding, Y. HMBI: A New Hybrid Deep Model Based on Behavior Information for Fake News Detection. Wirel. Commun. Mob. Comput. 2021, 2021, 9076211. [Google Scholar] [CrossRef]
- Jiang, T.; Li, J.P.; Haq, A.U.; Saboor, A.; Ali, A. A novel stacking approach for accurate detection of fake news. IEEE Access 2021, 9, 22626–22639. [Google Scholar] [CrossRef]
- Varshney, D.; Vishwakarma, D.K. A unified approach of detecting misleading images via tracing its instances on web and analyzing its past context for the verification of multimedia content. Int. J. Multimed. Inf. Retr. 2022, 11, 445–459. [Google Scholar] [CrossRef]
- Paka, W.S.; Bansal, R.; Kaushik, A.; Sengupta, S.; Chakraborty, T. Cross-SEAN: A cross-stitch semi-supervised neural attention model for COVID-19 fake news detection. Appl. Soft Comput. 2021, 107, 107393. [Google Scholar] [CrossRef]
- Ilie, V.-I.; Truică, C.-O.; Apostol, E.-S.; Paschke, A. Context-Aware Misinformation Detection: A Benchmark of Deep Learning Architectures Using Word Embeddings. IEEE Access 2021, 9, 162122–162146. [Google Scholar] [CrossRef]
- Kaliyar, R.K.; Goswami, A.; Narang, P. EchoFakeD: Improving fake news detection in social media with an efficient deep neural network. Neural Comput. Appl. 2021, 33, 8597–8613. [Google Scholar] [CrossRef]
- Akhter, M.P.; Zheng, J.; Afzal, F.; Lin, H.; Riaz, S.; Mehmood, A. Supervised ensemble learning methods towards automatically filtering Urdu fake news within social media. PeerJ Comput. Sci. 2021, 7, e425. [Google Scholar] [CrossRef]
- Ilias, L.; Roussaki, I. Detecting malicious activity in Twitter using deep learning techniques. Appl. Soft Comput. 2021, 107, 107360. [Google Scholar] [CrossRef]
- Waheeb, S.A.; Khan, N.A.; Shang, X. Topic Modeling and Sentiment Analysis of Online Education in the COVID-19 Era Using Social Networks Based Datasets. Electronics 2022, 11, 715. [Google Scholar] [CrossRef]
- Fang, Y.; Gao, J.; Huang, C.; Peng, H.; Wu, R. Self multi-head attention-based convolutional neural networks for fake news detection. PLoS ONE 2019, 14, e0222713. [Google Scholar] [CrossRef]
- Amoudi, G.; Albalawi, R.; Baothman, F.; Jamal, A.; Alghamdi, H.; Alhothali, A. Arabic rumor detection: A comparative study. Alex. Eng. J. 2022, 61, 12511–12523. [Google Scholar] [CrossRef]
- Karnyoto, A.S.; Sun, C.; Liu, B.; Wang, X. TB-BCG: Topic-Based BART Counterfeit Generator for Fake News Detection. Mathematics 2022, 10, 585. [Google Scholar] [CrossRef]
- Dixit, D.K.; Bhagat, A.; Dangi, D. Automating fake news detection using PPCA and levy flight-based LSTM. Soft Comput. 2022, 26, 12545–12557. [Google Scholar] [CrossRef] [PubMed]
- Kaliyar, R.K.; Goswami, A.; Narang, P. FakeBERT: Fake news detection in social media with a BERT-based deep learning approach. Multimed. Tools Appl. 2021, 80, 11765–11788. [Google Scholar] [CrossRef] [PubMed]
- Umer, M.; Imtiaz, Z.; Ullah, S.; Mehmood, A.; Choi, G.S.; On, B.-W. Fake news stance detection using deep learning architecture (CNN-LSTM). IEEE Access 2020, 8, 156695–156706. [Google Scholar] [CrossRef]
- Dixit, D.K.; Bhagat, A.; Dangi, D. Fake News Classification Using a Fuzzy Convolutional Recurrent Neural Network. CMC-Comput. Mater. Contin. 2022, 71, 5733–5750. [Google Scholar] [CrossRef]
- Olaleye, T.; Abayomi-Alli, A.; Adesemowo, K.; Arogundade, O.T.; Misra, S.; Kose, U. SCLAVOEM: Hyper parameter optimization approach to predictive modelling of COVID-19 infodemic tweets using smote and classifier vote ensemble. Soft Comput. 2022, 15, 1–20. [Google Scholar] [CrossRef]
- Kasnesis, P.; Toumanidis, L.; Patrikakis, C.Z. Combating Fake News with Transformers: A Comparative Analysis of Stance Detection and Subjectivity Analysis. Information 2021, 12, 409. [Google Scholar] [CrossRef]
- Kapusta, J.; Obonya, J. Improvement of misleading and fake news classification for flective languages by morphological group analysis. Informatics 2020, 7, 4. [Google Scholar] [CrossRef]
- Althubiti, S.A.; Alenezi, F.; Mansour, R.F. Natural Language Processing with Optimal Deep Learning Based Fake News Classification. CMC-Comput. Mater. Contin. 2022, 73, 3529–3544. [Google Scholar] [CrossRef]
- Lai, C.-M.; Chen, M.-H.; Kristiani, E.; Verma, V.K.; Yang, C.-T. Fake News Classification Based on Content Level Features. Appl. Sci. 2022, 12, 1116. [Google Scholar] [CrossRef]
- Karande, H.; Walambe, R.; Benjamin, V.; Kotecha, K.; Raghu, T. Stance detection with BERT embeddings for credibility analysis of information on social media. PeerJ Comput. Sci. 2021, 7, e467. [Google Scholar] [CrossRef]
- Himdi, H.; Weir, G.; Assiri, F.; Al-Barhamtoshy, H. Arabic fake news detection based on textual analysis. Arab. J. Sci. Eng. 2022, 1–17, 10453–10469. [Google Scholar] [CrossRef] [PubMed]
- Lee, S. Detection of Political Manipulation through Unsupervised Learning. KSII Trans. Internet Inf. Syst. TIIS 2019, 13, 1825–1844. [Google Scholar]
- Palani, B.; Elango, S.; Viswanathan, K.V. CB-Fake: A multimodal deep learning framework for automatic fake news detection using capsule neural network and BERT. Multimed. Tools Appl. 2022, 81, 5587–5620. [Google Scholar] [CrossRef]
- Cheng, M.; Li, Y.; Nazarian, S.; Bogdan, P. From rumor to genetic mutation detection with explanations: A GAN approach. Sci. Rep. 2021, 11, 5861. [Google Scholar] [CrossRef]
- Dong, X.; Victor, U.; Qian, L. Two-path deep semisupervised learning for timely fake news detection. IEEE Trans. Comput. Soc. Syst. 2020, 7, 1386–1398. [Google Scholar] [CrossRef]
- Ayoub, J.; Yang, X.J.; Zhou, F. Combat COVID-19 infodemic using explainable natural language processing models. Inf. Process. Manag. 2021, 58, 102569. [Google Scholar] [CrossRef]
- Buzea, M.C.; Trausan-Matu, S.; Rebedea, T. Automatic fake news detection for Romanian online news. Information 2022, 13, 151. [Google Scholar] [CrossRef]
- Alouffi, B.; Alharbi, A.; Sahal, R.; Saleh, H. An Optimized Hybrid Deep Learning Model to Detect COVID-19 Misleading Information. Comput. Intell. Neurosci. 2021, 2021, 9615034. [Google Scholar] [CrossRef]
- Rajapaksha, P.; Farahbakhsh, R.; Crespi, N. BERT, XLNet or RoBERTa: The Best Transfer Learning Model to Detect Clickbaits. IEEE Access 2021, 9, 154704–154716. [Google Scholar] [CrossRef]
- Saleh, H.; Alharbi, A.; Alsamhi, S.H. OPCNN-FAKE: Optimized convolutional neural network for fake news detection. IEEE Access 2021, 9, 129471–129489. [Google Scholar] [CrossRef]
- Goldani, M.H.; Momtazi, S.; Safabakhsh, R. Detecting fake news with capsule neural networks. Appl. Soft Comput. 2021, 101, 106991. [Google Scholar] [CrossRef]
- Kula, S.; Kozik, R.; Choraś, M. Implementation of the BERT-derived architectures to tackle disinformation challenges. Neural Comput. Appl. 2021, 1–13. [Google Scholar] [CrossRef]
- Das, S.D.; Basak, A.; Dutta, S. A heuristic-driven uncertainty based ensemble framework for fake news detection in tweets and news articles. Neurocomputing 2022, 491, 607–620. [Google Scholar] [CrossRef]
- Malla, S.; Alphonse, P. Fake or real news about COVID-19? Pretrained transformer model to detect potential misleading news. Eur. Phys. J. Spec. Top. 2022, 1–10. [Google Scholar] [CrossRef]
- Ghanem, B.; Rosso, P.; Rangel, F. An emotional analysis of false information in social media and news articles. ACM Trans. Internet Technol. TOIT 2020, 20, 1–18. [Google Scholar] [CrossRef]
- Apolinario-Arzube, Ó.; García-Díaz, J.A.; Medina-Moreira, J.; Luna-Aveiga, H.; Valencia-García, R. Comparing deep-learning architectures and traditional machine-learning approaches for satire identification in Spanish tweets. Mathematics 2020, 8, 2075. [Google Scholar] [CrossRef]
- Qureshi, K.A.; Malick, R.A.S.; Sabih, M.; Cherifi, H. Complex Network and Source Inspired COVID-19 Fake News Classification on Twitter. IEEE Access 2021, 9, 139636–139656. [Google Scholar] [CrossRef]
- Hayawi, K.; Mathew, S.; Venugopal, N.; Masud, M.M.; Ho, P.-H. DeeProBot: A hybrid deep neural network model for social bot detection based on user profile data. Soc. Netw. Anal. Min. 2022, 12, 43. [Google Scholar] [CrossRef]
- Rahman, M.; Halder, S.; Uddin, M.; Acharjee, U.K. An efficient hybrid system for anomaly detection in social networks. CyberSecurity 2021, 4, 10. [Google Scholar] [CrossRef]
- Ghaleb, F.A.; Alsaedi, M.; Saeed, F.; Ahmad, J.; Alasli, M. Cyber Threat Intelligence-Based Malicious URL Detection Model Using Ensemble Learning. Sensors 2022, 22, 3373. [Google Scholar] [PubMed]
- Jain, V.; Kaliyar, R.K.; Goswami, A.; Narang, P.; Sharma, Y. AENeT: An attention-enabled neural architecture for fake news detection using contextual features. Neural Comput. Appl. 2022, 34, 771–782. [Google Scholar] [CrossRef]
- Bezerra, R.; Fabio, J. Content-based fake news classification through modified voting ensemble. J. Inf. Telecommun. 2021, 5, 499–513. [Google Scholar]
- Agarwal, I.; Rana, D.; Shaikh, M.; Poudel, S. Spatio-temporal approach for classification of COVID-19 pandemic fake news. Soc. Netw. Anal. Min. 2022, 12, 68. [Google Scholar] [CrossRef]
- Toivanen, P.; Nelimarkka, M.; Valaskivi, K. Remediation in the hybrid media environment: Understanding countermedia in context. New Media Soc. 2022, 24, 2127–2152. [Google Scholar] [CrossRef]
- Mahabub, A. A robust technique of fake news detection using Ensemble Voting Classifier and comparison with other classifiers. SN Appl. Sci. 2020, 2, 525. [Google Scholar] [CrossRef]
- Chintalapudi, N.; Battineni, G.; Amenta, F. Sentimental analysis of COVID-19 tweets using deep learning models. Infect. Dis. Rep. 2021, 13, 329–339. [Google Scholar] [CrossRef]
- Al-Ahmad, B.; Al-Zoubi, A.M.; Abu Khurma, R.; Aljarah, I. An evolutionary fake news detection method for COVID-19 pandemic information. Symmetry 2021, 13, 1091. [Google Scholar] [CrossRef]
- Pujahari, A.; Sisodia, D.S. Clickbait detection using multiple categorisation techniques. J. Inf. Sci. 2021, 47, 118–128. [Google Scholar] [CrossRef]
- Albahar, M. A hybrid model for fake news detection: Leveraging news content and user comments in fake news. IET Inf. Secur. 2021, 15, 169–177. [Google Scholar] [CrossRef]
- Gayakwad, M.; Patil, S.; Kadam, A.; Joshi, S.; Kotecha, K.; Joshi, R.; Pandya, S.; Gonge, S.; Rathod, S.; Kadam, K. Credibility Analysis of User-Designed Content Using Machine Learning Techniques. Appl. Syst. Innov. 2022, 5, 43. [Google Scholar] [CrossRef]
- Rastogi, S.; Bansal, D. Disinformation detection on social media: An integrated approach. Multimed. Tools Appl. 2022, 81, 40675–40707. [Google Scholar] [CrossRef]
- Jang, Y.; Park, C.-H.; Seo, Y.-S. Fake news analysis modeling using quote retweet. Electronics 2019, 8, 1377. [Google Scholar] [CrossRef]
- Shao, C.; Chen, X. Deep-learning-based financial message sentiment classification in business management. Comput. Intell. Neurosci. 2022, 2022, 3888675. [Google Scholar] [CrossRef]
- Sansonetti, G.; Gasparetti, F.; D’aniello, G.; Micarelli, A. Unreliable users detection in social media: Deep learning techniques for automatic detection. IEEE Access 2020, 8, 213154–213167. [Google Scholar] [CrossRef]
- Mohammed, M.; Sha’aban, A.; Jatau, A.I.; Yunusa, I.; Isa, A.M.; Wada, A.S.; Obamiro, K.; Zainal, H.; Ibrahim, B. Assessment of COVID-19 information overload among the general public. J. Racial Ethn. Health Disparities 2022, 9, 184–192. [Google Scholar] [CrossRef]
- Coste, C.I.; Bufnea, D. Advances in Clickbait and Fake News Detection Using New Language-independent Strategies. J. Commun. Softw. Syst. 2021, 17, 270–280. [Google Scholar] [CrossRef]
- Alonso-Bartolome, S.; Segura-Bedmar, I. Multimodal Fake News Detection. Expert Syst. Appl. 2021, 13, 284. [Google Scholar]
- Ozbay, F.A.; Alatas, B. A novel approach for detection of fake news on social media using metaheuristic optimization algorithms. Elektron. Ir. Elektrotechnika 2019, 25, 62–67. [Google Scholar] [CrossRef]
- Ahmad, I.; Yousaf, M.; Yousaf, S.; Ahmad, M.O. Fake news detection using machine learning ensemble methods. Complexity 2020, 2020, 8885861. [Google Scholar] [CrossRef]
- Shang, L.; Zhang, Y.; Zhang, D.; Wang, D. Fauxward: A graph neural network approach to fauxtography detection using social media comments. Soc. Netw. Anal. Min. 2020, 10, 76. [Google Scholar] [CrossRef]
- Mazzeo, V.; Rapisarda, A.; Giuffrida, G. Detection of fake news on COVID-19 on Web Search Engines. Front. Phys. 2021, 351, 685730. [Google Scholar] [CrossRef]
- Mathur, M.B.; Vander Weele, T.J. Estimating publication bias in meta-analyses of peer-reviewed studies: A meta-meta-analysis across disciplines and journal tiers. Res. Synth. Methods 2021, 12, 176–191. [Google Scholar] [CrossRef] [PubMed]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Criterion | |
|---|---|
| Exclusion Criteria | |
| EC1 | Papers in which only the abstract is available |
| EC2 | Review and survey papers |
| EC3 | Duplicate records |
| EC4 | Papers not written in the English language |
| EC5 | Papers not relevant to fake news detection |
| EC6 | Papers not applying the DL, ML, or ensemble approaches |
| EC7 | Papers not reporting sample size |
| EC8 | Papers not reporting fake news detection results in terms of accuracy |
| Inclusion criteria | |
| IC1 | Articles published in English |
| IC2 | Papers stating the fake news detection method using DL, ML, or ensemble approaches on linguistic or visual based data |
| IC3 | Papers providing clear information about the datasets and sample size |
| IC4 | Papers providing the detection results in terms of accuracy |
| Extraction Element | Contents | Type |
|---|---|---|
| 1 | Title | Title of the article |
| 2 | Author | The authors of the article |
| 3 | Country | The country of the research institute |
| 4 | Year | The year of publication |
| 5 | Approach | DL, ML, Ensemble DL, Ensemble ML, Hybrid, and Sentiment analysis |
| 6 | Method | For instance, BiLSTM, CNN, LSTM, RF, LR, SVM, and NB |
| 7 | Dataset | List of the datasets used for evaluation |
| 8 | Sample size | The number of samples used for detection |
| 9 | Accuracy | The average accuracy of the results |
| Meta-Analysis Summary: Random-Effects Model: DerSimonian–Laird | Heterogeneity | τ2 | 3.440 | I2 | 75.27 | ||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| Study (n = 125) | Effect Size | [95% CI] | Weight | Study | Effect Size | [95% CI] | Weight | ||||
| (Sadeghi, Bidgoly, and Amirkhani 2022) | [46] | −10.230 | −12.692 | −7.769 | 0.730 | (Khan et al. 2022) | [26] | −7.181 | −9.265 | −5.097 | 0.800 |
| (Jarrahi and Safari 2022) | [62] | −9.698 | −11.669 | −7.727 | 0.820 | (Stitini, Kaloun, and Bencharef 2022) | [37] | −6.132 | −8.135 | −4.130 | 0.820 |
| (Ni, Li and Kao 2021) | [4] | −7.129 | −9.170 | −5.088 | 0.810 | (Wang et al. 2021) | [63] | −10.617 | −12.699 | −8.534 | 0.800 |
| (Fouad, Sabbeh, and Medhat 2022) | [47] | −8.713 | −10.976 | −6.449 | 0.770 | (Abdelminaam et al. 2021) | [64] | −12.803 | −14.901 | −10.705 | 0.800 |
| (Seddari et al. 2022) | [65] | −4.362 | −6.393 | −2.332 | 0.810 | (Madani, Erritali, and Bouikhalene 2021) | [66] | −7.836 | −10.042 | −5.631 | 0.780 |
| (Tembhurne, Almin, and Diwan 2022) | [29] | −11.199 | −13.189 | −9.209 | 0.820 | (Endo et al. 2022) | [67] | −9.402 | −11.423 | −7.380 | 0.810 |
| (Ying et al. 2021b) | [68] | −9.620 | −11.714 | −7.526 | 0.800 | (Ke et al. 2020) | [69] | −8.930 | −10.970 | −6.889 | 0.810 |
| (Do et al. 2021) | [33] | −9.558 | −11.737 | −7.379 | 0.780 | (Wu et al. 2020) | [70] | −11.147 | −13.797 | −8.497 | 0.700 |
| (Abonizio et al. 2020) | [71] | −9.362 | −11.484 | −7.240 | 0.800 | (Singh and Sharma 2021) | [72] | −9.488 | −11.636 | −7.341 | 0.790 |
| (Amer, Kwak, and El-Sappagh 2022) | [73] | −10.722 | −12.692 | −8.752 | 0.820 | (Thaher et al. 2021) | [74] | −7.734 | −9.905 | −5.562 | 0.790 |
| (Ying et al. 2021a) | [35] | −9.760 | −11.843 | −7.676 | 0.800 | (Gereme et al. 2021) | [75] | −8.258 | −10.226 | −6.291 | 0.820 |
| (Jang et al. 2021) | [50] | −11.400 | −13.517 | −9.283 | 0.800 | (Galende et al. 2022) | [11] | −8.610 | −10.775 | −6.446 | 0.790 |
| (Elsaeed et al. 2021) | [41] | −11.156 | −13.160 | −9.151 | 0.820 | (Raza and Ding 2022) | [12] | −8.023 | −10.297 | −5.748 | 0.770 |
| (Galli et al. 2022) | [45] | −6.483 | −8.726 | −4.240 | 0.770 | (Kiruthika and Thailambal 2022) | [76] | −8.740 | −10.932 | −6.549 | 0.780 |
| (Vicario et al. 2019) | [36] | −15.764 | −17.819 | −13.710 | 0.810 | (Ma et al. 2022) | [77] | −10.665 | −12.661 | −8.670 | 0.820 |
| (Verma et al. 2021) | [42] | −11.220 | −13.213 | −9.227 | 0.820 | (Choi et al. 2021) | [13] | −8.993 | −11.100 | −6.887 | 0.800 |
| (Ahmed et al. 2021) | [78] | −10.231 | −12.213 | −8.249 | 0.820 | (Bangyal et al. 2021) | [14] | −9.261 | −11.251 | −7.271 | 0.820 |
| (Tashtoush et al. 2022) | [79] | −10.03 | −12.049 | −8.010 | 0.810 | (Tang et al. 2022) | [80] | −10.593 | −12.589 | −8.598 | 0.820 |
| (Wang et al. 2021) | [63] | −9.090 | −11.174 | −7.007 | 0.800 | (Upadhyay, Pasi, and Viviani 2022) | [81] | −9.546 | −11.602 | −7.490 | 0.810 |
| (Rohera et al. 2022) | [82] | −8.834 | −10.874 | −6.794 | 0.810 | (Al-Yahya et al. 2021) | [83] | −12.435 | −14.712 | −10.158 | 0.770 |
| (Mertoğlu and Genç 2020) | [84] | −11.385 | −13.377 | −9.393 | 0.820 | (Xing et al. 2021) | [85] | −10.180 | −12.988 | −7.371 | 0.670 |
| (Jiang et al. 2021) | [86] | −10.864 | −12.844 | −8.884 | 0.820 | (Varshney and Vishwakarma 2022) | [87] | −9.406 | −11.376 | −7.436 | 0.820 |
| (Paka et al. 2021) | [88] | −10.767 | −12.774 | −8.761 | 0.820 | (Ilie et al. 2021) | [89] | −11.645 | −13.739 | −9.551 | 0.800 |
| (Kaliyar, Goswami, and Narang 2021a) | [90] | −5.279 | −7.324 | −3.234 | 0.810 | (Upadhyay, Pasi, and Viviani 2022) | [81] | −9.246 | −11.271 | −7.221 | 0.810 |
| (Akhter et al. 2021) | [91] | −8.236 | −10.473 | −5.999 | 0.770 | (Kausar, Tahir, and Mehmood 2020) | [16] | −9.451 | −11.505 | −7.396 | 0.810 |
| (Sharma and Garg 2021) | [31] | −11.010 | −13.032 | −8.989 | 0.801 | (Ilias and Roussaki 2021) | [92] | −15.732 | −17.888 | −13.575 | 0.790 |
| (Awan et al. 2021) | [30] | −10.140 | −12.105 | −8.175 | 0.830 | (Waheeb, Khan, and Shang 2022) | [93] | −13.927 | −16.171 | −11.683 | 0.770 |
| (Ghayoomi and Mousavian 2022) | [32] | −9.671 | −11.690 | −7.653 | 0.820 | (Salem et al. 2021) | [15] | −6.805 | −8.884 | −4.726 | 0.800 |
| (Fang et al. 2019) | [94] | −10.043 | −12.048 | −8.039 | 0.820 | (Amoudi et al. 2022) | [95] | −8.589 | −10.781 | −6.398 | 0.780 |
| (Karnyoto et al. 2022) | [96] | −7.449 | −9.449 | −5.449 | 0.820 | (Dixit, Bhagat, and Dangi 2022a) | [97] | −11.095 | −13.069 | −9.120 | 0.820 |
| (Kaliyar, Goswami, and Narang 2021b) | [98] | −9.954 | −11.925 | −7.983 | 0.820 | (Umer et al. 2020) | [99] | −11.253 | −13.234 | −9.271 | 0.820 |
| (Dixit, Bhagat, and Dangi 2022b) | [100] | −11.407 | −13.622 | −9.192 | 0.780 | (Olaleye et al. 2022) | [101] | −12.240 | −14.360 | −10.120 | 0.800 |
| (Islam et al. 2021) | [39] | −10.009 | −12.039 | −7.979 | 0.810 | (Kasnesis, Toumanidis, and Patrikakis 2021) | [102] | −9.847 | −11.823 | −7.870 | 0.820 |
| (Kapusta and Obonya 2020) | [103] | −5.358 | −7.627 | −3.090 | 0.770 | (Althubiti, Alenezi, and Mansour 2022) | [104] | −10.83 | −12.795 | −8.865 | 0.830 |
| (Fayaz et al. 2022) | [38] | −10.740 | −12.727 | −8.753 | 0.820 | (Qasem, Al-Sarem, and Saeed 2021) | [19] | −8.269 | −10.306 | −6.232 | 0.810 |
| (Lai et al. 2022) | [105] | −10.646 | −12.626 | −8.666 | 0.820 | (Khan and Michalas 2021) | [17] | −10.861 | −12.861 | −8.860 | 0.820 |
| (Karande et al. 2021) | [106] | −8.802 | −10.810 | −6.794 | 0.820 | (Truică and Apostol 2022) | [20] | −11.591 | −13.629 | −9.553 | 0.810 |
| (Nassif et al. 2022) | [48] | −9.222 | −11.194 | −7.250 | 0.820 | (Panagiotou, Saravanou, and Gunopulos 2021) | [18] | −6.296 | −8.341 | −4.251 | 0.810 |
| (Himdi et al. 2022) | [107] | −7.236 | −9.442 | −5.030 | 0.780 | (Lee 2019) | [108] | −13.993 | −16.034 | −11.952 | 0.810 |
| (Palani, Elango, and Viswanathan K 2022) | [109] | −10.025 | −12.062 | −7.987 | 0.810 | (Cheng et al. 2021) | [110] | −9.770 | −12.118 | −7.423 | 0.750 |
| (Biradar, Saumya, and Chauhan 2022) | [43] | −9.308 | −11.299 | −7.318 | 0.820 | (Elhadad, Li, and Gebali 2020) | [21] | −8.924 | −10.887 | −6.961 | 0.830 |
| (Dong, Victor and Qian 2020) | [111] | −11.869 | −14.179 | −9.559 | 0.760 | (Ayoub, Yang, and Zhou 2021) | [112] | −9.372 | −11.338 | −7.406 | 0.830 |
| (Buzea, Trausan-Matu, and Rebedea 2022) | [113] | −10.190 | −12.169 | −8.211 | 0.820 | (Alouffi et al. 2021) | [114] | −7.004 | −8.967 | −5.041 | 0.830 |
| (Hansrajh, Adeliyi, and Wing 2021) | [40] | −11.191 | −13.386 | −8.995 | 0.780 | (Rajapaksha, Farahbakhsh, and Crespi 2021) | [115] | −10.780 | −12.902 | −8.658 | 0.800 |
| (Saleh, Alharbi, and Alsamhi 2021) | [116] | −11.585 | −13.689 | −9.481 | 0.800 | (Kumari et al. 2022) | [34] | −13.171 | −15.226 | −11.116 | 0.810 |
| (Goldani, Momtazi, and Safabakhsh 2021) | [117] | −11.302 | −13.650 | −8.954 | 0.750 | (Kula, Kozik, and Choraś 2021) | [118] | −9.779 | −11.750 | −7.808 | 0.820 |
| (Das, Basak, and Dutta 2022) | [119] | −10.433 | −12.446 | −8.420 | 0.820 | (Malla and Alphonse 2022) | [120] | −9.289 | −11.260 | −7.318 | 0.820 |
| (Ghanem, Rosso, and Rangel 2020) | [121] | −12.442 | −14.744 | −10.140 | 0.760 | (Apolinario-Arzube et al. 2020) | [122] | −9.328 | −11.431 | −7.225 | 0.800 |
| (Qureshi et al. 2021) | [123] | −10.928 | −12.952 | −8.904 | 0.810 | (Hayawi et al. 2022) | [124] | −11.366 | −13.409 | −9.322 | 0.810 |
| (Rafique et al. 2022) | [9] | −6.853 | −8.865 | −4.841 | 0.820 | (Rahman et al. 2021) | [125] | −10.303 | −12.286 | −8.320 | 0.820 |
| (Aslam et al. 2021) | [51] | −8.532 | −10.600 | −6.463 | 0.810 | (Ghaleb et al. 2022) | [126] | −13.414 | −15.401 | −11.427 | 0.820 |
| (Jain et al. 2022) | [127] | −10.002 | −12.879 | −7.124 | 0.660 | (Bezerra and Fabio 2021) | [128] | −10.909 | −13.040 | −8.778 | 0.790 |
| (Agarwal et al. 2022) | [129] | −7.998 | −9.985 | −6.012 | 0.820 | (Toivanen, Nelimarkka, and Valaskivi 2022) | [130] | −9.105 | −11.231 | −6.979 | 0.790 |
| (Mahabub 2020) | [131] | −8.836 | −10.852 | −6.820 | 0.820 | (Chintalapudi, Battineni, and Amenta 2021) | [132] | −8.152 | −10.230 | −6.074 | 0.800 |
| (Al-Ahmad et al. 2021) | [133] | −8.594 | −10.851 | −6.337 | 0.770 | (Pujahari and Sisodia 2021) | [134] | −9.711 | −11.701 | −7.721 | 0.820 |
| (Albahar 2021) | [135] | −14.655 | −16.772 | −12.537 | 0.800 | (Gayakwad et al. 2022) | [136] | −16.686 | −18.684 | −14.689 | 0.820 |
| (Lee and Kim 2022) | [49] | −11.200 | −13.408 | −8.992 | 0.780 | (Rastogi and Bansal 2022) | [137] | −8.016 | −9.986 | −6.046 | 0.820 |
| (Jang, Park, and Seo 2019) | [138] | −8.034 | −10.216 | −5.852 | 0.780 | (Shao and Chen 2022) | [139] | −7.815 | −9.997 | −5.633 | 0.780 |
| (Sansonetti et al. 2020) | [140] | −13.442 | −15.483 | −11.401 | 0.810 | (Mohammed et al. 2022) | [141] | −6.858 | −9.363 | −4.354 | 0.720 |
| (Coste and Bufnea 2021) | [142] | −7.380 | −9.661 | −5.100 | 0.770 | (Khan et al. 2022) | [26] | −7.181 | −9.265 | −5.097 | 0.800 |
| (Alonso-Bartolome and Segura-Bedmar 2021) | [143] | −13.573 | −15.674 | −11.472 | 0.800 | (Stitini, Kaloun, and Bencharef 2022) | [37] | −6.132 | −8.135 | −4.130 | 0.820 |
| (Ozbay and Alatas 2019) | [144] | −9.561 | −11.602 | −7.520 | 0.810 | (Wang et al. 2021) | [63] | −10.617 | −12.699 | −8.534 | 0.800 |
| (Kanagavalli and Priya 2022) | [44] | −9.474 | −11.448 | −7.500 | 0.820 | (Abdelminaam et al. 2021) | [64] | −12.803 | −14.901 | −10.705 | 0.800 |
| (Ahmad et al. 2020) | [145] | −11.303 | −13.357 | −9.248 | 0.810 | (Madani, Erritali, and Bouikhalene 2021) | [66] | −7.836 | −10.042 | −5.631 | 0.780 |
| (Shang et al. 2020) | [146] | −15.803 | −18.094 | −13.512 | 0.760 | (Endo et al. 2022) | [67] | −9.402 | −11.423 | −7.380 | 0.810 |
| (Mazzeo, Rapisarda, and Giuffrida 2021) | [147] | −8.157 | −10.158 | −6.157 | 0.820 | ||||||
| Theta | −9.942 | −10.317 | −9.567 | Test of homogeneity: Q = chi2(124) = 501.340 | |||||||
| Test of theta = 0 | z = −51.910 | Prob > |z| = 0.000 Prob > Q = 0.000 | |||||||||
| Group | Number of Studies | ES 95% CI | Q | I2 | Test for Heterogeneity | ||
|---|---|---|---|---|---|---|---|
| df | p-Value | ||||||
| Deep learning | 60 | −10.08 [−10.60, −9.58] | 202.90 | 70.92 | 59 | 0.000 * | |
| Ensemble deep learning | 11 | −10.03 [−10.65, −9.40] | 8.70 | 0.00 | 10 | 0.561 | |
| Ensemble machine learning | 16 | −10.23 [−11.00, 9.46] | 34.29 | 56.25 | 15 | 0.003 | |
| Hybrid | 10 | −11.13 [12.36, −9.90] | 38.22 | 76.45 | 9 | 0.000 * | |
| Machine learning | 27 | −8.98 [−10.04, −7.91] | 181.83 | 85.70 | 26 | 0.000 * | |
| Sentiment analysis | 1 | −8.15 [−10.23, −6.07] | 0.00 | 0.00 | 0 | - | |
| Overall | 125 | −9.94 [−10.32, −9.57] | 501.34 | 75.27 | 124 | 0.000 * | |
| Sources of Heterogeneity | Estimates | Std. Error | 95% CI | p-Value |
|---|---|---|---|---|
| Year | 0.361 | 0.201 | [−0.037, 0.756] | 0.075 |
| Approach | −0.070 | 0.111 | [−0.290, 0.149] | 0.526 |
| Sample size | −0.000 | 0.000 | [−0.000, −0.000] | 0.000 * |
| Constant | −734.199 | 406.931 | [−1539.826, −71.429] | 0.074 |
| Year | 0.361 | 0.201 | [−0.037, 0.756] | 0.075 |
| Parameter | Estimate | Std. Error | t | p | 95% Conf. Interval | |
|---|---|---|---|---|---|---|
| Slope | −9.641 | 2.723 | −3.54 | 0.001 | −15.031 | −4.250 |
| Bias | −0.282 | 2.545 | −0.11 | 0.912 | −5.319 | 4.755 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Thompson, R.C.; Joseph, S.; Adeliyi, T.T. A Systematic Literature Review and Meta-Analysis of Studies on Online Fake News Detection. Information 2022, 13, 527. https://doi.org/10.3390/info13110527
Thompson RC, Joseph S, Adeliyi TT. A Systematic Literature Review and Meta-Analysis of Studies on Online Fake News Detection. Information. 2022; 13(11):527. https://doi.org/10.3390/info13110527
Chicago/Turabian StyleThompson, Robyn C., Seena Joseph, and Timothy T. Adeliyi. 2022. "A Systematic Literature Review and Meta-Analysis of Studies on Online Fake News Detection" Information 13, no. 11: 527. https://doi.org/10.3390/info13110527
APA StyleThompson, R. C., Joseph, S., & Adeliyi, T. T. (2022). A Systematic Literature Review and Meta-Analysis of Studies on Online Fake News Detection. Information, 13(11), 527. https://doi.org/10.3390/info13110527