

Multi-Microworld Conversational Agent with RDF Knowledge Graph Integration


Abstract
:1. Introduction
- Introduce a personal assistant built for the Romanian language on top of the RASA framework that supports concurrently multiple microworlds, each targeting a different domain and in which additional microworlds can easily be plugged in;
- Propose a novel processing pipeline, custom language models, and syntactic features to improve intent classification. This approach is, to the best of our knowledge, a unique take on the chatbot’s architecture and can be further used to improve its performance;
- Consider integrating RDF knowledge graphs with the conversational agent to ensure the extensibility of data modeling.
2. Literature Review
3. Method
3.1. Microworld Definition
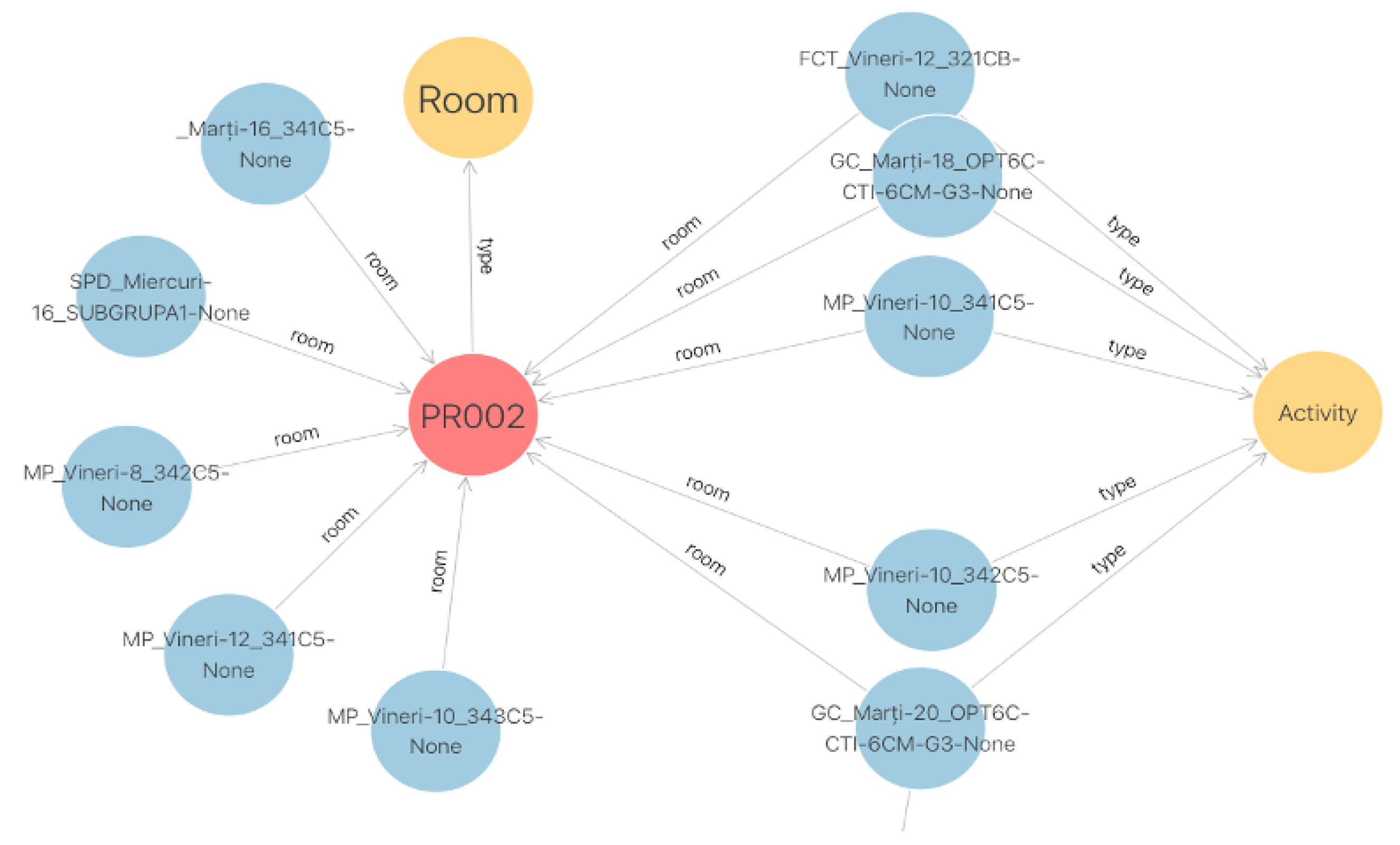
3.1.1. Microworld for University Guidance
- Professors: name, description, teaching degree, and office;
- Classrooms: ID and direction (guidance description);
- Activities: ID, name, student series or groups, room (link to a classroom node), teacher name, type (course, seminar, or laboratory), and time slot (workday, time, and duration).
3.1.2. Microworld for Memory Assistance
3.1.3. Generic Microworld
3.2. Language Models
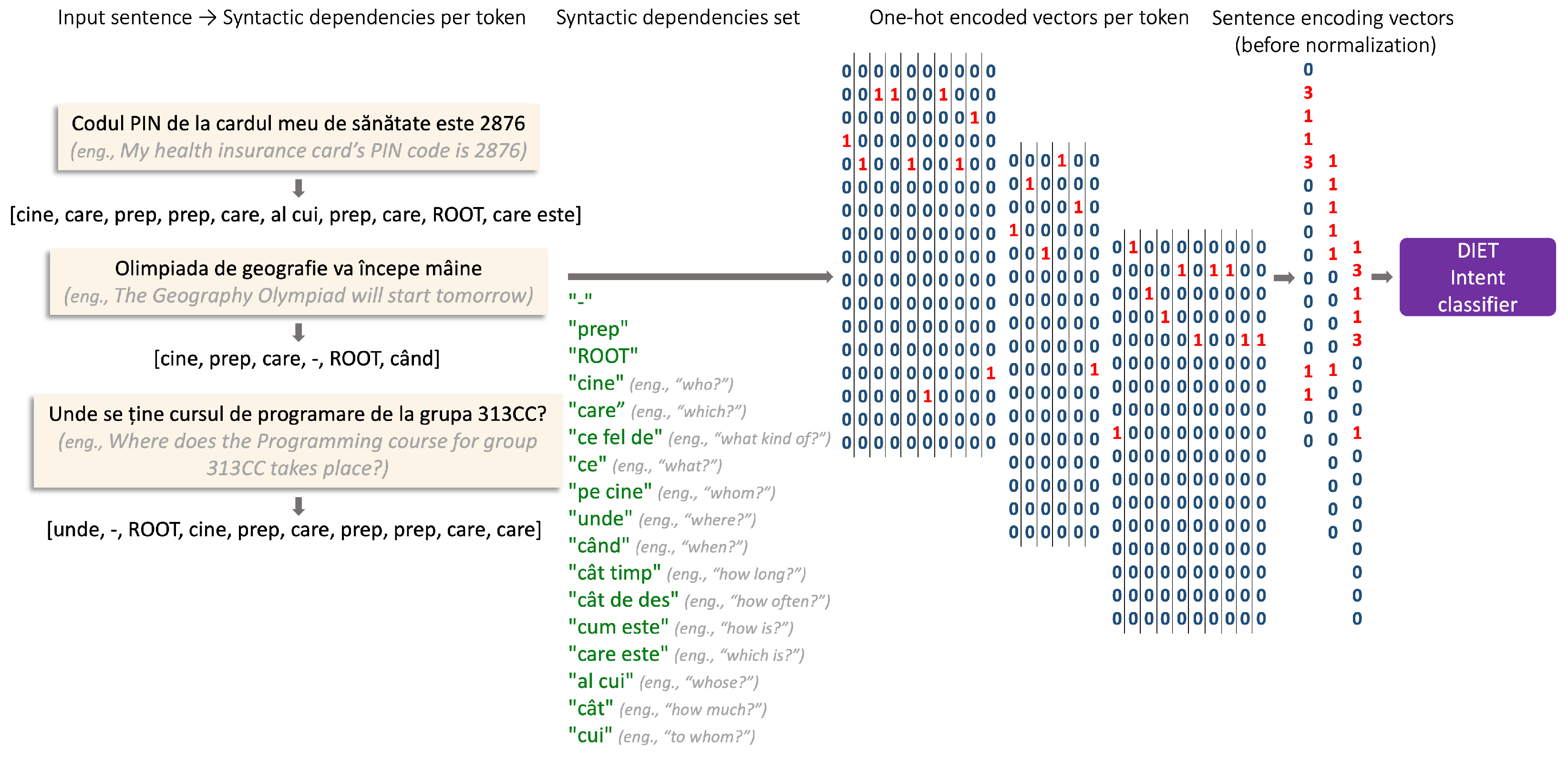
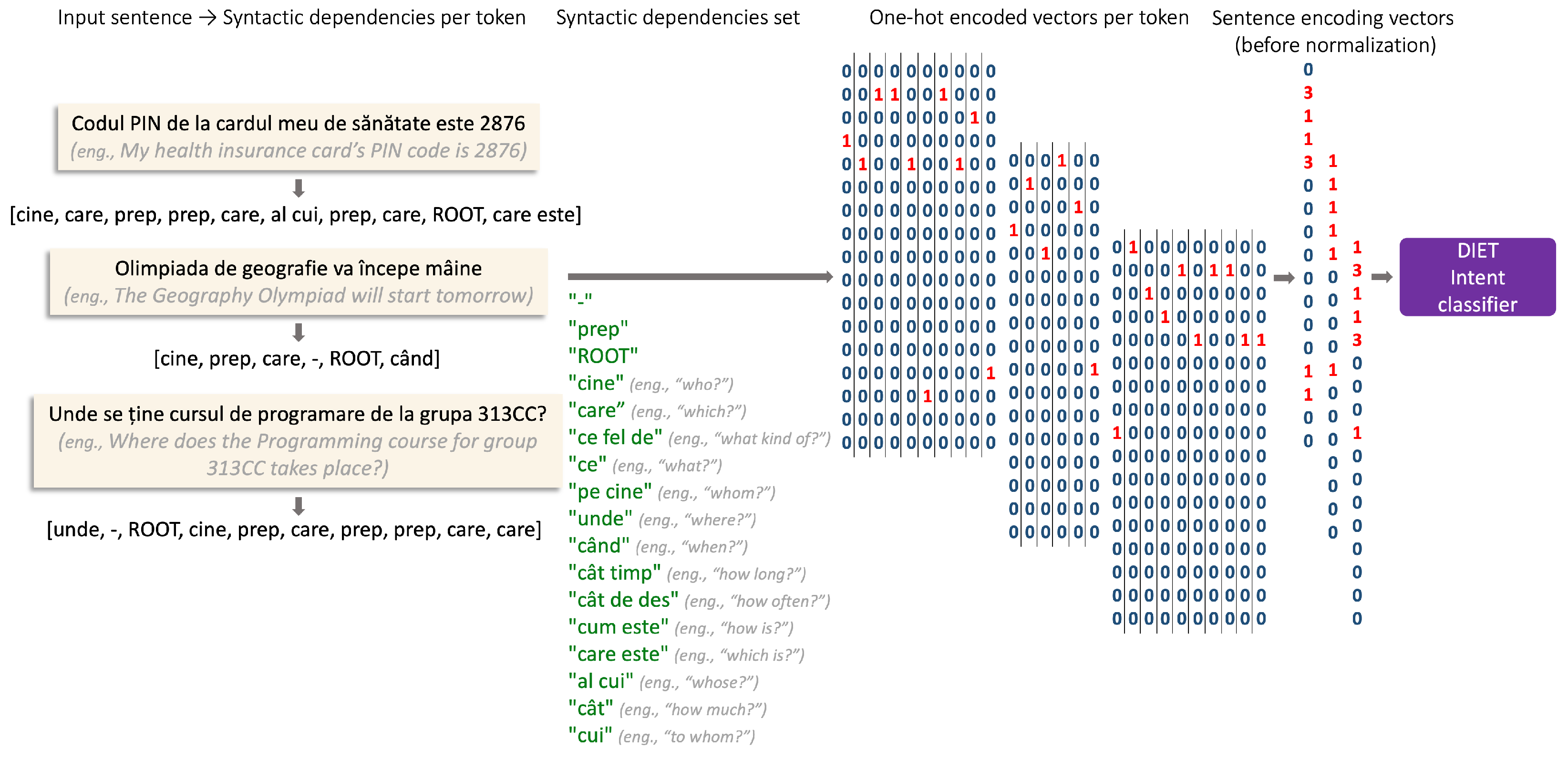
3.3. Syntactic Features
- “Cine?” (Eng., “who?”): defines the subject of the action;
- “ROOT”: label marking the verb;
- “Pe cine?”, “ce?” (Eng., “whom?”, “what?”): identify a direct object;
- “Care?”, “ce fel de?” (Eng., “which?”, “what kind of?”): identify the attributes of a noun or a substitute of a noun (creating together a noun phrase, or a grammatical structure that performs syntactically similar to a single noun);
- “Unde?” (Eng., “where?”): identifies a location complement that can define a source or destination location (depending on the prepending prepositions);
- “Când?”, “cât timp?”, “cât de des?” (Eng., “when?”, “how long?”, “how often?”): identify a temporal complement defining a point in time, a duration, or a frequency, respectively;
- “Care este?”, “cum este?” (Eng., “which is?”, “how is?”): describe tokens representing the predicative of a nominal predicate where, semantically, they express the value and qualification of the subject, respectively;
- “Al cui?” (Eng., “whose?”): marks the ownership of the entity;
- “Cui?” (Eng., “to whom?”): identifies an indirect object;
- “Prep”: label marking a preposition (no syntactic role, but necessary for linking the tokens in structures such as noun phrases);
- “Cât?” (Eng., “how much?”): describes a quantity of the entity that it determines, and it is expressed in general by a numeral or a quantitative adjective such as “mult” (Eng., “much”) or “puțin” (Eng., “little”).
3.4. Knowledge Representation and Retrieval
4. Results
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| BERT | Bidirectional encoder representations from transformers |
| DBMS | Database management system |
| DIET | Dual Intent and Entity Transformer |
| NER | Named-entity recognition |
| NLP | Natural language processing |
| NLU | Natural language understanding |
| RDF | Resource Description Framework |
| SPARQL | SPARQL Protocol and RDF query language |
| UUID | Universally unique identifier |
References
- Montenegro, J.L.Z.; da Costa, C.A.; da Rosa Righi, R. Survey of conversational agents in health. Expert Syst. Appl. 2019, 129, 56–67. [Google Scholar] [CrossRef]
- Boroghina, G.; Corlatescu, D.G.; Dascalu, M. Conversational Agent in Romanian for Storing User Information in a Knowledge Graph. In Proceedings of the 17th International Conference on Human-Computer Interaction, RoCHI 2020, Sibiu (Virtual), Romania, 22–23 October 2020; pp. 95–102. [Google Scholar] [CrossRef]
- Adewumi, T.; Liwicki, F.; Liwicki, M. State-of-the-Art in Open-Domain Conversational AI: A Survey. Information 2022, 13, 298. [Google Scholar] [CrossRef]
- Caldarini, G.; Jaf, S.; McGarry, K. A Literature Survey of Recent Advances in Chatbots. Information 2022, 13, 41. [Google Scholar] [CrossRef]
- Beckett, D.; McBride, B. RDF/XML syntax specification (revised). W3C Recomm. 2004, 10, 1–56. [Google Scholar]
- Ait-Mlouk, A.; Jiang, L. KBot: A Knowledge graph based chatBot for natural language understanding over linked data. IEEE Access 2020, 8, 149220–149230. [Google Scholar] [CrossRef]
- Gerontas, A.; Zeginis, D.; Promikyridis, R.; Androš, M.; Tambouris, E.; Cipan, V.; Tarabanis, K. Enhancing Core Public Service Vocabulary to Enable Public Service Personalization. Information 2022, 13, 225. [Google Scholar] [CrossRef]
- Promikyridis, R.; Tambouris, E. Using Knowledge Graphs to provide public service information. In Proceedings of the DG. O 2022: The 23rd Annual International Conference on Digital Government Research, Virtual, 15–17 June 2022; pp. 252–259. [Google Scholar]
- Bao, Q.; Ni, L.; Liu, J. HHH: An Online Medical Chatbot System based on Knowledge Graph and Hierarchical Bi-Directional Attention. In Proceedings of the Australasian Computer Science Week, ACSW 2020, Melbourne, VIC, Australia, 3–7 February 2020; pp. 32:1–32:10. [Google Scholar] [CrossRef] [Green Version]
- Ni, P.; Okhrati, R.; Guan, S.; Chang, V. Knowledge Graph and Deep Learning-based Text-to-GraphQL Model for Intelligent Medical Consultation Chatbot. Inf. Syst. Front. 2022, 1–20. [Google Scholar] [CrossRef]
- Breitfuss, A.; Errou, K.; Kurteva, A.; Fensel, A. Representing emotions with knowledge graphs for movie recommendations. Future Gener. Comput. Syst. 2021, 125, 715–725. [Google Scholar] [CrossRef]
- Varitimiadis, S.; Kotis, K.; Pittou, D.; Konstantakis, G. Graph-Based Conversational AI: Towards a Distributed and Collaborative Multi-Chatbot Approach for Museums. Appl. Sci. 2021, 11, 9160. [Google Scholar] [CrossRef]
- Varitimiadis, S.; Kotis, K.; Spiliotopoulos, D.; Vassilakis, C.; Margaris, D. “Talking” Triples to Museum Chatbots. In Proceedings of the Culture and Computing—8th International Conference, C&C 2020, Held as Part of the 22nd HCI International Conference, HCII 2020, Copenhagen, Denmark, 19–24 July 2020; Rauterberg, M., Ed.; Springer: Berlin/Heidelberg, Germany, 2020; Volume 12215, pp. 281–299. [Google Scholar] [CrossRef]
- Github. Conversational Agent Project. 2022. Available online: https://github.com/readerbench/conversational-agent (accessed on 2 May 2022).
- HuggingFace. HuggingFace. 2021. Available online: https://huggingface.co/ (accessed on 1 February 2022).
- Hardalov, M.; Koychev, I.; Nakov, P. Machine Reading Comprehension for Answer Re-Ranking in Customer Support Chatbots. Information 2019, 10, 82. [Google Scholar] [CrossRef] [Green Version]
- da Silva, D.A.; Louro, H.D.B.; Goncalves, G.S.; Marques, J.C.; Dias, L.A.V.; da Cunha, A.M.; Tasinaffo, P.M. Could a Conversational AI Identify Offensive Language? Information 2021, 12, 418. [Google Scholar] [CrossRef]
- Bocklisch, T.; Faulkner, J.; Pawlowski, N.; Nichol, A. Rasa: Open source language understanding and dialogue management. arXiv 2017, arXiv:1712.05181. [Google Scholar]
- Wit.ai. Wit.ai. 2022. Available online: https://wit.ai/ (accessed on 1 March 2022).
- Mikolov, T.; Karafiát, M.; Burget, L.; Černocký, J.; Khudanpur, S. Recurrent neural network based language model. In Proceedings of the Eleventh Annual Conference of the International Speech Communication Association, Makuhari, Japan, 26–30 September 2010. [Google Scholar]
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to sequence learning with neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; pp. 3104–3112. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30, pp. 5998–6008. [Google Scholar]
- Bunk, T.; Varshneya, D.; Vlasov, V.; Nichol, A. DIET: Lightweight Language Understanding for Dialogue Systems. arXiv 2020, arXiv:2004.09936. [Google Scholar]
- Lafferty, J.; McCallum, A.; Pereira, F.C. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. In Proceedings of the ICML, Williamstown, MA, USA, 8 June–1 July 2001; pp. 282–289. [Google Scholar]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MA, USA, 2–7 June 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Honnibal, M.; Montani, I. spacy 2: Natural language understanding with bloom embeddings. Convolutional Neural Netw. Increm. Parsing 2017, 7, 411–420. [Google Scholar]
- Sharma, V.; Dave, M. SQL and NoSQL databases. Int. J. Adv. Res. Comput. Sci. Softw. Eng. 2012, 2, 20–27. [Google Scholar]
- Bonatti, P.A.; Decker, S.; Polleres, A.; Presutti, V. Knowledge graphs: New directions for knowledge representation on the semantic web (dagstuhl seminar 18371). Dagstuhl Rep. 2019, 8, 29–111. [Google Scholar] [CrossRef]
- Berners-Lee, T.; Hendler, J.; Lassila, O. The semantic web. Sci. Am. 2001, 284, 34–43. [Google Scholar] [CrossRef]
- Horrocks, I.; Patel-Schneider, P.F. Knowledge representation and reasoning on the semantic web: Owl. In Handbook of Semantic Web Technologies; Chapter 9; Springer: Berlin/Heidelberg, Germany, 2011; pp. 365–398. [Google Scholar]
- Smith, E.M.; Williamson, M.; Shuster, K.; Weston, J.; Boureau, Y.L. Can you put it all together: Evaluating conversational agents’ ability to blend skills. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics (ACL 2020). Association for Computational Linguistics, Seattle, WA, USA (Virtual), 5–10 July 2020; pp. 2021–2030. [Google Scholar] [CrossRef]
- Nenciu, B.; Corlatescu, D.G.; Dascalu, M. RASA Conversational Agent in Romanian for Predefined Microworlds. In Proceedings of the RoCHI-International Conference On Human-Computer Interaction, Sibiu, Romania (Virtual), 22–23 October 2020; pp. 87–94. [Google Scholar]
- Vrandečić, D.; Krötzsch, M. Wikidata: A free collaborative knowledgebase. Commun. ACM 2014, 57, 78–85. [Google Scholar] [CrossRef] [Green Version]
- Auer, S.; Bizer, C.; Kobilarov, G.; Lehmann, J.; Cyganiak, R.; Ives, Z. Dbpedia: A nucleus for a web of open data. In The Semantic Web; Springer: Berlin/Heidelberg, Germany, 2007; pp. 722–735. [Google Scholar]
- Pérez, J.; Arenas, M.; Gutierrez, C. Semantics and complexity of SPARQL. Acm Trans. Database Syst. (TODS) 2009, 34, 1–45. [Google Scholar] [CrossRef] [Green Version]
- Explosion. spaCy Romanian Models. 2022. Available online: https://spacy.io/models/ro (accessed on 20 February 2022).
- Barbu Mititelu, V.; Ion, R.; Simionescu, R.; Irimia, E.; Perez, C.A. The romanian treebank annotated according to universal dependencies. In Proceedings of the Tenth International Conference on Natural Language Processing (hrtal2016), Dubrovnik, Croatia, 29 September–1 October 2016. [Google Scholar]
- Contributors, U.D. Universal Dependencies Corpora. 2014–2021. Available online: http://universaldependencies.org/u/dep/all.html (accessed on 14 July 2021).
- Masala, M.; Ruseti, S.; Dascalu, M. RoBERT—A Romanian BERT Model. In Proceedings of the 28th International Committee on Computational Linguistics (COLING), Barcelona, Spain, 8–13 December 2020; pp. 6626–6637. [Google Scholar] [CrossRef]
- Avram, A.M.; Catrina, D.; Cercel, D.C.; Dascălu, M.; Rebedea, T.; Păiş, V.; Tufiş, D. Distilling the Knowledge of Romanian BERTs Using Multiple Teachers. arXiv 2021, arXiv:2112.12650. [Google Scholar]
- Bărbuță, I.; Cicală, A.; Constantinovici, E.; Cotelnic, T.; Dîrul, A. Gramatica Uzuală a Limbii Române; Litera: Chisinau, Republic of Moldavia, 2000. [Google Scholar]
- Güting, R.H. GraphDB: Modeling and querying graphs in databases. In Proceedings of the VLDB, Citeseer, Santiago de Chile, Chile, 12–15 September 1994; Volume 94, pp. 12–15. [Google Scholar]
- Eclipse Foundation. RDF4J. 2022. Available online: https://rdf4j.org/ (accessed on 1 May 2022).
- Ontotext. LoadRDF. 2016. Available online: https://www.graphdb.ontotext.com/documentation/7.2/standard/loadrdf-tool.html (accessed on 2 May 2022).









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Microworld | Class | Properties |
|---|---|---|
| University Guidance | Professor | Name, academic position, description, office |
| Room | ID, location indications | |
| Activity | Type, name, ID, student groups, classroom, time slot | |
| Memory Assistance | Entity | Location, description, specifier |
| Event | Timestamp | |
| Property of entity | Value | |
| Subject | Owned entity |
| Language Model | Syntactic Features | Precision M (SD) | Recall M (SD) | F1 Score M (SD) |
|---|---|---|---|---|
| None | No | 79.2 (2.5) | 76.7 (2.6) | 75.9 (2.9) |
| None | Yes | 80.7 (3.3) | 78.5 (3.1) | 77.9 (3.2) |
| SpaCy Ro | No | 80.5 (2.4) | 77.8 (2.8) | 77.1 (3.0) |
| DistilMulti-BERT-base-ro | No | 78.2 (2.7) | 75.9 (2.4) | 75.2 (2.6) |
| RoBERT large | No | 82.4 (2.3) | 81.0 (2.5) | 80.1 (2.9) |
| RoBERT large | Yes | 85.2 (3.0) | 83.2 (3.1) | 82.6 (3.1) |
| Sentence | Real Intent | Predicted Intent | Confi-Dence | Discussion |
|---|---|---|---|---|
| Ok | generic. affirm | generic. goodbye | 90.6 | Short sentence (harder for count vectors), foreign words (harder for language model) |
| Mi-ai fost de mare ajutor. (Eng.: You have been really helpful.) | generic. thanks | mem_assistant. store_request | 64.4 | Insufficient generic microworld support in the data set |
| Care sunt lucrurile pe care știi să le faci? (Eng.: What are the things that you know how to do?) | generic. agent_abilities | mem_assistant. get_attr | 99.9 | Phrase “care sunt” (Eng.: what are) similar to the predicted intent |
| Help | generic. agent_abilities | generic. goodbye | 45.1 | Short sentence (harder for count vectors), foreign words (harder for language model) |
| Hotelul la care ne-am cazat anul trecut la mare e acesta. (Eng.: The hotel where we stayed last year at the seaside is the following.) | mem_assistant. store_following_attr | mem_assistant. get_specifier | 99.9 | Phrase “la care” (Eng.: where) specific to the predicted intent |
| Programul de la notarul de la Universitate este acesta. (Eng.: The program from the notary at the University is the following.) | mem_assistant. store_following_attr | mem_assistant. store_attr | 60.0 | Examples of the two intents have similar prefixes |
| Sunt în grupa 232. (Eng.: I’m in group 232.) | university_guide. find_schedule_fill_slots | university_guide. find_room | 77.3 | Sequence (232) interpreted as room ID |
| Cursul de Programare Orientata pe Obiecte (Eng.: Object-Oriented Programming Course) | university_guide. find_schedule_fill_slots | university_guide. find_schedule | 99.9 | Some “find_schedule_fill_slots” examples are subsequences of “find_schedule”-specific sentences |
| Cum pot ajunge rapid la laserul de la Măgurele? (Eng.: How can I quickly get to the Magurele laser?) | generic. find_transport | mem_assistant. get_specifier | 34.1 | No obvious justification for confusion, but the low confidence indicates possible wrong detection |
| Sala laboratorului de PP este EG321. (Eng.: The PP laboratory room is EG321) | mem_assistant. store_attr | university_guide. find_room | 94.8 | Entities specific to the university guidance microworld (activity type: laboratory, classroom: “EG321”) |
| Suprafața apartamentului de la București este de 58 mp. (Eng.: The surface of the apartment in Bucharest is 58 sqm.) | mem_assistant. store_attr | mem_assistant. store_location | 99.9 | Sentence contains a location, although as an attribute and not a complement |
| Am mers cu mașina până la Iași. (Eng.: We drove by car to Iasi.) | mem_assistant. store_location | mem_assistant. get_timestamp | 42.8 | No obvious justification for confusion, but the low confidence indicates possible wrong detection |
| Chitara mea este de la Andrei. (Eng.: My guitar is from Andrei.) | mem_assistant. store_location | mem_assistant. store_attr | 75.4 | Phrase “<subj> este” similar to the predicted intent |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Boroghina, G.; Corlatescu, D.G.; Dascalu, M. Multi-Microworld Conversational Agent with RDF Knowledge Graph Integration. Information 2022, 13, 539. https://doi.org/10.3390/info13110539
Boroghina G, Corlatescu DG, Dascalu M. Multi-Microworld Conversational Agent with RDF Knowledge Graph Integration. Information. 2022; 13(11):539. https://doi.org/10.3390/info13110539
Chicago/Turabian StyleBoroghina, Gabriel, Dragos Georgian Corlatescu, and Mihai Dascalu. 2022. "Multi-Microworld Conversational Agent with RDF Knowledge Graph Integration" Information 13, no. 11: 539. https://doi.org/10.3390/info13110539
APA StyleBoroghina, G., Corlatescu, D. G., & Dascalu, M. (2022). Multi-Microworld Conversational Agent with RDF Knowledge Graph Integration. Information, 13(11), 539. https://doi.org/10.3390/info13110539