
CA-STD: Scene Text Detection in Arbitrary Shape Based on Conditional Attention

 , ,
, , 
Abstract
1. Introduction
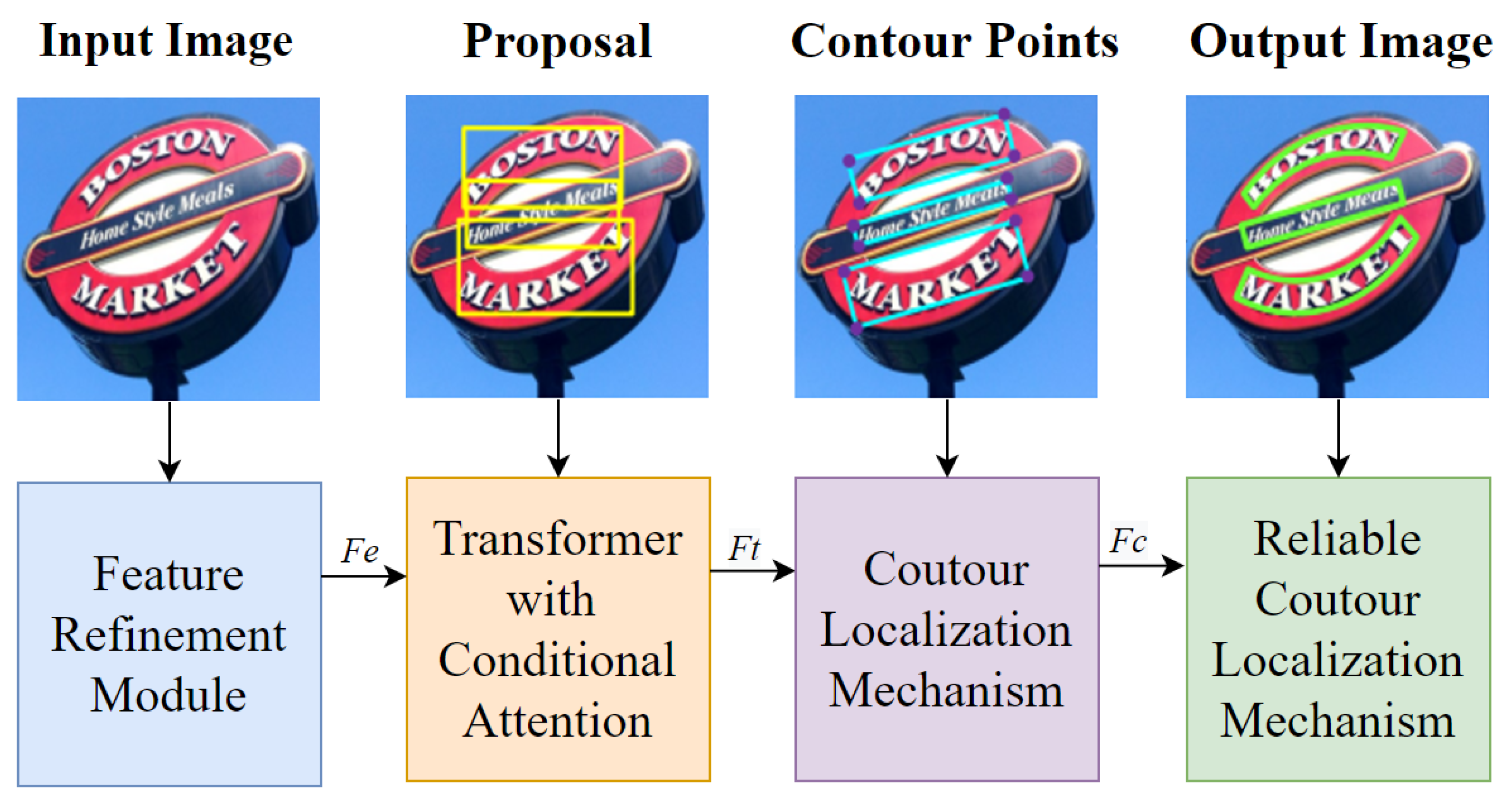
- Designing the Feature Refinement Module (FRM) to enhance features with a lightweight network;
- Proposing the conditional attention mechanism to improve the model’s performance;
- Generating the bounding boxes with arbitrary shape by the Contour Information Aggregation (CIA).
2. Related Work
3. Method
3.1. Feature Extraction Network
3.2. Positional Encoding for Transformer
3.3. Horizontal Text Proposal Generation
3.4. Oriented Text Proposal Generation
3.5. Arbitrary-Shape Text Contour Generation
3.6. Loss Functions
- 3.6.1. Matching Loss
- 3.6.2. Hungarian Loss
- 3.6.3. Bounding Box Loss
4. Experiments
4.1. Datasets
- SynthText. There are 858,750 synthetic pictures with character-level labels, word-level labels, and bounding box coordinates. A non-class is added to the original dataset to represent the boundary boxes without text.
- TotalText. The text is horizontal, random, and curved in the dataset. Additionally, 1255 images are used to train the model, and 300 images are used to test it. Only word-level labels and bounding boxes are included in the annotations file.
- CTW-1500. CTW-1500 is utilized to train a model for curved text, containing 1000 training images and 500 test images with word-level annotations and bounding boxes.
4.2. Implementation Details
4.2.1. Experimental Environment and Hyper-parameters
4.2.2. Evaluation Metrics
4.2.3. Experiment Results
4.3. Ablation Study
5. Discussion and Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| STD | Scene Text Detection |
| CA-STD | Conditional Attention-based Scene Text Detection |
| FRM | Feature Refinement Module |
| CIA | Contour Information Aggregation |
| CLM | Contour Localization Mechanism |
| RCLM | Reliable Contour Localization Mechanism |
| CNN | Convolutional Neural Network |
| ROI | Region Of Interest |
| RPN | Region Proposal Network |
| FPN | Feature Pyramid Network |
| MSER | Maximum Stable Extreme Regions |
| NMS | Maximum Suppression |
| IOU | Intersection Over Union |
| GIOU | Generalized Intersection Over Union |
References
- Raisi, Z.; Naiel, M.A.; Younes, G. Transformer-based text detection in the wild. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 3162–3171. [Google Scholar]
- Zhang, Z.; Zhang, C.; Shen, W. Multi-oriented text detection with fully convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4159–4167. [Google Scholar]
- Matas, J.; Chum, O.; Urban, M. Robust wide-baseline stereo from maximally stable extremal regions. Image Vis. Comput. 2004, 22, 761–767. [Google Scholar] [CrossRef]
- Wu, X.; Chen, C.; Li, P. FTAP: Feature transferring autonomous machine learning pipeline. Inf. Sci. 2022, 593, 385–397. [Google Scholar] [CrossRef]
- Wu, X.; Zhang, Y.; Li, Q. Face aging with pixel-level alignment GAN. Appl. Intell. 2022, 52, 14665–14678. [Google Scholar] [CrossRef]
- Jiao, L.; Zhang, F.; Liu, F. A survey of deep learning-based object detection. IEEE Access 2019, 7, 128837–128868. [Google Scholar] [CrossRef]
- Shi, B.; Bai, X.; Belongie, S. Detecting oriented text in natural images by linking segments. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2550–2558. [Google Scholar]
- Lyu, P.; Liao, M.; Yao, C. Mask textspotter: An end-to-end trainable neural network for spotting text with arbitrary shapes. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 67–83. [Google Scholar]
- Deng, D.; Liu, H.; Li, X. Pixellink: Detecting scene text via instance segmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Wang, W.; Xie, E.; Song, X. Efficient and accurate arbitrary-shaped text detection with pixel aggregation network. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Korea, 27 October–2 December 2019; pp. 8440–8449. [Google Scholar]
- Long, S.; Ruan, J.; Zhang, W. Textsnake: A flexible representation for detecting text of arbitrary shapes. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 20–36. [Google Scholar]
- Ye, J.; Chen, Z.; Liu, J. TextFuseNet: Scene Text Detection with Richer Fused Features. In Proceedings of the IJCAI, Rhodes, Greece, 12–18 September 2020; Volume 20, pp. 516–522. [Google Scholar]
- Wu, X.; Zhong, M.; Guo, Y. The assessment of small bowel motility with attentive deformable neural network. Inf. Sci. 2020, 508, 22–32. [Google Scholar] [CrossRef]
- Wu, X.; Jin, H.; Ye, X. Multiscale convolutional and recurrent neural network for quality prediction of continuous casting slabs. Processes 2020, 9, 33. [Google Scholar] [CrossRef]
- Ibrayim, M.; Li, Y.; Hamdulla, A. Scene Text Detection Based on Two-Branch Feature Extraction. Sensors 2022, 22, 6262. [Google Scholar] [CrossRef] [PubMed]
- Hassan, E. Scene Text Detection Using Attention with Depthwise Separable Convolutions. Appl. Sci. 2022, 12, 6425. [Google Scholar] [CrossRef]
- Li, Y.; Ibrayim, M.; Hamdulla, A. CSFF-Net: Scene Text Detection Based on Cross-Scale Feature Fusion. Information 2021, 12, 524. [Google Scholar] [CrossRef]
- Lyu, P.; Yao, C.; Wu, W. Multi-oriented scene text detection via corner localization and region segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7553–7563. [Google Scholar]
- Wang, X.; Jiang, Y.; Luo, Z. Arbitrary shape scene text detection with adaptive text region representation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6449–6458. [Google Scholar]
- Liao, M.; Zhu, Z.; Shi, B. Rotation-sensitive regression for oriented scene text detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 5909–5918. [Google Scholar]
- Liao, M.; Shi, B.; Bai, X. Textboxes: A fast text detector with a single deep neural network. In Proceedings of the Thirty-First AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017. [Google Scholar]
- Ma, J.; Shao, W.; Ye, H. Arbitrary-oriented scene text detection via rotation proposals. IEEE Trans. Multimed. 2018, 20, 3111–3122. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Xie, H.; Zha, Z.J. Contournet: Taking a further step toward accurate arbitrary-shaped scene text detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11753–11762. [Google Scholar]
- Du, B.; Ye, J.; Zhang, J. I3CL: Intra-and Inter-Instance Collaborative Learning for Arbitrary-shaped Scene Text Detection. Int. J. Comput. Vis. 2022, 130, 1961–1977. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Virtual Event, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- Carion, N.; Massa, F.; Synnaeve, G. End-to-end object detection with transformers. In Proceedings of the European Conference on Computer Vision; Springer: Cham, Switzerland, 2020; pp. 213–229. [Google Scholar]
- Chen, M.; Radford, A.; Child, R. Generative pretraining from pixels. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual Event, 13–18 July 2020; pp. 1691–1703. [Google Scholar]
- Liu, R.; Yuan, Z.; Liu, T. End-to-end lane shape prediction with transformers. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021; pp. 3694–3702. [Google Scholar]
- Peng, S.; Jiang, W.; Pi, H. Deep snake for real-time instance segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 July 2020; pp. 8533–8542. [Google Scholar]
- Wu, X.; Qi, Y.; Tang, B. DA-STD: Deformable Attention-Based Scene Text Detection in Arbitrary Shape. In Proceedings of the 2021 IEEE International Conference on Progress in Informatics and Computing (PIC), Shanghai, China, 17–19 December 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 102–106. [Google Scholar]
- Gupta, A.; Vedaldi, A.; Zisserman, A. Synthetic data for text localisation in natural images. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2315–2324. [Google Scholar]
- Ch’ng, C.K.; Chan, C.S. Total-text: A comprehensive dataset for scene text detection and recognition. In Proceedings of the 2017 14th IAPR International Conference on Document Analysis and Recognition (ICDAR), Kyoto, Japan, 9–15 November 2017; IEEE: Piscataway, NJ, USA, 2017; Volume 1, pp. 935–942. [Google Scholar]
- Baek, Y.; Lee, B.; Han, D. Character region awareness for text detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–19 June 2019; pp. 9365–9374. [Google Scholar]
- Brown, T.; Mann, B.; Ryder, N. Language models are few-shot learners. Adv. Neural Inf. Process. Syst. 2020, 33, 1877–1901. [Google Scholar]
- Zhang, C.; Liang, B.; Huang, Z. Look more than once: An accurate detector for text of arbitrary shapes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 10552–10561. [Google Scholar]
- Wang, P.; Zhang, C.; Qi, F. A single-shot arbitrarily-shaped text detector based on context attended multi-task learning. In Proceedings of the 27th ACM International Conference on Multimedia, Nice, France, 21–25 October 2019; pp. 1277–1285. [Google Scholar]
- Zhou, Y.; Xie, H.; Fang, S. CRNet: A center-aware representation for detecting text of arbitrary shapes. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12 October 2020; pp. 2571–2580. [Google Scholar]
- Tian, Z.; Huang, W.; He, T. Detecting text in natural image with connectionist text proposal network. In Proceedings of the European Conference on Computer Vision; Springer: Cham, Switzerland, 2016; pp. 56–72. [Google Scholar]
- Lin, Z.; Zhu, F.; Wang, Q. RSSGG-CS: Remote Sensing Image Scene Graph Generation by Fusing Contextual Information and Statistical Knowledge. Remote Sens. 2022, 14, 3118. [Google Scholar] [CrossRef]
- Wang, Y.; Mamat, H.; Xu, X. Scene Uyghur Text Detection Based on Fine-Grained Feature Representation. Sensors 2022, 22, 4372. [Google Scholar] [CrossRef] [PubMed]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | P | R | F1 |
|---|---|---|---|
| SegLink [7] | 30.3 | 23.8 | 26.7 |
| DeconvNet [33] | 33.0 | 40.0 | 36.0 |
| MaskSpotter [8] | 55.0 | 69.0 | 61.3 |
| TextSnake [11] | 82.7 | 74.5 | 78.4 |
| PSENet [10] | 81.8 | 75.1 | 78.3 |
| PAN [36] | 79.4 | 88.0 | 83.5 |
| LOMO [37] | 75.7 | 88.6 | 81.6 |
| SAST [38] | 76.9 | 83.8 | 80.2 |
| CRNet [39] | 82.5 | 85.8 | 84.1 |
| CA-STD | 82.9 | 82.1 | 82.5 |
| Methods | P | R | F1 |
|---|---|---|---|
| SegLink [7] | 42.3 | 40.0 | 40.8 |
| CTD+TLOC [40] | 69.8 | 77.4 | 73.4 |
| TextSnake [11] | 85.3 | 67.9 | 75.6 |
| PSENet [10] | 80.6 | 75.6 | 78.0 |
| CRAFT [41] | 81.1 | 86.0 | 83.5 |
| LOMO [38] | 69.6 | 89.2 | 78.4 |
| SAST [13] | 77.1 | 85.3 | 81.0 |
| CA-STD | 83.1 | 84.5 | 83.8 |
| Methods | P | R | F1 |
|---|---|---|---|
| Baseline | 81.4 | 80.2 | 80.8 |
| +FRM | 80.3 | 81.1 | 80.7 |
| +Cond-atte | 81.5 | 81.4 | 81.4 |
| +Cond-atte(FRM) | 81.9 | 81.7 | 81.8 |
| +CLM/RCLM | 82.2 | 81.9 | 82.0 |
| +CLM/RCLM(FRM) | 82.9 | 82.1 | 82.5 |
| Methods | P | R | F1 |
|---|---|---|---|
| Baseline | 82.3 | 79.8 | 81.0 |
| +FRM | 80.6 | 80.2 | 80.4 |
| +Cond-atte | 81.6 | 81.2 | 81.4 |
| +Cond-atte(FRM) | 82.5 | 81.4 | 81.9 |
| +CLM/RCLM | 82.8 | 82.6 | 82.7 |
| +CLM/RCLM(FRM) | 83.1 | 84.5 | 83.8 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, X.; Qi, Y.; Song, J.; Yao, J.; Wang, Y.; Liu, Y.; Han, Y.; Qian, Q. CA-STD: Scene Text Detection in Arbitrary Shape Based on Conditional Attention. Information 2022, 13, 565. https://doi.org/10.3390/info13120565
Wu X, Qi Y, Song J, Yao J, Wang Y, Liu Y, Han Y, Qian Q. CA-STD: Scene Text Detection in Arbitrary Shape Based on Conditional Attention. Information. 2022; 13(12):565. https://doi.org/10.3390/info13120565
Chicago/Turabian StyleWu, Xing, Yangyang Qi, Jun Song, Junfeng Yao, Yanzhong Wang, Yang Liu, Yuexing Han, and Quan Qian. 2022. "CA-STD: Scene Text Detection in Arbitrary Shape Based on Conditional Attention" Information 13, no. 12: 565. https://doi.org/10.3390/info13120565
APA StyleWu, X., Qi, Y., Song, J., Yao, J., Wang, Y., Liu, Y., Han, Y., & Qian, Q. (2022). CA-STD: Scene Text Detection in Arbitrary Shape Based on Conditional Attention. Information, 13(12), 565. https://doi.org/10.3390/info13120565