1. Introduction
Machine Learning models have widely applied Natural Language Processing (NLP) techniques, which replace the previous rule-based models and show better performances. NLP techniques, such as recommendation and sentiment analysis, have become ubiquitous and necessary among businesses across industries [
1]. Named Entity Recognition (NER) is a type of NLP technique based on machine learning models that extracts entities from sentences [
2]. Entities are generally considered the keywords in marketing, and recognizing ‘named entities’, i.e., the name of a person, an organization, a place, and all other entities identified by a name, is vital for the potential business strategies in the big data era [
3,
4]. On one hand, NER has seen considerable development in English, and many data-driven models have been proposed. On the other hand, there is insufficient research to support languages other than English [
5,
6]. Compared with English, some languages have many linguistic structures. Aiming at these grammar rules, this work proposes a grammar-based network for named entity recognition and selected four Nordic languages in experiments.
In the Norwegian Bokmål language, one of the experimental languages, some words have feminine, masculine, and neutral varieties. Moreover, there are many compound words, that is, one word consists of several separated words, and the boundaries in compound words are hard to discern. As is shown in
Table 1, English words cannot make a one-to-one alignment with Norwegian Bokmål language words, which will hinder the model’s performance. Here, ‘Høyesterettsjustitiarius’ comprises three word-tokens, ‘Supreme’, ‘Court’, and ‘Justice’ in English. However, data-driven models cannot well learn these linguistic structures. This work proposes a novel method incorporating the missing grammar information and discusses how the grammars influence NER performance.
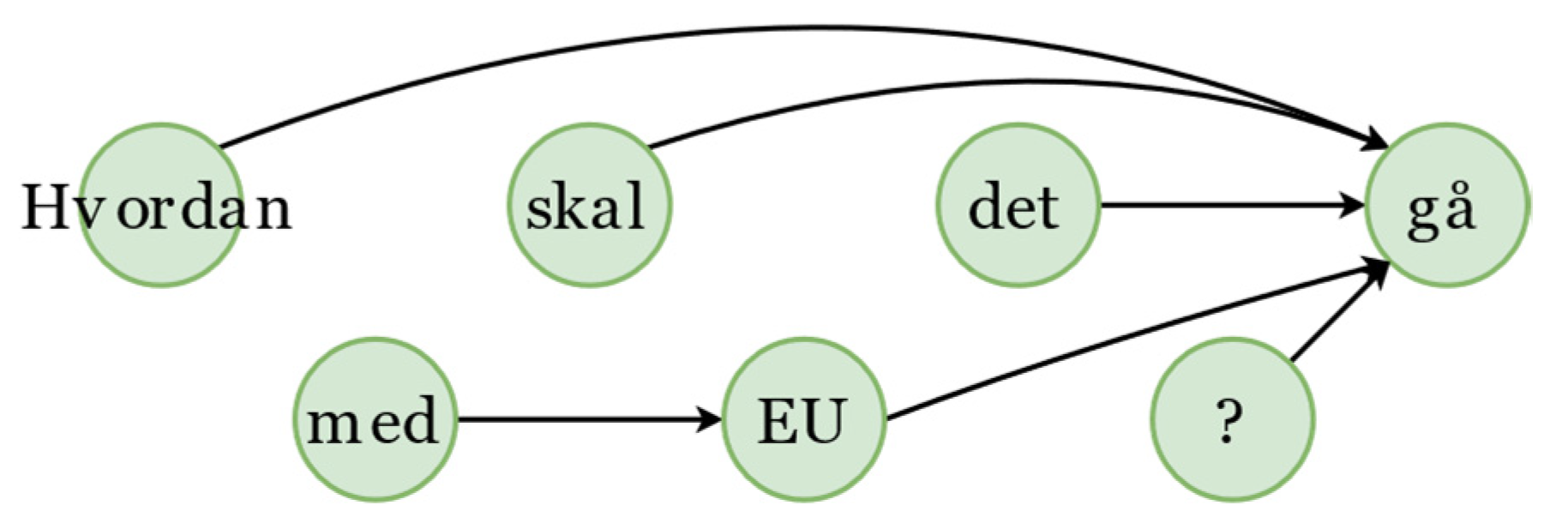
Traditionally, a bidirectional Long Short-Term Memory (Bi-LSTM) layer and a conditional random field (CRF) layer are applied, which encode the sentence in a sequential pattern [
7] (see
Figure 1). However, as Shen et al. argued, the Bi-LSTM- and CRF-based models also suffer some problems because a sentence does not follow a ‘front-to-end’ sequential pattern [
8]. The NorG network can break through the sequential pattern according to the graphical dependency grammars (see
Figure 2). Recently, stronger representations have been proposed. For example, BERT embedding achieved state-of-the-art performance in the NER model [
9], but knowledge of the grammar is not well considered during training.
To verify the effectiveness of the linguistic structure for NER, we built a new structure, called the NorG network, and conducted experiments on four Nordic languages. The NorG network incorporates morphological and syntactic grammars. Morphological and syntactic grammars can be obtained by existing tools, such as NLTK [
10]. NorG consists of a bidirectional LSTM layer to produce embeddings with word-level grammar, while a bidirectional Graph Attention (Bi-GAT) layer is used to capture the sentence-level dependency grammar. The NorG network reduces the reliability of the word embedding, shows good robustness in the four Nordic languages, and can alleviate the abovementioned problems.
The involved named entities in this study are defined in
Table 2. We used ten types of entities. The entity annotation IOB2 is explained in
Table 3.
The main contributions of this paper can be summarized as follows:
- (1)
In addition to using embeddings from content, we propose the use of embeddings from different grammars for NER.
- (2)
We propose the NorG network, which integrates the text content, morphology, and syntax. We found that bidirectional LSTM can capture the morphological knowledge well, and bidirectional GAT can capture the syntactic dependency knowledge well.
- (3)
Experimental results demonstrate the effectiveness of the proposed method in four languages and some exploratory experiments were conducted to discover the influences of different grammar components on the NER performance.
The rest of the paper is organized as follows.
Section 2 introduces related works about Nordic NER resources, Nordic NER algorithms, and general NER algorithms.
Section 3 presents the details of how we used the grammar features and explains the process from the input to the output.
Section 4 introduces the dataset and experimental setting.
Section 5 presents the results and a discussion. Finally, our conclusions on the NorG network can be found in
Section 6.
Author Contributions
Conceptualization, M.S.; methodology, M.S.; software, M.S. and Q.Y.; validation, M.S.; formal analysis, M.S.; investigation, M.S. and Q.Y.; resources, M.S.; data curation, M.S.; writing—original draft preparation, M.S.; writing—review and editing, H.W., M.P. and I.A.H.; visualization, M.S. and Q.Y.; supervision, H.W., M.P. and I.A.H.; project administration, H.W., M.P. and I.A.H.; funding acquisition, H.W., M.P. and I.A.H. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by Norwegian University of Sciences and Technology [Prosjektnummer 70441595].
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
Data available in a publicly accessible repository. The data presented in this study are openly available in reference [
11,
12,
16].
Conflicts of Interest
The authors declare no conflict of interest.
References
- Pollák, F.; Dorčák, P.; Markovič, P. Corporate Reputation of Family-Owned Businesses: Parent Companies vs. Their Brands. Information 2021, 12, 89. [Google Scholar] [CrossRef]
- Li, J.; Sun, A.; Han, J.; Li, C. A survey on deep learning for named entity recognition. IEEE Trans. Knowl. Data Eng. 2020, 34, 50–70. [Google Scholar] [CrossRef] [Green Version]
- Gu, K.; Vosoughi, S.; Prioleau, T. SymptomID: A framework for rapid symptom identification in pandemics using news reports. ACM Trans. Manag. Inf. Syst. (TMIS) 2021, 12, 1–17. [Google Scholar] [CrossRef]
- Lee, D.; Oh, B.; Seo, S.; Lee, K.H. News recommendation with topic-enriched knowledge graphs. In Proceedings of the 29th ACM International Conference on Information & Knowledge Management, Virtual Conference, 19–23 October 2020; pp. 695–704. [Google Scholar]
- Tanvir, H.M.; Kittask, C.; Sirts, K. EstBERT: A Pretrained Language-Specific BERT for Estonian. In Proceedings of the 23rd Nordic Conference on Computational Linguistics, Reykjavik, Iceland, 31 May–2 June 2021. [Google Scholar]
- Kutuzov, A.; Barnes, J.; Velldal, E.; Ovrelid, L.; Oepen, S. Large-Scale Contextualised Language Modelling for Norwegian. In Proceedings of the 23rd Nordic Conference on Computational Linguistics, Reykjavik, Iceland, 31 May–2 June 2021. [Google Scholar]
- Huang, Z.; Xu, W.; Yu, K. Bidirectional LSTM-CRF models for sequence tagging. arXiv 2015, arXiv:1508.01991. [Google Scholar]
- Shen, Y.; Tan, S.; Sordoni, A.; Courville, A. Ordered neurons: Integrating tree structures into recurrent neural networks. In Proceedings of the ICLR, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-training of deep bidirectional transformers for language understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 3–5 June 2019; Volume 1, pp. 4171–4186. [Google Scholar]
- Bird, S.; Klein, E.; Loper, E. Natural Language Processing with Python: Analyzing Text with the Natural Language Toolkit; O’Reilly Media, Inc.: Sebastopol, CA, USA, 2009. [Google Scholar]
- Jørgensen, F.; Aasmoe, T.; Husevåg, A.S.R.; Øvrelid, L.; Velldal, E. NorNE: Annotating named entities for Norwegian. In Proceedings of the 12th Language Resources and Evaluation Conference, Le Palais du Pharo, France, 11–16 May 2020; pp. 4547–4556. [Google Scholar]
- Hvingelby, R.; Pauli, A.B.; Barrett, M.; Rosted, C.; Lidegaard, L.M.; Søgaard, A. DaNE: A named entity resource for danish. In Proceedings of the 12th Language Resources and Evaluation Conference, Le Palais du Pharo, France, 11–16 May 2020; pp. 4597–4604. [Google Scholar]
- Derczynski, L. Simple natural language processing tools for Danish. arXiv 2019, arXiv:1906.11608. [Google Scholar]
- Bick, E. A named entity recognizer for Danish. In Proceedings of the Fourth International Conference on Language Resources and Evaluation, Lisbon, Portugal, 26–28 May 2004. [Google Scholar]
- Johannessen, J.B.; Hagen, K.; Haaland, Å.; Jónsdottir, A.B.; Nøklestad, A.; Kokkinakis, D.; Meurer, P.; Bick, E.; Haltrup, D. Named entity recognition for the mainland Scandinavian languages. Lit. Linguist. Comput. 2005, 20, 91–102. [Google Scholar] [CrossRef]
- Luoma, J.; Oinonen, M.; Pyykönen, M.; Laippala, V.; Pyysalo, S. A broad-coverage corpus for finnish named entity recognition. In Proceedings of the 12th Language Resources and Evaluation Conference, Le Palais du Pharo, France, 11–16 May 2020; pp. 4615–4624. [Google Scholar]
- Kettunen, K.; Löfberg, L. Tagging named entities in 19th century and modern Finnish newspaper material with a Finnish semantic tagger. In Proceedings of the 21st Nordic Conference on Computational Linguistics, Gothenburg, Sweden, 22–24 May 2017; pp. 29–36. [Google Scholar]
- Ruokolainen, T.; Kauppinen, P.; Silfverberg, M.; Lindén, K. A Finnish news corpus for named entity recognition. Lang. Resour. Eval. 2020, 54, 247–272. [Google Scholar] [CrossRef] [Green Version]
- Akbik, A.; Bergmann, T.; Blythe, D.; Rasul, K.; Schweter, S.; Vollgraf, R. FLAIR: An easy-to-use framework for state-of-the-art NLP. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics (Demonstrations), Minneapolis, MN, USA, 3–5 June 2019; pp. 54–59. [Google Scholar]
- Akbik, A.; Blythe, D.; Vollgraf, R. Contextual string embeddings for sequence labeling. In Proceedings of the 27th International Conference on Computational Linguistics, Santa Fe, NM, USA, 20–26 August 2018; pp. 1638–1649. [Google Scholar]
- Akbik, A.; Bergmann, T.; Vollgraf, R. Pooled contextualized embeddings for named entity recognition. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Minneapolis, MN, USA, 3–5 June 2019; Volume 1, pp. 724–728. [Google Scholar]
- Lafferty, J.; McCallum, A.; Pereira, F.C. Conditional random fields: Probabilistic models for segmenting and labeling sequence data. In Proceedings of the Eighteenth International Conference on Machine Learning, San Francisco, CA, USA, 28 June–1 July 2001; pp. 282–289. [Google Scholar]
- Veličković, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. arXiv 2017, arXiv:1710.10903. [Google Scholar]
- Zhang, Y.; Qi, P.; Manning, C.D. Graph convolution over pruned dependency trees improves relation extraction. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Zhang, J.; Shi, X.; Xie, J.; Ma, H.; King, I.; Yeung, D.Y. Gaan: Gated attention networks for learning on large and spatiotemporal graphs. In Proceedings of the Association for Uncertainty in Artificial Intelligence, Monterey, CA, USA, 7–9 August 2018; pp. 339–349. [Google Scholar]
- Lee, J.B.; Rossi, R.; Kong, X. Graph classification using structural attention. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, New York, NY, USA, 19–23 August 2018; pp. 1666–1674. [Google Scholar]
- Virtanen, A.; Kanerva, J.; Ilo, R.; Luoma, J.; Luotolahti, J.; Salakoski, T.; Ginter, F.; Pyysalo, S. Multilingual is not enough: BERT for Finnish. arXiv 2019, arXiv:1912.07076. [Google Scholar]
- Akhtyamova, L.; Martínez, P.; Verspoor, K.; Cardiff, J. testing contextualized word embeddings to improve NER in Spanish clinical case narratives. IEEE Access 2020, 8, 164717–164726. [Google Scholar] [CrossRef]
- Yan, H.; Jin, X.; Meng, X.; Guo, J.; Cheng, X. Event detection with multi-order graph convolution and aggregated attention. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, Hong Kong, China, 3–7 November 2019; pp. 5766–5770. [Google Scholar]
- Solberg, P.E.; Skjærholt, A.; Øvrelid, L.; Hagen, K.; Johannessen, J.B. The Norwegian Dependency Treebank. In Proceedings of the Ninth International Conference on Language Resources and Evaluation, Reykjavik, Iceland, 26–31 May 2014. [Google Scholar]
- Øvrelid, L.; Hohle, P. Universal Dependencies for Norwegian. In Proceedings of the Tenth International Conference on Language Resources and Evaluation, Portorož, Slovenia, 23–28 May 2016. [Google Scholar]
- Velldal, E.; Øvrelid, L.; Hohle, P. Joint UD parsing of Norwegian Bokmål and Nynorsk. In Proceedings of the 21st Nordic Conference of Computational Linguistics, Gothenburg, Sweden, 22–24 May 2017; pp. 1–10. [Google Scholar]
- Buch-Kromann, M. The danish dependency treebank and the DTAG treebank tool. In Proceedings of the 2nd Workshop on Treebanks and Linguistic Theories (TLT), Växjö, Sweden, 14–15 November 2003; pp. 217–220. [Google Scholar]
- Johannsen, A.; Alonso, H.M.; Plank, B. Universal dependencies for danish. In Proceedings of the International Workshop on Treebanks and Linguistic Theories (TLT14), Warsaw, Poland, 11–12 December 2015; p. 157. [Google Scholar]
- Keson, B. Vejledning til det Danske Morfosyntaktisk Taggede PAROLE-Korpus; Technical Report; Det Danske Sprog og Litteraturselskab (DSL): Copenhagen, Denmark, 2000. [Google Scholar]
- Nivre, J.; De Marneffe, M.C.; Ginter, F.; Goldberg, Y.; Hajic, J.; Manning, C.D.; McDonald, R.; Petrov, S.; Pyysalo, S.; Silveira, N.; et al. Universal dependencies v1: A multilingual treebank collection. In Proceedings of the Tenth International Conference on Language Resources and Evaluation (LREC’16), Portorož, Slovenia, 23–28 May 2016; pp. 1659–1666. [Google Scholar]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching word vectors with subword information. Trans. Assoc. Comput. Linguist. 2017, 5, 135–146. [Google Scholar] [CrossRef] [Green Version]
- Yang, J.; Zhang, Y. NCRF++: An Open-source Neural Sequence Labeling Toolkit. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics, Melbourne, Australia, 15–20 July 2018; pp. 74–79. [Google Scholar]
- Wolf, T.; Chaumond, J.; Debut, L.; Sanh, V.; Delangue, C.; Moi, A.; Cistac, P.; Funtowicz, M.; Davison, J.; Shleifer, S.; et al. Transformers: State-of-the-art natural language processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing, Virtual, 16–20 November 2020; pp. 38–45. [Google Scholar]
- Okazaki, N. CRFsuite: A Fast Implementation of Conditional Random Fields. Software Package. 2007. Available online: http://www.chokkan.org/software/crfsuite (accessed on 20 May 2021).
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. In Proceedings of the 2017 International Conference on Learning Representations, Toulon, France, 24–26 April 2017. [Google Scholar]
- Huang, W.; Zhang, T.; Rong, Y.; Huang, J. Adaptive sampling towards fast graph representation learning. In Proceedings of the 32nd Conference on Neural Information Processing Systems, Montréal, QC, Canada, 2–8 December 2018. [Google Scholar]
- Defferrard, M.; Bresson, X.; Vandergheynst, P. Convolutional neural networks on graphs with fast localized spectral filtering. Adv. Neural Inf. Processing Syst. 2016, 29, 3844–3852. [Google Scholar]
- Gui, T.; Zou, Y.; Zhang, Q.; Peng, M.; Fu, J.; Wei, Z.; Huang, X.J. A lexicon-based graph neural network for chinese ner. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, Hong Kong, China, 3–7 November 2019; pp. 1040–1050. [Google Scholar]
- Honnibal, M.; Montani, I.; Van Landeghem, S.; Boyd, A. spaCy: Industrial-Strength Natural Language Processing in Python. Software Package. 2020. Available online: https://spacy.io (accessed on 20 May 2021).
| Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}