
A Bottleneck Auto-Encoder for F0 Transformations on Speech and Singing Voice


Abstract
:1. Introduction
1.1. Related Work
1.1.1. F0 Analysis
1.1.2. Voice Transformation on Mel-Spectrograms
1.1.3. Auto-Encoders
1.2. Contributions
2. Materials and Methods
2.1. Problem Formulation
- The desired contour should be followed exactly;
- The result should sound like a human.
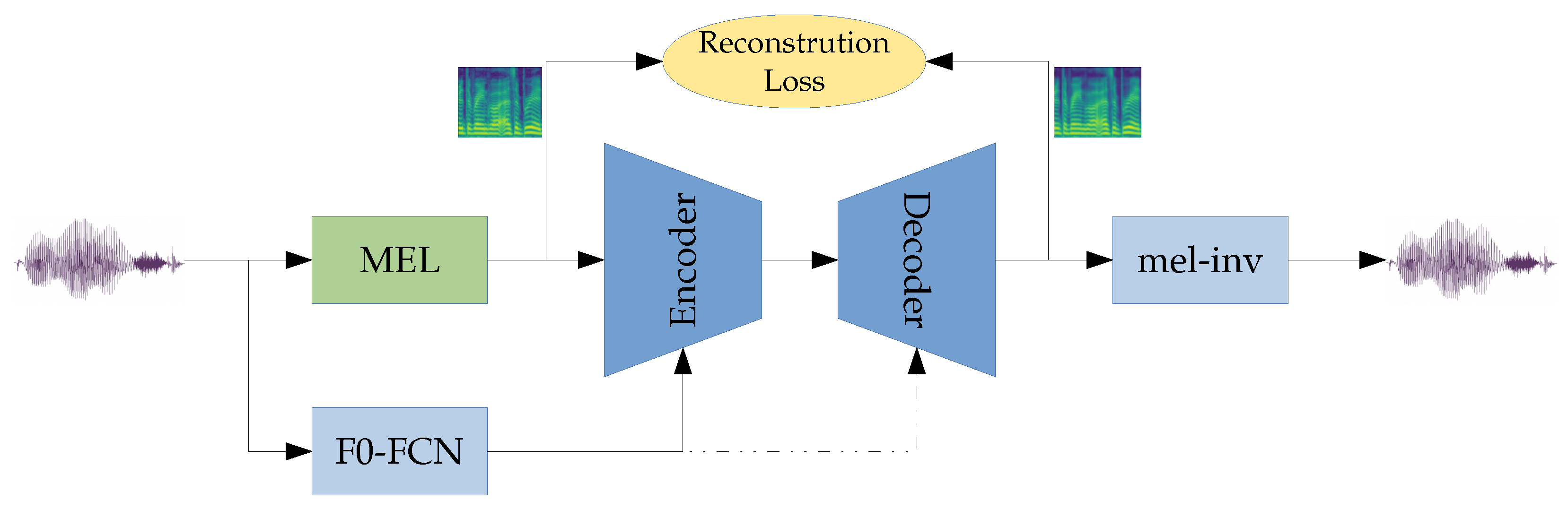
2.2. Proposed Model
2.2.1. Input Data
2.2.2. Network Architecture
2.2.3. Training Procedure
2.3. Datasets
- A pure singing-voice dataset, obtained by combining several publicly available datasets and our own proprietary datasets;
- A hybrid dataset of speech and singing, consisting of the two datasets above;
- A smaller speech dataset, consisting of a reduced number of VCTK speakers to match the duration of the singing-voice dataset.
- CREL Research Database (SVDB) [52];
- NUS sung and spoken lyrics corpus [53];
- Byzantine singing from the i-Treasures Intangible Cultural Heritage dataset [54];
- PJS phoneme-balanced Japanese singing-voice corpus [55];
- JVS-MuSiC [56];
- Tohoku Kiritan and Itako singing database [57];
- VocalSet: A singing voice dataset [58];
- Singing recordings from our internal singing databases used for the IRCAM singing synthesizer [59] and other projects.
Dataset Splits
2.4. Experimental Setup
3. Results
3.1. Accuracy
3.2. Bottleneck Size Analysis
3.3. Synthesis Quality
| Rating | Score |
| Real recording | 5 |
| Perceptible but not annoying | 4 |
| Slightly annoying | 3 |
| Annoying degradation | 2 |
| Very annoying | 1 |
3.4. Visualization of the Latent Code
4. Discussion
4.1. Conclusions
4.2. Future Work
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Network Architecture

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Inputs | Output | #Filters | Kernel Size | Stride | Activation | Out Shape |
|---|---|---|---|---|---|---|---|
| Conv2DTranspose | 2 | (1, 80) | none | ||||
| Concat | mel, | ||||||
| Conv2D | 512 | ReLU | |||||
| Conv2D | 512 | ReLU | |||||
| Conv2D | 512 | ReLU | |||||
| Conv2D | 512 | ReLU | |||||
| Conv2D | 512 | ReLU | |||||
| Conv2D | 512 | ReLU | |||||
| Conv2D | 512 | ReLU | |||||
| Conv2D | 512 | ReLU | |||||
| Conv2D | 512 | ReLU | |||||
| Conv2D | code | none |
| Layer | Inputs | Output | #Filters | Kernel Size | Stride | Activation | Out Shape |
|---|---|---|---|---|---|---|---|
| Concat | code, | ||||||
| Conv2D | 512 | ReLU | |||||
| Conv2DTranspose | 512 | ReLU | |||||
| Conv2D | 512 | ReLU | |||||
| Conv2DTranspose | 512 | ReLU | |||||
| Conv2D | 512 | ReLU | |||||
| Conv2DTranspose | 512 | ReLU | |||||
| Conv2D | 512 | ReLU | |||||
| Conv2DTranspose | 512 | ReLU | |||||
| Conv2D | 512 | ReLU | |||||
| Conv2DTranspose | 512 | ReLU | |||||
| Conv2D | mel’ | 1 | none |
References
- Dudley, H. Remaking speech. J. Acoust. Soc. Am. 1939, 11, 169–177. [Google Scholar] [CrossRef]
- Flanagan, J.L.; Golden, R.M. Phase vocoder. Bell Syst. Technol. J. 1966, 45, 1493–1509. [Google Scholar] [CrossRef]
- Moulines, E.; Charpentier, F. Pitch-synchronous waveform processing techniques for text-to-speech synthesis using diphones. Speech Commun. 1990, 9, 453–467. [Google Scholar] [CrossRef]
- Quatieri, T.F.; McAulay, R.J. Shape invariant time-scale and pitch modification of speech. IEEE Trans. Signal Process. 1992, 40, 497–510. [Google Scholar] [CrossRef]
- Roebel, A. A shape-invariant phase vocoder for speech transformation. In Proceedings of the Digital Audio Effects (DAFx), Graz, Austria, 6–10 September 2010. [Google Scholar]
- Kawahara, H. STRAIGHT, exploitation of the other aspect of VOCODER: Perceptually isomorphic decomposition of speech sounds. Acoust. Sci. Technol. 2006, 27, 349–353. [Google Scholar] [CrossRef] [Green Version]
- Morise, M.; Yokomori, F.; Ozawa, K. World: A vocoder-based high-quality speech synthesis system for real-time applications. Ieice Trans. Inf. Syst. 2016, 99, 1877–1884. [Google Scholar] [CrossRef] [Green Version]
- Degottex, G.; Lanchantin, P.; Roebel, A.; Rodet, X. Mixed source model and its adapted vocal tract filter estimate for voice transformation and synthesis. Speech Commun. 2013, 55, 278–294. [Google Scholar] [CrossRef]
- Huber, S.; Roebel, A. On glottal source shape parameter transformation using a novel deterministic and stochastic speech analysis and synthesis system. In Proceedings of the 16th Annual Conference of the International Speech Communication Association (Interspeech ISCA), Dresden, Germany, 6–10 September 2015. [Google Scholar]
- Qian, K.; Jin, Z.; Hasegawa-Johnson, M.; Mysore, G.J. F0-consistent many-to-many non-parallel voice conversion via conditional autoencoder. In Proceedings of the ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020. [Google Scholar]
- Desai, S.; Raghavendra, E.V.; Yegnanarayana, B.; Black, A.W.; Prahallad, K. Voice conversion using artificial neural networks. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing (ICASSP), Taipei, Taiwan, 19–24 April 2009. [Google Scholar]
- Kameoka, H.; Kaneko, T.; Tanaka, K.; Hojo, N. Stargan-vc: Non-parallel many-to-many voice conversion using star generative adversarial networks. In Proceedings of the 2018 IEEE Spoken Language Technology Workshop (SLT), Athens, Greece, 18–21 December 2018. [Google Scholar]
- Zhang, J.X.; Ling, Z.H.; Dai, L.R. Non-parallel sequence-to-sequence voice conversion with disentangled linguistic and speaker representations. Trans. Audio Speech Lang. Process. 2019, 28, 540–552. [Google Scholar] [CrossRef]
- Qian, K.; Zhang, Y.; Chang, S.; Yang, X.; Hasegawa-Johnson, M. Autovc: Zero-shot voice style transfer with only autoencoder loss. In Proceedings of the International Conference on Machine Learning (ICML). PMLR, Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]
- Ferro, R.; Obin, N.; Roebel, A. CycleGAN Voice Conversion of Spectral Envelopes using Adversarial Weights. In Proceedings of the European Signal Processing Conference (EUSIPCO), Amsterdam, The Netherlands, 18–21 January 2021. [Google Scholar]
- Robinson, C.; Obin, N.; Roebel, A. Sequence-to-sequence modelling of f0 for speech emotion conversion. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019. [Google Scholar]
- Le Moine, C.; Obin, N.; Roebel, A. Towards end-to-end F0 voice conversion based on Dual-GAN with convolutional wavelet kernels. In Proceedings of the European Signal Processing Conference (EUSIPCO), Dublin, Ireland, 23–27 August 2021. [Google Scholar]
- Zhao, G.; Sonsaat, S.; Levis, J.; Chukharev-Hudilainen, E.; Gutierrez-Osuna, R. Accent conversion using phonetic posteriorgrams. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018. [Google Scholar]
- Umbert, M.; Bonada, J.; Goto, M.; Nakano, T.; Sundberg, J. Expression control in singing voice synthesis: Features, approaches, evaluation, and challenges. IEEE Signal Process. Mag. 2015, 32, 55–73. [Google Scholar] [CrossRef] [Green Version]
- Umbert, M.; Bonada, J.; Blaauw, M. Generating singing voice expression contours based on unit selection. In Proceedings of the Stockholm Music Acoustics Conference (SMAC), Stockholm, Sweden, 30 July–3 August 2013. [Google Scholar]
- Ardaillon, L.; Chabot-Canet, C.; Roebel, A. Expressive control of singing voice synthesis using musical contexts and a parametric f0 model. In Proceedings of the 17th Annual Conference of the International Speech Communication Association (INTERSPEECH), ISCA, San Francisco, CA, USA, 8–12 September 2016. [Google Scholar]
- Ardaillon, L.; Degottex, G.; Roebel, A. A multi-layer F0 model for singing voice synthesis using a B-spline representation with intuitive controls. In Proceedings of the 16th Annual Conference of the International Speech Communication Association (INTERSPEECH), ISCA, Dresden, Germany, 6–10 September 2015. [Google Scholar]
- Bonada, J.; Umbert Morist, M.; Blaauw, M. Expressive singing synthesis based on unit selection for the singing synthesis challenge 2016. In Proceedings of the 17th Annual Conference of the International Speech Communication Association (INTERSPEECH), ISCA, San Francisco, CA, USA, 8–12 September 2016. [Google Scholar]
- Roebel, A.; Bous, F. Towards Universal Neural Vocoding with a Multi-band Excited WaveNet. arXiv 2021, arXiv:2110.03329. [Google Scholar]
- Veaux, C.; Rodet, X. Intonation conversion from neutral to expressive speech. In Proceedings of the Twelfth Annual Conference of the International Speech Communication Association (INTERSPEECH), ISCA, Florence, Italy, 27–31 August 2011. [Google Scholar]
- Farner, S.; Roebel, A.; Rodet, X. Natural transformation of type and nature of the voice for extending vocal repertoire in high-fidelity applications. In Proceedings of the Audio Engineering Society Conference: 35th International Conference: Audio for Games, London, UK, 11–13 February 2009. [Google Scholar]
- Arias, P.; Rachman, L.; Liuni, M.; Aucouturier, J.J. Beyond correlation: Acoustic transformation methods for the experimental study of emotional voice and speech. Emot. Rev. 2021, 13, 12–24. [Google Scholar] [CrossRef]
- Degottex, G.; Roebel, A.; Rodet, X. Pitch transposition and breathiness modification using a glottal source model and its adapted vocal-tract filter. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011. [Google Scholar]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. Image style transfer using convolutional neural networks. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial networks. Commun. ACM 2020, 63, 139–144. [Google Scholar] [CrossRef]
- He, Z.; Zuo, W.; Kan, M.; Shan, S.; Chen, X. Attgan: Facial attribute editing by only changing what you want. Trans. Image Process. 2019, 28, 5464–5478. [Google Scholar] [CrossRef] [Green Version]
- Lange, S.; Riedmiller, M. Deep auto-encoder neural networks in reinforcement learning. In Proceedings of the The 2010 International Joint Conference on Neural Networks (IJCNN), Barcelona, Spain, 18–23 July 2010; pp. 1–8. [Google Scholar]
- Lample, G.; Zeghidour, N.; Usunier, N.; Bordes, A.; Denoyer, L.; Ranzato, M. Fader networks: Manipulating images by sliding attributes. In Proceedings of the International Conference on Neural Information Processing Systems (NeurIPS), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Qian, K.; Zhang, Y.; Chang, S.; Hasegawa-Johnson, M.; Cox, D. Unsupervised speech decomposition via triple information bottleneck. In Proceedings of the International Conference on Machine Learning (ICML). PMLR, Virtual, 13–18 July 2020. [Google Scholar]
- Rabiner, L.; Cheng, M.; Rosenberg, A.; McGonegal, C. A comparative performance study of several pitch detection algorithms. IEEE Trans. Acoust. Speech Signal Process. 1976, 24, 399–418. [Google Scholar] [CrossRef]
- De Cheveigné, A.; Kawahara, H. YIN, a fundamental frequency estimator for speech and music. J. Acoust. Soc. Am. 2002, 111, 1917–1930. [Google Scholar] [CrossRef] [Green Version]
- Mauch, M.; Dixon, S. pYIN: A fundamental frequency estimator using probabilistic threshold distributions. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing (ICASSP), Florence, Italy, 4–9 May 2014. [Google Scholar]
- Camacho, A.; Harris, J.G. A sawtooth waveform inspired pitch estimator for speech and music. J. Acoust. Soc. Am. 2008, 124, 1638–1652. [Google Scholar] [CrossRef] [Green Version]
- Babacan, O.; Drugman, T.; d’Alessandro, N.; Henrich, N.; Dutoit, T. A comparative study of pitch extraction algorithms on a large variety of singing sounds. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing (ICASSP), Vancouver, BC, Canada, 26–31 May 2013. [Google Scholar]
- Kadiri, S.R.; Yegnanarayana, B. Estimation of Fundamental Frequency from Singing Voice Using Harmonics of Impulse-like Excitation Source. In Proceedings of the 19 Annual Conference of the International Speech Communication Association (INTERSPEECH), ISCA, Hyderabad, India, 2–6 September 2018. [Google Scholar]
- Kim, J.W.; Salamon, J.; Li, P.; Bello, J.P. Crepe: A convolutional representation for pitch estimation. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018. [Google Scholar]
- Ardaillon, L.; Roebel, A. Fully-convolutional network for pitch estimation of speech signals. In Proceedings of the 20th Annual Conference of the International Speech Communication Association (INTERSPEECH), ISCA, Graz, Austria, 15–19 September 2019. [Google Scholar]
- Roebel, A.; Bous, F. Neural Vocoding for Singing and Speaking Voices with the Multi-band Excited WaveNet. Information 2022, in press. [Google Scholar]
- Shen, J.; Pang, R.; Weiss, R.J.; Schuster, M.; Jaitly, N.; Yang, Z.; Chen, Z.; Zhang, Y.; Wang, Y.; Skerrv-Ryan, R.; et al. Natural tts synthesis by conditioning wavenet on mel spectrogram predictions. In Proceedings of the International Conference on Acoustics, Speech and Signal Processing (ICASSP), Calgary, AB, Canada, 15–20 April 2018. [Google Scholar]
- Ping, W.; Peng, K.; Gibiansky, A.; Arik, S.Ö.; Kannan, A.; Narang, S.; Raiman, J.; Miller, J. Deep Voice 3: Scaling Text-to-Speech with Convolutional Sequence Learning. In Proceedings of the 7th International Conference on Learning Representations (ICLR), Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Jang, W.; Lim, D.; Yoon, J. Universal MelGAN: A Robust Neural Vocoder for High-Fidelity Waveform Generation in Multiple Domains. arXiv 2020, arXiv:2011.09631. [Google Scholar]
- Bous, F.; Roebel, A. Analysing deep learning-spectral envelope prediction methods for singing synthesis. In Proceedings of the European Signal Processing Conference (EUSIPCO), A Coruña, Spain, 2–6 September 2019. [Google Scholar]
- Nair, V.; Hinton, G.E. Rectified linear units improve restricted boltzmann machines. In Proceedings of the International Conference on Machine Learning (ICML), PMLR, Haifa, Israel, 25 June 2010. [Google Scholar]
- Kingma, D.P.; Ba, J. Adam: A method for stochastic optimization. In Proceedings of the 3rd International Conference on Learning Representations (ICLR), Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Yamagishi, J.; Veaux, C.; MacDonald, K. CSTR VCTK Corpus: English Multi-Speaker Corpus for CSTR Voice Cloning Toolkit (version 0.92); The Centre of Speech Technology Research (CSTR), University of Edinburgh: Edinburgh, Scotland, 2019. [Google Scholar]
- Le Moine, C.; Obin, N. Att-HACK: An Expressive Speech Database with Social Attitudes. arXiv 2020, arXiv:2004.04410. [Google Scholar]
- Tsirulnik, L.; Dubnov, S. Singing Voice Database. In Proceedings of the International Conference on Speech and Computer (ICSC), Noida, India, 7–9 March 2019. [Google Scholar]
- Duan, Z.; Fang, H.; Li, B.; Sim, K.C.; Wang, Y. The NUS sung and spoken lyrics corpus: A quantitative comparison of singing and speech. In Proceedings of the 6th Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Kaohsiung, Taiwan, 29 October–1 November 2013. [Google Scholar]
- Grammalidis, N.; Dimitropoulos, K.; Tsalakanidou, F.; Kitsikidis, A.; Roussel, P.; Denby, B.; Chawah, P.; Buchman, L.; Dupont, S.; Laraba, S.; et al. The i-treasures intangible cultural heritage dataset. In Proceedings of the 3rd International Symposium on Movement and Computing (MOCO), Thessaloniki, Greece, 5–6 July 2016. [Google Scholar]
- Koguchi, J.; Takamichi, S.; Morise, M. PJS: Phoneme-balanced Japanese singing-voice corpus. In Proceedings of the Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Auckland, New Zealand, 7–10 December 2020. [Google Scholar]
- Tamaru, H.; Takamichi, S.; Tanji, N.; Saruwatari, H. JVS-MuSiC: Japanese multispeaker singing-voice corpus. arXiv 2020, arXiv:2001.07044. [Google Scholar]
- Ogawa, I.; Morise, M. Tohoku Kiritan singing database: A singing database for statistical parametric singing synthesis using Japanese pop songs. Acoust. Sci. Technol. 2021, 42, 140–145. [Google Scholar] [CrossRef]
- Wilkins, J.; Seetharaman, P.; Wahl, A.; Pardo, B. VocalSet: A Singing Voice Dataset. In Proceedings of the International Society for Music Information Retrieval Conference (ISMIR), ISMIR, Paris, France, 23–27 September 2018. [Google Scholar]
- Ardaillon, L. Synthesis and expressive transformation of singing voice. Ph.D. Thesis, Université Pierre et Marie Curie, Paris, France, 2017. Available online: https://hal.archives-ouvertes.fr/tel-01710926/document (accessed on 20 January 2022).
- Fant, G.; Liljencrants, J.; Lin, Q.G. A four-parameter model of glottal flow. STL-QPSR 1985, 4, 1–13. [Google Scholar]
- Fant, G. The LF-model revisited. Transformations and frequency domain analysis. Speech Trans. Lab. Q. Rep. R. Inst. Tech. Stockh. 1995, 2, 40. [Google Scholar]






| Code Size | Singing | Speech | Speech, Small Dataset | Speech + Singing | Speech, #Filters 256 | Speech, #Filters 128 |
|---|---|---|---|---|---|---|
| 1 | 3.13 (3.46) | 3.52 (3.55) | 3.68 (3.79) | |||
| 2 | 2.47 (2.91) | 2.84 (2.89) | 2.90 (3.36) | 3.06 (3.17) | 2.99 (3.03) | 3.09 (3.12) |
| 3 | 2.41 (2.70) | 2.51 (2.55) | 2.61 (2.72) | 2.85 (2.84) | ||
| 4 | 2.06 (2.44) | 2.36 (2.39) | 2.42 (2.74) | 2.54 (2.64) | 2.48 (2.51) | 2.68 (2.68) |
| 5 | 2.13 (2.45) | 2.19 (2.21) | 2.47 (2.46) | |||
| 6 | 2.03 (2.29) | 2.08 (2.11) | 2.14 (2.38) | 2.30 (2.39) | 2.16 (2.19) | 2.32 (2.33) |
| 7 | 1.96 (1.99) | 2.24 (2.24) | ||||
| 8 | 1.87 (1.90) | 1.94 (2.17) | 1.97 (2.00) | 2.18 (2.21) | ||
| 9 | 1.83 (1.85) | 1.88 (2.14) | 1.91 (1.93) | 2.10 (2.10) | ||
| 10 | 1.75 (1.76) | 1.81 (1.98) | 1.83 (1.85) | 1.97 (1.96) | ||
| 11 | 1.69 (1.71) | 1.76 (1.77) | 1.95 (1.95) | |||
| 12 | 1.64 (1.66) | 1.67 (1.87) | 1.71 (1.73) | 1.92 (1.92) | ||
| 13 | 1.56 (1.58) | 1.89 (1.89) | ||||
| 14 | 1.52 (1.54) | 1.56 (1.75) | 1.63 (1.65) | 1.85 (1.85) | ||
| 16 | 1.53 (1.54) |
| Transposition | Ground Truth | PaN Vocoder | (Speech) | (Speech) | (Speech + Singing) | (Speech) |
|---|---|---|---|---|---|---|
| 1760 | ||||||
| 1320 | ||||||
| 880 | ||||||
| 440 | ||||||
| 0 | ||||||
| −440 | ||||||
| −880 | ||||||
| −1320 | ||||||
| −1760 | ||||||
| average |
| Transposition | Ground Truth | PaN Vocoder | (Singing) | (Speech + Singing) | (Singing) |
|---|---|---|---|---|---|
| 2200 | |||||
| 1760 | |||||
| 1320 | |||||
| 880 | |||||
| 440 | |||||
| 0 | |||||
| −440 | |||||
| −880 | |||||
| −1320 | |||||
| −1760 | |||||
| −2200 | |||||
| average |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bous, F.; Roebel, A. A Bottleneck Auto-Encoder for F0 Transformations on Speech and Singing Voice. Information 2022, 13, 102. https://doi.org/10.3390/info13030102
Bous F, Roebel A. A Bottleneck Auto-Encoder for F0 Transformations on Speech and Singing Voice. Information. 2022; 13(3):102. https://doi.org/10.3390/info13030102
Chicago/Turabian StyleBous, Frederik, and Axel Roebel. 2022. "A Bottleneck Auto-Encoder for F0 Transformations on Speech and Singing Voice" Information 13, no. 3: 102. https://doi.org/10.3390/info13030102
APA StyleBous, F., & Roebel, A. (2022). A Bottleneck Auto-Encoder for F0 Transformations on Speech and Singing Voice. Information, 13(3), 102. https://doi.org/10.3390/info13030102