
A Character String-Based Stemming for Morphologically Derivative Languages


Abstract
:1. Introduction
- In this paper, we propose a stemming model that integrates sentence context and character features. In order to study the impact of context information on the model in this paper, the model is tested on sentence-level and word-level datasets. Effective It solves the problem that the sticky language stemming task is difficult to deal with sentence-level corpus with contextual information.
- Based on the BiLSTM-CRF model, we introduce an attention mechanism to improve it, compare it with the traditional model, and comprehensively consider the data characteristics, thus verifying the effectiveness of the model in this paper.
- Regarding the role of stemming in the fields of cross-language alignment and knowledge transfer, in this paper we propose a multilingual stemming method that automatically learns morphological phonetic inflections based on character embeddings and sequence models. Firstly, the characteristics of the dataset were analyzed, and letters were normalized for three agglutinative languages such as Uyghur, Kazakh and Kirghiz, and then a comparative experiment was conducted on the same dataset with two distribution forms of these three derivative languages. In addition, the proposed model is compared with traditional models and achieves better performance on stemming research.
2. Related Work
3. Methods
3.1. Stemming in Derivative Languages
- Uyghur Sentence1: u bazardin alma setiwaldi.
- Sentence2: qAlAmni qoluNGa alma.
- Kazakh Sentence1: ol at menep jater.
- Sentence2: topte bEre qaray at.
- Kirghiz Sentence1: al nArsAni bul jArgA qoy.
- Sentence2: bizdin OydU qoy bar.
(after split) vAllik + kA vAllik + ni qox + saq vAllik + niN vikki hAssi + gA tAN bol + idu.
(after splitting) Elw + gE Elw + de qos + sa Elw + deN Eke EsE + se + nE tEN bol + a + de.
(After segmentation) AlOO + gU AlOO + nO qox + so AlOO + nOn Aki AssA + si + nA tAN bol + ot.
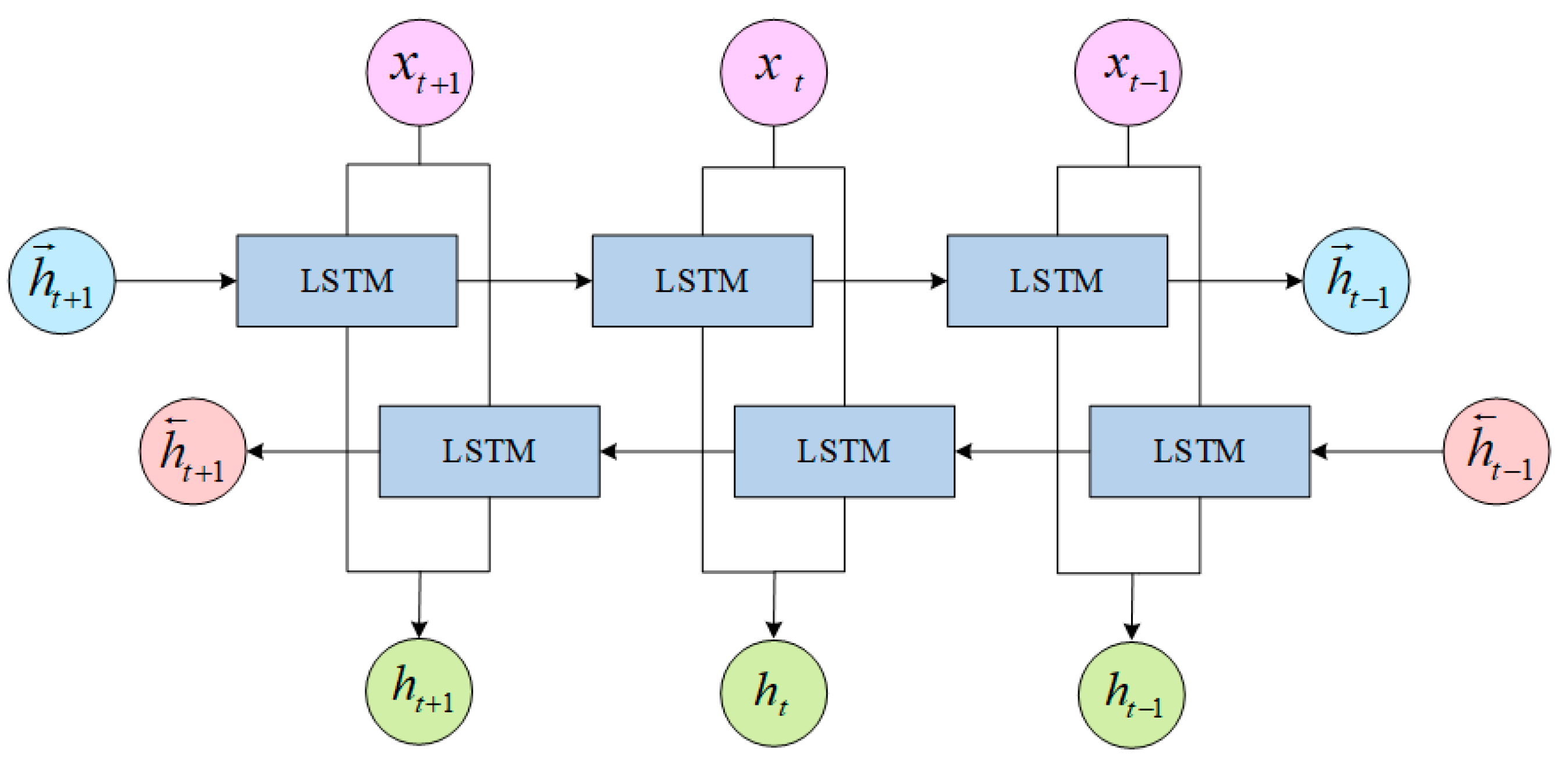
3.2. BiLSTM Layer
3.3. Attention Layer
3.4. CRF Layer
4. Experiment
4.1. Datasets
4.2. Experimental Preprocessing
4.2.1. Char Normalization
4.2.2. Data Tagging
- B-S: Stem first character
- I-S: Stem non-first character
- B-E: Affix first character
- I-E: Affix non-first character
- O: Non-morpheme character (number)
4.3. Experiment Settings
4.3.1. Data Distribution
4.3.2. Evaluation Indicators
4.4. Results
5. Conclusions and Future Works
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ablimit, M.; Parhat, A.; Hamdulla, T.; Zheng, F. A multilingual language processing tool for Uyghur, Kazak and Kirghiz. In Proceedings of the 2017 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Kuala Lumpur, Malaysia, 12–15 December 2017; pp. 737–740. [Google Scholar]
- Ablimit, M.; Kawahara, T.; Pattar, A.; Hamdulla, A. Stem-Affix based Uyghur Morphological Analyzer. Int. J. Future Gener. Commun. Netw. 2016, 9, 59–72. [Google Scholar] [CrossRef]
- Abmitl, M.; Pattar, A.; Hamdulla, A. Multilayer structure based lexiconoptimization for language modeling. Tsinghua Univ. (Sci. Technol.) 2017, 57, 257–263. [Google Scholar]
- Majumder, P.; Mitra, M.; Parui, S.K. YASS: Yet another suffix stripper. ACM Trans. Inf. Syst. 2007, 25, 409–420. [Google Scholar] [CrossRef]
- Chrupala, G.; Dinu, G.; Genabith, J.V. Learning morphology with Morfette. In Proceedings of the International Conference on Language Resources and Evaluation, LREC 2008, Marrakech, Morocco, 26 May–1 June 2008. [Google Scholar]
- Thomas, M.; Cotterell, R.; Fraser, A. Joint Lemmatization and Morphological Tagging with Lemming. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015. [Google Scholar]
- Bergmanis, T.; Kann, K.; Schütze, H. Training Data Augmentation for Low-Resource Morphological Inflection. In Proceedings of the CoNLL SIGMORPHON 2017 Shared Task: Universal Morphological Reinflection, Vancouver, BC, Canada, 3–4 August 2017. [Google Scholar]
- Malaviya, C.; Wu, S.; Ctterell, R. A Simple Joint Model for Improved Contextual Neural Lemmatization. arXiv 2019, arXiv:1904.02306. [Google Scholar]
- Sediyegvl, E.; Xiang, L.; Zong, C.; Akbar, P.; Askar, H. A Multi-Strategy Approach to Uyghur Stemming. J. Chin. Inf. Process. 2015, 29, 204–210. [Google Scholar]
- Ulan, N.; Rahmotola, M.; Aska, H. The Method of Kazakh Word Lemmatization Based on N-gram Model. Comput. Knowl. Technol. 2017, 13, 160–162. [Google Scholar]
- Abudukelimu, H.; Cheng, Y.; Liu, Y.; Sun, M. Uyghur morphological segmentation with bidirectional GRU neural networks. J. Tsinghua Univ. (Sci. Technol.) 2017, 57, 1–6. [Google Scholar]
- Ablimit, M.; Parhat, A.; Hamdulla, T.; Zheng, F. Multilingual Stemming and Term extraction for Uyghur, Kazak and Kirghiz. In Proceedings of the 2018 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Honolulu, HI, USA, 12–15 November 2018; pp. 587–590. [Google Scholar]
- Wumaierjiang, M.; Gulinigeer, A.; Maihemuti, M.; Kahaerjiang, A.; Tuergen, Y. A Comparative Study of Uzbek Stemming Algorithms. J. Chin. Inf. Processing 2020, 34, 45–50. [Google Scholar]
- Sardar, P.; Mijit, A.; Askar, H. Kazakh Short Text Classification Based on Stem Unit and Convolutional Neural Network. J. Chin. Comput. Syst. 2020, 41, 1627–1633. [Google Scholar]
- Mukaddam, I.; Sardar, P.; Askar, H. A Multilingual Morpheme Segmentation Tool. Video Eng. 2020, 44, 46–51. [Google Scholar]
- Wu, S.; Qian, Q.; Hu, T. Comparative Analysis of Methods and Tools for Word Stemming. Libr. Inf. Serv. 2012, 56, 109–115. [Google Scholar]
- Parhat, S.; Gao, T.; Ablimit, M. A morpheme sequence and convolutional neural network based Kazakh text classification. In Proceedings of the 2019 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Lanzhou, China, 18–21 November 2019. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J.S. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef] [PubMed]
- Bahdanau, D.; Cho, K.; Bengio, Y.D. Neural machine translation by jointly learning to align and translate. arXiv 2015, arXiv:1409.0473. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. In Advances in Neural Information Processing Systems; The Mit Press: Cambridge, MA, USA, 2013; pp. 3111–3119. [Google Scholar]
- Zhang, T.; Zhang, J. Across-domain Chinese word segmentation model based on feature transfer. J. Commun. Univ. China (Sci. Technol.) 2021, 28, 41–45. [Google Scholar]
- Halidanmu, A.; Sun, M.; Liu, Y.; Abudukelimu, A. THUUyMorph:An Uyghur Morpheme Segmentation Corpus. J. Chin. Inf. Process. 2018, 32, 81–86. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Latin | Uyghur | Latin | Uyghur | Latin | Uyghur | Latin | Kazakh | Latin | Kazakh | Latin | Kazakh | Latin | Kirghiz | Latin | Kirghiz | Latin | Kirghiz |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| a | ا | m | م | q | ق | a | ا | m | م | q | ق | a | ا | m | م | q | ق |
| A | ە | l | ل | f | ف | v | ء | l | ل | f | ف | A | ە | l | ل | f | ف |
| e | ې | b | ب | k | ك | E | ە | b | ب | k | ك | e | ى | b | ب | k | ك |
| i | ى | G | غ | g | گ | e | ى | G | ع | g | گ | i | ئ | G | ع | g | گ |
| o | و | h | ھ | N | ڭ | o | و | h | ھ | N | ڭ | o | و | p | پ | N | ڭ |
| u | ۇ | c | چ | d | د | u | ۇ | c | چ | d | د | u | ۇ | c | چ | d | د |
| O | ۆ | H | خ | y | ي | V | ۆ | H | ح | y | ي | U | ۅ | H | ح | y | ي |
| U | ۈ | j | ج | w | ۋ | z | ز | j | ج | w | ۋ | O | ۉ | j | ج | w | ۋ |
| x | ش | n | ن | J | ژ | x | ش | n | ن | p | پ | x | ش | n | ن | z | ز |
| s | س | t | ت | r | ر | s | س | t | ت | r | ر | s | س | t | ت | r | ر |
| z | ز | p | پ | v | ئ |
| Language | Words | Stems | Derivational Suffixes | Inflectional Suffixes |
|---|---|---|---|---|
| Uyghur | yazGucisi = yaz + Guci + si | yaz | Guci | si |
| Kazakh | sabaqtastar = sabaq + tas + tar | sabaq | tas | tar |
| Kirghiz | qoycular = qoy + cu + lar | qoy | cu | lar |
| Languages | Ambiguous Words | Semantic 1 | Semantic 2 |
|---|---|---|---|
| Uyghur | alma | Apple | Don’t take |
| Kazakh | at | Horse | Throw |
| Kirghiz | qoy | Sheep | Put |
| Language | Variants | Stems | Suffixes |
|---|---|---|---|
| Uyghur | vAllikkA (to fifty) = vAllik + kA | vAllik (fifty) | kA |
| vAllikni (put fifty) = vAllik + ni | ni | ||
| vAllikniN (fifty) = vAllik + niN | niN | ||
| Kazakh | ElwgE (to fifty) = Elw + gE | Elw (fifty) | gE |
| Elwde (put fifty) = Elw + de | de | ||
| ElwdeN (fifty) = Elw + deN | deN | ||
| Kirghiz | AlOOgU (put fifty) = AlOO + gU | AlOO (fifty) | gU |
| AlOOnO (put fifty) = AlOO + nO | nO | ||
| AlOOnOn (fifty) = AlOO + nOn | nOn |
| Language | Sentence Number | Train | Test | Dev |
|---|---|---|---|---|
| Uyghur(Uy) | 20,000 | 16,000 | 2000 | 2000 |
| Kazakh(Kz) | 2500 | 2000 | 250 | 250 |
| Kirghiz(Kr) | 2500 | 2000 | 250 | 250 |
| Uy-Kz-Kr | 25,000 | 20,000 | 2500 | 2500 |
| Data Set | Sentence Number | Morpheme Vocab | Word Vocab | Char Vocab |
|---|---|---|---|---|
| Train | 20,000 | 253,728 | 441,509 | 1,555,895 |
| Test | 2500 | 33,942 | 59,182 | 222,567 |
| Dev | 2500 | 34,131 | 60,092 | 224,528 |
| Unified Roman | IPA | Uyghur | Kazakh | Kirghiz |
|---|---|---|---|---|
| A | ä | ە | ءا | ە |
| 1749 | 1653 | 1749, 1577, 1607 | ||
| e | ë | ې | ى | ى |
| 1744 | 1609 | 1574, 1569 | ||
| y | j | ي | ي | ي |
| 1610 | 1610 | 1610 | ||
| G | ɣ | غ | ع | ع |
| 1594 | 1593 | 1593, 1594 | ||
| N | η | ڭ | ڭ | ڭ |
| 1709 | 1709 | 1709 |
| Data Type | Data Type1 | Data Type2 |
|---|---|---|
| Train | UyS1…S16000:KzS1…S2000:KrS1…S2000 | UyS1…S4:KzS1:KrS1: …:UyS15996…S16000:KzS2000:KrS2000 |
| Test | UyS1…S2000:KzS1…S250:KrS1…S250 | UyS1…S4:KzS1:KrS1: …:UyS1996…S2000:KzS250:KrS250 |
| Dev | UyS1…S2000:KzS1…S250:KrS1…S250 | UyS1…S4:KzS1:KrS1: …:UyS1996…S2000:KzS250:KrS250 |
| Model | Data Type | P (%) | R (%) | F1 (%) |
|---|---|---|---|---|
| BiLSTM | Data type1 | 91.23 | 91.15 | 91.19 |
| Data type2 | 91.50 | 91.48 | 91.49 | |
| BiLSTM-CRF | Data type1 | 92.09 | 91.94 | 92.01 |
| Data type2 | 92.24 | 92.06 | 92.15 | |
| BiLSTM-Attention-CRF | Data type1 | 93.37 | 93.33 | 93.35 |
| Data type2 | 93.42 | 93.37 | 93.40 |
| Model | Test Set | P (%) | R (%) | F1 (%) |
|---|---|---|---|---|
| BiLSTM | Uyghur test set | 91.34 | 91.28 | 91.31 |
| Kazakh test set | 86.17 | 86.07 | 86.12 | |
| Kirghiz test set | 81.34 | 80.96 | 81.15 | |
| Multilingual test set | 91.50 | 91.48 | 91.49 | |
| BiLSTM-CRF | Uyghur test set | 92.19 | 91.93 | 92.06 |
| Kazakh test set | 87.14 | 86.97 | 87.05 | |
| Kirghiz test set | 84.16 | 84.03 | 84.09 | |
| Multilingual test set | 92.24 | 92.06 | 92.15 | |
| BiLSTM-Attention-CRF | Uyghur test set | 92.80 | 92.71 | 92.75 |
| Kazakh test set | 88.26 | 88.20 | 88.23 | |
| Kirghiz test set | 86.06 | 84.86 | 85.46 | |
| Multilingual test set | 93.42 | 93.37 | 93.40 |
| Dataset | Train | Test | Dev |
|---|---|---|---|
| THUUyMoprh | 17,629 | 1000 | 1000 |
| Model | Dataset | P (%) | R (%) | F1 (%) |
|---|---|---|---|---|
| BiLSTM | THUUyMorph dataset | 91.34 | 91.28 | 91.31 |
| Multilingual dataset | 91.50 | 91.48 | 91.49 | |
| BiLSTM-CRF | THUUyMorph dataset | 92.19 | 91.93 | 92.06 |
| Multilingual dataset | 92.24 | 92.06 | 92.15 | |
| BiLSTM-Attention-CRF | THUUyMorph dataset | 92.80 | 92.71 | 92.75 |
| Multilingual dataset | 93.42 | 93.37 | 93.40 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Imin, G.; Ablimit, M.; Yilahun, H.; Hamdulla, A. A Character String-Based Stemming for Morphologically Derivative Languages. Information 2022, 13, 170. https://doi.org/10.3390/info13040170
Imin G, Ablimit M, Yilahun H, Hamdulla A. A Character String-Based Stemming for Morphologically Derivative Languages. Information. 2022; 13(4):170. https://doi.org/10.3390/info13040170
Chicago/Turabian StyleImin, Gvzelnur, Mijit Ablimit, Hankiz Yilahun, and Askar Hamdulla. 2022. "A Character String-Based Stemming for Morphologically Derivative Languages" Information 13, no. 4: 170. https://doi.org/10.3390/info13040170