
An Attention-Based Multi-Representational Fusion Method for Social-Media-Based Text Classification

Abstract
:1. Introduction
2. Related Work
2.1. Social-Media-Based Text Classification
2.2. Deep Learning for Text Classification
2.3. Attention in the NLP Domain
2.4. Research Gap
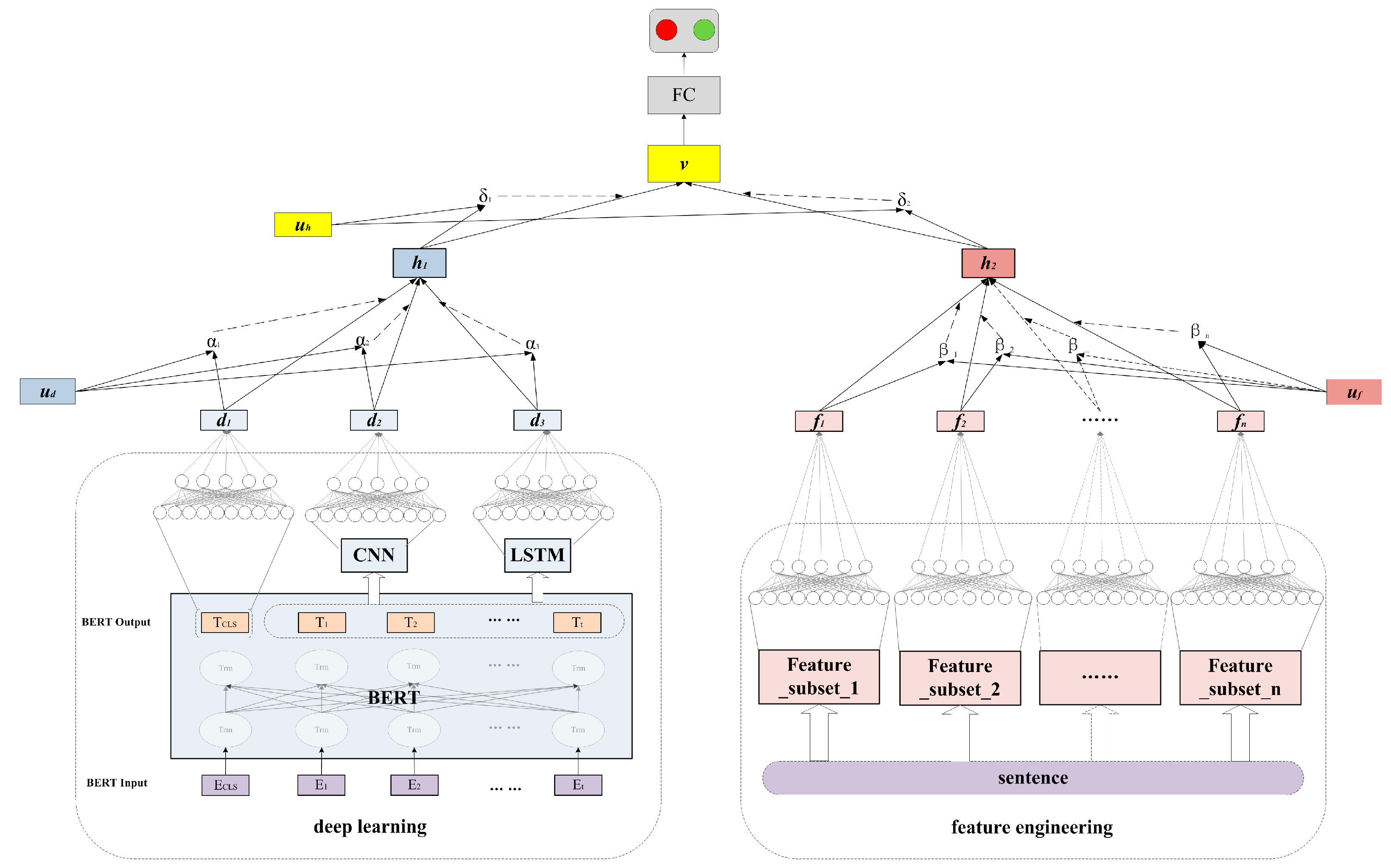
3. The Attention-Based Multirepresentational Fusion Method
3.1. Deep Neural Networks Explored in Our Method
3.1.1. BERT
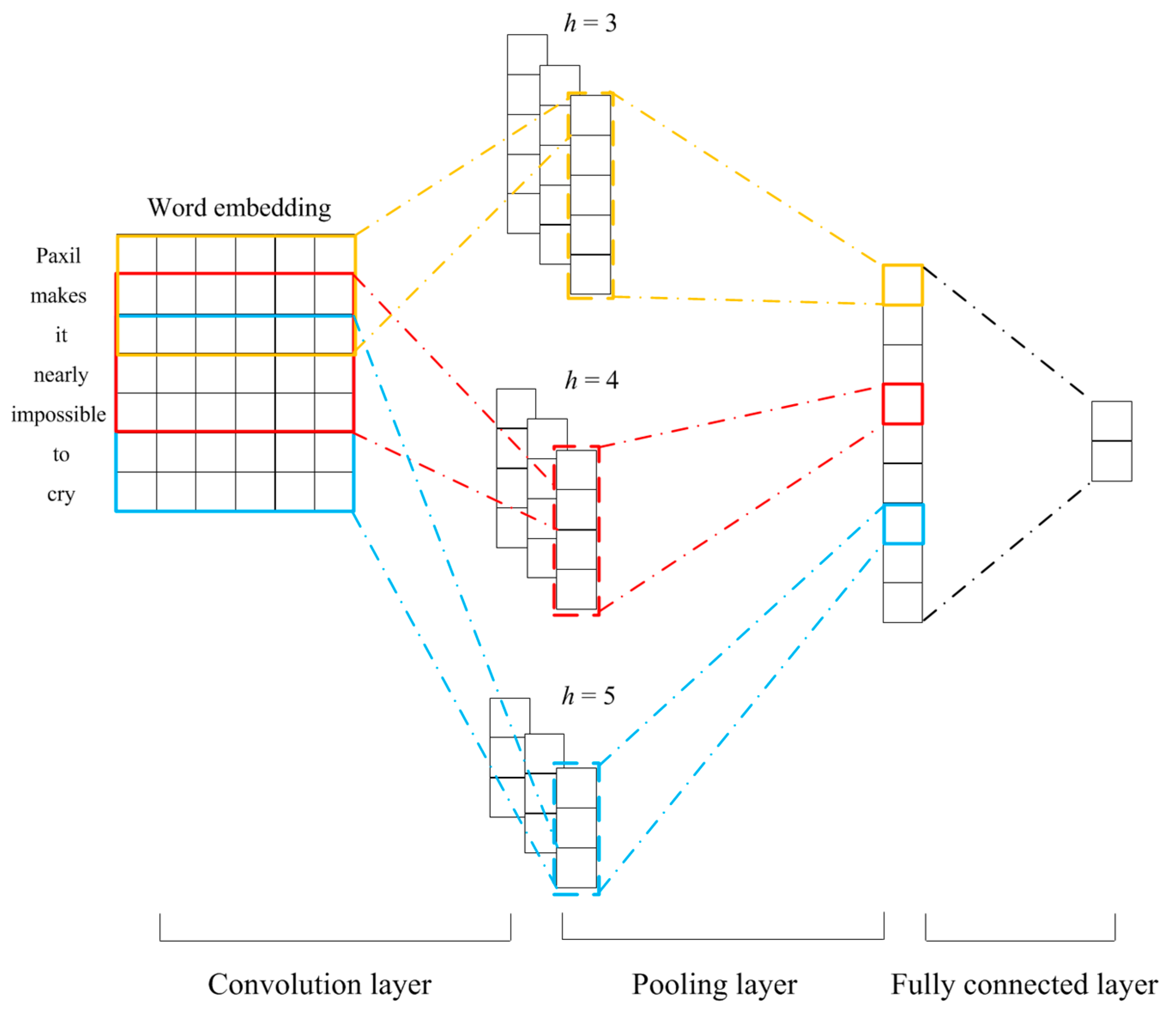
3.1.2. CNN
3.1.3. LSTM
3.1.4. Data-Driven Encoder with Attention Mechanism
3.2. Feature Engineering
3.3. Top-Level Representation Fusion with Attention Mechanism
3.4. Loss
4. Experimental Datasets and Settings
4.1. Experimental Datasets
4.1.1. Case Study 1: Identifying ADR-Relevant Tweets from Social Media (ADR)
4.1.2. Case Study 2: Identifying Comparative-Relevant Reviews from an E-Commerce Platform (CR)
4.2. Evaluation Metrics
4.3. Experimental Procedure
- 1.
- The traditional method refers to the existing state-of-the-art approach, which extracts rules with CSR (class sequence rule) as features and adopts SVM as the classification algorithm (i.e., CSR+SVM).
- 2.
- Individual deep-text representation by using BERT, CNN, and LSTM, respectively.
- 3.
- Different fusion strategies include model-level fusion, which combines different classifiers with majority voting, and feature-level fusion, which fuses multiple representations by simply concatenating all features.
5. Results and Discussion
6. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Ray, A.; Bala, P.K. User generated content for exploring factors affecting intention to use travel and food delivery services. Int. J. Hosp. Manag. 2021, 92, 102730. [Google Scholar] [CrossRef]
- Li, L.; Liu, X.; Zhang, X. Public attention and sentiment of recycled water: Evidence from social media text mining in China. J. Clean. Prod. 2021, 303, 126814. [Google Scholar] [CrossRef]
- Carta, S.M.; Consoli, S.; Piras, L.; Podda, A.S.; Recupero, D.R. Explainable machine learning exploiting news and domain-specific lexicon for stock market forecasting. IEEE Access 2021, 9, 30193–30205. [Google Scholar] [CrossRef]
- Dhelim, S.; Ning, H.; Aung, N. ComPath: User interest mining in heterogeneous signed social networks for Internet of people. IEEE Internet Things J. 2020, 8, 7024–7035. [Google Scholar] [CrossRef]
- Liu, J.; Wang, X.; Huang, L. Fusing Various Document Representations for Comparative Text Identification from Product Reviews. In Proceedings of the International Conference on Web Information Systems and Applications, Kaifeng, China, 24–26 September 2021; pp. 531–543. [Google Scholar]
- Bhattacharjee, S.D.; Tolone, W.J.; Paranjape, V.S. Identifying malicious social media contents using multi-view context-aware active learning. Future Gener. Comput. Syst. 2019, 100, 365–379. [Google Scholar] [CrossRef]
- Ligthart, A.; Catal, C.; Tekinerdogan, B. Analyzing the effectiveness of semi-supervised learning approaches for opinion spam classification. Appl. Soft Comput. 2021, 101, 107023. [Google Scholar] [CrossRef]
- Sarker, A.; Gonzalez, G. Portable automatic text classification for adverse drug reaction detection via multi-corpus training. J. Biomed. Inform. 2015, 53, 196–207. [Google Scholar] [CrossRef] [Green Version]
- Yang, M.; Kiang, M.; Shang, W. Filtering big data from social media–Building an early warning system for adverse drug reactions. J. Biomed. Inform. 2015, 54, 230–240. [Google Scholar] [CrossRef] [Green Version]
- Fatima, I.; Mukhtar, H.; Ahmad, H.F.; Rajpoot, K. Analysis of user-generated content from online social communities to characterise and predict depression degree. J. Inf. Sci. 2018, 44, 683–695. [Google Scholar] [CrossRef]
- Bing, C.; Wu, Y.; Dong, F.; Xu, S.; Liu, X.; Sun, S. Dual Co-Attention-Based Multi-Feature Fusion Method for Rumor Detection. Information 2022, 13, 25. [Google Scholar] [CrossRef]
- Zheng, X.; Sun, A. Collecting event-related tweets from twitter stream. J. Assoc. Inf. Sci. Technol. 2019, 70, 176–186. [Google Scholar] [CrossRef]
- Li, Q.; Peng, H.; Li, J.; Xia, C.; Yang, R.; Sun, L.; Yu, P.S.; He, L. A Survey on Text Classification: From Shallow to Deep Learning. arXiv 2020, arXiv:2008.00364. [Google Scholar]
- Minaee, S.; Kalchbrenner, N.; Cambria, E.; Nikzad, N.; Chenaghlu, M.; Gao, J. Deep learning--based text classification: A comprehensive review. ACM Comput. Surv. (CSUR) 2021, 54, 1–40. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv 2018, arXiv:1810.04805. [Google Scholar]
- Zhou, S.; Li, X. Feature engineering vs. deep learning for paper section identification: Toward applications in Chinese medical literature. Inf. Processing Manag. 2020, 57, 102206. [Google Scholar] [CrossRef]
- Xie, J.; Liu, X.; Zeng, D.D.; Fang, X. Understanding medication Nonadherence from Social Media: A sentiment-Enriched Deep Learning Approach. Available online: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=3091923 (accessed on 1 December 2021).
- Hochreiter, S.; Schmidhuber, J. Long Short-Term Memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Wu, P.; Li, X.; Ling, C.; Ding, S.; Shen, S. Sentiment classification using attention mechanism and bidirectional long short-term memory network. Appl. Soft Comput. 2021, 112, 107792. [Google Scholar] [CrossRef]
- Kim, Y. Convolutional Neural Networks for Sentence Classification. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; pp. 1746–1751. [Google Scholar]
- Zhang, X.; Zhao, J.; LeCun, Y. Character-level convolutional networks for text classification. Adv. Neural Inf. Process. Syst. 2015, 649–657. [Google Scholar]
- Vu, N.T.; Adel, H.; Gupta, P.; Schütze, H. Combining Recurrent and Convolutional Neural Networks for Relation Classification. In Proceedings of the NAACL 2016, San Diego, CA, USA, 12–17 June 2016. [Google Scholar]
- Yin, W.; Kann, K.; Yu, M.; Schütze, H. Comparative Study of CNN and RNN for Natural Language Processing. arXiv 2017, arXiv:1702.01923. [Google Scholar]
- Matthew, E.P.; Mark, N.; Mohit, I.; Matt, G.; Christopher, C.; Kenton, L.; Luke, Z. Deep contextualized word representations. arXiv 2018, arXiv:1802.05365. [Google Scholar]
- Radford, A.; Narasimhan, K.; Salimans, T.; Sutskever, I. Improving language understanding by generative pre-training. 2018. Available online: https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf (accessed on 3 March 2022).
- Sun, Y.; Wang, S.; Li, Y.; Feng, S.; Tian, H.; Wu, H.; Wang, H. Ernie 2.0: A continual pre-training framework for language understanding. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 8968–8975. [Google Scholar]
- Sun, Y.; Wang, S.; Li, Y.; Feng, S.; Chen, X.; Zhang, H.; Tian, X.; Zhu, D.; Tian, H.; Wu, H. Ernie: Enhanced representation through knowledge integration. arXiv 2019, arXiv:1904.09223. [Google Scholar]
- Gururangan, S.; Marasović, A.; Swayamdipta, S.; Lo, K.; Beltagy, I.; Downey, D.; Smith, N.A. Don′t stop pretraining: Adapt language models to domains and tasks. arXiv 2020, arXiv:2004.10964. [Google Scholar]
- Wang, J.; Yu, L.-C.; Lai, K.R.; Zhang, X. Dimensional sentiment analysis using a regional CNN-LSTM model. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics (Volume 2: Short Papers), Berlin, Germany, 7–12 August 2016; pp. 225–230. [Google Scholar]
- Liu, G.; Guo, J. Bidirectional LSTM with attention mechanism and convolutional layer for text classification. Neurocomputing 2019, 337, 325–338. [Google Scholar] [CrossRef]
- Chaudhari, S.; Mithal, V.; Polatkan, G.; Ramanath, R. An attentive survey of attention models. ACM Trans. Intell. Syst. Technol. (TIST) 2021, 12, 1–32. [Google Scholar] [CrossRef]
- Ahmad, Z.; Jindal, R.; Mukuntha, N.; Ekbal, A.; Bhattachharyya, P. Multi-modality helps in crisis management: An attention-based deep learning approach of leveraging text for image classification. Expert Syst. Appl. 2022, 195, 116626. [Google Scholar] [CrossRef]
- Bahdanau, D.; Cho, K.; Bengio, Y. Neural Machine Translation by Jointly Learning to Align and Translate. arXiv 2015, arXiv:1409.0473. [Google Scholar]
- Hermann, K.M.; Kocisky, T.; Grefenstette, E.; Espeholt, L.; Kay, W.; Suleyman, M.; Blunsom, P. Teaching machines to read and comprehend. Adv. Neural Inf. Process. Syst. 2015, 1693–1701. [Google Scholar]
- Yang, Z.; Yang, D.; Dyer, C.; He, X.; Hovy, E. Hierarchical Attention Networks for Document Classification. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016. [Google Scholar]
- Basiri, M.E.; Nemati, S.; Abdar, M.; Cambria, E.; Acharya, U.R. ABCDM: An attention-based bidirectional CNN-RNN deep model for sentiment analysis. Future Gener. Comput. Syst. 2021, 115, 279–294. [Google Scholar] [CrossRef]
- Kiela, D.; Wang, C.; Cho, K. Dynamic meta-embeddings for improved sentence representations. arXiv 2008, arXiv:1804.07983. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention Is All You Need. Adv. Neural Inf. Process. Syst. 2017, 6000–6010. [Google Scholar]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Pennington, J.; Socher, R.; Manning, C. Glove: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing, Doha, Qatar, 25–29 October 2014. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Actual | |||
|---|---|---|---|
| Positive | Negative | ||
| Prediction | Positive | True positive (TP) | False positive (FP) |
| Negative | False negative (FN) | True negative (TN) | |
| Feature Type | Feature | # Features 1 |
|---|---|---|
| Shallow linguistic features | N-grams with tf-idf | 10,000 |
| Domain knowledge-based features | Medical semantic features | 1150 |
| The ADR lexicon match-based features | 2 | |
| The negation features | 405 | |
| Other discriminative features | Synonym-expansion features | 3003 |
| Change-phrase features | 4 | |
| Sentiword-score features | 5 | |
| Topic-based features | 588 | |
| Total | 15,157 |
| Model | Precision (%) | Recall (%) | F1-Score | Acc (%) | |
|---|---|---|---|---|---|
| Individual deep-learning-based representation | BERT | 35.42 | 78.89 | 0.4879 | 83.06 |
| CNN | 35.93 | 78.34 | 0.4931 | 83.05 | |
| LSTM | 38.80 | 79.72 | 0.5191 | 84.79 | |
| The bottom-layer fusion | Data-driven | 45.47 | 67.22 | 0.5374 | 88.07 |
| Feature engineering | 33.43 | 63.47 | 0.4357 | 83.09 | |
| The top-layer fusion | Our method | 45.71 | 69.31 | 0.5476 | 88.20 |
| Model | CR_Phone | CR_Camera | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Precision (%) | Recall (%) | F1-Score | Acc (%) | Precision (%) | Recall (%) | F1-Score | Acc (%) | ||
| CSR+SVM | 50.18 | 83.35 | 0.6262 | 86.47 | 40.91 | 77.89 | 0.5088 | 87.22 | |
| Individual deep-learning-based representation | BERT | 67.55 | 92.08 | 0.7807 | 91.68 | 41.59 | 82.82 | 0.5534 | 85.38 |
| CNN | 68.06 | 92.05 | 0.7820 | 91.58 | 42.16 | 82.47 | 0.5561 | 85.36 | |
| LSTM | 66.43 | 92.93 | 0.7738 | 91.30 | 42.12 | 83.41 | 0.5575 | 85.01 | |
| Different fusion strategies | model-level | 68.76 | 92.60 | 0.7888 | 91.86 | 43.07 | 83.18 | 0.5660 | 86.00 |
| feature-level | 72.73 | 88.09 | 0.7923 | 92.36 | 44.68 | 79.65 | 0.5648 | 86.10 | |
| Our method | 87.02 | 77.31 | 0.8176 | 93.63 | 50.28 | 77.64 | 0.6085 | 88.95 | |
| Content | BERT | CNN | LSTM |
|---|---|---|---|
| Case study 1: Identifying ADR-relevant tweets | |||
| eqinnastra all the time take trazodone last night and it really help but it be difficult to wake up. | 0.5171 | 0.1699 | 0.3130 |
| just wonder why doctor prescribe dangerous addictive medication without any warning to patient paxil for instance. | 0.2445 | 0.2804 | 0.4751 |
| really bad rls from Seroquel. | 0.2427% | 0.3600 | 0.3973 |
| Case study 2: Identifying comparative-relevant reviews | |||
| 给我老爸用,感觉性价比很不错,相比之下845处理器比710和675还是s高些,总体满意. | 0.4468 | 0.4351 | 0.1181 |
| It’s a present for my father. It is, in my opinion, quite cost-effective. The 845 processor outperforms the 710 and 675 processors. In overall, I am satisfied. | |||
| 很赞,比现在的安卓系统快多了,不后悔,比我的vivo-x20强太多了,唯一比不上vivo的就是照相了,vivo的手机现在拍照超清. | 0.0947 | 0.4785 | 0.4268 |
| It’s fantastic. It’s noticeably quicker than the Android system. I have no regrets about purchasing. It is far superior to my vivo-x20. The only thing that cannot compare with vivo is photography. Vivo’s phones take crystal-clear photographs. | |||
| 非常流畅,在系统上一些细节感比安卓机要好很多. | 0.1769 | 0.5990 | 0.2241 |
| It runs without glitches. Some of the system’s details are far superior than those of Android. | |||
| Tweet | DL 1 | FE 2 |
| do trazodone actually make people feel like high omfg it make me sleepy | 0.5441 | 0.4559 |
| I think that Vyvanse is making me grind my teeth... | 0.5521 | 0.4479 |
| rocephin ciprofloxacin me barely able to stay awake | 0.5077 | 0.4923 |
| why do I not remember going to bed or waking up (the answer: probably seroquel) | 0.6457 | 0.3543 |
| I run on Vyvanse and RedBull.” So done with that life. Vyvance cooked my brain like a stove top | 0.6623 | 0.3377 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Liu, J.; Wang, X.; Tan, Y.; Huang, L.; Wang, Y. An Attention-Based Multi-Representational Fusion Method for Social-Media-Based Text Classification. Information 2022, 13, 171. https://doi.org/10.3390/info13040171
Liu J, Wang X, Tan Y, Huang L, Wang Y. An Attention-Based Multi-Representational Fusion Method for Social-Media-Based Text Classification. Information. 2022; 13(4):171. https://doi.org/10.3390/info13040171
Chicago/Turabian StyleLiu, Jing, Xiaoying Wang, Yan Tan, Lihua Huang, and Yue Wang. 2022. "An Attention-Based Multi-Representational Fusion Method for Social-Media-Based Text Classification" Information 13, no. 4: 171. https://doi.org/10.3390/info13040171