
Chinese-Uyghur Bilingual Lexicon Extraction Based on Weak Supervision


Abstract
:1. Introduction
2. Related Research
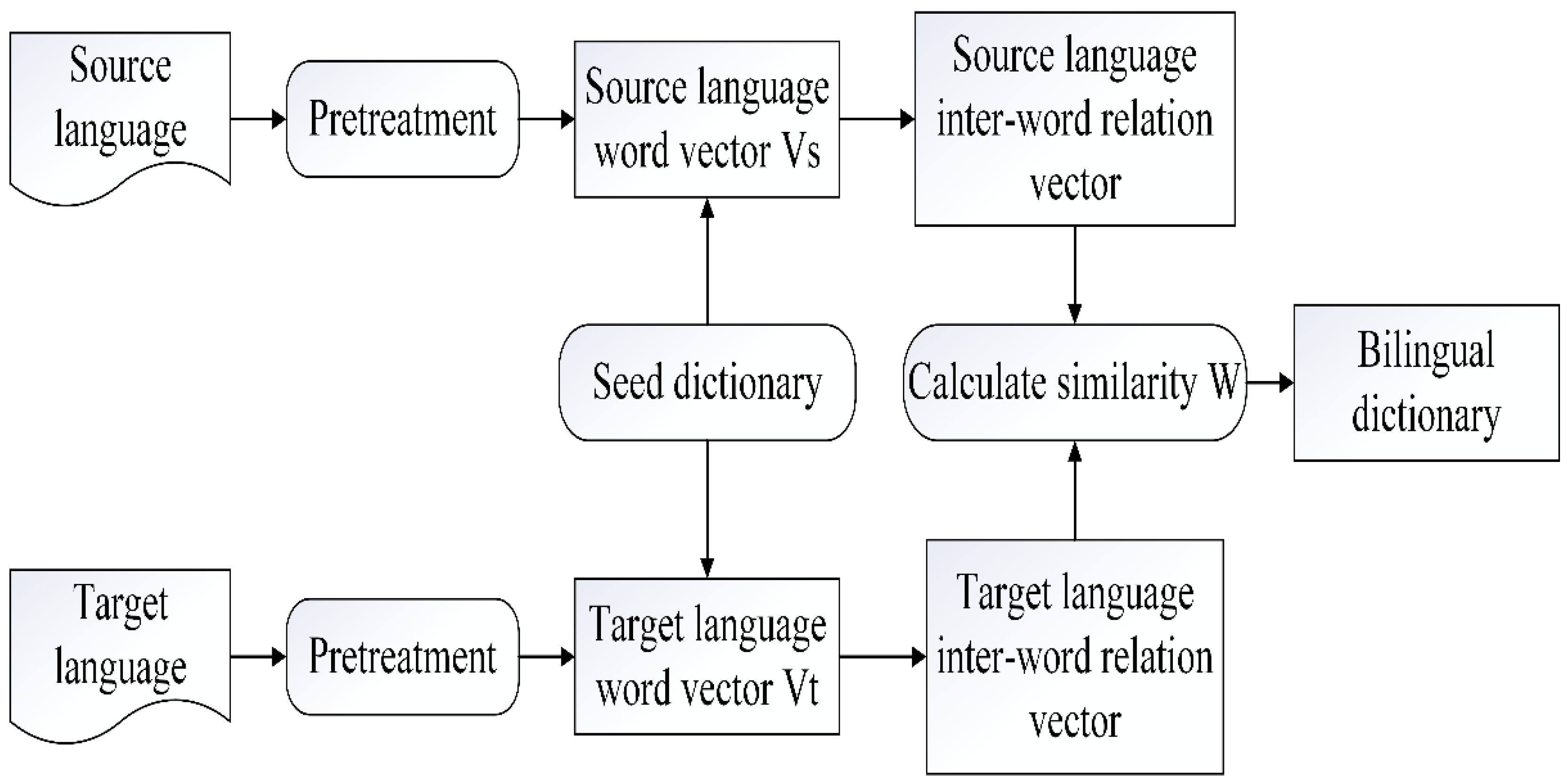
3. Bilingual Dictionary Construction Method Based on Cross-Language Word Vectors
3.1. Cross-Language Word Embedding Text Representation
3.2. Bilingual Dictionary Construction Method
- (1)
- The corpus of the source language and target language is preprocessed. The Chinese text needs to be segmented, and the Uyghur text does not need to be separated by spaces. The Chinese corpus sentences are processed by the Jieba word segmentation tool. Finally, the preprocessed Chinese and Uyghur sentences are obtained, and the word frequency and the number of words are counted, where n is the number of words in the source language, m is the number of words in the target language, {xi|i = 1, 2, …, n} is the source language’s word set, and {yj|j = 1, 2, …, m} is the target language’s word set.
- (2)
- The word vector embedding of all corpora is trained through the Skip-gram model based on a hierarchical softmax algorithm, and the words of Chinese and Uyghur are expressed as word vectors. The word vector dimension is expressed as d, and the word vector corresponding to the source language words is expressed as {vx1, vx2, vx3, …, vxi}, where vxi ∈ Rd, i ∈ {1, 2, …, n}. Similarly, the word vector corresponding to the target language words can be expressed as {vy1, vy2, vy3, …, vyi}, where vyi ∈ Rd, i ∈ {1, 2, …, m}.
- (3)
- The method based on a seed dictionary is used to learn the Chinese dimensional mapping matrix, Wxz. The premise for the construction method of a bilingual dictionary based on a seed dictionary needs a small-scale bilingual seed dictionary of the source language and the target language. The seed lexicons of mutual translation are extracted from the bilingual text, and the mapping relationship between the word vectors of the two languages is learned through the seed dictionary. If the number of seed word pairs is n, the formed seed set is expressed as {wsi, wti}, where ws is the source language word, wt is the corresponding translation of ws in the target language, and i is the index of ws in the seed dictionary.
- (4)
- In the cross-language word vector extraction of Chinese-Uyghur bilingual dictionaries, two methods of dictionary extraction will be introduced, i.e., the nearest neighbor method and CSLS method. After the word vectors of the source language and the target language are mapped to the same space through the orthogonal matrix W, the source language word vector corresponding to the target language word vector in the same vector space will be found according to the nearest neighbor search. Compute the cosine similarity between WX and Z. The greater the cosine value, the more correct the target language translation corresponding to the source language. The calculation is shown by Equation (4). However, this method may have a hub point (hubness) problem in a high-dimensional space [33]. Some points will become the nearest neighbors of most points, so the nearest neighbor search cannot accurately find the words closest to the semantics of each word. The CSLS method penalizes the similarity score of such pivot points. For two-word vectors x and z mapped to the same space, calculate the CSLS score between them as the final similarity score between the two words, as shown by Equation (7):
4. Experiments
4.1. Experimental Corpus
4.2. Evaluation Indicators
4.3. Experiment Settings
4.4. Experimental Results and Analysis
4.4.1. The Influence of Different Cross-Language Word Embedding Vector Mapping Dimensions
4.4.2. The Influence of the Number of Candidate Words
4.4.3. The Influence of the Context Window Size W
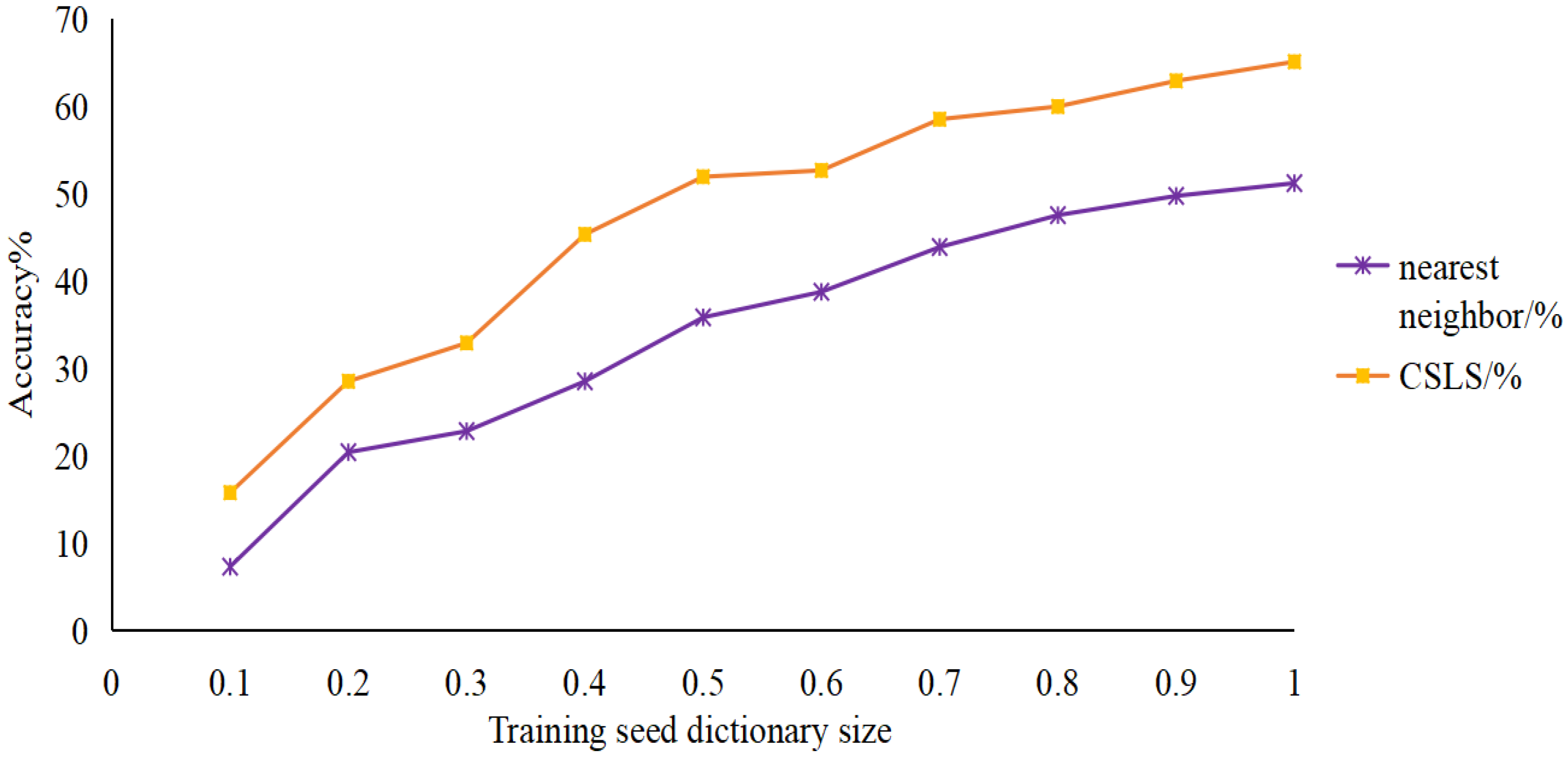
4.4.4. The Influence of the Size of the Training Seed Dictionary
4.4.5. The Effect of Word Frequency
4.4.6. Comparison of Our Method with Other Methods for Building Bilingual Dictionaries
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Ballesteros, L.A. Cross-language retrieval via transitive translation. In Advances in Information Retrieval; Springer: Cham, Switzerland, 2002; pp. 203–234. [Google Scholar]
- Zou, W.Y.; Socher, R.; Cer, D.; Manning, C.D. Bilingual word embeddings for phrase-based machine translation. In Proceedings of the 2013 Conference on Empirical Methods in Natural Language Processing, Seattle, WA, USA, 18–21 October 2013; pp. 1393–1398. [Google Scholar]
- Klementiev, A.; Titov, I.; Bhattarai, B. Inducing crosslingual distributed representations of words. In Proceedings of the COLING 2012, Mumbai, India, 8–15 December 2012; pp. 1459–1474. [Google Scholar]
- Zhang, M.; Liu, Y.; Luan, H.; Sun, M. Adversarial training for unsupervised bilingual lexicon induction. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vancouver, BC, Canada, 30 July–4 August 2017; pp. 1959–1970. [Google Scholar]
- Lauly, S.; Larochelle, H.; Khapra, M.M.; Ravindran, B.; Raykar, V.; Saha, A. An autoencoder approach to learning bilingual word representations. arXiv 2014, arXiv:1402.1454. [Google Scholar]
- Nassirudin, M.; Purwarianti, A. Indonesian-Japanese term extraction from bilingual corpora using machine learning. In Proceedings of the 2015 International Conference on Advanced Computer Science and Information Systems (ICACSIS), Depok, Indonesia, 10–11 October 2015; pp. 111–116. [Google Scholar]
- Liang, J.; Jiang, M.-J.; Wu, F.-S.; Deng, X. Neural Network Technology Application and Progress for the Field of Medicine. J. Liaoning Univ. Tradit. Chin. Med. 2011, 34, 89–93. [Google Scholar]
- Ruder, S.; Vulić, I.; Søgaard, A. A survey of cross-lingual word embedding models. J. Artif. Intell. Res. 2019, 65, 569–631. [Google Scholar] [CrossRef] [Green Version]
- Rapp, R. Automatic identification of word translations from unrelated English and German corpora. In Proceedings of the 37th Annual Meeting of the Association for Computational Linguistics, College Park, MD, USA, 20–26 June 1999; pp. 519–526. [Google Scholar]
- Sun, L.; Jin, Y.; Du, L.; Sun, Y. Automatic extraction of bilingual term lexicon from parallel corpora. J. Chin. Inf. Process. 2000, 14, 33–39. [Google Scholar]
- Mo, Y.; Guo, J.; Mao, C.; Yu, Z.; Niu, Y. A bilingual word alignment method of Vietnamese-Chinese based on deep neutral network. J. Shandong Univ. Nat. Sci. 2016, 51, 78–82. [Google Scholar]
- Luong, M.-T.; Pham, H.; Manning, C.D. Bilingual word representations with monolingual quality in mind. In Proceedings of the 1st Workshop on Vector Space Modeling for Natural Language Processing, Denver, CO, USA, 31 May–5 June 2015; pp. 151–159. [Google Scholar]
- Morin, E.; Prochasson, E. Bilingual lexicon extraction from comparable corpora enhanced with parallel corpora. In Proceedings of the 4th Workshop on Building and Using Comparable Corpora: Comparable Corpora and the Web, Portland, OR, USA, 24 June 2011; pp. 27–34. [Google Scholar]
- Gouws, S.; Søgaard, A. Simple task-specific bilingual word embeddings. In Proceedings of the 2015 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Denver, CO, USA, 31 May–5 June 2015; pp. 1386–1390. [Google Scholar]
- Mikolov, T.; Le, Q.V.; Sutskever, I. Exploiting similarities among languages for machine translation. arXiv 2013, arXiv:1309.4168. [Google Scholar]
- Mikolov, T.; Sutskever, I.; Chen, K.; Corrado, G.S.; Dean, J. Distributed representations of words and phrases and their compositionality. Adv. Neural Inf. Process. Syst. 2013, 26, 3111–3119. [Google Scholar]
- Wick, M.; Kanani, P.; Pocock, A. Minimally-constrained multilingual embeddings via artificial code-switching. In Proceedings of the AAAI Conference on Artificial Intelligence, Phoenix, AZ, USA, 12–17 February 2016; Volume 30. [Google Scholar]
- Conneau, A.; Lample, G.; Ranzato, M.A.; Denoyer, L.; Jégou, H. Word translation without parallel data. arXiv 2017, arXiv:1710.04087. [Google Scholar]
- Barone, A.V.M. Towards cross-lingual distributed representations without parallel text trained with adversarial autoencoders. arXiv 2016, arXiv:1608.02996. [Google Scholar]
- Cao, H.; Zhao, T.; Zhang, S.; Meng, Y. A distribution-based model to learn bilingual word embeddings. In Proceedings of the COLING 2016, the 26th International Conference on Computational Linguistics: Technical Papers, Osaka, Japan, 11–17 December 2016; pp. 1818–1827. [Google Scholar]
- Yu, Q.; Chang, L.; Xu, J.; Liu, T.Y. Research on bilingual term extraction based on Chinese Uygur medical parallel corpus. J. Inn. Mong. Univ. 2018, 49, 528–533. [Google Scholar]
- Silva, V.S.; Freitas, A.; Handschuh, S. Xte: Explainable text entailment. arXiv 2020, arXiv:2009.12431. [Google Scholar]
- Bengio, Y.; Ducharme, R.; Vincent, P.; Jauvin, C. A neural probabilistic language model. J. Mach. Learn. Res. 2003, 3, 1137–1155. [Google Scholar]
- Mnih, A.; Hinton, G. Three new graphical models for statistical language modelling. In Proceedings of the 24th International Conference on Machine learning, Corvallis, OR, USA, 20–24 June 2007; pp. 641–648. [Google Scholar]
- Lai, S.; Xu, L.; Liu, K.; Zhao, J. Recurrent convolutional neural networks for text classification. In Proceedings of the Twenty-ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015. [Google Scholar]
- Goldberg, Y.; Levy, O. word2vec Explained: Deriving Mikolov et al.’s negative-sampling word-embedding method. arXiv 2014, arXiv:1402.3722. [Google Scholar]
- Chen, Y.Q.; Nixon, M.S.; Damper, R.I. Implementing the k-nearest neighbour rule via a neural network. In Proceedings of the ICNN’95-International Conference on Neural Networks, Perth, WA, Australia, 27 November–1 December 1995; pp. 136–140. [Google Scholar]
- Levy, O.; Goldberg, Y.; Dagan, I. Improving distributional similarity with lessons learned from word embeddings. Trans. Assoc. Comput. Linguist. 2015, 3, 211–225. [Google Scholar] [CrossRef]
- Alipour, G.; Bagherzadeh Mohasefi, J.; Feizi-Derakhshi, M.-R. Learning Bilingual Word Embedding Mappings with Similar Words in Related Languages Using GAN. Appl. Artif. Intell. 2022, 10, 1–20. [Google Scholar] [CrossRef]
- Hossny, A.H.; Mitchell, L.; Lothian, N.; Osborne, G. Feature selection methods for event detection in Twitter: A text mining approach. Soc. Netw. Anal. Min. 2020, 10, 61. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013, arXiv:1301.3781. [Google Scholar]
- Artetxe, M.; Labaka, G.; Agirre, E. Bilingual lexicon induction through unsupervised machine translation. arXiv 2019, arXiv:1907.10761. [Google Scholar]
- Shigeto, Y.; Suzuki, I.; Hara, K.; Shimbo, M.; Matsumoto, Y. Ridge regression, hubness, and zero-shot learning. In Proceedings of the Joint European Conference on Machine Learning and Knowledge Discovery in Databases, Porto, Portugal, 7–11 September 2015; pp. 135–151. [Google Scholar]
- Joulin, A.; Bojanowski, P.; Mikolov, T.; Jégou, H.; Grave, E. Loss in translation: Learning bilingual word mapping with a retrieval criterion. arXiv 2018, arXiv:1804.07745. [Google Scholar]
- Zhang, M.; Xu, K.; Kawarabayashi, K.-I.; Jegelka, S.; Boyd-Graber, J. Are Girls Neko or Sh\= ojo? Cross-Lingual Alignment of Non-Isomorphic Embeddings with Iterative Normalization. arXiv 2019, arXiv:1906.01622. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Chinese 地球 (Earth) Related Vocabulary | Uyghur ھايۋان (Animal) Related Vocabulary | ||
|---|---|---|---|
| Related Words | Cosine Distance | Related Words | Cosine Distance |
| 月球 (Moon) | 0.8317 | دىنازاۋۇر (Dinosaur) | 0.8912 |
| 行星 (Planet) | 0.8098 | قۇش (Bird) | 0.8768 |
| 水星 (Mercury) | 0.7975 | بېلىق (Fish) | 0.8519 |
| 陆地 (Land) | 0.7653 | ئۆسۈملۈك (Botany) | 0.8348 |
| 太阳 (Sun) | 0.7571 | پىل (Elephant) | 0.8301 |
| Language Type | Chinese | Uyghur |
|---|---|---|
| parallel documents | 4000 | 4000 |
| Sentences | 55,457 | 58,124 |
| Vocabulary | 59,482 | 85,815 |
| Chinese | Uyghur | Chinese | Uyghur |
|---|---|---|---|
| 矩阵 (matrix) | ماترىتسا | 讲台 (platform) | سەھنە |
| 数学家 (mathematician) | ماتېماتىك | 尖锐 (sharp) | ئۆتكۈر |
| 空气 (air) | ھاۋا | 淋巴 (lymph) | لىمفا |
| 复习 (review) | تەكرار | 淀粉 (starch) | كراخمال |
| 先天性 (congenital) | تۇغما | 放大器 (amplifier) | كۈچەيتكۈچ |
| 芬兰 (Finland) | فىنلاندىيە | 流通 (circulation) | ئوبوروت |
| 好吃 (delicious) | يېيىشلىك | 行政 (administration) | مەمۇرىي |
| 药片 (tablet) | تابلېتكا | 做法 (practice) | ئۇسۇل |
| 合作者 (collaborator) | ھەمكارلاشقۇچى | 指导员 (instructor) | يېتەكچى |
| 流畅 (fluent) | راۋان | 衣服 (clothes) | كىيىم |
| Vector Dimension | Extraction Method | |
|---|---|---|
| Nearest Neighbor/% | CSLS/% | |
| 100 | 25.78 | 28.64 |
| 200 | 27.38 | 31.72 |
| 300 | 31.45 | 36.97 |
| 400 | 30.92 | 33.18 |
| 500 | 27.71 | 29.15 |
| Extraction Method | Candidate Words N | ||
|---|---|---|---|
| P@1 | P@5 | P@10 | |
| nearest neighbor/% | 31.45 | 43.55 | 51.17 |
| CSLS/% | 36.97 | 47.27 | 65.06 |
| Correctly Extracted Bilingual Dictionary | Incorrectly Extracted Bilingual Vocabulary | ||||
|---|---|---|---|---|---|
| Source Word | Target Words | Reference Target Word | Source Word | Target Words | Reference Target Word |
| 古代 | قەدىمكى | قەدىمكى | 山坡 | ئېگىز | قىيالىق |
| 敏感 | سەزگۈر | سەزگۈر | 包装 | تاۋار | ئورام |
| 高兴 | خۇشاللىق | خۇشاللىق | 空气 | ھاۋادىن | ھاۋا |
| 感染 | يۇقۇملىنىش | يۇقۇملىنىش | 生物 | جانلىقلار | جانلىق |
| 地质学家 | گېئولوگ | گېئولوگ | 方法 | تەدبىر | ئۇسۇل |
| Correctly Extracted Bilingual Dictionary | Incorrectly Extracted Bilingual Vocabulary | ||||
|---|---|---|---|---|---|
| Source Word | Target Words | Reference Target Word | Source Word | Target Words | Reference Target Word |
| 乐观 | كەيپىياتى ئۈمىدۋار ئۆگىنىش ئۆگىنىشكە بالىلارنى | ئۈمىدۋار | 态度 | خۇلق پىسخولوگلار ئەمەلىيەتچانلىق پوزىتسىيەسى ئەمەلىيەتتىن | پوزىتسىيە |
| 单位 | بىرلىك بىرلىكى بىرلىكىنى نىسبەتلا بىرلىكتىن | بىرلىك | 空白 | رېئاللىقتا كۆرۈنۈشنى ئۇنتۇلغۇسىز رېئاللىق تۇيغۇدا | بوشلۇق |
| 山坡 | ئېگىز تاغدىكى قىيالىق تۇپرىقى قۇملۇق | قىيالىق | 鸟儿 | قۇشقاچ شىر يىرتقۇچ شۈيخۇا ئۆردەك | قۇش |
| 农耕 | تېرىقچىلىق مۇداپىئەسى ئەمەلىيىتى شۇغۇللىنىش كەسىپلەر | تېرىقچىلىق | 尖锐 | تىرناقلىرى قوللىرىغا قۇشلارغا جاغ تاجىسى | ئۆتكۈر |
| 司机 | يېنىڭىزدىن شوپۇر بولسىڭىز ئولتۇرۇش تاكسىغا | شوپۇر | 器官 | يېتىلمىگەن ھۈجەيرىلىرىنىڭ ئەزالىرىنىڭ ھۈجەيرىلىرى نېرۋا | ئەزالارى |
| Correctly Extracted Bilingual Dictionary | Incorrectly Extracted Bilingual Vocabulary | ||||
|---|---|---|---|---|---|
| Source Word | Target Words | Reference Target Word | Source Word | Target Words | Reference Target Word |
| 态度 | پوزىتسىيە پىسخولوگلار ئەمەلىيەتچانلىق پوزىتسىيەسى ئەمەلىيەتتىن قابىلىيەت كەيپىياتى پوزىتسىيە يېزىقچىلىق ئۆگىنىشىگە | پوزىتسىيە | 人类 | ئىنسانلار ئىنسانلارنىڭ تەرەققىياتنى تەرەققىياتىدىكى جەمئىيەت مۇساپىسىدە ئىزدىنىشى مەدەنىيىتىنىڭ تەرەققىياتى يارىتىشى | ئىنسان |
| 尖锐 | تىرناقلىرى قوللىرىغا قۇشلارغا جاغ تاجىسى بۈرگىنىڭ ئەگمە ئەگمىسى ئۆتكۈر تىرنىقى | ئۆتكۈر | 米饭 | شامنىڭ توڭلاتقۇدىن سېتىۋالغاندىن دۇخوپكا ئائىلىلەردە توڭلاتقۇ ئىسسىتقىلى ساقلىغىلى قازاندىكى سۇنىلا | كۈچ |
| 巧克力 | ئارىلاشتۇرۇپ شاكىلات پاراشوكى سېرىقمايدىن ئىچىملىك بولكا ماروژنى سوپۇننىڭ پاختا شاكىلاتنىڭ | شاكىلات | 老虎 | تۈلكە شىر يىرتقۇچ قۇش تۆگىقۇش بۈركۈت قۇشلار جىگدىچى چۈمۈلىخور بۈركۈتنى | يولۋاس |
| 渔民 | بېلىقچىلار ئېلىمىز تاشپاقىسى ئىزدىشى بورانقۇش بېلىق قۇشى جەلپ دېڭىزدا دېلفىنى | بېلىقچىلار | 墨鱼 | ئويستېر بېلىقلاردۇر سەكسەنپۇت بېلىقلارمۇ پالانچە بۈركۈتنى ئۈزمىگەچكە قىسقۇچپاقا تالمۇ ئانىسىغا | سىياھبېلىق |
| 工业 | ئېتانولنى سانائەتنىڭ ئىشلەپچىقىرىشىدا سانائەت سانائىتىدە كەسپىن تۇغۇندىسى مەھسۇلاتلىرىنىڭ تەرەققىيات سانائىتىنىڭ | سانائەت | 波士顿 | كولۇمبىيە فاكۇلتېتى 309 زۇڭتۇڭى مۇھەررىرى فېدراتسىيە گىرېس ئىمزالاپ كونۋېي داۋىس | بوستون |
| Word Frequency | Extraction Method | |
|---|---|---|
| Nearest Neighbor/% | CSLS/% | |
| Low frequency | 16.23 | 21.89 |
| Intermediate frequency | 23.21 | 34.89 |
| High frequency | 34.43 | 57.38 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Aysa, A.; Ablimit, M.; Yilahun, H.; Hamdulla, A. Chinese-Uyghur Bilingual Lexicon Extraction Based on Weak Supervision. Information 2022, 13, 175. https://doi.org/10.3390/info13040175
Aysa A, Ablimit M, Yilahun H, Hamdulla A. Chinese-Uyghur Bilingual Lexicon Extraction Based on Weak Supervision. Information. 2022; 13(4):175. https://doi.org/10.3390/info13040175
Chicago/Turabian StyleAysa, Anwar, Mijit Ablimit, Hankiz Yilahun, and Askar Hamdulla. 2022. "Chinese-Uyghur Bilingual Lexicon Extraction Based on Weak Supervision" Information 13, no. 4: 175. https://doi.org/10.3390/info13040175