
Two New Datasets for Italian-Language Abstractive Text Summarization




Abstract
:1. Introduction
2. Related Work
2.1. Models
2.2. Datasets Used
3. Models and Metrics
4. Proposed Datasets
4.1. IlPost
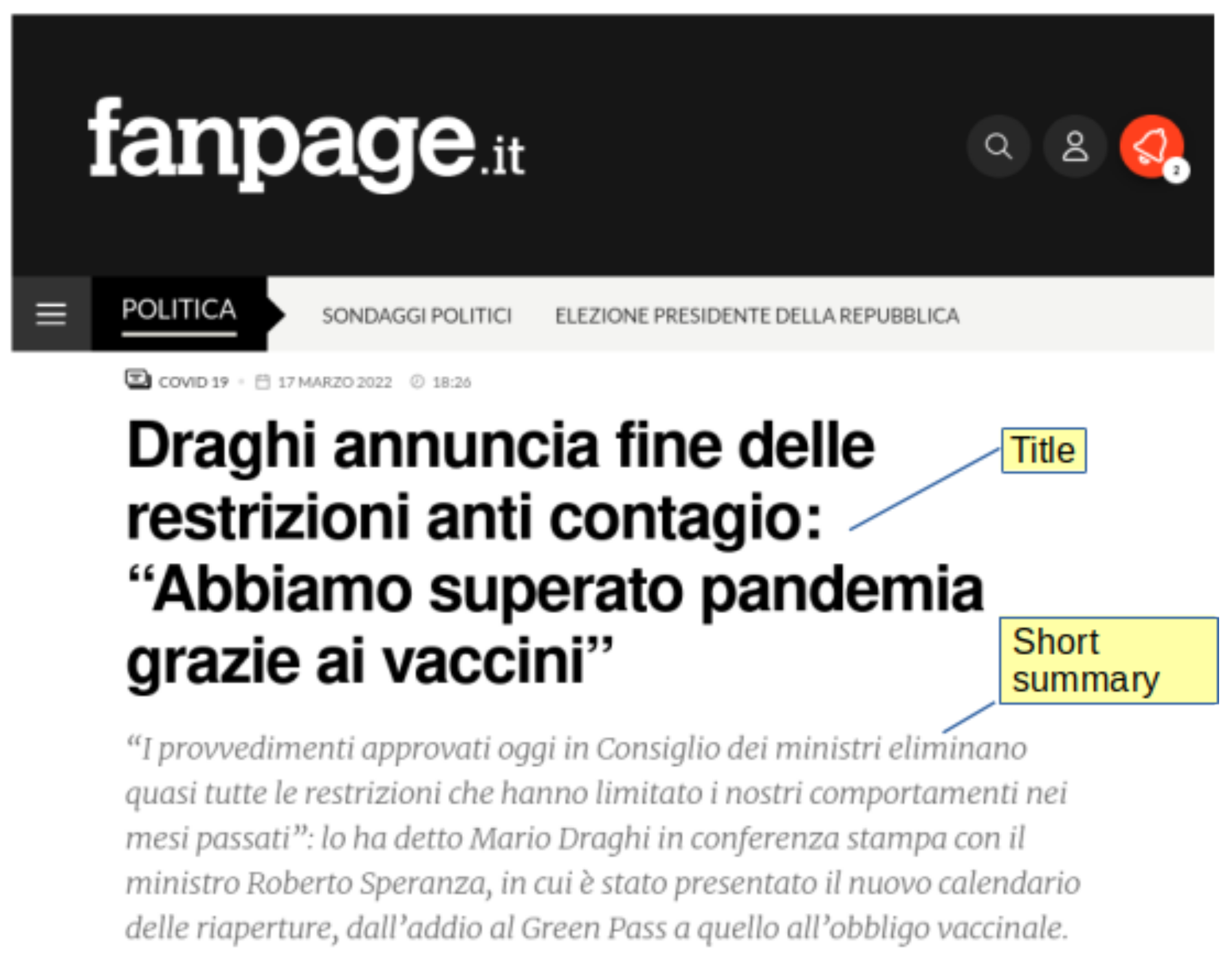
4.2. Fanpage
4.3. MLSum-It
5. Experiments
- Is it better to translate the dataset to the target language or to the input/output for the pre-trained model trained with a different target language?
- Is it better to train a “simple” model on a dataset created in the original target language, or is it better to use a SOTA model trained with a different target language, and then automatically translate the input/output for it?
- Is it worth creating a dataset in the target language, or is it better to automatically translate a dataset from a different language into the target language?
Human Evaluation
“Mary Katherine, una giovane ragazza alle prese con il mondo sconosciuto della flora che ci circonda, si risveglia un giorno e scopre di non essere più a casa sua, ma di essere stata trasportata in un altro universo. un viaggio epico, con un cast di doppiatori originali da brivido.”
“Chris Wedge, regista de “L’Era Glaciale” e “Rio”, porta nelle sale una fantastica storia ambientata nel mondo, a noi ignoto, dei piccoli esseri che vivono nella natura circostante. Sensazionale.”
“José Ortega Cano, dopo un mese e mezzo ricoverato nell’ospedale Vergine Macarena di Siviglia dopo aver subito un grave incidente stradale (nel quale è morto Carlos Parra, l’autista dell’altro veicolo coinvolto nel sinistro) ha lasciato ieri mattina il centro ospedaliero dove ha dedicato alcune parole ai numerosi mezzi di comunicazione nazionale.”
“L’ospedale di Siviglia dove è morto il defunto. José Ortega Cano è in ospedale da un mese e mezzo, dopo un incidente stradale in cui è morto Carlos Parra.”
“Ll Pentagono ha appena annunciato che sta testando un sofisticatissima IA che ha l’obiettivo di prevedere con “giorni di anticipo” eventi di grande rilevanza nazionale e internazionale, analizzando dati da molteplici fonti.”
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Khan, A. A Review on Abstractive Summarization Methods. J. Theor. Appl. Inf. Technol. 2014, 59, 64–72. [Google Scholar]
- Wong, K.F.; Wu, M.; Li, W. Extractive Summarization Using Supervised and Semi-Supervised Learning. In Proceedings of the 22nd International Conference on Computational Linguistics (Coling 2008), Manchester, UK, 18–22 August 2008; Coling 2008 Organizing Committee: Manchester, UK, 2008; pp. 985–992. [Google Scholar]
- Narayan, S.; Cohen, S.; Lapata, M. Don’t Give Me the Details, Just the Summary! Topic-Aware Convolutional Neural Networks for Extreme Summarization. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 1797–1807. [Google Scholar]
- Nallapati, R.; Zhou, B.; dos Santos, C.; Gulçehre, Ç.; Xiang, B. Abstractive Text Summarization using Sequence-to-sequence RNNs and Beyond. In Proceedings of the 20th SIGNLL Conference on Computational Natural Language Learning, Berlin, Germany, 11–12 August 2016; pp. 280–290. [Google Scholar]
- Shi, T.; Keneshloo, Y.; Ramakrishnan, N.; Reddy, C.K. Neural abstractive text summarization with sequence-to-sequence models. ACM Trans. Data Sci. 2021, 2, 1–37. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; pp. 5998–6008. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
- Rasley, J.; Rajbhandari, S.; Ruwase, O.; He, Y. Deepspeed: System optimizations enable training deep learning models with over 100 billion parameters. In Proceedings of the Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining; Virtual Event, 6–10 July 2020, pp. 3505–3506.
- Dale, R. GPT-3: What’s it good for? Nat. Lang. Eng. 2021, 27, 113–118. [Google Scholar] [CrossRef]
- Smith, S.; Patwary, M.; Norick, B.; LeGresley, P.; Rajbhandari, S.; Casper, J.; Liu, Z.; Prabhumoye, S.; Zerveas, G.; Korthikanti, V.; et al. Using deepspeed and megatron to train megatron-turing nlg 530b, a large-scale generative language model. arXiv 2022, arXiv:2201.11990. [Google Scholar]
- Sarti, G.; Nissim, M. IT5: Large-scale Text-to-text Pretraining for Italian Language Understanding and Generation. arXiv 2022, arXiv:2203.03759. [Google Scholar]
- Xue, L.; Constant, N.; Roberts, A.; Kale, M.; Al-Rfou, R.; Siddhant, A.; Barua, A.; Raffel, C. mT5: A Massively Multilingual Pre-trained Text-to-Text Transformer. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Virtual Event, 6–11 June 2021; pp. 483–498. [Google Scholar]
- Liu, Y.; Gu, J.; Goyal, N.; Li, X.; Edunov, S.; Ghazvininejad, M.; Lewis, M.; Zettlemoyer, L. Multilingual denoising pre-training for neural machine translation. Trans. Assoc. Comput. Linguist. 2020, 8, 726–742. [Google Scholar] [CrossRef]
- Mihalcea, R.; Tarau, P. TextRank: Bringing Order into Text. In Proceedings of the 2004 Conference on Empirical Methods in Natural Language Processing, Barcelona, Spain, 25–26 July 2004; pp. 404–411. [Google Scholar]
- Elbarougy, R.; Behery, G.; El Khatib, A. Extractive Arabic text summarization using modified PageRank algorithm. Egypt. Informatics J. 2020, 21, 73–81. [Google Scholar] [CrossRef]
- Zhang, J.; Zhao, Y.; Saleh, M.; Liu, P. Pegasus: Pre-training with extracted gap-sentences for abstractive summarization. In Proceedings of the International Conference on Machine Learning, PMLR, Virtual Event, 13–18 July 2020; pp. 11328–11339. [Google Scholar]
- Qi, W.; Yan, Y.; Gong, Y.; Liu, D.; Duan, N.; Chen, J.; Zhang, R.; Zhou, M. ProphetNet: Predicting Future N-gram for Sequence-to-Sequence Pre-training. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: Findings, Online, 16–20 November 2020; pp. 2401–2410. [Google Scholar]
- Petroni, F.; Piktus, A.; Fan, A.; Lewis, P.; Yazdani, M.; Cao, N.; Thorne, J.; Jernite, Y.; Karpukhin, V.; Maillard, J.; et al. KILT: A Benchmark for Knowledge Intensive Language Tasks. In Proceedings of the NAACL-HLT. Association for Computational Linguistics, Online, 6–11 June 2021; pp. 2523–2544. [Google Scholar]
- Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; Zettlemoyer, L. BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics; Online, 5–10 July 2020, pp. 7871–7880.
- Tiedemann, J. The Tatoeba Translation Challenge—Realistic Data Sets for Low Resource and Multilingual MT. In Proceedings of the Fifth Conference on Machine Translation, Online, 19–20 November 2020; pp. 1174–1182. [Google Scholar]
- Scialom, T.; Dray, P.A.; Lamprier, S.; Piwowarski, B.; Staiano, J. MLSUM: The Multilingual Summarization Corpus. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 16–20 November 2020; pp. 8051–8067. [Google Scholar]
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Transformers: State-of-the-Art Natural Language Processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, Online, 16–20 November 2020; pp. 38–45. [Google Scholar]
- Lin, C.Y. ROUGE: A Package for Automatic Evaluation of Summaries. In Proceedings of the Text Summarization Branches Out, Barcelona, Spain, 26 July 2004; pp. 74–81. [Google Scholar]
- Landro, N.; Gallo, I.; Federici, E. Source code to Create Dataset and Train. 2021. Available online: https://gitlab.com/nicolalandro/summarization (accessed on 28 April 2022).
- Landro, N.; Gallo, I.; Federici, E. It5 Ilpost Trained Model. 2021. Available online: https://huggingface.co/ARTeLab/it5-summarization-ilpost (accessed on 22 October 2021).
- Landro, N.; Gallo, I.; Federici, E. It5 Mlsum Trained Model. 2021. Available online: https://huggingface.co/ARTeLab/it5-summarization-mlsum (accessed on 22 October 2021).
- Landro, N.; Gallo, I.; Federici, E. It5 Fanpage Trained Model. 2021. Available online: https://huggingface.co/ARTeLab/it5-summarization-fanpage (accessed on 22 October 2021).
- Landro, N.; Gallo, I.; Federici, E. Mbart Ilpost Trained Model. 2021. Available online: https://huggingface.co/ARTeLab/mbart-summarization-mlsum (accessed on 22 October 2021).
- Landro, N.; Gallo, I.; Federici, E. Mbart Mlsum Trained Model. 2021. Available online: https://huggingface.co/ARTeLab/mbart-summarization-ilpost (accessed on 22 October 2021).
- Landro, N.; Gallo, I.; Federici, E. Mbart Fanpage Trained Model. 2021. Available online: https://huggingface.co/ARTeLab/mbart-summarization-fanpage (accessed on 22 October 2021).
- Hermann, K.M.; Kocisky, T.; Grefenstette, E.; Espeholt, L.; Kay, W.; Suleyman, M.; Blunsom, P. Teaching machines to read and comprehend. Adv. Neural Inf. Process. Syst. 2015, 28, 1693–1701. [Google Scholar]



{kind=link}
{kind=link}
| Dataset | Input Text | Summary | |
|---|---|---|---|
| MLSum-It | 184.73 | 17.05 | |
| Avg. num. of words | IlPost | 174.43 | 26.39 |
| FanPage | 312.70 | 43.85 | |
| MLSum-It | 6.07 | 1.06 | |
| Avg. num. of sentences | IlPost | 5.88 | 1.91 |
| FanPage | 11.67 | 1.96 | |
| MLSum-It | 308,419 | 67,507 | |
| Vocabulary size | IlPost | 309,609 | 97,099 |
| FanPage | 730,850 | 198,649 |
| Number of Documents | |||
|---|---|---|---|
| Topic | IlPost | FanPage | MLSum-It |
| Tech (Tech) | 2497 | 3776 | - |
| Scienza (Science) | 3849 | 5157 | - |
| Italia (Italy) | 10,739 | - | - |
| Politica (Politics) | 4759 | - | - |
| Internet (Web) | 2939 | - | - |
| Economia (Economy) | 3823 | - | - |
| Cultura (Culture) | 15,419 | - | - |
| Misc (Miscellaneous) | - | 23,150 | - |
| Travel (Travel) | - | 1535 | - |
| Donna (Whoman) | - | 9104 | - |
| Design (Design) | - | 5946 | - |
| Musica (Music) | - | 12,034 | - |
| Gossip (Gossip) | - | 15,770 | - |
| Cinema (Cinema) | - | 7936 | - |
| Total | 44,025 | 84,308 | 40,000 |
| MLSum-It | IT5 | mBART | Pegasus-XSum | Pegasus-CNN/DM |
|---|---|---|---|---|
| ROUGE-1 | 19.29 | 19.35 | 15.17 | 16.97 |
| ROUGE-2 | 6.04 | 6.40 | 3.57 | 5.03 |
| ROUGE-L | 16.50 | 16.35 | 12.45 | 13.11 |
| ROUGE-LS | 16.62 | 16.54 | 12.44 | 13.11 |
| 32.76 | 33.59 | 35.03 | 81.04 |
| Fanpage | IT5 | mBART | Pegasus-XSum | Pegasus-CNN/DM |
|---|---|---|---|---|
| ROUGE-1 | 33.83 | 36.50 | 20.01 | 26.82 |
| ROUGE-2 | 15.46 | 17.44 | 6.49 | 9.02 |
| ROUGE-L | 24.90 | 26.17 | 14.78 | 18.10 |
| ROUGE-LS | 28.31 | 30.26 | 14.76 | 18.10 |
| 69.80 | 75.24 | 32.33 | 80.50 |
| IlPost | IT5 | mBART | Pegasus-XSum | Pegasus-CNN/DM |
|---|---|---|---|---|
| ROUGE-1 | 33.78 | 38.91 | 21.03 | 23.96 |
| ROUGE-2 | 16.29 | 21.38 | 6.63 | 7.72 |
| ROUGE-L | 27.48 | 32.05 | 16.10 | 16.81 |
| ROUGE-LS | 30.23 | 35.07 | 16.07 | 16.81 |
| 45.32 | 39.88 | 29.79 | 77.53 |
| Trainset | Model | R-1 | R-2 | R-L | R-LS | |
|---|---|---|---|---|---|---|
| IlPost test set | ||||||
| Fanpage | IT5 | 23.62 | 10.91 | 19.65 | 19.65 | 19.0 |
| MLSum-It | IT5 | 19.58 | 7.56 | 16.53 | 16.53 | 18.98 |
| Fanpage | mBART | 29.36 | 12.12 | 21.01 | 21.01 | 75.9 |
| MLSum-It | mBART | 24.69 | 8.91 | 18.69 | 18.69 | 39.72 |
| Fanpage test set | ||||||
| Il Post | IT5 | 20.57 | 9.33 | 16.76 | 16.76 | 18.99 |
| MLSum-It | IT5 | 17.4 | 7.4 | 14.66 | 14.66 | 18.97 |
| Il Post | mBART | 29.33 | 11.3 | 20.46 | 20.46 | 45.09 |
| MLSum-It | mBART | 23.4 | 8.73 | 17.58 | 17.58 | 35.34 |
| MLSum-It test set | ||||||
| Fanpage | IT5 | 15.13 | 4.83 | 13.6 | 13.6 | 19.0 |
| Il Post | IT5 | 15.77 | 4.94 | 13.97 | 13.97 | 18.99 |
| Fanpage | mBART | 18.64 | 6.13 | 14.51 | 14.51 | 80.48 |
| Il Post | mBART | 19.24 | 5.52 | 15.38 | 15.38 | 46.26 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Landro, N.; Gallo, I.; La Grassa, R.; Federici, E. Two New Datasets for Italian-Language Abstractive Text Summarization. Information 2022, 13, 228. https://doi.org/10.3390/info13050228
Landro N, Gallo I, La Grassa R, Federici E. Two New Datasets for Italian-Language Abstractive Text Summarization. Information. 2022; 13(5):228. https://doi.org/10.3390/info13050228
Chicago/Turabian StyleLandro, Nicola, Ignazio Gallo, Riccardo La Grassa, and Edoardo Federici. 2022. "Two New Datasets for Italian-Language Abstractive Text Summarization" Information 13, no. 5: 228. https://doi.org/10.3390/info13050228
APA StyleLandro, N., Gallo, I., La Grassa, R., & Federici, E. (2022). Two New Datasets for Italian-Language Abstractive Text Summarization. Information, 13(5), 228. https://doi.org/10.3390/info13050228