
Bias Discovery in Machine Learning Models for Mental Health

 ,
,
Abstract
:1. Introduction
- For a model trained to predict future administrations of benzodiazepines based on past data, does gender unfairly influence the decisions of the model?
- If gender does influence the decisions of said model, how much model performance is sacrificed when applying mitigation strategies to avoid the bias?
2. Materials and Methods
2.1. Related Work
2.2. Data
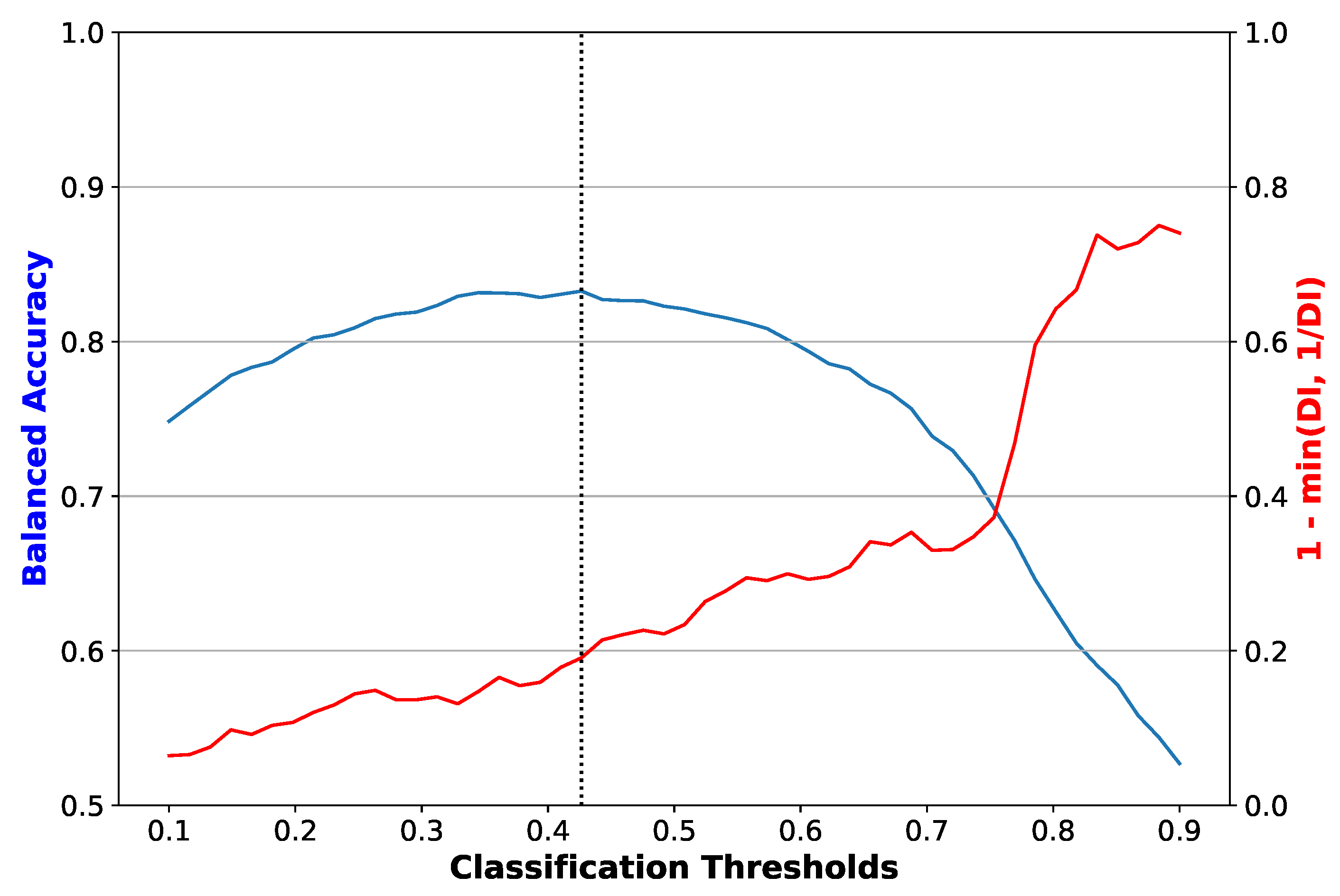
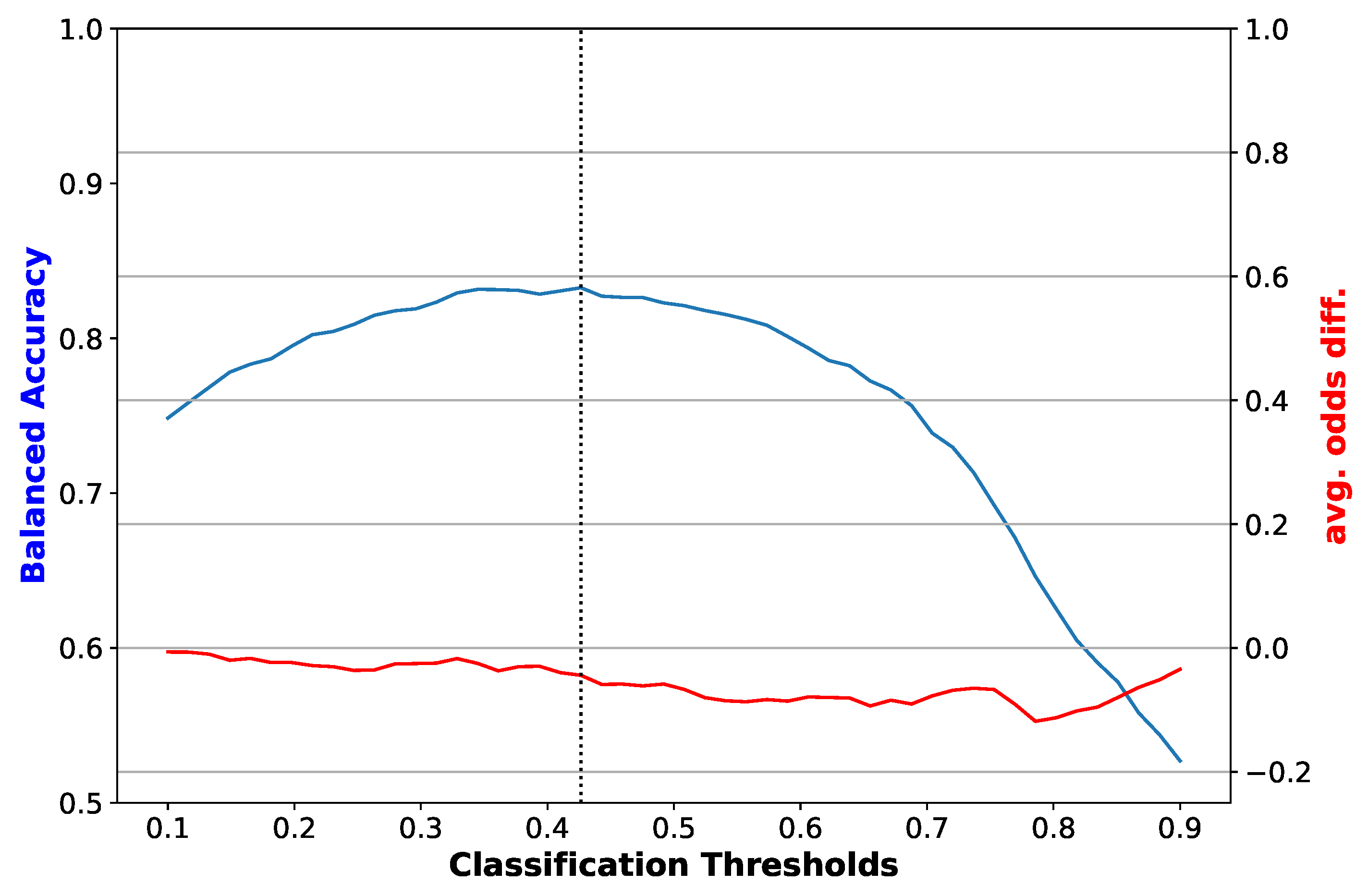
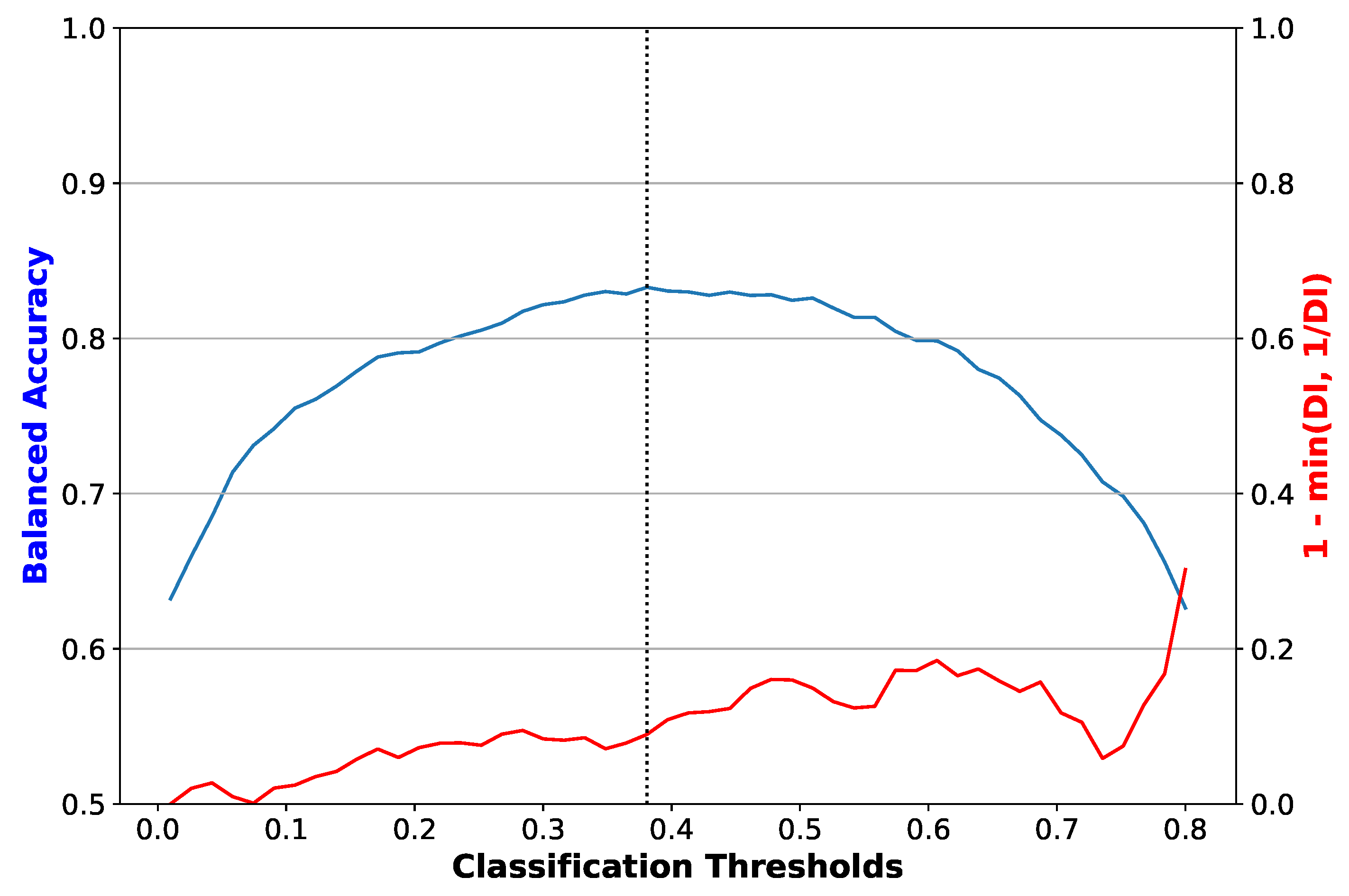
2.3. Evaluation Metrics
- Statistical Parity Difference: Discussed in [26] as the difference between the correctly classified instances for the privileged and the unprivileged group. If the statistical parity difference is 0, then the privileged and unprivileged groups receive the same percentage of positive classifications. Statistical parity is an indicator for representation and therefore a group fairness metric. If the value is negative, the privileged group has an advantage.
- Disparate Impact: Computed as the ratio of the rate of favourable outcome for the unprivileged group to that of the privileged group [31]. This value should be close to 1 for a fair result; lower than 1 implies a benefit for the privileged group.
- Equal Opportunity Difference: The difference between the true positive rates between the unprivileged group and the privileged group. It evaluates the ability of the model to classify the unprivileged group compared to the privileged group. The value should be close to 0 for a fair result. If the value is negative, then the privileged group has an advantage.
- Average Odds Difference: The difference between false positives rates and true positive rates between the unprivileged group and privileged group. It provides insights into a possible positive biases towards a group. This value should be close to 0 for a fair result. If the value is negative, then the privileged group has an advantage.
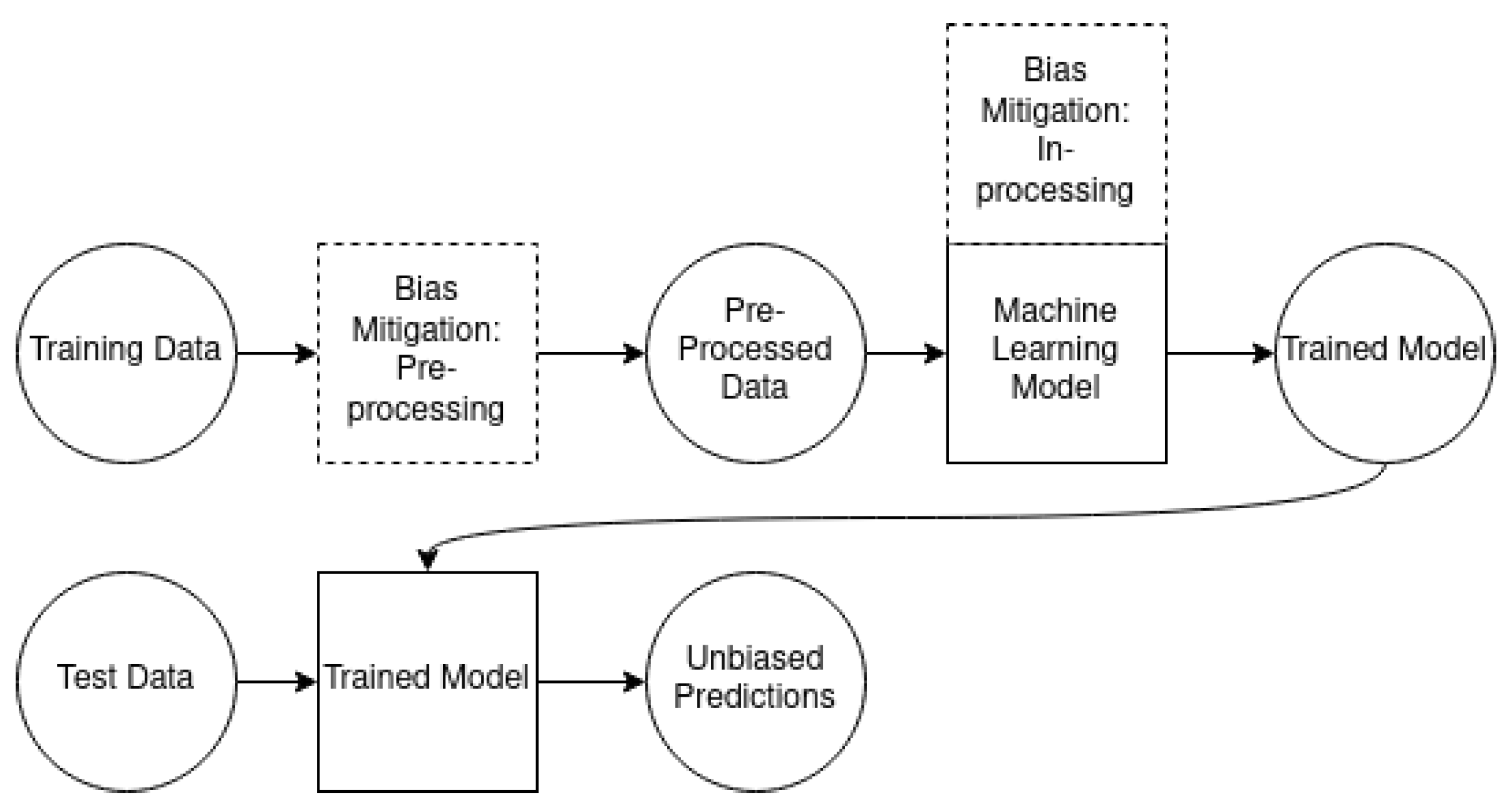
2.4. Machine Learning Methods
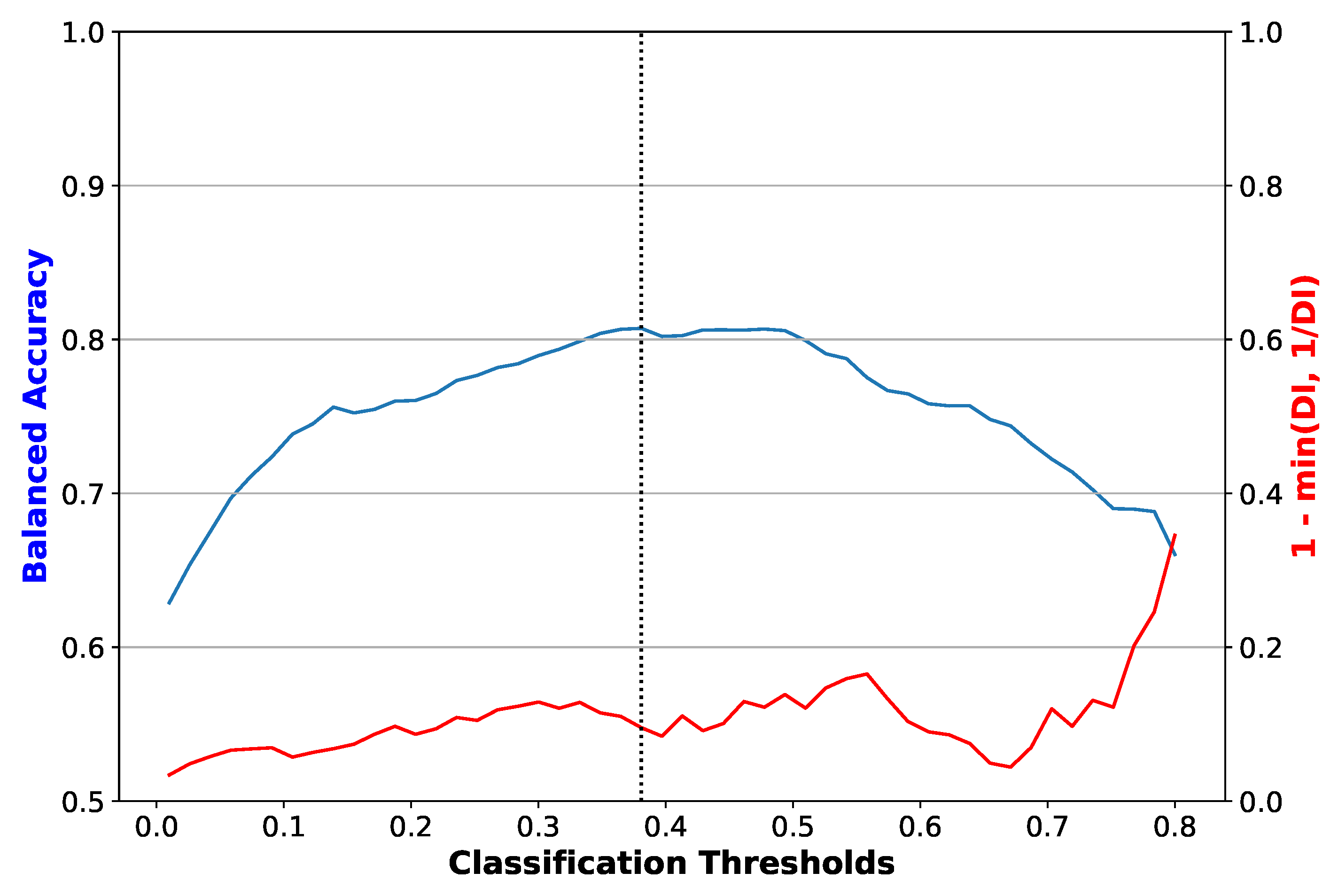
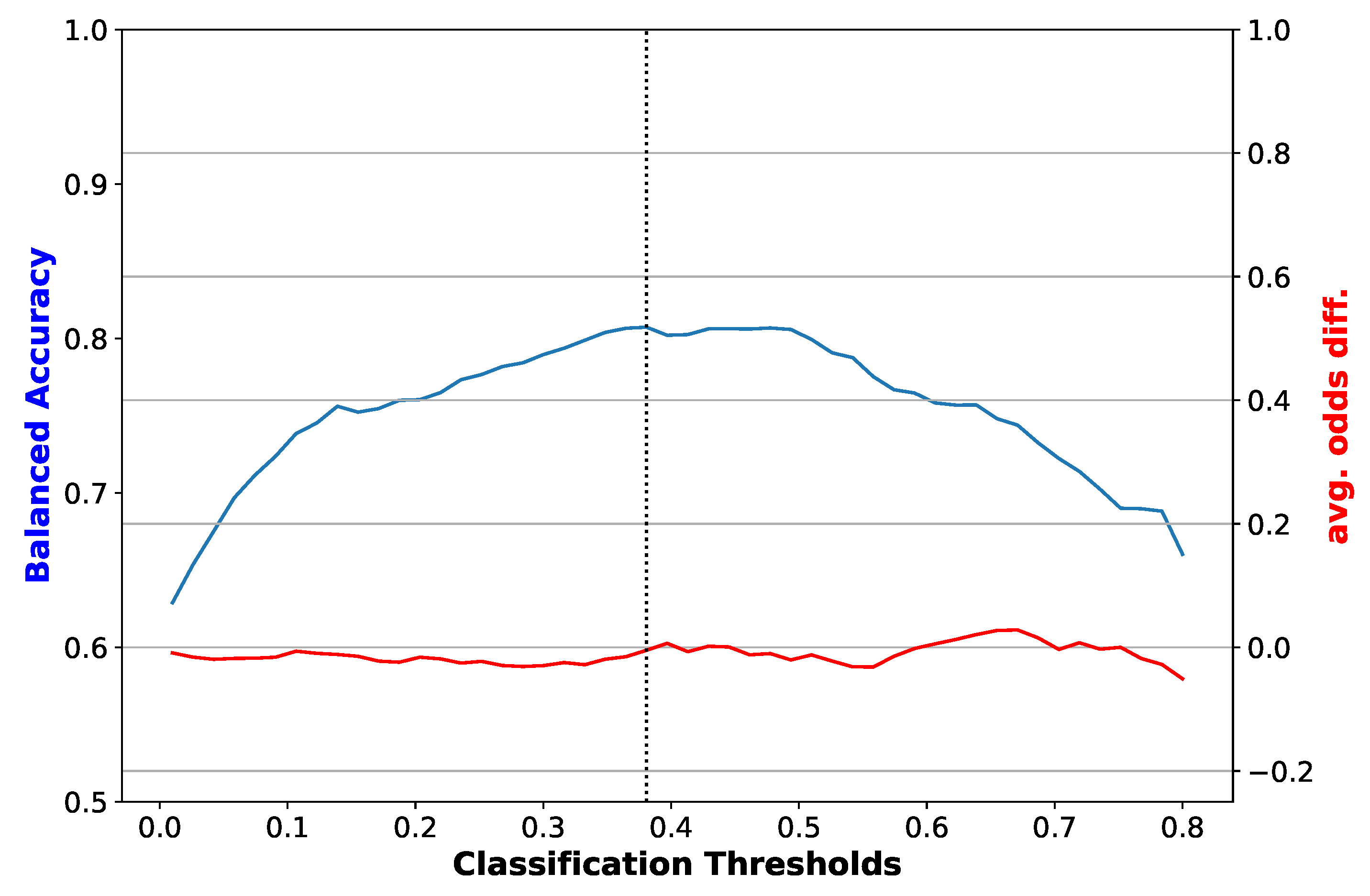
3. Results
4. Discussion
4.1. Analysis of Results
4.2. Limitations
4.3. Future Work
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Pestian, J.; Nasrallah, H.; Matykiewicz, P.; Bennett, A.; Leenaars, A. Suicide Note Classification Using Natural Language Processing: A Content Analysis. Biomed. Inform. Insights 2010, 3, BII.S4706. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Menger, V.; Spruit, M.; van Est, R.; Nap, E.; Scheepers, F. Machine Learning Approach to Inpatient Violence Risk Assessment Using Routinely Collected Clinical Notes in Electronic Health Records. JAMA Netw. Open 2019, 2, e196709. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Le, D.V.; Montgomery, J.; Kirkby, K.C.; Scanlan, J. Risk prediction using natural language processing of electronic mental health records in an inpatient forensic psychiatry setting. J. Biomed. Inform. 2018, 86, 49–58. [Google Scholar] [CrossRef] [PubMed]
- Suchting, R.; Green, C.E.; Glazier, S.M.; Lane, S.D. A data science approach to predicting patient aggressive events in a psychiatric hospital. Psychiatry Res. 2018, 268, 217–222. [Google Scholar] [CrossRef] [PubMed]
- van Mens, K.; de Schepper, C.; Wijnen, B.; Koldijk, S.J.; Schnack, H.; de Looff, P.; Lokkerbol, J.; Wetherall, K.; Cleare, S.; O’Connor, R.C.; et al. Predicting future suicidal behaviour in young adults, with different machine learning techniques: A population-based longitudinal study. J. Affect. Disord. 2020, 271, 169–177. [Google Scholar] [CrossRef] [PubMed]
- Kalidas, V. Siamese Fine-Tuning of BERT for Classification of Small and Imbalanced Datasets, Applied to Prediction of Involuntary Admissions in Mental Healthcare. Master’s Thesis, Eindhoven University of Technology, Eindhoven, The Netherlands, 2020. [Google Scholar]
- Delgado-Rodriguez, M.; Llorca, J. Bias. J. Epidemiol. Community Health 2004, 58, 635–641. [Google Scholar] [CrossRef] [Green Version]
- Kim, H.B.; Myung, S.K.; Park, Y.C.; Park, B. Use of benzodiazepine and risk of cancer: A meta-analysis of observational studies. Int. J. Cancer 2017, 140, 513–525. [Google Scholar] [CrossRef] [Green Version]
- Quaglio, G.; Pattaro, C.; Gerra, G.; Mathewson, S.; Verbanck, P.; Des Jarlais, D.C.; Lugoboni, F. High dose benzodiazepine dependence: Description of 29 patients treated with flumazenil infusion and stabilised with clonazepam. Psychiatry Res. 2012, 198, 457–462. [Google Scholar] [CrossRef]
- Federatie Medisch Specialisten. Angststoornissen. Available online: https://richtlijnendatabase.nl/richtlijn/angststoornissen/gegeneraliseerde_angststoornis_gas/farmacotherapie_bij_gas/benzodiazepine_gegeneraliseerde_angststoornis.html (accessed on 18 November 2021).
- Vinkers, C.H.; Tijdink, J.K.; Luykx, J.J.; Vis, R. Kiezen voor de juiste benzodiazepine. Ned. Tijdschr. Geneeskd. 2012, 156, A4900. [Google Scholar]
- Bjorner, T.; Laerum, E. Factors associated with high prescribing of benzodiazepines and minor opiates. Scand. J. Prim. Health Care 2003, 21, 115–120. [Google Scholar] [CrossRef] [Green Version]
- Peters, S.M.; Knauf, K.Q.; Derbidge, C.M.; Kimmel, R.; Vannoy, S. Demographic and clinical factors associated with benzodiazepine prescription at discharge from psychiatric inpatient treatment. Gen. Hosp. Psychiatry 2015, 37, 595–600. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Cook, B.; Creedon, T.; Wang, Y.; Lu, C.; Carson, N.; Jules, P.; Lee, E.; Alegría, M. Examining racial/ethnic differences in patterns of benzodiazepine prescription and misuse. Drug Alcohol Depend. 2018, 187, 29–34. [Google Scholar] [CrossRef] [PubMed]
- Olfson, M.; King, M.; Schoenbaum, M. Benzodiazepine Use in the United States. JAMA Psychiatry 2015, 72, 136–142. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- McIntyre, R.S.; Chen, V.C.H.; Lee, Y.; Lui, L.M.W.; Majeed, A.; Subramaniapillai, M.; Mansur, R.B.; Rosenblat, J.D.; Yang, Y.H.; Chen, Y.L. The influence of prescriber and patient gender on the prescription of benzodiazepines: Evidence for stereotypes and biases? Soc. Psychiatry Psychiatr. Epidemiol. 2021, 56, 1433–9285. [Google Scholar] [CrossRef] [PubMed]
- Lui, L.M.W.; Lee, Y.; Lipsitz, O.; Rodrigues, N.B.; Gill, H.; Ma, J.; Wilkialis, L.; Tamura, J.K.; Siegel, A.; Chen-Li, D.; et al. The influence of prescriber and patient gender on the prescription of benzodiazepines: Results from the Florida Medicaid Dataset. CNS Spectrums 2021, 26, 1–5. [Google Scholar] [CrossRef] [PubMed]
- Maric, N.P.; Latas, M.; Andric Petrovic, S.; Soldatovic, I.; Arsova, S.; Crnkovic, D.; Gugleta, D.; Ivezic, A.; Janjic, V.; Karlovic, D.; et al. Prescribing practices in Southeastern Europe—Focus on benzodiazepine prescription at discharge from nine university psychiatric hospitals. Psychiatry Res. 2017, 258, 59–65. [Google Scholar] [CrossRef]
- Bellamy, R.K.E.; Dey, K.; Hind, M.; Hoffman, S.C.; Houde, S.; Kannan, K.; Lohia, P.; Martino, J.; Mehta, S.; Mojsilović, A.; et al. AI Fairness 360: An extensible toolkit for detecting and mitigating algorithmic bias. IBM J. Res. Dev. 2019, 63, 4:1–4:15. [Google Scholar] [CrossRef]
- Baer, T. Understand, Manage, and Prevent Algorithmic Bias; Apress: Berkeley, CA, USA, 2019. [Google Scholar]
- Ellenberg, J.H. Selection bias in observational and experimental studies. Stat. Med. 1994, 13, 557–567. [Google Scholar] [CrossRef]
- Barocas, S.; Selbst, A. Big Data’s Disparate Impact. Calif. Law Rev. 2016, 104, 671. [Google Scholar] [CrossRef]
- d’Alessandro, B.; O’Neil, C.; LaGatta, T. Conscientious Classification: A Data Scientist’s Guide to Discrimination-Aware Classification. Big Data 2017, 5, 120–134. [Google Scholar] [CrossRef]
- Lang, W.W.; Nakamura, L.I. A Model of Redlining. J. Urban Econ. 1993, 33, 223–234. [Google Scholar] [CrossRef]
- Chouldechova, A.; Roth, A. A Snapshot of the Frontiers of Fairness in Machine Learning. Commun. ACM 2020, 63, 82–89. [Google Scholar] [CrossRef]
- Dwork, C.; Hardt, M.; Pitassi, T.; Reingold, O.; Zemel, R. Fairness through Awareness. Available online: https://arxiv.org/abs/1104.3913 (accessed on 18 November 2021).
- Zemel, R.; Wu, Y.; Swersky, K.; Pitassi, T.; Dwork, C. Learning Fair Representations. In Proceedings of the 30th International Conference on Machine Learning, PMLR, Atlanta, GA, USA, 17–19 June 2013; Volume 28, pp. 325–333. [Google Scholar]
- Joseph, M.; Kearns, M.; Morgenstern, J.; Roth, A. Fairness in Learning: Classic and Contextual Bandits. Available online: https://arxiv.org/abs/1605.07139 (accessed on 18 November 2021).
- Friedler, S.A.; Scheidegger, C.; Venkatasubramanian, S. On the (Im)Possibility of Fairness. Available online: https://arxiv.org/abs/1609.07236 (accessed on 18 November 2021).
- Saleiro, P.; Kuester, B.; Hinkson, L.; London, J.; Stevens, A.; Anisfeld, A.; Rodolfa, K.T.; Ghani, R. Aequitas: A Bias and Fairness Audit Toolkit. Available online: https://arxiv.org/abs/1811.05577 (accessed on 18 November 2021).
- Feldman, M.; Friedler, S.; Moeller, J.; Scheidegger, C.; Venkatasubramanian, S. Certifying and Removing Disparate Impact. Available online: https://arxiv.org/abs/1412.3756 (accessed on 18 November 2021).
- Kamiran, F.; Calders, T. Data preprocessing techniques for classification without discrimination. Knowl. Inf. Syst. 2012, 33, 1–33. [Google Scholar] [CrossRef] [Green Version]
- Kamishima, T.; Akaho, S.; Asoh, H.; Sakuma, J. Fairness-Aware Classifier with Prejudice Remover Regularizer. In Machine Learning and Knowledge Discovery in Databases; Flach, P.A., De Bie, T., Cristianini, N., Eds.; Springer: Berlin/Heidelberg, Germany, 2012; pp. 35–50. [Google Scholar]
- Scheuerman, M.K.; Wade, K.; Lustig, C.; Brubaker, J.R. How We’ve Taught Algorithms to See Identity: Constructing Race and Gender in Image Databases for Facial Analysis. Proc. ACM Hum.-Comput. Interact. 2020, 4, 1–35. [Google Scholar] [CrossRef]
- Xu, T.; White, J.; Kalkan, S.; Gunes, H. Investigating Bias and Fairness in Facial Expression Recognition. In Proceedings of the Computer Vision—ECCV 2020 Workshops, Glasgow, UK, 23–28 August 2020; Bartoli, A., Fusiello, A., Eds.; Springer International Publishing: Cham, Switzerland, 2020; pp. 506–523. [Google Scholar]
- Yucer, S.; Akcay, S.; Al-Moubayed, N.; Breckon, T.P. Exploring Racial Bias Within Face Recognition via Per-Subject Adversarially-Enabled Data Augmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Seattle, DC, USA, 14–19 June 2020; pp. 18–19. [Google Scholar]
- Liu, H.; Dacon, J.; Fan, W.; Liu, H.; Liu, Z.; Tang, J. Does Gender Matter? Towards Fairness in Dialogue Systems. Available online: https://arxiv.org/abs/1910.10486 (accessed on 18 November 2021).
- Kizilcec, R.F.; Lee, H. Algorithmic Fairness in Education. Available online: https://arxiv.org/abs/2007.05443 (accessed on 18 November 2021).
- Geneviève, L.D.; Martani, A.; Shaw, D.; Elger, B.S.; Wangmo, T. Structural racism in precision medicine: Leaving no one behind. BMC Med. Ethics 2020, 21, 17. [Google Scholar] [CrossRef]
- Tripathi, S.; Fritz, B.A.; Abdelhack, M.; Avidan, M.S.; Chen, Y.; King, C.R. (Un)Fairness in Post-Operative Complication Prediction Models. Available online: https://arxiv.org/abs/2011.02036 (accessed on 18 November 2021).
- Singh, H.; Mhasawade, V.; Chunara, R. Generalizability Challenges of Mortality Risk Prediction Models: A Retrospective Analysis on a Multi-center Database. medRxiv 2021. [Google Scholar] [CrossRef]
- Amir, S.; van de Meent, J.W.; Wallace, B.C. On the Impact of Random Seeds on the Fairness of Clinical Classifiers. Available online: https://arxiv.org/abs/2104.06338 (accessed on 18 November 2021).
- Jasuja, G.K.; Reisman, J.I.; Weiner, R.S.; Christopher, M.L.; Rose, A.J. Gender differences in prescribing of zolpidem in the Veterans Health Administration. Am. J. Manag. Care 2019, 25, e58–e65. [Google Scholar] [CrossRef]
- Nam, S.K.; Chu, H.J.; Lee, M.K.; Lee, J.H.; Kim, N.; Lee, S.M. A Meta-analysis of Gender Differences in Attitudes Toward Seeking Professional Psychological Help. J. Am. Coll. Health 2010, 59, 110–116. [Google Scholar] [CrossRef]
- Strakowski, S.M.; McElroy, S.L.; Keck, P.E.; West, S.A. Racial influence on diagnosis in psychotic mania. J. Affect. Disord. 1996, 39, 157–162. [Google Scholar] [CrossRef]
- Rumshisky, A.; Ghassemi, M.; Naumann, T.; Szolovits, P.; Castro, V.M.; McCoy, T.H.; Perlis, R.H. Predicting early psychiatric readmission with natural language processing of narrative discharge summaries. Transl. Psychiatry 2016, 6, e921. [Google Scholar] [CrossRef] [Green Version]
- Tang, S.X.; Kriz, R.; Cho, S.; Park, S.J.; Harowitz, J.; Gur, R.E.; Bhati, M.T.; Wolf, D.H.; Sedoc, J.; Liberman, M.Y. Natural language processing methods are sensitive to sub-clinical linguistic differences in schizophrenia spectrum disorders. NPJ Schizophr. 2021, 7, 25. [Google Scholar] [CrossRef] [PubMed]
- Kaczmarek-Majer, K.; Casalino, G.; Castellano, G.; Hryniewicz, O.; Dominiak, M. Explaining smartphone-based acoustic data in bipolar disorder: Semi-supervised fuzzy clustering and relative linguistic summaries. Inf. Sci. 2022, 588, 174–195. [Google Scholar] [CrossRef]
- Nederlands Huisartsen Genootschap. Omrekentabel Benzodiazepine naar Diazepam 2 mg Tabletten. 2014. Available online: https://www.nhg.org/sites/default/files/content/nhg_org/images/thema/omrekentabel_benzodiaz._naar_diazepam_2_mg_tab.pdf (accessed on 22 March 2022).
- Pedregosa, F.; Varoquaux, G.; Gramfort, A.; Michel, V.; Thirion, B.; Grisel, O.; Blondel, M.; Prettenhofer, P.; Weiss, R.; Dubourg, V.; et al. Scikit-learn: Machine Learning in Python. J. Mach. Learn. Res. 2011, 12, 2825–2830. [Google Scholar]
- Pfohl, S.R.; Foryciarz, A.; Shah, N.H. An empirical characterization of fair machine learning for clinical risk prediction. J. Biomed. Inform. 2021, 113, 103621. [Google Scholar] [CrossRef] [PubMed]
- Kuiper, J. Machine-Learning Based Bias Discovery in Medical Data. Master’s Thesis, Utrecht University, Utrecht, The Netherlands, 2021. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Variable | Type |
|---|---|---|
| Admissions | Admission ID | Identifier |
| Patient ID | Identifier | |
| Nursing ward ID | Identifier | |
| Admission date | Date | |
| Discharge date | Date | |
| Admission time | Time | |
| Discharge time | Time | |
| Emergency | Boolean | |
| First admission | Boolean | |
| Gender | Man/Woman | |
| Age at admission | Integer | |
| Admission status | Ongoing/Discharged | |
| Duration in days | Integer | |
| Medication | Patient ID | Identifier |
| Prescription ID | Identifier | |
| ATC code (medication ID) | String | |
| Medication name | String | |
| Dose | Float | |
| Unit (for dose) | String | |
| Administration date | Date | |
| Administration time | Time | |
| Administered | Boolean | |
| Dose used | Float | |
| Original dose | Float | |
| Continuation After Suspension | Boolean | |
| Not administered | Boolean | |
| Diagnoses | Patient ID | Identifier |
| Diagnosis number | Identifier | |
| Start date | Date | |
| End date | Date | |
| Main diagnosis group | Categorical | |
| Level of care demand | Numeric | |
| Multiple problem | Boolean | |
| Personality disorder | Boolean | |
| Admission | Boolean | |
| Diagnosis date | Date | |
| Aggression | Patient ID | Identifier |
| Date of incident | Date | |
| Start time | Time | |
| Patient | Patient ID | Identifier |
| Age at start of dossier | Integer |
| Tranquillizer | Multiplier | mg/(mg Diazepam) |
|---|---|---|
| Diazepam | 1.0 | 1.00 |
| Alprazolam | 10.0 | 0.10 |
| Bromazepam | 1.0 | 1.00 |
| Brotizolam | 40.0 | 0.03 |
| Chlordiazepoxide | 0.5 | 2.00 |
| Clobazam | 0.5 | 2.00 |
| Clorazepate potassium | 0.75 | 1.33 |
| Flunitrazepam | 0.1 | 10 |
| Flurazepam | 0.33 | 3.03 |
| Lorazepam | 5.0 | 0.20 |
| Lormetazepam | 10.0 | 0.10 |
| Midazolam | 1.33 | 0.10 |
| Nitrazepam | 1.0 | 1.00 |
| Oxazepam | 0.33 | 3.03 |
| Temazepam | 1.0 | 1.00 |
| Zolpidem | 1.0 | 1.00 |
| Zopiclone | 1.33 | 0.75 |
| Variable | Type |
|---|---|
| Patient ID | Numeric |
| Emergency | Binary |
| First admission | Binary |
| Gender | Binary |
| Age at admission | Numeric |
| Duration in days | Numeric |
| Age at start of dossier | Numeric |
| Incidents during admission | Numeric |
| Incidents before admission | Numeric |
| Multiple problem | Binary |
| Personality disorder | Binary |
| Minimum level of care demand | Numeric |
| Maximum level of care demand | Numeric |
| Past diazepam-equivalent dose | Numeric |
| Future diazepam-equivalent dose | Numeric |
| Nursing ward: Clinical Affective and Psychotic Disorders | Binary |
| Nursing ward: Clinical Acute and Intensive Care | Binary |
| Nursing ward: Clinical Acute and Intensive Care Youth | Binary |
| Nursing ward: Clinical Diagnosis and Early Psychosis | Binary |
| Diagnosis: Attention Deficit Disorder | Binary |
| Diagnosis: Other issues that may be a cause for concern | Binary |
| Diagnosis: Anxiety disorders | Binary |
| Diagnosis: Autism spectrum disorder | Binary |
| Diagnosis: Bipolar Disorders | Binary |
| Diagnosis: Cognitive disorders | Binary |
| Diagnosis: Depressive Disorders | Binary |
| Diagnosis: Dissociative Disorders | Binary |
| Diagnosis: Behavioural disorders | Binary |
| Diagnosis: Substance-Related and Addiction Disorders | Binary |
| Diagnosis: Obsessive Compulsive and Related Disorders | Binary |
| Diagnosis: Other mental disorders | Binary |
| Diagnosis: Other Infant or Childhood Disorders | Binary |
| Diagnosis: Personality Disorders | Binary |
| Diagnosis: Psychiatric disorders due to a general medical condition | Binary |
| Diagnosis: Schizophrenia and other psychotic disorders | Binary |
| Diagnosis: Somatic Symptom Disorder and Related Disorders | Binary |
| Diagnosis: Trauma- and stressor-related disorders | Binary |
| Diagnosis: Nutrition and Eating Disorders | Binary |
| Model | Performance | ||
|---|---|---|---|
| Clf. | Mit. | Accbal | F1 |
| LR | 0.834 ± 0.015 | 0.843 ± 0.014 | |
| RF | 0.843 ± 0.018 | 0.835 ± 0.020 | |
| LR | RW | 0.830 ± 0.014 | 0.839 ± 0.011 |
| RF | RW | 0.847 ± 0.019 | 0.840 ± 0.020 |
| LR | PR | 0.793 ± 0.020 | 0.802 ± 0.029 |
| Model | Fairness | ||||
|---|---|---|---|---|---|
| Clf. | Mit. | DI | AOD | SPD | EOD |
| LR | 0.793 ± 0.074 | −0.046 ± 0.021 | −0.110 ± 0.038 | −0.038 ± 0.028 | |
| RF | 0.796 ± 0.071 | −0.018 ± 0.017 | −0.083 ± 0.031 | −0.013 ± 0.035 | |
| LR | RW | 0.869 ± 0.066 | −0.003 ± 0.013 | −0.066 ± 0.035 | 0.004 ± 0.034 |
| RF | RW | 0.830 ± 0.077 | −0.004 ± 0.023 | −0.070 ± 0.034 | 0.001 ± 0.043 |
| LR | PR | 0.886 ± 0.056 | −0.008 ± 0.003 | −0.060 ± 0.034 | −0.020 ± 0.045 |
| Model | Performance | ||
|---|---|---|---|
| Clf. | Mit. | ΔAccbal | ΔF1 |
| LR | PR | −0.040 ± 0.013 | −0.041 ± 0.025 |
| LR | RW | −0.003 ± 0.013 | −0.005 ± 0.013 |
| RF | RW | 0.003 ± 0.002 | 0.005 ± 0.001 |
| Model | Fairness | ||||
|---|---|---|---|---|---|
| Clf. | Mit. | ΔDI | ΔAOD | ΔSPD | ΔEOD |
| LR | PR | 0.092 ± 0.036 | 0.038 ± 0.021 | 0.050 ± 0.019 | 0.018 ± 0.042 |
| LR | RW | 0.075 ± 0.021 | 0.043 ± 0.017 | 0.043 ± 0.014 | 0.042 ± 0.034 |
| RF | RW | 0.034 ± 0.013 | 0.014 ± 0.006 | 0.013 ± 0.006 | 0.014 ± 0.011 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Mosteiro, P.; Kuiper, J.; Masthoff, J.; Scheepers, F.; Spruit, M. Bias Discovery in Machine Learning Models for Mental Health. Information 2022, 13, 237. https://doi.org/10.3390/info13050237
Mosteiro P, Kuiper J, Masthoff J, Scheepers F, Spruit M. Bias Discovery in Machine Learning Models for Mental Health. Information. 2022; 13(5):237. https://doi.org/10.3390/info13050237
Chicago/Turabian StyleMosteiro, Pablo, Jesse Kuiper, Judith Masthoff, Floortje Scheepers, and Marco Spruit. 2022. "Bias Discovery in Machine Learning Models for Mental Health" Information 13, no. 5: 237. https://doi.org/10.3390/info13050237
APA StyleMosteiro, P., Kuiper, J., Masthoff, J., Scheepers, F., & Spruit, M. (2022). Bias Discovery in Machine Learning Models for Mental Health. Information, 13(5), 237. https://doi.org/10.3390/info13050237