
A Literature Review of Textual Hate Speech Detection Methods and Datasets



Abstract
:1. Introduction
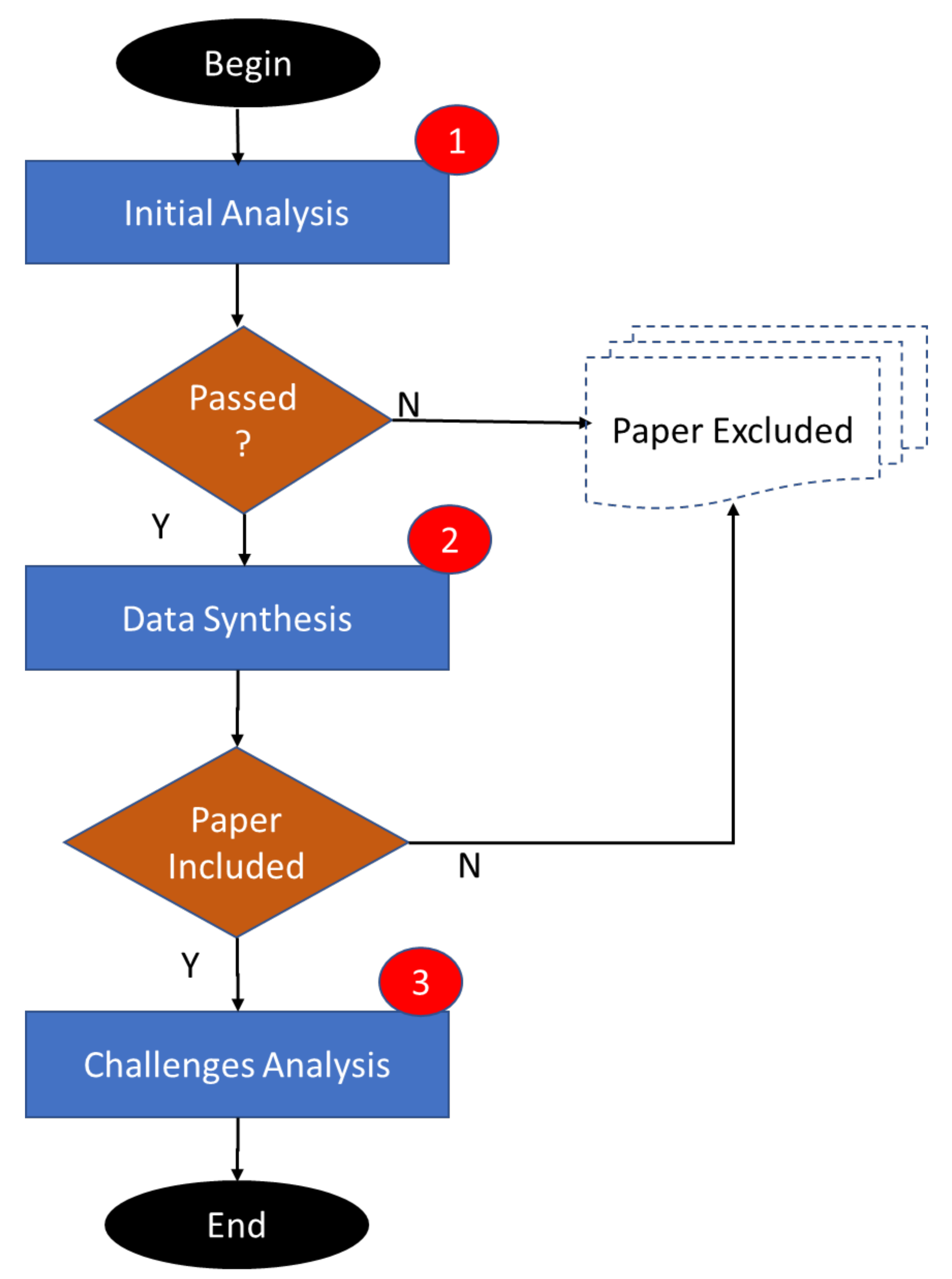
2. Methodology
3. Results and Analysis
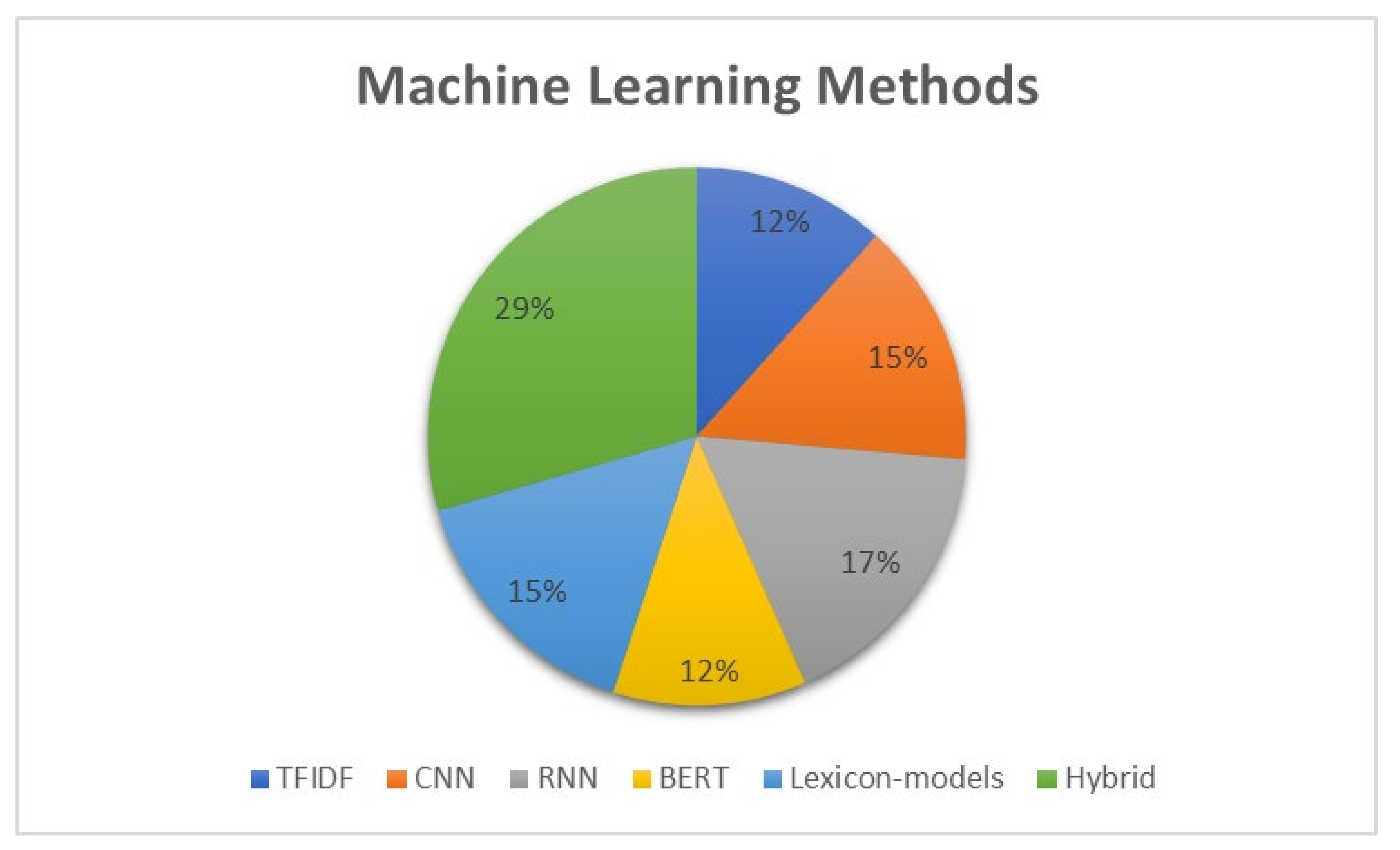
3.1. Machine Learning Hate Speech Models
3.1.1. TFIDF Methods
3.1.2. Lexicon-Based Methods
3.1.3. Deep Learning Methods
3.1.4. Hybrid Methods
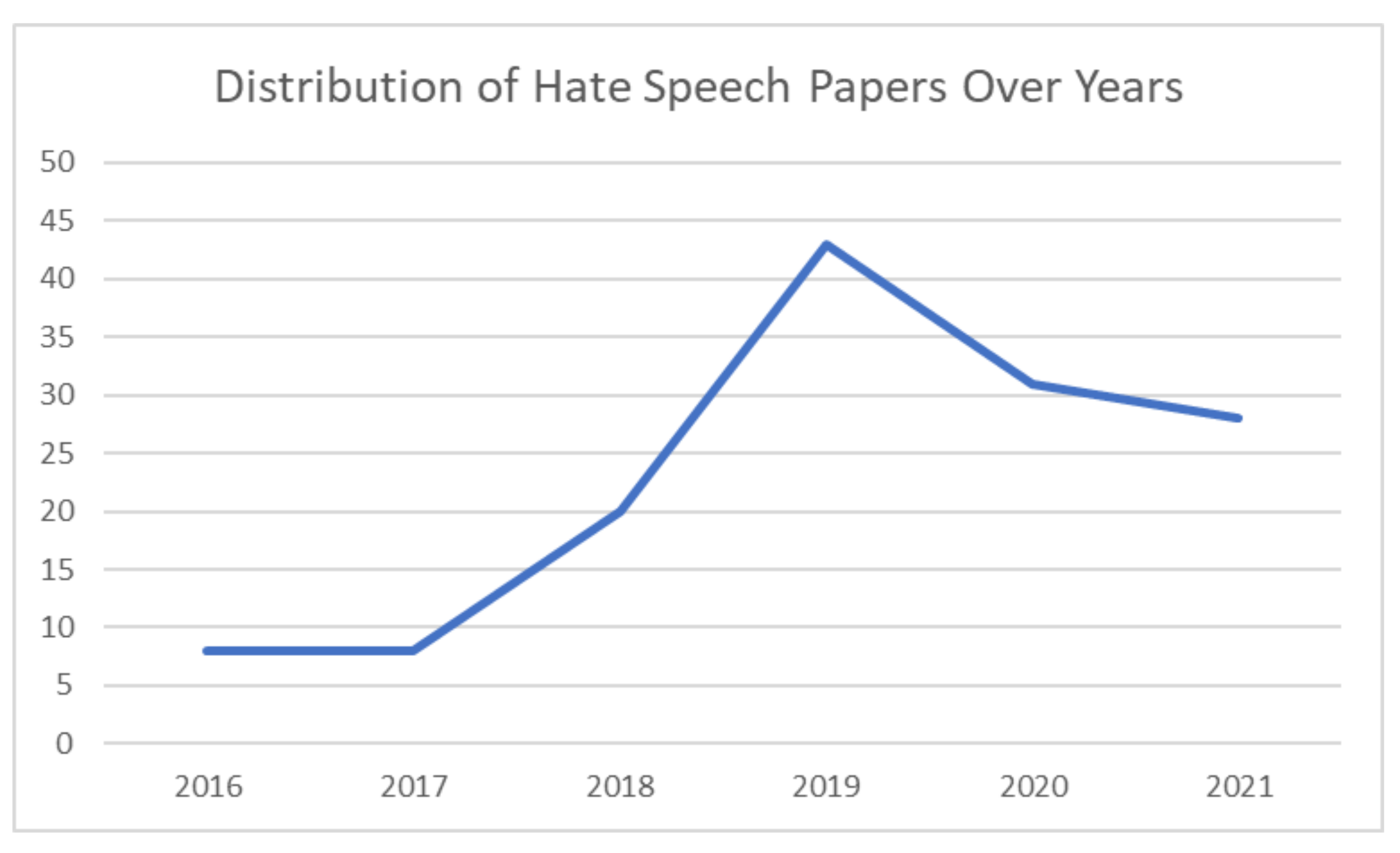
3.2. Datasets
4. Discussion
4.1. Challenges of Machine Learning Models
4.2. Challenges of Datasets
4.3. Challenges of Feature Sets
4.4. Future Research Directions
- There is a critical dearth of reporting in the literature on the optimal set of features for hate speech detection that can be applied to both classical and deep learning models. Therefore, extensive research is needed to develop features that work well with diverse datasets with multifaceted hate speech concepts. A successful model should also have features that can be applied to new datasets and previously unseen tweets. A direction could be research [45,153] in which more features are added to develop additional features.
- Aside from the basic hate/no hate categorization for traditional and deep learning models, the literature lacks a detailed investigation of fine-grained hate speech detection at the label level. According to the studies gathered, there is still a gap in creating a model that successfully performs the multi-classification of hate speech, has acceptable performance, and can be generalized across settings. A starting point could be using the models of [81], where several classes were adopted.
- There are no recommendations in the literature to ensure that hate speech detection methods are adequately compared across different datasets. Therefore, a new methodology for dataset comparison is needed so that datasets can be rigorously compared.
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Appendix A

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Paper | Dataset | Best Method | Results | Limitation |
|---|---|---|---|---|
| [40] | Islamophobic hate speech data set (109,488 tweets) | One-versus-one SVM | 0.77 accuracy | The dataset was for the UK context and the word context was not considered. |
| [25] | 25,000 tweets | SVM | 0.91 F1-measure | The one-versus-rest classifier is trained for each class, where the class label is assigned to the highest probability scores across classifiers. |
| [30] | 5593 tweets | SVM | 0.97 F1-score | The sexual-orientation hate class only obtained a 0.51 F1-score. |
| [26] | 14 K tweets | J48 graft | 0.78 F1-measure | Hate speech classes: clean, offensive, hateful(three classes of hate mixed with offensive hate). |
| [34] | Automatic Misogyny Identification (AMI) IberEval [35] (3251 tweets), AMI EvalIta [36] (4000 tweets), and the SRW [28] (5006 tweets) | LR | accuracy AMI IberEval: 0.7605AMI EvalIta: 0.7947SRW:0.8937 | General sexist tweets hide a sentiment of hate or misogynistic attitude. Sexist jokes could contribute to making sexism or misogyny not generic to hate speech. |
| [28] | 16 K tweets | LR | 73.93 F1-score | Based on three classes—racism, sexism, and none—results were due to false positives for multi-class labels with an F1-score of 0.53 as compared to a binary classification of 0.73 F1-score. |
| [22] | EVALITA shared task 2018 (5000 tweets) | LR | 0.704 accuracy | Misogyny classification has a low F1-score of 0.37. |
| [44] | 10 K tweets (English) and 5 K tweets in Spanish | SVM | 0.38/0.37 F1-measure of evaluation dataset (Task A, Task B [45]). Detection of hate speech (Task A), and identifying whether the objective of hatred is a person or a group of people (Task B). | Low-performance, approximately random, and shallow feature sets. |
| [46] | Semeval-2019 task 5: multilingual detection of hate speech against immigrants and women on Twitter(19,600 tweets—13,000 in English and 6600 in Spanish) | LIBSVM with RBF | TASK 1: hateful or not: 0.58 accuracy TASK 2: individual or generic: 0.81 accuracy TASK 3: aggressive or not: 0.80 accuracy | Focused on detection of hate speech against immigrants and women on Twitter (HatEval). |
| [116] | 2228 sarcastic tweets | RF | 0.83 accuracy | Most of the sarcastic tweets do not fall in the category of sarcasm where a positive sentiment contrasts with a negative situation. Some authors did not recognize sarcasm as hate speech. |
| [37] | CrowdFlower (Davidson et al.) [25] and the Forum for Information Retrieval Evaluation (FIRE) dataset. The FIRE task is a forum for Identifying Hate Speech and Offensive Content in Social Media Text (HASOC) [38]. CrowdFlower dataset (24,783, 9322). HASOC dataset (5852, 9292) | SVM with GLOVE | Accuracy HASOC Dataset:0.63 CrowdFlower Dataset:0.89 | Binary classification classes are hate, offensive, and neither, not considering other types of hate speech. |
| [52] | MMHS150K dataset (150 K tweets) | LDA | 0.704 F1-score | Despite using images in the dataset, it did not outperform textual models. |
| [65] | 76 K tweets | MCD + LSTM | 0.78 accuracy | The dataset was built into the following categories: sexual orientation, religion, nationality, gender, and ethnicity; however, the classifiers were trained on three classes: hateful, abusive, or neither. |
| [69] | 6655 tweets | GRU + CNN | 0.78 F1-score | The system identified racist and sexist tweets, but was not able to correctly identify the category ‘both’ since there are very few examples in this category. |
| [53,54] | 120,000 tweets | Fuzzy ensemble | 0.80 accuracy | Focused on detecting profiles rather than content. |
| [71] | 12,311 tweets from COVID-19 dataset [72] 1105 tweets for US elections 4989 tweets from Waseem and Hovy | Multi-kernel convolution (MKC) of CNN | 0.88 F1-score in US elections 0.83 in COVID-19 dataset 0.61 in Waseem and Hovy dataset | Focused on an election and COVID-19. |
| [140] | Davidson dataset [25] (24,783 tweets) | MCBiGRU | 0.80–0.94 F1-score over different datasets. 0.94 in Davidson dataset of 24,783 tweets | One potential issue with pre-trained embeddings is out-of-vocabulary (OOV) words. |
| [115] | 1235 tweets | CAT boost | 0.94 F1-score | Binary classification. Small dataset. |
| [76] | 13,240 tweets from OLID [101] | LDA | 0.66 F1-score (Subtask A: offensive/not) 0.88 F1-score (Subtask B: categorization of offense types) | Sarcastic tweets make it difficult to discern the emotions (as per the author). Topic-wise, rather than the classification of hate speech content. Small dataset. |
| [59] | Dataset1: CrowdFlower (24,783, 9322)Dataset2: Waseem dataset [28] (16,093) Dataset 3: Davidson dataset [25] (24,783) | RETINA | Hate, offensive, neither) from Dataset 1, F1-score: 0.14, 0.67, 0.88 | Sexism, racism, and neither labels had an F1-score of 0.04, 0, 0.92 in Dataset 3 as well as a low F1-score in Dataset 2. |
| [80] | SemEval-2019 Task 6 [95] dataset (14 K for subtask A: Offensive (OFF) and non-offensive(NOT)) | MCD + LSTM | 0.78 F1-score | Binary classification: offensive and non-offensive. |
| [114] | SemEval-2019 Task 6 [154] | GRU + CNN | Task A: classification of tweets into either offensive (OFF) or not offensive (NOT) 0.78 for supervised 0.77 for unsupervised approach | Binary classification: offensive and no offensive. |
| [117] | Davidson [25], Hateval [83], Waseem and Hovy [28], Waseem [27,81] Total of 121 annotated tweets out of 396 tweets | Cat Boost | F1-score ranging from 0.85 to 0.89 Best average F1-score 87.74 across all datasets | The classified hate is related to ethnic hate, racism, sexism, gender, and refugee hate. Similarly to HASOC Subtask 1 [38] and topic-relevant forum posts [155], where the topic of hate is detected rather than the type of hate speech. |
Appendix B
| No. | Dataset Name | Size (# of Tweets) | Categories of the Dataset | Ref |
|---|---|---|---|---|
| 1 | Waseem and Hovy | 16,000 | Racism, sexism, neither | [28] |
| 2 | Davidson et al. | 24,783 | Hate, offensive, neither | [25] |
| 3 | Waseem | 6909 | Racism, sexism, neither, both | [28] |
| 4 | SemEval Task 6 (OLID) | 14,000 tweets | Level A: offensive, not offensive Level B: targeted insult, untargeted Level C: individual, group, other | [101] |
| 5 | SemEval Task 5 (HatEval) | 19,600, 13,000 in English, 6600 in Spanish | Subtask A: hate, non-hate Subtask B: individual target, group target Subtask C: aggressive, non-aggressive | [83] |
| 6 | Hate Speech and Offensive Content Identification in Indo-European Languages (HASOC) | 5335 for the English dataset of HASOC 20207005 for HASOC 2019 | Subtask A: hate and not offensive Subtask B: hate speech, offensive, and profanity | [19,38] |
| 7 | ElSherief et al. | 25,278 hate instigators 22,857 targets 27,330 tweets | Archaic, class, disability, ethnicity, gender, nationality, religion, sexual orientation | [131] |
| 8 | Founta et al. | 80,000 (Size Doesn’t Guarantee Diversity [137]) | Offensive, abusive, hateful speech, aggressive, cyberbullying, spam, normal | [84] |
| Ousidhoum et al. | 5647 instances | Hateful, abusive or neither Directness (‘‘direct/indirect’’), hostility (‘‘abusive/hateful/offensive/disrespectful/ fearful/normal’’), target (‘‘origin/gender/sexual orientation/religion/disability/ other’’), group (‘‘individual/woman/special needs/African descent/other’’) and the feeling aroused in the annotator by the tweet (‘‘disgust/shock/anger/sadness/ fear/confusion/indifference’’) | [81] | |
| 9 | MMHS150K | 150 K tweets | Not hate, religion, sexist, racist, homophobic, other hate | [52] |
| 10 | ConaN | 1288Pairs for English counter features. | Topics: crimes, culture, economics, generic, islamophobia, racism, terrorism, women | [156] |
| 11 | AbusEval | 18,740 | Offensive, targeted, not targeted, not offensive, explicitly abusive, implicitly abusive, not abusive | [103] |
| 12 | Amievalita | 4000 | misogynous, discredit, sexual harassment, stereotype, dominance, derailing | [36] |
| 13 | HateXplain | 20,148 | hate speech, offensive, normal the target community (i.e., the community that has been the victim of hate speech/offensive speech in the post), and the rationales, i.e., the portions of the post on which their labelling decision (as hate, offensive or normal) | [157] |
| 14 | Levantine Hate Speech and Abusive (L-HSAB) | 5846 | Hate, abusive, normal group or person target | [134] |
| 15 | News hate | 1528 (Fox News) | Hate, not hate | [158] |
| 16 | Sexism | 712 | Benevolent sexism, hostile sexism, none | [158] |
| 17 | Women | 3977 | misogyny/not, stereotype, dominance, derailing, sexual harassment, discredit of misogyny, (active or passive) target | [35] |
| 18 | Hate | 4972 | Binary hate or not | [159] |
| 19 | Harassment | 35,000 | Harassment, not | [89] |
| 20 | Hate Topics | 24,189 | Topics: racism, sexism, appearance-related, intellectual, political | [159] |
References
- Poletto, F.; Basile, V.; Sanguinetti, M.; Bosco, C.; Patti, V. Resources and benchmark corpora for hate speech detection: A systematic review. Lang. Resour. Eval. 2021, 55, 477–523. [Google Scholar] [CrossRef]
- Theodosiadou, O.; Pantelidou, K.; Bastas, N.; Chatzakou, D.; Tsikrika, T.; Vrochidis, S.; Kompatsiaris, I. Change point detection in terrorism-related online content using deep learning derived indicators. Information 2021, 12, 274. [Google Scholar] [CrossRef]
- Sánchez-Compaña, M.T.; Sánchez-Cruzado, C.; García-Ruiz, C.R. An interdisciplinary scientific and mathematic education, addressing relevant social problems such as sexist hate speech. Information 2020, 11, 543. [Google Scholar] [CrossRef]
- Mondal, M.; Silva, L.A.; Benevenuto, F. A measurement study of hate speech in social media. In Proceedings of the HT 2017—28th ACM Conference on Hypertext and Social Media, Prague, Czech Republic, 4–7 July 2017; pp. 85–94. [Google Scholar] [CrossRef]
- Sanoussi, M.S.A.; Xiaohua, C.; Agordzo, G.K.; Guindo, M.L.; al Omari, A.M.M.A.; Issa, B.M. Detection of Hate Speech Texts Using Machine Learning Algorithm. In Proceedings of the 2022 IEEE 12th Annual Computing and Communication Workshop and Conference (CCWC), Las Vegas, NV, USA, 26–29 January 2022; pp. 266–273. [Google Scholar] [CrossRef]
- Forestiero, A. Metaheuristic algorithm for anomaly detection in Internet of Things leveraging on a neural-driven multiagent system. Knowl. Based Syst. 2021, 228, 107241. [Google Scholar] [CrossRef]
- Ayo, F.E.; Folorunso, O.; Ibharalu, F.T.; Osinuga, I.A. Machine learning techniques for hate speech classification of twitter data: State-of-The-Art, future challenges and research directions. Comput. Sci. Rev. 2020, 38, 100311. [Google Scholar] [CrossRef]
- Strossen, N. Freedom of speech and equality: Do we have to choose. JL Pol’y 2016, 25, 185. [Google Scholar]
- Comito, C.; Forestiero, A.; Pizzuti, C. Word embedding based clustering to detect topics in social media. In Proceedings of the 2019 IEEE/WIC/ACM Int. Conf. Web Intell. WI 2019, Thessaloniki, Greece, 14–17 October 2019; pp. 192–199. [Google Scholar] [CrossRef]
- MacAvaney, S.; Yao, H.R.; Yang, E.; Russell, K.; Goharian, N.; Frieder, O. Hate speech detection: Challenges and solutions. PLoS ONE 2019, 14, e0221152. [Google Scholar] [CrossRef]
- Chetty, N.; Alathur, S. Hate speech review in the context of online social networks. Aggress. Violent Behav. 2018, 40, 108–118. [Google Scholar] [CrossRef]
- Paz, M.A.; Montero-Díaz, J.; Moreno-Delgado, A. Hate Speech: A Systematized Review. SAGE Open 2020, 10, 3022. [Google Scholar] [CrossRef]
- Matamoros-Fernández, A.; Farkas, J. Racism, Hate Speech, and Social Media: A Systematic Review and Critique. Telev. New Media 2021, 2, 205–224. [Google Scholar] [CrossRef]
- Fortuna, P.; Bonavita, I.; Nunes, S. Merging datasets for hate speech classification in Italian. CEUR Workshop Proc. 2018, 2263. [Google Scholar] [CrossRef] [Green Version]
- Tranfield, D.; Denyer, D.; Smart, P. Towards a Methodology for Developing Evidence-Informed Management Knowledge by Means of Systematic Review. Br. J. Manag. 2003, 14, 207–222. [Google Scholar] [CrossRef]
- Snyder, H. Literature review as a research methodology: An overview and guidelines. J. Bus. Res. 2019, 104, 333–339. [Google Scholar] [CrossRef]
- Guest, G.; MacQueen, K.M.; Namey, E.E. Applied Thematic Analysis; Sage Publications: Newbury Park, CA, USA, 2011. [Google Scholar]
- Zampieri, M.; Malmasi, S.; Nakov, P.; Rosenthal, S.; Farra, N.; Kumar, R. SemEval-2019 Task 6: Identifying and Categorizing Offensive Language in Social Media (OffensEval). In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 July 2019; pp. 75–86. [Google Scholar]
- Mandl, T.; Modha, S.; Kumar, A.; Chakravarthi, B.R. Overview of the HASOC track at FIRE 2020: Hate speech and offensive content identification in Indo-European languages. CEUR Workshop Proc. 2020, 2826, 87–111. [Google Scholar]
- Wadhwa, P.; Bhatia, M.P.S. Classification of Radical Messages on Twitter Using Security Associations. In Case Studies in Secure Computing: Achievements and Trends; Auerbach Publications: New York, NY, USA, 2014; pp. 273–294. [Google Scholar]
- Rangel, F.; Sarracén, G.L.D.L.P.; Chulvi, B.; Fersini, E.; Rosso, P. Profiling Hate Speech Spreaders on Twitter Task at PAN 2021. In Proceedings of the CLEF 2021–Conference and Labs of the Evaluation Forum, Bucharest, Romania, 21–24 September 2021. [Google Scholar]
- Saha, P.; Mathew, B.; Goyal, P.; Mukherjee, A. Hateminers: Detecting Hate speech against Women. arXiv 2018, arXiv:1812.06700. [Google Scholar]
- Cer, D.; Yang, Y.; Kong, S.Y.; Hua, N.; Limtiaco, N.; John, R.S.; Kurzweil, R. Universal Sentence Encoder. arXiv 2018, arXiv:1803.11175. [Google Scholar]
- De Andrade, C.M.V.; Gonçalves, M.A. Profiling Hate Speech Spreaders on Twitter: Exploiting textual analysis of tweets and combinations of multiple textual representations. CEUR Workshop Proc. 2021, 2936, 2186–2192. [Google Scholar]
- Davidson, T.; Warmsley, D.; Macy, M.; Weber, I. Automated hate speech detection and the problem of offensive language. In Proceedings of the 11th International Conference on Web and Social Media, ICWSM 2017, Quebec, MO, Canada, 15–18 May 2017; pp. 512–515. [Google Scholar]
- Watanabe, H.; Bouazizi, M.; Ohtsuki, T. Hate Speech on Twitter: A Pragmatic Approach to Collect Hateful and Offensive Expressions and Perform Hate Speech Detection. IEEE Access 2018, 6, 13825–13835. [Google Scholar] [CrossRef]
- Waseem, Z. Are You a Racist or Am I Seeing Things? Annotator Influence on Hate Speech Detection on Twitter. In Proceedings of the First Workshop on NLP and Computational Social Science, Austin, TX, USA, 5 November 2016. [Google Scholar]
- Waseem, Z.; Hovy, D. Hateful Symbols or Hateful People? Predictive Features for Hate Speech Detection on Twitter. In Proceedings of the NAACL Student Research Workshop, San Diego, CA, USA, 16–17 June 2016; pp. 88–93. [Google Scholar] [CrossRef]
- Aziz, N.A.A.; Maarof, M.A.; Zainal, A. Hate Speech and Offensive Language Detection: A New Feature Set with Filter-Embedded Combining Feature Selection. In Proceedings of the 2021 3rd International Cyber Resilience Conference CRC 2021, online, 29–31 January 2021. [Google Scholar] [CrossRef]
- Burnap, P.; Williams, M.L. Us and them: Identifying cyber hate on Twitter across multiple protected characteristics. EPJ Data Sci. 2016, 5, 1–15. [Google Scholar] [CrossRef] [Green Version]
- Ombui, E.; Muchemi, L.; Wagacha, P. Hate Speech Detection in Code-switched Text Messages. In Proceedings of the 3rd International Symposium on Multidisciplinary Studies and Innovative Technologies ISMSIT 2019, Ankara, Turkey, 11–13 October 2019; pp. 1–6. [Google Scholar] [CrossRef]
- Nobata, C.; Tetreault, J.; Thomas, A.; Mehdad, Y.; Chang, Y. Abusive language detection in online user content. In Proceedings of the 25th International Conference on World Wide Web WWW 2016, Montreal, Canada, 11–15 May 2016; pp. 145–153. [Google Scholar] [CrossRef] [Green Version]
- Martins, R.; Gomes, M.; Almeida, J.J.; Novais, P.; Henriques, P. Hate speech classification in social media using emotional analysis. In Proceedings of the 2018 Brazilian Conference on Intelligent Systems BRACIS 2018, Sao Paolo, Brazil, 22–25 October 2018; pp. 61–66. [Google Scholar] [CrossRef]
- Frenda, S.; Ghanem, B.; Montes-Y-Gómez, M.; Rosso, P. Online hate speech against women: Automatic identification of misogyny and sexism on twitter. J. Intell. Fuzzy Syst. 2019, 36, 4743–4752. [Google Scholar] [CrossRef]
- Fersini, E.; Rosso, P.; Anzovino, M. Overview of the Task on Automatic Misogyny Identification at IberEval 2018. IberEval@ SEPLN 2018, 2150, 214–228. [Google Scholar]
- Fersini, E.; Nozza, D.; Rosso, P. Overview of the evalita 2018 task on automatic misogyny identification (ami). EVALITA Eval. NLP Speech Tools Ital. 2018, 12, 59. [Google Scholar]
- Srivastava, N.D.; Sharma, Y. Combating Online Hate: A Comparative Study on Identification of Hate Speech and Offensive Content in Social Media Text. In Proceedings of the 2020 IEEE Recent Advances in Intelligent Computational Systems RAICS 2020, Thiruvananthapuram, India, 3–5 December 2020; pp. 47–52. [Google Scholar] [CrossRef]
- Mandl, T.; Modha, S.; Majumder, P.; Patel, D.; Dave, M.; Mandlia, C.; Patel, A. Overview of the HASOC track at FIRE 2019: Hate speech and offensive content identification in Indo-European languages. In Proceedings of the FIRE ’19: Proceedings of the 11th Forum for Information Retrieval Evaluation, Kolkata, India, 12–15 December 2019; Volume 2826, pp. 87–111. [Google Scholar]
- Warner, W.; Hirschberg, J. Detecting Hate Speech on the World Wide Web. Available online: http://dl.acm.org/citation.cfm?id=2390374.2390377 (accessed on 23 May 2022).
- Vidgen, B.; Yasseri, T. Detecting weak and strong Islamophobic hate speech on social media. J. Inf. Technol. Polit. 2020, 17, 66–78. [Google Scholar] [CrossRef] [Green Version]
- Capozzi, A.T.E.; Lai, M.; Basile, V.; Poletto, F.; Sanguinetti, M.; Bosco, C.; Patti, V.; Ruffo, G.F.; Stranisci, M.A. Computational linguistics against hate: Hate speech detection and visualization on social media in the ‘Contro L’Odio’ project. CEUR Workshop Proc. 2019, 2481, 1–6. [Google Scholar]
- Sanguinetti, M.; Poletto, F.; Bosco, C.; Patti, V.; Stranisci, M. An italian twitter corpus of hate speech against immigrants. In Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018), Miyazaki, Japan, 7–12 May 2018; pp. 2798–2805. [Google Scholar]
- Basile, V. Semeval-2019 task 5: Multilingual detection of hate speech against immigrants and women in twitter. In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2019; pp. 54–63. [Google Scholar]
- Vega, L.E.A.; Reyes-Magaña, J.C.; Gómez-Adorno, H.; Bel-Enguix, G. MineriaUNAM at SemEval-2019 Task 5: Detecting Hate Speech in Twitter using Multiple Features in a Combinatorial Framework. In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2019; pp. 447–452. [Google Scholar] [CrossRef]
- Tellez, E.S.; Moctezuma, D.; Miranda-Jimnez, S.; Graff, M. An Automated Text Categorization Framework Based on Hyperparameter Optimization. Know. Based Syst. 2018, 149, 110–123. [Google Scholar] [CrossRef] [Green Version]
- Bauwelinck, N.; Jacobs, G.; Hoste, V.; Lefever, E. LT3 at SemEval-2019 Task 5: Multilingual Detection of Hate Speech Against Immigrants and Women in Twitter (hatEval). In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2019; pp. 436–440. [Google Scholar] [CrossRef]
- Perelló, C.; Tomás, D.; Garcia-Garcia, A.; Garcia-Rodriguez, J.; Camacho-Collados, J. UA at SemEval-2019 Task 5: Setting A Strong Linear Baseline for Hate Speech Detection. In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2019; pp. 508–513. [Google Scholar] [CrossRef]
- I Orts, Ò.G. Multilingual detection of hate speech against immigrants and women in Twitter at SemEval-2019 task 5: Frequency analysis interpolation for hate in speech detection. In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2019; pp. 460–463. [Google Scholar]
- Ribeiro, A.; Silva, N. INF-HatEval at SemEval-2019 Task 5: Convolutional Neural Networks for Hate Speech Detection Against Women and Immigrants on Twitter. In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2019; pp. 420–425. [Google Scholar] [CrossRef]
- Indurthi, V.; Syed, B.; Shrivastava, M.; Chakravartula, N.; Gupta, M.; Varma, V. FERMI at SemEval-2019 Task 5: Using Sentence embeddings to Identify Hate Speech Against Immigrants and Women in Twitter. In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2019; pp. 70–74. [Google Scholar] [CrossRef]
- Chakrabarty, N. A Machine Learning Approach to Comment Toxicity Classification; Springer: Singapore, 2020; Volume 999. [Google Scholar] [CrossRef] [Green Version]
- Gomez, R.; Gibert, J.; Gomez, L.; Karatzas, D. Exploring hate speech detection in multimodal publications. In Proceedings of the 2020 IEEE Winter Conference on Applications on Computer Vision (WACV), Snowmass, CO, USA, 1–5 March 2020; pp. 1459–1467. [Google Scholar] [CrossRef]
- Siino, M.; di Nuovo, E.; Tinnirello, I.; la Cascia, M. Detection of Hate Speech Spreaders using convolutional neural networks. CEUR Workshop Proc. 2021, 2936, 2126–2136. [Google Scholar]
- Balouchzahi, F.; Shashirekha, H.L.; Sidorov, G. HSSD: Hate speech spreader detection using N-Grams and voting classifier. CEUR Workshop Proc. 2021, 2936, 1829–1836. [Google Scholar]
- Winter, K.; Kern, R. Know-Center at SemEval-2019 Task 5: Multilingual Hate Speech Detection on Twitter using CNNs. In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2019; pp. 431–435. [Google Scholar] [CrossRef]
- Kamble, S.; Joshi, A. Hate Speech Detection from Code-mixed Hindi-English Tweets Using Deep Learning Models. arXiv 2018, arXiv:1811.05145. [Google Scholar]
- Djuric, N.; Zhou, J.; Morris, R.; Grbovic, M.; Radosavljevic, V.; Bhamidipati, N. Hate speech detection with comment embeddings. In Proceedings of the 24th International Conference on World Wide Web, Florence, Italy, 18–22 May 2015; pp. 29–30. [Google Scholar]
- Rozental, A.; Biton, D. Amobee at SemEval-2019 Tasks 5 and 6: Multiple Choice CNN Over Contextual Embedding. In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2019; pp. 377–381. [Google Scholar] [CrossRef]
- Khan, M.U.S.; Abbas, A.; Rehman, A.; Nawaz, R. HateClassify: A Service Framework for Hate Speech Identification on Social Media. IEEE Internet Comput. 2021, 25, 40–49. [Google Scholar] [CrossRef]
- Yin, W.; Schütze, H. Attentive convolution: Equipping cnns with rnn-style attention mechanisms. Trans. Assoc. Comput. Linguist. 2018, 6, 687–702. [Google Scholar] [CrossRef] [Green Version]
- Fortuna, P.; Soler-Company, J.; Wanner, L. Toxic, hateful, offensive or abusive? What are we really classifying? An empirical analysis of hate speech datasets. In Proceedings of the 12th Language Resources and Evaluation Conference, Marseille, France, 24 May 2020; pp. 6786–6794. [Google Scholar]
- Margffoy-Tuay, E.; Pérez, J.C.; Botero, E.; Arbeláez, P. Dynamic multimodal instance segmentation guided by natural language queries. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–16 September 2018; pp. 630–645. [Google Scholar]
- Suryawanshi, S.; Chakravarthi, B.R.; Arcan, M.; Buitelaar, P. Multimodal Meme Dataset (MultiOFF) for Identifying Offensive Content in Image and Text. In Proceedings of the Second Workshop on Trolling, Aggression and Cyberbullying, Marseille, France, 16 May 2020; Available online: https://www.aclweb.org/anthology/2020.trac-1.6 (accessed on 2 April 2022).
- Kiela, D.; Firooz, H.; Mohan, A.; Goswami, V.; Singh, A.; Fitzpatrick, C.A.; Bull, P.; Lipstein, G.; Nelli, T.; Zhu, R.; et al. The Hateful Memes Challenge: Competition Report. Proc. Mach. Learn. Res. 2021, 133, 344–360. [Google Scholar]
- Vashistha, N.; Zubiaga, A. Online multilingual hate speech detection: Experimenting with hindi and english social media. Information 2021, 12, 5. [Google Scholar] [CrossRef]
- Park, J.H.; Fung, P. One-step and Two-step Classification for Abusive Language Detection on Twitter. arXiv 2017, arXiv:1706.01206. [Google Scholar]
- Zimmerman, S.; Fox, C.; Kruschwitz, U. Improving hate speech detection with deep learning ensembles. In Proceedings of the 11th International Conference on Language Resources and Evaluation, Marseille, France, 11–16 May 2020; pp. 2546–2553. [Google Scholar]
- Poursepanj, H.; Weissbock, J.; Inkpen, D. Uottawa: System description for semeval 2013 task 2 sentiment analysis in twitter. In Proceedings of the Seventh International Workshop on Semantic Evaluation (SemEval 2013), Atlanta, GA, USA, 14–15 June 2013; pp. 380–383. [Google Scholar]
- Gambäck, B.; Sikdar, U.K. Using Convolutional Neural Networks to Classify Hate-Speech. In Proceedings of the first workshop on abusive language online, Vancouver, BC, Canada, 4 August 2017; 7491, pp. 85–90. [Google Scholar] [CrossRef] [Green Version]
- Qian, J.; ElSherief, M.; Belding, E.; Wang, W.Y. Hierarchical CVAE for fine-grained hate speech classification. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 3550–3559. [Google Scholar] [CrossRef] [Green Version]
- Agarwal, S.; Chowdary, C.R. Combating hate speech using an adaptive ensemble learning model with a case study on COVID-19. Expert Syst. Appl. 2021, 185, 115632. [Google Scholar] [CrossRef]
- Ziems, C.; He, B.; Soni, S.; Kumar, S. Racism is a Virus: Anti-Asian Hate and Counterhate in Social Media during the COVID-19 Crisis. arXiv 2020, arXiv:2005.12423. Available online: https://europepmc.org/article/PPR/PPR268779 (accessed on 2 April 2022).
- Agarwal, S.; Chowdary, C.R. A-Stacking and A-Bagging: Adaptive versions of ensemble learning algorithms for spoof fingerprint detection. Expert Syst. Appl. 2020, 146, 3160. [Google Scholar] [CrossRef]
- Mehdad, Y.; Tetreault, J. Do Characters Abuse More Than Words? In Proceedings of the 17th Annual Meeting of the Special Interest Group on Discourse and Dialogue, Los Angeles, CA, USA, 13–15 September 2016; pp. 299–303. [Google Scholar] [CrossRef]
- Malmasi, S.; Zampieri, M. Challenges in discriminating profanity from hate speech. J. Exp. Theor. Artif. Intell. 2018, 30, 187–202. [Google Scholar] [CrossRef] [Green Version]
- Doostmohammadi, E.; Sameti, H.; Saffar, A. Ghmerti at SemEval-2019 Task 6: A Deep Word- and Character-based Approach to Offensive Language Identification. arXiv 2019, arXiv:2009.10792. [Google Scholar]
- Garain, A.; Basu, A. The Titans at SemEval-2019 Task 6: Offensive Language Identification, Categorization and Target Identification. 2019, 759–762. In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2019; pp. 759–762. [Google Scholar] [CrossRef]
- Mishra, A.K.; Saumya, S.; Kumar, A. IIIT_DWD@HASOC 2020: Identifying offensive content in Indo-European languages. CEUR Workshop Proc. 2020, 2826, 139–144. [Google Scholar]
- Mohtaj, S.; Woloszyn, V.; Möller, S. TUB at HASOC 2020: Character based LSTM for hate speech detection in Indo-European languages. CEUR Workshop Proc. 2020, 2826, 298–303. [Google Scholar]
- Modha, S.; Majumder, P.; Patel, D. DA-LD-Hildesheim at SemEval-2019 Task 6: Tracking Offensive Content with Deep Learning using Shallow Representation. In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2019; pp. 577–581. [Google Scholar] [CrossRef]
- Ousidhoum, N.; Lin, Z.; Zhang, H.; Song, Y.; Yeung, D.Y. Multilingual and multi-aspect hate speech analysis. In Proceedings of the 9th International Joint Conference on Natural Language Processing Conference, Hong Kong, China, 3–7 November 2019; pp. 4675–4684. [Google Scholar] [CrossRef]
- Wullach, T.; Adler, A.; Minkov, E. Towards Hate Speech Detection at Large via Deep Generative Modeling. IEEE Internet Comput. 2021, 25, 48–57. [Google Scholar] [CrossRef]
- Yang, X.; Obadinma, S.; Zhao, H.; Zhang, Q.; Matwin, S.; Zhu, X. SemEval-2020 Task 5: Counterfactual Recognition. In Proceedings of the Fourteenth Workshop on Semantic Evaluation, Barcelona, Spain, 12–13 December 2020; pp. 322–335. [Google Scholar]
- Founta, A.M. Large scale crowdsourcing and characterization of twitter abusive behavior. In Proceedings of the 12th International AAI Conference on Web and Social Media, ICWSM 2018, Palo Alto, CA, USA, 25–28 June 2018; pp. 491–500. [Google Scholar]
- De Gibert, O.; Perez, N.; García-Pablos, A.; Cuadros, M. Hate Speech Dataset from a White Supremacy Forum. In Proceedings of the 2nd Workshop on Abusive Language Online (ALW2), Brussels, Belgium, 31 October–4 November 2019; pp. 11–20. [Google Scholar] [CrossRef] [Green Version]
- Radford, I.S.A.; Wu, J.; Child, R.; Luan, D.; Amodei, D. [GPT-2] Language Models are Unsupervised Multitask Learners. OpenAI Blog 2020, 1, 9. Available online: https://github.com/codelucas/newspaper (accessed on 3 April 2022).
- Ziqi, Z.; Robinson, D.; Jonathan, T. Hate Speech Detection Using a Convolution-LSTM Based Deep Neural Network. IJCCS 2019, 11816, 2546–2553. [Google Scholar] [CrossRef]
- Naseem, U.; Razzak, I.; Hameed, I.A. Deep Context-Aware Embedding for Abusive and Hate Speech detection on Twitter. J. Chem. Inf. Model. 2019, 53, 1689–1699. [Google Scholar]
- Golbeck, J. A large human-labeled corpus for online harassment research. In Proceedings of the 2017 ACM Web Science Conference, Troy, NY, USA, 25–28 June 2017; pp. 229–233. [Google Scholar] [CrossRef] [Green Version]
- Founta, A.M.; Chatzakou, D.; Kourtellis, N.; Blackburn, J.; Vakali, A.; Leontiadis, I. A unified deep learning architecture for abuse detection. In Proceedings of the 10th ACM Conference on Web Science, Boston, MA, USA, 30 June–3 July 2019; pp. 105–114. [Google Scholar] [CrossRef] [Green Version]
- Chatzakou, D.; Kourtellis, N.; Blackburn, J.; de Cristofaro, E.; Stringhini, G.; Vakali, A. Mean birds: Detecting aggression and bullying on Twitter. In Proceedings of the 2017 ACM Web Science Conference, Troy, NY, USA, 25–28 June 2017; pp. 13–22. [Google Scholar] [CrossRef] [Green Version]
- Rajadesingan, A.; Zafarani, R.; Liu, H. Sarcasm detection on twitter: A behavioral modeling approach. In Proceedings of the Eigth ACM International Conference on Web Search and Data Mining, Shanghai, China, 2–6 February 2015; pp. 97–106. [Google Scholar] [CrossRef]
- Menini, S.; Moretti, G.; Corazza, M.; Cabrio, E.; Tonelli, S.; Villata, S. A System to Monitor Cyberbullying based on Message Classification and Social Network Analysis. In Proceedings of the Third Workshop on Abusive Language Online, Florence, Italy, 1 August 2019; pp. 105–110. [Google Scholar] [CrossRef]
- Corazza, M.; Menini, S.; Cabrio, E.; Tonelli, S.; Villata, S. A Multilingual Evaluation for Online Hate Speech Detection. ACM Trans. Internet Technol. 2020, 20. [Google Scholar] [CrossRef] [Green Version]
- Zhu, R. Enhance Multimodal Transformer with External Label and In-Domain Pretrain: Hateful Meme Challenge Winning Solution. arXiv 2020, arXiv:2012.0829. [Google Scholar]
- Su, W.; Zhu, X.; Cao, Y.; Li, B.; Lu, L.; Wei, F.; Dai, J. Vl-bert: Pre-training of generic visual-linguistic representations. arXiv 2019, arXiv:1908.08530. [Google Scholar]
- Yu, F.; Tang, J.; Yin, W.; Sun, Y.; Tian, H.; Wu, H.; Wang, H. Ernie-vil: Knowledge enhanced vision-language representations through scene graph. arXiv 2020, arXiv:2006.16934. [Google Scholar]
- Kiela, D.; Firooz, H.; Mohan, A.; Goswami, V.; Singh, A.; Ringshia, P.; Testuggine, D. The Hateful Memes Challenge: Detecting Hate Speech in Multimodal Memes. Adv. Neural Inf. Process. Syst. 2020, 33, 2611–2624. [Google Scholar]
- Lee, R.K.-W.; Cao, R.; Fan, Z.; Jiang, J.; Chong, W.-H. Disentangling Hate in Online Memes; Association for Computing Machinery: New York, NY, USA, 2021; Volume 1. [Google Scholar] [CrossRef]
- Liu, P.; Li, W.; Zou, L. NULI at SemEval-2019 task 6: Transfer learning for offensive language detection using bidirectional transformers. In Proceedings of the NAACL HLT 2019—International Workshop on Semantic Evaluation, SemEval 2019, Proceedings of the 13th Workshop, Minneapolis, MN, USA, 6–7 June 2019; pp. 87–91. [Google Scholar] [CrossRef] [Green Version]
- Zampieri, M.; Malmasi, S.; Nakov, P.; Rosenthal, S.; Farra, N.; Kumar, R. Predicting the type and target of offensive posts in social media. In Proceedings of the NAACL HLT 2019—2019 Annual Conference of the North American Chapter of the Association for Computational Linguistics, Minneapolis, MN, USA, 2–7 June 2019; Volume 1, pp. 1415–1420. [Google Scholar] [CrossRef] [Green Version]
- Caselli, T.; Basile, V.; Mitrović, J.; Granitzer, M. HateBERT: Retraining BERT for Abusive Language Detection in English. arXiv 2021, arXiv:2010.12472. [Google Scholar]
- Caselli, T.; Basile, V.; Mitrovic, J.; Kartoziya, I.; Granitzer, M. I feel offended, don’t be abusive! implicit/explicit messages in offensive and abusive language. In Proceedings of the 12th Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020; pp. 6193–6202. [Google Scholar]
- Nguyen, D.Q.; Vu, T.; Nguyen, A.T. BERTweet: A pre-trained language model for English Tweets. arXiv 2020, arXiv:2005.10200. [Google Scholar]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Conneau, A.; Baevski, A.; Collobert, R.; Mohamed, A.; Auli, M. Unsupervised Cross-lingual Representation Learning at Scale. arXiv 2020, arXiv:2006.13979. [Google Scholar]
- Jahan, M.S.; Oussalah, M. A systematic review of Hate Speech automatic detection using Natural Language Processing. arXiv 2021, arXiv:2106.00742. [Google Scholar]
- Pitsilis, G.K.; Ramampiaro, H.; Langseth, H. Effective hate-speech detection in Twitter data using recurrent neural networks. Appl. Intell. 2018, 48, 4730–4742. [Google Scholar] [CrossRef] [Green Version]
- Badjatiya, P.; Gupta, S.; Gupta, M.; Varma, V. Deep Learning for Hate Speech Detection in Tweets. In Proceedings of the 26th International Conference on World Wide Web Companion, Perth, Australia, 3–7 April 2017; Volume 2, pp. 759–760. [Google Scholar] [CrossRef] [Green Version]
- Paschalides, D.; Stephanidis, D.; Andreou, A.; Orphanou, K.; Pallis, G.; Dikaiakos, M.D.; Markatos, E. MANDOLA: A big-data processing and visualization platform for monitoring and detecting online hate speech. ACM Trans. Internet Technol. 2020, 20, 1–21. [Google Scholar] [CrossRef] [Green Version]
- Masud, S.; Duuta, S.; Makkar, S.; Jain, C.; Goyal, V.; Das, A.; Chakraborty, T. Hate is the new infodemic: A topic-aware modeling of hate speech diffusion on twitter. Proc. Int. Conf. Data Eng. 2021, 2021, 504–515. [Google Scholar] [CrossRef]
- Kumar, A.; Abirami, S.; Trueman, T.E.; Cambria, E. Comment toxicity detection via a multichannel convolutional bidirectional gated recurrent unit. Neurocomputing 2021, 441, 272–278. [Google Scholar] [CrossRef]
- Wang, B.; Ding, H. YNU NLP at SemEval-2019 task 5: Attention and capsule ensemble for identifying hate speech. In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2019; pp. 529–534. [Google Scholar] [CrossRef]
- Wiedemann, G.; Ruppert, E.; Biemann, C. UHH-LT at SemEval-2019 Task 6: Supervised vs. Unsupervised Transfer Learning for Offensive Language Detection. In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2019; pp. 782–787. [Google Scholar] [CrossRef]
- Setyadi, N.A.; Nasrun, M.; Setianingsih, C. Text Analysis for Hate Speech Detection Using Backpropagation Neural Network. In Proceedings of the 2018 International Conference on Control, Electronics, Renewable Energy and Communications (ICCEREC), Bandung, Indonesia, 5–7 December 2018; pp. 159–165. [Google Scholar] [CrossRef]
- Bouazizi, M.; Otsuki, T. A Pattern-Based Approach for Sarcasm Detection on Twitter. IEEE Access 2016, 4, 5477–5488. [Google Scholar] [CrossRef]
- Qureshi, K.A.; Sabih, M. Un-Compromised Credibility: Social Media Based Multi-Class Hate Speech Classification for Text. IEEE Access 2021, 9, 109465–109477. [Google Scholar] [CrossRef]
- Kshirsagar, R.; Cukuvac, T.; McKeown, K.; McGregor, S. Predictive Embeddings for Hate Speech Detection on Twitter. arXiv 2019, arXiv:1809.10644. [Google Scholar]
- Shen, D.; Shen, D.; Wang, G.; Wang, W.; Min, M.R.; Su, Q.; Zhang, Y.; Henao, R.; Carin, L. On the use of word embeddings alone to represent natural language sequences. In Proceedings of the 6th International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Faris, H.; Aljarah, I.; Habib, M.; Castillo, P.A. Hate speech detection using word embedding and deep learning in the Arabic language context. In Proceedings of the ICPRAM 2020—9th International Conference on Pattern Recognition Applications and Methods, Valletta, Malta, 22–24 February 2020; pp. 453–460. [Google Scholar] [CrossRef]
- Siddiqua, U.A.; Chy, A.N.; Aono, M. KDEHatEval at SemEval-2019 Task 5: A Neural Network Model for Detecting Hate Speech in Twitter. roceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2019; pp. 365–370. [Google Scholar] [CrossRef]
- Miok, K.; Nguyen-Doan, D.; Škrlj, B.; Zaharie, D.; Robnik-Šikonja, M. Prediction Uncertainty Estimation for Hate Speech Classification. Lect. Notes Comput. Sci. 2019, 11816, 286–298. [Google Scholar] [CrossRef] [Green Version]
- Sachdeva, J.; Chaudhary, K.K.; Madaan, H.; Meel, P. Text Based Hate-Speech Analysis. In Proceedings of the International Conference on Artificial Intelligence and Smart Systems, ICAIS, Tamilnadu, India, 25–27 March 2021; pp. 661–668. [Google Scholar] [CrossRef]
- Sajjad, M.; Zulifqar, F.; Khan, M.U.G.; Azeem, M. Hate Speech Detection using Fusion Approach. In Proceedings of the 2019 International Conference on Applied and Engineering Mathematics, Taxila, Pakistan, 27–29 August 2019; pp. 251–255. [Google Scholar] [CrossRef]
- Liu, H.; Alorainy, W.; Burnap, P.; Williams, M.L. Fuzzy multi-task learning for hate speech type identification. In Proceedings of the Web Conf. 2019—Proc. World Wide Web Conference, New York, UK, USA, 13–17 May 2019; pp. 3006–3012. [Google Scholar] [CrossRef]
- Berthold, M.R. Mixed fuzzy rule formation. Int. J. Approx. Reason. 2003, 32, 67–84. [Google Scholar] [CrossRef] [Green Version]
- Mulki, H.; Ali, C.B.; Haddad, H.; Babaoğlu, I. Tw-StAR at SemEval-2019 task 5: N-gram embeddings for hate speech detection in multilingual tweets. In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2019; pp. 503–507. [Google Scholar] [CrossRef]
- Yang, Z.; Yang, D.; Dyer1, C.; He, X.; Smola, A.; Hovy, E. Hierarchical attention networks for document classification. In Proceedings of the 2016 Conference of the North American chapter of the association for computational linguistics: Human language technologies, San Diego, CA, USA, 12–17 June 2016; pp. 1480–1489. [Google Scholar]
- Kocoń, J.; Figas, A.; Gruza, M.; Puchalska, D.; Kajdanowicz, T.; Kazienko, P. Offensive, aggressive, and hate speech analysis: From data-centric to human-centered approach. Inf. Process. Manag. 2021, 58, 102643. [Google Scholar] [CrossRef]
- Wiegand, M.; Ruppenhofer, J.; Eder, E. Implicitly Abusive Language—What does it actually look like and why are we not getting there? In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 576–587. [Google Scholar] [CrossRef]
- ElSherief, M.; Nilizadeh, S.; Nguyen, D.; Vigna, G.; Belding, E. Peer to peer hate: Hate speech instigators and their targets. In Proceedings of the 12th International AAAI Conference on Web and Social Media, ICWSM 2018, Pao Alto, CA, USA, 25–28 June 2018; pp. 52–61. [Google Scholar]
- Guest, E.; Vidgen, B.; Mittos, A.; Sastry, N.; Tyson, G.; Margetts, H. An expert annotated dataset for the detection of online misogyny. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics, Kvyv, Ukraine, 21–23 April 2021; pp. 1336–1350. [Google Scholar] [CrossRef]
- Qian, J.; Bethke, A.; Liu, Y.; Belding, E.; Wang, W.Y. A benchmark dataset for learning to intervene in online hate speech. In Proceedings of the EMNLP-IJCNLP 2019—2019 Conference on Empirical Methods in Natural Language Processing and 9th International Joint Conference on Natural Language Processing, Hong Kong, China, 3–7 November 2020; pp. 4755–4764. [Google Scholar] [CrossRef]
- Mulki, H.; Haddad, H.; Ali, C.B.; Alshabani, H. L-HSAB: A Levantine Twitter Dataset for Hate Speech and Abusive Language. In Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics, Kvyv, Ukraine, 19–23 April 2019; pp. 1336–1350. [Google Scholar] [CrossRef] [Green Version]
- Culpeper, J. Impoliteness and hate speech: Compare and contrast. J. Pragmat. 2021, 179, 4–11. [Google Scholar] [CrossRef]
- Waseem, Z.; Davidson, T.; Warmsley, D.; Weber, I. Understanding abuse: A typology of abusive language detection subtasks. arXiv 2017, arXiv:1705.09899. [Google Scholar]
- Bender, E.M.; Gebru, T.; McMillan-Major, A.; Shmitchell, S. On the Dangers of Stochastic Parrots: Can Language Models Be Too Big? Association for Computing Machinery: New York, NY, USA, 2021; Volume 1. [Google Scholar] [CrossRef]
- Plaza-del-Arco, F.M.; Molina-González, M.D.; Martin, M.; Ureña-López, L.A. SINAI at SemEval-2019 Task 5: Ensemble learning to detect hate speech against inmigrants and women in English and Spanish tweets. In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2019; pp. 476–479. [Google Scholar] [CrossRef]
- Mitrović, J.; Birkeneder, B.; Granitzer, M. nlpUP at SemEval-2019 Task 6: A Deep Neural Language Model for Offensive Language Detection. In Proceedings of the 13th International Workshop on Semantic Evaluation, Minneapolis, MN, USA, 6–7 June 2019; pp. 722–726. [Google Scholar] [CrossRef]
- Zhang, Z.; Luo, L. Hate speech detection: A solved problem? The challenging case of long tail on Twitter. Semant. Web 2019, 10, 925–945. [Google Scholar] [CrossRef] [Green Version]
- Dahiya, S. Would Your Tweet Invoke Hate on the Fly? Forecasting Hate Intensity of Reply Threads on Twitter. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Singapore, 14–18 August 2021; Volume 1, pp. 2732–2742. [Google Scholar] [CrossRef]
- Kapil, P.; Ekbal, A. A deep neural network based multi-task learning approach to hate speech detection. Knowl. Based Syst. 2020, 210, 106458. [Google Scholar] [CrossRef]
- Anand, M.; Eswari, R. Classification of abusive comments in social media using deep learning. In Proceedings of the Third International Conference on Computing Methodologies and Communication (ICCMC 2019), Erode, India, 27–29 March 2019; pp. 974–977. [Google Scholar] [CrossRef]
- Tontodimamma, A.; Nissi, E.; Sarra, A.; Fontanella, L. Thirty years of research into hate speech: Topics of interest and their evolution. Scientometrics 2021, 126, 157–179. [Google Scholar] [CrossRef]
- Nugroho, K. Improving random forest method to detect hatespeech and offensive word. In Proceedings of the 2019 International Conference on Information and Communications Technology, Baku, Azerbaijan, 23–25 October 2019; pp. 514–518. [Google Scholar] [CrossRef]
- Lingiardi, V.; Carone, N.; Semeraro, G.; Musto, C.; D’Amico, M.; Brena, S. Mapping Twitter hate speech towards social and sexual minorities: A lexicon-based approach to semantic content analysis. Behav. Inf. Technol. 2020, 39, 711–721. [Google Scholar] [CrossRef]
- Shibly, F.H.A.; Sharma, U.; Naleer, H.M.M. Classifying and Measuring Hate Speech in Twitter Using Topic Classifier of Sentiment Analysis; Springer: Singapore, 2021; Volume 1165. [Google Scholar] [CrossRef]
- ElSherief, M.; Kulkarni, V.; Nguyen, D.; Wang, W.Y.; Belding, E. Hate lingo: A target-based linguistic analysis of hate speech in social media. In Proceedings of the International AAAI Conference on Web and Social Media, ICWSM 2018, Pao Alto, CA, USA, 25–28 June 2018; pp. 42–51. [Google Scholar]
- Abburi, H.; Sehgal, S.; Maheshwari, H. Knowledge-Based Neural Framework for Sexism Detection and Classification; IIIT: Hyderabad, India, 2021. [Google Scholar]
- Fino, A. Defining Hate Speech. J. Int. Crim. Justice 2020, 18, 31–57. [Google Scholar] [CrossRef]
- Ullmann, S.; Tomalin, M. Quarantining online hate speech: Technical and ethical perspectives. Ethics Inf. Technol. 2020, 22, 69–80. [Google Scholar] [CrossRef] [Green Version]
- Mosca, E.; Wich, M.; Groh, G. Understanding and Interpreting the Impact of User Context in Hate Speech Detection. In Proceedings of the Ninth International Workshop on Natural Language Processing for Social Media, Online, 10 June 2021; pp. 91–102. [Google Scholar] [CrossRef]
- Alizadeh, M.; Weber, I.; Cioffi-Revilla, C.; Fortunato, S.; Macy, M. Psychology and morality of political extremists: Evidence from Twitter language analysis of alt-right and Antifa. EPJ Data Sci. 2019, 8, 9. [Google Scholar] [CrossRef]
- Zampieri, M.; Malmasi, S.; Nakov, P.; Rosenthal, S.; Farra, N.; Kumar, R. Semeval-2019 task 6: Identifying and categorizing offensive language in social media (offenseval). arXiv 2019, arXiv:1903.08983. [Google Scholar]
- Yang, B.; Tang, H.; Hao, L.; Rose, J.R. Untangling chaos in discussion forums: A temporal analysis of topic-relevant forum posts in MOOCs. Comput. Educ. 2022, 178, 104402. [Google Scholar] [CrossRef]
- Chung, Y.L.; Kuzmenko, E.; Tekiroglu, S.S.; Guarini, M. ConaN—Counter narratives through nichesourcing: A multilingual dataset of responses to fight online hate speech. In Proceedings of Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, Florence, Italy, 28 June–2 August 2019; pp. 2819–2829. [Google Scholar]
- Mathew, B.; Saha, P.; Yimam, S.M.; Biemann, C.; Goyal, P.; Mukherjee, A. HateXplain: A Benchmark Dataset for Explainable Hate Speech Detection. Proc. AAAI Conf. Artif. Intell. 2021, 35, 14867–14875. [Google Scholar]
- Gao, L.; Huang, R. Detecting Online Hate Speech Using Context Aware Models. In Proceedings of the International Conference Recent Advances in Natural Language Processing, {RANLP} 2017, Varna, Bulgaria, 2–8 September 2017; pp. 260–266. [Google Scholar] [CrossRef]
- Ribeiro, M.H.; Calais, P.H.; Santos, Y.A.; Almeida, V.A.F.; Meira, W. Characterizing and detecting hateful users on twitter. Twelfth Int. AAAI Conf. Web Soc. Media 2018, 12, 676–679. [Google Scholar]





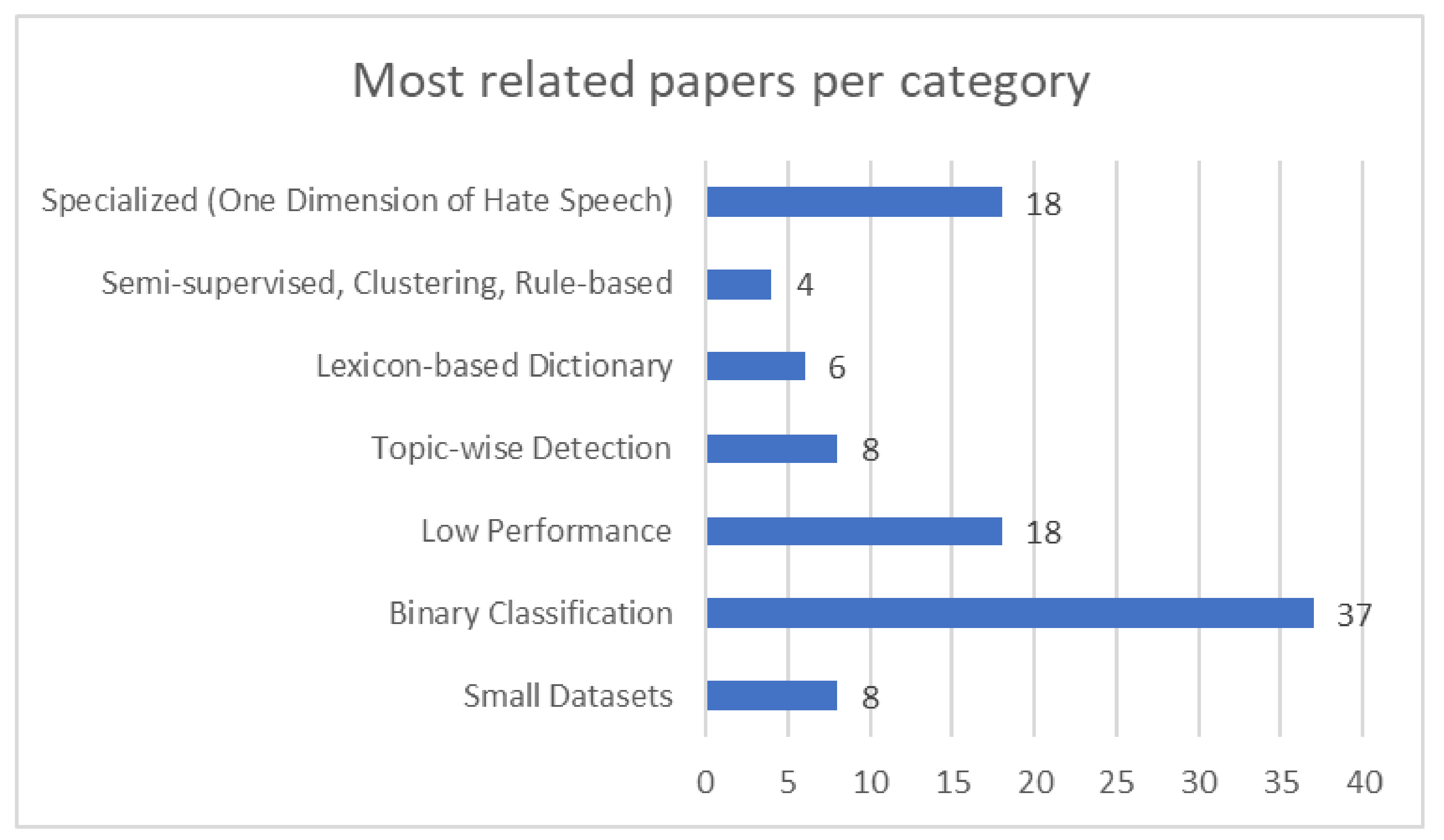
| Category of Papers | Meaning | Papers |
|---|---|---|
| Small datasets | A dataset is considered small if it has less than the initial dataset of Waseem, which was 16 K tweets. | [33,41,49,55,76,81,115,115] |
| Binary classification | A model is considered a binary classification model if it presents a work that classifies hate speech into two or three classes. | [26,28,28,31,37,37,41,41,46,51,59,65,65,67,69,69,78,80,80,90,93,94,108,109,114,115,115,113,61,121,88,123,114,126,110,113,87] |
| Low performance | A low-performance classifier is considered as that which reports a binary classification below 0.6. | [22,22,22,28,30,41,44,46,47,49,55,59,59,59,78,82,121,138] |
| Topic-wise detection | A study that uses topic-wise categorization instead of classification. | [41,46,71,76,76,117,117,139] |
| Lexicon-based dictionary generalization | A low-performance classifier is considered as those which report a binary classification below 0.6. | [24,102,104,106,122,140] |
| Semi-supervised, clustering, rule-based | A study that uses semi-supervised learning or rule-based methods instead of classification to solve the issue of hate detection. | [7,113,125,141] |
| Specialized (one dimension of hate speech) | Focused on a specific category of hate speech or dimension of hate speech. | Sarcasm [116] Racism [66,70] Sexism [25,66] General sexist tweets hide a sentiment of hate or misogynistic attitude [34] Detecting profiles [53,54] UK only [40] Retweeting [111] Hate intensity [141] Multi-mixed languages [56] Multi-hierarchical classification [142] Hate speech against immigrants [46] Comments and large text [74,112,143,144] |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alkomah, F.; Ma, X. A Literature Review of Textual Hate Speech Detection Methods and Datasets. Information 2022, 13, 273. https://doi.org/10.3390/info13060273
Alkomah F, Ma X. A Literature Review of Textual Hate Speech Detection Methods and Datasets. Information. 2022; 13(6):273. https://doi.org/10.3390/info13060273
Chicago/Turabian StyleAlkomah, Fatimah, and Xiaogang Ma. 2022. "A Literature Review of Textual Hate Speech Detection Methods and Datasets" Information 13, no. 6: 273. https://doi.org/10.3390/info13060273
APA StyleAlkomah, F., & Ma, X. (2022). A Literature Review of Textual Hate Speech Detection Methods and Datasets. Information, 13(6), 273. https://doi.org/10.3390/info13060273