
GaSubtle: A New Genetic Algorithm for Generating Subtle Higher-Order Mutants


Abstract
:1. Introduction
- Which of the five selection strategies is more effective in producing subtle HOMs?Effectiveness of each selection strategy is computed by using the number of subtle HOMs, the number of HOMs generated, and the distribution of the degree of the subtle HOMs.
- Which of the five selection strategies is more costly?Cost is computed by using the running time. We measured the running time of the proposed algorithm with each of the five selection strategies.
- What is the effectiveness of the proposed crossover technique, compared with single point crossover?The number of generated subtle HOMs by the single point crossover and proposed crossover (which we call GaSubtle crossover) are compared. The goal is to determine if GaSubtle crossover is more effective in finding subtle HOMs.
2. Related Work
3. Proposed Approach
3.1. Fitness Function
- is the set of all non-equivalent FOMs for the program under test.
- H is the space of all candidate HOMs. , where is a power set.
- U is the universe of all possible test cases.
- is the set of all test cases under consideration (the given test suite), and T kills all the FOMs in F.
- is an HOM constructed from n different FOMs, such that . The notation can be simplified to without confusion.
- Let denote the set of those test cases in T that kill . if none of the test cases in T kill .
- There are n test sets and contains all test cases that kill in .
- is a test set such that .
3.2. Initialization
- First-order mutants: 10% of the generation size.
- Second-order mutants: 80% of the generation size.
- Third-order mutants: 5% of the generation size.
- Fourth-order mutants: 5% of the generation size.
3.3. Selection
- Roulette Wheel Selection [44]: Selects n random candidates, where the probability of each candidate getting selected is proportional to its fitness score. Candidates may get selected more than once. In some cases, particularly with small population sizes, the randomness of selection may result in excessively high occurrences of particular candidates.
- Stochastic Universal Sampling [45]: An alternative to Roulette Wheel Selection as a fitness-proportionate selection strategy. It ensures that the frequency of selection for each candidate is consistent with its expected frequency of selection.
- Tournament Selection [46]: Selects a random pair of candidates and then selects the fitter of the two candidates with probability p, where p is the configured selection probability therefore the probability of the least fit candidate being selected is 1—p.
- Truncation Selection [47]: Selects n candidates from a population by simply selecting n candidates with the highest fitness value (the rest are discarded). A candidate is never selected more than once.
- Random Selection [48]: Selects candidates from a population at absolute randomness.
3.4. Mutation
3.5. Crossover
- Find the fitness of each FOM in the participating HOMs
- Decide the order of the generated children. The order of the generated children will be the average order of the parents. Both children will have the same order if the sum of the parents’ order is even. If the sum is odd, one child will have a higher order (higher by one). For example, if the parent HOMs are of orders two and four, then the two children will have an order of three. If the parent HOMs are of orders two and five, then one child will be of order three and the other will be of order four.
- Select the fittest FOMs from both parents and place them in the first child, and the least fit FOMs in the second child. If the two parents differ in order (e.g., second-order mutant crossover with third-order mutant) then the fittest child will be in the lower order whereas the least fit child will have an order higher by one.
3.6. Termination
- Reaching a given number of overall generated HOMs.
- Reaching a given number of subtle HOMs are found.
- Reaching a given number of generations.
- Timeout.
| Algorithm 1 Genetic Algorithm |
| Require: Ensure: 1: 2: 3: 4: 5: 6: while do 7: 8: 9: 10: 11: 12: 13: 14: 15: 16: end while 17: return |
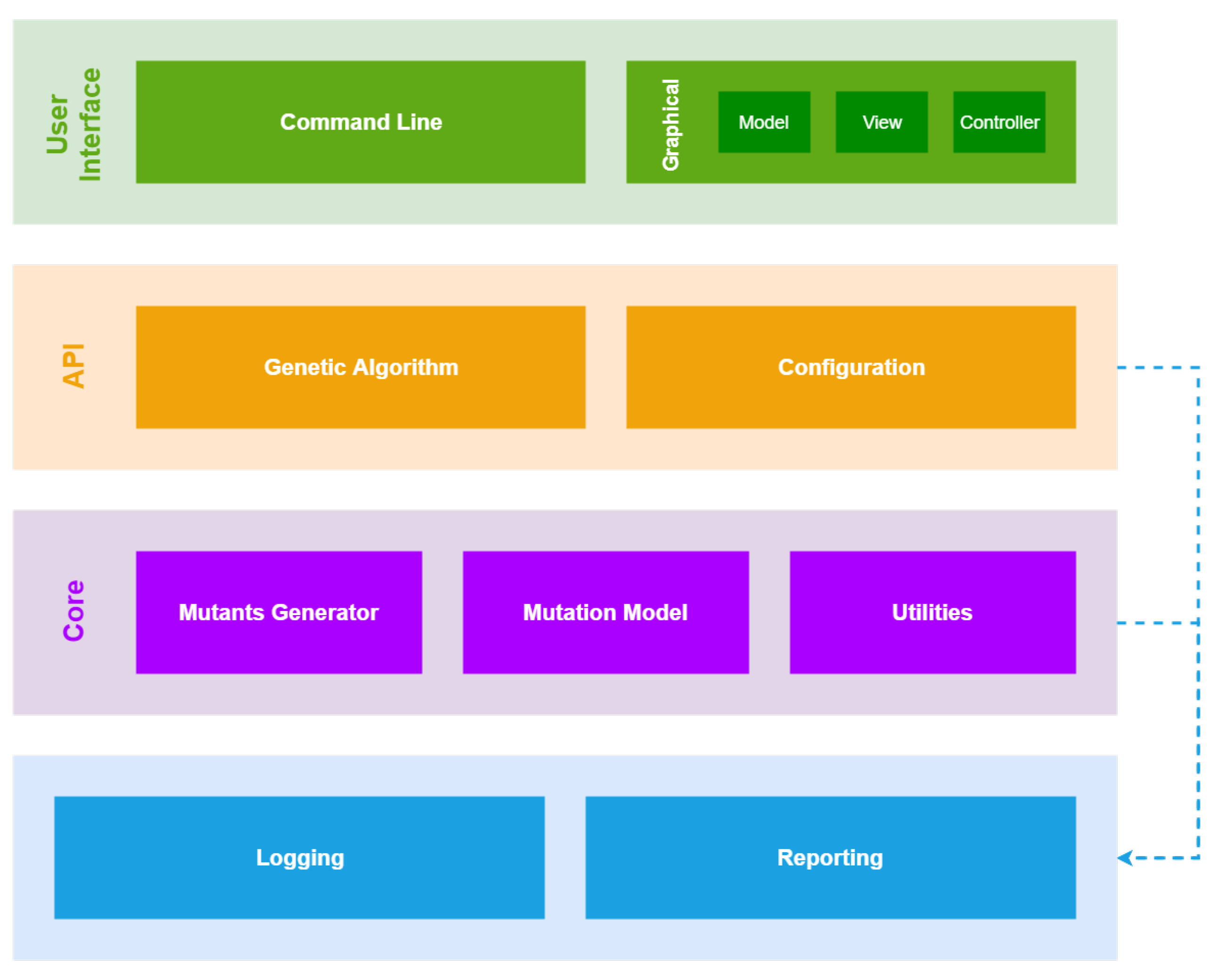
4. Gasubtle Tool
4.1. User Interface
4.2. Api: Application Programming Interface
4.3. Core
4.3.1. Mutants Generator
4.3.2. Mutation Model
4.3.3. Utilities
- Command Line Utilities: Contains operations that utilizes executing command line commands.
- Compiler: There were many compiler implementations available. However, most of these compilers were too heavy and need a lot of time to compile mutants. This was a critical issue because the generated HOMs cannot all be compiled at once because they all represent the same process. Thus, the compiler of GaSubtle uses Spoon API [50], which is an open-source library that gives the ability of transforming and analyzing Java source code.
- Test Executor: Test execution is performed using the Command Line Utilities.
5. Empirical Evaluation
5.1. Subject Programs
- Binary search: The program implements the binary search algorithm that finds the position of a target value within a sorted array. It takes as an input a string key to search for and a sorted string array to search in. It then recursively calls a methods that performs binary search and returns the index of the provided key.
- Charge https://introcs.cs.princeton.edu/java/32class/Charge.java.html (accessed on 1 May 2022): This is a data type to define charged particles. It is based on Coulomb’s law which says that the electric potential at a point due to a given charged particle is , where q is the charge value, r is the distance from the point to the charge, and is the electrostatic constant.
- Complex https://introcs.cs.princeton.edu/java/32class/Complex.java.html (accessed on 1 May 2022): This is a data type used to represent a complex number. A complex number is a number of the form , where x and y are real numbers and i is the square root of . The basic operations on complex numbers are to add and multiply them.
- Counter https://introcs.cs.princeton.edu/java/33design/Counter.java.html (accessed on 1 May 2022): The program is used for counting. It encapsulates a single integer and ensures that the only operation that can be performed on the integer is increment by one.
- Euclid https://introcs.cs.princeton.edu/java/23recursion/Euclid.java.html (accessed on 1 May 2022): This is an implementation of the Euclidean algorithm, which is an algorithm for finding the greatest common divisor of two numbers.
- Gaussian https://introcs.cs.princeton.edu/java/21function/Gaussian.java.html (accessed on 1 May 2022): This implements some of the normal distribution functions, which is characterized by the familiar bell-shaped curve.
- Harmonic https://introcs.cs.princeton.edu/java/21function/Harmonic.java.html (accessed on 1 May 2022): This calculates the harmonic of a given number, which is the sum of the reciprocals of the first n natural numbers as shown in Equation (5).
- LongestCommonSubsequence https://introcs.cs.princeton.edu/java/23recursion/LongestCommonSubsequence.java.html (accessed on 1 May 2022): This implements the longest common sub-sequence problem, which is the problem of finding the longest sub-sequence common to all sequences in a given set of sequences.
- ArrayList https://docs.oracle.com/javase/8/docs/api/java/util/ArrayList.html (accessed on 1 May 2022): The program is a simplified implementation of Java Collections ArrayList.
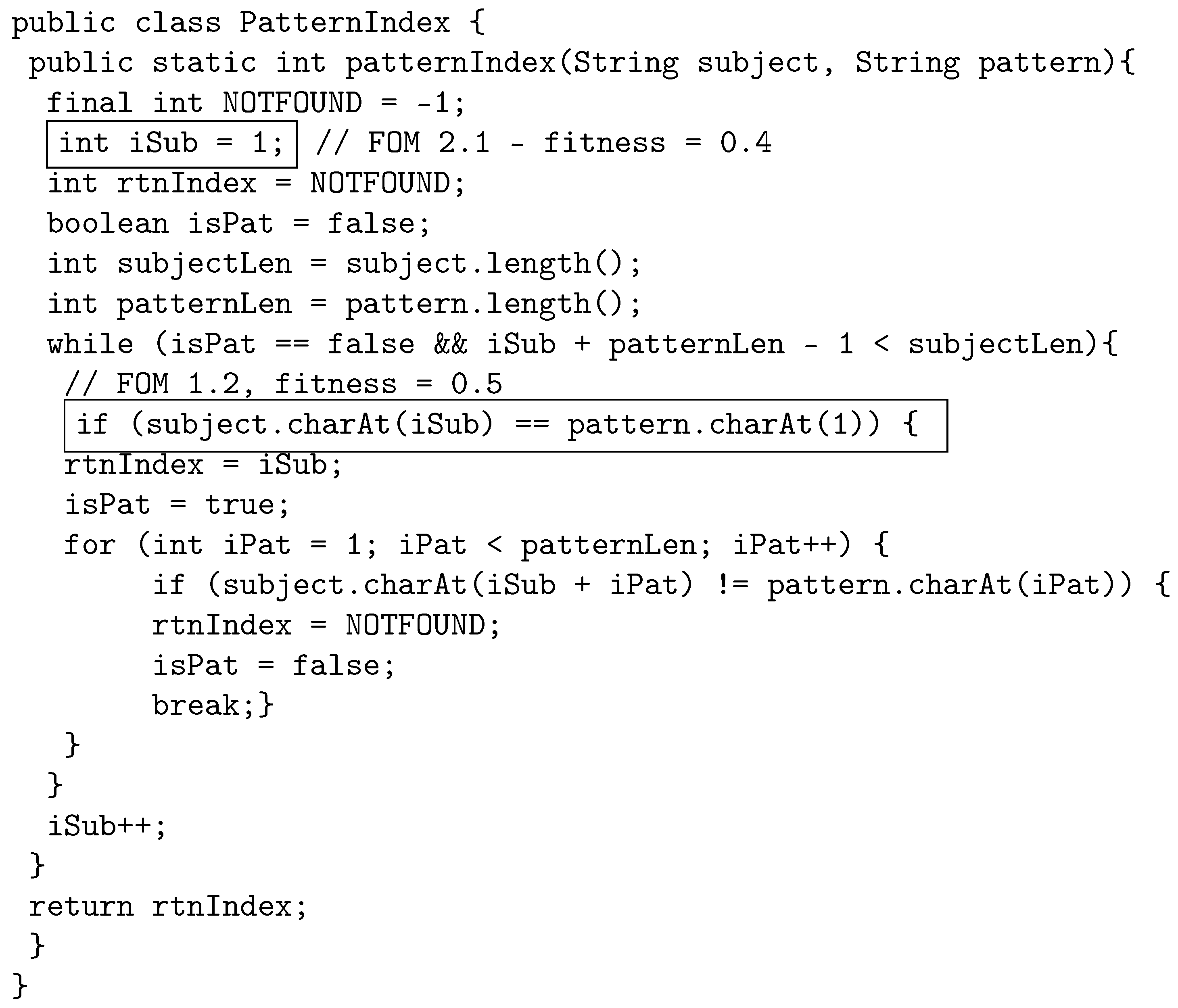
- PatternIndex https://cs.gmu.edu/~offutt/softwaretest/java/PatternIndex.java (accessed on 1 May 2022): The program searches for a given pattern in a given string and returns the beginning index of that pattern.
5.2. Research Questions
- RQ1 :
- Which selection strategy generates the highest number of subtle mutants?
- RQ2 :
- Does the proposed crossover generate more subtle mutants, compared with single-point crossover?
- RQ3 :
- Which selection strategy generates the least percentage of equivalent mutants?
- RQ4 :
- Does the proposed crossover generate a lesser percentage of equivalent mutants, compared with single-point crossover?
- RQ5 :
- What is the percentage of the generated HOMs from each mutation order?
- RQ6 :
- Which selection strategy has the least execution cost?
- RQ7 :
- Which crossover technique has the least execution cost?
5.3. Used Tools
5.3.1. Mutation Testing Tools
- MuJava [34]: This is a Java-based mutation testing tool developed through the collaboration between the Korean Advanced Institute of Science and Technology in South Korea and George Mason University in the USA. MuJava is widely used research for performing mutation analysis. In this experiment, we used MuJava to generate FOMs.
- GaSubtle: A tool we developed to implement the proposed approach for constructing subtle mutants.
5.3.2. Test Cases Generation Tools
- Randoop [51]: This is an open source unit test generator for Java. It automatically creates unit tests for the provided classes, in JUnit format.Randoop generates unit tests by using feedback-directed random test generation. It is done by executing the sequences it creates, using the results of the execution to create assertions that capture the behavior of the provided classes [51].
- EvoSuite [52]: This is an open-source unit test generator for Java. It uses search-based approach integrating techniques such as hybrid search, dynamic symbolic execution, and testability transformation in order to generate JUnit test cases for a provided Java class.
- Parasoft Jtest https://www.parasoft.com/products/jtest (accessed on 1 May 2022): A commercial tool by Parasoft which provides a set of tools such as static analysis and security, unit testing for active development, unit testing for legacy code, coverage analysis and traceability, and reporting.
5.3.3. Test Coverage Tools
5.4. Experiment Setup
5.4.1. Mutants Generation
5.4.2. Finding Test Suites
5.4.3. Configuration
- The value of of the fitness function was set at 0.75.
- Termination condition was set to reach 300 generations.
- Maximum mutation order not to be exceeded was set to 5.
- Mutation percentage was set to 5%.
6. Results and Analysis
6.1. Rq1: Which Selection Strategy Generates the Highest Number of Subtle Mutants?
6.1.1. Single-Point Crossover
6.1.2. Proposed Crossover
6.2. Rq2: Does the Proposed Crossover Generate More Subtle Mutants Compared with Single-Point Crossover?
6.3. Rq3: Which Selection Strategy Generates the Smallest Percentage of Equivalent Mutants?
6.3.1. Single-Point Crossover
6.3.2. Proposed Crossover
6.4. Rq4: Does the Proposed Crossover Generate a Lesser Percentage of Equivalent Mutants Compared with Single-Point Crossover?
6.5. Rq5: What Is the Percentage of the Generated HOMs from Each Mutation Order?
6.5.1. Single-Point Crossover
6.5.2. Proposed Crossover
6.6. Rq6: Which Selection Strategy Has the Least Execution Cost?
6.6.1. Single-Point Crossover
6.6.2. Proposed Crossover
6.7. Rq7: Which Crossover Technique Has The Least Execution Cost?
7. Threats to Validity
- The setup and configuration of the parameters of the genetic algorithm. Identifying the optimal configuration that may lead to the best results can be hard. Moreover, the performance of the tool may vary from one machine to another as the idleness of the machine cannot be guaranteed. However, in this paper we performed an experimental evaluation to identify the best configuration for the algorithm. We also ran the tool on an isolated environment to insure that the machine is not running anything besides the tool. Moreover, to minimize this effect, we performed each run 10 times.
- The number and quality of the test cases. We used three different tools to generate the test cases. Using other tools may lead to different results. However, the test cases used had a 100% branch coverage and were able to kill all the generated FOMs. Moreover, we used handcrafted test cases to ensure the quality of the test cases when the test cases generated by the tools failed to cover all branches or kill all FOMs.
- The subject programs. We performed the empirical evaluation on 10 subject programs, and there is no evidence that the results can be extended or generalized to other Java programs or programs implemented in other programming languages. However, as mentioned earlier, the selected subject programs differ in their size, complexity, operations, and object-oriented programming concepts used.
- The subject programs are small (less than 200 lines of code) and constituent from only one class. Using larger programs or more than class may produce different results. In the future, additional programs with larger sizes will be studied.
8. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| FOM | First Order Mutant |
| SOM | Second Order Mutant |
| HOM | Higher Order Mutant |
| GA | Genetic Algorithm |
| LOC | Lines Of Code excluding spaces |
| MVC | Model View Controller |
| GaSubtle | Genetic algorithm for generating subtle higher order mutants |
References
- DeMillo, R.A.; Lipton, R.J.; Sayward, F.G. Hints on test data selection: Help for the practicing programmer. Computer 1978, 11, 34–41. [Google Scholar] [CrossRef]
- Hamlet, R.G. Testing programs with the aid of a compiler. IEEE Trans. Softw. Eng. 1977, SE-3, 279–290. [Google Scholar] [CrossRef]
- Frankl, P.G.; Weiss, S.N.; Hu, C. All-uses vs mutation testing: An experimental comparison of effectiveness. J. Syst. Softw. 1997, 38, 235–253. [Google Scholar] [CrossRef]
- Andrews, J.H.; Briand, L.C.; Labiche, Y.; Namin, A.S. Using mutation analysis for assessing and comparing testing coverage criteria. IEEE Trans. Softw. Eng. 2006, 32, 608–624. [Google Scholar] [CrossRef]
- Jia, Y.; Harman, M. Higher Order Mutation Testing. Inf. Softw. Technol. 2009, 51, 1379–1393. [Google Scholar] [CrossRef] [Green Version]
- Budd, T.A.; Angluin, D. Two notions of correctness and their relation to testing. Acta Inform. 1982, 18, 31–45. [Google Scholar] [CrossRef]
- Schuler, D.; Andreas, Z. Covering and uncovering equivalent mutants. Softw. Test. Verif. Reliab. 2013, 23, 353–374. [Google Scholar] [CrossRef]
- Mresa, E.S.; Bottaci, L. Efficiency of mutation operators and selective mutation strategies: An empirical study. Softw. Test. Verif. Reliab. 1999, 9, 205–232. [Google Scholar] [CrossRef]
- Offutt, A.J.; Lee, S.D. An empirical evaluation of weak mutation. IEEE Trans. Softw. Eng. 1994, 20, 337–344. [Google Scholar] [CrossRef]
- Budd, T.A. Mutation Analysis of Program Test Data. Ph.D. Thesis, Yale University, New Haven, CT, USA, 1980. [Google Scholar]
- Hussain, S. Mutation Clustering. Master’s Thesis, King’s College London, London, UK, 2008. [Google Scholar]
- Howden, W.E. Weak mutation testing and completeness of test sets. IEEE Trans. Softw. Eng. 1982, SE-8, 371–379. [Google Scholar] [CrossRef]
- Baldwin, D.; Sayward, F. Heuristics for Determining Equivalence of Program Mutations; Technical Report; School of Computer Science: Atlanta, GA, USA, 1979. [Google Scholar]
- Offutt, A.J.; Pan, J. Automatically detecting equivalent mutants and infeasible paths. Softw. Test. Verif. Reliab. 1997, 7, 165–192. [Google Scholar] [CrossRef]
- Hierons, R.; Harman, M.; Danicic, S. Using program slicing to assist in the detection of equivalent mutants. Softw. Test. Verif. Reliab. 1999, 9, 233–262. [Google Scholar] [CrossRef]
- Grun, B.J.; Schuler, D.; Andreas, Z. The impact of equivalent mutants. In Proceedings of the Software Testing, Verification and Validation Workshops, Denver, CO, USA, 1–4 April 2009; pp. 192–199. [Google Scholar]
- Adamopoulos, K.; Harman, M.; Hierons, R.M. How to overcome the equivalent mutant problem and achieve tailored selective mutation using co-evolution. In Proceedings of the Genetic and Evolutionary Computation Conference, Seattle, WA, USA, 26–30 June 2004; pp. 1338–1349. [Google Scholar]
- Purushothaman, R.; Perry, D.E. Toward understanding the rhetoric of small source code changes. IEEE Trans. Softw. Eng. 2005, 31, 511–526. [Google Scholar] [CrossRef] [Green Version]
- Gopinath, R.; Jensen, C.; Groce, A. Mutations: How close are they to real faults? In Proceedings of the Software Reliability Engineering (ISSRE), Naples, Italy, 3–6 November 2014; pp. 189–200. [Google Scholar]
- Langdon, W.B.; Harman, M.; Jia, Y. Efficient Multi-objective Higher Order Mutation Testing with Genetic Programming. J. Syst. Softw. 2010, 83, 2416–2430. [Google Scholar] [CrossRef] [Green Version]
- Omar, E.; Ghosh, S. An exploratory study of higher order mutation testing in aspect-oriented programming. In Proceedings of the Software Reliability Engineering (ISSRE), Dallas, TX, USA, 27–30 November 2012; pp. 1–10. [Google Scholar]
- Mateo, P.R.; Usaola, M.P.; Aleman, J.L.F. Validating second-order mutation at system level. IEEE Trans. Softw. Eng. 2013, 39, 570–587. [Google Scholar] [CrossRef]
- Omar, E.; Ghosh, S.; Whitley, D. Constructing subtle higher order mutants for Java and AspectJ programs. In Proceedings of the Software Reliability Engineering (ISSRE), Pasadena, CA, USA, 4–7 November 2013; pp. 340–349. [Google Scholar]
- Wedyan, F.; Ghosh, S. On generating mutants for AspectJ programs. Inf. Softw. Technol. 2012, 54, 900–914. [Google Scholar] [CrossRef]
- Jia, Y.; Harman, M. Constructing subtle faults using higher order mutation testing. In Proceedings of the Source Code Analysis and Manipulation, Beijing, China, 28–29 September 2008; pp. 249–258. [Google Scholar]
- Kintis, M.; Papadakis, M.; Malevris, N. Isolating first order equivalent mutants via second order mutation. In Proceedings of the Software Testing, Verification and Validation (ICST), Montreal, QC, Canada, 17–21 April 2012; pp. 701–710. [Google Scholar]
- do Prado Lima, J.A.; Vergilio, S.R. A systematic mapping study on higher order mutation testing. J. Syst. Softw. 2019, 154, 92–109. [Google Scholar] [CrossRef]
- Ghiduk, A.S.; Girgis, M.R.; Shehata, M.H. Higher order mutation testing: A systematic literature review. Comput. Sci. Rev. 2017, 25, 29–48. [Google Scholar] [CrossRef]
- Pizzoleto, A.V.; Ferrari, F.C.; Offutt, J.; Fernandes, L.; Ribeiro, M. A systematic literature review of techniques and metrics to reduce the cost of mutation testing. J. Syst. Softw. 2019, 157, 110388. [Google Scholar] [CrossRef]
- Lima, J.A.P.; Vergilio, S.R. Search-based higher order mutation testing: A mapping study. In Proceedings of the III Brazilian Symposium on Systematic and Automated Software Testing, Sao Carlos, Brazil, 17–21 September 2018; pp. 87–96. [Google Scholar]
- Polo, M.; Piattini, M.; Garcia-Rodiguez, I. Decreasing the Cost of Mutation Testing with Second-order Mutants. Softw. Test. Verif. Reliab. 2009, 19, 111–131. [Google Scholar] [CrossRef]
- Fonseca, C.M.; Fleming, P.J. Genetic Algorithms for Multiobjective Optimization: FormulationDiscussion and Generalization. InIcga 1993, 93, 416–423. [Google Scholar]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef] [Green Version]
- Ma, Y.S.; Offutt, J.; Kwon, Y.R. MuJava: A Mutation System for Java. In Proceedings of the 28th International Conference on Software Engineering, Shanghai, China, 20–28 May 2006; ACM: New York, NY, USA, 2006; pp. 827–830. [Google Scholar] [CrossRef]
- Delamare, R.; Baudry, B.; Le Traon, Y. AjMutator: A tool for the mutation analysis of AspectJ pointcut descriptors. In Proceedings of the Software Testing, Verification and Validation Workshops, Denver, CO, USA, 1–4 April 2009; pp. 200–204. [Google Scholar]
- Omar, E.; Ghosh, S.; Whitley, D. Comparing search techniques for finding subtle higher order mutants. In Proceedings of the 2014 Annual Conference on Genetic and Evolutionary Computation, Vancouver, BC, Canada, 12–16 July 2014; pp. 1271–1278. [Google Scholar]
- Omar, E.; Ghosh, S.; Whitley, D. Subtle higher order mutants. Inf. Softw. Technol. 2017, 81, 3–18. [Google Scholar] [CrossRef]
- Nguyen, Q.V.; Madeyski, L. Addressing mutation testing problems by applying multi-objective optimization algorithms and higher order mutation. J. Intell. Fuzzy Syst. 2017, 32, 1173–1182. [Google Scholar] [CrossRef] [Green Version]
- Abuljadayel, A.; Wedyan, F. An Approach for the Generation of Higher Order Mutants Using Genetic Algorithms. Int. J. Intell. Syst. Appl. 2018, 10, 34. [Google Scholar] [CrossRef] [Green Version]
- Nguyen, Q.V. Increasing Mutation Testing Effectiveness by Combining Lower Order Mutants to Construct Higher Order Mutants. In Proceedings of the International Conference on Computational Collective Intelligence, Da Nang, Vietnam, 30 November–3 December 2020; pp. 205–216. [Google Scholar]
- Jang, J.I.; Ryu, D.; Baik, J. HOTFUZ: Cost-effective higher-order mutation-based fault localization. Softw. Test. Verif. Reliab. 2021, e1802. [Google Scholar] [CrossRef]
- Wang, H.; Li, Z.; Liu, Y.; Chen, X.; Paul, D.; Cai, Y.; Fan, L. Can Higher-Order Mutants Improve the Performance of Mutation-Based Fault Localization? IEEE Trans. Reliab. 2022, 71, 1157–1173. [Google Scholar] [CrossRef]
- Holland, J.H. Genetic algorithms and the optimal allocation of trials. SIAM J. Comput. 1973, 2, 88–105. [Google Scholar] [CrossRef]
- Goldberg, D.E. Genetic Algorithms in Search, Optimization and Machine Learning, 1st ed.; Addison-Wesley Longman Publishing Co., Inc.: Boston, MA, USA, 1989. [Google Scholar]
- Baker, J.E. Reducing Bias and Inefficiency in the Selection Algorithm. In Proceedings of the Second International Conference on Genetic Algorithms on Genetic Algorithms and Their Application, Cambridge, MA, USA, 28–31 July 1987; Lawrence Erlbaum Associates Inc.: Hillsdale, NJ, USA, 1987; pp. 14–21. [Google Scholar]
- Miller, B.L.; Goldberg, D.E. Genetic algorithms, tournament selection and the effects of noise. Complex Syst. 1995, 9, 193–212. [Google Scholar]
- Crow, J.F.; Kimura, M. Efficiency of truncation selection. Proc. Natl. Acad. Sci. USA 1979, 76, 396–399. [Google Scholar] [CrossRef] [Green Version]
- Baker, J.E. Adaptive Selection Methods for Genetic Algorithms. In Proceedings of the 1st International Conference on Genetic Algorithms, Sheffield, UK, 12–14 September 1995; Lawrence Erlbaum Associates Inc.: Hillsdale, NJ, USA, 1985; pp. 101–111. [Google Scholar]
- Whitley, D. A genetic algorithm tutorial. Stat. Comput. 1994, 4, 65–85. [Google Scholar] [CrossRef]
- Pawlak, R.; Monperrus, M.; Petitprez, N.; Noguera, C.; Seinturier, L. Spoon: A Library for Implementing Analyses and Transformations of Java Source Code. Softw. Pract. Exp. 2015, 46, 1155–1179. [Google Scholar] [CrossRef] [Green Version]
- Pacheco, C.; Ernst, M.D. Randoop: Feedback-directed random testing for Java. In Proceedings of the Companion to the 22nd ACM SIGPLAN conference on Object-oriented programming systems and applications companion, Montreal, QC, Canada, 21–25 October 2007; pp. 815–816. [Google Scholar]
- Fraser, G.; Andrea, A. Evosuite: Automatic test suite generation for object-oriented software. In Proceedings of the 19th ACM SIGSOFT Symposium and the 13th European Conference on Foundations of Software Engineering, Szeged, Hungary, 5–9 September 2011; pp. 416–419. [Google Scholar]
- Kerlinger, F.N. Foundations of Behavioral Research; Rinehart and Winston: New York, NY, USA, 1966. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Program | Source Code |
|---|---|
| Original | int sum(int n1, int n2) { int sum = n1 + n2; return sum; } |
| Mutant 1 | int sum(int n1, int n2) { int sum = ++n1 + n2; return sum; } |
| Mutant 2 | int sum(int n1, int n2) { int sum = n1++ + n2; return sum; } |
| Mutant 3 | int sum(int n1, int n2) { int sum = n1 + n2; return ++sum; } |
| Uncompilable HOM (by combining mutants 1 & 2) | int sum(int n1, int n2) { int sum = ++n1++ + n2; return sum; } |
| Compilable HOM (by combining mutants 1 & 3) | int sum(int n1, int n2) { int sum = ++n1 + n2; return ++sum; } |
| Subject Program | LOC | No. FOMs | No. Test Cases |
|---|---|---|---|
| BinarySearch | 33 | 175 | 62 |
| Charge | 29 | 132 | 75 |
| Complex | 55 | 239 | 87 |
| Counter | 38 | 62 | 67 |
| Euclid | 26 | 106 | 95 |
| Gaussian | 58 | 457 | 90 |
| Harmonic | 15 | 57 | 72 |
| LongestCommonSubsequence | 41 | 371 | 78 |
| ArrayList | 130 | 380 | 105 |
| PatternIndex | 49 | 175 | 90 |
| Subject Program | Selection Strategy | ||||
|---|---|---|---|---|---|
| Random | Roulette Wheel | SUS | Tournament | Truncation | |
| BinarySearch | 1676 | 1141 | 1935 | 1264 | 877 |
| Charge | 1008 | 160 | 383 | 1534 | 245 |
| Complex | 27 | 79 | 4 | 41 | 14 |
| Counter | 847 | 685 | 1175 | 1137 | 732 |
| Euclid | 205 | 152 | 256 | 238 | 268 |
| Gaussian | 70 | 39 | 61 | 19 | 27 |
| Harmonic | 201 | 236 | 380 | 300 | 2029 |
| LongestCommonSubsequence | 65 | 67 | 90 | 25 | 15 |
| ArrayList | 2268 | 1632 | 2587 | 1561 | 3412 |
| PatternIndex | 829 | 728 | 564 | 1018 | 521 |
| Total | 7196 | 4919 | 7435 | 7137 | 8140 |
| Subject Program | Selection Strategy | ||||
|---|---|---|---|---|---|
| Random | Roulette Wheel | SUS | Tournament | Truncation | |
| BinarySearch | 4416 | 2498 | 3184 | 2451 | 7626 |
| Charge | 891 | 1427 | 293 | 436 | 464 |
| Complex | 276 | 235 | 59 | 56 | 0 |
| Counter | 2644 | 2421 | 2200 | 5764 | 3534 |
| Euclid | 529 | 386 | 359 | 326 | 559 |
| Gaussian | 110 | 120 | 60 | 115 | 316 |
| Harmonic | 677 | 525 | 400 | 960 | 252 |
| LongestCommonSubsequence | 29 | 107 | 126 | 40 | 0 |
| ArrayList | 5019 | 2862 | 2649 | 3511 | 6744 |
| PatternIndex | 441 | 1291 | 1068 | 777 | 994 |
| Total | 15,032 | 11,872 | 10,398 | 14,436 | 20,489 |
| Subject Program | Selection Strategy | ||||
|---|---|---|---|---|---|
| Random | Roulette Wheel | SUS | Tournament | Truncation | |
| BinarySearch | 8% | 5% | 9% | 3% | 6% |
| Charge | 4% | 2.7% | 8% | 3% | 5.6% |
| Complex | 9.7% | 7.4% | 0% | 7.3% | 3% |
| Counter | 10% | 9% | 7% | 8% | 8% |
| Euclid | 14% | 13.2% | 20.5% | 15.7% | 16.1% |
| Gaussian | 13.6% | 5.1% | 3.2% | 5.2% | 3.7% |
| Harmonic | 5% | 6% | 5% | 7% | 4% |
| LongestCommonSubsequence | 10.7% | 5.4% | 3.3% | 9% | 6.7% |
| ArrayList | 5% | 4% | 3% | 6% | 5% |
| PatternIndex | 2% | 4% | 5% | 5% | 3% |
| Total | 6.2% | 2.2% | 2.4 % | 1.4% | 1.3% |
| Subject Program | Selection Strategy | ||||
|---|---|---|---|---|---|
| Random | Roulette Wheel | SUS | Tournament | Truncation | |
| BinarySearch | 4% | 3% | 10% | 4% | 8% |
| Charge | 4% | 5% | 3% | 3% | 4% |
| Complex | 6% | 5% | 8.5% | 5.1% | 0% |
| Counter | 9% | 7% | 8% | 6% | 7% |
| Euclid | 12% | 7% | 5% | 8% | 4% |
| Gaussian | 2% | 1% | 3% | 1% | 2% |
| Harmonic | 3% | 5% | 6% | 4% | 2% |
| LongestCommonSubsequence | 3.4% | 3% | 5% | 2.5% | 0% |
| ArrayList | 3% | 4% | 6% | 5% | 4% |
| PatternIndex | 3% | 2% | 5% | 3% | 4% |
| Total | 4.8% | 1.9% | 2.1% | 1.4% | 1.7% |
| Mutation | Selection Strategy | ||||
|---|---|---|---|---|---|
| Order | Random | Roulette Wheel | SUS | Tournament | Truncation |
| Second | 60.2 | 88.2 | 90.1 | 88.2 | 74.2 |
| Third | 28.5 | 7.7 | 7.7 | 8.5 | 22 |
| Fourth | 8.9 | 3.4 | 1.9 | 1.8 | 2.1 |
| Fifth | 2.5 | 0.7 | 0.4 | 0.2 | 0.4 |
| Mutation | Selection Strategy | ||||
|---|---|---|---|---|---|
| Order | Random | Roulette Wheel | SUS | Tournament | Truncation |
| Second | 21.5 | 59.1 | 57.1 | 58.7 | 72.9 |
| Third | 37.1 | 25.2 | 28 | 25.9 | 20.2 |
| Fourth | 30.6 | 12.9 | 12.8 | 12.7 | 5.8 |
| Fifth | 10.8 | 2.8 | 2.1 | 2.6 | 1.2 |
| Subject Program | Selection Strategy | ||||
|---|---|---|---|---|---|
| Random | Roulette Wheel | SUS | Tournament | Truncation | |
| BinarySearch | 17.2 | 16.1 | 17.3 | 17.2 | 11.8 |
| Charge | 14.9 | 14.8 | 15.2 | 15.1 | 14.1 |
| Complex | 25.2 | 26.7 | 28.1 | 13.1 | 11.6 |
| Counter | 16.6 | 17.3 | 17.2 | 16.8 | 12.2 |
| Euclid | 15.1 | 13.4 | 14.1 | 14.6 | 13.4 |
| Gaussian | 29.6 | 31.5 | 33.2 | 24.8 | 25.1 |
| Harmonic | 16.5 | 16.2 | 16.4 | 16.8 | 15.4 |
| LongestCommonSubsequence | 27.1 | 29.4 | 28.9 | 23.2 | 18.6 |
| ArrayList | 23.5 | 31.2 | 27.6 | 24.1 | 19.4 |
| PatternIndex | 21.3 | 25.8 | 25.2 | 20.9 | 18.5 |
| Total | 20.7 | 22.24 | 22.32 | 18.66 | 16.01 |
| Subject Program | Selection Strategy | ||||
|---|---|---|---|---|---|
| Random | Roulette Wheel | SUS | Tournament | Truncation | |
| BinarySearch | 14.3 | 9.1 | 13.9 | 14.2 | 13.6 |
| Charge | 12.8 | 13.4 | 12.7 | 13.1 | 11.3 |
| Complex | 17.9 | 28.6 | 29.3 | 17.2 | 15.3 |
| Counter | 8.3 | 8.2 | 7.9 | 8.1 | 7.8 |
| Euclid | 13.1 | 13.2 | 13.4 | 11.9 | 11.3 |
| Gaussian | 24.6 | 29.2 | 28.3 | 21.1 | 17.9 |
| Harmonic | 12.5 | 13.2 | 12.9 | 12.1 | 15.4 |
| LongestCommonSubsequence | 21.1 | 23.3 | 20.7 | 17.1 | 14.1 |
| ArrayList | 19.6 | 20.1 | 18.2 | 18.4 | 13.1 |
| PatternIndex | 15.4 | 16.3 | 15.3 | 16.2 | 13.7 |
| Total | 15.96 | 17.46 | 17.26 | 14.94 | 13.35 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wedyan, F.; Al-Shishani, A.; Jararweh, Y. GaSubtle: A New Genetic Algorithm for Generating Subtle Higher-Order Mutants. Information 2022, 13, 327. https://doi.org/10.3390/info13070327
Wedyan F, Al-Shishani A, Jararweh Y. GaSubtle: A New Genetic Algorithm for Generating Subtle Higher-Order Mutants. Information. 2022; 13(7):327. https://doi.org/10.3390/info13070327
Chicago/Turabian StyleWedyan, Fadi, Abdullah Al-Shishani, and Yaser Jararweh. 2022. "GaSubtle: A New Genetic Algorithm for Generating Subtle Higher-Order Mutants" Information 13, no. 7: 327. https://doi.org/10.3390/info13070327
APA StyleWedyan, F., Al-Shishani, A., & Jararweh, Y. (2022). GaSubtle: A New Genetic Algorithm for Generating Subtle Higher-Order Mutants. Information, 13(7), 327. https://doi.org/10.3390/info13070327