
About Challenges in Data Analytics and Machine Learning for Social Good



Abstract
:1. Introduction
- Challenge 1 (C1)—Dataset acquisition and preparation:The acquisition of datasets is always a complex matter, for instance in scenarios such as the medical one due to ethical issues, but also in others due to data confidentiality. Moreover, from a technical point of view, extracting the required data in large quantities and from multiple sources, while also preparing it (e.g., feature extraction, dataset balancing, etc.) in such a way to properly support the specific machine learning tasks, is often a challenge in itself.
- Challenge 2 (C2)—Output interpretation:Designing and building the model(s), choosing the most suitable and effective ML algorithm(s), performing the tests and evaluating effectiveness results are only the first steps in these contexts. Interpretation of the results in terms of the reasons why ML models produced specific results are key to advancing knowledge and obtaining the complex goals envisioned in each scenario.
2. Machine Learning for Social Good
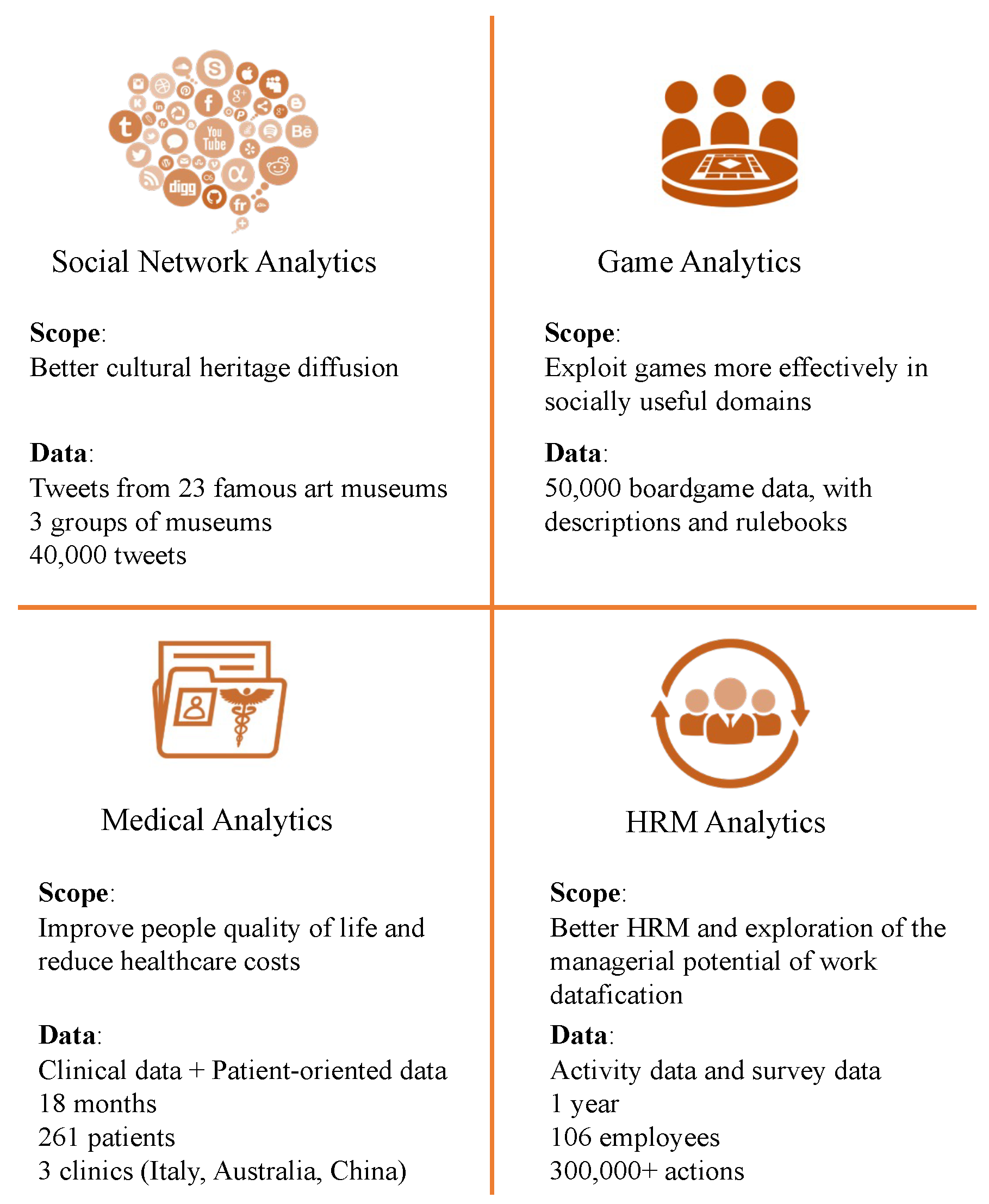
2.1. Scenario 1: Social Network Analytics
2.2. Scenario 2: Game Analytics
2.3. Scenario 3: Medical Analytics
2.4. Scenario 4: Human Resource Management (Hrm) Analytics
3. Challenges in the Social Network Analytics/Cultural Heritage Scenario
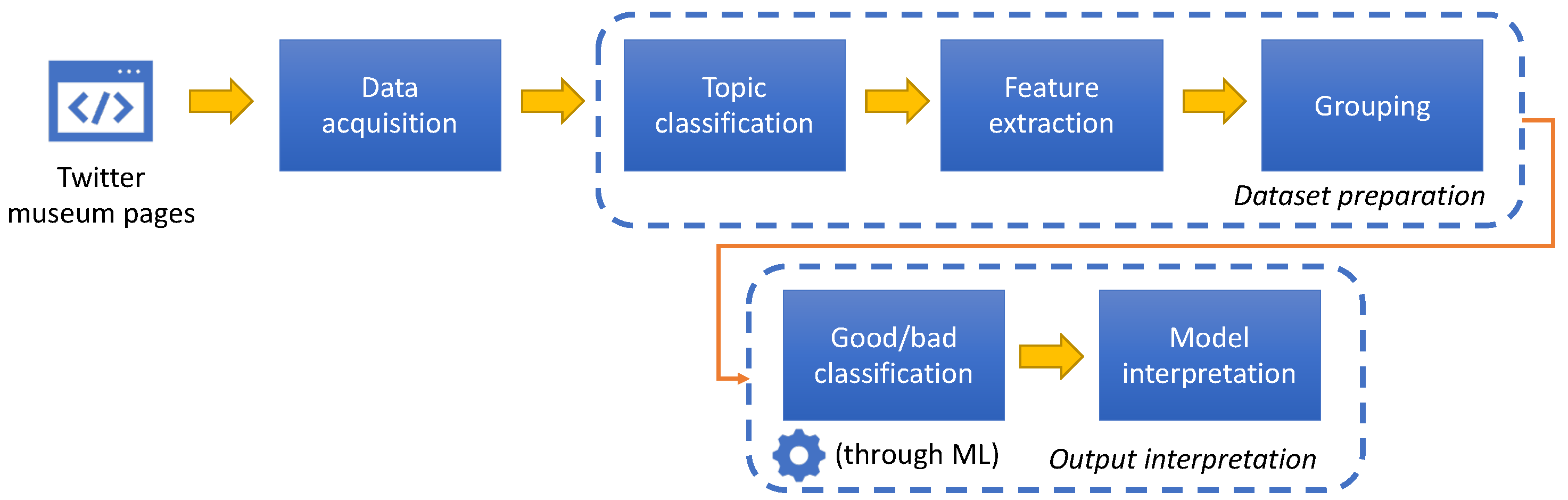
3.1. Challenge 1—Dataset Acquisition and Preparation
- Tweet topic feature: Reading some of the tweets in the dataset, we observed that museums have a limited number of different tweet topics. Therefore, we decided to take advantage of this particular situation for the GOOD/BAD classification by adding the relevance of a tweet to topic classes. This step in the dataset preparation is new with respect to the proposal presented in [10].
- -
- Artwork: description/presentation of some piece of art;
- -
- Festivities greetings;
- -
- Historical celebrations or facts related to artworks;
- -
- Happened #OnThisDay;
- -
- Museum promotions;
- -
- Important historical people or their citations;
- -
- Miscellany: tweets not falling into other classes.
- -
- we counted how many words of the corresponding word list are contained in the tweet;
- -
- we counted how many entities of the corresponding entity list are contained in the tweet;
- -
- we then normalized the counts with respect to the lists lengths, and summed the resulting numbers.
- Features extraction: We identified a set of features to be used for GOOD/BAD classification. Some of these features are content-dependent (e.g., number of mentions and URLs in the message, the length of the message, if the post contains an image or not, and so on), others are context dependent (e.g., the time of the day in which the post was published or if it is a retweet or not). The complete list of content and context features might be found in [10]. Moreover, we added one feature per topic and the feature value as explained before.
- Grouping: As we said, we measure the success of a tweet by the numbers of likes and retweets it received. However, it is not possible to define the same thresholds to these numbers for all museums. Indeed, the best tweet posted by a small museum might have the same number of likes (or even less) of the worst post of a very large museums. Therefore, we divided the museums into three groups according to the number of followers of their Twitter accounts, grouping together museums with similar numbers. Tweets in the dataset were divided accordingly into three groups.
3.2. Challenge 2—Output Interpretation
- Tweet Classification: We classify tweets into GOOD and BAD by considering the content and context features, and the topic class features. We evaluated different classifiers to identify the best performing one (XGboost) and obtained the promising accuracy results shown in Table 1.
- Model interpretation: Besides tweets classification, other information can be gathered by interpreting the machine learning algorithm output. We want to understand which feature values contributed the most to tweets being classified into BAD. Such insights are then used to suggest to the museum social media manager how the tweet can be enhanced to make communications (and cultural heritage diffusion) more effective. Suggestions are indications on how to modify features values (e.g., add a mention or remove a URL) are thus easy to give, to understand, and to implement.
4. Challenges in the Game Analytics Scenario
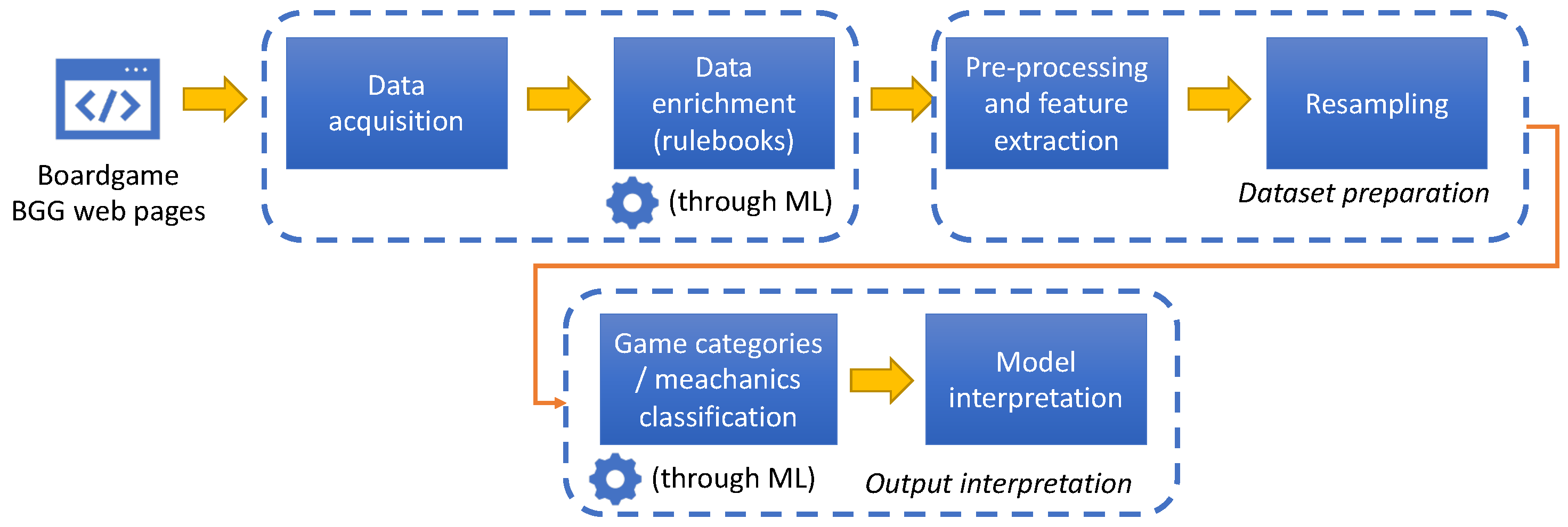
4.1. Challenge 1—Dataset Acquisition and Preparation
- Data acquisition: First of all, the data had to be acquired from the BoardGameGeek—BGG (http://boardgamegeek.com/, accessed on 5 May 2022) website, the current reference for the board game community. The website is based on a very large database which, however, is not directly accessible as a download. Some information is accessible from an API, other information is available only through direct navigation on the website pages. This required the identification of the relevant information from the page of each game, construction of an ad hoc parser exploiting both direct scraping and BGG API to acquire the data from the pages and associated XML data of the first 50,000 games in the BGG ranking. Among the extracted fields, one of the most important is the textual description of the game;
- Data enrichment: In order to possibly enhance the effectiveness of ML classification, the dataset has been enrinched with additional information coming from the rulebook associated to each game. This enrichment process was completely unfeasible to be done manually: in BGG, each game was associated to a community page containing various files, and the rulebook could be “hidden” among dozens of files (which are not categorized in any way and typically vary a lot from game to game in terms of content). In order to solve this, the process was modelled as an ML process itself: a subset of the files (some thousands) were manually identified and labeled as “rulebook” or “other”. Then, based on the file contents, an ML model was built and trained in order to automatically learn if a file was actually a rulebook: this allowed the extension of the whole dataset with a very high accuracy ratio (>95%).
- Pre-processing and feature extraction included elaborating the textual information, performing stopword removal and computing the textual features’ TF-IDF values;
- Resampling was needed since the categories distribution of the dataset was very unbalanced: only the most frequent categories were kept, each with an equal number of samples.
4.2. Challenge 2—Output Interpretation
- Dataset splitting, cross validation: grid search techniques, combined with cross validation, enabled us to perform a significant number of runs and determine the best parameters for the model;
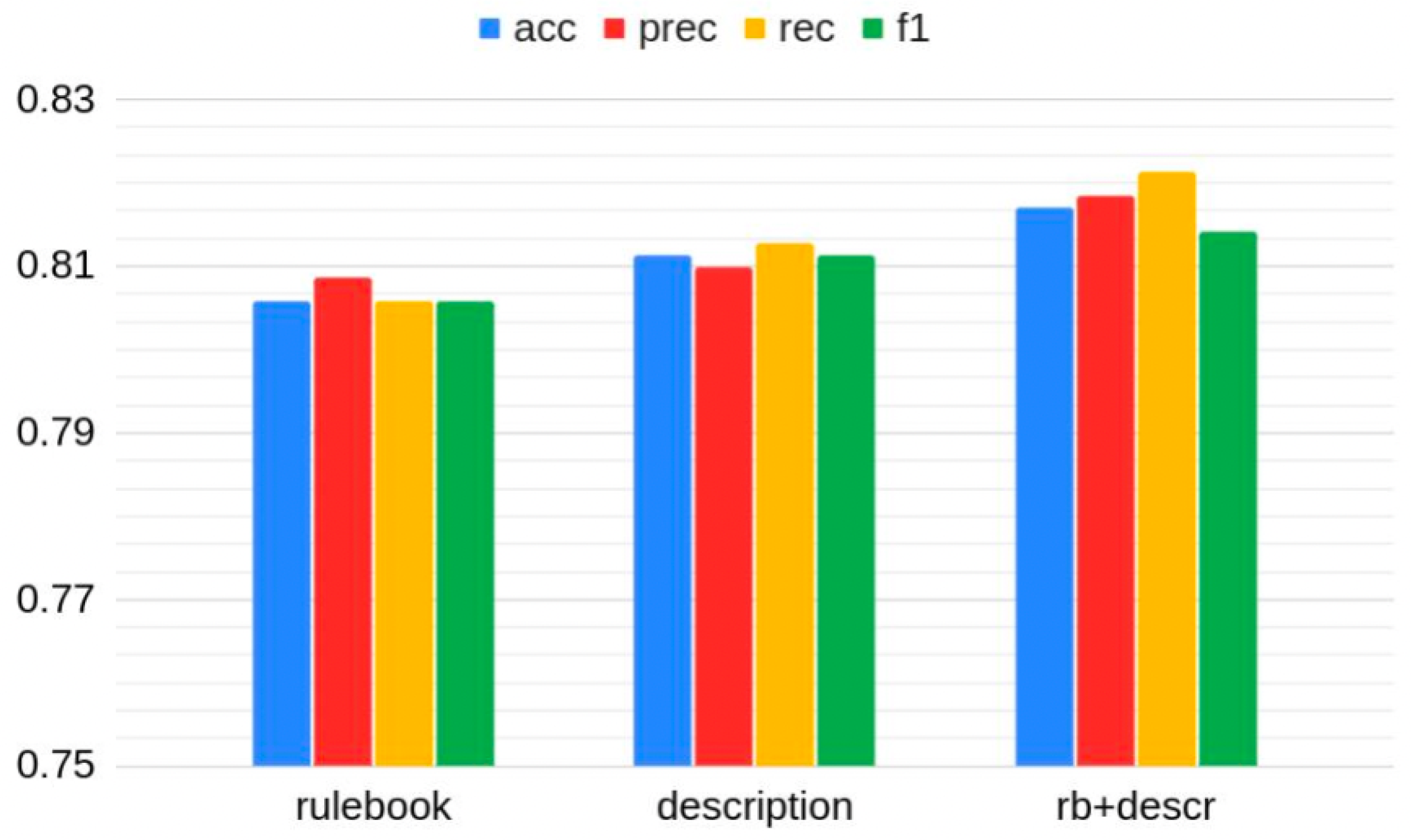
- Different classifiers: Evaluating different classifiers was crucial to determine the best-performing ones for the specific situation; Figure 5 shows the accuracy, precision, recall and f1 levels obtained in the best performing case (Random Forest). As we can see, the accuracy obtained on the “enriched” dataset (also including rulebook information) was quite satisfying (82%);
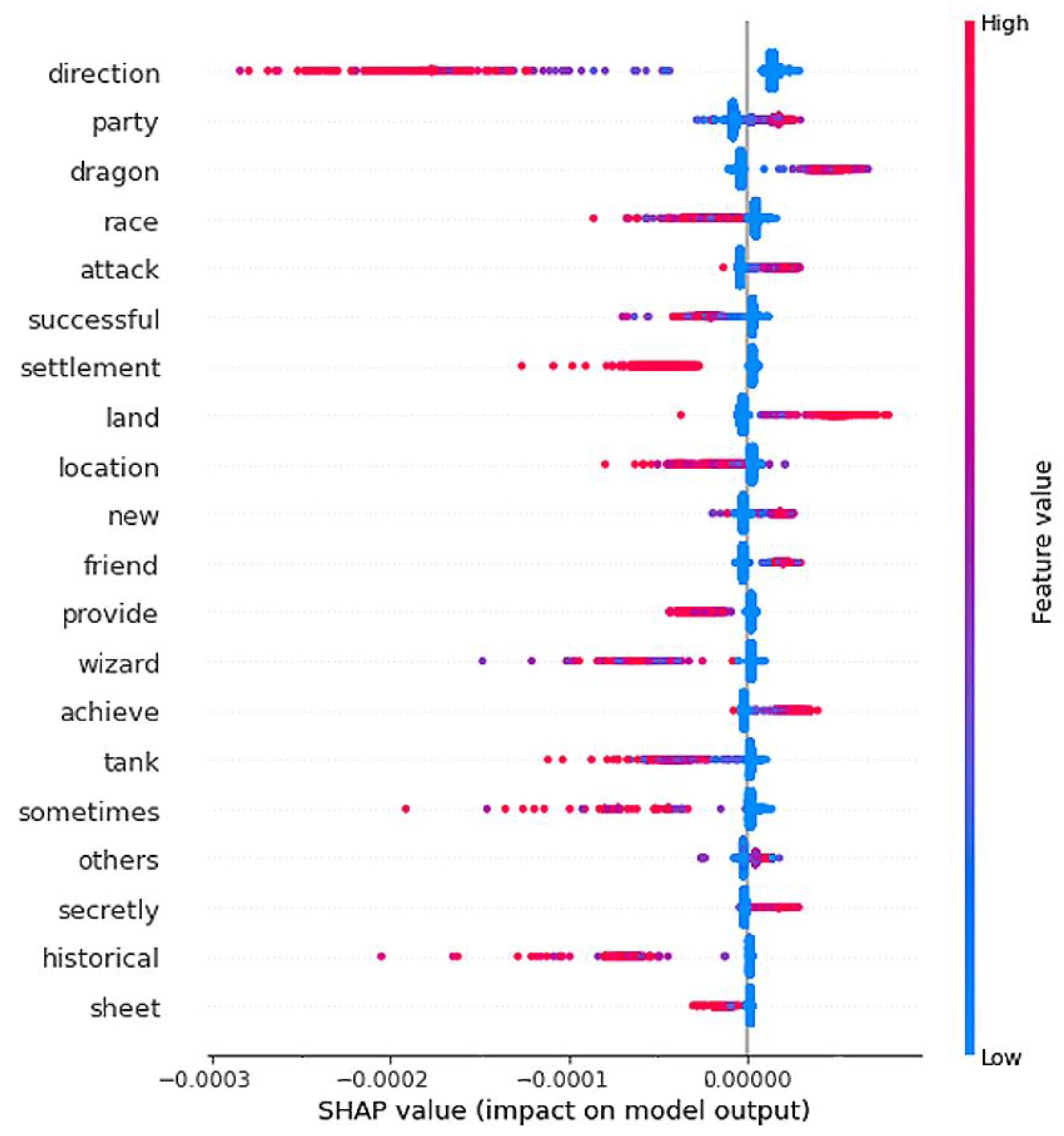
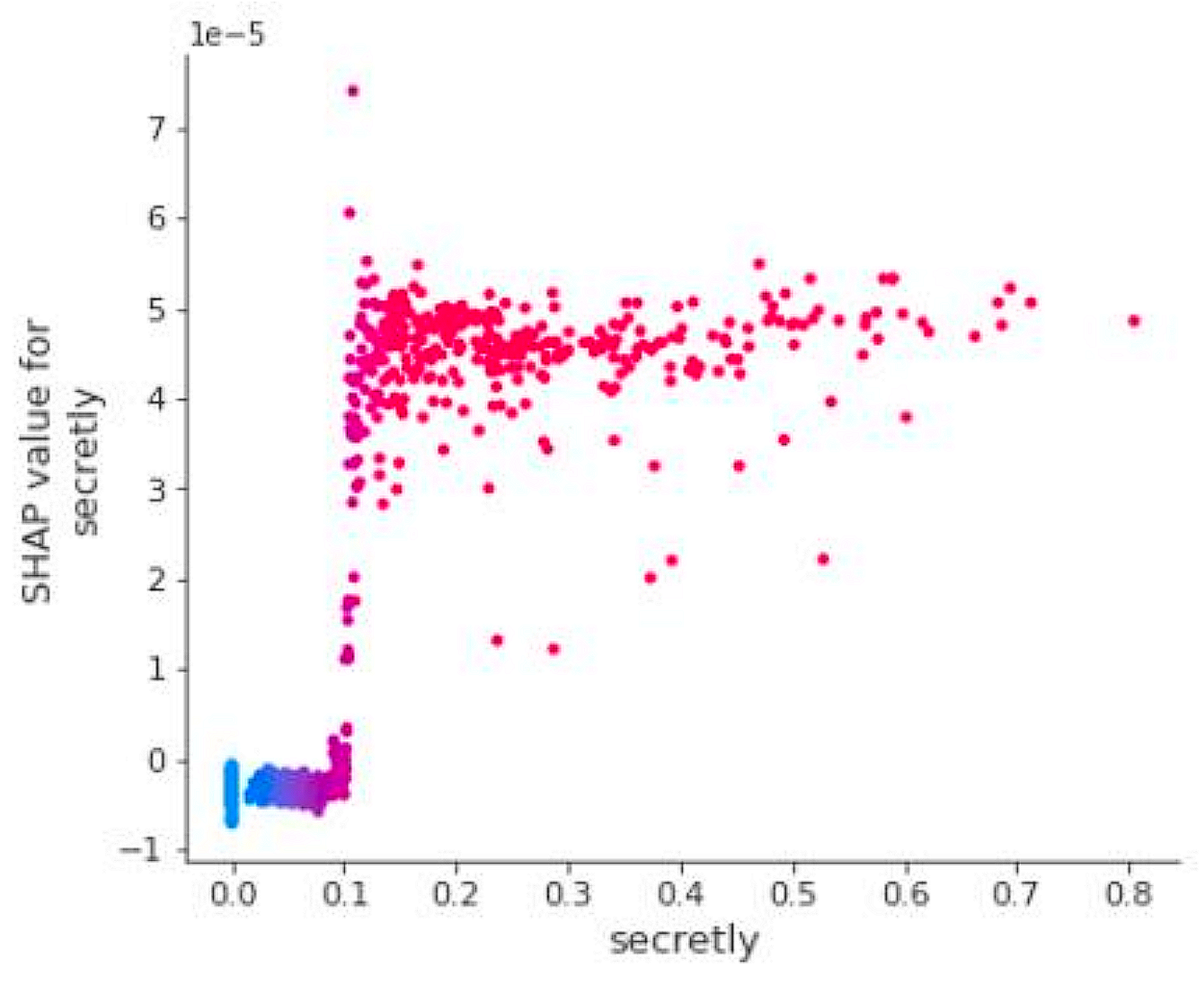
- Model interpretation: Besides accuracy levels, interpreting the models can lead to interesting knowledge. By analyzing the Shapley values in a summary plot (Figure 6 shows the one for the Fantasy category), it is possible to acquire possibly unknown information about the games and their categories, including the most discriminant features (keywords). For instance, terms such as “dragon” and “land” positively connote the category, while others (e.g., “tank”) are typically not found in its games. More in-depth analyses can also be performed by plotting a dependency plot specific to a particular feature (Figure 7 shows an example of the “secretly” feature for the Cardgame category): since the SHAP value of each sample (vertical axis) grows for increasing TF-IDF scores (horizontal axis), we understand that the concept of “having secret information” is indeed typically found in card games but seldom in others. By exploiting insights coming from analyses such as these, the knowledge about games, game categories and game mechanics can be effectively improved.
5. A Short Overview of the Challenges in the Medical and HRM Analytics Scenarios
5.1. Medical Scenario
5.2. Human Resource Management Scenario
6. Related Works
6.1. Scenario 1: Social Network Analytics
6.2. Scenario 2: Game Analytics
6.3. Scenario 3: Medical Analytics
6.4. Scenario 4: HRM Analytics
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Volume of Data/Information Created, Captured, Copied, and Consumed Worldwide from 2010 to 2025. Available online: https://www.statista.com/statistics/871513/worldwide-data-created/ (accessed on 8 June 2022).
- Ahmad, M.A.; Eckert, C.; Teredesai, A.; McKelvey, G. Interpretable Machine Learning in Healthcare. IEEE Intell. Inform. Bull. 2018, 19, 1–7. [Google Scholar]
- Coeckelbergh, M. Artificial Intelligence: Some ethical issues and regulatory challenges. Technol. Regul. 2019, 2019, 31–34. [Google Scholar]
- Broussard, M. Artificial Unintelligence: How Computers Misunderstand the World; MIT Press: Cambridge, MA, USA, 2018. [Google Scholar]
- Yapo, A.; Weiss, J. Ethical Implications of Bias in Machine Learning. 2018. Available online: https://aisel.aisnet.org/hicss-51/os/topics_in_os/6/ (accessed on 5 May 2022).
- Martoglia, R. Invited speech: Data analytics and (interpretable) machine learning for social good. In Proceedings of the 2021 IEEE 23rd Int Conf on High Performance Computing and Communications; 7th Int Conf on Data Science andSystems; 19th Int Conf on Smart City; 7th Int Conf on Dependability in Sensor, Cloud and Big Data Systems and Application (HPCC/DSS/SmartCity/DependSys), Haikou, China, 20–22 December 2021; pp. 2144–2149. [Google Scholar] [CrossRef]
- Chianese, A.; Marulli, F.; Piccialli, F. Cultural heritage and social pulse: A semantic approach for CH sensitivity discovery in social media data. In Proceedings of the IEEE 10th International Conference on Semantic Computing (ICSC), Laguna Hills, CA, USA, 3–5 February 2016; pp. 459–464. [Google Scholar]
- Langa, L. Does Twitter Help Museums Engage with Visitors? Proc. iConference 2014, 484–495. [Google Scholar] [CrossRef]
- Furini, M.; Mandreoli, M.; Martoglia, R.; Montangero, M. 5 steps to make art museums tweet influentially. In Proceedings of the 3rd International Workshop on Social Sensing, SocialSens, Orlando, FL, USA, 17 April 2018. [Google Scholar]
- Furini, M.; Mandreoli, F.; Martoglia, R.; Montangero, M. A Predictive Method to Improve the Effectiveness of Twitter Communication in a Cultural Heritage Scenario. ACM J. Comput. Cult. Herit. 2022, 15, 1–18. [Google Scholar] [CrossRef]
- Furini, M.; Mandreoli, F.; Martoglia, R.; Montangero, M. The use of hashtags in the promotion of art exhibitions. In Proceedings of the 13th Italian Research Conference on Digital Libraries (IRCDL), Revised Selected Papers, Modena, Italy, 26–27 January 2017; pp. 187–198. [Google Scholar]
- Furini, M.; Mandreoli, F.; Martoglia, R.; Montangero, M. Towards tweet content suggestions for museum media managers. In Proceedings of the 4th EAI International Conference on Smart Objects and Technologies for Social Good, Bologna, Italy, 28–30 November 2018; pp. 265–270. [Google Scholar]
- Martoglia, R.; Montangero, M. An intelligent dashboard for assisted tweet composition in the cultural heritage area (work-in-progress). In Proceedings of the 6th EAI International Conference on Smart Objects and Technologies for Social Good, Antwerp, Belgium, 14–16 September 2020; pp. 226–229. [Google Scholar]
- Kase, S.E.; Bowman, E.K. Operating in the new information environment: An army vision of social sensing? In Proceedings of the 2018 International Workshop on Social Sensing (SocialSens), Orlando, FL, USA, 17 April 2018; IEEE Computer Society: Los Alamitos, CA, USA, 2018; pp. 1–11. [Google Scholar]
- Giachanou, A.; Crestani, F. Like It or Not: A Survey of Twitter Sentiment Analysis Methods. ACM Comput. Surv. 2016, 49, 1–41. [Google Scholar] [CrossRef]
- Aston, N.; Liddle, J.; Hu, W. Twitter Sentiment in Data Streams with Perceptron. J. Comput. Commun. 2014, 2, 11–16. [Google Scholar] [CrossRef]
- Hu, X.; Tang, J.; Gao, H.; Liu, H. Unsupervised sentiment analysis with emotional signals. In Proceedings of the 22nd International Conference on World Wide Web, Rio de Janeiro, Brazil, 13–17 May 2013. [Google Scholar]
- Hamari, J.; Koivisto, J.; Sarsa, H. Does gamification work?—A literature review of empirical studies on gamification. In Proceedings of the 2014 47th Hawaii International Conference on System Sciences, Waikoloa, HI, USA, 6–9 January 2014; pp. 3025–3034. [Google Scholar]
- Cook, M.; Colton, S.; Gow, J.; Smith, G. General analytical techniques for parameter-based procedural content generators. In Proceedings of the IEEE Conference on Games, CoG 2019, London, UK, 20–23 August 2019; pp. 1–8. [Google Scholar]
- Kowalski, J.; Miernik, R.; Mika, M.; Pawlik, W.; Sutowicz, J.; Szykula, M.; Tkaczyk, A. Efficient reasoning in regular boardgames. In Proceedings of the IEEE Conference on Games, CoG 2020, Osaka, Japan, 24–27 August 2020; pp. 455–462. [Google Scholar]
- Martoglia, R.; Pontiroli, M. Let the games speak by themselves: Towards game features discovery through data-driven analysis and explainable AI. In Proceedings of the 2021 IEEE 23rd Int Conf on High Performance Computing and Communications; 7th Int Conf on Data Science and Systems; 19th Int Conf on Smart City; 7th Int Conf on Dependability in Sensor, Cloud and Big Data Systems and Application (HPCC/DSS/SmartCity/DependSys), Haikou, China, 20–22 December 2021; pp. 2332–2337. [Google Scholar] [CrossRef]
- Konen, W. General board game playing for education and research in generic AI game learning. In Proceedings of the IEEE Conference on Games, CoG 2019, London, UK, 20–23 August 2019; pp. 1–8. [Google Scholar]
- Rabbi, M.; Ali, S.; Choudhury, T.; Berke, E. Passive and in-situ assessment of mental and physical well-being using mobile sensors. In Proceedings of the 13th International Conference on Ubiquitous Computing, Beijing, China, 17–21 September 2011; pp. 385–394. [Google Scholar]
- Veličković, P.; Karazija, L.; Lane, N.D.; Bhattacharya, S.; Liberis, E.; Lio, P.; Chien, A.; Bellahsen, O.; Vegreville, M. Cross-modal recurrent models for weight objective prediction from multimodal time-series data. In Proceedings of the 12th EAI International Conference on Pervasive Computing Technologies for Healthcare, New York, NY, USA, 21–24 May 2018; pp. 178–186. [Google Scholar]
- Ferrari, D.; Guaraldi, G.; Mandreoli, F.; Martoglia, R.; Milic, J.; Missier, P. Data-driven vs. knowledge-driven inference of health outcomes in the ageing population: A case study. In Proceedings of the 4th International Workshop on Data Analytics Solutions for Real-Life Applications, Co-Located with EDBT/ICDT 2020 Joint Conference (DARLI-AP EDBT 2020), Copenhagen, Denmark, 30 March 2020. [Google Scholar]
- Vischioni, C.; Bove, F.; Mandreoli, F.; Martoglia, R.; Pisi, V.; Taccioli, C. Visual Exploratory Data Analysis for Copy Number Variation Studies in Biomedical Research. Big Data Res. 2022, 27, 100298. [Google Scholar] [CrossRef]
- Bove, F.; Mandreoli, F.; Martoglia, R.; Pisi, V.; Taccioli, C.; Vischioni, C. VarCopy: A visual exploratory data analysis platform for copy number variation studies. In Proceedings of the 24 International Conference Information Visualisation (iV 2020), Melbourne, VIC, Australia, 7–11 September 2020. [Google Scholar]
- Ghidoni, G.; Martoglia, R.; Taccioli, C.; Vischioni, C. InstaCircos: A web application for fast and interactive circular visualization of large genomic data. In Proceedings of the 24 International Conference Information Visualisation (iV 2020), Melbourne, VIC, Australia, 7–11 September 2020. [Google Scholar]
- Guidotti, R.; Monreale, A.; Ruggieri, S.; Turini, F.; Giannotti, F.; Pedreschi, D. A survey of methods for explaining black box models. ACM Comput. Surv. 2018, 51, 1–42. [Google Scholar] [CrossRef]
- Gilpin, L.H.; Bau, D.; Yuan, B.Z.; Bajwa, A.; Specter, M.; Kagal, L. Explaining explanations: An overview of interpretability of machine learning. In Proceedings of the 2018 IEEE 5th International Conference on Data Science and Advanced Analytics (DSAA), Turin, Italy, 1–3 October 2018; pp. 80–89. [Google Scholar]
- Fabbri, T. Digital work: An organizational perspective. In Working in Digital and Smart Organizations—Legal, Economic and Organizational Perspectives on the Digitalization of Labour Relations; Senatori, I., Ales, E., Eds.; Palgrave/MacMillan: London, UK, 2018. [Google Scholar]
- March, J.G.; Simon, H.A. Organizations; Wiley and Sons: Hoboken, NJ, USA, 1958. [Google Scholar]
- McAbee, S.T.; Landis, R.S.; Burke, M.I. Inductive reasoning: The promise of big data. Hum. Resour. Manag. Rev. 2017, 27, 277–290. [Google Scholar] [CrossRef]
- Bertolotti, F.; Fabbri, T.; Mandreoli, F.; Martoglia, R.; Scapolan, A. Work datafication and digital work behavior analysis as a source of social good. In Proceedings of the IEEE Consumer Communications and Networking Conference (CCNC), Las Vegas, NV, USA, 10–13 January 2020. [Google Scholar]
- Ng, T.W.; Feldman, D.C. Organizational embeddedness and occupational embeddedness across career stages. J. Vocat. Behav. 2007, 70, 336–351. [Google Scholar] [CrossRef]
- Bertolotti, F.; Fabbri, T.; Mandreoli, F.; Martoglia, R.; Muzzini, F.; Scapolan, A. Modelling Employees’ Attitudes through Digital “Exhausts”: A First Experiment; University of Modena and Reggio Emilia: Modena, Italy, 2022; submitted. [Google Scholar]
- Fabbri, T.; Mandreoli, F.; Martoglia, R.; Scapolan, A. Employee attitudes and (digital) collaboration data: A preliminary analysis in the HRM field. In Proceedings of the International Workshop on Social Media Sensing (SMS’19 @ IEEE ICCCN), Valencia, Spain, 29 July–1 August 2019. [Google Scholar]
- Schwade, F.; Schubert, P. Social collaboration analytics for enterprise collaboration systems: Providing business intelligence on collaboration activities. In Proceedings of the 50th Hawaii International Conference on System Sciences (2017), Hilton, HI, USA, 4–7 January 2017. [Google Scholar]
- Wehner, B.; Ritter, C.; Leist, S. Enterprise social networks: A literature review and research agenda. Comput. Netw. 2017, 114, 125–142. [Google Scholar] [CrossRef]
- Wu, B.; Shen, H. Analyzing and Predicting News Popularity on Twitter. Int. J. Inf. Manag. 2015, 35, 702–711. [Google Scholar] [CrossRef]
- Zhang, L.; Peng, T.; Zhang, Y.; Wang, X.; Zhu, J.J.H. Content or context: Which matters more in information processing on microblogging sites. Comput. Hum. Behav. 2014, 31, 242–249. [Google Scholar] [CrossRef]
- Gao, S.; Ma, J.; Chen, Z. Effective and Effortless Features for Popularity Prediction in Microblogging Network. In Proceedings of the 23rd International Conference on World Wide Web, Seoul, Korea, 7–11 April 2014; pp. 269–270. [Google Scholar]
- Zhao, Q.; Erdogdu, M.A.; He, H.Y.; Rajaraman, A.; Leskovec, J. SEISMIC: A self-exciting point process model for predicting tweet popularity. In Proceedings of the 21th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, NSW, Australia, 10–13 August 2015; pp. 1513–1522. [Google Scholar]
- Woodward, P.; Woodward, S. Mining the BoardGameGeek. Significance 2019, 16, 24–29. [Google Scholar] [CrossRef]
- Kohli, S. Predicting Board Game Reviews using KMeans Clustering & Linear Regression. 2016. Available online: https://guneetkohli.github.io/machine-learning/board-game-reviews/#.YD1oo2hKjIU (accessed on 5 May 2022).
- Kritz, J.; Mangeli, E.; Xexéo, G. Building an Ontology of Boardgame Mechanics based on the BoardGameGeek Database and the MDA Framework. SBGames 2017, 16, 182–191. [Google Scholar]
- Van Gerwen, R. Exploring the Relationship between Motivation, Mechanics and Genre for Tabletop Games. Ph.D. Thesis, Tilburg University, Tilburg, The Netherlands, 2019. [Google Scholar]
- Nori, H.; Jenkins, S.; Koch, P.; Caruana, R. InterpretML: A Unified Framework for Machine Learning Interpretability. arXiv 2019, arXiv:1909.09223. [Google Scholar]
- Ustun, B.; Rudin, C. Supersparse Linear Integer Models for Optimized Medical Scoring Systems. Mach. Learn. 2015, 102, 349–391. [Google Scholar] [CrossRef]
- Lundberg, S.; Nair, B.; Vavilala, M.; Horibe, M.; Eisses, M.J.; Adams, T.; Liston, D.E.; Low, D.K.-W.; Newman, S.-F.; Kim, K.; et al. Explainable machine learning predictions to help anesthesiologists prevent hypoxemia during surgery. Nat. Biomed. Eng. 2018, 2, 749–760. [Google Scholar] [CrossRef] [PubMed]
- Lundberg, S.; Lee, S. A unified approach to interpreting model predictions. In Advances in Neural Information Processing Systems 30; Guyon, I., Luxburg, U.V., Bengio, S., Wallach, H., Fergus, R., Vishwanathan, S., Garnett, R., Eds.; Curran Associates, Inc.: New York, NY, USA, 2017; pp. 4765–4774. [Google Scholar]
- Shapley, L.S. A value for n-person games. Contributions to the Theory of Games; Princeton University Press: Princeton, NJ, USA, 1953; Volume 2. [Google Scholar]
- Behrendt, S.; Richter, A.; Trier, M. Mixed methods analysis of enterprise social networks. Comput. Netw. 2014, 13, 9266. [Google Scholar] [CrossRef]
- Al-garadi, M.A.; Varathan, K.D.; Ravana, S.D.; Ahmed, E.; Shaikh, G.M.; Khan, M.U.S.; Khan, S.U. Analysis of Online Social Network Connections for Identification of Influential Users: Survey and Open Research Issues. ACM Comput. Surv. 2018, 51, 1–37. [Google Scholar] [CrossRef]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Museum Group | Accuracy |
|---|---|
| Group 1 | 87.63% |
| Group 2 | 92.65% |
| Group 3 | 81.29% |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Martoglia, R.; Montangero, M. About Challenges in Data Analytics and Machine Learning for Social Good. Information 2022, 13, 359. https://doi.org/10.3390/info13080359
Martoglia R, Montangero M. About Challenges in Data Analytics and Machine Learning for Social Good. Information. 2022; 13(8):359. https://doi.org/10.3390/info13080359
Chicago/Turabian StyleMartoglia, Riccardo, and Manuela Montangero. 2022. "About Challenges in Data Analytics and Machine Learning for Social Good" Information 13, no. 8: 359. https://doi.org/10.3390/info13080359
APA StyleMartoglia, R., & Montangero, M. (2022). About Challenges in Data Analytics and Machine Learning for Social Good. Information, 13(8), 359. https://doi.org/10.3390/info13080359