
Queuing-Based Federation and Optimization for Cloud Resource Sharing

Abstract
:1. Introduction
- We modeled the cloud system based on queuing theory, and constructed the utility function for cloud federation, which consists of the value of service and the cost of users’ time.
- Based on the queuing model, we obtained an optimal request allocation rule among the over-provision cloud providers. Hence, we derived a Pareto-optimal light-federation sharing scheme that could improve the net utility of cloud federation through a simplifying running mechanism.
- Furthermore, to obtain optimal net utility of cloud federation, we design a cloud cooperative federation sharing solution with Banzhaf value-based payoff division, and derived a fair cloud federation.
2. Related Work
- In our work, we address the federation of private clouds while taking into account both the service valuation brought by cloud resources and the cost of inner users for waiting time. Thus, the objective of our work was to improve the net utility of cloud federation.
- To avoid complex computation for request and profit allocation in a fully cooperative federation, we designed a simplified federation method which does not require complex computation, and the performance is still close to that of the fully cooperative federation scheme.
3. System Model
4. Cloud Resource Sharing Solutions
4.1. Cloud-Light Federation: From the Non-Cooperative Game Perspective
4.1.1. Light-Federation Scenario
- Step 1: The broker receives the dropped service requests with rate submitted by all under-provisioning CPs.
- Step 2: The broker allocates the received requests to over-provisioning CPs.
- Step 3: The broker allocates the profits to over-provisioning CPs according to their added requests which come from under-provisioning CPs and are processed by over-provisioning CPs.
4.1.2. Cloud Light-Federation Sharing (CLFS)
| Algorithm 1: Service request allocation algorithm in CLFS. |
 |
- Case 1: (), that is, all the CPs are in over-provisioning state. In this case, any reallocation for service requests will decrease the utility of CPs who lose service requests.
- Case 2: , and there exits in over-provisioning without obtaining request allocation after allocation ( ). In this case, all the CPs with must still be in over-provisioning state, and the CPs with are in an optimal state, since . Any reallocation among the over-provisioning state will decrease the utility of CPs who lose service requests, and increasing or decreasing the service requests for CPs in an optimal state will decrease their utility too.
- Case 3: , and after the request allocation of the broker, all the CPs in over-provisioning state obtain request allocation. That is, all cloud providers in will either still be in an over-provisioning state or change to an under-provisioning state. In the former case, each CP will have decreased utility if there is a decrease the service request allocation. In the later case, these CPs will be in an optimal state by dropping overfull service requests, to obtain optimal utility, and no further allocation could improve utility.
4.2. Cloud Cooperative-Federation: From the Perspective of a Coalition Game
4.2.1. The Properties of Cloud Cooperative-Federation
| Algorithm 2: Service request allocation algorithm in CCFS. |
 |
4.2.2. Profit Sharing in CCF
5. Performance Evaluation
5.1. Experiment Setup
5.2. Result Analysis
6. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Tak, B.C.; Urgaonkar, B.; Sivasubramaniam, A. To Move or Not to Move: The Economics of Cloud Computing. In Proceedings of the 3rd USENIX Conference on Hot Topics in Cloud Computing, (HotCloud’11), Berkeley, CA, USA, 14–15 June 2011; p. 5. [Google Scholar]
- Mohammed, A.B.; Altmann, J.; Hwang, J. Cloud Computing Value Chains: Understanding Businesses and Value Creation in the Cloud. In Economic Models and Algorithms for Distributed Systems; Neumann, D., Baker, M., Altmann, J., Rana, O., Eds.; Birkhäuser: Basel, Belgium, 2010; pp. 187–208. [Google Scholar] [CrossRef]
- Omri, A.; Benouaret, K.; Benslimane, D.; Omri, M.N. Towards an understanding of cloud services under uncertainty: A possibilistic approach. Int. J. Approx. Reason. 2018, 98, 146–162. [Google Scholar] [CrossRef]
- Darzanos, G.; Koutsopoulos, I.; Stamoulis, G.D. A model for evaluating the economics of cloud federation. In Proceedings of the 2015 IEEE 4th International Conference on Cloud Networking (CloudNet), Niagara Falls, ON, Canada, 5–7 October 2015; pp. 291–296. [Google Scholar]
- Mashayekhy, L.; Nejad, M.M.; Grosu, D. Cloud Federations in the Sky: Formation Game and Mechanism. Cloud Comput. IEEE Trans. 2015, 3, 14–27. [Google Scholar] [CrossRef]
- Halabi, T.; Bellaiche, M. Towards Security-based Formation of Cloud Federations: A Game Theoretical Approach. IEEE Trans. Cloud Comput. 2018, 8, 928–942. [Google Scholar] [CrossRef]
- Abdi, S.; Pourkarimi, L.; Ahmadi, M.; Zargari, F. Cost minimization for bag-of-tasks workflows in a federation of clouds. J. Supercomput. 2018, 74, 1–22. [Google Scholar] [CrossRef]
- Ray, B.K.; Saha, A.; Khatua, S.; Roy, S. Toward maximization of profit and quality of cloud federation: Solution to cloud federation formation problem. J. Supercomput. 2019, 75, 885–929. [Google Scholar] [CrossRef]
- Rubio-Montero, A.J.; Rodr aguez Pascual, M.A.; Mayo-Garca, R. A simple model to exploit reliable algorithms in cloud federations. Soft Comput. 2016, 21, 1–13. [Google Scholar] [CrossRef]
- Rochwerger, B.; Breitgand, D.; Levy, E.; Galis, A. The Reservoir model and architecture for open federated cloud computing. Ibm J. Res. Dev. 2009, 53, 535–545. [Google Scholar] [CrossRef] [Green Version]
- Buyya, R.; Ranjan, R.; Calheiros, R.N. InterCloud: Utility-Oriented Federation of Cloud Computing Environments for Scaling of Application Services; Springer: Berlin/Heidelberg, Germany, 2010; pp. 13–31. [Google Scholar]
- Celesti, A.; Tusa, F.; Villari, M.; Puliafito, A. How to Enhance Cloud Architectures to Enable Cross-Federation. In Proceedings of the IEEE International Conference on Cloud Computing, Miami, FL, USA, 5–10 July 2010; pp. 337–345. [Google Scholar]
- Bernstein, D.; Ludvigson, E.; Sankar, K.; Diamond, S. Blueprint for the Intercloud-Protocols and Formats for Cloud Computing Interoperability. In Proceedings of the International Conference on Internet and Web Applications and Services, Washington, DC, USA, 24–28 May 2009; pp. 328–336. [Google Scholar]
- Marosi, A.; Kecskemeti, G.; Kertesz, A.; Kacsuk, P. FCM: An Architecture for Integrating IAAS Cloud Systems. In Proceedings of the International Conference on Cloud Computing, GRIDs, and Virtualization, Rome, Italy, 25–30 September 2011; pp. 7–12. [Google Scholar]
- Yuan, H.; Bi, J.; Tan, W.; Zhou, M.; Li, B.H.; Li, J. TTSA: An Effective Scheduling Approach for Delay Bounded Tasks in Hybrid Clouds. IEEE Trans. Cybern. 2016, 3658–3668. [Google Scholar] [CrossRef]
- Hadji, M.; Zeghlache, D. Mathematical Programming Approach for Revenue Maximization in Cloud Federations. IEEE Trans. Cloud Comput. 2015, 5, 99–111. [Google Scholar] [CrossRef]
- Gouasmi, T.; Louati, W.; Kacem, A.H. Exact and heuristic MapReduce scheduling algorithms for cloud federation. Comput. Electr. Eng. 2018, 69, 274–286. [Google Scholar] [CrossRef]
- Ahmed, U.; Al-Saidi, A.; Petri, I.; Rana, O.F. QoS-aware trust establishment for cloud federation. Concurr. Comput. Pract. Exp. 2021, 34, e6598. [Google Scholar] [CrossRef]
- Rosa, M.; Ralha, C.G.; Holanda, M.; Araujo, A. Computational resource and cost prediction service for scientific workflows in federated clouds. Future Gener. Comput. Syst. 2021, 125, 844–858. [Google Scholar] [CrossRef]
- Shi, Z.; Farshidi, S.; Zhou, H.; Zhao, Z. An Auction and Witness Enhanced Trustworthy SLA Model for Decentralized Cloud Marketplaces. In Proceedings of the GoodIT ’21: Conference on Information Technology for Social Good, Rome, Italy, 9–11 September 2021; Gaggi, O., Manzoni, P., Palazzi, C.E., Eds.; ACM: New York, NY, USA, 2021; pp. 109–114. [Google Scholar] [CrossRef]
- Goiri, I.; Guitart, J.; Torres, J. Economic Model of a Cloud Provider Operating in a Federated Cloud. Inf. Syst. Front. 2012, 14, 827–843. [Google Scholar] [CrossRef] [Green Version]
- Samaan, N. A Novel Economic Sharing Model in a Federation of Selfish Cloud Providers. IEEE Trans. Parallel Distrib. Syst. 2014, 25, 12–21. [Google Scholar] [CrossRef]
- Hassan, M.M.; Hossain, M.S.; Sarkar, A.M.J.; Huh, E.N. Cooperative game-based distributed resource allocation in horizontal dynamic cloud federation platform. Inf. Syst. Front. 2012, 16, 523–542. [Google Scholar] [CrossRef]
- Khandelwal, Y.; Ganti, K.; Purini, S.; Reddy, P.V. Cloud Federation Formation in Oligopolistic Markets. In Proceedings of the European Conference on Parallel Processing, Turin, Italy, 26–30 August 2018; pp. 392–403. [Google Scholar]
- Chen, H.; Bo, A.; Niyato, D.; Soh, Y.; Miao, C. Workload Factoring and Resource Sharing via Joint Vertical and Horizontal Cloud Federation Networks. IEEE J. Sel. Areas Commun. 2017, 35, 1. [Google Scholar] [CrossRef]
- Ata, B.; Shneorson, S. Dynamic Control of an M/M/1 Service System with Adjustable Arrival and Service Rates. Manag. Sci. 2006, 52, 1778–1791. [Google Scholar] [CrossRef] [Green Version]
- Dewan, S.; Mendelson, H. User Delay Costs and Internal Pricing for a Service Facility. Manag. Sci. 1990, 36, 1502–1517. [Google Scholar] [CrossRef]
- Fan, M.; Kumar, S.; Whinston, A.B. Short-term and long-term competition between providers of shrink-wrap software and software as a service. Eur. J. Oper. Res. 2009, 196, 661–671. [Google Scholar] [CrossRef]
- Jhang-Li, J.H.; Chiang, I.R. Resource allocation and revenue optimization for cloud service providers. Decis. Support Syst. 2015, 77, 55–66. [Google Scholar] [CrossRef]
- Mendelson, H. Pricing Computer Services: Queuing Effects. Commun. ACM 1985, 28, 312–321. [Google Scholar] [CrossRef]
- Mendelson, H.; Whang, S. Optimal Incentive-Compatible Priority Pricing for the M/M/1 Queue. Oper. Res. 1990, 38, 870–883. [Google Scholar] [CrossRef]
- Nisan, N.; Roughgarden, T.; Tardos, É.; Vazirani, V.V. (Eds.) Algorithmic Game Theory; Cambridge University Press: Cambridge, UK, 2007. [Google Scholar]
- Matsui, Y.; Matsui, T. NP-completeness for Calculating Power Indices of Weighted Majority Games. Theor. Comput. Sci. 2001, 263, 305–310. [Google Scholar] [CrossRef] [Green Version]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Job Process Rate | Job Arrival Rate | |
|---|---|---|
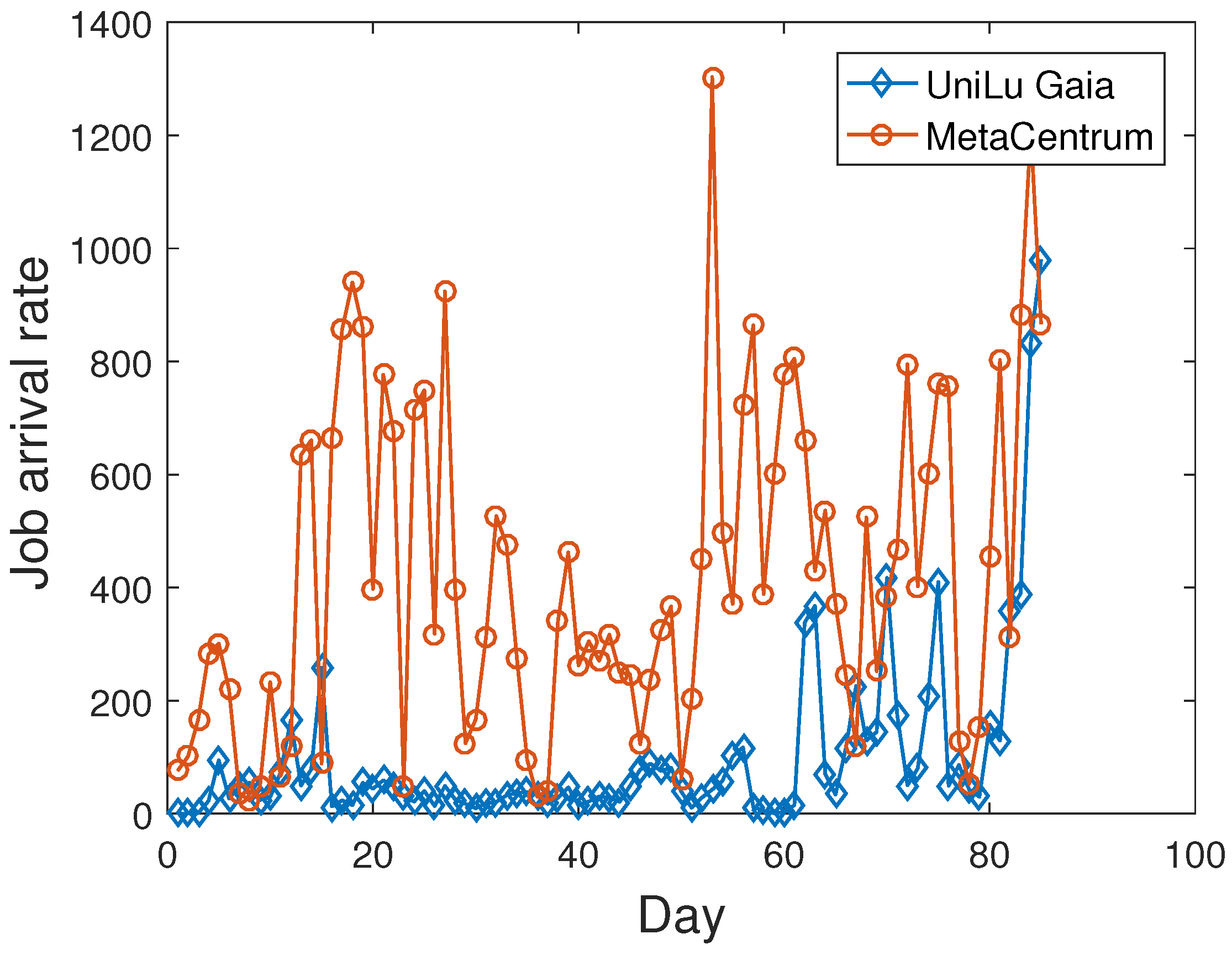
| Two-player (1) | , | Obtained by workload log |
| of MetaCentrum () and UniLu Gaia () | ||
| Two-player (2) | , | Obtained by workload log |
| of MetaCentrum () and UniLu Gaia () | ||
| Three-player | , , , | Generated randomly with , , |
| Multi-player | Generated randomly with | Generated randomly with |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wu, S.; Wu, Z.; Wu, X.; Tao, J.; Gu, Y. Queuing-Based Federation and Optimization for Cloud Resource Sharing. Information 2022, 13, 361. https://doi.org/10.3390/info13080361
Wu S, Wu Z, Wu X, Tao J, Gu Y. Queuing-Based Federation and Optimization for Cloud Resource Sharing. Information. 2022; 13(8):361. https://doi.org/10.3390/info13080361
Chicago/Turabian StyleWu, Shuyou, Zhengxiao Wu, Xiaohong Wu, Jie Tao, and Yonggen Gu. 2022. "Queuing-Based Federation and Optimization for Cloud Resource Sharing" Information 13, no. 8: 361. https://doi.org/10.3390/info13080361