


The Faceted and Exploratory Search for Test Knowledge


Abstract
:1. Introduction
2. Background and Related Work
2.1. Article Relevant Definition
2.2. Knowledge Graph in the Scope of Test Knowledge
2.3. Searchable Information inside a Test Case
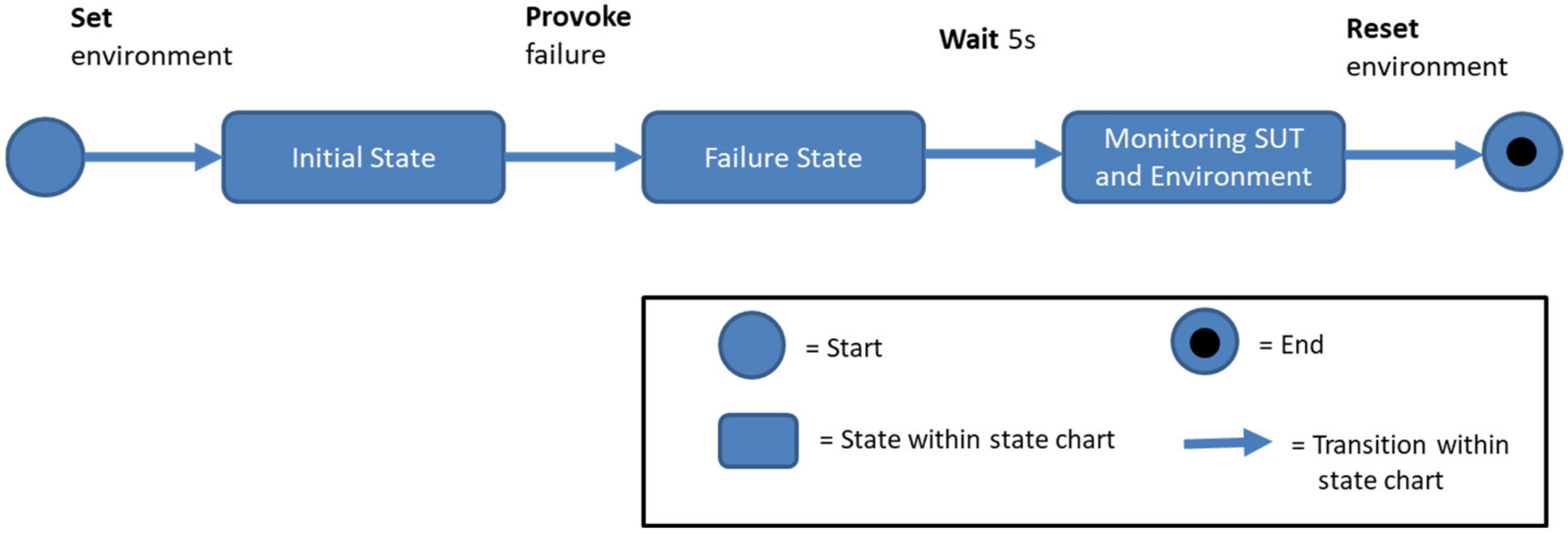
2.3.1. Structure of a Test Case
2.3.2. Structure of Test Script Languages
2.3.3. Heterogeneity in Language Complexity of Test Script Languages
2.4. Summary
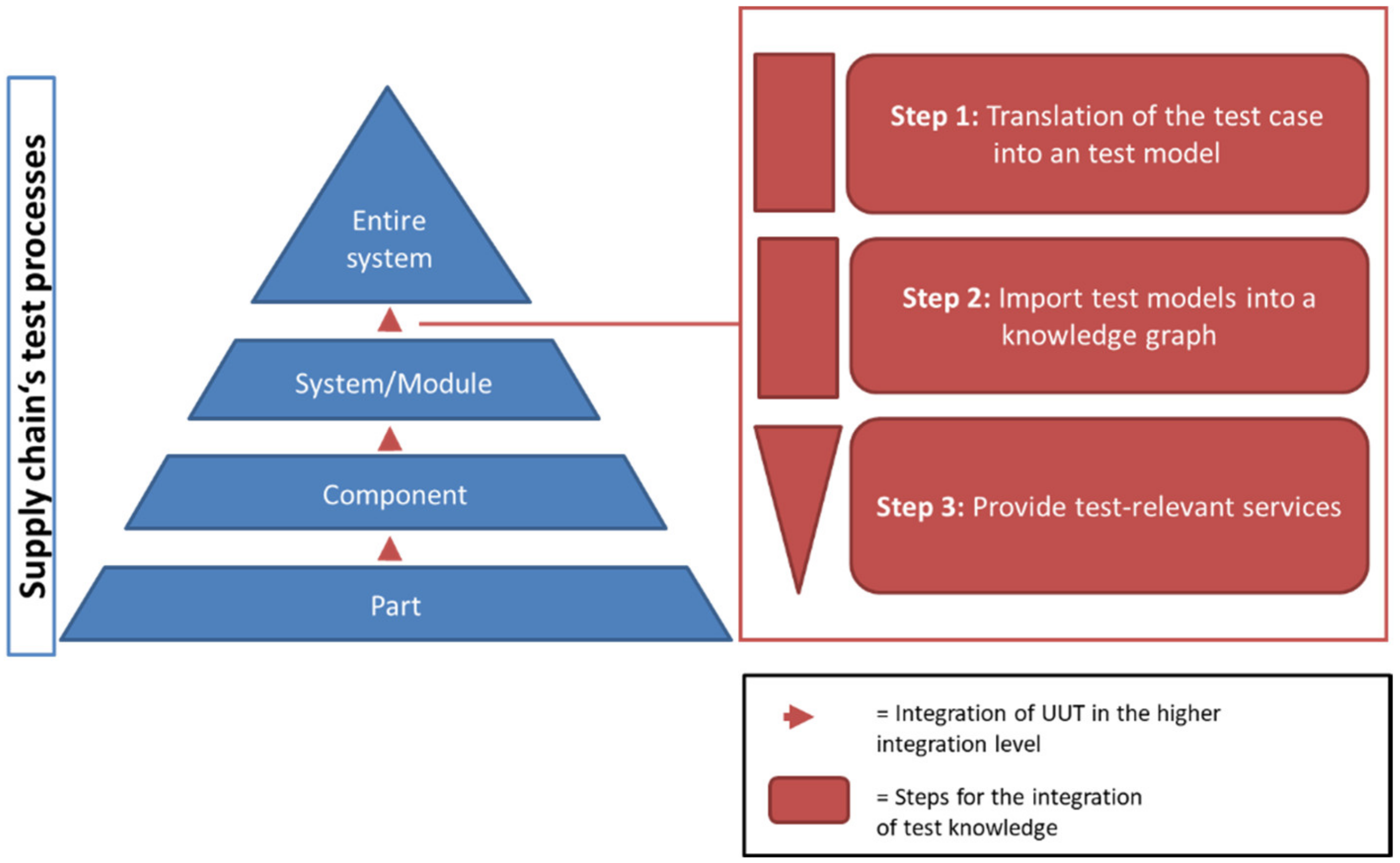
3. Concept of a Knowledge Graph for Test Knowledge
3.1. Step 1: Translation of the Test Case into a Test Model
- The latest version of Generic SCXML introduced TASCXML commands to replace the test automation function represented natively in SCXML states, including its complete semantics;
- A test case’s overall structure is not compatible any longer with the outcome by Rasche et al.;
- The meta-information has been completely revised and is not compatible with the outcome by Rasche et al.
3.2. Step 2: Import Test Models into a Knowledge Graph
3.2.1. Nodes and Labels
3.2.2. Edges and Labels
3.2.3. Graph Definition for Test Cases
3.2.4. Mapping of a Test Case in SCXML to Graph G
3.3. Step 3: Provide Test-Relevant Services
3.3.1. Pattern Language as the Baseline for Explorative Search
lambdaExpression;
3.3.2. Mapping of a Pattern to a Graph Query
4. Evaluation of the Test Knowledge Graph
4.1. Application Scenario
4.2. Example of Look and Feel of the Pattern Search
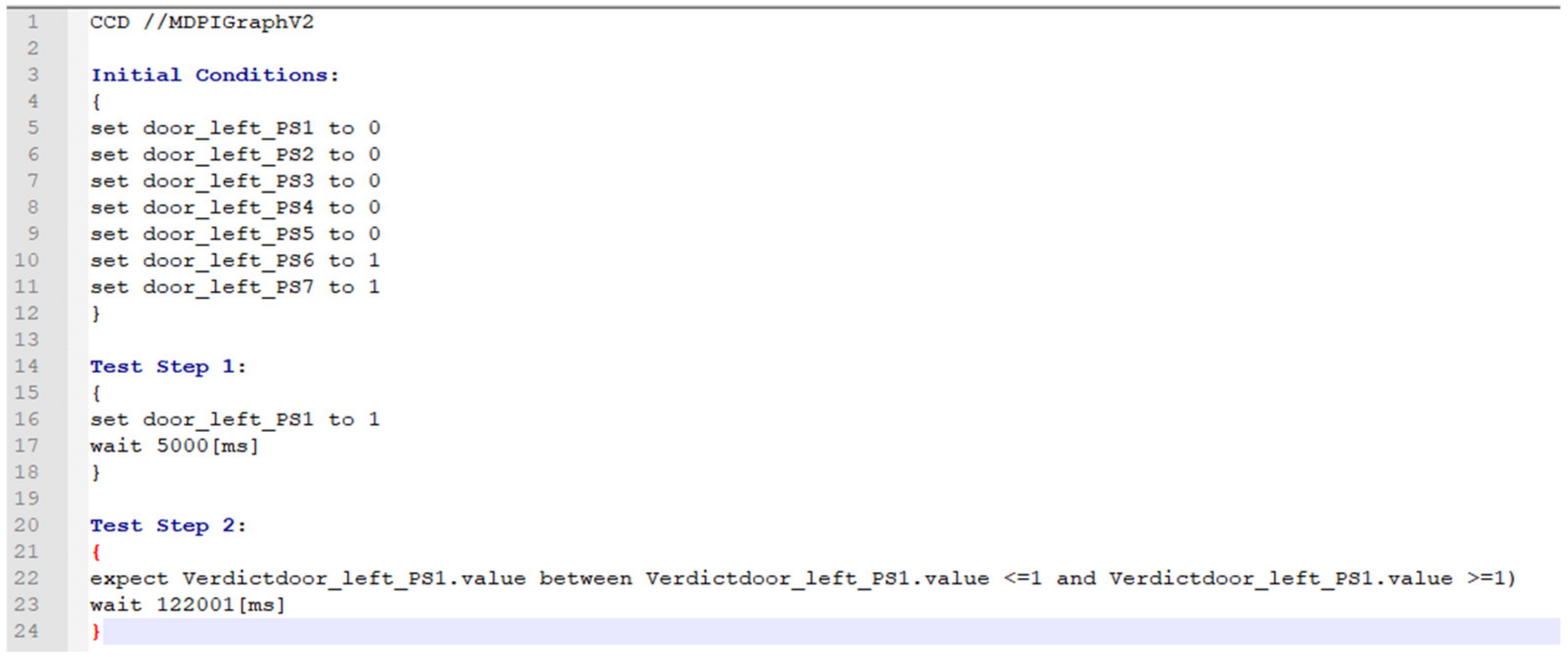
4.2.1. Example of a Test Case as Graph G
4.2.2. Two Examples of the Explorative Search
where x0.variable = ‘door_left_PS1’ and x0.value = ‘0’ WITH DISTINCT s0
RETURN DISTINCT s0.filename,s0.id AS list
‘startup_c0’ RETURN p
where s.filename = ‘MDPIGraphV2’ And s.id = ‘logic_c0_c1_c0’ RETURN p
4.3. Evaluation
4.3.1. Verification of the Search Capabilities by Similarity Search
- All test cases are provided in Generic SCXML, which is a derivate of SCXML for test cases. For that purpose, the original test cases have been translated from Python to Generic SCXML using the step 1 solution;
- The test corpus includes test cases for different doors with the same stimuli and checking the same behaviour. They only differ in specific signal names;
- The test cases for ordinary and emergency operations are similar apart from the emergency-specific signal values.
- The match was 100% for the first door test case. The result returned the exact test case name and the state id of the state in which the pattern was contained;
- The similarity was lower than 100% for the other test cases. The lower similarity value resulted from the different signal names for the other doors. If the user selects a replacement order as described above, the similarity is 33,3% for test cases of the same operational mode. In addition, if the user selects the replacement order to first substitute the signal names with wildcards, the similarity is 66,6% having the same operational mode. The result returned a list of the other 14 test cases defining the test case name and the state id where the pattern starts;
- The match between both variants of the first test case (emergency, ordinary operation) was also lower than 100% because both test cases differ in the signals for the emergency operation. To evaluate this capability, the test case of the first left door for the operational modus ordinary has been translated to a pattern and has been searched inside the Neo4J database. The pattern had a length of 1001 statements, and the calculated similarity to the emergency test case of the first left door was 96.81%;
- The right region of the pattern was found in every test case.
- The original test case is implemented in Python and uses Python libraries to enfold its capabilities. Any string-matching method can only work on the syntax level and could find, for example, the set statement in three different files: At least one file for the implementation, one file of concrete usage and one for the specific configuration of the signal. All three locations define one statement of a pattern. The question is also what should be returned as a search result. Subsequently, if the pattern is extended to two statements, the string-matching method is not applicable anymore. To enable any search for more than 1 statement, the test case and the libraries have to be merged into one single file already contained in step 1 of the solution;
- The definition of a pattern on the syntax level must address a lot of variants because the syntax differs between the test cases while having the same semantics. Moreover, one particular detail of test cases increases the complexity of the supported variants. It should be noted that the executed TASCXML commands are described within Python or within an SCXML state or test script in a sequence, but the semantics here are a set. This means that the order of the TASCXML commands is irrelevant, and this fact should also be considered for regular expressions. This means two different sequences of statements are semantically similar if they include the same set of TASCXML commands. To do this, the individual variations would have to be linked with the or operator, which makes the regular expressions very long and not efficient. Moreover, the built-in search functions in development environments focus on the programming language’s syntax, not semantics, and are, therefore, not applicable. In summary, no solutions are known which enable the search over semantics in test cases from multiple test script languages.
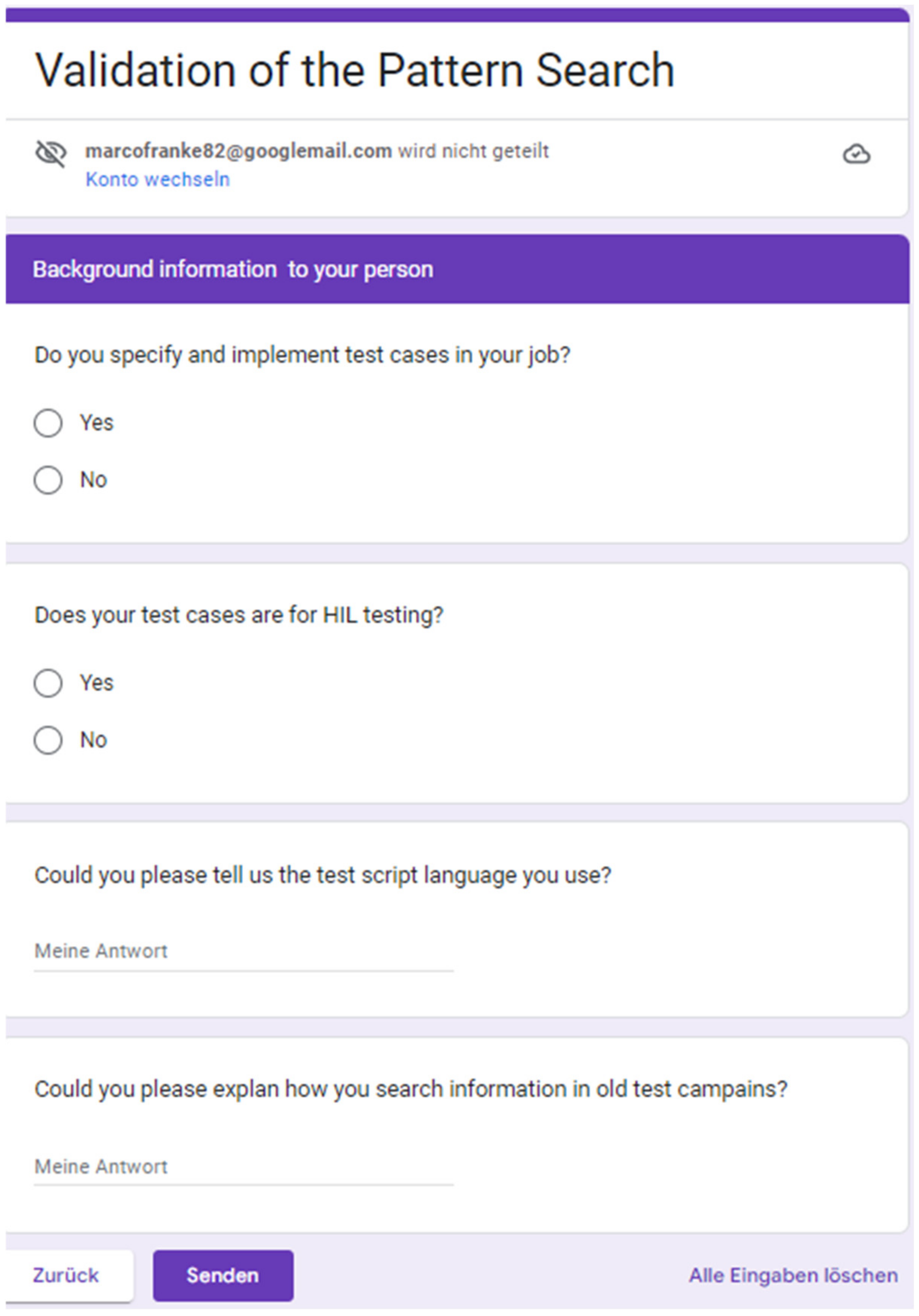
4.3.2. Validation of the Search Capabilities by a Questionnaire
5. Discussions
5.1. Challenges and Findings
5.2. Alignment with Existing Studies
5.3. Implications for Practice
5.4. Limitations and Future Research
6. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Bolton, W. Mechatronics: Electronic Control Systems in Mechanical Engineering; Longman Scientific & Technical: Harlow, UK, 1995; ISBN 0582256348. [Google Scholar]
- Histand, M.B.; Alciatore, D.G. Introduction to Mechatronics and Measurement Systems, international ed.; WCB/McGraw-Hill: Boston, MA, USA, 1999; ISBN 0071163778. [Google Scholar]
- Campetelli, A.; Broy, M. Modelling Logical Architecture of Mechatronic Systems and Its Quality Control. In Automotive Systems Engineering II; Winner, H., Prokop, G., Maurer, M., Eds.; Springer International Publishing: Cham, Switzerland, 2018; pp. 73–91. ISBN 978-3-319-61605-6. [Google Scholar]
- Braid, D.M.; Johnson, C.W.; Schillinger, G.D. An integrated test approach for avionics system development. In Proceedings of the 2001 IEEE/AIAA 20th Digital Avionics Systems Conference, Daytona Beach, FL, USA, 14–18 October 2001; IEEE: Piscataway, NJ, USA; pp. 9B2/1–9B2/9, ISBN 0-7803-7034-1. [Google Scholar]
- Mitra, R.; Jayakumar, S.S.; Kishore, K.R. Proof of Concept on Application of Formal Methods at different phases of development cycle of Avionics Software A Landscaping. INCOSE Int. Symp. 2016, 26, 329–345. [Google Scholar] [CrossRef]
- Franke, M.; Meyer, V.; Rasche, R.; Himmler, A.; Thoben, K.-D. Interoperability of Test Procedures Between Enterprises. In Enterprise Interoperability VIII; Popplewell, K., Thoben, K.-D., Knothe, T., Eds.; Smart Services and Business Impact of Enterprise Interoperability: Cham, Switzerland; Springer International Publishing: New York, NY, USA, 2019; pp. 177–188. ISBN 978-3-030-13693-2. [Google Scholar]
- Rasche, R.; Himmler, A.; Franke, M.; Meyer, V.; Klaus-Dieter, T. (Eds.) Interfacing & Interchanging–Reusing Real-Time Tests for Safety-Critical Systems. In Proceedings of the 2018 AIAA Modeling and Simulation Technologies Conference, Kissimmee, FL, USA, 8–12 January 2018; p. 0123. [Google Scholar]
- Franke, M.; Gerke, D.; Hans, C.; Thoben, K. Functional System Verification. In Air Transport and Operations: Proceedings of the Third International Air Transport and Operations Symposium 2012; IOS Press: Amsterdam, The Netherlands, 2012; p. 36. [Google Scholar]
- Franke, M.; Krause, S.; Thoben, K.-D.; Himmler, A.; Hribernik, K.A. Adaptive Test Feedback Loop: A Modeling Approach for Checking Side Effects during Test Execution in Advised Explorative Testing. In SAE Technical Paper Series; AeroTech, MAR. 17, 2020; SAE International: Warrendale, PA, USA, 2020. [Google Scholar]
- Peleska, J. Industrial-Strength Model-Based Testing-State of the Art and Current Challenges. Electron. Proc. Theor. Comput. Sci. 2013, 111, 3–28. [Google Scholar] [CrossRef]
- Singhal, A. Introducing the Knowledge Graph: Things, Not Strings. Google [Online]. 16 May 2012. Available online: https://blog.google/products/search/introducing-knowledge-graph-things-not/ (accessed on 9 January 2023).
- Guarino, N. Formal Ontology in Information Systems: Proceedings of the First International Conference (FOIS’98), 6–8 June, Trento, Italy; IOS Press: Amsterdam, The Netherlands, 1998; ISBN 9789051993998. [Google Scholar]
- Bizer, C.; Lehmann, J.; Kobilarov, G.; Auer, S.; Becker, C.; Cyganiak, R.; Hellmann, S. DBpedia-A crystallisation point for the Web of Data. J. Web Semant. 2009, 7, 154–165. [Google Scholar] [CrossRef]
- IEEE Std 610.12-1990; IEEE Standard Glossary of Software Engineering Terminology. IEEE Std 610.12-1990; IEEE: Piscataway, NJ, USA, 1990; pp. 1–84.
- Franke, M.; Thoben, K.-D. Interoperable Test Cases to Mediate between Supply Chain’s Test Processes. Information 2022, 13, 498. [Google Scholar] [CrossRef]
- Bonatti, P.A.; Decker, S.; Polleres, A.; Presutti, V. Knowledge graphs: New directions for knowledge representation on the semantic web (dagstuhl seminar 18371). In Dagstuhl Reports; Schloss Dagstuhl-Leibniz-Zentrum fuer Informatik: Wadern, Germany, 2019. [Google Scholar]
- Ehrlinger, L.; Wöß, W. Towards a definition of knowledge graphs. SEMANTiCS 2016, 48, 2. [Google Scholar]
- Bergman, M.K. A Common Sense View of Knowledge Graphs. Available online: https://www.mkbergman.com/2244/a-common-sense-view-of-knowledge-graphs/ (accessed on 31 August 2022).
- Hogan, A.; Blomqvist, E.; Cochez, M.; d’Amato, C.; Melo, G.D.; Gutierrez, C.; Kirrane, S.; Gayo, J.E.L.; Navigli, R.; Neumaier, S.; et al. Knowledge Graphs. ACM Comput. Surv. 2021, 54, 1–37. [Google Scholar] [CrossRef]
- Uschold, M.; Gruninger, M. Ontologies: Principles, methods and applications. Knowl. Eng. Rev. 1996, 11, 93–136. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Y.; Zhu, H. Ontology for Service Oriented Testing of Web Services. In Proceedings of the 2008 IEEE International Symposium on Service-Oriented System Engineering, Jhongli, Taiwan, 18–19 December 2008; pp. 129–134. [Google Scholar]
- Bezerra, D.; Costa, A.; Okada, K. SWTOI (software test ontology integrated) and its application in Linux test. In International Workshop on Ontology, Conceptualization and Epistemology for Information Systems, Software Engineering and Service Science; Elsevier: Amsterdam, The Netherlands, 2009; pp. 25–36. [Google Scholar]
- Pilorget, L. (Ed.) Testen von Informationssystemen: Integriertes und Prozessorientiertes Testen; Vieweg+Teubner Verlag: Wiesbaden, Germany, 2012; ISBN 978-3-8348-1866-9. [Google Scholar]
- International Software Testing Qualifications Board. Available online: https://www.istqb.org/ (accessed on 11 November 2022).
- Pierce, B.C. Types and programming languages. In Bulletin of Symbolic Logic; MIT Press: Cambridge, MA, USA, 2002; pp. 213–214. [Google Scholar]
- Jifa, G. Data, Information, Knowledge, Wisdom and Meta-Synthesis of Wisdom-Comment on Wisdom Global and Wisdom Cities. Procedia Comput. Sci. 2013, 17, 713–719. [Google Scholar] [CrossRef] [Green Version]
- Bellinger, G.; Castro, D.; Mills, A. Data, Information, Knowledge, and Wisdom. Available online: http://www.systemsthinking.org/dikw/dikw.htm (accessed on 9 January 2023).
- Berre, A.-J.; Elvesæter, B.; Figay, N.; Guglielmina, C.; Johnsen, S.G.; Karlsen, D.; Knothe, T.; Lippe, S. The ATHENA interoperability framework. In Enterprise Interoperability II; Springer: Berlin/Heidelberg, Germany, 2007; pp. 569–580. [Google Scholar]
- dSPACE GmbH. AGILE-VT-dSPACE-Agiles Virtuelles Testen der Nächsten Generation für die Luftfahrtindustrie von dSPACE im Verbund AGILE-VT: Schlussbericht-Öffentlich: BMWi-Verbundprojekt im Rahmen des Luftfahrtforschungsprogramms LuFo V-3: Berichtszeitraum: 1. Oktober 2017-30. Juni 2021; dSPACE GmbH: Paderborn, Germany, 2021. [Google Scholar]
- Federal Aviation Administration. Federal Aviation Administration Joint Aircraft System/Component Code Table and Definitions. Available online: https://air.flyingway.com/books/jasc-codes.pdf (accessed on 8 December 2022).
- Franke, M.; Hribernik, K.A.; Thoben, K.-D. Interoperable Access to Heterogeneous Test Knowledge. SSRN J. 2020. [Google Scholar] [CrossRef]
- Shani, U.; Franke, M.; Hribernik, K.A.; Thoben, K.-D. Ontology mediation to rule them all: Managing the plurality in product service systems. In Proceedings of the 2017 Annual IEEE International Systems Conference (SysCon), Montreal, QC, Canada, 24–27 April 2017; IEEE: New York, NY, USA; pp. 1–7. [Google Scholar] [CrossRef]


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Definition | Description |
|---|---|
| Block | A block is a structural element used to group statements within a test case. Most of the time, a block describes a test step in the test case. |
| State | A state describes the current state of a system in a state diagram or in test execution. An example of a state is the off state when all of the aircraft’s systems are off. Hereby a state can be divided into two parts: micro-state and macro-state. The micro-state defines all statements which shall be executed immediately. The macro-state describes the result of the execution of the statements. |
| Statement | A statement is a line within the source code of a test case that executes instructions. For example, assigning a number to a variable is a statement. |
| Stimulus | A stimulus is a statement that leads to a change of state. For example, the stimulus to turn on the light causes the lamps to glow afterwards |
| Ramp | A ramp is a repetitive stimulus in which a signal is increased at a predefined slope. |
| Id | TASCXML Commando | Type of Statement | Description |
|---|---|---|---|
| 1 | <TASCXML:set> | Stimulation | Sets a signal to a specific value |
| 2 | <TASCXML:get> | Stimulation | Reads the current value of a signal |
| 3 | <TASCXML:result> | Verdicts | Logs a result (verdict) of the test case |
| 4 | <TASCXML:ramp> | Stimulation | Triggers a ramp that changes a signal for a specified duration |
| 5 | <TASCXML:sine> | Stimulation | Generates a curve shape of a sine curve |
| 6 | <TASCXML:sawtooth> | Stimulation | Creates a waveform of a sawtooth |
| 7 | <TASCXML:pulse> | Stimulation | Creates a waveform of a pulse |
| 8 | <TASCXML:verifytolerance> | Verdicts | Verifies whether the value of a signal is within a specific tolerance range |
| x | v |
|---|---|
| <xsd:element name=“state” type=“scxml.state.type”/> | v = {P,‘STATE’} |
| <xsd:element name=“set” type=“scxml.state.type”/> | v = {P,‘SET’} |
| <xsd:element name=“result” type=“scxml.state.type”/> | v = {P,‘RESULT’} |
| <xsd:element name=“ramp” type=“scxml.state.type”/> | v = {P,‘RAMP’} |
| <xsd:element name=“sine” type=“scxml.state.type”/> | v = {P,‘SINE’} |
| <xsd:element name=“sawtooth” type=“scxml.state.type”/> | v = {P, ‘SAWTOOTH’} |
| <xsd:element name=“pulse” type=“scxml.state.type”/> | v = {P, ‘PULSE’} |
| <xsd:element name=“verifytolerance” type=“scxml.state.type”/> | v = {P, ‘VERIFYTOLERANCE’} |
| x | e |
|---|---|
 | e = ((P,‘STATE’), (P,‘STATE’), ‘SIMPLE’, P) |
 | e = ((P,‘STATE’), (P, l ϵ {‘SET’,‘RESULT’,‘RAMP’,‘SINE’,‘SAWTOOTH’,‘PULSE’,‘VERIFYTOLERANCE’}), ‘PARRALLEL_STATEMENT’, P) |
 | e = (P, (‘STATE’), (P, ‘STATE’), ‘WAIT’, (‘duration’,Z)) |
| Test Case | Length in Python Lines | Length in SCXML Lines | Length as Complete Pattern Lines |
|---|---|---|---|
| Left Door 1, ordinary | 58 lines but importing 7 libraries (all libraries have 15881 lines) | 18,434 | Unknown |
| Left Door 1, emergency | 59 lines but importing 7 libraries (all libraries have 15881 lines) | 20,520 | 1001 |
| Right Door 1, ordinary | 58 lines but importing 7 libraries (all libraries have 15881 lines) | 18,434 | Unknown |
| Right Door 1, emergency | 59 lines but importing 7 libraries (all libraries have 15881 lines) | 20,520 | Unknown |
| Left Door 2, ordinary | 58 lines but importing 7 libraries (all libraries have 15881 lines) | 18,434 | Unknown |
| Left Door 2, emergency | 59 lines but importing 7 libraries (all libraries have 15881 lines) | 20,520 | Unknown |
| Right Door 2, ordinary | 58 lines but importing 7 libraries (all libraries have 15881 lines) | 18,434 | Unknown |
| Right Door 2, emergency | 59 lines but importing 7 libraries (all libraries have 15881 lines) | 20,520 | Unknown |
| Left Door 3, ordinary | 58 lines but importing 7 libraries (all libraries have 15881 lines) | 18,434 | Unknown |
| Left Door 3, emergency | 59 lines but importing 7 libraries (all libraries have 15881 lines) | 20,520 | Unknown |
| Right Door 3, ordinary | 58 lines but importing 7 libraries (all libraries have 15881 lines) | 18,434 | Unknown |
| Right Door 3, emergency | 59 lines but importing 7 libraries (all libraries have 15881 lines) | 20,520 | Unknown |
| Left Door 4, ordinary | 58 lines but importing 7 libraries (all libraries have 15881 lines) | 18,434 | Unknown |
| Left Door 4, emergency | 59 lines but importing 7 libraries (all libraries have 15881 lines) | 20,520 | Unknown |
| Right Door 4, ordinary | 58 lines but importing 7 libraries (all libraries have 15881 lines) | 18,434 | Unknown |
| Right Door 4, emergency | 59 lines but importing 7 libraries (all libraries have 15881 lines) | 20,520 | Unknown |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Franke, M.; Thoben, K.-D.; Ehrhardt, B. The Faceted and Exploratory Search for Test Knowledge. Information 2023, 14, 45. https://doi.org/10.3390/info14010045
Franke M, Thoben K-D, Ehrhardt B. The Faceted and Exploratory Search for Test Knowledge. Information. 2023; 14(1):45. https://doi.org/10.3390/info14010045
Chicago/Turabian StyleFranke, Marco, Klaus-Dieter Thoben, and Beate Ehrhardt. 2023. "The Faceted and Exploratory Search for Test Knowledge" Information 14, no. 1: 45. https://doi.org/10.3390/info14010045
APA StyleFranke, M., Thoben, K.-D., & Ehrhardt, B. (2023). The Faceted and Exploratory Search for Test Knowledge. Information, 14(1), 45. https://doi.org/10.3390/info14010045