

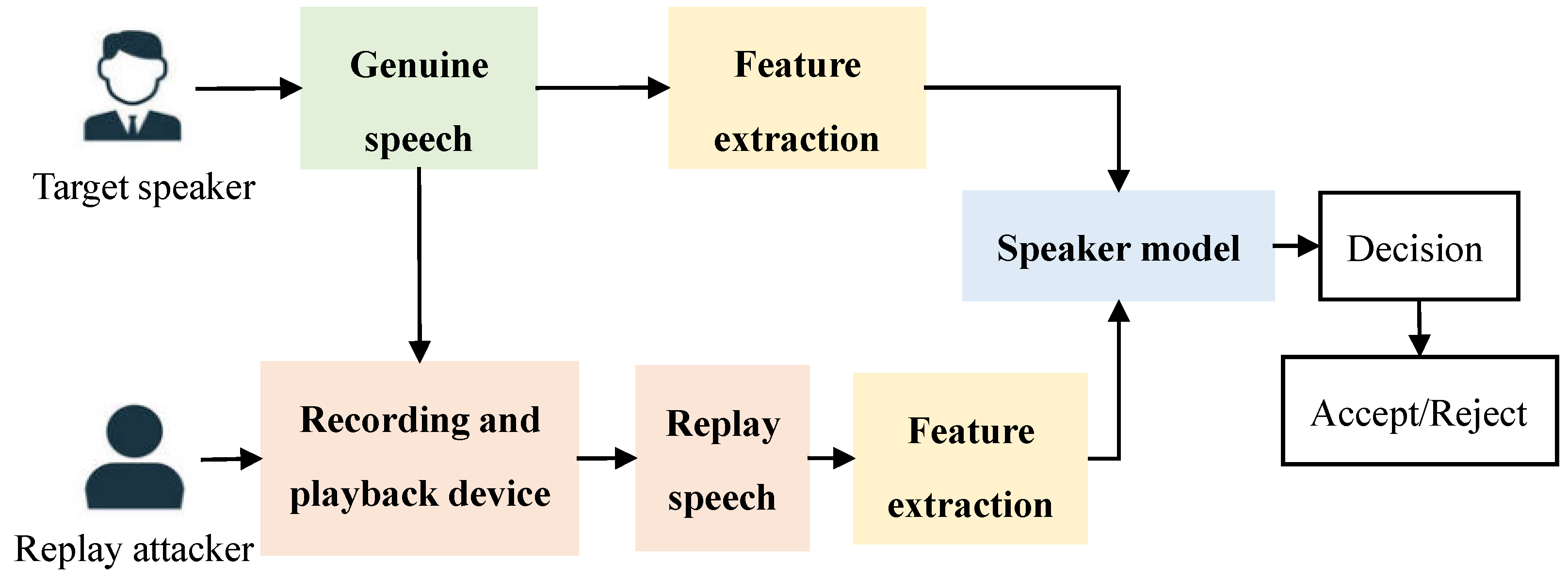
Replay Attack Detection Based on High Frequency Missing Spectrum


Abstract
:1. Introduction
- (1)
- Impersonation attack. The attacker deceives by imitating high-level speaker characteristics of the target speaker such as the prosody, accent, and pronunciation.
- (2)
- Replay attack (RA). The attacker records the real voice of the target speaker through a recording device, then the attack is carried out by playing back the copied voice.
- (3)
- Speech Synthesis (SS) attack. The attacker uses speech synthesis technology to generate the fake speech of the target speaker to deceive the ASV system.
- (4)
- Voice Conversion (VC) attack. The attacker converts the voice signal of the non-target speaker into the voice signal of the target speaker through conversion technology.
2. Related Work
3. Spectral Cues in High Sampling Rate Replayed Signal
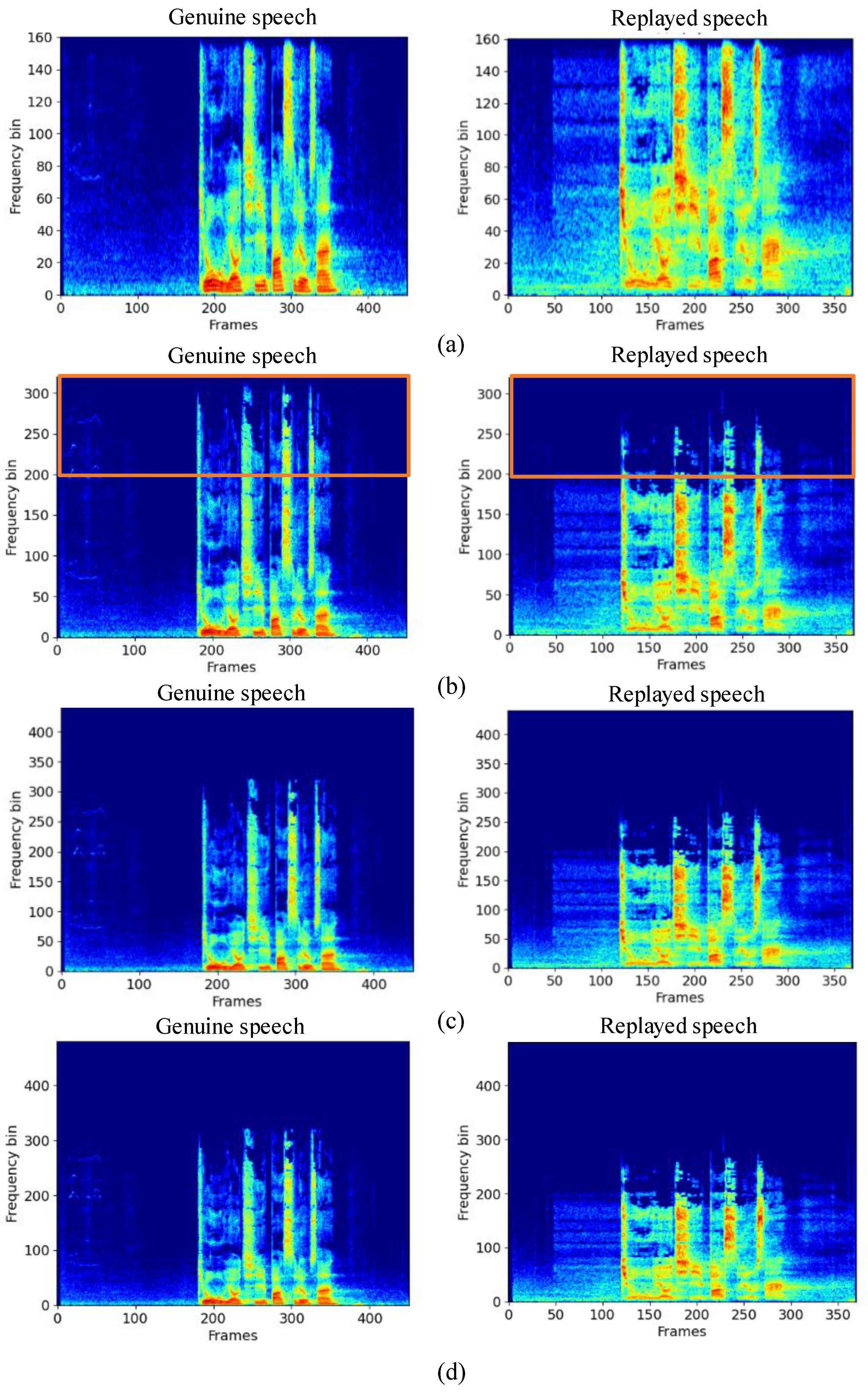
3.1. Spectrum Loss Phenomenon
3.2. High Sampling Rate Database
4. Experiment
4.1. Experimental Configuration
4.1.1. Feature Selection
4.1.2. Model Selection
4.1.3. Evaluation Metric
4.2. Results and Discussion
4.2.1. Replay Detection Performance at Different Sampling Rate
4.2.2. Comparison of Differences among Frequency Bands
4.2.3. Replay Detection Performance at High Sampling Rate
4.3. Limitation
5. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Das, R.K.; Tian, X.; Kinnunen, T.; Li, H. The attacker’s perspective on automatic speaker verification: An overview. arXiv 2020, arXiv:2004.08849. [Google Scholar]
- Chen, Y.; Guo, Y.; Li, Q.; Cheng, G.; Zhang, P.; Yan, Y. Interrelate training and searching: A unified online clustering framework for speaker diarization. arXiv 2022, arXiv:2206.13760. [Google Scholar]
- Evans, N.W.; Kinnunen, T.; Yamagishi, J. Spoofing and countermeasures for automatic speaker verification. In Proceedings of the INTERSPEECH, Lyon, France, 25–29 August 2013; pp. 925–929. [Google Scholar]
- Wu, Z.; Evans, N.; Kinnunen, T.; Yamagishi, J.; Alegre, F.; Li, H. Spoofing and countermeasures for speaker verification: A survey. Speech Commun. 2015, 66, 130–153. [Google Scholar] [CrossRef] [Green Version]
- Singh, M.; Pati, D. Countermeasures to replay attacks: A review. IETE Tech. Rev. 2020, 37, 599–614. [Google Scholar] [CrossRef]
- Furui, S. Recent advances in speaker recognition. Pattern Recognit. Lett. 1997, 18, 859–872. [Google Scholar] [CrossRef]
- Koppell, J. International organization for standardization. Handb. Transnatl. Gov. Inst. Innov. 2011, 41, 289. [Google Scholar]
- Delgado, H.; Todisco, M.; Sahidullah, M.; Evans, N.; Kinnunen, T.; Lee, K.A.; Yamagishi, J. ASVspoof 2017 Version 2.0: Meta-data analysis and baseline enhancements. In Proceedings of the Odyssey 2018—The Speaker and Language Recognition Workshop, Les Sables d’Olonne, France, 26–29 June 2018. [Google Scholar]
- Kinnunen, T.; Evans, N.; Yamagishi, J.; Lee, K.A.; Sahidullah, M.; Todisco, M.; Delgado, H. Asvspoof 2017: Automatic speaker verification spoofing and countermeasures challenge evaluation plan. Training 2017, 10, 1508. [Google Scholar]
- Johnson, R.; Boult, T.E.; Scheirer, W.J. Voice authentication using short phrases: Examining accuracy, security and privacy issues. In Proceedings of the 2013 IEEE Sixth International Conference on Biometrics: Theory, Applications and Systems (BTAS), IEEE, Washington, DC, USA, 29 September–2 October 2013; pp. 1–8. [Google Scholar]
- Gałka, J.; Grzywacz, M.; Samborski, R. Playback attack detection for text-dependent speaker verification over telephone channels. Speech Commun. 2015, 67, 143–153. [Google Scholar] [CrossRef]
- Bredin, H.; Miguel, A.; Witten, I.H.; Chollet, G. Detecting replay attacks in audiovisual identity verification. In Proceedings of the ICASSP 2006 Proceedings—2006 IEEE International Conference on Acoustics, Speech and Signal Processing, Toulouse, France, 14–19 May 2006. [Google Scholar]
- Mochizuki, S.; Shiota, S.; Kiya, H. Voice liveness detection using phoneme-based pop-noise detector for speaker verifcation. Threshold 2018, 5. [Google Scholar]
- Liu, M.; Wang, L.; Lee, K.A.; Chen, X.; Dang, J. Replay-attack detection using features with adaptive spectro-temporal resolution. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, Toronto, ON, Canada, 6–11 June 2021; pp. 6374–6378. [Google Scholar]
- You, C.H.; Yang, J.; Tran, H.D. Device Feature Extractor for Replay Spoofing Detection. In Proceedings of the INTERSPEECH, Graz, Austria, 15–19 September 2019; pp. 2933–2937. [Google Scholar]
- Li, L.; Chen, Y.; Wang, D.; Zheng, T.F. A study on replay attack and anti-spoofing for automatic speaker verification. arXiv 2017, arXiv:1706.02101. [Google Scholar]
- Avila, A.R.; Alam, M.J.; O’Shaughnessy, D.D.; Falk, T.H. Blind channel response estimation for replay attack detection. In Proceedings of the INTERSPEECH, Graz, Austria, 15–19 September 2019; pp. 2893–2897. [Google Scholar]
- Witkowski, M.; Kacprzak, S.; Zelasko, P.; Kowalczyk, K.; Galka, J. Audio Replay attack detection using high-frequency features. In Proceedings of the INTERSPEECH, Stockholm, Sweden, 20–24 August 2017; pp. 27–31. [Google Scholar]
- Alluri, K.R.; Achanta, S.; Kadiri, S.R.; Gangashetty, S.V.; Vuppala, A.K. SFF Anti-spoofer: IIIT-H submission for automatic speaker verification spoofing and countermeasures challenge 2017. In Proceedings of the INTERSPEECH, Stockholm, Sweden, 20–24 August 2017; pp. 107–111. [Google Scholar]
- Kamble, M.R.; Tak, H.; Patil, H.A. Effectiveness of speech demodulation-based features for replay detection. In Proceedings of the INTERSPEECH, Hyderabad, India, 2–6 September 2018; pp. 641–645. [Google Scholar]
- Suthokumar, G.; Sethu, V.; Wijenayake, C.; Ambikairajah, E. Modulation dynamic features for the detection of replay attacks. In Proceedings of the INTERSPEECH, Hyderabad, India, 2–6 September 2018; pp. 691–695. [Google Scholar]
- Gunendradasan, T.; Wickramasinghe, B.; Le, P.N.; Ambikairajah, E.; Epps, J. Detection of replay-spoofing attacks using frequency modulation features. In Proceedings of the INTERSPEECH, Hyderabad, India, 2–6 September 2018; pp. 636–640. [Google Scholar]
- Singh, M.; Pati, D. Linear prediction residual based short-term cepstral features for replay attacks detection. In Proceedings of the INTERSPEECH, Hyderabad, India, 2–6 September 2018; pp. 751–755. [Google Scholar]
- Li, D.; Wang, L.; Dang, J.; Liu, M.; Oo, Z.; Nakagawa, S.; Guan, H.; Li, X. Multiple phase information combination for replay attacks detection. In Proceedings of the INTERSPEECH, Hyderabad, India, 2–6 September 2018; pp. 656–660. [Google Scholar]
- Williams, J.; Rownicka, J. Speech replay detection with X-vector attack embeddings and spectral features. arXiv 2019, arXiv:1909.10324. [Google Scholar]
- Parasu, P.; Epps, J.; Sriskandaraja, K.; Suthokumar, G. Investigating light-resnet architecture for spoofing detection under mismatched conditions. In Proceedings of the INTERSPEECH, Shangai, China, 14–18 September 2020; pp. 1111–1115. [Google Scholar]
- Lei, Z.; Yang, Y.; Liu, C.; Ye, J. Siamese convolutional neural network using gaussian probability feature for spoofing speech detection. In Proceedings of the INTERSPEECH, Shangai, China, 14–18 September 2020; pp. 1116–1120. [Google Scholar]
- Li, X.; Li, N.; Weng, C.; Liu, X.; Su, D.; Yu, D.; Meng, H. Replay and synthetic speech detection with res2net architecture. In Proceedings of the ICASSP 2021—2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, Toronto, ON, Canada, 6–11 June 2021; pp. 6354–6358. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| #Genuine Speech Samples | #Replayed Speech Samples | Total Duration (h) | Average Sample Duration (s) | |
|---|---|---|---|---|
| Train | 16 | 2928 | 3.25 | 3.97 |
| Test | 64 | 733 | 0.88 | 3.98 |
| Total | 80 | 3661 | 4.13 | - |
| Stage | ResNet34 | SE-ResNet34 | Res2Net50 |
|---|---|---|---|
| Conv1 | Conv2D, 7 × 7, 16, stride = 2 Max pool, 3 × 3, stride = 2 | Conv2D, 7 × 7, 16, stride = 2 Max pool, 3 × 3, stride = 2 | [Conv2D, 3 × 3, 16, stride = 1] × 3 |
| Conv2 | [Basic block, 16] × 3 | [SE-ResNet block, 16] × 3 | [Res2Net block, 16] × 3 |
| Conv3 | [Basic block, 32] × 4 | [SE-ResNet block, 32] × 4 | [Res2Net block, 32] × 4 |
| Conv4 | [Basic block, 64] × 6 | [SE-ResNet block, 64] × 6 | [Res2Net block, 64] × 6 |
| Conv5 | [Basic block, 128] × 3 | [SE-ResNet block, 128] × 3 | [Res2Net block, 64] × 3 |
| Global average pool, 2-D fully connected layer, softmax | |||
| Sampling Rate (kHz) | SVM (Kernel = rbf) EER(%) | SVM (Kernel = Linear) EER(%) |
|---|---|---|
| 16 | 1.90 | 2.04 |
| 32 | 1.63 | 1.09 |
| 44.1 | 1.09 | 0.81 |
| 48 | 0.27 | 0.54 |
| Freq Range (kHz) | 0–4 | 2–6 | 4–8 | 6–10 | 8–12 | 10–14 | 12–16 | 14–18 | 16–20 | 18–22 | 20–24 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| SVM(kernel = rbf) EER(%) | 30.55 | 42.29 | 26.05 | 29.46 | 28.24 | 37.92 | 29.74 | 36.01 | 15.68 | 23.73 | 38.60 |
| SVM(kernel = linear) EER(%) | 23.87 | 25.10 | 31.37 | 28.24 | 6.54 | 36.97 | 53.20 | 54.97 | 12.55 | 13.36 | 26.60 |
| System | EER(%) |
|---|---|
| SVM(kernel = rbf) | 0.27 |
| SVM(kernel = linear) | 0.54 |
| ResNet34 | 0.00 |
| SE-ResNet34 | 0.00 |
| Res2Net50 | 0.00 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2022 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Yuan, J.; Ablimit, M.; Hamdulla, A. Replay Attack Detection Based on High Frequency Missing Spectrum. Information 2023, 14, 7. https://doi.org/10.3390/info14010007
Yuan J, Ablimit M, Hamdulla A. Replay Attack Detection Based on High Frequency Missing Spectrum. Information. 2023; 14(1):7. https://doi.org/10.3390/info14010007
Chicago/Turabian StyleYuan, Junming, Mijit Ablimit, and Askar Hamdulla. 2023. "Replay Attack Detection Based on High Frequency Missing Spectrum" Information 14, no. 1: 7. https://doi.org/10.3390/info14010007