
Deep Learning for Time Series Forecasting: Advances and Open Problems



Abstract
:1. Introduction
2. Deterministic Time Series
3. Deep Learning Models for Short-Term Forecasting
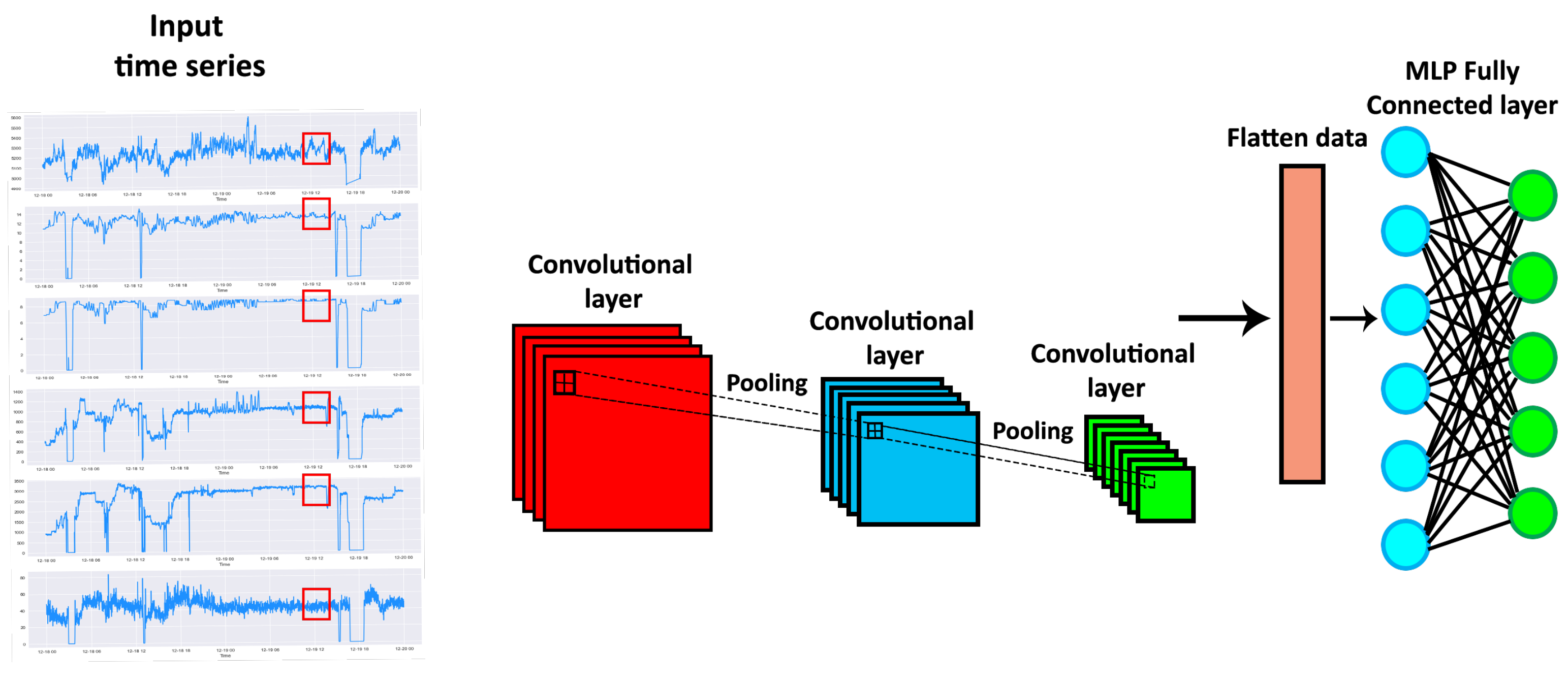
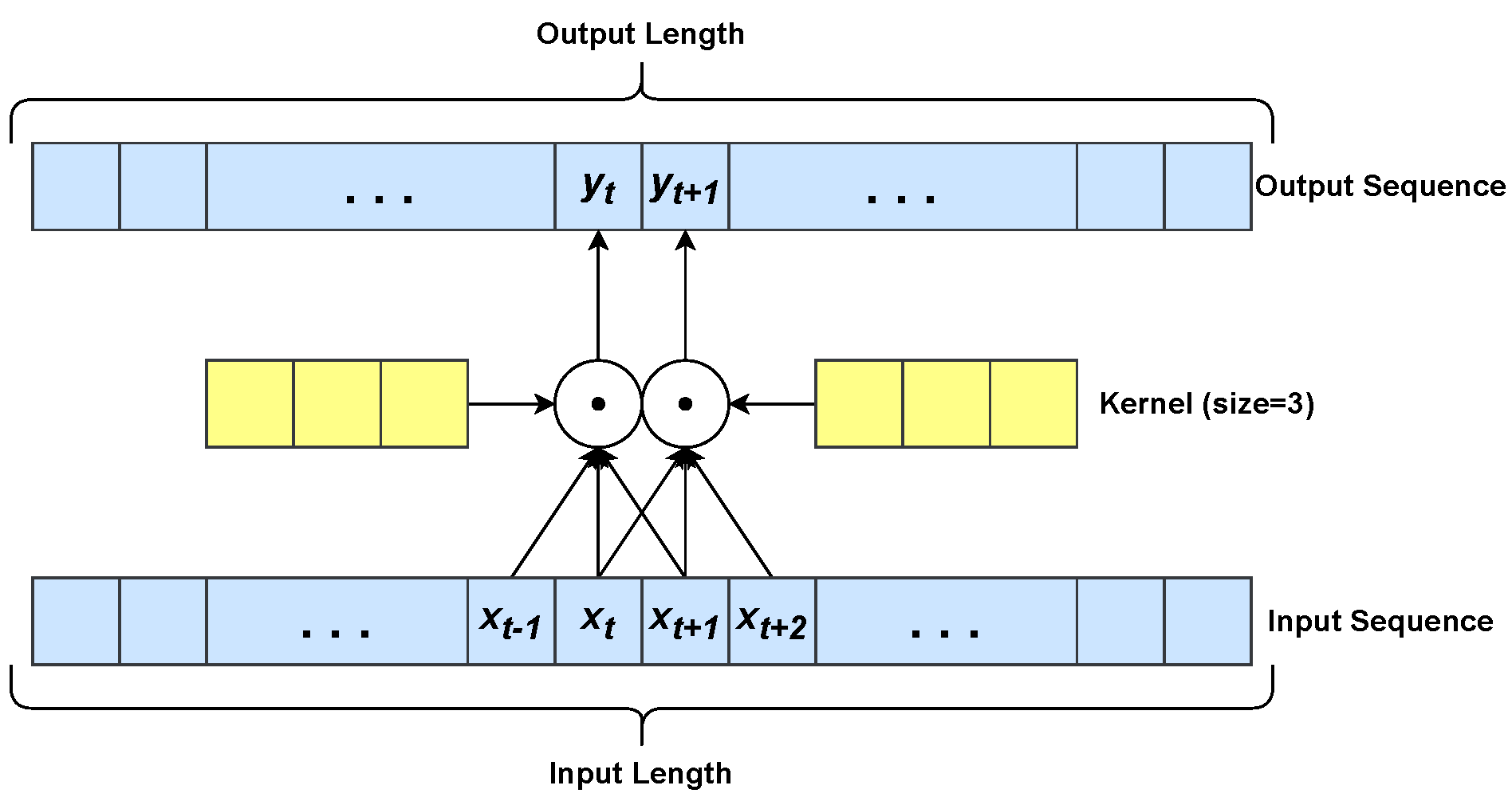
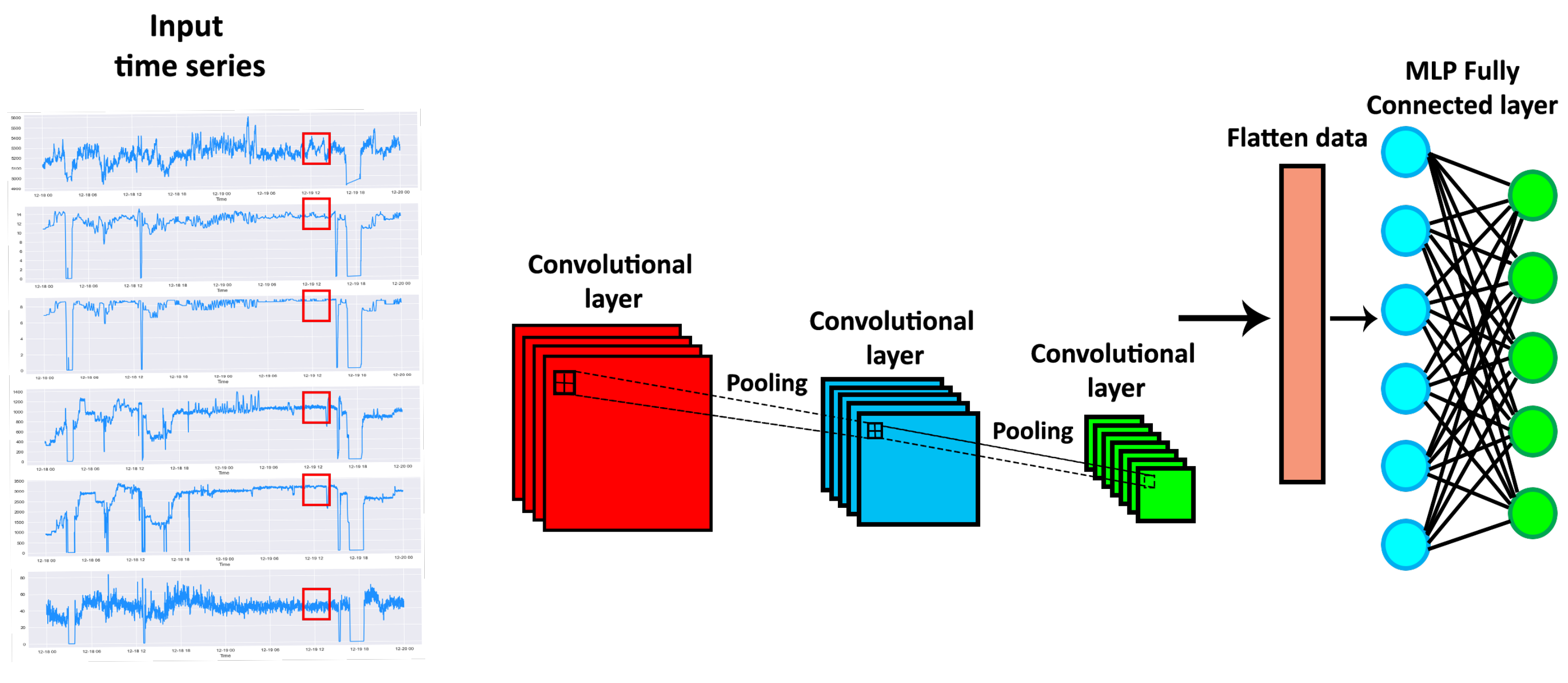
3.1. Convolutional Neural Networks
3.1.1. Shortcomings of Convolutional Neural Networks
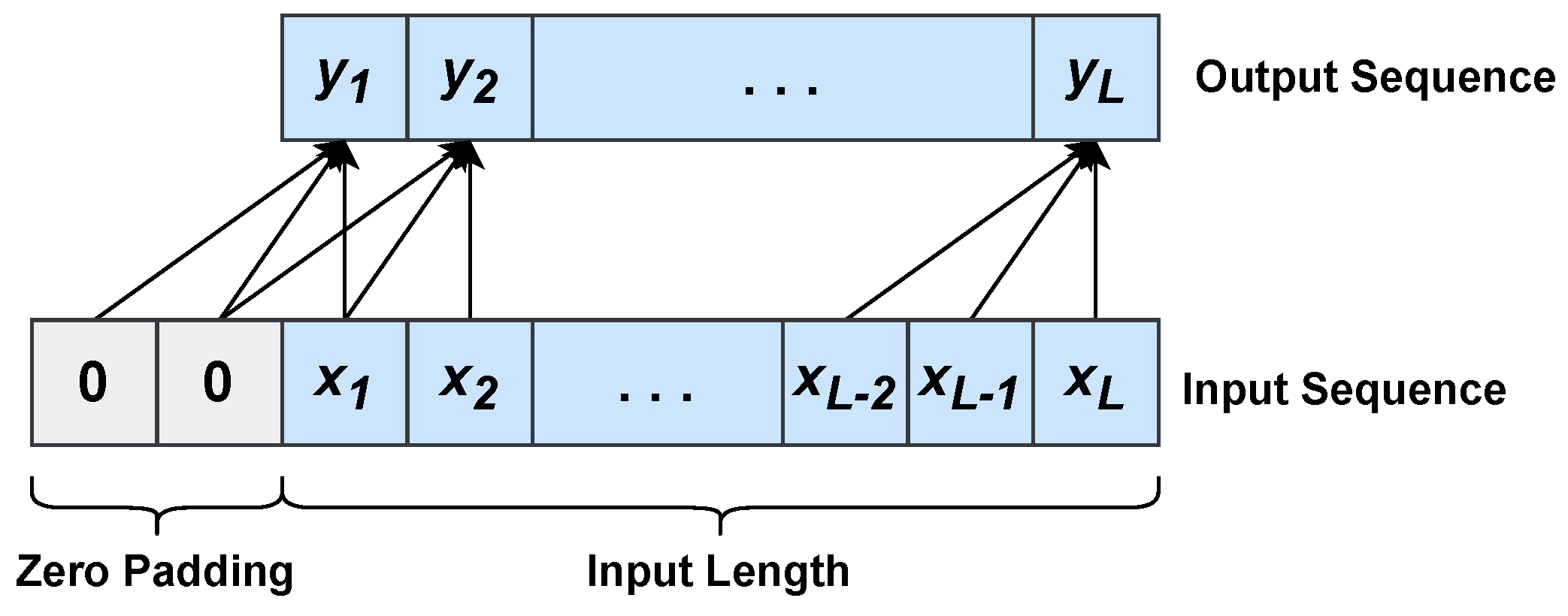
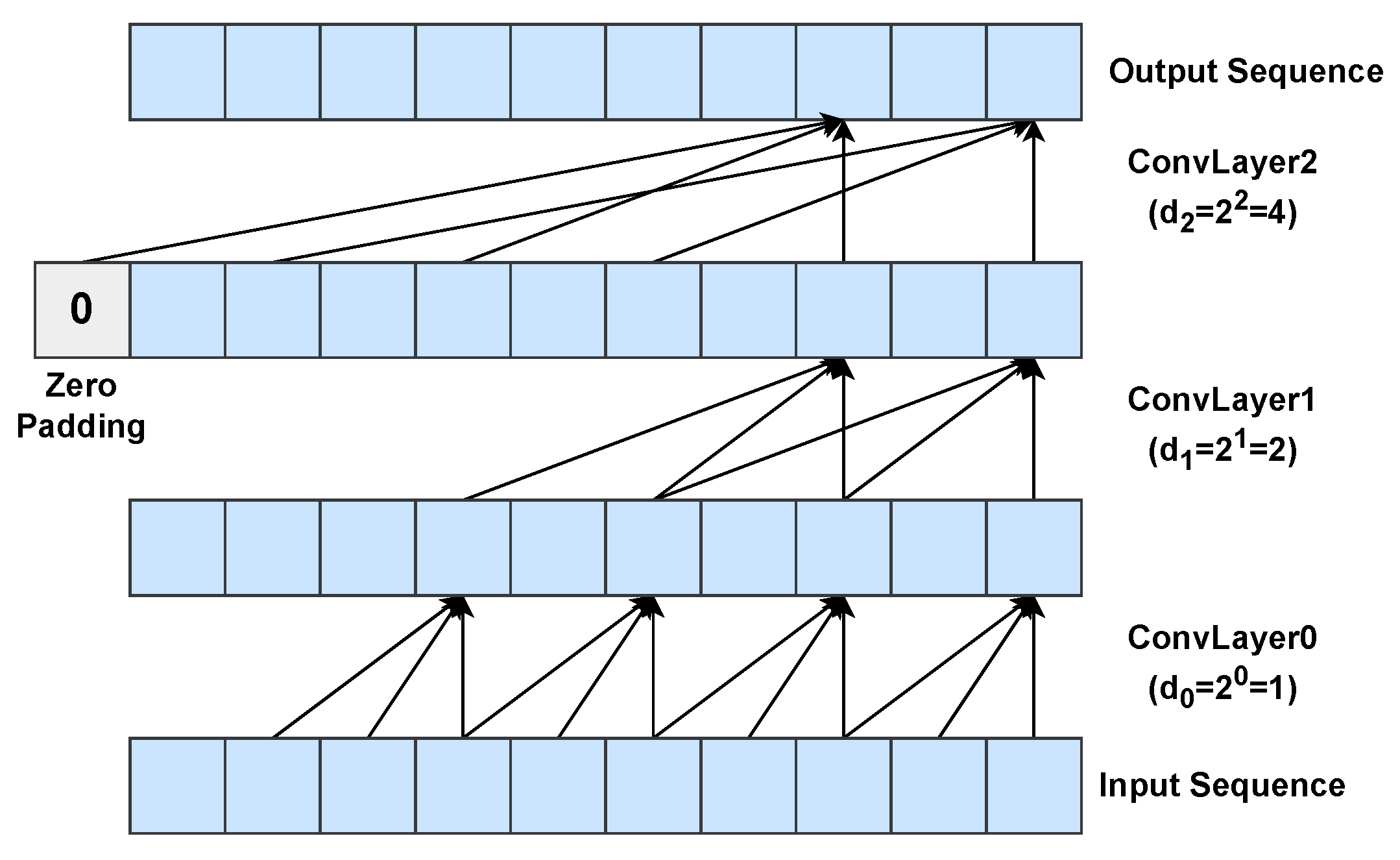
3.1.2. Temporal Convolutional Networks
3.2. Recurrent Neural Networks
3.2.1. Elman Recurrent Neural Networks
3.2.2. Shortcomings of Recurrent Neural Networks
3.2.3. Echo State Networks
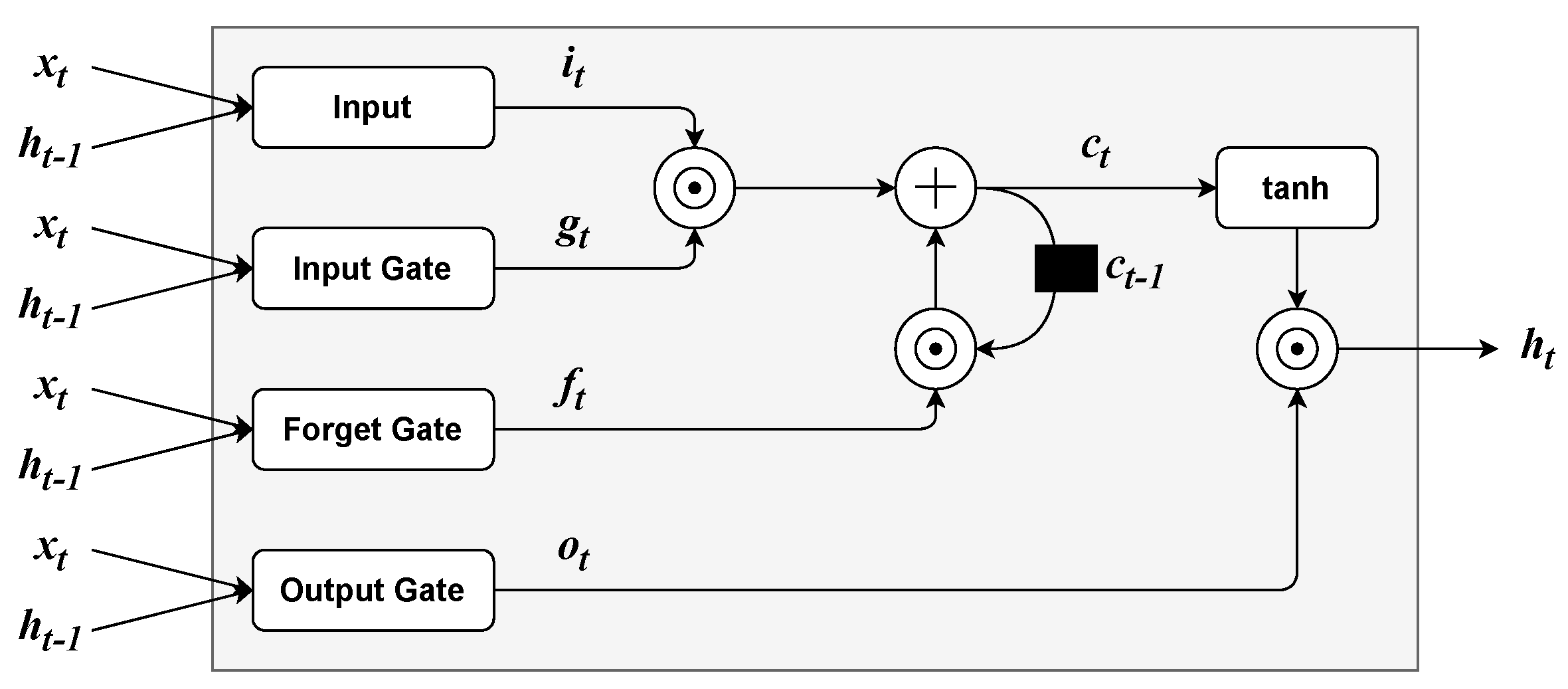
3.2.4. Long Short-Term Memory
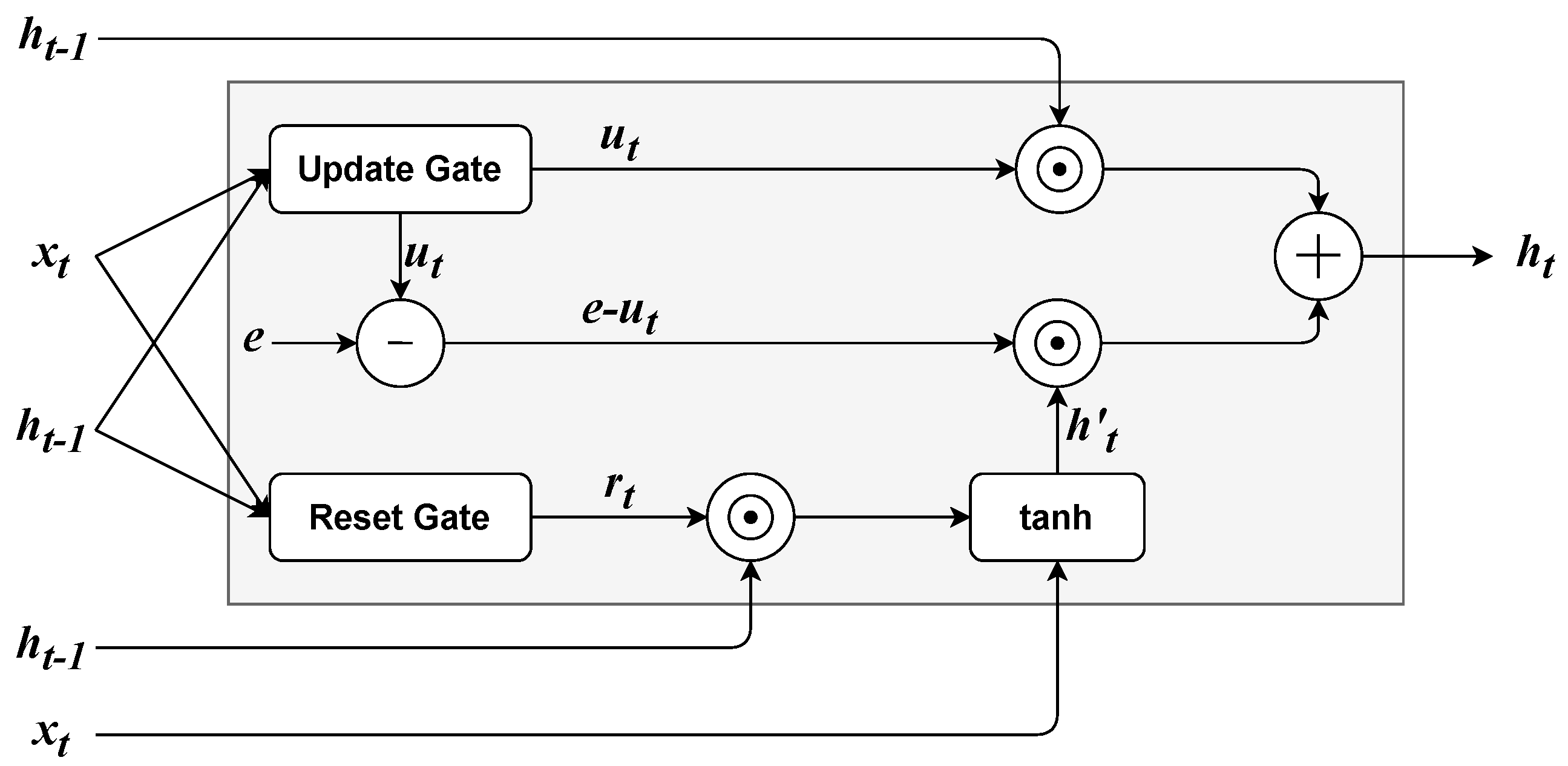
3.2.5. Gated Recurrent Units
3.2.6. Shortcomings of LSTMs and GRUs
3.3. Hybrids and Variants of Deep Neural Networks
3.4. Graph Neural Networks
3.5. Deep Gaussian Processes
3.6. Generative Models
3.6.1. Generative Adversarial Networks
3.6.2. Generative Adversarial Networks in Time Series Forecasting
3.6.3. Diffusion Models
3.6.4. Diffusion Models in Short-Term Time Series Forecasting
4. Deep Learning Models for Long-Term Forecasting
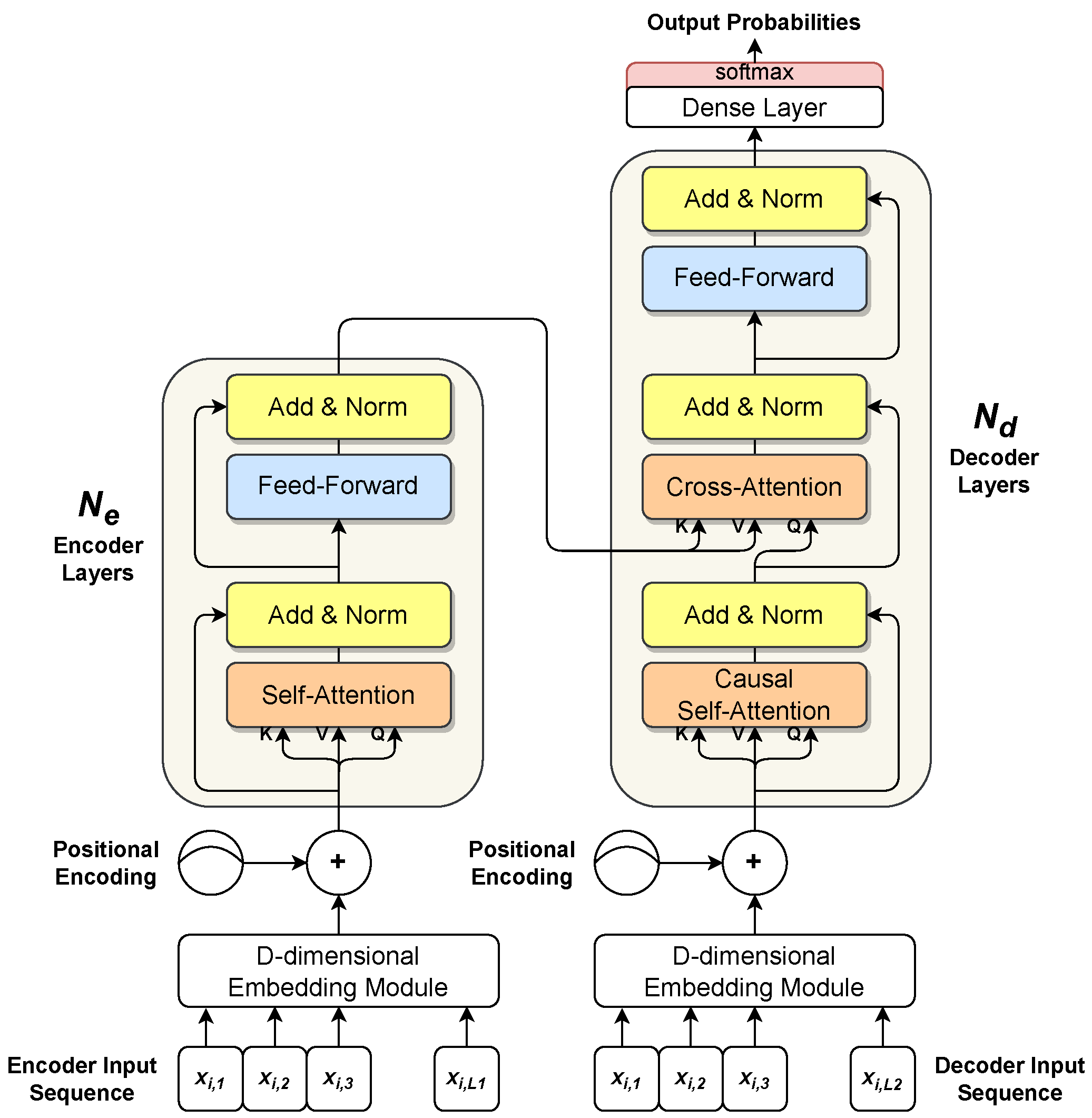
4.1. Transformers
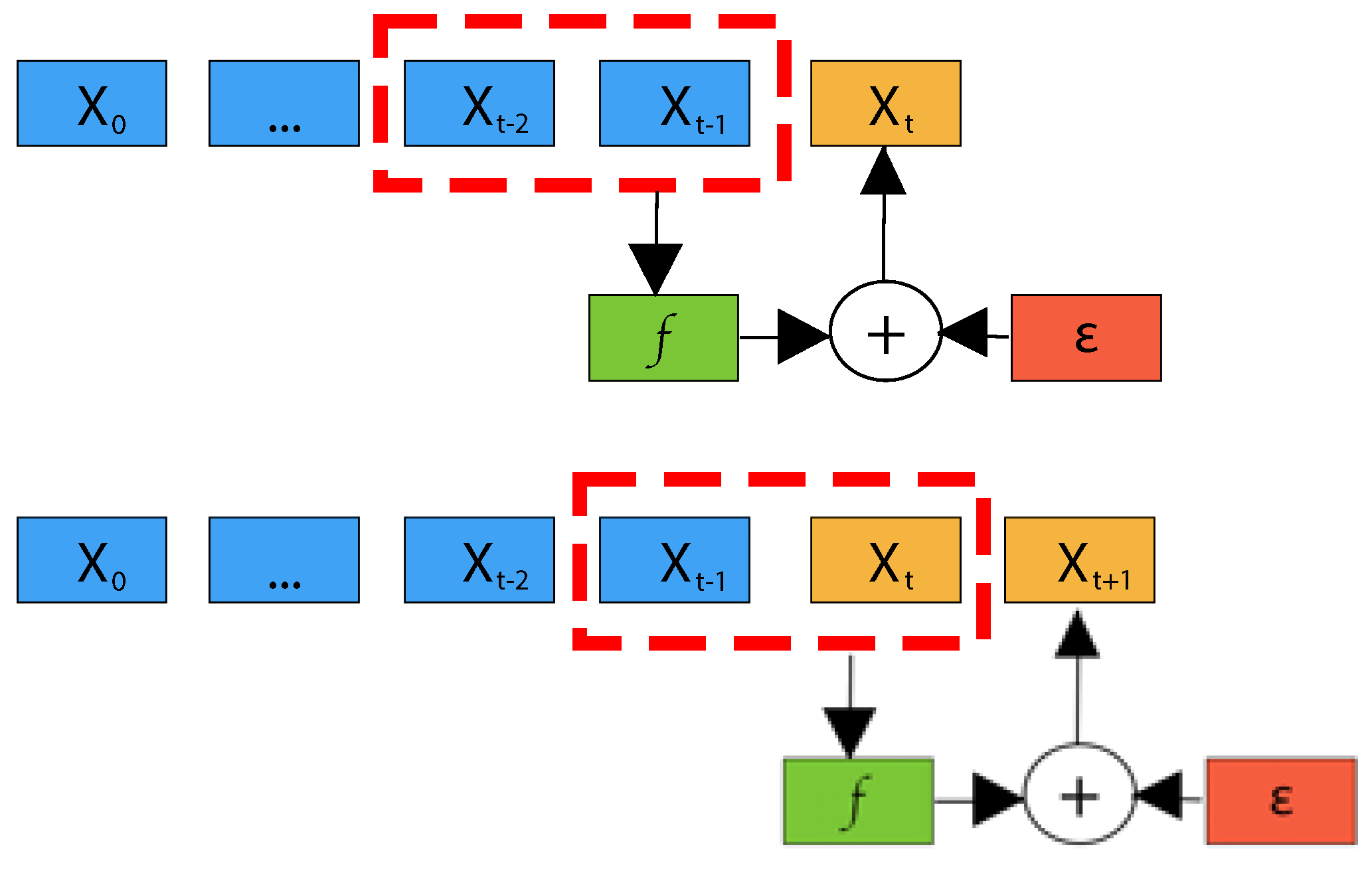
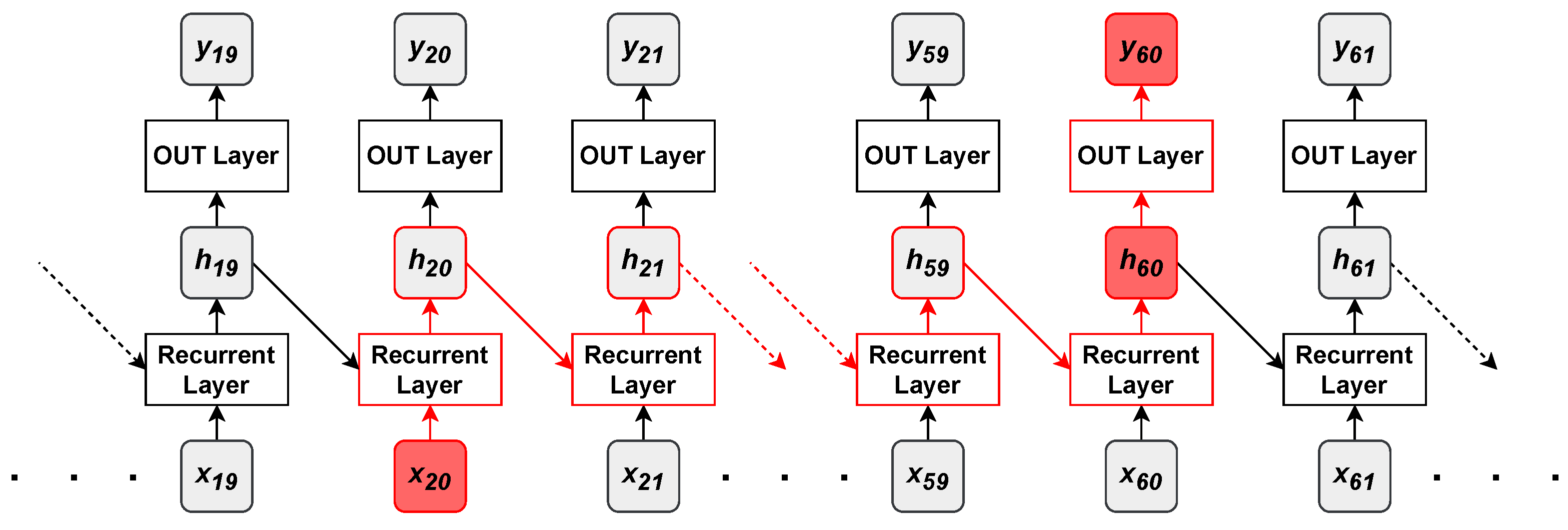
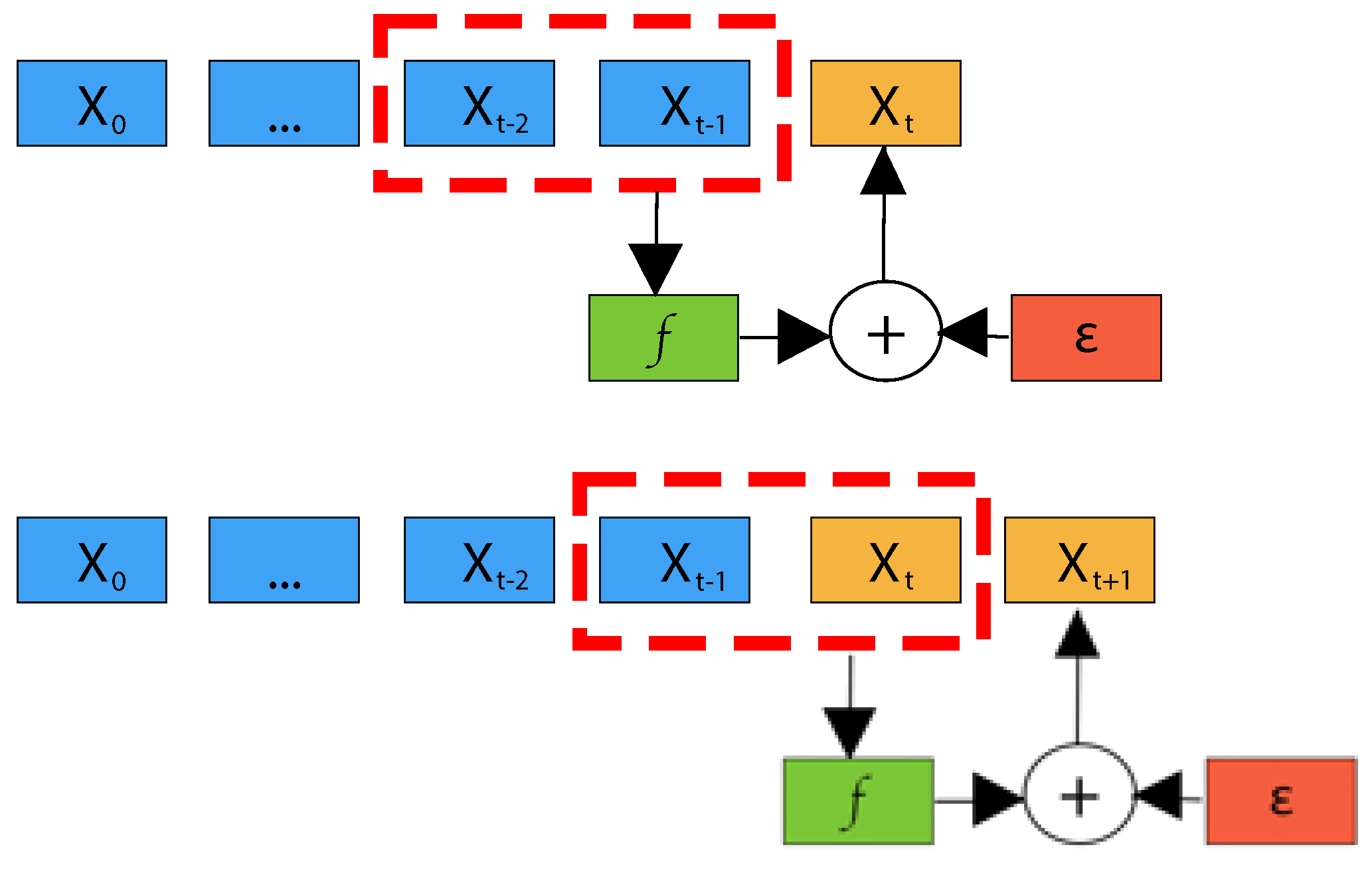
- The output state of a recurrent layer at time t depends on the state , produced at the previous time step. This inherent sequential nature prohibits the intra-sequence parallelism of recurrent networks.
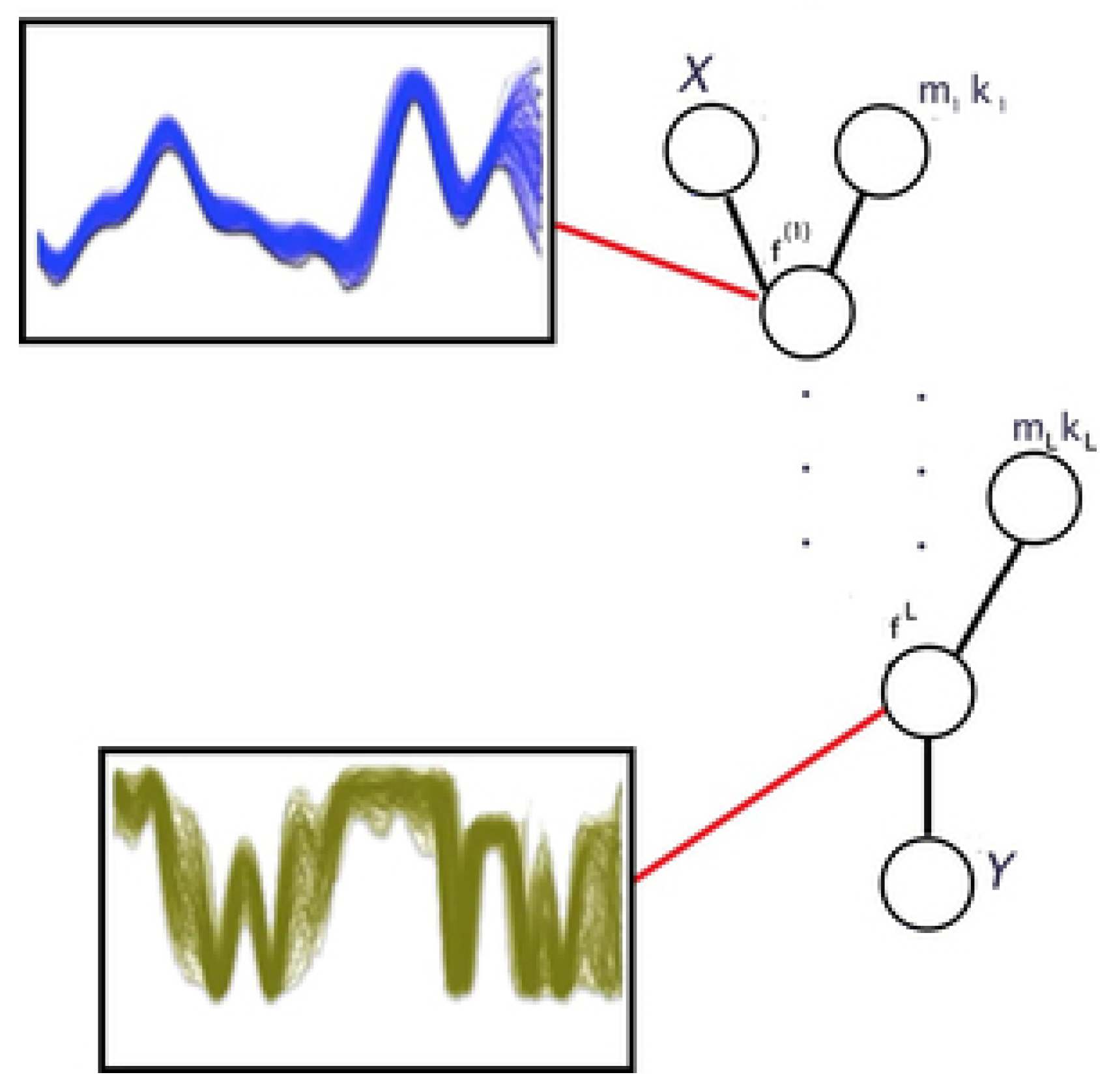
- Recurrent networks cannot generally learn relationships between sequences of distant samples, since information must first pass through all data samples in between (see Figure 8).
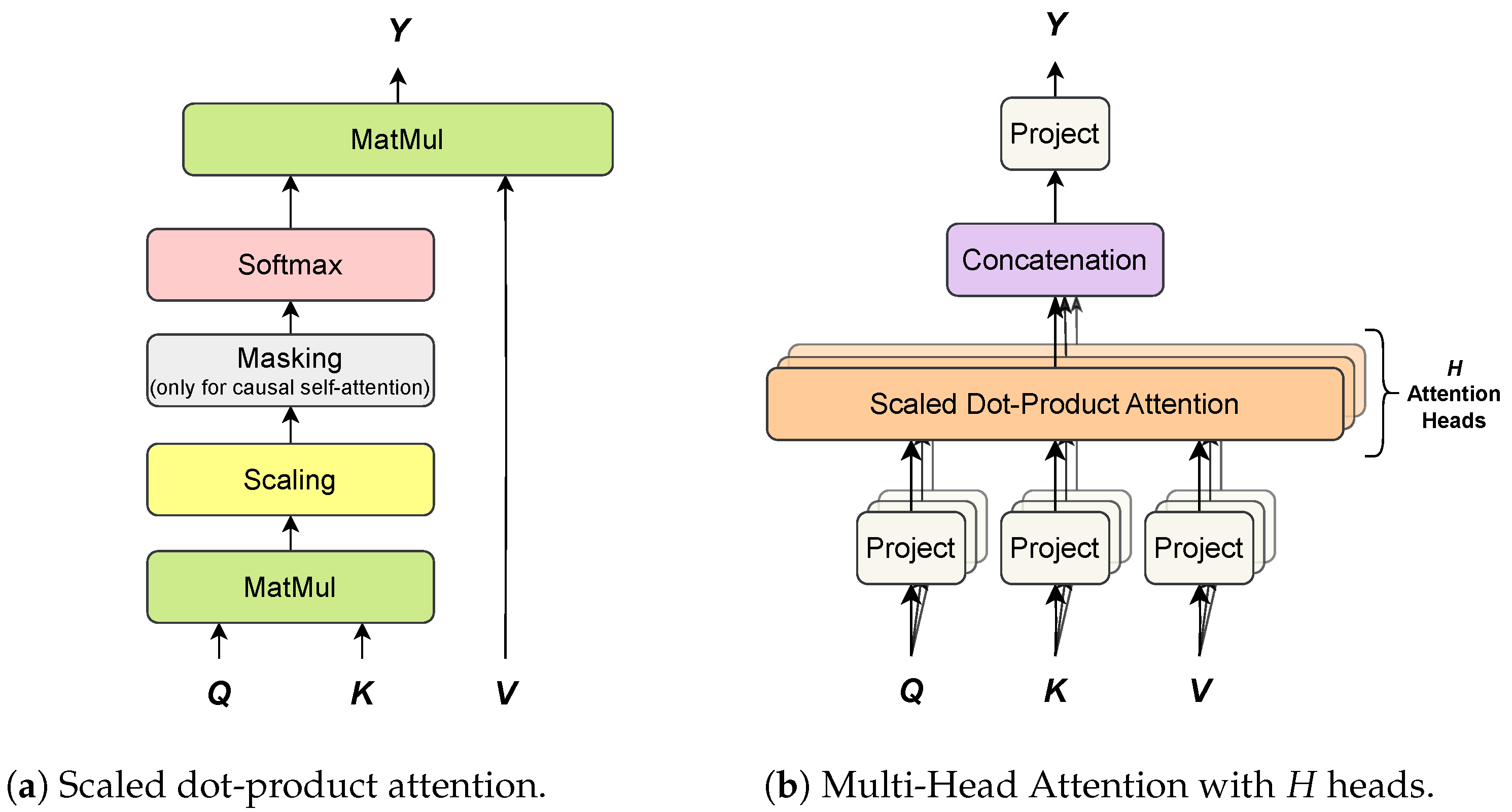
4.1.1. Attention Mechanisms
4.1.2. Multi-Head Attention
4.1.3. Shortcomings of Transformers
4.1.4. Transformer Variants for Time Series Forecasting
5. Other Relevant Deep Learning Models
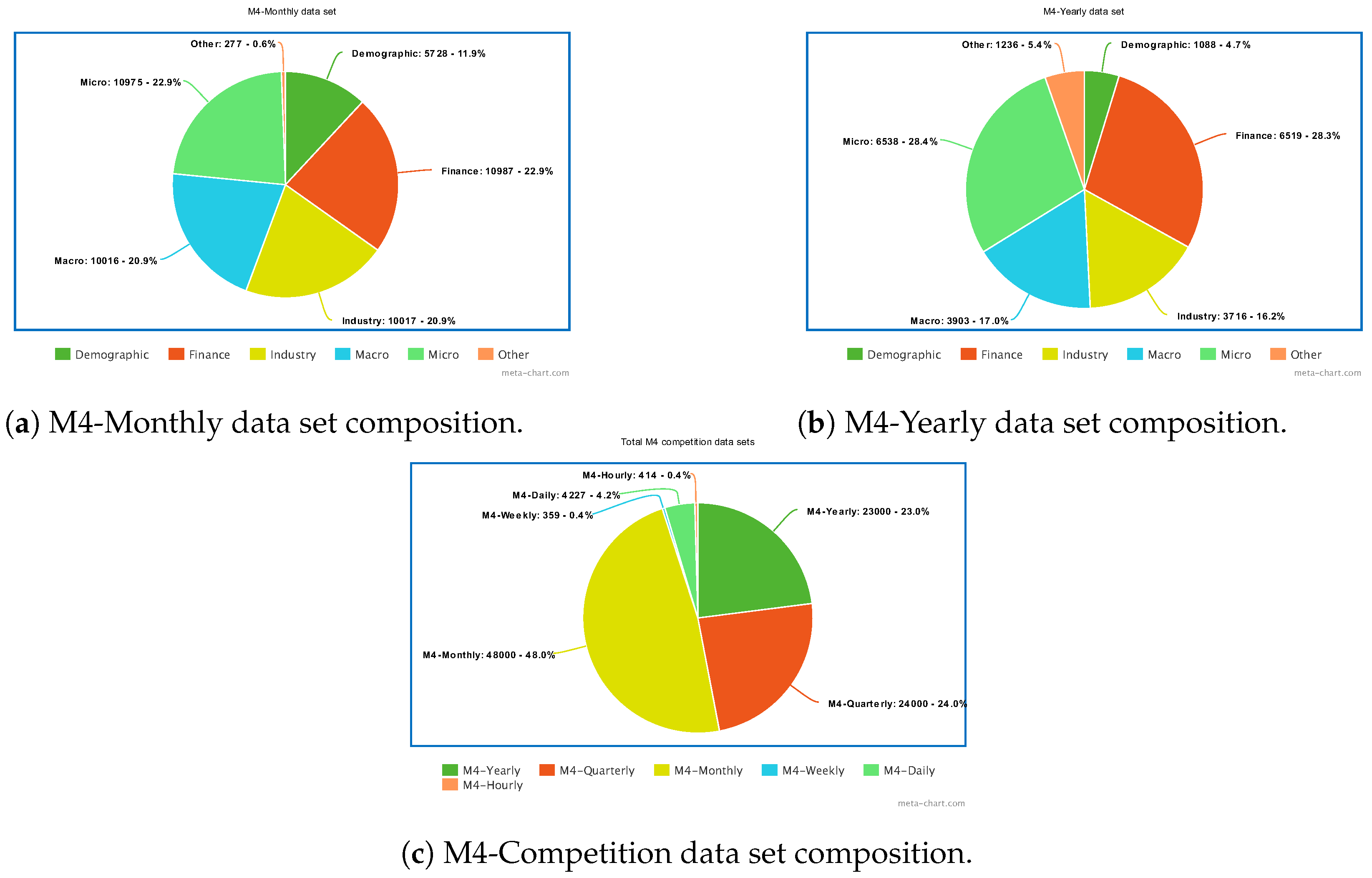
6. Benchmarks for Time Series Forecasting
6.1. Benchmarks for Short-Term Forecasting
6.2. Benchmarks for Long-Term Forecasting
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
Appendix A. Table of Mathematical Expressions

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Definition |
|---|---|
| Convolution between a kernel w and a sequence . The result is a new sequence . | |
| Element-wise product between two vectors and . The result is a vector such that . | |
| Tensor product between two vectors V and W, the result is a matrix. | |
| The Identity matrix. |
Appendix B. Diffusion Models
Appendix B.1. Denoising Diffusion Probabilistic Models
Appendix B.2. Score-Based Generative Models
Appendix B.3. Stochastic Differential Equations
References
- Chianese, E.; Camastra, F.; Ciaramella, A.; Landi, T.C.; Staiano, A.; Riccio, A. Spatio-temporal learning in predicting ambient particulate matter concentration by multi-layer perceptron. Ecol. Inform. 2019, 49, 54–61. [Google Scholar] [CrossRef]
- Feng, Y.; Zhang, W.; Sun, D.; Zhang, L. Ozone concentration forecast method based on genetic algorithm optimized back propagation neural networks and support vector machine data classification. Atmos. Environ. 2011, 45, 1979–1985. [Google Scholar] [CrossRef]
- Paine, C.T.; Marthews, T.R.; Vogt, D.R.; Purves, D.; Rees, M.; Hector, A.; Turnbull, L.A. How to fit nonlinear plant growth models and calculate growth rates: An update for ecologists. Methods Ecol. Evol. 2012, 3, 245–256. [Google Scholar] [CrossRef]
- Pala, Z.; Atici, R. Forecasting sunspot time series using deep learning methods. Sol. Phys. 2019, 294, 50. [Google Scholar] [CrossRef]
- Duarte, F.B.; Tenreiro Machado, J.; Monteiro Duarte, G. Dynamics of the Dow Jones and the NASDAQ stock indexes. Nonlinear Dyn. 2010, 61, 691–705. [Google Scholar] [CrossRef]
- Binkowski, M.; Marti, G.; Donnat, P. Autoregressive convolutional neural networks for asynchronous time series. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 580–589. [Google Scholar]
- Ugurlu, U.; Oksuz, I.; Tas, O. Electricity price forecasting using recurrent neural networks. Energies 2018, 11, 1255. [Google Scholar] [CrossRef]
- Kuan, L.; Yan, Z.; Xin, W.; Yan, C.; Xiangkun, P.; Wenxue, S.; Zhe, J.; Yong, Z.; Nan, X.; Xin, Z. Short-term electricity load forecasting method based on multilayered self-normalising GRU network. In Proceedings of the 2017 IEEE Conference on Energy Internet and Energy System Integration (EI2), Beijing, China, 26–28 November 2017; pp. 1–5. [Google Scholar]
- Zhu, R.; Liao, W.; Wang, Y. Short-term prediction for wind power based on temporal convolutional network. Energy Rep. 2020, 6, 424–429. [Google Scholar] [CrossRef]
- Koprinska, I.; Wu, D.; Wang, Z. Convolutional neural networks for energy time series forecasting. In Proceedings of the 2018 International Joint Conference on Neural Networks (IJCNN), Rio de Janeiro, Brazil, 8–13 July 2018; pp. 1–8. [Google Scholar]
- Li, D.; Jiang, F.; Chen, M.; Qian, T. Multi-step-ahead wind speed forecasting based on a hybrid decomposition method and temporal convolutional networks. Energy 2022, 238, 121981. [Google Scholar] [CrossRef]
- Narigina, M.; Kempleis, A.; Romanovs, A. Machine Learning-based Forecasting of Sensor Data for Enhanced Environmental Sensing. Wseas Trans. Syst. 2013, 22, 543–555. [Google Scholar] [CrossRef]
- Han, M.; Xu, M. Laplacian echo state network for multivariate time series prediction. IEEE Trans. Neural Netw. Learn. Syst. 2017, 29, 238–244. [Google Scholar] [CrossRef]
- Kumar, D.; Singh, A.; Samui, P.; Jha, R.K. Forecasting monthly precipitation using sequential modelling. Hydrol. Sci. J. 2019, 64, 690–700. [Google Scholar] [CrossRef]
- Wan, R.; Mei, S.; Wang, J.; Liu, M.; Yang, F. Multivariate temporal convolutional network: A deep neural networks approach for multivariate time series forecasting. Electronics 2019, 8, 876. [Google Scholar] [CrossRef]
- Liu, H.; Zhang, X. AQI time series prediction based on a hybrid data decomposition and echo state networks. Environ. Sci. Pollut. Res. 2021, 28, 51160–51182. [Google Scholar] [CrossRef] [PubMed]
- Akita, R.; Yoshihara, A.; Matsubara, T.; Uehara, K. Deep learning for stock prediction using numerical and textual information. In Proceedings of the 2016 IEEE/ACIS 15th International Conference on Computer and Information Science (ICIS), Okayama, Japan, 26–29 June 2016; pp. 1–6. [Google Scholar]
- Pang, X.; Zhou, Y.; Wang, P.; Lin, W.; Chang, V. An innovative neural network approach for stock market prediction. J. Supercomput. 2020, 76, 2098–2118. [Google Scholar] [CrossRef]
- Zhang, L.; Aggarwal, C.; Qi, G.J. Stock price prediction via discovering multi-frequency trading patterns. In Proceedings of the 23rd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Halifax, NS, Canada, 13–17 August 2017; pp. 2141–2149. [Google Scholar]
- McNally, S.; Roche, J.; Caton, S. Predicting the price of bitcoin using machine learning. In Proceedings of the 2018 26th Euromicro International Conference on Parallel, Distributed and Network-Based Processing (PDP), Cambridge, UK, 21–23 March 2018; pp. 339–343. [Google Scholar]
- Ye, J.; Liu, Z.; Du, B.; Sun, L.; Li, W.; Fu, Y.; Xiong, H. Learning the evolutionary and multi-scale graph structure for multivariate time series forecasting. In Proceedings of the 28th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Washington, DC, USA, 14–18 August 2022; pp. 2296–2306. [Google Scholar]
- Chen, L.; Chen, D.; Shang, Z.; Wu, B.; Zheng, C.; Wen, B.; Zhang, W. Multi-Scale Adaptive Graph Neural Network for Multivariate Time Series Forecasting. IEEE Trans. Knowl. Data Eng. 2023, 35, 10748–10761. [Google Scholar] [CrossRef]
- Song, Y.; Gao, S.; Li, Y.; Jia, L.; Li, Q.; Pang, F. Distributed attention-based temporal convolutional network for remaining useful life prediction. IEEE Internet Things J. 2020, 8, 9594–9602. [Google Scholar] [CrossRef]
- Alhassan, Z.; McGough, A.S.; Alshammari, R.; Daghstani, T.; Budgen, D.; Al Moubayed, N. Type-2 diabetes mellitus diagnosis from time series clinical data using deep learning models. In Proceedings of the Artificial Neural Networks and Machine Learning–ICANN 2018: 27th International Conference on Artificial Neural Networks, Rhodes, Greece, 4–7 October 2018; Proceedings, Part III 27. Springer: Berlin/Heidelberg, Germany, 2018; pp. 468–478. [Google Scholar]
- Kim, T.; King, B.R. Time series prediction using deep echo state networks. Neural Comput. Appl. 2020, 32, 17769–17787. [Google Scholar] [CrossRef]
- Lim, B. Forecasting treatment responses over time using recurrent marginal structural networks. Adv. Neural Inf. Process. Syst. 2018, 31. [Google Scholar]
- Huang, S.; Wang, D.; Wu, X.; Tang, A. Dsanet: Dual self-attention network for multivariate time series forecasting. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, Beijing, China, 3–7 November 2019; pp. 2129–2132. [Google Scholar]
- Wu, Z.; Pan, S.; Long, G.; Jiang, J.; Chang, X.; Zhang, C. Connecting the dots: Multivariate time series forecasting with graph neural networks. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual, 6–10 July 2020; pp. 753–763. [Google Scholar]
- Cui, Y.; Zheng, K.; Cui, D.; Xie, J.; Deng, L.; Huang, F.; Zhou, X. METRO: A generic graph neural network framework for multivariate time series forecasting. Proc. Vldb Endow. 2021, 15, 224–236. [Google Scholar] [CrossRef]
- Zhao, W.; Gao, Y.; Ji, T.; Wan, X.; Ye, F.; Bai, G. Deep temporal convolutional networks for short-term traffic flow forecasting. IEEE Access 2019, 7, 114496–114507. [Google Scholar] [CrossRef]
- Sagheer, A.; Kotb, M. Time series forecasting of petroleum production using deep LSTM recurrent networks. Neurocomputing 2019, 323, 203–213. [Google Scholar] [CrossRef]
- Sánchez, L.; Anseán, D.; Otero, J.; Couso, I. Assessing the health of LiFePO4 traction batteries through monotonic echo state networks. Sensors 2017, 18, 9. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.; Xiong, R.; He, H.; Pecht, M.G. Long short-term memory recurrent neural network for remaining useful life prediction of lithium-ion batteries. IEEE Trans. Veh. Technol. 2018, 67, 5695–5705. [Google Scholar] [CrossRef]
- Colla, V.; Matino, I.; Dettori, S.; Cateni, S.; Matino, R. Reservoir computing approaches applied to energy management in industry. In Proceedings of the Engineering Applications of Neural Networks: 20th International Conference, EANN 2019, Xersonisos, Greece, 24–26 May 2019; Proceedings 20. Springer: Berlin/Heidelberg, Germany, 2019; pp. 66–79. [Google Scholar]
- Li, Z.; Zheng, Z.; Outbib, R. Adaptive prognostic of fuel cells by implementing ensemble echo state networks in time-varying model space. IEEE Trans. Ind. Electron. 2019, 67, 379–389. [Google Scholar] [CrossRef]
- Bala, A.; Ismail, I.; Ibrahim, R.; Sait, S.M.; Oliva, D. An improved grasshopper optimization algorithm based echo state network for predicting faults in airplane engines. IEEE Access 2020, 8, 159773–159789. [Google Scholar] [CrossRef]
- Mahmoud, A.; Mohammed, A. A survey on deep learning for time series forecasting. In Machine Learning and Big Data Analytics Paradigms: Analysis, Applications and Challenges; Springer: Cham, Switzerland, 2021; pp. 365–392. [Google Scholar]
- Lim, B.; Zohren, S. Time-series forecasting with deep learning: A survey. Philos. Trans. R. Soc. 2021, 379, 20200209. [Google Scholar] [CrossRef] [PubMed]
- Sezer, O.B.; Gudelek, M.U.; Ozbayoglu, A.M. Financial time series forecasting with deep learning: A systematic literature review: 2005–2019. Appl. Soft Comput. 2020, 90, 106181. [Google Scholar] [CrossRef]
- Zeroual, A.; Harrou, F.; Dairi, A.; Sun, Y. Deep learning methods for forecasting COVID-19 time-Series data: A Comparative study. Chaos Solitons Fractals 2020, 140, 110121. [Google Scholar] [CrossRef]
- Lara-Benítez, P.; Carranza-García, M.; Riquelme, J.C. An experimental review on deep learning architectures for time series forecasting. Int. J. Neural Syst. 2021, 31, 2130001. [Google Scholar] [CrossRef]
- Barrera-Animas, A.Y.; Oyedele, L.O.; Bilal, M.; Akinosho, T.D.; Delgado, J.M.D.; Akanbi, L.A. Rainfall prediction: A comparative analysis of modern machine learning algorithms for time series forecasting. Mach. Learn. Appl. 2022, 7, 100204. [Google Scholar] [CrossRef]
- Lakshmanna, K.; Kaluri, R.; Gundluru, N.; Alzamil, Z.S.; Rajput, D.S.; Khan, A.A.; Haq, M.A.; Alhussen, A. A review on deep learning techniques for IoT data. Electronics 2022, 11, 1604. [Google Scholar] [CrossRef]
- Makridakis, S.; Spiliotis, E.; Assimakopoulos, V. The M4 Competition: 100,000 time series and 61 forecasting methods. Int. J. Forecast. 2020, 36, 54–74. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016. [Google Scholar]
- Hastie, T.; Tibshirani, R.; Friedman, J.H.; Friedman, J.H. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: Berlin/Heidelberg, Germany, 2009; Volume 2. [Google Scholar]
- Gudelek, M.U.; Boluk, S.A.; Ozbayoglu, A.M. A deep learning based stock trading model with 2-D CNN trend detection. In Proceedings of the 2017 IEEE Symposium Series on Computational Intelligence (SSCI), Honolulu, HI, USA, 27 November–1 December 2017; pp. 1–8. [Google Scholar]
- Kuo, P.H.; Huang, C.J. A high precision artificial neural networks model for short-term energy load forecasting. Energies 2018, 11, 213. [Google Scholar] [CrossRef]
- Zahid, M.; Ahmed, F.; Javaid, N.; Abbasi, R.A.; Zainab Kazmi, H.S.; Javaid, A.; Bilal, M.; Akbar, M.; Ilahi, M. Electricity price and load forecasting using enhanced convolutional neural network and enhanced support vector regression in smart grids. Electronics 2019, 8, 122. [Google Scholar] [CrossRef]
- Cai, M.; Pipattanasomporn, M.; Rahman, S. Day-ahead building-level load forecasts using deep learning vs. traditional time series techniques. Appl. Energy 2019, 236, 1078–1088. [Google Scholar] [CrossRef]
- Bronstein, M.M.; Bruna, J.; LeCun, Y.; Szlam, A.; Vandergheynst, P. Geometric deep learning: Going beyond euclidean data. IEEE Signal Process. Mag. 2017, 34, 18–42. [Google Scholar] [CrossRef]
- Lea, C.; Flynn, M.D.; Vidal, R.; Reiter, A.; Hager, G.D. Temporal convolutional networks for action segmentation and detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Virtual, 6–10 July 2017; pp. 156–165. [Google Scholar]
- Borovykh, A.; Bohte, S.; Oosterlee, C.W. Dilated convolutional neural networks for time series forecasting. J. Comput. Financ. Forthcom. 2018. [Google Scholar] [CrossRef]
- Lara-Benítez, P.; Carranza-García, M.; Luna-Romera, J.M.; Riquelme, J.C. Temporal convolutional networks applied to energy-related time series forecasting. Appl. Sci. 2020, 10, 2322. [Google Scholar] [CrossRef]
- Hewage, P.; Behera, A.; Trovati, M.; Pereira, E.; Ghahremani, M.; Palmieri, F.; Liu, Y. Temporal convolutional neural (TCN) network for an effective weather forecasting using time series data from the local weather station. Soft Comput. 2020, 24, 16453–16482. [Google Scholar] [CrossRef]
- Sfetsos, A.; Coonick, A. Univariate and multivariate forecasting of hourly solar radiation with artificial intelligence techniques. Sol. Energy 2000, 68, 169–178. [Google Scholar] [CrossRef]
- Hsieh, T.J.; Hsiao, H.F.; Yeh, W.C. Forecasting stock markets using wavelet transforms and recurrent neural networks: An integrated system based on artificial bee colony algorithm. Appl. Soft Comput. 2011, 11, 2510–2525. [Google Scholar] [CrossRef]
- Elman, J.L. Finding structure in time. Cogn. Sci. 1990, 14, 179–211. [Google Scholar] [CrossRef]
- Jaeger, H. The “echo state” approach to analysing and training recurrent neural networks-with an erratum note. Bonn Ger. Ger. Natl. Res. Cent. Inf. Technol. Gmd Tech. Rep. 2001, 148, 13. [Google Scholar]
- Hochreiter, S.; Schmidhuber, J. Long short-term memory. Neural Comput. 1997, 9, 1735–1780. [Google Scholar] [CrossRef]
- Cho, K.; van Merrienboer, B.; Gulcehre, C.; Bahdanau, D.; Bougares, F.; Schwenk, H.; Bengio, Y. Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; Association for Computational Linguistics: Cedarville, OH, USA, 2014; p. 1724. [Google Scholar]
- Williams, R.J.; Zipser, D. A learning algorithm for continually running fully recurrent neural networks. Neural Comput. 1989, 1, 270–280. [Google Scholar] [CrossRef]
- Jordan, M.I. Serial order: A parallel distributed processing approach. In Advances in Psychology; Elsevier: Amsterdam, The Netherlands, 1997; Volume 121, pp. 471–495. [Google Scholar]
- Shi, H.; Xu, M.; Ma, Q.; Zhang, C.; Li, R.; Li, F. A whole system assessment of novel deep learning approach on short-term load forecasting. Energy Procedia 2017, 142, 2791–2796. [Google Scholar] [CrossRef]
- Mohammadi, M.; Talebpour, F.; Safaee, E.; Ghadimi, N.; Abedinia, O. Small-scale building load forecast based on hybrid forecast engine. Neural Process. Lett. 2018, 48, 329–351. [Google Scholar] [CrossRef]
- Ruiz, L.G.B.; Rueda, R.; Cuéllar, M.P.; Pegalajar, M. Energy consumption forecasting based on Elman neural networks with evolutive optimization. Expert Syst. Appl. 2018, 92, 380–389. [Google Scholar] [CrossRef]
- Bishop, C.M. Neural Networks for Pattern Recognition; Oxford University Press: Oxford, UK, 1995. [Google Scholar]
- Kantz, H.; Schreiber, T. Nonlinear Time Series Analysis; Cambridge University Press: Cambridge, UK, 2004; Volume 7. [Google Scholar]
- Simonyan, K.; Vedaldi, A.; Zisserman, A. Deep inside convolutional networks: Visualising image classification models and saliency maps. arXiv 2013, arXiv:1312.6034. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Morando, S.; Jemei, S.; Hissel, D.; Gouriveau, R.; Zerhouni, N. ANOVA method applied to proton exchange membrane fuel cell ageing forecasting using an echo state network. Math. Comput. Simul. 2017, 131, 283–294. [Google Scholar] [CrossRef]
- Antonelo, E.A.; Camponogara, E.; Foss, B. Echo state networks for data-driven downhole pressure estimation in gas-lift oil wells. Neural Netw. 2017, 85, 106–117. [Google Scholar] [CrossRef] [PubMed]
- Shen, L.; Chen, J.; Zeng, Z.; Yang, J.; Jin, J. A novel echo state network for multivariate and nonlinear time series prediction. Appl. Soft Comput. 2018, 62, 524–535. [Google Scholar] [CrossRef]
- Jing, Z.; Yuxi, L.; Yan, C.; Bao, Y.; Jiakui, Z.; Di, L. Photovoltaic Output Prediction Model Based on Echo State Networks with Weather Type Index. In Proceedings of the 2019 3rd International Conference on Innovation in Artificial Intelligence, Suzhou, China, 15–18 March 2019; pp. 91–95. [Google Scholar]
- Hu, H.; Wang, L.; Peng, L.; Zeng, Y.R. Effective energy consumption forecasting using enhanced bagged echo state network. Energy 2020, 193, 116778. [Google Scholar] [CrossRef]
- Mansoor, M.; Grimaccia, F.; Mussetta, M. Echo State Network Performance in Electrical and Industrial Applications. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–7. [Google Scholar]
- Hu, H.; Wang, L.; Lv, S.X. Forecasting energy consumption and wind power generation using deep echo state network. Renew. Energy 2020, 154, 598–613. [Google Scholar] [CrossRef]
- Yang, Y.; Zhao, X.; Liu, X. A novel echo state network and its application in temperature prediction of exhaust gas from hot blast stove. IEEE Trans. Instrum. Meas. 2020, 69, 9465–9476. [Google Scholar] [CrossRef]
- Li, N.; Tuo, J.; Wang, Y.; Wang, M. Prediction of blood glucose concentration for type 1 diabetes based on echo state networks embedded with incremental learning. Neurocomputing 2020, 378, 248–259. [Google Scholar] [CrossRef]
- Gao, R.; Du, L.; Duru, O.; Yuen, K.F. Time series forecasting based on echo state network and empirical wavelet transformation. Appl. Soft Comput. 2021, 102, 107111. [Google Scholar] [CrossRef]
- Mansoor, M.; Grimaccia, F.; Leva, S.; Mussetta, M. Comparison of echo state network and feed-forward neural networks in electrical load forecasting for demand response programs. Math. Comput. Simul. 2021, 184, 282–293. [Google Scholar] [CrossRef]
- Sui, Y.; Gao, H. Modified echo state network for prediction of nonlinear chaotic time series. Nonlinear Dyn. 2022, 110, 3581–3603. [Google Scholar] [CrossRef]
- Marino, D.L.; Amarasinghe, K.; Manic, M. Building energy load forecasting using deep neural networks. In Proceedings of the IECON 2016—42nd Annual Conference of the IEEE Industrial Electronics Society, Florence, Italy, 23-26 October 2016; pp. 7046–7051. [Google Scholar]
- Fu, R.; Zhang, Z.; Li, L. Using LSTM and GRU neural network methods for traffic flow prediction. In Proceedings of the 2016 31st Youth Academic Annual Conference of Chinese Association of Automation (YAC), Wuhan, China, 11–13 November 2016; pp. 324–328. [Google Scholar]
- Li, Z.; Tam, V. Combining the real-time wavelet denoising and long-short-term-memory neural network for predicting stock indexes. In Proceedings of the 2017 IEEE Symposium Series on Computational Intelligence (SSCI), Honolulu, HI, USA, 27 November–1 December 2017; pp. 1–8. [Google Scholar]
- dos Santos Pinheiro, L.; Dras, M. Stock market prediction with deep learning: A character-based neural language model for event-based trading. In Proceedings of the Australasian Language Technology Association Workshop 2017, Brisbane, Australia, 6–8 December 2017; pp. 6–15. [Google Scholar]
- Shi, H.; Xu, M.; Li, R. Deep learning for household load forecasting—A novel pooling deep RNN. IEEE Trans. Smart Grid 2017, 9, 5271–5280. [Google Scholar] [CrossRef]
- Li, X.; Peng, L.; Yao, X.; Cui, S.; Hu, Y.; You, C.; Chi, T. Long short-term memory neural network for air pollutant concentration predictions: Method development and evaluation. Environ. Pollut. 2017, 231, 997–1004. [Google Scholar] [CrossRef] [PubMed]
- Baek, Y.; Kim, H.Y. ModAugNet: A new forecasting framework for stock market index value with an overfitting prevention LSTM module and a prediction LSTM module. Expert Syst. Appl. 2018, 113, 457–480. [Google Scholar] [CrossRef]
- Fischer, T.; Krauss, C. Deep learning with long short-term memory networks for financial market predictions. Eur. J. Oper. Res. 2018, 270, 654–669. [Google Scholar] [CrossRef]
- Kratzert, F.; Klotz, D.; Brenner, C.; Schulz, K.; Herrnegger, M. Rainfall–runoff modelling using Long Short-Term Memory (LSTM) networks. Hydrol. Earth Syst. Sci. 2018, 22, 6005–6022. [Google Scholar] [CrossRef]
- Zhang, J.; Zhu, Y.; Zhang, X.; Ye, M.; Yang, J. Developing a Long Short-Term Memory (LSTM) based model for predicting water table depth in agricultural areas. J. Hydrol. 2018, 561, 918–929. [Google Scholar] [CrossRef]
- Bouktif, S.; Fiaz, A.; Ouni, A.; Serhani, M.A. Optimal deep learning lstm model for electric load forecasting using feature selection and genetic algorithm: Comparison with machine learning approaches. Energies 2018, 11, 1636. [Google Scholar] [CrossRef]
- Xu, L.; Li, C.; Xie, X.; Zhang, G. Long-short-term memory network based hybrid model for short-term electrical load forecasting. Information 2018, 9, 165. [Google Scholar] [CrossRef]
- Wang, Y.; Shen, Y.; Mao, S.; Chen, X.; Zou, H. LASSO and LSTM integrated temporal model for short-term solar intensity forecasting. IEEE Internet Things J. 2018, 6, 2933–2944. [Google Scholar] [CrossRef]
- Freeman, B.S.; Taylor, G.; Gharabaghi, B.; Thé, J. Forecasting air quality time series using deep learning. J. Air Waste Manag. Assoc. (1995) 2018, 68, 866–886. [Google Scholar] [CrossRef]
- Wang, Y.; Smola, A.; Maddix, D.; Gasthaus, J.; Foster, D.; Januschowski, T. Deep factors for forecasting. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6607–6617. [Google Scholar]
- Nichiforov, C.; Stamatescu, G.; Stamatescu, I.; Făgărăşan, I. Evaluation of sequence-learning models for large-commercial-building load forecasting. Information 2019, 10, 189. [Google Scholar] [CrossRef]
- Zou, M.; Fang, D.; Harrison, G.; Djokic, S. Weather based day-ahead and week-ahead load forecasting using deep recurrent neural network. In Proceedings of the 2019 IEEE 5th International forum on Research and Technology for Society and Industry (RTSI), Florence, Italy, 9–12 September 2019; pp. 341–346. [Google Scholar]
- Chimmula, V.K.R.; Zhang, L. Time series forecasting of COVID-19 transmission in Canada using LSTM networks. Chaos Solitons Fractals 2020, 135, 109864. [Google Scholar] [CrossRef] [PubMed]
- Wu, Y.; Ni, J.; Cheng, W.; Zong, B.; Song, D.; Chen, Z.; Liu, Y.; Zhang, X.; Chen, H.; Davidson, S.B. Dynamic gaussian mixture based deep generative model for robust forecasting on sparse multivariate time series. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 651–659. [Google Scholar]
- Dastgerdi, A.K.; Mercorelli, P. Investigating the effect of noise elimination on LSTM models for financial markets prediction using Kalman Filter and Wavelet Transform. WSEAS Trans. Bus. Econ. 2022, 19, 432–441. [Google Scholar] [CrossRef]
- Wang, Y.; Liao, W.; Chang, Y. Gated recurrent unit network-based short-term photovoltaic forecasting. Energies 2018, 11, 2163. [Google Scholar] [CrossRef]
- Du, Y.; Wang, J.; Feng, W.; Pan, S.; Qin, T.; Xu, R.; Wang, C. Adarnn: Adaptive learning and forecasting of time series. In Proceedings of the 30th ACM International Conference on Information & Knowledge Management, Gold Coast, QLD, Australia, 1–5 November 2021; pp. 402–411. [Google Scholar]
- Bollerslev, T. Generalized autoregressive conditional heteroskedasticity. J. Econom. 1986, 31, 307–327. [Google Scholar] [CrossRef]
- Gensler, A.; Henze, J.; Sick, B.; Raabe, N. Deep Learning for solar power forecasting—An approach using AutoEncoder and LSTM Neural Networks. In Proceedings of the 2016 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Budapest, Hungary, 9–12 October 2016; pp. 2858–2865. [Google Scholar]
- Bao, W.; Yue, J.; Rao, Y. A deep learning framework for financial time series using stacked autoencoders and long-short term memory. PLoS ONE 2017, 12, e0180944. [Google Scholar] [CrossRef] [PubMed]
- Lee, C.Y.; Soo, V.W. Predict stock price with financial news based on recurrent convolutional neural networks. In Proceedings of the 2017 Conference on Technologies and Applications of Artificial Intelligence (TAAI), Taipei, Taiwan, 1–3 December 2017; pp. 160–165. [Google Scholar]
- Kuo, P.H.; Huang, C.J. An electricity price forecasting model by hybrid structured deep neural networks. Sustainability 2018, 10, 1280. [Google Scholar] [CrossRef]
- Tian, C.; Ma, J.; Zhang, C.; Zhan, P. A deep neural network model for short-term load forecast based on long short-term memory network and convolutional neural network. Energies 2018, 11, 3493. [Google Scholar] [CrossRef]
- Liu, H.; Mi, X.; Li, Y. Smart deep learning based wind speed prediction model using wavelet packet decomposition, convolutional neural network and convolutional long short term memory network. Energy Convers. Manag. 2018, 166, 120–131. [Google Scholar] [CrossRef]
- Chen, Y.; Wu, J.; Bu, H. Stock market embedding and prediction: A deep learning method. In Proceedings of the 2018 15th International Conference on Service Systems and Service Management (ICSSSM), Hangzhou, China, 21–22 July 2018; pp. 1–6. [Google Scholar]
- Hossain, M.A.; Karim, R.; Thulasiram, R.; Bruce, N.D.; Wang, Y. Hybrid deep learning model for stock price prediction. In Proceedings of the 2018 IEEE Symposium Series on Computational Intelligence (SSCI), Bangalore, India, 18–21 November 2018; pp. 1837–1844. [Google Scholar]
- Kim, H.Y.; Won, C.H. Forecasting the volatility of stock price index: A hybrid model integrating LSTM with multiple GARCH-type models. Expert Syst. Appl. 2018, 103, 25–37. [Google Scholar] [CrossRef]
- Li, Y.; Yu, R.; Shahabi, C.; Liu, Y. Diffusion Convolutional Recurrent Neural Network: Data-Driven Traffic Forecasting. In Proceedings of the International Conference on Learning Representations, Vancouver, BC, Canada, 30 April–3 May 2018. [Google Scholar]
- Huang, C.J.; Kuo, P.H. A deep CNN-LSTM model for particulate matter (PM2. 5) forecasting in smart cities. Sensors 2018, 18, 2220. [Google Scholar] [CrossRef]
- Soh, P.W.; Chang, J.W.; Huang, J.W. Adaptive deep learning-based air quality prediction model using the most relevant spatial-temporal relations. IEEE Access 2018, 6, 38186–38199. [Google Scholar] [CrossRef]
- Fan, C.; Zhang, Y.; Pan, Y.; Li, X.; Zhang, C.; Yuan, R.; Wu, D.; Wang, W.; Pei, J.; Huang, H. Multi-horizon time series forecasting with temporal attention learning. In Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Anchorage, AK, USA, 4–8 August 2019; pp. 2527–2535. [Google Scholar]
- Pan, C.; Tan, J.; Feng, D.; Li, Y. Very short-term solar generation forecasting based on LSTM with temporal attention mechanism. In Proceedings of the 2019 IEEE 5th International Conference on Computer and Communications (ICCC), Chengdu, China, 6–9 December 2019; pp. 267–271. [Google Scholar]
- Wang, S.; Wang, X.; Wang, S.; Wang, D. Bi-directional long short-term memory method based on attention mechanism and rolling update for short-term load forecasting. Int. J. Electr. Power Energy Syst. 2019, 109, 470–479. [Google Scholar] [CrossRef]
- Shen, Z.; Zhang, Y.; Lu, J.; Xu, J.; Xiao, G. A novel time series forecasting model with deep learning. Neurocomputing 2020, 396, 302–313. [Google Scholar] [CrossRef]
- Pal, R.; Sekh, A.A.; Kar, S.; Prasad, D.K. Neural network based country wise risk prediction of COVID-19. Appl. Sci. 2020, 10, 6448. [Google Scholar] [CrossRef]
- Dudukcu, H.V.; Taskiran, M.; Taskiran, Z.G.C.; Yildirim, T. Temporal Convolutional Networks with RNN approach for chaotic time series prediction. Appl. Soft Comput. 2023, 133, 109945. [Google Scholar] [CrossRef]
- Scarselli, F.; Gori, M.; Tsoi, A.C.; Hagenbuchner, M.; Monfardini, G. The graph neural network model. IEEE Trans. Neural Netw. 2008, 20, 61–80. [Google Scholar] [CrossRef]
- Hamilton, W.L. Graph Representation Learning; Morgan & Claypool Publishers: San Rafael, CA, USA, 2020. [Google Scholar]
- Cheng, D.; Yang, F.; Xiang, S.; Liu, J. Financial time series forecasting with multi-modality graph neural network. Pattern Recognit. 2022, 121, 108218. [Google Scholar] [CrossRef]
- Geng, X.; He, X.; Xu, L.; Yu, J. Graph correlated attention recurrent neural network for multivariate time series forecasting. Inf. Sci. 2022, 606, 126–142. [Google Scholar] [CrossRef]
- Xiang, S.; Cheng, D.; Shang, C.; Zhang, Y.; Liang, Y. Temporal and Heterogeneous Graph Neural Network for Financial Time Series Prediction. In Proceedings of the 31st ACM International Conference on Information & Knowledge Management, Atlanta, GA, USA, 17–21 October 2022; pp. 3584–3593. [Google Scholar]
- Jin, M.; Zheng, Y.; Li, Y.F.; Chen, S.; Yang, B.; Pan, S. Multivariate time series forecasting with dynamic graph neural odes. IEEE Trans. Knowl. Data Eng. 2022, 35, 9168–9180. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, Q.; Zhang, J.W.; Feng, H.; Wang, Z.; Zhou, Z.; Chen, W. Multivariate time series forecasting with temporal polynomial graph neural networks. Adv. Neural Inf. Process. Syst. 2022, 35, 19414–19426. [Google Scholar]
- Williams, C.K.; Rasmussen, C.E. Gaussian Processes for Machine Learning; MIT Press: Cambridge, MA, USA, 2006; Volume 2. [Google Scholar]
- Berg, C.; Christensen, J.P.R.; Ressel, P. Harmonic Analysis on Semigroups: Theory of Positive Definite and Related Functions; Springer: Berlin/Heidelberg, Germany, 1984; Volume 100. [Google Scholar]
- Hensman, J.; Fusi, N.; Lawrence, N.D. Gaussian processes for big data. arXiv 2013, arXiv:1309.6835. [Google Scholar]
- Damianou, A.; Lawrence, N.D. Deep gaussian processes. In Proceedings of the Artificial Intelligence and Statistics, Scottsdale, AZ, USA, 29 April–1 May 2013; pp. 207–215. [Google Scholar]
- You, J.; Li, X.; Low, M.; Lobell, D.; Ermon, S. Deep gaussian process for crop yield prediction based on remote sensing data. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Mahdi, M.D.; Mrittika, N.J.; Shams, M.; Chowdhury, L.; Siddique, S. A Deep Gaussian Process for Forecasting Crop Yield and Time Series Analysis of Precipitation Based in Munshiganj, Bangladesh. In Proceedings of the IGARSS 2020—2020 IEEE International Geoscience and Remote Sensing Symposium, Waikoloa, HI, USA, 26 September–2 October 2020; pp. 1331–1334. [Google Scholar]
- Jiang, Y.; Fan, J.; Liu, Y.; Zhang, X. Deep graph Gaussian processes for short-term traffic flow forecasting from spatiotemporal data. IEEE Trans. Intell. Transp. Syst. 2022, 23, 20177–20186. [Google Scholar] [CrossRef]
- Chang, W.; Li, R.; Fu, Y.; Xiao, Y.; Zhou, S. A multistep forecasting method for online car-hailing demand based on wavelet decomposition and deep Gaussian process regression. J. Supercomput. 2023, 79, 3412–3436. [Google Scholar] [CrossRef]
- Camastra, F.; Casolaro, A.; Iannuzzo, G. Time Series prediction with missing data by an Iterated Deep Gaussian Process. In Proceedings of the 31st Edition of WIRN 2023, Vietri sul Mare, Salerno, Italy, 22–26 May 2023. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Volume 27. [Google Scholar]
- Radford, A.; Metz, L.; Chintala, S. Unsupervised representation learning with deep convolutional generative adversarial networks. arXiv 2015, arXiv:1511.06434. [Google Scholar]
- Mogren, O. C-RNN-GAN: Continuous recurrent neural networks with adversarial training. arXiv 2016, arXiv:1611.09904. [Google Scholar]
- Box, G.E.; Jenkins, G.M.; Reinsel, G.C.; Ljung, G.M. Time Series Analysis: Forecasting and Control; John Wiley & Sons: Hoboken, NJ, USA, 2015. [Google Scholar]
- Wu, D.; Hur, K.; Xiao, Z. A GAN-Enhanced Ensemble Model for Energy Consumption Forecasting in Large Commercial Buildings. IEEE Access 2021, 9, 158820–158830. [Google Scholar] [CrossRef]
- Mirza, M.; Osindero, S. Conditional generative adversarial nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Chen, X.; Duan, Y.; Houthooft, R.; Schulman, J.; Sutskever, I.; Abbeel, P. InfoGAN: Interpretable Representation Learning by Information Maximising Generative Adversarial Nets. Adv. Neural Inf. Process. Syst. 2016, 29. [Google Scholar]
- Wang, H.; Tao, G.; Ma, J.; Jia, S.; Chi, L.; Yang, H.; Zhao, Z.; Tao, J. Predicting the epidemics trend of COVID-19 using epidemiological-based generative adversarial networks. IEEE J. Sel. Top. Signal Process. 2022, 16, 276–288. [Google Scholar] [CrossRef]
- Wiese, M.; Knobloch, R.; Korn, R.; Kretschmer, P. Quant GANs: Deep generation of financial time series. Quant. Financ. 2020, 20, 1419–1440. [Google Scholar] [CrossRef]
- Hazra, D.; Byun, Y.C. SynSigGAN: Generative adversarial networks for synthetic biomedical signal generation. Biology 2020, 9, 441. [Google Scholar] [CrossRef] [PubMed]
- Esteban, C.; Hyland, S.L.; Rätsch, G. Real-valued (medical) time series generation with recurrent conditional gans. arXiv 2017, arXiv:1706.02633. [Google Scholar]
- Yoon, J.; Jarrett, D.; Van der Schaar, M. Time-series generative adversarial networks. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Ni, H.; Szpruch, L.; Wiese, M.; Liao, S.; Xiao, B. Conditional sig-wasserstein gans for time series generation. arXiv 2020, arXiv:2006.05421. [Google Scholar] [CrossRef]
- Li, X.; Metsis, V.; Wang, H.; Ngu, A.H.H. Tts-gan: A transformer-based time series generative adversarial network. In Proceedings of the International Conference on Artificial Intelligence in Medicine, Halifax, NS, Canada, 14–17 June 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 133–143. [Google Scholar]
- Koochali, A.; Schichtel, P.; Dengel, A.; Ahmed, S. Probabilistic forecasting of sensory data with generative adversarial networks–ForGAN. IEEE Access 2019, 7, 63868–63880. [Google Scholar] [CrossRef]
- Bej, A.; Maulik, U.; Sarkar, A. Time-Series prediction for the epidemic trends of COVID-19 using Conditional Generative adversarial Networks Regression on country-wise case studies. SN Comput. Sci. 2022, 3, 352. [Google Scholar] [CrossRef]
- Zúñiga, G.; Acuña, G. Probabilistic multistep time series forecasting using conditional generative adversarial networks. In Proceedings of the 2021 IEEE Latin American Conference on Computational Intelligence (LA-CCI), Temuco, Chile, 2–4 November 2021; pp. 1–6. [Google Scholar]
- Huang, X.; Li, Q.; Tai, Y.; Chen, Z.; Liu, J.; Shi, J.; Liu, W. Time series forecasting for hourly photovoltaic power using conditional generative adversarial network and Bi-LSTM. Energy 2022, 246, 123403. [Google Scholar] [CrossRef]
- Li, F.; Zheng, H.; Li, X. A novel hybrid model for multi-step ahead photovoltaic power prediction based on conditional time series generative adversarial networks. Renew. Energy 2022, 199, 560–586. [Google Scholar] [CrossRef]
- Zhou, X.; Pan, Z.; Hu, G.; Tang, S.; Zhao, C. Stock market prediction on high-frequency data using generative adversarial nets. Math. Probl. Eng. 2018, 2018, 4907423. [Google Scholar] [CrossRef]
- Zhang, Y.; Wang, S.; Chen, B.; Cao, J.; Huang, Z. Trafficgan: Network-scale deep traffic prediction with generative adversarial nets. IEEE Trans. Intell. Transp. Syst. 2019, 22, 219–230. [Google Scholar] [CrossRef]
- Kaushik, S.; Choudhury, A.; Natarajan, S.; Pickett, L.A.; Dutt, V. Medicine expenditure prediction via a variance-based generative adversarial network. IEEE Access 2020, 8, 110947–110958. [Google Scholar] [CrossRef]
- Gu, Y.; Chen, Q.; Liu, K.; Xie, L.; Kang, C. GAN-based Model for Residential Load Generation Considering Typical Consumption Patterns. In Proceedings of the 2019 IEEE Power & Energy Society Innovative Smart Grid Technologies Conference (ISGT), Washington, DC, USA, 18–21 February 2019; pp. 1–5. [Google Scholar]
- He, B.; Kita, E. Stock price prediction by using hybrid sequential generative adversarial networks. In Proceedings of the 2020 International Conference on Data Mining Workshops (ICDMW), Sorrento, Italy, 17–20 November 2020; pp. 341–347. [Google Scholar]
- Wu, S.; Xiao, X.; Ding, Q.; Zhao, P.; Wei, Y.; Huang, J. Adversarial sparse transformer for time series forecasting. Adv. Neural Inf. Process. Syst. 2020, 33, 17105–17115. [Google Scholar]
- Li, Q.; Hao, H.; Zhao, Y.; Geng, Q.; Liu, G.; Zhang, Y.; Yu, F. GANs-LSTM model for soil temperature estimation from meteorological: A new approach. IEEE Access 2020, 8, 59427–59443. [Google Scholar] [CrossRef]
- Yin, X.; Han, Y.; Sun, H.; Xu, Z.; Yu, H.; Duan, X. Multi-attention generative adversarial network for multivariate time series prediction. IEEE Access 2021, 9, 57351–57363. [Google Scholar] [CrossRef]
- Wu, W.; Huang, F.; Kao, Y.; Chen, Z.; Wu, Q. Prediction method of multiple related time series based on generative adversarial networks. Information 2021, 12, 55. [Google Scholar] [CrossRef]
- Jiang, C.; Mao, Y.; Chai, Y.; Yu, M. Day-ahead renewable scenario forecasts based on generative adversarial networks. Int. J. Energy Res. 2021, 45, 7572–7587. [Google Scholar] [CrossRef]
- Bendaoud, N.M.M.; Farah, N.; Ben Ahmed, S. Comparing Generative Adversarial Networks architectures for electricity demand forecasting. Energy Build. 2021, 247, 111152. [Google Scholar] [CrossRef]
- Wu, X.; Yang, H.; Chen, H.; Hu, Q.; Hu, H. Long-term 4D trajectory prediction using generative adversarial networks. Transp. Res. Part Emerg. Technol. 2022, 136, 103554. [Google Scholar] [CrossRef]
- Ye, Y.; Strong, M.; Lou, Y.; Faulkner, C.A.; Zuo, W.; Upadhyaya, S. Evaluating performance of different generative adversarial networks for large-scale building power demand prediction. Energy Build. 2022, 269, 112247. [Google Scholar] [CrossRef]
- Vuletić, M.; Prenzel, F.; Cucuringu, M. Fin-Gan: Forecasting and Classifying Financial Time Series via Generative Adversarial Networks. 2023. Available online: https://ssrn.com/abstract=4328302 (accessed on 25 September 2023).
- Sohl-Dickstein, J.; Weiss, E.; Maheswaranathan, N.; Ganguli, S. Deep unsupervised learning using nonequilibrium thermodynamics. In Proceedings of the International Conference on Machine Learning, Lille, France, 7–9 July 2015; pp. 2256–2265. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising diffusion probabilistic models. Adv. Neural Inf. Process. Syst. 2020, 33, 6840–6851. [Google Scholar]
- Song, Y.; Ermon, S. Generative modeling by estimating gradients of the data distribution. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Song, Y.; Sohl-Dickstein, J.; Kingma, D.P.; Kumar, A.; Ermon, S.; Poole, B. Score-Based Generative Modeling through Stochastic Differential Equations. In Proceedings of the International Conference on Learning Representations, Addis Ababa, Ethiopia, 26–32 April 2020. [Google Scholar]
- Rasul, K.; Seward, C.; Schuster, I.; Vollgraf, R. Autoregressive denoising diffusion models for multivariate probabilistic time series forecasting. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 8857–8868. [Google Scholar]
- Yan, T.; Zhang, H.; Zhou, T.; Zhan, Y.; Xia, Y. ScoreGrad: Multivariate probabilistic time series forecasting with continuous energy-based generative models. arXiv 2021, arXiv:2106.10121. [Google Scholar]
- Li, Y.; Lu, X.; Wang, Y.; Dou, D. Generative time series forecasting with diffusion, denoise, and disentanglement. Adv. Neural Inf. Process. Syst. 2022, 35, 23009–23022. [Google Scholar]
- Biloš, M.; Rasul, K.; Schneider, A.; Nevmyvaka, Y.; Günnemann, S. Modeling temporal data as continuous functions with process diffusion. arXiv 2022, arXiv:2211.02590. [Google Scholar]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30. [Google Scholar]
- Zhou, H.; Zhang, S.; Peng, J.; Zhang, S.; Li, J.; Xiong, H.; Zhang, W. Informer: Beyond efficient transformer for long sequence time series forecasting. In Proceedings of the AAAI Conference on Artificial Intelligence, Virtual, 2–9 February 2021; Volume 35, pp. 11106–11115. [Google Scholar]
- Wu, H.; Xu, J.; Wang, J.; Long, M. Autoformer: Decomposition transformers with auto-correlation for long-term series forecasting. Adv. Neural Inf. Process. Syst. 2021, 34, 22419–22430. [Google Scholar]
- Zhou, T.; Ma, Z.; Wen, Q.; Wang, X.; Sun, L.; Jin, R. Fedformer: Frequency enhanced decomposed transformer for long-term series forecasting. In Proceedings of the International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; pp. 27268–27286. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 770–778. [Google Scholar]
- Ba, J.L.; Kiros, J.R.; Hinton, G.E. Layer normalization. arXiv 2016, arXiv:1607.06450. [Google Scholar]
- Luong, T.; Pham, H.; Manning, C.D. Effective Approaches to Attention-based Neural Machine Translation. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; Association for Computational Linguistics: Cedarville, OH, USA, 2015; pp. 1412–1421. [Google Scholar]
- Li, S.; Jin, X.; Xuan, Y.; Zhou, X.; Chen, W.; Wang, Y.X.; Yan, X. Enhancing the locality and breaking the memory bottleneck of transformer on time series forecasting. Adv. Neural Inf. Process. Syst. 2019, 32. [Google Scholar]
- Wang, S.; Li, B.Z.; Khabsa, M.; Fang, H.; Ma, H. Linformer: Self-attention with linear complexity. arXiv 2020, arXiv:2006.04768. [Google Scholar]
- Donoho, D.L. Compressed sensing. IEEE Trans. Inf. Theory 2006, 52, 1289–1306. [Google Scholar] [CrossRef]
- Nie, Y.; Nguyen, N.H.; Sinthong, P.; Kalagnanam, J. A Time Series is Worth 64 Words: Long-term Forecasting with Transformers. In Proceedings of the International Conference on Learning Representations, Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Zhang, Y.; Yan, J. Crossformer: Transformer utilising cross-dimension dependency for multivariate time series forecasting. In Proceedings of the Eleventh International Conference on Learning Representations, Kigali, Rwanda, 1–5 May 2022. [Google Scholar]
- Liu, S.; Yu, H.; Liao, C.; Li, J.; Lin, W.; Liu, A.X.; Dustdar, S. Pyraformer: Low-Complexity Pyramidal Attention for Long-Range Time Series Modeling and Forecasting. In Proceedings of the International Conference on Learning Representations, Virtual, 25–29 April 2022. [Google Scholar]
- Shabani, M.A.; Abdi, A.H.; Meng, L.; Sylvain, T. Scaleformer: Iterative Multi-scale Refining Transformers for Time Series Forecasting. In Proceedings of the The Eleventh International Conference on Learning Representations, Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Cirstea, R.G.; Guo, C.; Yang, B.; Kieu, T.; Dong, X.; Pan, S. Triformer: Triangular, Variable-Specific Attentions for Long Sequence Multivariate Time Series Forecasting–Full Version. arXiv 2022, arXiv:2204.13767. [Google Scholar]
- Liu, Y.; Wu, H.; Wang, J.; Long, M. Non-stationary transformers: Exploring the stationarity in time series forecasting. Adv. Neural Inf. Process. Syst. 2022, 35, 9881–9893. [Google Scholar]
- Schirmer, M.; Eltayeb, M.; Lessmann, S.; Rudolph, M. Modeling irregular time series with continuous recurrent units. In Proceedings of the International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; pp. 19388–19405. [Google Scholar]
- Zhou, T.; Ma, Z.; Wen, Q.; Sun, L.; Yao, T.; Yin, W.; Jin, R. Film: Frequency improved legendre memory model for long-term time series forecasting. Adv. Neural Inf. Process. Syst. 2022, 35, 12677–12690. [Google Scholar]
- Ekambaram, V.; Jati, A.; Nguyen, N.; Sinthong, P.; Kalagnanam, J. TSMixer: Lightweight MLP-Mixer Model for Multivariate Time Series Forecasting. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining, Long Beach, CA, USA, 6–10 August 2023; pp. 459–469. [Google Scholar]
- Wang, H.; Peng, J.; Huang, F.; Wang, J.; Chen, J.; Xiao, Y. MICN: Multi-scale Local and Global Context Modeling for Long-term Series Forecasting. In Proceedings of the Eleventh International Conference on Learning Representations, Kigali, Rwanda, 1–5 May 2023. [Google Scholar]
- Mackey, M.C.; Glass, L. Oscillation and chaos in physiological control systems. Science 1977, 197, 287–289. [Google Scholar] [CrossRef] [PubMed]
- Weiss, C.O.; Hübner, U.; Abraham, N.B.; Tang, D. Lorenz-like chaos in NH3-FIR lasers. Infrared Phys. Technol. 1995, 36, 489–512. [Google Scholar] [CrossRef]
- Aguirre, L.A.; Rodrigues, G.G.; Mendes, E.M. Nonlinear identification and cluster analysis of chaotic attractors from a real implementation of Chua’s circuit. Int. J. Bifurc. Chaos 1997, 7, 1411–1423. [Google Scholar] [CrossRef]
- Wijngaard, J.; Klein Tank, A.; Können, G. Homogeneity of 20th century European daily temperature and precipitation series. Int. J. Climatol. J. R. Meteorol. Soc. 2003, 23, 679–692. [Google Scholar] [CrossRef]
- Weigend, A.S.; Gershenfeld, N.A. Time Series Prediction: Forecasting the Future and Understanding the Past; Santa Fe Institute Studies in the Sciences of Complexity: Santa Fe, NM, USA, 1994. [Google Scholar]
- Jospin, L.V.; Laga, H.; Boussaid, F.; Buntine, W.; Bennamoun, M. Hands-on Bayesian neural networks—A tutorial for deep learning users. IEEE Comput. Intell. Mag. 2022, 17, 29–48. [Google Scholar] [CrossRef]
- Lu, J.; Liu, A.; Dong, F.; Gu, F.; Gama, J.; Zhang, G. Learning under concept drift: A review. IEEE Trans. Knowl. Data Eng. 2018, 31, 2346–2363. [Google Scholar] [CrossRef]
- Hyvärinen, A.; Dayan, P. Estimation of non-normalized statistical models by score matching. J. Mach. Learn. Res. 2005, 6. [Google Scholar]
- Vincent, P. A connection between score matching and denoising autoencoders. Neural Comput. 2011, 23, 1661–1674. [Google Scholar] [CrossRef] [PubMed]
- Song, Y.; Garg, S.; Shi, J.; Ermon, S. Sliced score matching: A scalable approach to density and score estimation. In Proceedings of the Uncertainty in Artificial Intelligence, Virtual, 3–6 August 2020; pp. 574–584. [Google Scholar]
- Anderson, B.D. Reverse-time diffusion equation models. Stoch. Process. Their Appl. 1982, 12, 313–326. [Google Scholar] [CrossRef]
- Papoulis, A.; Unnikrishna Pillai, S. Probability, Random Variables and Stochastic Processes; McGraw-Hill: New York, NY, USA, 2002. [Google Scholar]










| Ref. | Year | Application |
|---|---|---|
| [47] | 2017 | ETFs prices |
| [48] | 2018 | Electricity consumption |
| [10] | 2018 | Solar power and electricity load |
| [6] | 2018 | Electricity consumption |
| [7] | 2018 | Electricity price |
| [49] | 2019 | Electricity price and load forecasting |
| [50] | 2019 | Building-level load |
| [12] | 2023 | /Temperature/Humidity |
| Ref. | Year | Application |
|---|---|---|
| [53] | 2018 | Stock market |
| [15] | 2019 | Beijing |
| [30] | 2019 | Traffic |
| [54] | 2020 | National electric demand and power demand |
| [9] | 2020 | Wind power generation |
| [55] | 2020 | Weather |
| [11] | 2022 | Wind speed |
| Ref. | Year | Application |
|---|---|---|
| [64] | 2017 | Electricity load |
| [65] | 2018 | Electricity load |
| [66] | 2018 | Energy consumption |
| [14] | 2019 | Monthly precipitation |
| [16] | 2021 | Air Quality Index |
| Ref. | Year | Application |
|---|---|---|
| [71] | 2017 | Fuel cell voltage ageing |
| [32] | 2017 | Health of automotive batteries |
| [72] | 2017 | Slugging flow phenomenon |
| [13] | 2017 | Temperature/Rainfall |
| [73] | 2018 | Lorenz/Rossler/Sunspot-Runoff |
| [34] | 2019 | Industrial processes |
| [35] | 2019 | Fuel cell durability |
| [74] | 2019 | Photovoltaic voltage |
| [75] | 2020 | Electricity load |
| [76] | 2020 | Electricity load |
| [77] | 2020 | Energy consumption/Wind power generation |
| [78] | 2020 | Temperature of exhaust gas |
| [36] | 2020 | Faults in airplane engines |
| [79] | 2020 | Multiple time series |
| [25] | 2020 | Blood glucose concentration |
| [80] | 2021 | Multiple time series |
| [81] | 2021 | Electrical load |
| [16] | 2021 | Air Quality Index |
| [82] | 2022 | Chaotic time series |
| Ref. | Year | Application |
|---|---|---|
| [17] | 2016 | Stock market |
| [83] | 2016 | Electricity load |
| [84] | 2016 | Traffic flow |
| [19] | 2017 | Stock prices |
| [85,86] | 2017 | Stock market |
| [87] | 2017 | Electricity load |
| [88] | 2017 | Air quality |
| [26] | 2018 | Forecasting Cancer Growth |
| [89,90] | 2018 | Stock market |
| [20] | 2018 | Stock prices |
| [7] | 2018 | Electricity price |
| [24] | 2018 | Diabetes mellitus |
| [91] | 2018 | Rainfall-runoff modelling |
| [92] | 2018 | Predicting water table depth |
| [93,94] | 2018 | Electricity load |
| [33] | 2018 | Life prediction of batteries |
| [10] | 2018 | Solar power and electricity load |
| [95] | 2018 | Solar intensity |
| [96] | 2018 | Air quality |
| [97] | 2019 | UCI data sets |
| [98] | 2019 | Building load |
| [31] | 2019 | Petroleum production |
| [14] | 2019 | Monthly precipitation |
| [99] | 2019 | Weather forecasting |
| [18] | 2020 | Stock market |
| [100] | 2020 | COVID-19 |
| [79] | 2020 | Multiple time series |
| [101] | 2021 | Weather/Air Quality/Clinical data |
| [16] | 2021 | Air Quality Index |
| [102] | 2022 | Financial markets |
| [12] | 2023 | /Temperature/Humidity |
| Ref. | Year | Application |
|---|---|---|
| [84] | 2016 | Traffic flow |
| [8] | 2017 | Electricity load |
| [103] | 2018 | Photovoltaic forecasting |
| [7] | 2018 | Electricity price |
| [24] | 2018 | Diabetes mellitus |
| [97] | 2019 | UCI data sets |
| [79] | 2020 | Multiple time series |
| [104] | 2021 | Air quality/Stock prices/Household electric power |
| Ref. | Year | Architecture | Application |
|---|---|---|---|
| [106] | 2016 | Autoencoder + LSTM | Solar power |
| [107] | 2017 | Autoencoder + LSTM | Stock prices |
| [108] | 2017 | CNN + LSTM | Stock prices |
| [109] | 2018 | CNN + LSTM | Electricity prices |
| [110] | 2018 | CNN + LSTM | Electricity load |
| [111] | 2018 | CNN + LSTM | Wind speed |
| [112] | 2018 | LSTM + Attention mechanism (see Section 4.1.1) | Stock market |
| [113] | 2018 | LSTM + GRU | Stock prices |
| [114] | 2018 | GARCH + LSTM | Stock prices |
| [115] | 2018 | GRU variant | Traffic forecasting |
| [116] | 2018 | CNN + LSTM | concentration |
| [117] | 2018 | ANN + LSTM + CNN | concentration |
| [118] | 2019 | LSTM + Attention mechanism (see Section 4.1.1) | Online Sales/Electricity prices |
| [119] | 2019 | LSTM + Attention mechanism (see Section 4.1.1) | Solar generation |
| [120] | 2019 | LSTM + Attention mechanism (see Section 4.1.1) | Electricity load |
| [27] | 2019 | CNN + Attention mechanism (see Section 4.1.1) | Traffic/Stock market |
| [121] | 2020 | CNN + LSTM | Stock market/Temperature |
| [122] | 2020 | LSTM + Fuzzy Logic | COVID-19 |
| [23] | 2020 | TCN + Attention | Remaining Useful Life |
| [123] | 2023 | TCN + LSTM/GRU | Chaotic Time Series/ECG |
| Ref. | Year | Application |
|---|---|---|
| [28] | 2020 | Traffic/Electricity load/Exchange rate |
| [29] | 2021 | Solar energy/Traffic/Electricity load/Exchange rate |
| [126] | 2022 | Stock market |
| [127] | 2022 | /Traffic/Wind speed |
| [128] | 2022 | Stock market |
| [129] | 2022 | Electricity load/Solar energy/Traffic |
| [21] | 2022 | Solar energy/Wind power generation/Electricity load/Exchange rate |
| [130] | 2022 | Solar energy/Traffic/Electricity load/Exchange rate |
| [22] | 2023 | Solar energy/Traffic/Electricity load/Exchange rate |
| Ref. | Year | Application |
|---|---|---|
| [135] | 2017 | Crop Yield forecasting |
| [136] | 2020 | Crop Yield forecasting |
| [137] | 2022 | Electricity load |
| [138] | 2023 | Car-hailing demand |
| [139] | 2023 | Ozone concentration forecasting |
| Ref. | Year | Application |
|---|---|---|
| [159] | 2018 | Stock market |
| [160] | 2019 | Traffic forecasting |
| [154] | 2019 | Lorenz/Mackey-Glass/Internet Traffic data |
| [161] | 2019 | Medicine expenditure |
| [162] | 2019 | Electricity load |
| [163] | 2020 | Stock price |
| [164] | 2020 | Long-term benchmark data sets (see Section 6.2) |
| [165] | 2020 | Soil temperature |
| [166] | 2021 | Stock market/Energy production/EEG/Air quality |
| [156] | 2021 | Internet Traffic data |
| [167] | 2021 | Store Item Demand/Internet Traffic/Meteorological data |
| [168] | 2021 | Wind power/Solar power |
| [144] | 2021 | Energy consumption |
| [169] | 2021 | Electricity load |
| [170] | 2022 | Trajectories forecasting |
| [147,155] | 2022 | COVID-19 |
| [157,158] | 2022 | Photovoltaic power |
| [171] | 2022 | Building power demand |
| [172] | 2023 | Financial time series |
| Ref. | Year | Model |
|---|---|---|
| [177] | 2021 | TimeGrad |
| [178] | 2021 | ScoreGrad |
| [180] | 2022 | DSPD |
| [179] | 2022 |
| Ref. | Year | Model |
|---|---|---|
| [188] | 2019 | LogTrans |
| [182] | 2021 | Informer |
| [183] | 2021 | Autoformer |
| [184] | 2022 | FEDFormer |
| [193] | 2022 | Pyraformer |
| [195] | 2022 | Triformer |
| [196] | 2022 | Non-stationary Transfomers |
| [191] | 2023 | PatchTST |
| [192] | 2023 | Crossformer |
| [194] | 2023 | Scaleformer |
| Models | Crossformer | PatchTST | Non-Stationary | Pyraformer | FEDFormer | Autoformer | Informer | LogTrans | LSTM | TCN | |||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Metric | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | MSE | MAE | |
| Weather | 96 | - | - | 0.149 | 0.198 | 0.173 | 0.223 | 0.354 | 0.392 | 0.217 | 0.296 | 0.266 | 0.336 | 0.300 | 0.384 | 0.458 | 0.490 | 0.369 | 0.406 | 0.615 | 0.589 |
| 192 | - | - | 0.194 | 0.241 | 0.245 | 0.285 | 0.673 | 0.597 | 0.276 | 0.336 | 0.307 | 0.367 | 0.598 | 0.544 | 0.658 | 0.589 | 0.416 | 0.435 | 0.629 | 0.600 | |
| 336 | 0.495 | 0.515 | 0.245 | 0.282 | 0.321 | 0.338 | 0.634 | 0.592 | 0.339 | 0.380 | 0.359 | 0.395 | 0.578 | 0.523 | 0.797 | 0.652 | 0.455 | 0.454 | 0.639 | 0.608 | |
| 720 | 0.526 | 0.542 | 0.314 | 0.334 | 0.414 | 0.410 | 0.942 | 0.723 | 0.403 | 0.482 | 0.419 | 0.428 | 1.059 | 0.741 | 0.869 | 0.675 | 0.535 | 0.520 | 0.639 | 0.610 | |
| Traffic | 96 | - | - | 0.360 | 0.249 | 0.612 | 0.338 | 0.684 | 0.393 | 0.562 | 0.349 | 0.613 | 0.388 | 0.719 | 0.391 | 0.684 | 0.384 | 0.843 | 0.453 | 1.438 | 0.784 |
| 192 | - | - | 0.379 | 0.256 | 0.613 | 0.340 | 0.692 | 0.394 | 0.562 | 0.346 | 0.616 | 0.382 | 0.696 | 0.379 | 0.685 | 0.390 | 0.847 | 0.453 | 1.463 | 0.794 | |
| 336 | 0.530 | 0.300 | 0.392 | 0.264 | 0.618 | 0.328 | 0.699 | 0.396 | 0.570 | 0.323 | 0.622 | 0.337 | 0.777 | 0.420 | 0.733 | 0.408 | 0.853 | 0.455 | 1.479 | 0.799 | |
| 720 | 0.573 | 0.313 | 0.432 | 0.286 | 0.653 | 0.355 | 0.712 | 0.404 | 0.596 | 0.368 | 0.660 | 0.408 | 0.864 | 0.472 | 0.717 | 0.396 | 0.500 | 0.805 | 1.499 | 0.804 | |
| Electricity | 96 | - | - | 0.129 | 0.222 | 0.169 | 0.273 | 0.498 | 0.299 | 0.183 | 0.297 | 0.201 | 0.317 | 0.274 | 0.368 | 0.258 | 0.357 | 0.375 | 0.437 | 0.985 | 0.813 |
| 192 | - | - | 0.147 | 0.240 | 0.182 | 0.286 | 0.828 | 0.312 | 0.195 | 0.308 | 0.222 | 0.334 | 0.296 | 0.386 | 0.266 | 0.368 | 0.442 | 0.473 | 0.996 | 0.821 | |
| 336 | 0.323 | 0.369 | 0.163 | 0.159 | 0.200 | 0.304 | 1.476 | 0.326 | 0.212 | 0.313 | 0.231 | 0.338 | 0.300 | 0.394 | 0.280 | 0.380 | 0.439 | 0.473 | 1.000 | 0.824 | |
| 720 | 0.404 | 0.423 | 0.197 | 0.290 | 0.222 | 0.321 | 4.090 | 0.372 | 0.231 | 0.343 | 0.254 | 0.361 | 0.373 | 0.439 | 0.283 | 0.376 | 0.980 | 0.814 | 1.438 | 0.784 | |
| ILI | 24 | 3.041 | 1.186 | 1.319 | 0.754 | 2.294 | 0.945 | 5.800 | 1.693 | 2.203 | 0.963 | 3.483 | 1.287 | 5.764 | 1.677 | 4.480 | 1.444 | 5.914 | 1.734 | 6.624 | 1.830 |
| 36 | 3.406 | 1.232 | 1.579 | 0.870 | 1.825 | 0.848 | 6.043 | 1.733 | 2.272 | 0.976 | 3.103 | 1.148 | 4.755 | 1.467 | 4.799 | 1.467 | 6.631 | 1.845 | 6.858 | 1.879 | |
| 48 | 3.459 | 1.221 | 1.553 | 0.815 | 2.010 | 0.900 | 6.213 | 1.763 | 2.209 | 0.981 | 2.669 | 1.085 | 4.763 | 1.469 | 4.800 | 1.468 | 6.736 | 1.857 | 6.968 | 1.892 | |
| 60 | 3.640 | 1.305 | 1.470 | 0.788 | 2.178 | 0.963 | 6.531 | 1.814 | 2.545 | 1.061 | 2.770 | 1.125 | 5.264 | 1.564 | 5.278 | 1.560 | 6.870 | 1.879 | 7.127 | 1.918 | |
| ETTm2 | 96 | - | - | 0.166 | 0.256 | 0.192 | 0.274 | 0.409 | 0.488 | 0.203 | 0.287 | 0.255 | 0.339 | 0.365 | 0.453 | 0.768 | 0.642 | 2.041 | 1.073 | 3.041 | 1.330 |
| 192 | - | - | 0.223 | 0.296 | 0.280 | 0.339 | 0.673 | 0.641 | 0.269 | 0.328 | 0.281 | 0.340 | 0.533 | 0.563 | 0.989 | 0.757 | 2.249 | 1.112 | 3.072 | 1.339 | |
| 336 | - | - | 0.274 | 0.329 | 0.334 | 0.361 | 1.210 | 0.846 | 0.325 | 0.366 | 0.339 | 0.372 | 1.363 | 0.887 | 1.334 | 0.872 | 2.568 | 1.238 | 3.105 | 1.348 | |
| 720 | - | - | 0.362 | 0.385 | 0.417 | 0.413 | 4.044 | 1.526 | 0.421 | 0.415 | 0.422 | 0.419 | 3.379 | 1.388 | 3.048 | 1.328 | 2.720 | 1.287 | 3.153 | 1.354 | |
| Ref. | Year | Application |
|---|---|---|
| [197] | 2022 | Climate data/Electronic Health Records |
| [198] | 2022 | Long-term benchmark data sets (see Section 6.2) |
| [199,200] | 2023 | Long-term benchmark data sets (see Section 6.2) |
| Dataset | Dim | Data Type (Real/Synthetic) |
|---|---|---|
| M4-Yearly [44] | 1 | Real |
| M4-Quarterly [44] | 1 | Real |
| M4-Monthly [44] | 1 | Real |
| M4-Weekly [44] | 1 | Real |
| M4-Daily [44] | 1 | Real |
| M4-Hourly [44] | 1 | Real |
| Mackey-Glass [201] | 1 | Synthetic |
| DatasetA [202] | 1 | Real |
| DSVC1 [203] | 1 | Real |
| Paris-14E [204] | 1 | Real |
| DatasetD [205] | 1 | Synthetic |
| Dataset | Dim | Pred Len | Dataset Size | Time Res | Domain |
|---|---|---|---|---|---|
| ETTm1 | 7 | [96,192,336,720] | (34,465, 11,521, 11,521) | 15 mins | Electricity |
| ETTm2 | 7 | [96,192,336,720] | (34,465, 11,521, 11,521) | 15 mins | Electricity |
| ETTh1 | 7 | [96,192,336,720] | (8545, 2881, 2881) | 15 mins | Electricity |
| ETTh2 | 7 | [96,192,336,720] | (8545, 2881, 2881) | 15 mins | Electricity |
| Electricity | 321 | [96,192,336,720] | (18,317, 2633, 5261) | 1 h | Electricity |
| Traffic | 862 | [96,192,336,720] | (12,185, 1757, 3509) | 1 h | Transport |
| Weather | 21 | [96,192,336,720] | (36,792, 5271, 10,540) | 10 mins | Weather |
| Exchange | 8 | [96,192,336,720] | (5120, 665, 1422) | 1 day | Finance |
| ILI | 7 | [24,36,48,60] | (617, 74, 170) | 1 week | Illness |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Casolaro, A.; Capone, V.; Iannuzzo, G.; Camastra, F. Deep Learning for Time Series Forecasting: Advances and Open Problems. Information 2023, 14, 598. https://doi.org/10.3390/info14110598
Casolaro A, Capone V, Iannuzzo G, Camastra F. Deep Learning for Time Series Forecasting: Advances and Open Problems. Information. 2023; 14(11):598. https://doi.org/10.3390/info14110598
Chicago/Turabian StyleCasolaro, Angelo, Vincenzo Capone, Gennaro Iannuzzo, and Francesco Camastra. 2023. "Deep Learning for Time Series Forecasting: Advances and Open Problems" Information 14, no. 11: 598. https://doi.org/10.3390/info14110598