

POSS-CNN: An Automatically Generated Convolutional Neural Network with Precision and Operation Separable Structure Aiming at Target Recognition and Detection



Abstract
:1. Introduction
- (1)
- A design method of a multi-branch CNN structure is proposed in this paper. As mentioned above, we can obtain seven CNN models by one-time training with different branching modes. Compared with other schemes that only generate models with a fixed precision, the method proposed in this paper can improve efficiency and save time.
- (2)
- A methodology of automatic parallel selection for super parameters based on a multi-branch CNN structure is proposed, which makes the generation process of a multi-branch CNN structure with separable precision and operation automatic and procedural.
- (3)
- POSS-CNN: An automatically generated convolutional neural network with a precision and operation separable structure aimed at recognition and detection. A parameter tuning method named Parameters Substitution with Nodes Compensation (PSNC) reduces the parameters of the network model.
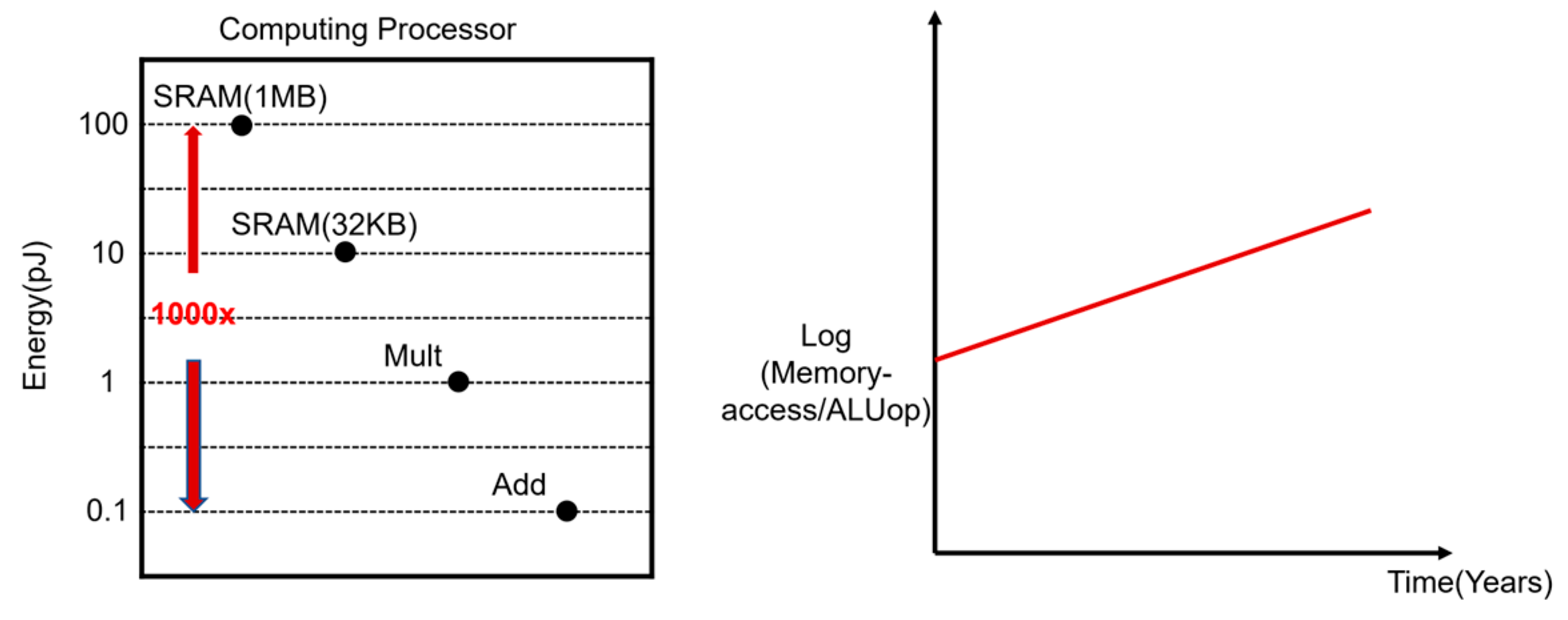
2. Related Work and Motivation
2.1. Related Work
2.2. Motivation
3. Materials and Methods
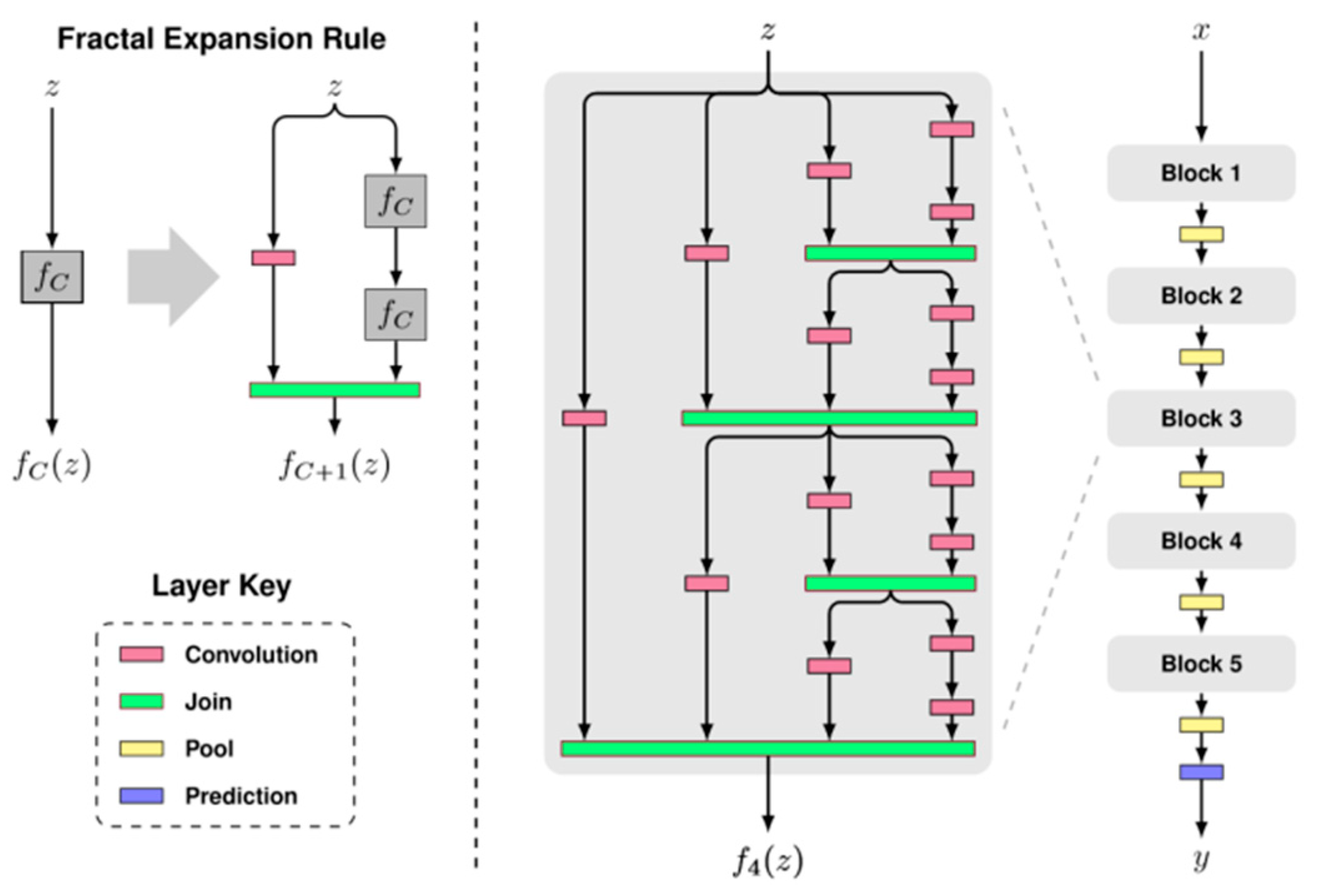
3.1. Multi-Branch Structure with Separable Precision and Operation
3.1.1. Basis of Branch Structure
3.1.2. Multi-Branch CNN Structure
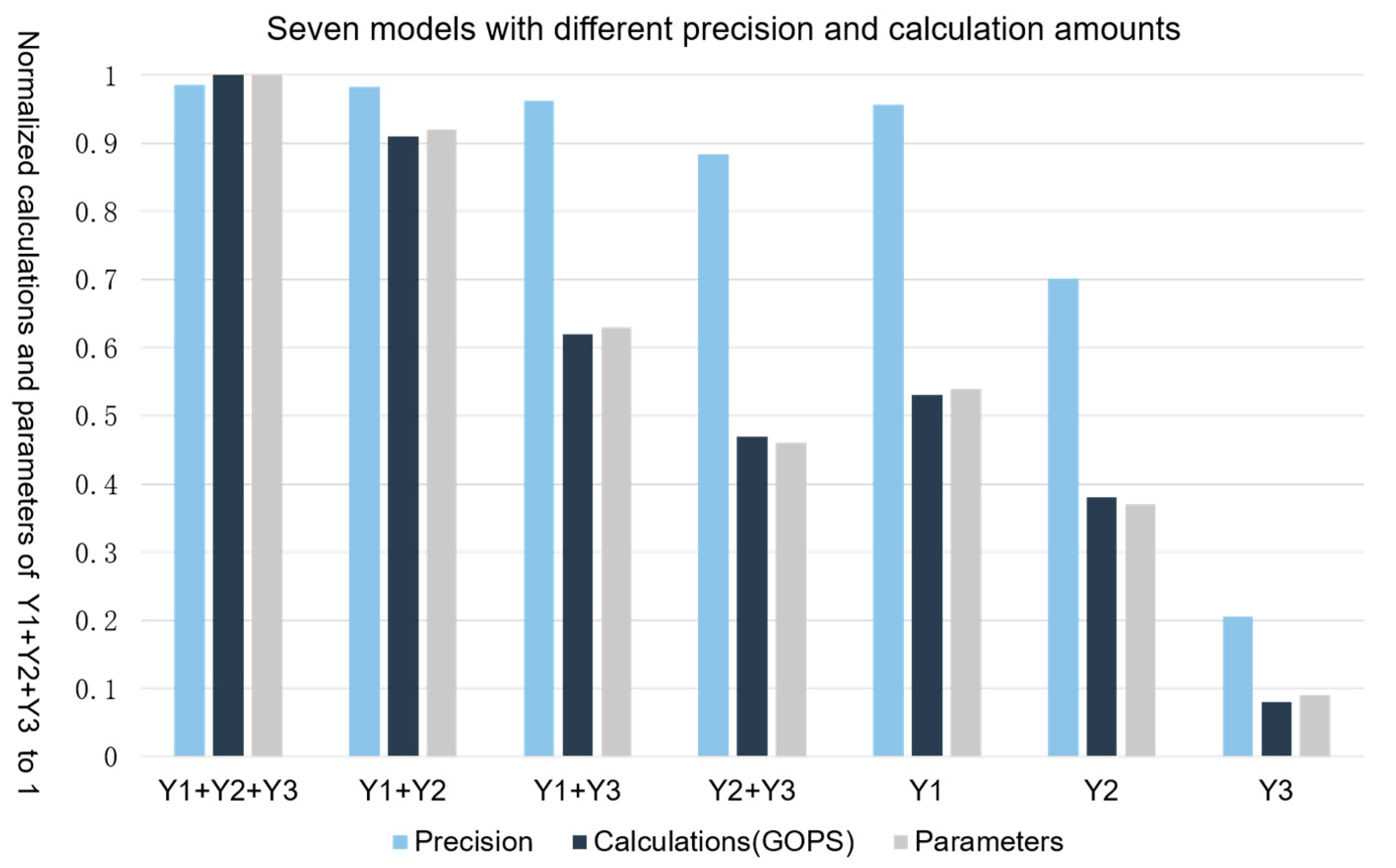
3.1.3. Evaluation of Separable Precision and Operation
3.2. Automatic Parallel Selection for Super Parameters on Multi-Branch CNN Structure
3.2.1. Design Flow
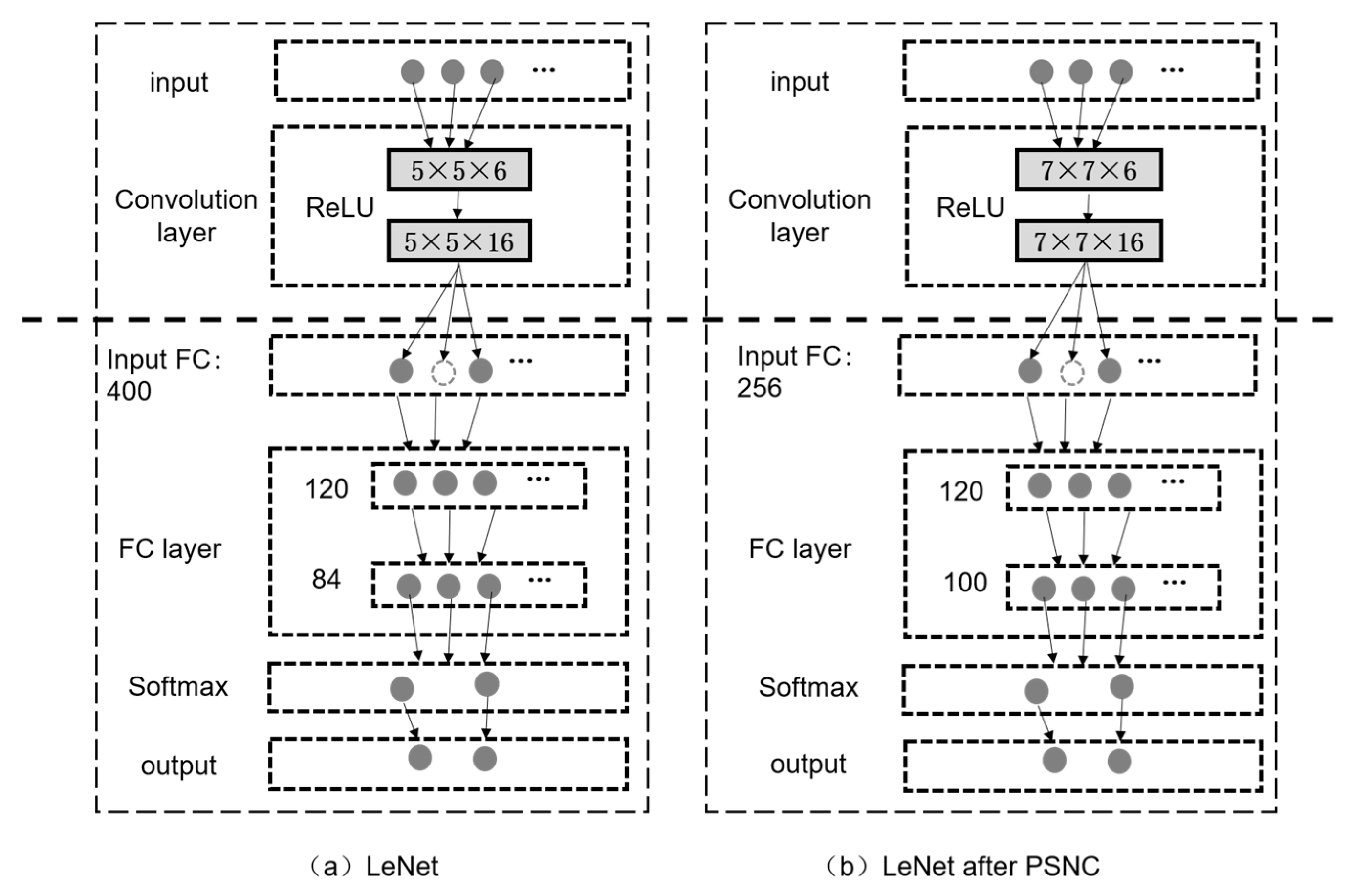
3.2.2. Parameter Tuning of Model Optimization
3.2.3. Evaluation of Training Time and Accuracy
3.3. POSS-CNN for Target Recognition and Detection
3.3.1. Multi-Branch Architecture for Target Recognition
3.3.2. Multi-Branch Architecture for Target Detection
4. Results
4.1. Experimental Platform and Datasets
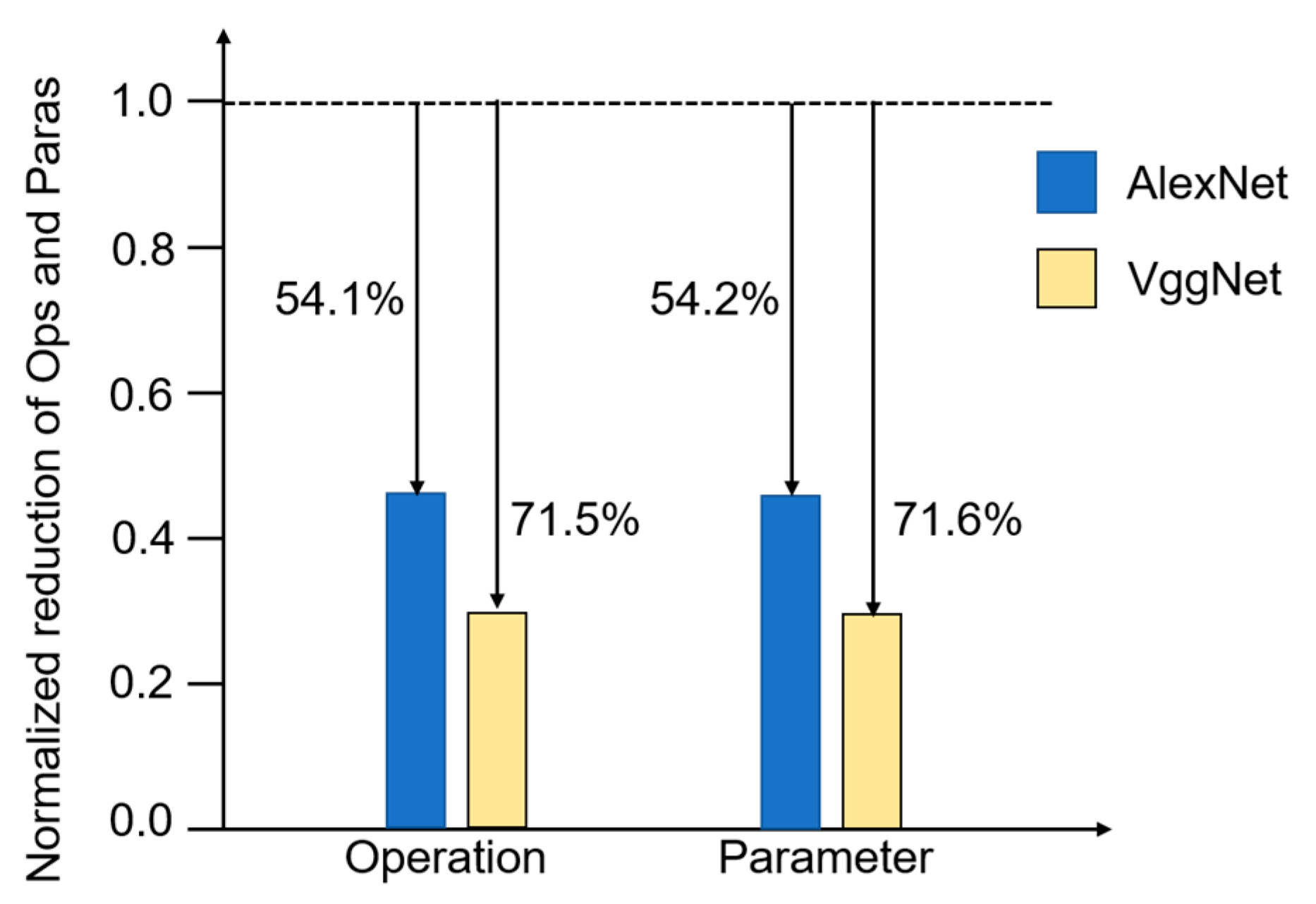
4.2. Target Recognition
4.3. Target Detection
4.4. FPGA Acceleration and Comparison
5. Discussion
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zoph, B.; Vasudevan, V.; Shlens, J.; Le, Q.V. Learning Transferable Architectures for Separable Image Recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8697–8710. [Google Scholar] [CrossRef]
- Larsson, G.; Maire, M.; Shakhnarovich, G. FractalNet: Ultra-Deep Neural Networks without Residuals. International Conference on Neural Information. arXiv 2017, arXiv:1605.07648. [Google Scholar] [CrossRef]
- Quan, Y.; Zhang, D.; Zhang, L.; Tang, J. Centralized Feature Pyramid for Object Detection. IEEE Trans. Image Process. 2023, 32, 4341–4354. [Google Scholar] [CrossRef] [PubMed]
- Pan, J.; Li, Z.; Wei, Y.; Chen, Z.; Nong, Y.; Zhou, B.; Huan, W.; Zou, J.; Pan, Z.; Liu, W. FEDNet: A real-time deep-learning framework for object detection. In Proceedings of the 2023 IEEE 3rd International Conference on Electronic Technology, Communication and Information (ICETCI), Changchun, China, 26–28 May 2023; pp. 1020–1025. [Google Scholar] [CrossRef]
- Zhang, X.; Liu, W.; Wu, G. Multi-Branch Cascade Receptive Field Residual Network. IEEE Access 2023, 11, 82613–82623. [Google Scholar] [CrossRef]
- Tan, M.; Le, Q.V. EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks. arXiv 2019, arXiv:1905.11946. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16×6 Words: Transformers for Image Recognition at Scale. arXiv 2020, arXiv:2010.11929. [Google Scholar] [CrossRef]
- Brock, A.; De, S.; Smith, S.L.; Simonyan, K. High-Performance Large-Scale Image Recognition Without Normalization. arXiv 2021, arXiv:2102.06171. [Google Scholar] [CrossRef]
- Real, E.; Aggarwal, A.; Huang, Y.; Le, Q.V. Regularized evolution for image classifier architecture search. Conf. Artif. Intell. (AAAI) 2019, 33, 4780–4789. [Google Scholar] [CrossRef]
- Kang, M.-G.; Kim, H.-H.; Kang, D.-J. Finding a High Accuracy Neural Network for the Welding Defects Classification Using Efficient Neural Architecture Search via Parameter Sharing. In Proceedings of the International Conference on Control, Automation and Systems (ICCAS), PyeongChang, Republic of Korea, 17–20 October 2018; pp. 402–405. [Google Scholar]
- Zhao, H.; Yan, K.; Cao, M. Multi-branch Attention Fusion Network for Aspect Sentiment Classification. In Proceedings of the 2023 8th International Conference on Intelligent Computing and Signal Processing (ICSP), Xi’an, China, 21–23 April 2023; pp. 892–896. [Google Scholar] [CrossRef]
- Talemi, N.A.; Kashiani, H.; Malakshan, S.R.; Saadabadi, M.S.E. AAFACE: Attribute-Aware Attentional Network for Face Recognition. In Proceedings of the 2023 IEEE International Conference on Image Processing (ICIP), Kuala Lumpur, Malaysia, 8–11 October 2023; pp. 1940–1944. [Google Scholar] [CrossRef]
- Chi, W.; Liu, J.; Wang, X.; Feng, R.; Cui, J. DBGNet: Dual-Branch Gate-Aware Network for Infrared Small Target Detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–14. [Google Scholar] [CrossRef]
- Luo, R.; Tian, F.; Qin, T.; Lin, T.-Y. Neural Architecture Optimization. arXiv 2018, arXiv:1808.07233. [Google Scholar] [CrossRef]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask R-CNN. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 42, 386–397. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Canny, J.; Zhao, H.; Jaros, B.; Chen, Y.; Mao, J. Machine learning at the limit. In Proceedings of the IEEE International Conference on Big Data, Santa Clara, CA, USA, 29 October–1 November 2015; pp. 233–242. [Google Scholar] [CrossRef]
- Kang, M.; Kim, Y.; Patil, A.D.; Shanbhag, N.R. Deep In-Memory Architectures for Machine Learning Accuracy Versus Efficiency Trade-Offs. IEEE Trans. Circuits Syst. I Regul. Pap. 2020, 67, 1627–1639. [Google Scholar] [CrossRef]
- Lecun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Krizhevsky, A. Imagenet classification with deep convolutional neural networks. IEEE Adv. Neural Inf. Process. Syst. 2012, 60, 1097–1105. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely Connected Convolutional Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2261–2269. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Girshick, R. Fast R-CNN. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar] [CrossRef]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolo9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 6517–6525. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar] [CrossRef]
- Lévesque, J.C.; Gagné, C.; Sabourin, R. Bayesian Hyperparameter Optimization for Ensemble Learning. In Proceedings of the Conference on Uncertainty in Artificial Intelligence, New York, NY, USA, 25–29 June 2016. [Google Scholar] [CrossRef]
- Sun, Y.; Xue, B.; Zhang, M.; Yen, G.G. A particle swarm optimization based flexible convolutional autoencoder for image classification. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 2295–2309. [Google Scholar] [CrossRef]
- Fielding, B.; Lawrence, T.; Zhang, L. Evolving and Ensembling Deep CNN Architectures for Image Classification. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Budapest, Hungary, 14–19 July 2019; pp. 1–8. [Google Scholar] [CrossRef]
- Wang, B.; Sun, Y.; Xue, B.; Zhang, M. A hybrid differential evolution approach to designing deep convolutional neural networks for image classification. In Australasian Joint Conference on Artificial Intelligence; Springer: Berlin/Heidelberg, Germany, 2018; pp. 237–250. [Google Scholar] [CrossRef]
- Lee, W.Y.; Park, S.M.; Sim, K.B. Optimal hyperparameter tuning of convolutional neural networks based on the parameter-setting-free harmony search algorithm. Optik 2018, 172, 359–367. [Google Scholar] [CrossRef]
- Baker, B.; Gupta, O.; Naik, N.; Raskar, R. Designing neural network architectures using reinforcement learning. arXiv 2016, arXiv:1611.02167. [Google Scholar] [CrossRef]
- Neary, P. Automatic hyperparameter tuning in deep convolutional neural networks using asynchronous reinforcement learning. In Proceedings of the 2018 IEEE International Conference on Cognitive Computing (ICCC), San Francisco, CA, USA, 2–7 July 2018; pp. 73–77. [Google Scholar] [CrossRef]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S. Going Deeper with Convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv 2017, arXiv:1704.04861. [Google Scholar] [CrossRef]
- Liu, C.; Zoph, B.; Neumann, M.; Shlens, J.; Hua, W.; Li, L.J.; Li, F.F.; Yuille, A.; Huang, J.; Murphy, K. Progressive Neural Architecture Search. arXiv 2017, arXiv:1712.00559. [Google Scholar] [CrossRef]
- Zhong, Z.; Yan, J.; Wu, W.; Shao, J.; Liu, C.L. Practical Block-wise Neural Network Architecture Generation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 2423–2432. [Google Scholar] [CrossRef]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 6848–6856. [Google Scholar] [CrossRef]
- Chen, Y.H.; Krishna, T.; Emer, J.S.; Sze, V. Eyeriss: An energy-efficient reconfigurable accelerator for deep convolutional neural networks. IEEE J. Solid-State Circuits 2017, 52, 127–138. [Google Scholar] [CrossRef]
- Szegedy, C.; Vanhoucke, V.; Ioffe, S.; Shlens, J.; Wojna, Z. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 2818–2826. [Google Scholar] [CrossRef]
- Ioffe, S.; Szegedy, C. Batch normalization: Accelerating deep network training by reducing internal covariate shift. Int. Conf. Mach. Learn. 2015, 37, 448–456. [Google Scholar] [CrossRef]
- Szegedy, C.; Ioffe, S.; Vanhoucke, V.; Alemi, A. Inception-v4, inception-resnet and the impact of residual connections on learning. In Proceedings of the Conference on Artificial Intelligence (AAAI), San Francisco, CA, USA, 4–9 February 2017; pp. 1–12. [Google Scholar] [CrossRef]
- Yang, C.; Zhang, J.; Chen, Q.; Xu, Y.; Lu, C. UL-CNN: An Ultra-Lightweight Convolutional Neural Network aiming at Flash-based Computing-In-Memory Architecture for Pedestrian Recognition. J. Circuits Syst. Comput. (JCSC) 2021, 30, 2150022. [Google Scholar] [CrossRef]
- Hu, X.; Xu, X.; Xiao, Y.; Chen, H.; He, S.; Qin, J.; Heng, P. SINet: A Scale-Insensitive Convolutional Neural Network for Fast Vehicle Detection. IEEE Trans. Intell. Transp. Syst. 2019, 20, 1010–1019. [Google Scholar] [CrossRef]
- Yang, C.; Wang, Y.; Wang, X.; Geng, L. WRA: A 2.2-to-6.3 TOPS Highly Unified Dynamically Reconfigurable Accelerator Using a Novel Winograd Decomposition Algorithm for Convolutional Neural Networks. IEEE Trans. Circuits Syst. I Regul. Pap. 2019, 66, 3480–3493. [Google Scholar] [CrossRef]
- Yang, C.; Wang, Y.; Wang, X.; Geng, L. A Stride-based Convolution Decomposition Method to Stretch CNN Acceleration Algorithms for Efficient and Flexible Hardware Implementation. IEEE Trans. Circuits Syst. I Regul. Pap. 2020, 67, 3007–3020. [Google Scholar] [CrossRef]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| CNN | Top-1 | Top-5 | Parameters (Million) | Operation (MFlops) |
|---|---|---|---|---|
| AlexNet | 37.5% | 17% | 60 | 720 |
| VggNet | 24.4% | 7.1% | 138 | 15,300 |
| ResNet-152 | 21.43% | 5.71% | 62 | 23,000 |
| DenseNet | 20.8% | 5.29% | 34 | 12,000 |
| Network | Test Error | Parameters | GPU | Time (Days) |
|---|---|---|---|---|
| NasNet | 2.4% | 27.6 | 500 | 4 |
| ENASNet | 2.89% | 4.6 | 1 | 0.45 |
| NAONet | 2.93% | 2.5 | 200 | 0.3 |
| AmoebaNet | 3.34% | 3.2 | 450 | 7 |
| PNASNet | 3.41% | 3.2 | 100 | - |
| BlockQNN | 3.54% | 39.8 | 32 | 3 |
| Network | Accuracy | Iteration |
|---|---|---|
| LeNet | 99.35% | 35,000 |
| Multi-branch CNN | 99.5% | 25,000 |
| Kernel | Parameters | Operation |
|---|---|---|
| 3 × 3 | (Ci × 3 × 3 + 1) × Co = 9Ci × Co + Co | 18 × Ci × Co × Fho × Fwo × B |
| 5 × 5 | (Ci × 5 × 5 + 1) × Co = 25Ci × Co + Co | 50 × Ci × Co × Fho × Fwo × B |
| 7 × 7 | (Ci × 7 × 7 + 1) × Co = 49Ci × Co + Co | 98 × Ci × Co × Fho × Fwo × B |
| 9 × 9 | (Ci × 9 × 9 + 1) × Co = 81Ci × Co + Co | 168 × Ci × Co × Fho × Fwo × B |
| 1 × 1 | (Ci × 1 × 1 + 1) × Co = Ci × Co + Co | 2 × Ci × Co × Fho × Fwo × B |
| CNN | Dataset | Models | Parameters before PSNC (Million) | Parameters after PSNC (Million) |
|---|---|---|---|---|
| POSS-CNN | CIFAR10 | Y1 + Y2 + Y3 | 20.9 | 9.9 |
| Y3 + Y2 | 20.1 | 9.1 | ||
| Y1 + Y3 | 18.7 | 8.9 | ||
| Y1 + Y2 | 3.03 | 1.86 | ||
| Y3 | 17.9 | 8.07 | ||
| Y2 | 2.2 | 1.05 | ||
| Y1 | 0.81 | 0.81 |
| MNIST | Time (Hours) | Precision |
|---|---|---|
| Ours | 1 | 98.7% |
| Grid Search | 2 | 98.67% |
| Random Search | 1.3 | 98.49% |
| Bayesian Search | 6 | 99% |
| CNN Models | Precision | Operation | Parameters |
|---|---|---|---|
| Y1 + Y2 + Y3 | 98.5% | 799,010 | 400,958 |
| Y2 + Y3 | 98.2% | 728,156 | 365,140 |
| Y1 + Y3 | 96.3% | 499,278 | 250,932 |
| Y1 + Y2 | 88.3% | 370,586 | 185,844 |
| Y3 | 95.9% | 428,244 | 215,114 |
| Y2 | 70.1% | 299,732 | 150,026 |
| Y1 | 20.5% | 70,854 | 35,818 |
| CNN | Parameters (Million) | Operation (Gops) |
|---|---|---|
| YOLOv3 | 61.95 | 65.8 |
| POSS-CNN for target detection | 53.56 | 41.8 |
| CNN | Models | Accuracy | Operation (Ops) | Parameters (Million) |
|---|---|---|---|---|
| AlexNet | Original | 89% [20] | 43,225,160 | 21.62 |
| VggNet | VGG + BN | 82.6% [48,49] | 67,251,600 | 33.64 |
| POSS-CNN for target recognition | Y1 + Y2 + Y3 | 86.4% | 19,848,513 | 9.9 |
| Y3 + Y2 | 86.6% | 18,232,666 | 9.1 | |
| Y1 + Y3 | 78.9% | 17,754,486 | 8.9 | |
| Y1 + Y2 | 73.4% | 3,709,874 | 1.86 | |
| Y3 | 69% | 16,138,639 | 8.07 | |
| Y2 | 73.6% | 2,094,027 | 1.05 | |
| Y1 | 23% | 1,615,847 | 0.81 |
| LSVH | MAP | Sparse mAP | Crowded mAP | Operation (Gops) | Parameters (Million) |
|---|---|---|---|---|---|
| Ours | 45.8 | 56.8 | 51.3 | 41.8 | 53.56 |
| YOLOv3 | 62.3 | 51.8 | 75.5 | 65.8 | 61.95 |
| Faster R-CNN | 59.5 | 58 | 61.1 | 46.7 | 58.19 |
| YOLOv2 | 32.4 | 42.1 | 31.3 | 57.4 | 50.59 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hou, J.; Zhang, J.; Chen, Q.; Xiang, S.; Meng, Y.; Wang, J.; Lu, C.; Yang, C. POSS-CNN: An Automatically Generated Convolutional Neural Network with Precision and Operation Separable Structure Aiming at Target Recognition and Detection. Information 2023, 14, 604. https://doi.org/10.3390/info14110604
Hou J, Zhang J, Chen Q, Xiang S, Meng Y, Wang J, Lu C, Yang C. POSS-CNN: An Automatically Generated Convolutional Neural Network with Precision and Operation Separable Structure Aiming at Target Recognition and Detection. Information. 2023; 14(11):604. https://doi.org/10.3390/info14110604
Chicago/Turabian StyleHou, Jia, Jingyu Zhang, Qi Chen, Siwei Xiang, Yishuo Meng, Jianfei Wang, Cimang Lu, and Chen Yang. 2023. "POSS-CNN: An Automatically Generated Convolutional Neural Network with Precision and Operation Separable Structure Aiming at Target Recognition and Detection" Information 14, no. 11: 604. https://doi.org/10.3390/info14110604
APA StyleHou, J., Zhang, J., Chen, Q., Xiang, S., Meng, Y., Wang, J., Lu, C., & Yang, C. (2023). POSS-CNN: An Automatically Generated Convolutional Neural Network with Precision and Operation Separable Structure Aiming at Target Recognition and Detection. Information, 14(11), 604. https://doi.org/10.3390/info14110604