



The PolitiFact-Oslo Corpus: A New Dataset for Fake News Analysis and Detection



Abstract
:1. Introduction
2. The PolitiFact-Oslo Corpus
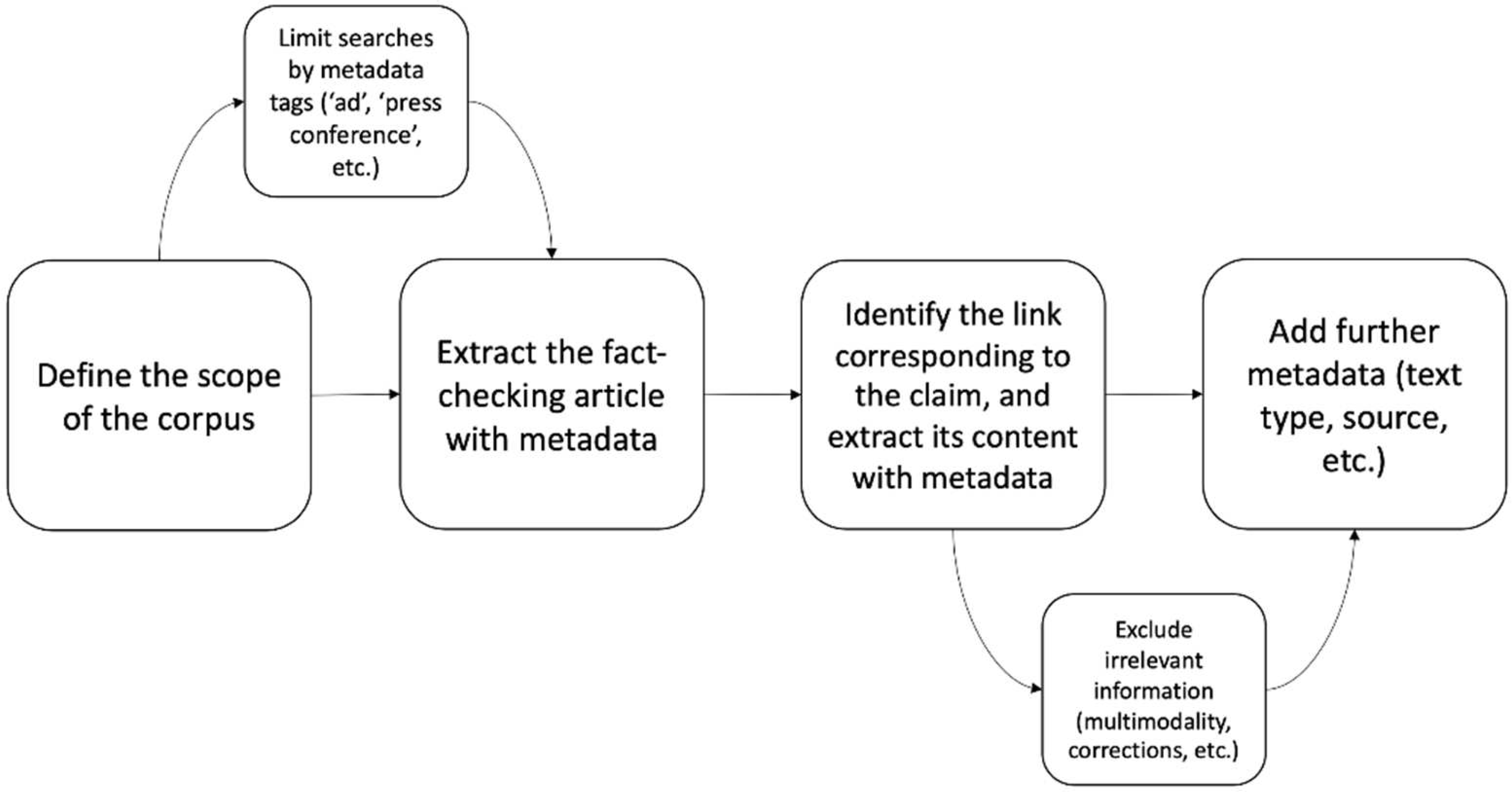
2.1. Data Collection, Design and Metadata
2.2. Key Features and Applications
- (i)
- The texts have been individually labelled for veracity by expert journalists working for a reputable fact-checking organization.
- (ii)
- They are complete texts, rather than short claims or statements, which strictly correspond to the claims in question.
- (iii)
- They are accompanied by important metadata about the news items.
3. Fake News Analysis Using Natural Language Processing
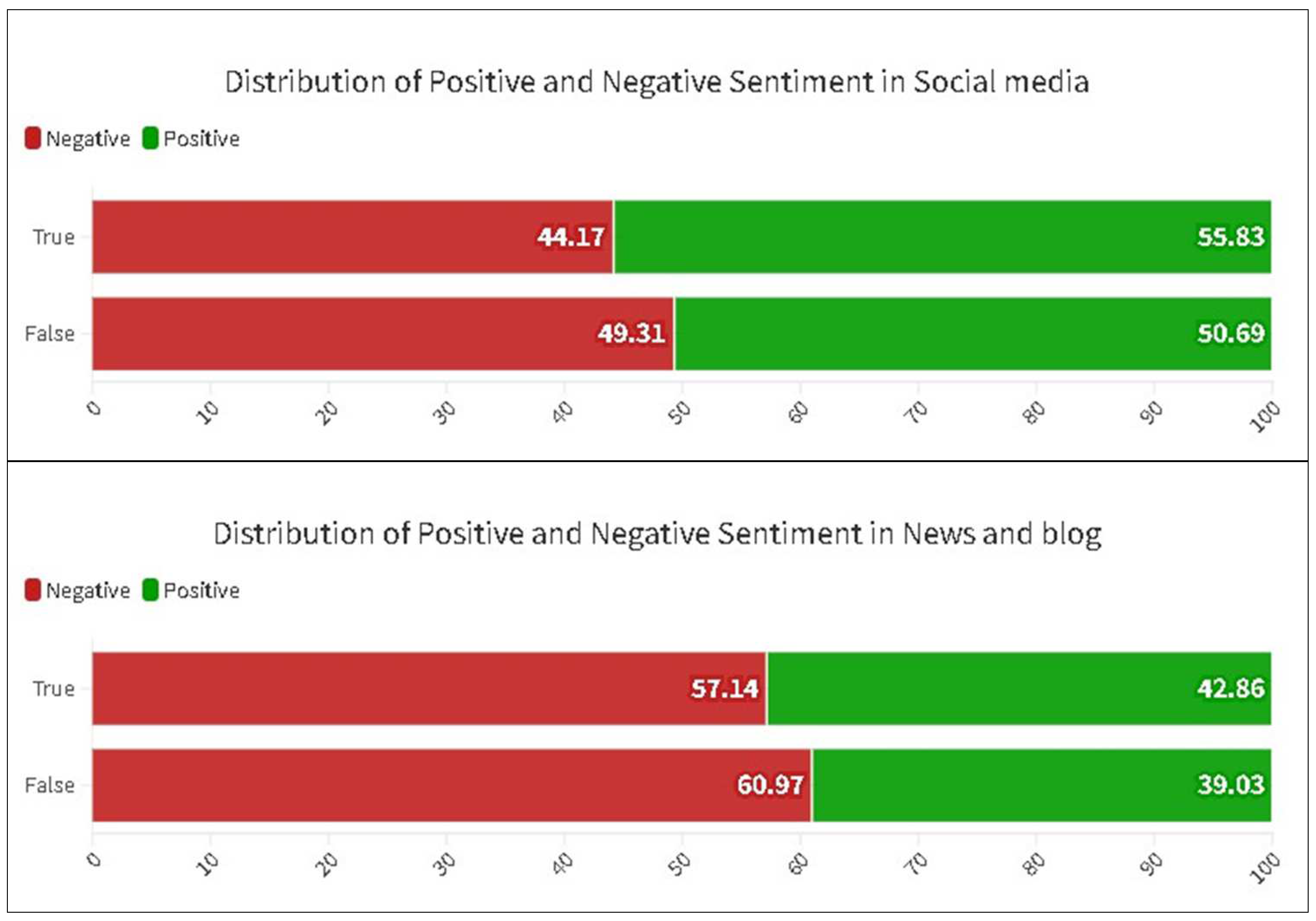
3.1. Sentiment
- (1)
- It sounds like science fiction. A fabric that smothers coronaviruses in less than a minute, its electrokinetic superpowers choking the life out of COVID-19 like Thanos squeezing the life out of Loki? It’s real, says Chandan Sen, the director of the Indiana Center for Regenerative Medicine and Engineering at the Indiana University School of Medicine in Indianapolis. And, with the number of novel coronavirus infections sitting at 4 million as of 10 May, it holds tantalizing potential for the future of personal protective equipment.
- (2)
- The “novel Coronavirus” outbreak affecting China and many other countries right now, has been determined to be a military BIO-WEAPON, which was being worked on at the Wuhan Virology Laboratory by China’s People’s Liberation Army, Nanjiang Command. Somehow, it got out. The world is now facing a massive wipe-out of humanity as a result.
3.2. Part-of-Speech
- (3)
- Queen Pelosi wasn’t happy with the small USAF C-20B jet, Gulfstream III, that comes with the Speaker’s job … OH NO! Queen Pelosi was aggravated that this little jet had to stop to refuel, so she ordered a Big Fat, 200-seat, USAF C-32, Boeing 757 jet that could get her back to California without stopping […] Queen Pelosi wants you and me to conserve our carbon footprint. She wants us to buy smaller cars and Obama wants us to get a bicycle pump and air up our tires. Who do these people think they are??? Their motto is … Don’t do as I do … JUST DO AS I SAY!
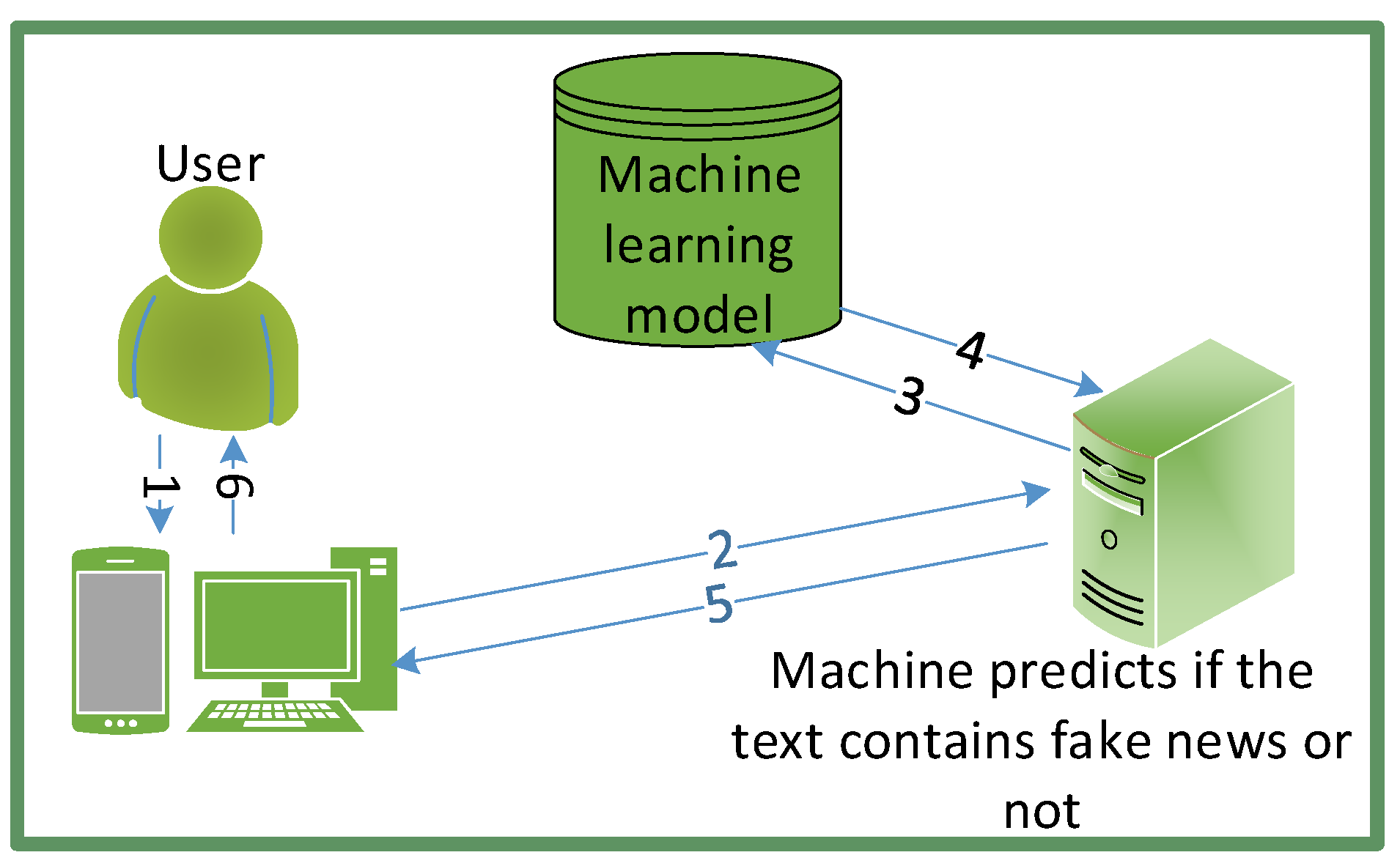
4. Machine Learning for Fake News Detection
4.1. Overview
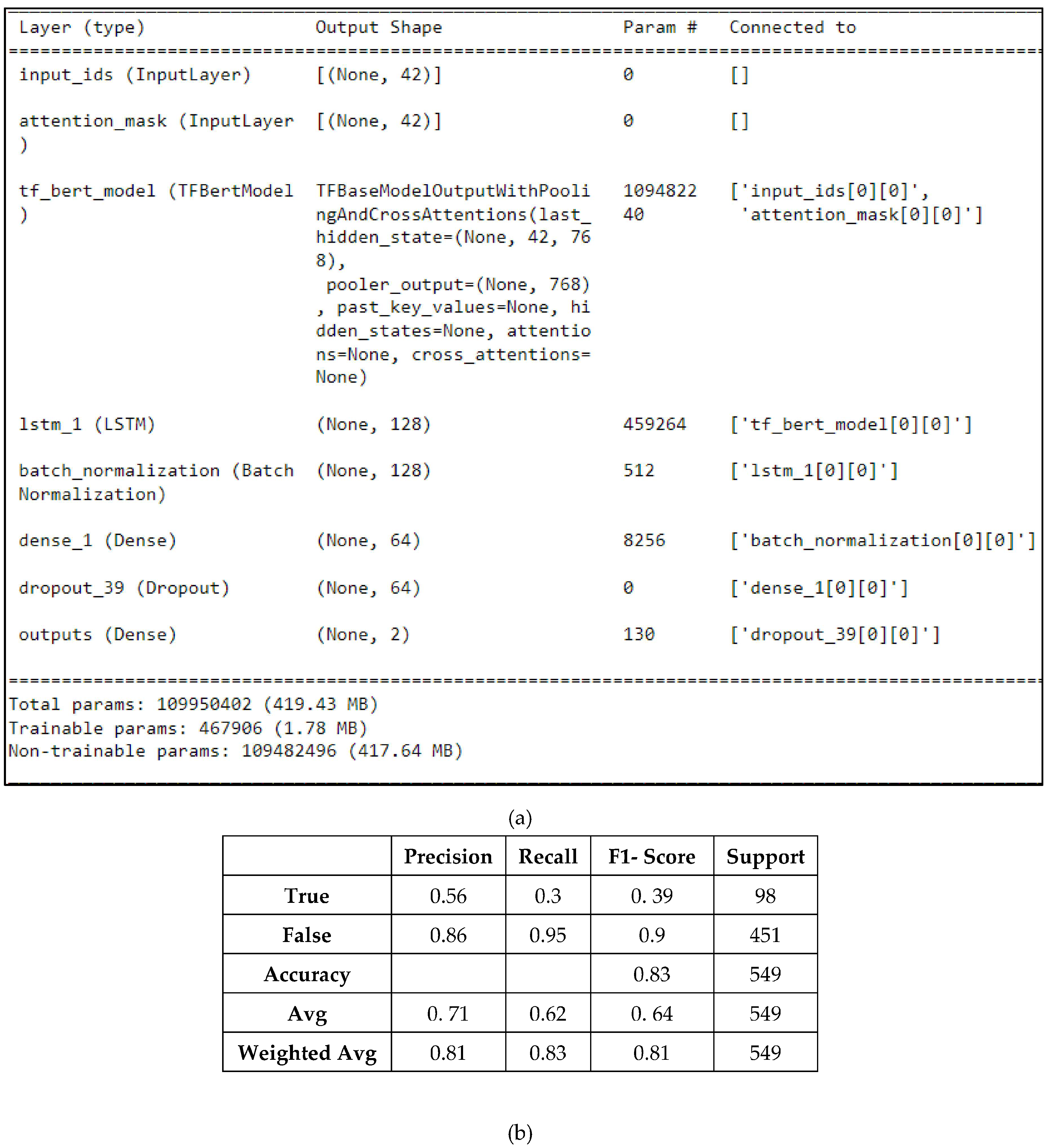
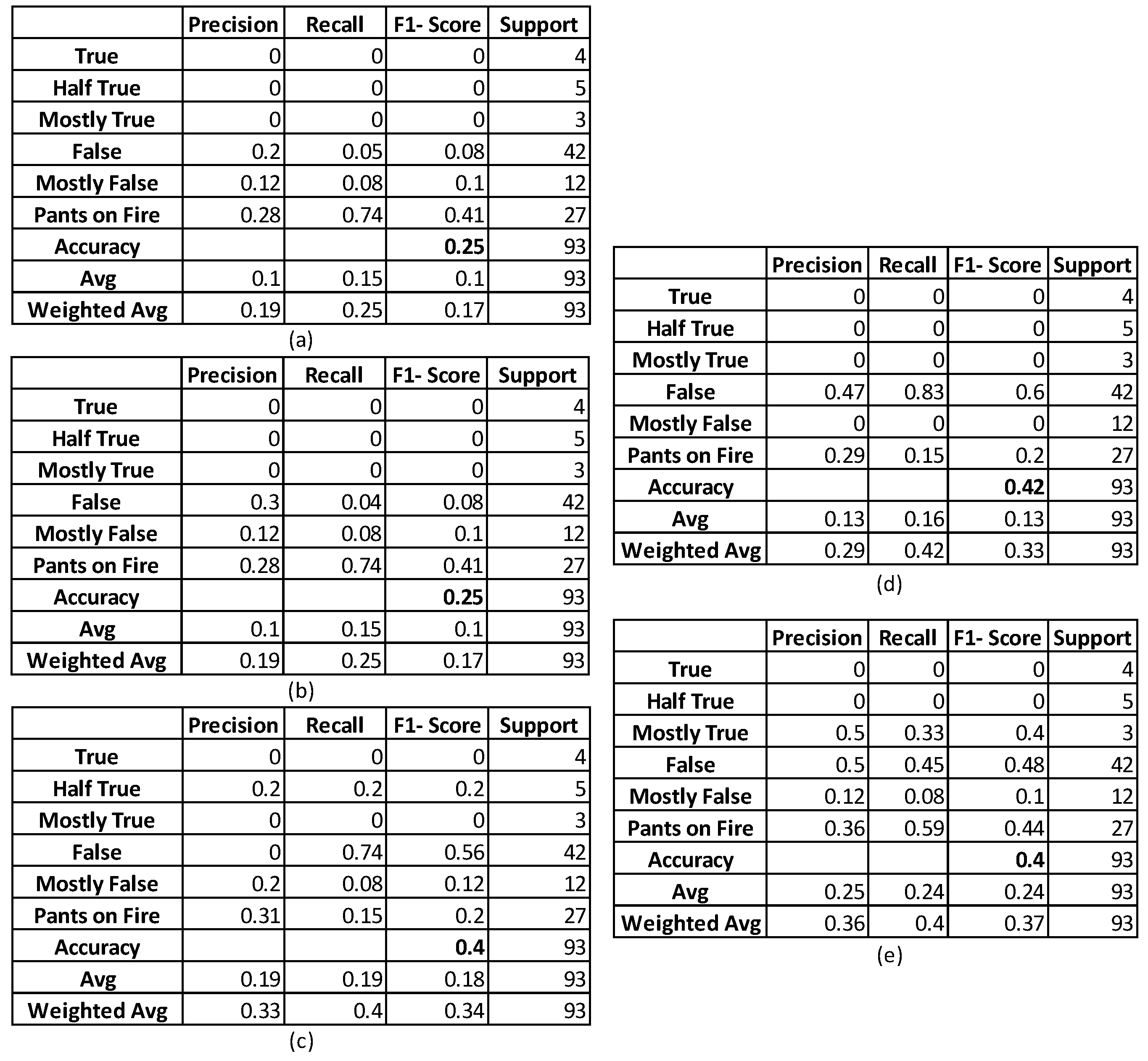
4.2. Experimental Results and Discussion
4.2.1. Full Dataset
4.2.2. Full DeClarE Dataset
4.2.3. News and Blog
4.2.4. Social Media
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Newman, N.; Fletcher, R.; Schulz, A.; Andi, S.; Robertson, C.T.; Nielsen, R.K. Reuters Institute Digital News Report 2021; Reuters Institute: Oxford, UK, 2021. [Google Scholar]
- Capuano, N.; Fenza, G.; Loia, V.; Nota, F.D. Content-based fake news detection with machine and deep learning: A systematic review. Neurocomputing 2023, 530, 91–103. [Google Scholar] [CrossRef]
- Conroy, N.K.; Rubin, V.L.; Chen, Y. Automatic deception detection: Methods for finding fake news. In Proceedings of the 78th ASIS&T Annual Meeting, St. Louis, MO, USA, 6–10 November 2015; Association for Information Science and Technology: St. Louis, MO, USA, 2015; pp. 1–4. [Google Scholar]
- Ibrishimova, M.D.; Li, K. A machine learning approach to fake news detection using knowledge verification and natural language processing. In Advances in Intelligent Networking and Collaborative Systems, INCoS 2019; Barolli, L., Nishino, H., Miwa, H., Eds.; Springer: Cham, Switzerland, 2020; Volume 1035, pp. 223–234. [Google Scholar]
- Oshikawa, R.; Qian, J.; Wang, W.Y. A survey of natural language processing for fake news detection. In Proceedings of the 12th Language Resources and Evaluation Conference (LREC 2020), Marseille, France, 11–16 May 2018; European Language Resources Association: Marseille, France, 2018; pp. 6086–6093. [Google Scholar]
- Villela, H.F.; Correa, F.; Ribeiro, J.S.A.N.; Rabelo, A.; Carvalho, D.B.F. Fake news detection: A systematic literature review of machine learning algorithms and datasets. J. Interact. Syst. 2023, 14, 47–58. [Google Scholar] [CrossRef]
- Rashkin, H.; Choi, E.; Jang, J.Y.; Volkova, S.; Choi, Y. Truth of varying shades: Analyzing language in fake news and political fact-checking. In Proceedings of the 2017 Conference on Empirical Methods in Natural Language Processing, Copenhagen, Denmark, 7–11 September 2017; Association for Computational Linguistics: Copenhagen, Denmark, 2017; pp. 2931–2937. [Google Scholar]
- Volkova, S.; Shaffer, K.; Jang, J.Y.; Hodas, N. Separating facts from fiction: Linguistic models to classify suspicious and trusted news posts on Twitter. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; Association for Computational Linguistics: Vancouver, BC, Canada, 2017; pp. 647–653. [Google Scholar]
- Siino, M.; Di Nuovo, E.; Tinnirello, I.; La Cascia, M. Fake News Spreaders Detection: Sometimes Attention Is Not All You Need. Information 2022, 13, 426. [Google Scholar] [CrossRef]
- Vlachos, A.; Riedel, S. Fact checking: Task definition and dataset construction. In Proceedings of the ACL 2014 Workshop on Language Technologies and Computational Social Science, Baltimore, MD, USA, 26 June 2014; Association for Computational Linguistics: Baltimore, MD, USA, 2014; pp. 18–22. [Google Scholar]
- Ferreira, W.; Vlachos, A. Emergent: A novel data-set for stance classification. In Proceedings of the 2016 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, San Diego, CA, USA, 12–17 June 2016; Association for Computational Linguistics: San Diego, CA, USA, 2016; pp. 1163–1168. [Google Scholar]
- Wang, W.Y. “Liar, Liar Pants on Fire”: A new benchmark dataset for fake news detection. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; Association for Computational Linguistics: Vancouver, BC, Canada, 2017; pp. 422–426. [Google Scholar]
- Asr, F.T.; Taboada, M. Big Data and quality data for fake news and misinformation detection. Big Data Soc. 2019, 6, 3310. [Google Scholar] [CrossRef]
- Allcott, H.; Gentzkow, M. Social media and fake news in the 2016 election. J. Econ. Perspect. 2017, 31, 211–236. [Google Scholar] [CrossRef]
- Popat, K.; Mukherjee, S.; Yates, A.; Weikum, G. DeClarE: Debunking fake news and false claims using evidence-aware deep learning. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; Association for Computational Linguistics: Brussels, Belgium, 2018; pp. 22–32. [Google Scholar]
- Grieve, J.; Woodfield, H. The Language of Fake News; Cambridge University Press: Cambridge, UK, 2023. [Google Scholar]
- Subba, B.; Kumari, S. A heterogeneous stacking ensemble based sentiment analysis framework using multiple word embeddings. Comput. Intell. 2021, 38, 530–559. [Google Scholar] [CrossRef]
- Rodriguez, P.L.; Spirling, A. Word Embeddings: What Works, What Doesn’t, and How to Tell the Difference for Applied Research. J. Polit. 2022, 84, 101–115. [Google Scholar] [CrossRef]
- Mangione, S.; Siino, M.; Garbo, G. Improving Irony and Stereotype Spreaders Detection using Data Augmentation and Convolutional Neural Network. In CEUR Workshop Proceedings; Università degli Studi di Palermo, Dipartimento di Ingegneria: Palermo, Italy, 2022; Volume 3180, pp. 2585–2593. [Google Scholar]
- Saleh, H.; Alhothali, A.; Moria, K. Detection of Hate Speech using BERT and Hate Speech Word Embedding with Deep Model. Appl. Artif. Intell. 2023, 37, 2166719. [Google Scholar] [CrossRef]
- Daniele, C.; Garlisi, D.; Siino, M. An SVM Ensamble Approach to Detect Irony and Stereotype Spreaders on Twitter. In CEUR Workshop Proceedings; Sun SITE Central Europe: Aachen, Germany, 2022; Volume 3180. [Google Scholar]
- Incitti, F.; Urli, F.; Snidaro, L. Beyond word embeddings: A survey. Inf. Fusion 2023, 89, 418–436. [Google Scholar] [CrossRef]
- Espinosa, D.; Sidorov, G. Using BERT to profiling cryptocurrency influencers. In Working Notes of CLEF; Sun SITE Central Europe: Aachen, Germany, 2023. [Google Scholar]
- Biber, D. Variation across Speech and Writing; Cambridge University Press: Cambridge, UK, 1988. [Google Scholar]
- Association for Progressive Communications: Disinformation and Freedom of Expression. 2021. Available online: https://www.apc.org/sites/default/files/APCSubmissionDisinformationFebruary2021.pdf (accessed on 2 November 2023).
- Sousa-Silva, R. Fighting the fake: A forensic linguistic analysis to fake news detection. Int. J. Semiot. Law 2022, 35, 2409–2433. [Google Scholar] [CrossRef] [PubMed]
- Nakamura, K.; Levy, S.; Wang, W.Y. r/Fakeddit: A new multimodal benchmark dataset for fine-grained fake news detection. In Proceedings of the 12th Language Resources and Evaluation Conference (LREC 2020), Marseille, France, 11–16 May 2018; European Language Resources Association: Marseille, France, 2020; pp. 6149–6157. [Google Scholar]
- Hutto, C.; Gilbert, E. Vader: A parsimonious rule-based model for sentiment analysis of social media text. In Proceedings of the International AAAI Conference on Web and Social Media, Ann Arbor, MI, USA, 1–4 June 2014; Volume 8. [Google Scholar]
- Manning, C.D.; Surdeanu, M.; Bauer, J.; Finkel, J.R.; Bethard, S.; McClosky, D. The Stanford CoreNLP natural language processing toolkit. In Proceedings of the 52nd Annual Meeting of the Association for Computational Linguistics: System Demonstrations, Baltimore, MD, USA, 23–24 June 2014; pp. 55–60. [Google Scholar]
- Markowitz, D.M.; Hancock, J.T. Linguistic traces of a scientific fraud: The case of Diederik Stapel. PLoS ONE 2014, 9, e105937. [Google Scholar] [CrossRef] [PubMed]
- Uddin, Z. Applied Machine Learning for Assisted Living; Springer Science and Business Media LLC: Dordrecht, The Netherlands, 2022. [Google Scholar] [CrossRef]
- Uddin, Z.; Hassan, M.M.; Alsanad, A.; Savaglio, C. A body sensor data fusion and deep recurrent neural network-based behavior recognition approach for robust healthcare. Inf. Fusion 2020, 55, 105–115. [Google Scholar] [CrossRef]
- Patwardhan, N.; Marrone, S.; Sansone, C. Transformers in the Real World: A Survey on NLP Applications. Information 2023, 14, 242. [Google Scholar] [CrossRef]
- Masciari, E.; Moscato, V.; Picariello, A.; Sperli, G. A deep learning approach to fake news detection. In Proceedings of the Foundations of Intelligent Systems: 25th International Symposium, ISMIS 2020, Graz, Austria, 23–25 September 2020; Springer International Publishing: Berlin/Heidelberg, Germany, 2020. [Google Scholar]
- Konkobo, P.M.; Zhang, R.; Huang, S.; Minoungou, T.T.; Ouedraogo, J.A.; Li, L. A deep learning model for early detection of fake news on social media. In Proceedings of the 2020 7th International Conference on Behavioural and Social Computing (BESC), Bournemouth, UK, 5–7 November 2020. [Google Scholar]
- Alghamdi, J.; Lin, Y.; Luo, S. A Comparative Study of Machine Learning and Deep Learning Techniques for Fake News Detection. Information 2022, 13, 576. [Google Scholar] [CrossRef]
- Palani, B.; Elango, S.; Viswanathan, K.V. CB-Fake: A multimodal deep learning framework for automatic fake news detection using capsule neural network and BERT. Multimed. Tools Appl. 2022, 81, 5587–5620. [Google Scholar] [CrossRef] [PubMed]
- Ali, A.M.; Ghaleb, F.A.; Al-Rimy, B.A.S.; Alsolami, F.J.; Khan, A.I. Deep Ensemble Fake News Detection Model Using Sequential Deep Learning Technique. Sensors 2022, 22, 6970. [Google Scholar] [CrossRef] [PubMed]





























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Text Type | Texts | Words | Average Text Length * | |||
|---|---|---|---|---|---|---|
| False | True | False | True | False | True | |
| Social media | 1878 | 403 | 119,002 | 20,498 | 63 | 50 |
| News and blog | 351 | 42 | 215,563 | 33,156 | 614 | 789 |
| Press release | 27 | 25 | 16,105 | 14,699 | 778 | 588 |
| Personal | 8 | 2 | 951 | 1348 | 119 | 674 |
| Academic | 5 | 0 | 4352 | 0 | 869 | 0 |
| Political | 3 | 1 | 2543 | 700 | 848 | 700 |
| Sub-total | 2272 | 473 | 358,516 | 70,401 | 160 | 148 |
| Corpus | 2745 | 428,917 | 158 | |||
| Text Type | Average Sentiment Score | News Items | ||
|---|---|---|---|---|
| False | True | False | True | |
| Social media | −0.102 | −0.03 | 1878 | 403 |
| News and blog | −0.228 | −0.115 | 351 | 42 |
| Sub-total | −0.122 | −0.038 | 2229 | 445 |
| Total | −0.16 | 2674 | ||
| DBN | LSTM | Bidirectional LSTM | BERT | RoBERTa | DistilBERT | XLNet | |
|---|---|---|---|---|---|---|---|
| True | 19.21 | 26.33 | 33.15 | 33.24 | 39.23 | 28.14 | 28.61 |
| False | 70.32 | 90.52 | 92.69 | 95.14 | 92.70 | 92.63 | 98.59 |
| Mean | 44.76 | 58.42 | 62.45 | 61.88 | 62.64 | 60.38 | 63.60 |
| DBN | LSTM | Bidirectional LSTM | BERT | RoBERTa | DistilBERT | XLNet | |
|---|---|---|---|---|---|---|---|
| True | 2.78 | 3.21 | 3.28 | 4.58 | 4.47 | 15.13 | 3.12 |
| Half True | 10.54 | 12.31 | 13.72 | 15.23 | 25.72 | 16.59 | 10.14 |
| Mostly True | 3.21 | 4.73 | 6.24 | 5.77 | 8.33 | 5.02 | 12.37 |
| False | 33.47 | 47.93 | 50.78 | 65.29 | 65.15 | 56.19 | 72.66 |
| Mostly False | 19.48 | 22.34 | 24.35 | 18.71 | 11.09 | 15.07 | 15.13 |
| Pants on Fire | 27.34 | 28.57 | 27.53 | 28.76 | 27.11 | 23.15 | 22.57 |
| Mean | 16.14 | 19.85 | 20.98 | 23.05 | 23.65 | 21.86 | 22.66 |
| DBN | LSTM | Bidirectional LSTM | BERT | RoBERTa | DistilBERT | XLNet | |
|---|---|---|---|---|---|---|---|
| True | 51.29 | 72.17 | 76.54 | 75.23 | 73.89 | 76.92 | 74.15 |
| False | 14.27 | 60.18 | 70.13 | 73.19 | 76.18 | 73.90 | 70.57 |
| Mean | 32.78 | 66.17 | 73.35 | 74.21 | 75.06 | 75.41 | 72.36 |
| DBN | LSTM | Bidirectional LSTM | BERT | RoBERTa | DistilBERT | XLNet | |
|---|---|---|---|---|---|---|---|
| True | 23.61 | 40.181 | 54.14 | 57.12 | 47.93 | 55.18 | 51.02 |
| Half True | 30.23 | 50.02 | 52.71 | 54.24 | 50.09 | 57.97 | 54.83 |
| Mostly True | 24.12 | 45.71 | 51.74 | 45.91 | 55.18 | 47.18 | 56.18 |
| False | 50.18 | 51.17 | 55.18 | 55.08 | 61.18 | 59.91 | 57.15 |
| Mostly False | 40.23 | 45.30 | 55.48 | 54.94 | 54.11 | 48.14 | 49.61 |
| Pants on Fire | 33.12 | 48.58 | 52.17 | 60.03 | 57.18 | 52.13 | 53.02 |
| Mean | 33.58 | 48.82 | 53.57 | 54.55 | 54.27 | 53.41 | 53.64 |
| DBN | LSTM | Bidirectional LSTM | BERT | RoBERTa | DistilBERT | XLNet | |
|---|---|---|---|---|---|---|---|
| True | 19.03 | 22.19 | 13.13 | 18.58 | 25.51 | 14.13 | 25.61 |
| False | 60.15 | 84.18 | 95.13 | 94.17 | 95.62 | 95.61 | 86.57 |
| Mean | 39.60 | 53.19 | 54.14 | 56.37 | 60.56 | 54.87 | 56.09 |
| DBN | LSTM | Bidirectional LSTM | BERT | RoBERTa | DistilBERT | XLNet | |
|---|---|---|---|---|---|---|---|
| True | 0.02 | 0.76 | 1.21 | 0.87 | 2.15 | 1.69 | 0.98 |
| Half True | 0.74 | 2.37 | 2.91 | 2.26 | 21.25 | 2.13 | 1.56 |
| Mostly True | 0.25 | 1.18 | 3.58 | 5.47 | 3.87 | 2.15 | 34.15 |
| False | 12.71 | 11.35 | 10.15 | 8.13 | 74.76 | 83.97 | 46.12 |
| Mostly False | 8.77 | 6.02 | 09.22 | 10.09 | 10.72 | 3.61 | 9.16 |
| Pants on Fire | 25.63 | 27.28 | 73.97 | 73.91 | 17.21 | 16.15 | 59.69 |
| Mean | 8.02 | 8.16 | 16.84 | 16.78 | 21.66 | 18.28 | 25.27 |
| DBN | LSTM | Bidirectional LSTM | BERT | RoBERTa | DistilBERT | XLNet | |
|---|---|---|---|---|---|---|---|
| True | 18.23 | 25.16 | 26.27 | 33.81 | 41.71 | 36.47 | 40.15 |
| False | 77.14 | 90.06 | 91.37 | 93.96 | 90.37 | 93.19 | 85.91 |
| Mean | 47.69 | 57.61 | 58.82 | 63.88 | 66.04 | 64.83 | 63.03 |
| DBN | LSTM | Bidirectional LSTM | BERT | RoBERTa | DistilBERT | XLNet | |
|---|---|---|---|---|---|---|---|
| True | 10.92 | 11.47 | 15.44 | 23.18 | 5.14 | 4.61 | 24.47 |
| Half True | 12.17 | 15.79 | 17.29 | 14.61 | 8.61 | 3.17 | 19.28 |
| Mostly True | 2.19 | 3.23 | 10.01 | 7.13 | 15.17 | 3.83 | 4.15 |
| False | 38.14 | 41.16 | 49.01 | 72.15 | 65.37 | 86.19 | 72.32 |
| Mostly False | 18.17 | 21.27 | 25.09 | 10.31 | 11.15 | 21.52 | 15.81 |
| Pants on Fire | 17.28 | 18.84 | 20.14 | 27.51 | 12.57 | 10.15 | 16.27 |
| Mean | 16.47 | 18.63 | 22.83 | 25.81 | 19.66 | 21.58 | 25.38 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Põldvere, N.; Uddin, Z.; Thomas, A. The PolitiFact-Oslo Corpus: A New Dataset for Fake News Analysis and Detection. Information 2023, 14, 627. https://doi.org/10.3390/info14120627
Põldvere N, Uddin Z, Thomas A. The PolitiFact-Oslo Corpus: A New Dataset for Fake News Analysis and Detection. Information. 2023; 14(12):627. https://doi.org/10.3390/info14120627
Chicago/Turabian StylePõldvere, Nele, Zia Uddin, and Aleena Thomas. 2023. "The PolitiFact-Oslo Corpus: A New Dataset for Fake News Analysis and Detection" Information 14, no. 12: 627. https://doi.org/10.3390/info14120627
APA StylePõldvere, N., Uddin, Z., & Thomas, A. (2023). The PolitiFact-Oslo Corpus: A New Dataset for Fake News Analysis and Detection. Information, 14(12), 627. https://doi.org/10.3390/info14120627