
AdvRain: Adversarial Raindrops to Attack Camera-Based Smart Vision Systems

Abstract
:1. Introduction
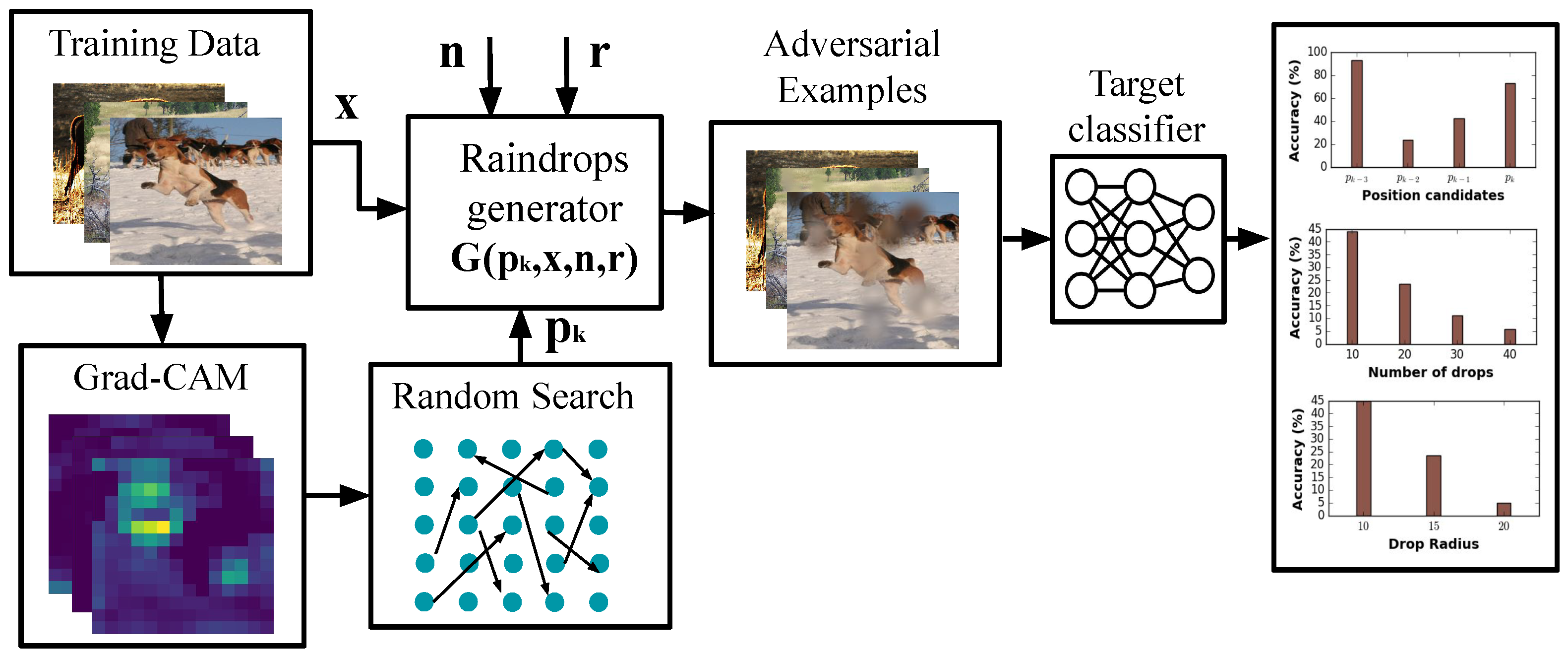
- We propose a novel technique that utilizes a random search optimization method guided by grad-cam to craft adversarial perturbations. These perturbations are introduced into the visual path between the camera and the object without altering the appearance of the object itself.
- The adversarial perturbations are designed to resemble a natural phenomenon, specifically raindrops, resulting in an inconspicuous pattern. These patterns are printed on a translucent sticker and affixed to the camera lens, making them difficult to detect.
- The proposed adversarial sticker applies the same perturbation to all images belonging to the same class, making it a universal attack against the target class.
- Our experiments demonstrate the potency of the AdvRain attack, achieving a significant decrease of over 61% in accuracy for VGG-19 on ImageNet and 57% for Resnet34 on Caltech-101 compared to 37% and 40% (for the same structural similarity index (SSIM)) when using FakeWeather [9].
- We study the impact of blurring specific parts of the image, introducing low-frequency patterns, on model interpretability. This provides valuable insights into the behavior of the deep learning models under the proposed adversarial attack.
2. Background & Related Work
2.1. Camera-Based Vision Systems
2.2. Digital Adversarial Attacks
2.3. Physical Adversarial Attacks
3. Proposed Approach
3.1. Threat Model for Physical Camera Sticker Attacks
3.2. Overview of the Proposed Approach
3.3. Identify Critical Positions
| Algorithm 1 Grad-CAM-guided Random Search Method |
|
3.4. Raindrop Generator
4. Experimental Results
4.1. Experimental Setup
4.2. Evaluation of Attack Performance
4.3. Comparison with State-of-the-Art: AdvRain vs. FakeWeather
4.4. AdvRain vs. Natural Rain
5. Discussion
5.1. Evaluation on More DNN Models
5.2. Impact of Drop Radius
5.3. Impact on SSIM
5.4. Impact on Network Interpretation
5.5. Possible Defenses
5.6. AdvRain on Videos
5.7. Limitations
- Device-Specific: The success of AdvRain can depend on the specific camera and lens characteristics of the target device. Variations in camera types, lens coatings, and sensor resolutions can affect the effectiveness of the attack. This means that the same AdvRain sticker may not work with same efficiency on all devices.
- Sticker Placement: The success of the attack depends on the precise placement of the AdvRain sticker on the camera lens. If the sticker is misaligned or partially obstructed, it may not create the desired perturbations, reducing the attack’s effectiveness.
- Environmental Conditions: The effectiveness of AdvRain can be influenced by environmental conditions such as lighting, weather, and visibility. Raindrop patterns may be more or less convincing under different conditions, potentially limiting the attack’s reliability.
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Al-Qizwini, M.; Barjasteh, I.; Al-Qassab, H.; Radha, H. Deep learning algorithm for autonomous driving using GoogLeNet. In Proceedings of the IEEE Intelligent Vehicles Symposium (IV), Los Angeles, CA, USA, 11–14 June 2017; pp. 89–96. [Google Scholar]
- Tramèr, F.; Zhang, F.; Juels, A.; Reiter, M.K.; Ristenpart, T. Stealing Machine Learning Models via Prediction APIs. In Proceedings of the 25th USENIX Security Symposium (USENIX Security 16), Austin, TX, USA, 10–12 August 2016; pp. 601–618. [Google Scholar]
- Goodfellow, I.J.; Shlens, J.; Szegedy, C. Explaining and Harnessing Adversarial Examples. arXiv 2015, arXiv:1412.6572. [Google Scholar]
- Kurakin, A.; Goodfellow, I.J.; Bengio, S. Adversarial examples in the physical world. arXiv 2016, arXiv:1607.02533. [Google Scholar]
- Carlini, N.; Wagner, D.A. Towards Evaluating the Robustness of Neural Networks. arXiv 2016, arXiv:1608.04644. [Google Scholar]
- Zhong, Y.; Liu, X.; Zhai, D.; Jiang, J.; Ji, X. Shadows can be Dangerous: Stealthy and Effective Physical-world Adversarial Attack by Natural Phenomenon. arXiv 2022, arXiv:2209.02430. [Google Scholar] [CrossRef]
- Hu, C.; Shi, W. Adversarial Color Film: Effective Physical-World Attack to DNNs. arXiv 2022, arXiv:2209.02430. [Google Scholar] [CrossRef]
- Duan, R.; Ma, X.; Wang, Y.; Bailey, J.; Qin, A.K.; Yang, Y. Adversarial Camouflage: Hiding Physical-World Attacks with Natural Styles. arXiv 2020, arXiv:2003.08757. [Google Scholar] [CrossRef]
- Marchisio, A.; Caramia, G.; Martina, M.; Shafique, M. fakeWeather: Adversarial Attacks for Deep Neural Networks Emulating Weather Conditions on the Camera Lens of Autonomous Systems. arXiv 2022, arXiv:2205.13807. [Google Scholar] [CrossRef]
- Brown, T.; Mane, D.; Roy, A.; Abadi, M.; Gilmer, J. Adversarial Patch. arXiv 2017, arXiv:1712.09665. [Google Scholar]
- Subramanya, A.; Pillai, V.; Pirsiavash, H. Towards Hiding Adversarial Examples from Network Interpretation. arXiv 2018, arXiv:1812.02843. [Google Scholar]
- Szegedy, C.; Zaremba, W.; Sutskever, I.; Bruna, J.; Erhan, D.; Goodfellow, I.J.; Fergus, R. Intriguing properties of neural networks. In Proceedings of the 2nd International Conference on Learning Representations, ICLR 2014, Banff, AB, Canada, 14–16 April 2014. [Google Scholar]
- Brendel, W.; Rauber, J.; Bethge, M. Decision-Based Adversarial Attacks: Reliable Attacks Against Black-Box Machine Learning Models. arXiv 2017, arXiv:1712.04248. [Google Scholar]
- Narodytska, N.; Kasiviswanathan, S.P. Simple Black-Box Adversarial Perturbations for Deep Networks. arXiv 2016, arXiv:1612.06299. [Google Scholar]
- Chen, J.; Jordan, M.I. Boundary Attack++: Query-Efficient Decision-Based Adversarial Attack. arXiv 2019, arXiv:1904.02144. [Google Scholar]
- Hu, Y.C.T.; Chen, J.C.; Kung, B.H.; Hua, K.L.; Tan, D.S. Naturalistic Physical Adversarial Patch for Object Detectors. In Proceedings of the 2021 IEEE/CVF International Conference on Computer Vision (ICCV), Montreal, QC, Canada, 10–17 October 2021; pp. 7828–7837. [Google Scholar] [CrossRef]
- Guesmi, A.; Bilasco, I.M.; Shafique, M.; Alouani, I. AdvART: Adversarial Art for Camouflaged Object Detection Attacks. arXiv 2023, arXiv:2303.01734. [Google Scholar]
- Guesmi, A.; Ding, R.; Hanif, M.A.; Alouani, I.; Shafique, M. DAP: A Dynamic Adversarial Patch for Evading Person Detectors. arXiv 2023, arXiv:2305.11618. [Google Scholar]
- Athalye, A.; Engstrom, L.; Ilyas, A.; Kwok, K. Synthesizing robust adversarial examples. PMLR 2018, 80, 284–293. [Google Scholar]
- Sayles, A.; Hooda, A.; Gupta, M.; Chatterjee, R.; Fernandes, E. Invisible Perturbations: Physical Adversarial Examples Exploiting the Rolling Shutter Effect. arXiv 2020, arXiv:2011.13375. [Google Scholar]
- Kim, K.; Kim, J.; Song, S.; Choi, J.H.; Joo, C.; Lee, J.S. Light Lies: Optical Adversarial Attack. arXiv 2021, arXiv:2106.09908. [Google Scholar]
- Gnanasambandam, A.; Sherman, A.M.; Chan, S.H. Optical Adversarial Attack. arXiv 2021, arXiv:2108.06247. [Google Scholar]
- Kennedy, J.; Eberhart, R. Particle swarm optimization. In Proceedings of the Proceedings of ICNN’95—International Conference on Neural Networks, Perth, Australia, 27 November–1 December 1995; Volume 4, pp. 1942–1948. [CrossRef]
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar] [CrossRef]
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. arXiv 2014, arXiv:1409.1556. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. arXiv 2015, arXiv:1512.03385. [Google Scholar]
- Li, F.F.; Andreeto, M.; Ranzato, M.; Perona, P. Caltech 101; CaltechDATA; California Institute of Technology: Pasadena, CA, USA, 2022. [Google Scholar] [CrossRef]
- Deng, J.; Dong, W.; Socher, R.; Li, L.J.; Li, K.; Fei-Fei, L. Imagenet: A large-scale hierarchical image database. In Proceedings of the 2009 IEEE Conference on Computer Vision and Pattern Recognition, Miami, FL, USA, 20–25 June 2009; pp. 248–255. [Google Scholar]
- Wang, Z.; Bovik, A.; Sheikh, H.; Simoncelli, E. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Drops | VGG-19 | Resnet34 |
|---|---|---|
| 0 | 100% | 100% |
| 10 | 72% | 81% |
| 20 | 59% | 69% |
| 30 | 46% | 50% |
| 40 | 39% | 43% |
| Number of Drops | Walker Hound | Cock | Snake | Spider | Fish | Parrot | American Flamingo | Bison |
|---|---|---|---|---|---|---|---|---|
| 10 | 43% | 70% | 79% | 68% | 66% | 86% | 78% | 68% |
| 20 | 22% | 56% | 63% | 59% | 58% | 82% | 69% | 57% |
| 30 | 12% | 48% | 49% | 51% | 35% | 68% | 60% | 33% |
| 40 | 4% | 40% | 37% | 43% | 29% | 60% | 52% | 31% |
| Method | ImageNet | Caltech-101 |
|---|---|---|
| FakeWeather [9] | 37% | 40% |
| AdvRain (ours) | 65% | 62% |
| Model | VGG-19 | Resnet-50 | Inception v4 |
|---|---|---|---|
| Accuracy | 37% | 41% | 43% |
| Number of Drops | 0 | 10 | 20 | ||
|---|---|---|---|---|---|
| Radius | - | 10 | 15 | 10 | 15 |
| VGG-19 | 100% | 76% | 57% | 59% | 37% |
| Number of Drops | 0 | 10 | 20 | ||
|---|---|---|---|---|---|
| Radius | - | 10 | 15 | 10 | 15 |
| Resnet-34 | 100% | 79% | 70% | 69% | 55% |
| Number of Drops | 10 | 20 | 30 | 40 |
|---|---|---|---|---|
| SSIM | 0.89 | 0.78 | 0.73 | 0.69 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guesmi, A.; Hanif, M.A.; Shafique, M. AdvRain: Adversarial Raindrops to Attack Camera-Based Smart Vision Systems. Information 2023, 14, 634. https://doi.org/10.3390/info14120634
Guesmi A, Hanif MA, Shafique M. AdvRain: Adversarial Raindrops to Attack Camera-Based Smart Vision Systems. Information. 2023; 14(12):634. https://doi.org/10.3390/info14120634
Chicago/Turabian StyleGuesmi, Amira, Muhammad Abdullah Hanif, and Muhammad Shafique. 2023. "AdvRain: Adversarial Raindrops to Attack Camera-Based Smart Vision Systems" Information 14, no. 12: 634. https://doi.org/10.3390/info14120634
APA StyleGuesmi, A., Hanif, M. A., & Shafique, M. (2023). AdvRain: Adversarial Raindrops to Attack Camera-Based Smart Vision Systems. Information, 14(12), 634. https://doi.org/10.3390/info14120634