
Eye-Tracking System with Low-End Hardware: Development and Evaluation



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
1.1. Exploring the Applications of Human Eye Attention
1.2. Motivation for Building Our Eye-Tracking System
1.3. Roadmap
2. Related Works
2.1. Model-Based Techniques
2.2. Appearance-Based Techniques
3. Core Techniques in Our System
3.1. MediaPipe
3.1.1. Face Detection Model
3.1.2. Face Landmark Model
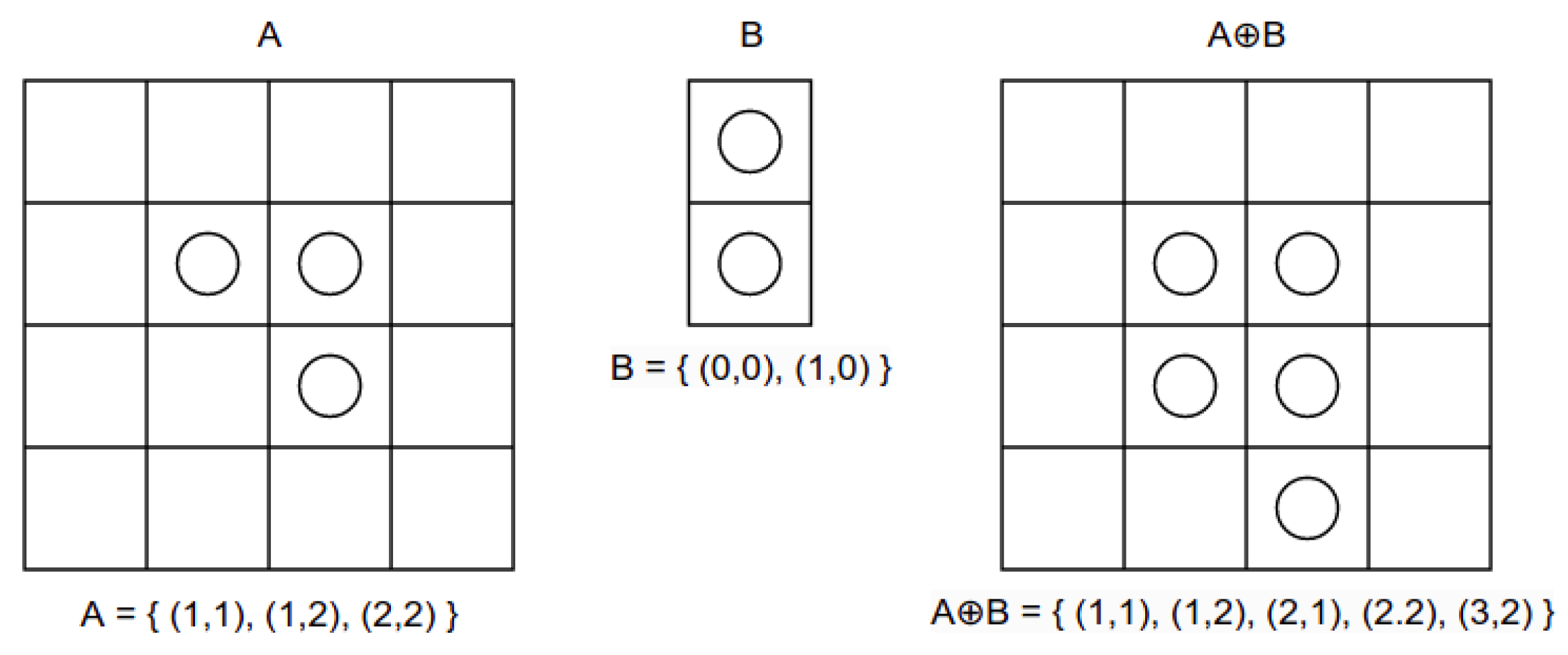
3.2. Morphological Transformations
3.2.1. Dilation
3.2.2. Erosion
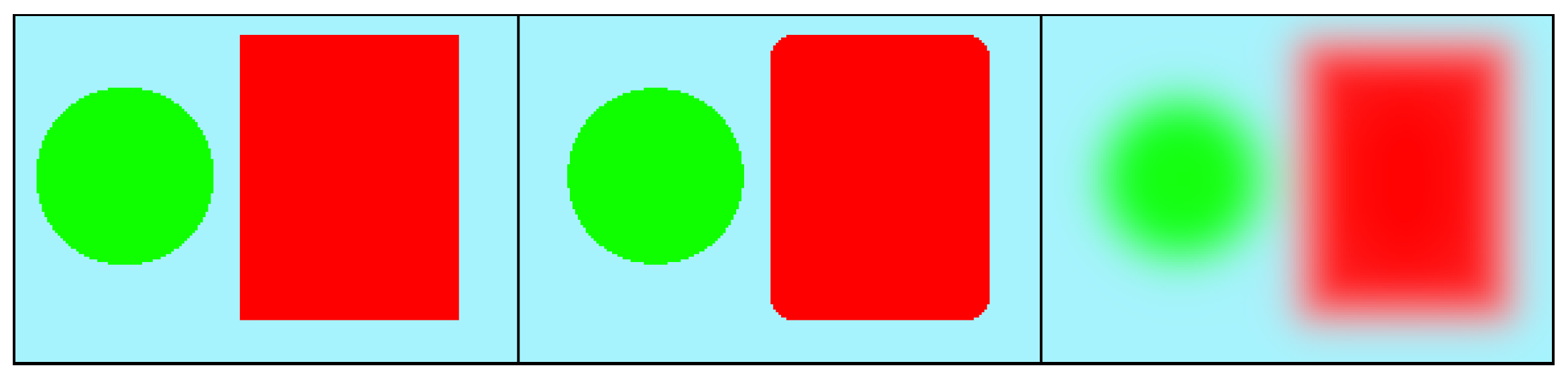
3.3. Median Blur Filter
4. Methodology
4.1. Software Overview
4.1.1. Pre-Calibration
4.1.2. Calibration
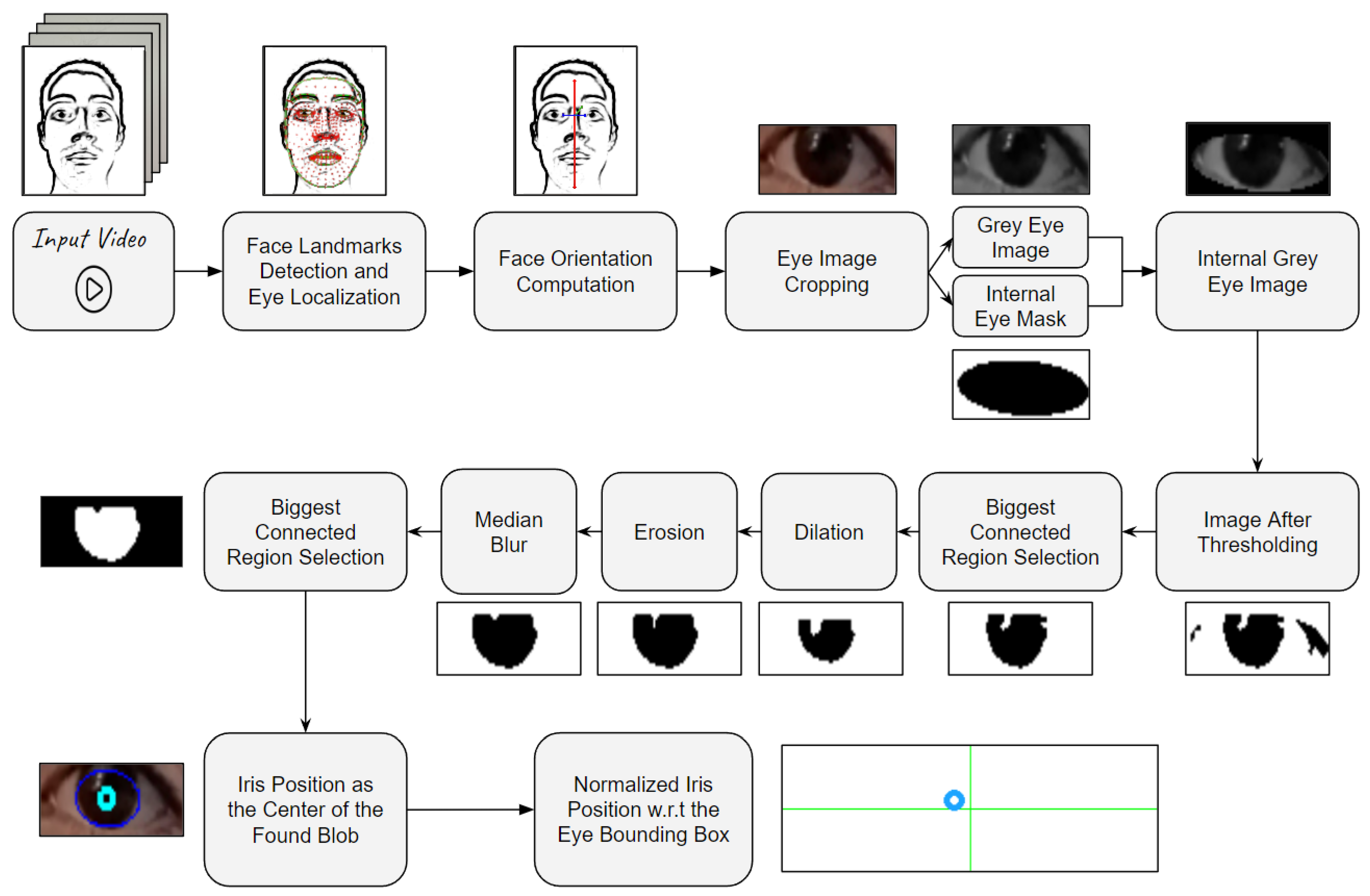
4.1.3. Irises Detection Algorithm (IDA)
4.1.4. Active Tracking and Data Saving
4.2. Participant Demographics in the Dataset
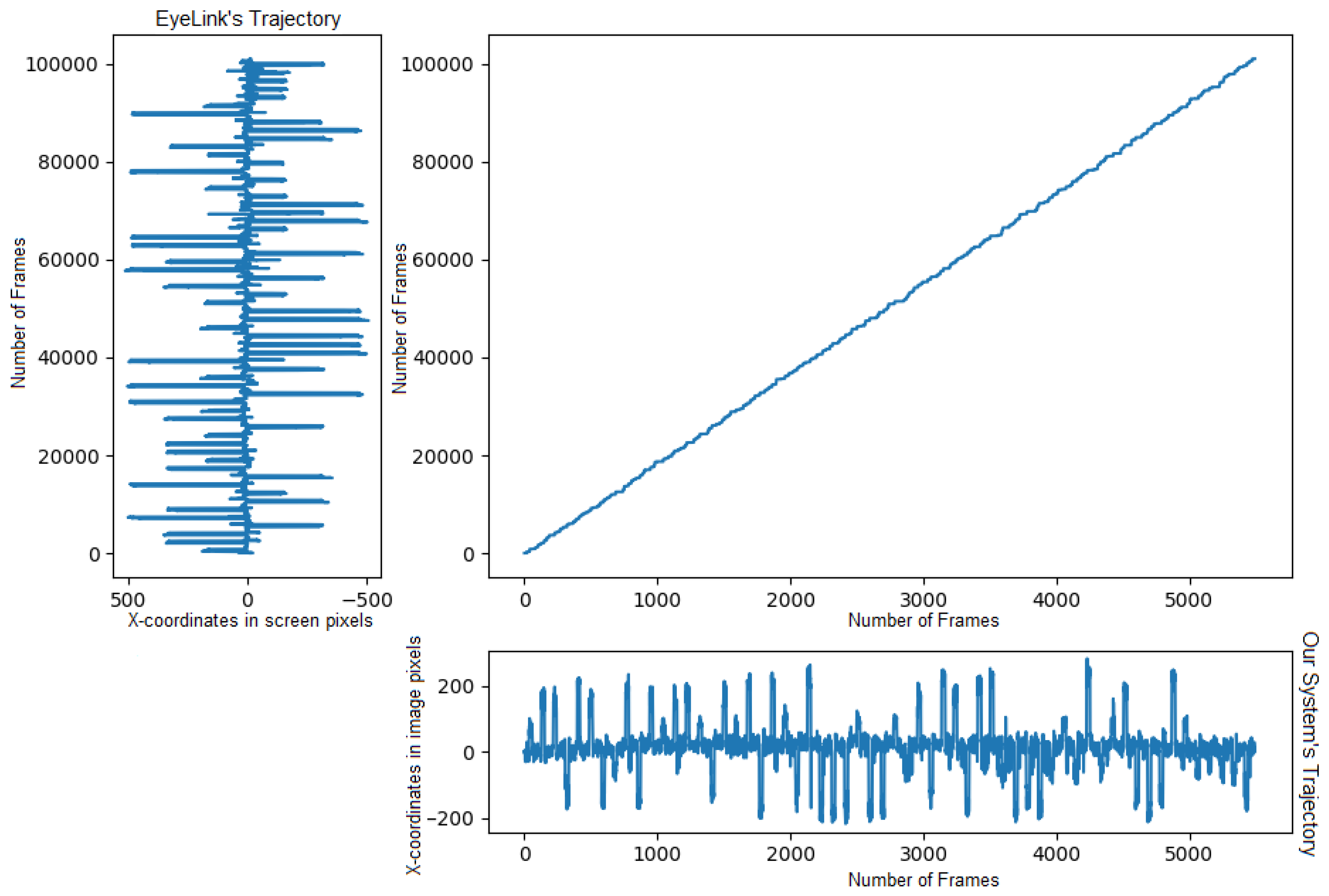
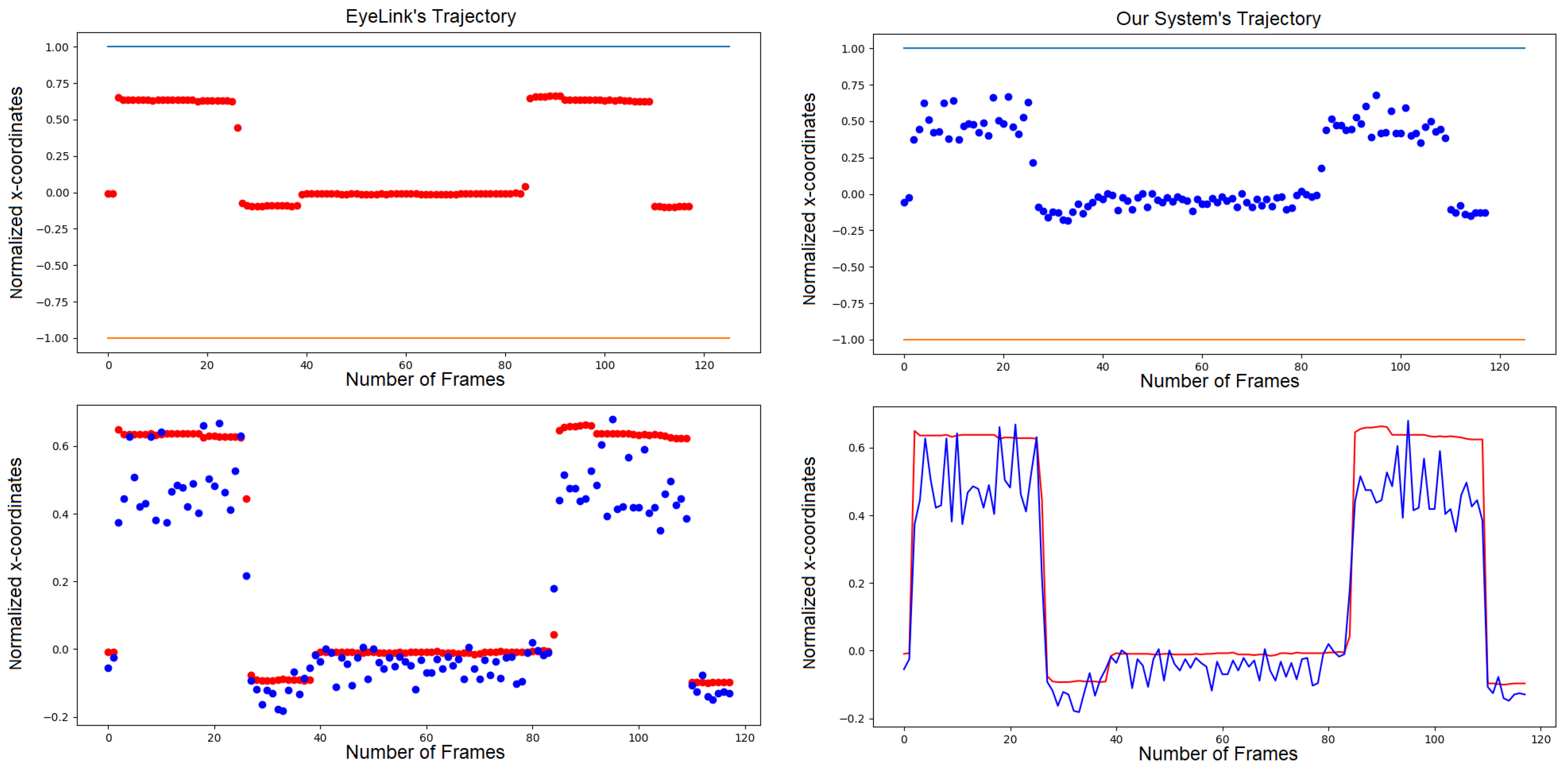
5. Results
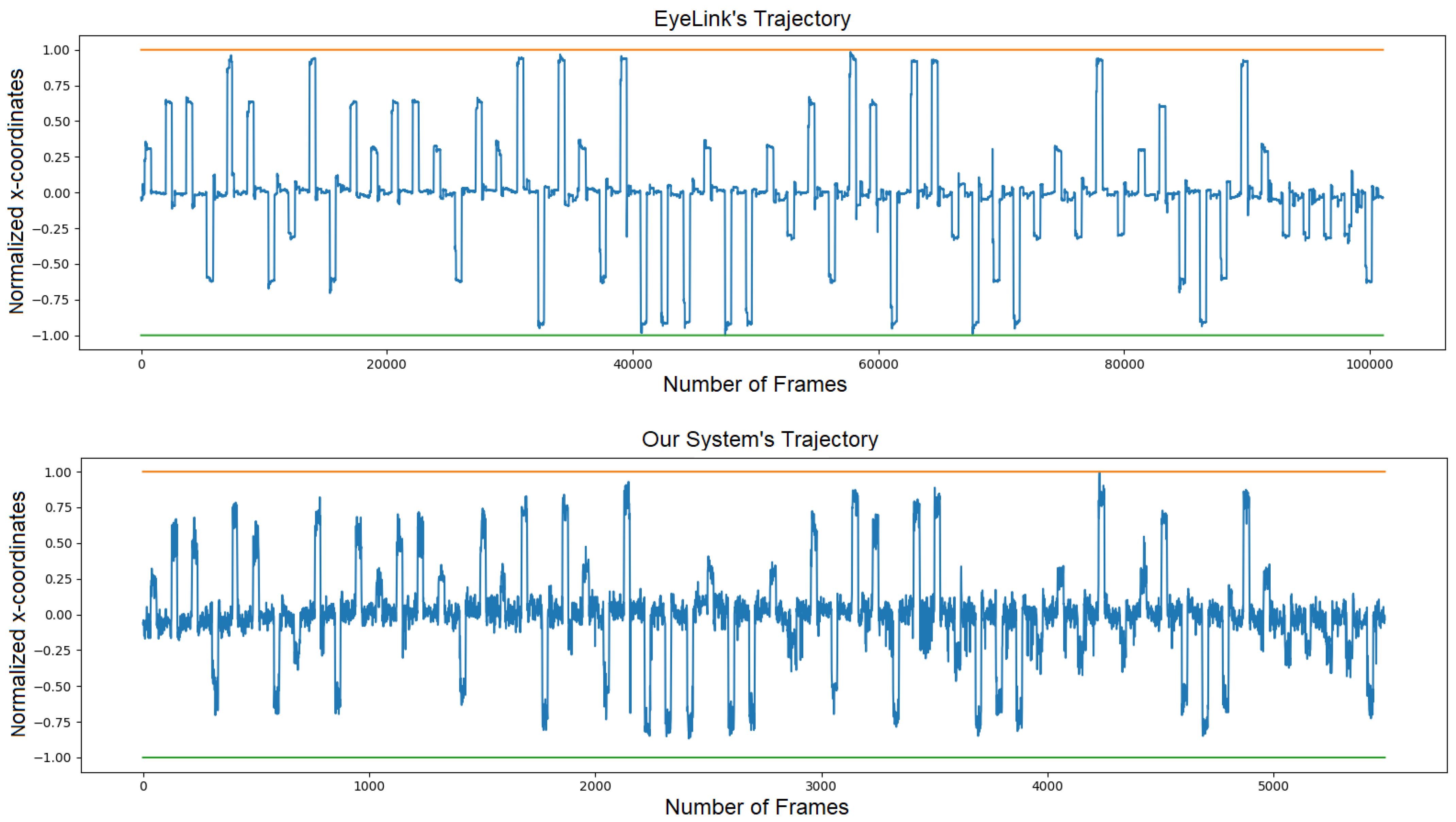
5.1. Dynamic Time Warping Algorithm
- : the starting indices of both time series have to be matched together;
- : the ending indices of both time series have to be matched together;
- and : the sequence of the indices of both time series have to be monotonically increasing and all the indices should appear at least once.
5.2. System Limitations
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Roper-Hall, G. Louis émile javal (1839–1907): The father of orthoptics. Am. Orthopt. J. 2007, 57, 131–136. [Google Scholar] [CrossRef] [PubMed]
- Armstrong, T.; Olatunji, B.O. Eye tracking of attention in the affective disorders: A meta-analytic review and synthesis. Clin. Psychol. Rev. 2012, 32, 704–723. [Google Scholar] [CrossRef] [PubMed]
- Pepe, S.; Tedeschi, S.; Brandizzi, N.; Russo, S.; Iocchi, L.; Napoli, C. Human Attention Assessment Using A Machine Learning Approach with GAN-based Data Augmentation Technique Trained Using a Custom Dataset. OBM Neurobiol. 2022, 6, 17. [Google Scholar] [CrossRef]
- Wedel, M.; Pieters, R. Eye tracking for visual marketing. Found. Trends Mark. 2008, 1, 231–320. [Google Scholar] [CrossRef]
- Lee, T.T.; Yeung, M.K.; Sze, S.L.; Chan, A.S. Eye tracking use in researching driver distraction: A scientometric and qualitative literature review approach. Brain Sci. 2021, 11, 314. [Google Scholar] [CrossRef] [PubMed]
- Danielson, M.L.; Bitsko, R.H.; Ghandour, R.M.; Holbrook, J.R.; Kogan, M.D.; Blumberg, S.J. Prevalence of Parent-Reported ADHD Diagnosis and Associated Treatment Among U.S. Children and Adolescents, 2016. J. Clin. Child Adolesc. Psychol. 2018, 47, 199–212. [Google Scholar] [CrossRef] [PubMed]
- Ponzi, V.; Russo, S.; Wajda, A.; Napoli, C. A Comparative Study of Machine Learning Approaches for Autism Detection in Children from Imaging Data. In Proceedings of the CEUR Workshop Proceedings, Catania, Italy, 26–29 August 2022; Volume 3398, pp. 9–15. [Google Scholar]
- Țichindelean, M.; Țichindelean, M.T.; Orzan, I.C.G. A Comparative Eye Tracking Study of Usability—Towards Sustainable Web Design. Sustainability 2021, 13, 10415. [Google Scholar] [CrossRef]
- Cvahte, O.; Darja, T.; Darja, T. Eye tracking use in researching driver distraction: A scientometric and qualitative literature review approach. J. Eye Mov. Res. 2019, 12. [Google Scholar] [CrossRef]
- Zhang, X.; Sugano, Y.; Bulling, A. Evaluation of appearance-based methods and implications for gaze-based applications. In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, Glasgow, UK, 4–9 May 2019; pp. 1–13. [Google Scholar]
- Ponzi, V.; Russo, S.; Bianco, V.; Napoli, C.; Wajda, A. Psychoeducative Social Robots for an Healthier Lifestyle using Artificial Intelligence: A Case-Study. In Proceedings of the CEUR Workshop Proceedings, Virtual, 20 August 2021; Volume 3118, pp. 26–33. [Google Scholar]
- De Magistris, G.; Caprari, R.; Castro, G.; Russo, S.; Iocchi, L.; Nardi, D.; Napoli, C. Vision-Based Holistic Scene Understanding for Context-Aware Human-Robot Interaction. In Proceedings of the 20th International Conference of the Italian Association for Artificial Intelligence, Virtual Event, 1–3 December 2021; Lecture Notes in Computer Science (Including Subseries Lecture Notes in Artificial Intelligence and Lecture Notes in Bioinformatics). Volume 13196, pp. 310–325. [Google Scholar] [CrossRef]
- Kim, B.C.; Ko, D.; Jang, U.; Han, H.; Lee, E.C. 3D Gaze tracking by combining eye- and facial-gaze vectors. J. Supercomput. 2017, 73, 3038–3052. [Google Scholar] [CrossRef]
- Xiong, X.; Liu, Z.; Cai, Q.; Zhang, Z. Eye gaze tracking using an RGBD camera: A comparison with a RGB solution. In Proceedings of the 2014 ACM International Joint Conference on Pervasive and Ubiquitous Computing: Adjunct Publication, Seattle, WA, USA, 13–17 September 2014; pp. 1113–1121. [Google Scholar]
- Wang, K.; Ji, Q. Real time eye gaze tracking with 3d deformable eye-face model. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1003–1011. [Google Scholar] [CrossRef]
- Wang, C.; Shi, F.; Xia, S.; Chai, J. Realtime 3D eye gaze animation using a single RGB camera. ACM Trans. Graph. (TOG) 2016, 35, 1–14. [Google Scholar] [CrossRef]
- Wang, Z.; Chai, J.; Xia, S. Realtime and Accurate 3D Eye Gaze Capture with DCNN-Based Iris and Pupil Segmentation. IEEE Trans. Vis. Comput. Graph. 2021, 27, 190–203. [Google Scholar] [CrossRef] [PubMed]
- Ronneberger, O.; Fischer, P.; Brox, T. U-net: Convolutional networks for biomedical image segmentation. In Proceedings of the Medical Image Computing and Computer-Assisted Intervention–MICCAI 2015: 18th International Conference, Munich, Germany, 5–9 October 2015; Proceedings, Part III 18. Springer: Cham, Switzerland, 2015; pp. 234–241. [Google Scholar]
- Iandola, F.N.; Han, S.; Moskewicz, M.W.; Ashraf, K.; Dally, W.J.; Keutzer, K. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5 MB model size. arXiv 2016, arXiv:1602.07360. [Google Scholar]
- Albawi, S.; Mohammed, T.A.; Al-Zawi, S. Understanding of a convolutional neural network. In Proceedings of the 2017 International Conference on Engineering and Technology (ICET), Antalya, Turkey, 21–23 August 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–6. [Google Scholar]
- Krafka, K.; Khosla, A.; Kellnhofer, P.; Kannan, H.; Bhandarkar, S.M.; Matusik, W.; Torralba, A. Eye Tracking for Everyone. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 26 June–1 July 2016. [Google Scholar]
- Cottrell, S.S. A simple method for finding the scattering coefficients of quantum graphs. J. Math. Phys. 2015, 56, 092203. [Google Scholar] [CrossRef]
- Cheung, Y.m.; Peng, Q. Eye Gaze Tracking With a Web Camera in a Desktop Environment. IEEE Trans. Hum. Mach. Syst. 2015, 45, 419–430. [Google Scholar] [CrossRef]
- Meng, C.; Zhao, X. Webcam-Based Eye Movement Analysis Using CNN. IEEE Access 2017, 5, 19581–19587. [Google Scholar] [CrossRef]
- Tonsen, M.; Steil, J.; Sugano, Y.; Bulling, A. InvisibleEye: Mobile Eye Tracking Using Multiple Low-Resolution Cameras and Learning-Based Gaze Estimation. In Proceedings of the ACM on Interactive, Mobile, Wearable and Ubiquitous Technologies; Association for Computing Machinery: New York, NY, USA, 2017; Volume 1. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–22 June 2018; pp. 4510–4520. [Google Scholar]
- Sakoe, H.; Chiba, S. Dynamic programming algorithm optimization for spoken word recognition. IEEE Trans. Acoust. Speech Signal Process. 1978, 26, 43–49. [Google Scholar] [CrossRef]
- Vintsyuk, T.K. Speech discrimination by dynamic programming. Cybernetics 1968, 4, 52–57. [Google Scholar] [CrossRef]
- Myers, C.; Rabiner, L.; Rosenberg, A. Performance tradeoffs in dynamic time warping algorithms for isolated word recognition. IEEE Trans. Acoust. Speech Signal Process. 1980, 28, 623–635. [Google Scholar] [CrossRef]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Iacobelli, E.; Ponzi, V.; Russo, S.; Napoli, C. Eye-Tracking System with Low-End Hardware: Development and Evaluation. Information 2023, 14, 644. https://doi.org/10.3390/info14120644
Iacobelli E, Ponzi V, Russo S, Napoli C. Eye-Tracking System with Low-End Hardware: Development and Evaluation. Information. 2023; 14(12):644. https://doi.org/10.3390/info14120644
Chicago/Turabian StyleIacobelli, Emanuele, Valerio Ponzi, Samuele Russo, and Christian Napoli. 2023. "Eye-Tracking System with Low-End Hardware: Development and Evaluation" Information 14, no. 12: 644. https://doi.org/10.3390/info14120644
APA StyleIacobelli, E., Ponzi, V., Russo, S., & Napoli, C. (2023). Eye-Tracking System with Low-End Hardware: Development and Evaluation. Information, 14(12), 644. https://doi.org/10.3390/info14120644