


Blind Estimation of Spreading Code Sequence of QPSK-DSSS Signal Based on Fast-ICA

Abstract
:1. Introduction
- This paper mainly focuses on the spreading code sequence estimation problem of QPSK- DSSS signals modulated by two different spreading code sequences with the same period. A blind estimation method of QPSK-DSSS signal spreading code sequences based on Fast-ICA algorithms is proposed.
- The proposed estimation method of spreading code sequences mainly includes signal whitening, separation matrix calculation, and spreading code extraction.
- The computational complexity of the algorithm is analyzed in Section 3.4 and is compared with other algorithms.
- In Section 4, we make experiments to study the influence of different spreading code lengths, information code lengths, frequency offsets, and different SNR on the spreading code estimation method. Finally, it is compared with the existing spreading code estimation method of QPSK-DSSS signal.
2. QPSK-DSSS Signal Model
3. Spreading Code Estimation Based on Fast-ICA Algorithm
3.1. Signal Whitening
- (1)
- The first step is calculating the covariance matrix of the received signal, r(t), . The larger means, the richer the information of the spreading sequence contained in the received signal. Therefore, theoretically, under the same condition of the SNR, the longer the information code length, , means the better the estimation effect of the spreading sequence;
- (2)
- Then, the eigendecomposition should be performed on , as shown in Equation (6).where represents the signal subspace, represents the noise subspace, and are the matrices formed by the eigenvalues corresponding to the vectors constituting the signal subspace and the noise subspace, respectively.
- (3)
- Finally, the received signal should be whitened using and .
3.2. Calculate the Separation Matrix
3.3. Calculate the Spreading Code Sequence
3.4. Algorithm Complexity Analysis
4. Simulation Experiment and Result Analysis
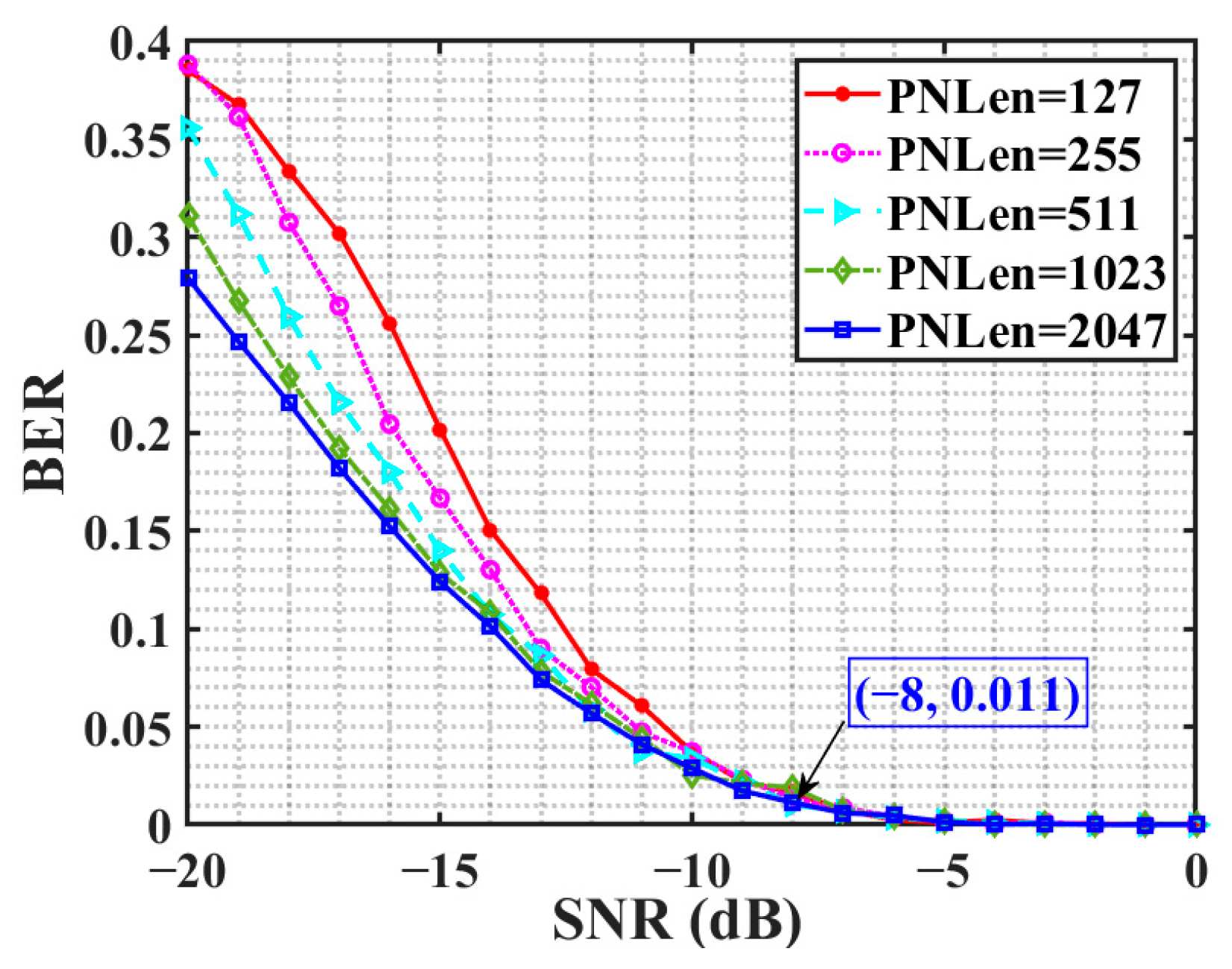
4.1. Relationship between BER and Spreading Code Length
4.2. Relationship between BER and Message Code Length
4.3. Relationship between BER and Residual Carrier
4.4. Comparison Experiment with Different Methods
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Chen, J. Research on Blind Reconstruction Method of Spreading Code Sequence for Direct Spread Signal; Harbin Engineering University: Harbin, China, 2017. [Google Scholar]
- Choi, H.; Moon, H. Blind Estimation of Spreading Sequence and Data Bits in Direct-Sequence Spread Spectrum Communication Systems. IEEE Access 2020, 8, 148066–148074. [Google Scholar] [CrossRef]
- Sun, X.Y.; Fan, Z.; Ji, Y.F.; Yan, S.Q.; Wang, S.H.; Zhen, W.M. Blind Estimation of PN Sequence Based on FLO Joint M Estimation for Short-Code DSSS Signals. In Proceedings of the 2018 7th International Conference on Digital Home (ICDH), Guilin, China, 30 November–1 December 2018. [Google Scholar]
- Mehboodi, S.; Jamshidi, A.; Farhang, M. Two Algorithms for Spread Spectrum Sequence Estimation for DSSS Signals in Noncooperative Communication Systems. In Proceedings of the 2016 24th Iranian Conference on Electrical Engineering(ICEE), Shiraz, Iran, 10–12 May 2016. [Google Scholar]
- Xiong, G.; Zhao, E.F. Spread Spectrum Code Sequence Recognition Method based on Hebb Optimization Criterion. Commun. Technol. 2019, 52, 2098–2101. [Google Scholar]
- Qiang, X.Z.; Zhang, T.Q. Estimation of Spreading Code in non-periodic Long-Code DSSS Signal. In Proceedings of the 2021 Sixth International Conference on Wireless Communications, Signal Processing and Networking (WiSPNET), Chennai, India, 25–27 March 2021. [Google Scholar]
- Liu, Q.H.; Li, T.Y.; Xu, M.K. Joint Blind Estimation of PN Codes and Channels for Long-Code DSSS Signals in Multiple Paths at Low SNR. In Proceedings of the 2020 IEEE 20th International Conference on Communication Technology (ICCT), Nanning, China, 28–31 October 2020. [Google Scholar]
- Zhang, H.G.; Wei, P. Spreading squence estimation based on constant modulus property for QPSK-DSSS signals. Acta Aeroautica Astronaut. Sin. 2013, 34, 1389–1396. [Google Scholar]
- Qiu, Z.Y.; Peng, H.; Li, T.Y. A Blind Despreading and Demodulation Method for QPSK-DSSS Signal with Unknown Carrier Offset Based on Matrix Subspace Analysis. IEEE Access 2019, 7, 125700–125710. [Google Scholar] [CrossRef]
- Chen, X.L.; Zhang, T.Q.; Meng, Y.; Wang, X.Y. Blind Estimation of Pseudo-Code Sequences for QPSK-DSSS Signals with Residual Frequency Offset. J. Beijing Univ. Posts Telecommun. 2022, 45, 90–95. [Google Scholar]
- Wang, Y.; Fu, Y.H.; He, Z.M. Fetal Electrocardiogram Extraction Based on Fast ICA and Wavelet Denoising. In Proceedings of the 2018 2nd IEEE Advanced Information Management, Communicates, Electronic and Automation Control Conference (IMCEC), Xi’an, China, 25–27 May 2018. [Google Scholar]
- Zhang, X.; Liu, X.M. Frogmen Formation Voice Communication Technology Based on Fast ICA. In Proceedings of the 2021 OES China Ocean Acoustics (COA), Harbin, China, 14–17 July 2021. [Google Scholar]
- Tu, S.J.; Chen, H. Blind Source Separation of Underwater Acoustic Signal by Use of Negentropy-Based Fast ICA Algorithm. In Proceedings of the 2015 IEEE International Conference on Computational Intelligence & Communication Technology, Ghazizbad, India, 13–14 February 2015. [Google Scholar]
- Hyvarinen, A. A family of fixed-point algorithms for independent component analysis. In Proceedings of the 1997 IEEE International Conference on Acoustics, Speech, and Signal Processing, Munich, Germany, 21–24 April 1997. [Google Scholar]
- Naeem, A.; Arslan, H. Joint Radar and Communication based Blind Signal Separation using a New Non-Linear Function for Fast-ICA. In Proceedings of the 2021 IEEE 94th Vehicular Technology Conference (VTC2021-Fall), Norman, OK, USA, 27–30 September 2021. [Google Scholar]
- Albataineh, Z.; Salem, F. New Blind Multiuser Detection in DS-CDMA Using H-DE and ICA Algorithms. In Proceedings of the 2013 4th International Conference on Intelligent Systems, Modelling and Simulation, Bangkok, Thailand, 29–31 January 2013. [Google Scholar]
- Tian, R.X.; Hui, X.; Tao, H.Z.; Wang, F.H.; Lu, F.B. Fast-ICA Based Blind Estimation of the Spreading Sequences for Down-link Multi-Rate DS/CDMA Signals. In Proceedings of the 2012 Fifth International Conference on Intelligent Computation Technology and Automation, Zhangjiajie, China, 12–14 January 2012. [Google Scholar]
- Adkhan, S.B.; Mohammed, S.J.; Shubbar, M.M. Fast ICA and JADE Algorithms for DS-CDMA. In Proceedings of the 2017 Second Al-Sadiq International Conference on Multidisciplinary in IT and Communication Science and Applications (AICMITCSA), Baghdad, Iraq, 30–31 December 2017. [Google Scholar]
- Mora, H.R.C.; Garzón, N.V.O.; Almeida, C.D. Mean Bit Error Rate Evaluation of MC-CDMA Cellular Systems Employing Multiuser-Maximum-Likelihood Detector. IEEE Trans. Veh. Technol. 2017, 66, 9838–9851. [Google Scholar] [CrossRef]
- Karan, Y.; Kahveci, S. Extraction of Theoretical Bit and Symbol Error Rates of Dual Carrier Modulation with QPSK. In Proceedings of the 2019 27th Signal Processing and Communications Applications Conference (SIU), Sivas, Turkey, 24–26 April 2019. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Step 1: Use to calculate the covariance matrix of the received signal. Then, the eigendecomposition of this matrix is used to get and ; |
| Step 2: Compute the whitened signal Z by Equation (7); |
| Step 3: Set initial values for the separation vector , and normalize it by using Equation (12); |
| Step 4: Iterate according to Equation (11), and use Equation (12) to unitize the iterative result for each iteration; |
| Step 5: Determine whether the separation vector converges, if not, return to step 4; |
| Step 6: Orthogonalize the separation vector by Equation (13); |
| Step 7: Determine whether all source signals have been completely separated.That is to judge whether j is less than the number of spreading sequences, if not, return to Step 4 until all spreading sequences are separated; |
| Step 8: The estimated spreading code sequence is calculated by Equation (15). |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Xu, L.; Liu, X.; Zhang, Y. Blind Estimation of Spreading Code Sequence of QPSK-DSSS Signal Based on Fast-ICA. Information 2023, 14, 112. https://doi.org/10.3390/info14020112
Xu L, Liu X, Zhang Y. Blind Estimation of Spreading Code Sequence of QPSK-DSSS Signal Based on Fast-ICA. Information. 2023; 14(2):112. https://doi.org/10.3390/info14020112
Chicago/Turabian StyleXu, Lu, Xiaxia Liu, and Yijia Zhang. 2023. "Blind Estimation of Spreading Code Sequence of QPSK-DSSS Signal Based on Fast-ICA" Information 14, no. 2: 112. https://doi.org/10.3390/info14020112