

Transferring CNN Features Maps to Ensembles of Explainable Neural Networks


Abstract
1. Introduction
1.1. Related Work
1.1.1. Rule Extraction from Ensembles of NNs
1.1.2. Explainability with Deep Models
2. Materials and Methods
2.1. MLP and DIMLP
2.1.1. MLP
2.1.2. DIMLP
2.2. Ensembles
2.3. Convolutional Neural Networks
2.3.1. Architecture
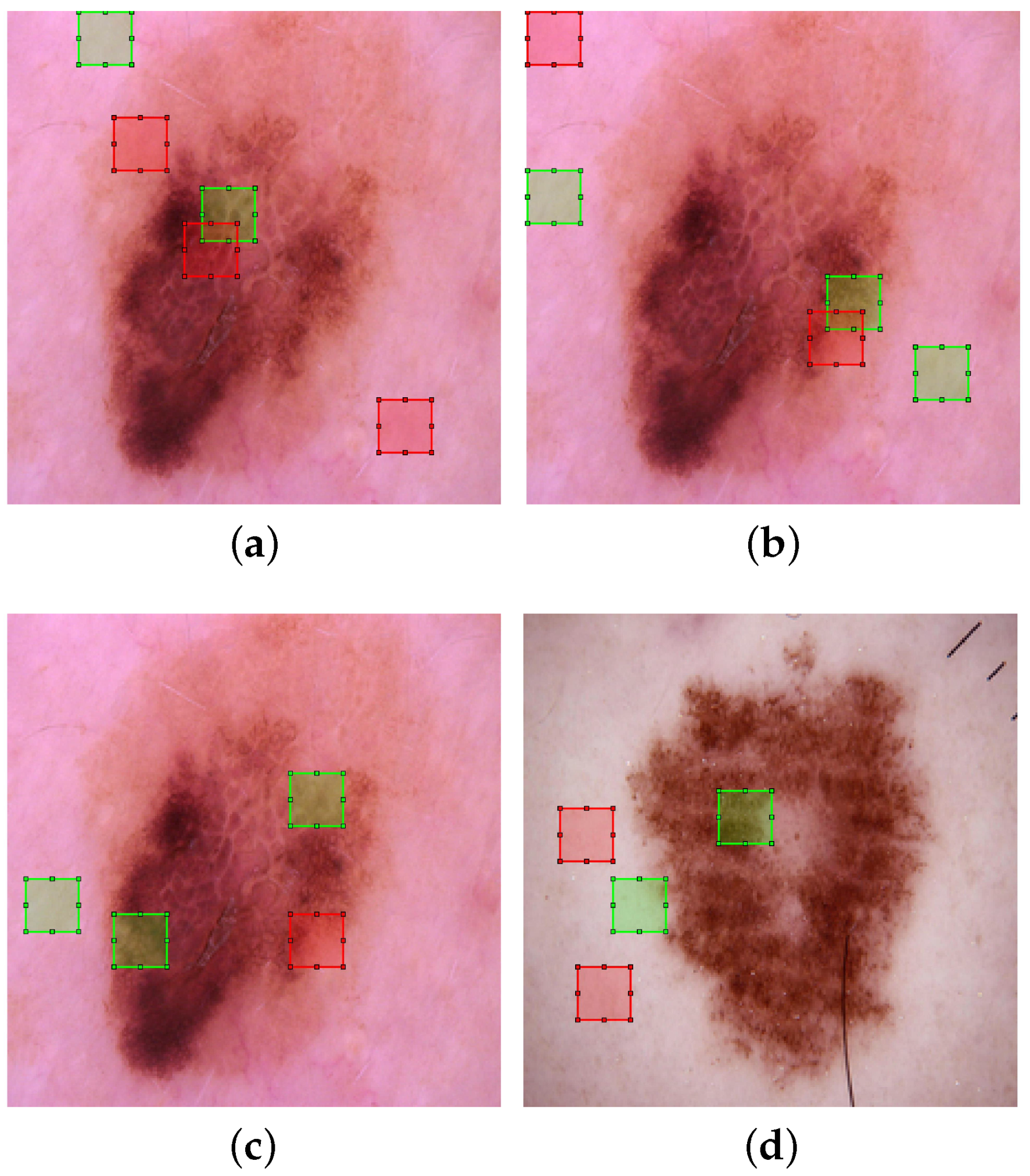
2.3.2. Transferring Featrure Maps to DIMLPs
3. Results
- Learning parameter = 0.1;
- Momentum = 0.6;
- Flat Spot Elimination = 0.01;
- Number of stairs in the staircase activation function = 50.
- Average predictive accuracy of the model;
- Average fidelity on the testing set, which is the degree of matching between the generated rules and the model. Specifically, with P samples in the test set and Q samples for which the classifications of the rules match the classifications of the model, the fidelity is ;
- Average predictive accuracy of the rules;
- Average predictive accuracy of the rules when rules and model agree. Specifically, it is the proportion of correctly classified samples among the Q samples defined above;
- Average number of extracted rules;
- Average number of rule antecedents.
3.1. Experiments with a COVID-19 Dataset
| Listing 1. Examples of rules generated from DIMLP-BT. Meaningful antecedents are represented in italics. The numbers in parenthesis represent the number of samples covered in the training set, with the rules ranked in descending order with respect to these. |
| Rule 1: IF AND AND THEN COVID (2551) |
| Rule 2: IF THEN COVID (2186) |
| Rule 3: IF AND THEN COVID (1908) |
| Rule 4: IF AND THEN COVID (1877) |
| Rule 5: IF AND THEN COVID (1725) |
| Rule 6: IF AND AND THEN COVID (1574) |
| Rule 7: IF AND AND AND THEN COVID (1141) |
| Rule 8: IF AND NOT AND THEN COVID (1140) |
| Rule 9: IF AND AND AND NOT THEN COVID (1074) |
| Rule 10: IF AND AND THEN COVID (770) |
| Rule 11: IF NOT AND NOT AND NOT AND NOT THEN NEGATIVE (511) |
| Rule 12: IF NOT AND NOT AND NOT THEN NEGATIVE (414) |
| Rule 13: IF NOT AND NOT AND NOT THEN NEGATIVE (382) |
| Rule 14: IF AND AND AND AND NOT THEN COVID (377) |
| Rule 15: IF NOT AND NOT AND NOT THEN NEGATIVE (351) |
| Listing 2. Activations of the rules by the test samples of a cross-validation trial. From left to right, the columns show the rule number, the number of activations of the rule, the number of correctly classified samples, the number of wrongly classified samples, the resulting accuracy and the class of the rule. |
| Rule 1: 308 306 2 0.993506 Class = COVID |
| Rule 2: 265 265 0 1.000000 Class = COVID |
| Rule 3: 211 211 0 1.000000 Class = COVID |
| Rule 4: 210 210 0 1.000000 Class = COVID |
| Rule 5: 203 203 0 1.000000 Class = COVID |
| Rule 6: 174 173 1 0.994253 Class = COVID |
| Rule 7: 119 118 1 0.991597 Class = COVID |
| Rule 8: 137 136 1 0.992701 Class = COVID |
| Rule 9: 135 134 1 0.992593 Class = COVID |
| Rule 10: 93 93 0 1.000000 Class = COVID |
| Rule 11: 61 61 0 1.000000 Class = NEGATIVE |
| Rule 12: 43 43 0 1.000000 Class = NEGATIVE |
| Rule 13: 38 38 0 1.000000 Class = NEGATIVE |
| Rule 14: 43 43 0 1.000000 Class = COVID |
| Rule 15: 38 38 0 1.000000 Class = NEGATIVE |
| Rule 16: 37 37 0 1.000000 Class = NEGATIVE |
| Rule 17: 25 25 0 1.000000 Class = COVID |
| Rule 18: 25 24 1 0.960000 Class = NEGATIVE |
| Rule 19: 18 18 0 1.000000 Class = NEGATIVE |
| Rule 20: 21 21 0 1.000000 Class = NEGATIVE |
| Rule 21: 11 11 0 1.000000 Class = NEGATIVE |
| Rule 22: 17 17 0 1.000000 Class = NEGATIVE |
| Rule 23: 14 14 0 1.000000 Class = NEGATIVE |
| Rule 24: 8 8 0 1.000000 Class = COVID |
| Rule 25: 5 5 0 1.000000 Class = NEGATIVE |
| Rule 26: 5 5 0 1.000000 Class = COVID |
| Rule 27: 2 2 0 1.000000 Class = NEGATIVE |
3.2. Comparison with Other Explainability Methods
- Chess: 200;
- Connect4: 40;
- EEG eye state: 100;
- Letter recognition: 200;
3.3. Experiments with CNNs
- 2D-Convolution with 32 kernels of size and ReLU activation function.
- Max-Pooling layer with blocks of size (32 units).
- 2D-Convolution with 32 kernels of size and ReLU activation function.
- Max-Pooling layer with blocks of size (32 units).
- 2D-Convolution with 32 kernels of size and ReLU activation function.
- Max-Pooling layer with blocks of size (32 units).
- 2D-Convolution with 32 kernels of size and ReLU activation function.
- Max-Pooling layer with blocks of size (32 units).
- Fully connected layer with sigmoid activation function (128 neurons).
- Fully connected layer with sigmoid activation function (64 neurons).
- Fully connected layer with sigmoid activation function (2 neurons).
- First level of feature maps: 32 DIMLPs with inputs and five neurons in the second hidden layer (in the first hidden layer the number of neurons is the same as in the input layer).
- Second level of feature maps: 32 DIMLPs with inputs and ten neurons in the second hidden layer.
- Third level of feature maps: 32 DIMLPs with inputs and 30 neurons in the second hidden layer.
- Fourth level of feature maps: 32 DIMLPs with inputs and 50 neurons in the second hidden layer.
3.3.1. Extraction of Rules at the Top Level (E Ensemble Dataset)
| Listing 3. Example of rules generated from the highest level of abstraction ( dataset). Odd attributes are relative to the probability of the “Malignant” class, while even attributes are relative to the “Benign” class. |
| Rule 1: |
| Rule 2: |
| Rule 3: |
| Rule 4: |
| Rule 5: |
| Rule 6: |
| Rule 7: |
| Rule 8: |
| Rule 9: |
| Rule 10: |
| Rule 11: |
| Rule 12: |
3.3.2. Extraction of Rules at the Level of the CNN Feature Maps
4. Discussion
5. Conclusions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | Artificial Intelligence |
| CNN | Convolutional Neural Network |
| DCT | Discrete Cosinus Transform |
| DIMLP | Discretized Interpretable Multi Layer Perceptron |
| DNNs | Deep neural network |
| DT | Decision Trees |
| IMLP | Interpretable Multi Layer Perceptrons |
| LIME | Interpretable Model-Agnostic Explanations |
| ML | Machine Learning |
| MLR-UCI | Machine Learning Repository at the University of California, Irvine |
| MLP | Multi Layer Perceptron |
| NN | Neural Network |
| SMOTE | Synthetic Minority Oversampling Technique |
| XAI | Explainable Artificial Intelligence |
| xDNN | Explainable Deep Neural Network |
References
- Namatēvs, I.; Sudars, K.; Dobrājs, A. Interpretability versus Explainability: Classification for Understanding Deep Learning Systems and Models. Comput. Assist. Methods Eng. Sci. 2022, 29, 297–356. [Google Scholar]
- Rudin, C. Please stop explaining black box models for high stakes decisions. arXiv 2018, arXiv:1811.10154. [Google Scholar]
- Andrews, R.; Diederich, J.; Tickle, A.B. Survey and critique of techniques for extracting rules from trained artificial neural networks. Knowl.-Based Syst. 1995, 8, 373–389. [Google Scholar] [CrossRef]
- Diederich, J. Rule Extraction from Support Vector Machines; Springer Science and Business Media: Berlin/Heidelberg, Germany, 2008; Volume 80. [Google Scholar] [CrossRef]
- Breiman, L. Bagging predictors. Mach. Learn. 1996, 24, 123–140. [Google Scholar] [CrossRef]
- Freund, Y.; Schapire, R.E. A desicion-theoretic generalization of on-line learning and an application to boosting. J. Comput. Syst. Sci. 1997, 55, 119–139. [Google Scholar] [CrossRef]
- Minh, D.; Wang, H.X.; Li, Y.F.; Nguyen, T.N. Explainable artificial intelligence: A comprehensive review. Artif. Intell. Rev. 2021, 55, 3503–3568. [Google Scholar] [CrossRef]
- Guidotti, R.; Monreale, A.; Ruggieri, S.; Turini, F.; Giannotti, F.; Pedreschi, D. A survey of methods for explaining black box models. ACM Comput. Surv. 2018, 51, 93. [Google Scholar] [CrossRef]
- Adadi, A.; Berrada, M. Peeking inside the black-box: A survey on Explainable Artificial Intelligence (XAI). IEEE Access 2018, 6, 52138–52160. [Google Scholar] [CrossRef]
- Holzinger, A.; Saranti, A.; Molnar, C.; Biecek, P.; Samek, W. Explainable AI methods-a brief overview. In Proceedings of the International Workshop on Extending Explainable AI Beyond Deep Models and Classifiers; Springer: Cham, Switzerland, 2022; pp. 13–38. [Google Scholar]
- Bologna, G. Rule extraction from a multilayer perceptron with staircase activation functions. In Proceedings of the IEEE-INNS-ENNS International Joint Conference on Neural Networks. IJCNN 2000. Neural Computing: New Challenges and Perspectives for the New Millennium, Como, Italy, 27 July 2000; pp. 419–424. [Google Scholar]
- Bologna, G. A study on rule extraction from several combined neural networks. Int. J. Neural Syst. 2001, 11, 247–255. [Google Scholar] [CrossRef]
- Bologna, G. A model for single and multiple knowledge based networks. Artif. Intell. Med. 2003, 28, 141–163. [Google Scholar] [CrossRef]
- Bologna, G. Is it worth generating rules from neural network ensembles? J. Appl. Log. 2004, 2, 325–348. [Google Scholar] [CrossRef]
- Golea, M. On the complexity of rule extraction from neural networks and network querying. In Proceedings of the Rule Extraction From Trained Artificial Neural Networks Workshop, Society For the Study of Artificial Intelligence and Simulation of Behavior Workshop Series (AISB), Brighton, UK, 1–2 April 1996; pp. 51–59. [Google Scholar]
- Saito, K.; Nakano, R. Medical diagnostic expert system based on PDP model. In Proceedings of the ICNN, San Diego, CA, USA, 24–27 July 1988; pp. 255–262. [Google Scholar] [CrossRef]
- Jiang, Y.; Zhou, Z.H.; Chen, Z.Q. Rule learning based on neural network ensemble. In Proceedings of the 2002 International Joint Conference on Neural Networks. IJCNN’02 (Cat. No. 02CH37290), Honolulu, HI, USA, 12–17 May 2002; pp. 1416–1420. [Google Scholar]
- Zhou, Z.H.; Jiang, Y.; Chen, S.F. Extracting symbolic rules from trained neural network ensembles. Artif. Intell. Commun. 2003, 16, 3–16. [Google Scholar]
- Hartono, P.; Hashimoto, S. An interpretable neural network ensemble. In Proceedings of the IECON 2007-33rd Annual Conference of the IEEE Industrial Electronics Society, Taipei, Taiwan, 5–8 November 2007; pp. 228–232. [Google Scholar]
- Quinlan, J.R. Learning efficient classification procedures and their application to chess end games. In Machine Learning; Springer: Berlin/Heidelberg, Germany, 1983; pp. 463–482. [Google Scholar]
- Zhou, Z.H.; Jiang, Y. Medical diagnosis with C4.5 rule preceded by artificial neural network ensemble. IEEE Trans. Inf. Technol. Biomed. 2003, 7, 37–42. [Google Scholar] [CrossRef]
- Johansson, U. Obtaining Accurate and Comprehensible Data Mining Models: An Evolutionary Approach; Linköping University, Department of Computer and Information Science: Linköping, Sweden, 2007. [Google Scholar]
- Hara, A.; Hayashi, Y. Ensemble neural network rule extraction using Re-RX algorithm. In Proceedings of the Neural Networks (IJCNN), Brisbane, QLD, Australia, 10–15 June 2012; pp. 1–6. [Google Scholar]
- Hayashi, Y.; Sato, R.; Mitra, S. A new approach to three ensemble neural network rule extraction using recursive-rule extraction algorithm. In Proceedings of the The 2013 International Joint Conference on Neural Networks (IJCNN), Dallas, TX, USA, 4–9 August 2013; pp. 1–7. [Google Scholar] [CrossRef]
- Setiono, R.; Baesens, B.; Mues, C. Recursive neural network rule extraction for data with mixed attributes. IEEE Trans. Neural Netw. 2008, 19, 299–307. [Google Scholar] [CrossRef]
- Sendi, N.; Abchiche-Mimouni, N.; Zehraoui, F. A new transparent ensemble method based on deep learning. Procedia Comput. Sci. 2019, 159, 271–280. [Google Scholar] [CrossRef]
- Chakraborty, M.; Biswas, S.K.; Purkayastha, B. Rule extraction using ensemble of neural network ensembles. Cogn. Syst. Res. 2022, 75, 36–52. [Google Scholar] [CrossRef]
- Schaaf, N.; Huber, M.; Maucher, J. Enhancing decision tree based interpretation of deep neural networks through l1-orthogonal regularization. In Proceedings of the 2019 18th IEEE International Conference On Machine Learning Furthermore, Applications (ICMLA), Boca Raton, FL, USA, 16–19 December 2019; pp. 42–49. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. "Why should I trust you?" Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar]
- Chen, H.; Lundberg, S.; Lee, S. Explaining models by propagating Shapley values of local components. arXiv 2019, arXiv:1911.11888. [Google Scholar]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Frosst, N.; Hinton, G. Distilling a neural network into a soft decision tree. arXiv 2017, arXiv:1711.09784. [Google Scholar]
- Zhang, Q.; Yang, Y.; Wu, Y.N.; Zhu, S.C. Interpreting CNNs via decision trees. arXiv 2018, arXiv:1802.00121. [Google Scholar]
- Angelov, P.; Soares, E. Towards explainable deep neural networks (xDNN). Neural Netw. 2020, 130, 185–194. [Google Scholar] [CrossRef]
- Zeiler, M.D.; Fergus, R. Visualizing and understanding convolutional networks. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; pp. 818–833. [Google Scholar]
- Mahendran, A.; Vedaldi, A. Understanding deep image representations by inverting them. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 5188–5196. [Google Scholar]
- Lapuschkin, S.; Binder, A.; Montavon, G.; Muller, K.R.; Samek, W. Analyzing classifiers: Fisher vectors and deep neural networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 2912–2920. [Google Scholar]
- Haar, L.V.; Elvira, T.; Ochoa, O. An analysis of explainability methods for convolutional neural networks. Eng. Appl. Artif. Intell. 2023, 117, 105606. [Google Scholar] [CrossRef]
- Breiman, L. Bias, Variance, and Arcing Classifiers; Technical Report, Tech. Rep. 460; Statistics Department, University of California, Berkeley: Berkeley, CA, USA, 1996. [Google Scholar]
- Bologna, G. A rule extraction technique applied to ensembles of neural networks, random forests, and gradient-boosted trees. Algorithms 2021, 14, 339. [Google Scholar] [CrossRef]
- Lichman, M. UCI Machine Learning Repository, University of California, Irvine, School of Information and Computer Sciences. 2023. Available online: https://archive.ics.uci.edu/ml/index.php (accessed on 1 September 2022).
- Olson, D.L.; Delen, D. Advanced Data Mining Techniques; Springer Science and Business Media: Berlin/Heidelberg, Germany, 2008. [Google Scholar]
- Villavicencio, C.N.; Macrohon, J.J.; Inbaraj, X.A.; Jeng, J.H.; Hsieh, J.G. Development of a machine learning based web application for early diagnosis of COVID-19 based on symptoms. Diagnostics 2022, 12, 821. [Google Scholar] [CrossRef] [PubMed]
- Vilone, G.; Longo, L. A quantitative evaluation of global, rule-based explanations of post hoc, model agnostic methods. Front. Artif. Intell. 2021, 4, 717899. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Craven, M.W.; Shavlik, J.W. Using sampling and queries to extract rules from trained neural networks. In Machine Learning Proceedings 1994; Elsevier: Amsterdam, The Netherlands, 1994; pp. 37–45. [Google Scholar]
- Das, P.; Upadhyay, R.K.; Das, P.; Ghosh, D. Exploring dynamical complexity in a time-delayed tumor-immune model. Chaos Interdiscip. J. Nonlinear Sci. 2020, 30, 123118. [Google Scholar] [CrossRef]
- Das, P.; Mukherjee, S.; Das, P.; Banerjee, S. Characterizing chaos and multifractality in noise-assisted tumor-immune interplay. Nonlinear Dyn. 2020, 101, 675–685. [Google Scholar] [CrossRef]
- Dehingia, K.; Das, P.; Upadhyay, R.K.; Misra, A.K.; Rihan, F.A.; Hosseini, K. Modelling and analysis of delayed tumour–immune system with hunting T-cells. Math. Comput. Simul. 2023, 203, 669–684. [Google Scholar] [CrossRef]
- Bologna, G. Explaining cnn classifications by propositional rules generated from dct feature maps. In Proceedings of the International Work-Conference on the Interplay Between Natural and Artificial Computation, Puerto de la Cruz, Tenerife, Spain, 31 May–3 June 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 318–327. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Type | Result | Reference |
|---|---|---|---|
| LIME | local | relevance of features | [29] |
| SHAP | local/global | relevance of features | [30] |
| Grad-CAM | map | relevant image pixels | [31] |
| DeconvNet | map | relevant pixels at each layer | [35] |
| CNN inversion | map | relevant pixels at each layer | [36] |
| LRP | map | relevant pixels at each layer | [37] |
| DT learning CNN input/output associations | global | DT predicates on relevant pixels | [32] |
| DT learning CNN input/output associations | global | DT predicates on feature maps | [33] |
| xDNN | global | Propositional rules relative to the similarity of prototypes | [34] |
| Dataset | #Samp. | #Attr. | Attr. Types | #Class | Platform |
|---|---|---|---|---|---|
| Chess | 28,056 | 6 | cat. | 18 | MLR-UCI |
| Connect4 | 67,557 | 42 | cat. | 3 | MLR-UCI |
| Covid symptoms | 5434 | 20 | cat. | 2 | Kaggle |
| EEG eye state | 14,980 | 14 | real | 2 | MLR-UCI |
| Letter recognition | 20,000 | 16 | real | 26 | MLR-UCI |
| Melanoma diagnosis | 3297 | 150,528 | real | 2 | Kaggle |
| Model | Acc. | Fid. | Acc. R. (a) | Acc. R. (b) | Nb. R. | Nb. Ant. |
|---|---|---|---|---|---|---|
| DIMLP-AT | 97.5 (0.2) | 100 (0.0) | 97.5 (0.2) | 97.5 (0.2) | 25.5 (1.1) | 4.0 (0.1) |
| DIMLP-BT | 98.1 (0.1) | 100 (0.0) | 98.1 (0.1) | 98.1 (0.1) | 26.3 (0.6) | 4.1 (0.0) |
| Data, Model | Acc. | Fid. | Acc. R. (a) | Acc. R. (b) | Nb. R. | Nb. Ant. |
|---|---|---|---|---|---|---|
| Chess, DIMLP-AT | 43.3 (0.2) | 99.7 (0.0) | 43.2 (0.2) | 43.3 (0.2) | 1435.1 (16.6) | 7.7 (0.1) |
| Connect4, DIMLP-AT | 85.6 (0.3) | 93.7 (0.1) | 84.4 (0.1) | 88.0 (0.1) | 6041.3 (56.4) | 8.4 (0.0) |
| EEG eye, DIMLP-AT | 79.4 (3.7) | 94.3 (1.0) | 77.1 (3.6) | 80.1 (4.0) | 1069.0 (118.4) | 5.7 (0.2) |
| Letter, DIMLP-AT | 96.7 (0.0) | 93.1 (0.2) | 91.8 (0.2) | 98.1 (0.1) | 1879.1 (8.1) | 7.5 (0.0) |
| Chess, DIMLP-BT | 45.0 (0.2) | 99.8 (0.0) | 45.7 (0.2) | 45.8 (0.2) | 1178.6 (9.3) | 7.4 (0.1) |
| Connect4, DIMLP-BT | 84.7 (0.1) | 96.2 (0.1) | 83.7 (0.0) | 86.0 (0.1) | 3900.4 (23.1) | 8.2 (0.0) |
| EEG eye, DIMLP-BT | 85.0 (0.2) | 94.3 (0.2) | 82.3 (0.2) | 85.7 (0.2) | 1107.0 (20.7) | 5.6 (0.0) |
| Letter, DIMLP-BT | 95.5 (0.0) | 93.1 (0.1) | 91.4 (0.1) | 97.4 (0.1) | 1815.8 (9.5) | 7.6 (0.0) |
| Data, Model | Acc. | Fid. | Acc. R. (a) | Acc. R. (b) | Nb. R. | Nb. Ant. |
|---|---|---|---|---|---|---|
| Chess, DIMLP-AT | 38.2 (0.2) | 95.7 (0.2) | 37.0 (0.2) | 38.3 (0.2) | 3518.6 (55.6) | 8.4 (0.0) |
| Connect4, DIMLP-AT | 84.1 (0.2) | 90.2 (0.2) | 81.1 (0.2) | 87.2 (0.1) | 6357.6 (138.5) | 8.2 (0.0) |
| EEG eye, DIMLP-AT | 82.8 (3.3) | 93.2 (0.9) | 80.5 (3.2) | 84.1 (3.5) | 1308.8 (140.0) | 5.8 (0.1) |
| Letter, DIMLP-AT | 96.7 (0.1) | 92.6 (0.1) | 91.4 (0.1) | 98.1 (0.0) | 1975.4 (19.6) | 7.4 (0.0) |
| Chess, DIMLP-BT | 41.1 (0.2) | 97.2 (0.1) | 40.5 (0.3) | 41.3 (0.3) | 2644.1 (34.1) | 8.1 (0.0) |
| Connect4, DIMLP-BT | 83.6 (0.1) | 91.8 (0.1) | 80.9 (0.1) | 85.9 (0.1) | 6176.7 (42.6) | 8.1 (0.0) |
| EEG eye, DIMLP-BT | 85.4 (0.2) | 94.3 (0.3) | 82.7 (0.2) | 86.1 (0.2) | 1228.4 (16.5) | 5.6 (0.0) |
| Letter, DIMLP-BT | 95.5 (0.1) | 92.1 (0.2) | 90.6 (0.1) | 97.6 (0.1) | 2020.2 (11.2) | 7.5 (0.0) |
| Chess, C4.5-PANE | - | 32.9 | 24.3 | - | 24,769 | 16.1 |
| Connect4, C4.5-PANE | - | 77.9 | 67.3 | - | 7115 | 18.8 |
| EEG eye, Trepan | - | 68.6 | 60.1 | - | 2 | 9.0 |
| Letter, C4.5-PANE | - | 79.8 | 69.0 | - | 13,826 | 15.2 |
| Model | Acc. | Fid. | Acc. R. (a) | Acc. R. (b) | Nb. R. | Nb. Ant. |
|---|---|---|---|---|---|---|
| CNN | 84.5 (0.9) | - | - | - | - | - |
| DIMLP-BT | 84.7 (0.9) | 95.5 (1.0) | 83.6 (1.0) | 85.8 (1.0) | 141.7 (18.2) | 5.4 (0.2) |
| Trial | Acc. CNN | Acc. DIMLP-BT | Acc. R. (a) | Acc. R. (b) |
|---|---|---|---|---|
| 1 | 84.2 | 84.4 | 83.2 | 85.0 |
| 2 | 84.6 | 85.0 | 83.0 | 85.2 |
| 3 | 83.6 | 84.5 | 84.4 | 86.1 |
| 4 | 83.3 | 84.1 | 84.2 | 86.3 |
| 5 | 85.3 | 83.3 | 83.3 | 84.6 |
| 6 | 83.6 | 84.7 | 82.9 | 85.5 |
| 7 | 85.5 | 86.2 | 85.3 | 87.8 |
| 8 | 85.3 | 85.9 | 84.2 | 86.4 |
| 9 | 85.6 | 83.9 | 82.0 | 85.0 |
| 10 | 83.5 | 85.2 | 83.8 | 86.1 |
| Average | 84.5 | 84.7 | 83.6 | 85.8 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bologna, G. Transferring CNN Features Maps to Ensembles of Explainable Neural Networks. Information 2023, 14, 89. https://doi.org/10.3390/info14020089
Bologna G. Transferring CNN Features Maps to Ensembles of Explainable Neural Networks. Information. 2023; 14(2):89. https://doi.org/10.3390/info14020089
Chicago/Turabian StyleBologna, Guido. 2023. "Transferring CNN Features Maps to Ensembles of Explainable Neural Networks" Information 14, no. 2: 89. https://doi.org/10.3390/info14020089
APA StyleBologna, G. (2023). Transferring CNN Features Maps to Ensembles of Explainable Neural Networks. Information, 14(2), 89. https://doi.org/10.3390/info14020089