
Assessing Fine-Grained Explicitness of Song Lyrics



Abstract
:1. Introduction
- We propose and released a new dataset of 4000 song lyrics manually annotated with explicitness information. Besides the indication of whether the song lyrics contain explicit content or not, each explicit song’s lyrics was also appropriately annotated according to the five reasons for explicitness previously mentioned. To the best of our knowledge, this is: (i) the first released dataset containing manually curated information on the explicitness of song lyrics (the few available datasets mainly rely on explicitness information provided by online platforms (e.g., Spotify in [5]), acknowledged to be inaccurate by the platform themselves (e.g., https://support.spotify.com/us/article/explicit-content/), accessed on 2 February 2023); and (ii) the first dataset containing fine-grained explicitness annotations, detailing the reasons for the explicitness of the song lyrics. The development of datasets is fundamental for the advancement of the state-of-the-art in computer science and related disciplines, especially for problems for which training and testing material is lacking, as the one considered in this paper.
- We present a preliminary assessment of the quality of the explicitness information available on a popular online streaming platform (Spotify), comparing, on the same songs, the explicitness tags in the platform with our manual annotations.
- We experimented with some ML classifiers to assess the feasibility of automatically predicting the explicitness and, if so, the reasons for the explicitness of a given song’s lyrics. To the best of our knowledge, no previous work has addressed the problem of providing possible reasons for the explicitness of song lyrics. We also released, as part of the evaluation material, a pre-trained model for predicting the explicitness, and possible reasons for it, of any English song lyrics.
2. Related Work
3. Problem
- Strong language: The song lyrics include offensive words or curse words, i.e., words generally found to be disturbing and that are not normally used in regular conversation. Swear words (e.g., fuck yourself, bitch) are generally considered strong language. An example of song lyrics containing strong language are those of “Spaz” by “N.E.R.D.” (e.g., “I’m a star bitch, I don’t give a fuck”) (https://www.musixmatch.com/lyrics/N-E-R-D/Spaz, accessed on 2 February 2023).
- Substance abuse: The song lyrics refer to excessive use (e.g., getting stoned, getting high, indulging in a dependency) of a drug, alcohol, prescription medicine, etc., in a way that is detrimental to self, society, or both. Both psychological and physical addiction to some substances are covered by this concept. An example of song lyrics referring to substance abuse are those of “Alcohol” by “The Kinks” (e.g., “Who thought I would fall, A slave to demon alcohol”) (https://www.musixmatch.com/lyrics/The-Kinks/Alcohol, accessed on 2 February 2023).
- Sexual reference: The song lyrics contain references to sex, sexual organs, sexual body parts, sexual activity, sexual abuse, and so on. Idiomatic phrases such as “go fuck yourself” or “what the fuck” were excluded and categorized as strong language instead. An example of song lyrics containing sexual reference are those in “Morning Wood” by “Rodney Carrington” (e.g., “’Cause underneath the covers is my morning wood”) (https://www.musixmatch.com/lyrics/Rodney-Carrington/Morning-Wood, accessed on 2 February 2023).
- Reference to violence: The song lyrics contain references to hurting a person or living being intentionally, including the description or suggestion of acts typically considered as violent (e.g., killing, stabbing, mentally or physically torturing, committing suicide). Both physical and mental violence and abuse are covered by this concept. Idiomatic expressions using words that are associated with violent acts (e.g., “my heart is bleeding”, “I’m devastated”) are typically not considered evidence of a reference to violence. An example of song lyrics containing a reference to violence are those of “Story of a Hero” by “Drearylands” (e.g., “You have killed or left dying in the waste”) (https://www.musixmatch.com/lyrics/Drearylands/Story-of-a-Hero, accessed on 2 February 2023).
- Discriminatory language: The song lyrics contain (i) insulting or pejorative expressions referring to races, ethnic groups, nationalities, genders, sexual orientation, etc.; (ii) offensive language directed at one specific subset of people; (iii) reiteration of stereotypes that can be hurtful for a specific target group of people. An example of song lyrics using discriminatory language are those of “Dash’s Interlude” by “Rapper Big Pooh” (e.g., “Faggots gonna hate me”) (https://www.musixmatch.com/lyrics/Rapper-Big-Pooh-feat-O-Dash/Dash-s-Interlude, accessed on 2 February 2023).
4. Dataset
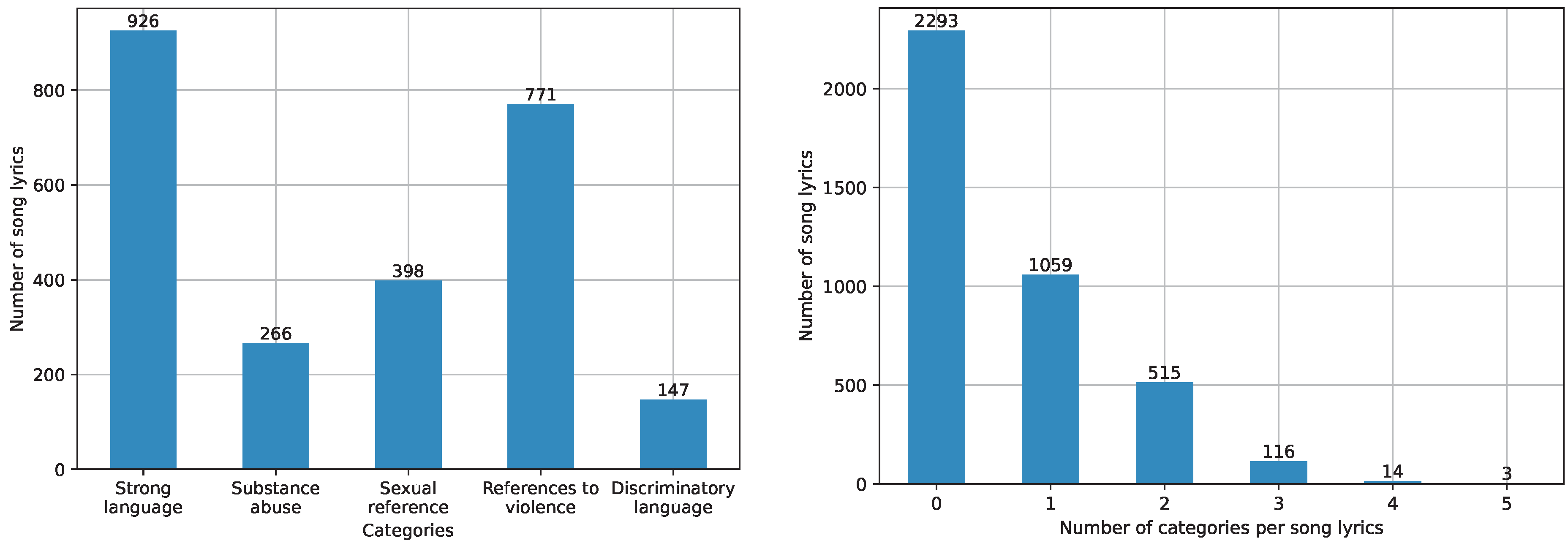
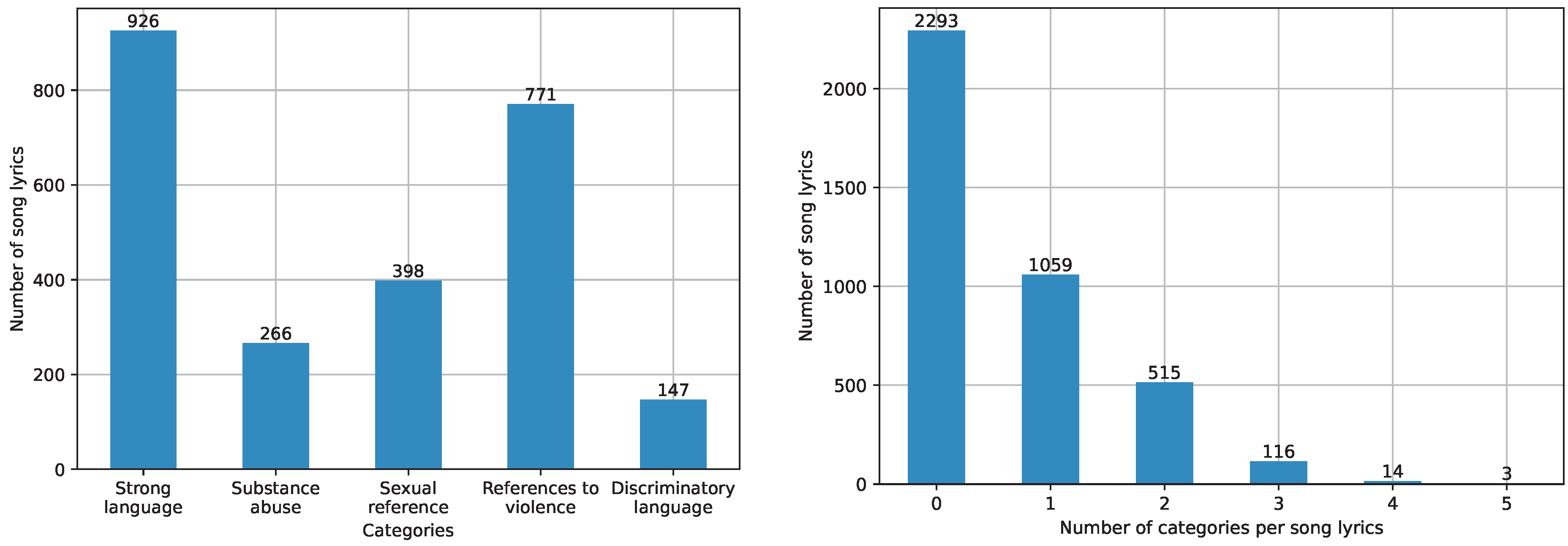
4.1. Dataset’s Statistics
4.2. Comparison with the Explicitness Information Available on Spotify
- The song does not contain explicit content itself, but is contained in an album (or collection) that is marked as a whole as explicit;
- The song does not contain explicit content itself, but its cover art (or of the album or collection in which it is contained) contains explicit content;
- Different opinions (possibly due to different cultures, sensibilities, etc.) between the right holder providing the explicitness information to Spotify and our annotators.
5. Automatic Detection of Fine-Grained Explicit Lyrics
5.1. Text Classifiers Compared
5.1.1. 1D CNNFT
5.1.2. DistilBERTC
- 1D CNNFT proved very effective and efficient for explicit lyrics’ classification, outperforming other simpler approaches (e.g., logistic regression) and attaining a score on par with classifiers developed on top of TLMs while requiring much less computational power (training and testing can be performed on standard CPUs) than the latter (training and testing require substantial computation power as offered by GPUs);
- Among classifiers based on TLMs, DistilBERTC achieved comparable scores to larger models (e.g., BERT) for explicit lyrics’ classification, while being smaller and computationally less demanding, thus presenting itself as a good candidate for practical usages.
5.2. Research Question and Evaluation Protocol
- RQ
- Is it feasible to effectively determine the reasons for the explicitness of song lyrics via automatic text classification techniques?
- Precision : this measures how precise the method is on the class, independent of its coverage;
- Recall : this measures how extensively the class is covered by the method;
- : this combines the previous two in a single representative measure.
5.3. Evaluation Results and Discussion
6. Limitations
7. Conclusions
Author Contributions
Funding
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chin, H.; Kim, J.; Kim, Y.; Shin, J.; Yi, M.Y. Explicit Content Detection in Music Lyrics Using Machine Learning. In Proceedings of the 2018 IEEE International Conference on Big Data and Smart Computing, BigComp 2018, Shanghai, China, 15–17 January 2018; IEEE Computer Society: Washington, DC, USA, 2018; pp. 517–521. [Google Scholar] [CrossRef]
- Kim, J.; Yi, M.Y. A Hybrid Modeling Approach for an Automated Lyrics-Rating System for Adolescents. In Proceedings of the Advances in Information Retrieval—41st European Conference on IR Research, ECIR 2019, Cologne, Germany, 14–18 April 2019; Proceedings, Part I. Azzopardi, L., Stein, B., Fuhr, N., Mayr, P., Hauff, C., Hiemstra, D., Eds.; Springer: Berlin/Heidelberg, Germany, 2019; Volume 11437, pp. 779–786. [Google Scholar] [CrossRef]
- Bergelid, L. Classification of Explicit Music Content Using Lyrics and Music Metadata. Master’s Thesis, KTH, School of Electrical Engineering and Computer Science (EECS), Stockholm, Sweden, 2018. [Google Scholar]
- Fell, M.; Cabrio, E.; Korfed, E.; Buffa, M.; Gandon, F. Love Me, Love Me, Say (and Write!) that You Love Me: Enriching the WASABI Song Corpus with Lyrics Annotations. In Proceedings of the 12th Language Resources and Evaluation Conference, Marseille, France, 11–16 May 2020; European Language Resources Association: Marseille, France, 2020; pp. 2138–2147. [Google Scholar]
- Rospocher, M. Explicit song lyrics detection with subword-enriched word embeddings. Expert Syst. Appl. 2021, 163, 113749. [Google Scholar] [CrossRef]
- Rospocher, M. On exploiting transformers for detecting explicit song lyrics. Entertain. Comput. 2022, 43, 100508. [Google Scholar] [CrossRef]
- Rospocher, M. Detecting explicit lyrics: A case study in Italian music. Lang. Resour. Eval. 2022. [Google Scholar] [CrossRef]
- Vaglio, A.; Hennequin, R.; Moussallam, M.; Richard, G.; d’Alché-Buc, F. Audio-Based Detection of Explicit Content in Music. In Proceedings of the ICASSP 2020—2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Barcelona, Spain, 4–8 May 2020; pp. 526–530. [Google Scholar]
- Fell, M.; Cabrio, E.; Corazza, M.; Gandon, F. Comparing Automated Methods to Detect Explicit Content in Song Lyrics. In Proceedings of the International Conference on Recent Advances in Natural Language Processing (RANLP 2019), Varna, Bulgaria, 2–4 September 2019; INCOMA Ltd.: Varna, Bulgaria, 2019; pp. 338–344. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.W.; Lee, K.; Toutanova, K. BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; Association for Computational Linguistics: Minneapolis, MN, USA, 2019; pp. 4171–4186. [Google Scholar] [CrossRef]
- Liu, Y.; Ott, M.; Goyal, N.; Du, J.; Joshi, M.; Chen, D.; Levy, O.; Lewis, M.; Zettlemoyer, L.; Stoyanov, V. RoBERTa: A Robustly Optimized BERT Pretraining Approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Sanh, V.; Debut, L.; Chaumond, J.; Wolf, T. DistilBERT, a distilled version of BERT: Smaller, faster, cheaper and lighter. arXiv 2019, arXiv:1910.01108. [Google Scholar]
- Passonneau, R. Measuring Agreement on Set-valued Items (MASI) for Semantic and Pragmatic Annotation. In Proceedings of the Fifth International Conference on Language Resources and Evaluation (LREC’06), Genoa, Italy, 22–28 May 2006; European Language Resources Association (ELRA): Genoa, Italy, 2006. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef] [Green Version]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching Word Vectors with Subword Information. Trans. Assoc. Comput. Linguist. 2017, 5, 135–146. [Google Scholar] [CrossRef] [Green Version]
- Minaee, S.; Kalchbrenner, N.; Cambria, E.; Nikzad, N.; Chenaghlu, M.; Gao, J. Deep Learning–Based Text Classification: A Comprehensive Review. ACM Comput. Surv. 2021, 54, 1–40. [Google Scholar] [CrossRef]
- Chollet, F. Keras. 2015. Available online: https://keras.io (accessed on 2 February 2023).
- Wolf, T.; Debut, L.; Sanh, V.; Chaumond, J.; Delangue, C.; Moi, A.; Cistac, P.; Rault, T.; Louf, R.; Funtowicz, M.; et al. Transformers: State-of-the-Art Natural Language Processing. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations, online, 16–20 November 2020; Association for Computational Linguistics: Stroudsburg, PA, USA, 2020; pp. 38–45. [Google Scholar]
- Chicco, D.; Jurman, G. The advantages of the Matthews correlation coefficient (MCC), over F1 score and accuracy in binary classification evaluation. BMC Genom. 2020, 21, 6. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Basile, V.; Cabitza, F.; Campagner, A.; Fell, M. Toward a Perspectivist Turn in Ground Truthing for Predictive Computing. arXiv 2021, arXiv:2109.04270. [Google Scholar]
- Ouyang, L.; Wu, J.; Jiang, X.; Almeida, D.; Wainwright, C.L.; Mishkin, P.; Zhang, C.; Agarwal, S.; Slama, K.; Ray, A.; et al. Training language models to follow instructions with human feedback. arXiv 2022, arXiv:2203.02155. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
| Strong | Substance | Sexual | References | Discriminatory | Single | |
|---|---|---|---|---|---|---|
| Language | Abuse | Reference | to Violence | Language | Annotation | |
| Strong language | 926 (1.00) | 109 (0.12) | 186 (0.20) | 276 (0.30) | 99 (0.11) | 339 (0.37) |
| Substance abuse | 109 (0.41) | 266 (1.00) | 47 (0.18) | 60 (0.23) | 20 (0.08) | 103 (0.39) |
| Sexual reference | 186 (0.47) | 47 (0.12) | 398 (1.00) | 89 (0.22) | 45 (0.11) | 143 (0.36) |
| References to violence | 276 (0.36) | 60 (0.08) | 89 (0.12) | 771 (1.00) | 46 (0.06) | 403 (0.52) |
| Discriminatory language | 99 (0.67) | 20 (0.14) | 45 (0.31) | 46 (0.31) | 147 (1.00) | 11 (0.07) |
| Category | System | P | R | |
|---|---|---|---|---|
| Explicit | 1D CNNFT | 0.809 | 0.798 | 0.802 |
| DistilBERTC | 0.861 | 0.862 | 0.862 | |
| Strong language | 1D CNNFT | 0.898 | 0.921 | 0.909 |
| DistilBERTC | 0.906 | 0.941 | 0.922 | |
| Substance abuse | 1D CNNFT | 0.467 | 0.500 | 0.483 |
| DistilBERTC | 0.745 | 0.755 | 0.750 | |
| Sexual reference | 1D CNNFT | 0.636 | 0.566 | 0.582 |
| DistilBERTC | 0.820 | 0.771 | 0.792 | |
| Reference to violence | 1D CNNFT | 0.559 | 0.517 | 0.501 |
| DistilBERTC | 0.765 | 0.788 | 0.775 | |
| Discriminatory language | 1D CNNFT | 0.684 | 0.571 | 0.599 |
| DistilBERTC | 0.938 | 0.845 | 0.886 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Rospocher, M.; Eksir, S. Assessing Fine-Grained Explicitness of Song Lyrics. Information 2023, 14, 159. https://doi.org/10.3390/info14030159
Rospocher M, Eksir S. Assessing Fine-Grained Explicitness of Song Lyrics. Information. 2023; 14(3):159. https://doi.org/10.3390/info14030159
Chicago/Turabian StyleRospocher, Marco, and Samaneh Eksir. 2023. "Assessing Fine-Grained Explicitness of Song Lyrics" Information 14, no. 3: 159. https://doi.org/10.3390/info14030159
APA StyleRospocher, M., & Eksir, S. (2023). Assessing Fine-Grained Explicitness of Song Lyrics. Information, 14(3), 159. https://doi.org/10.3390/info14030159