
Applications of Text Mining in the Transportation Infrastructure Sector: A Review



Abstract
:1. Introduction
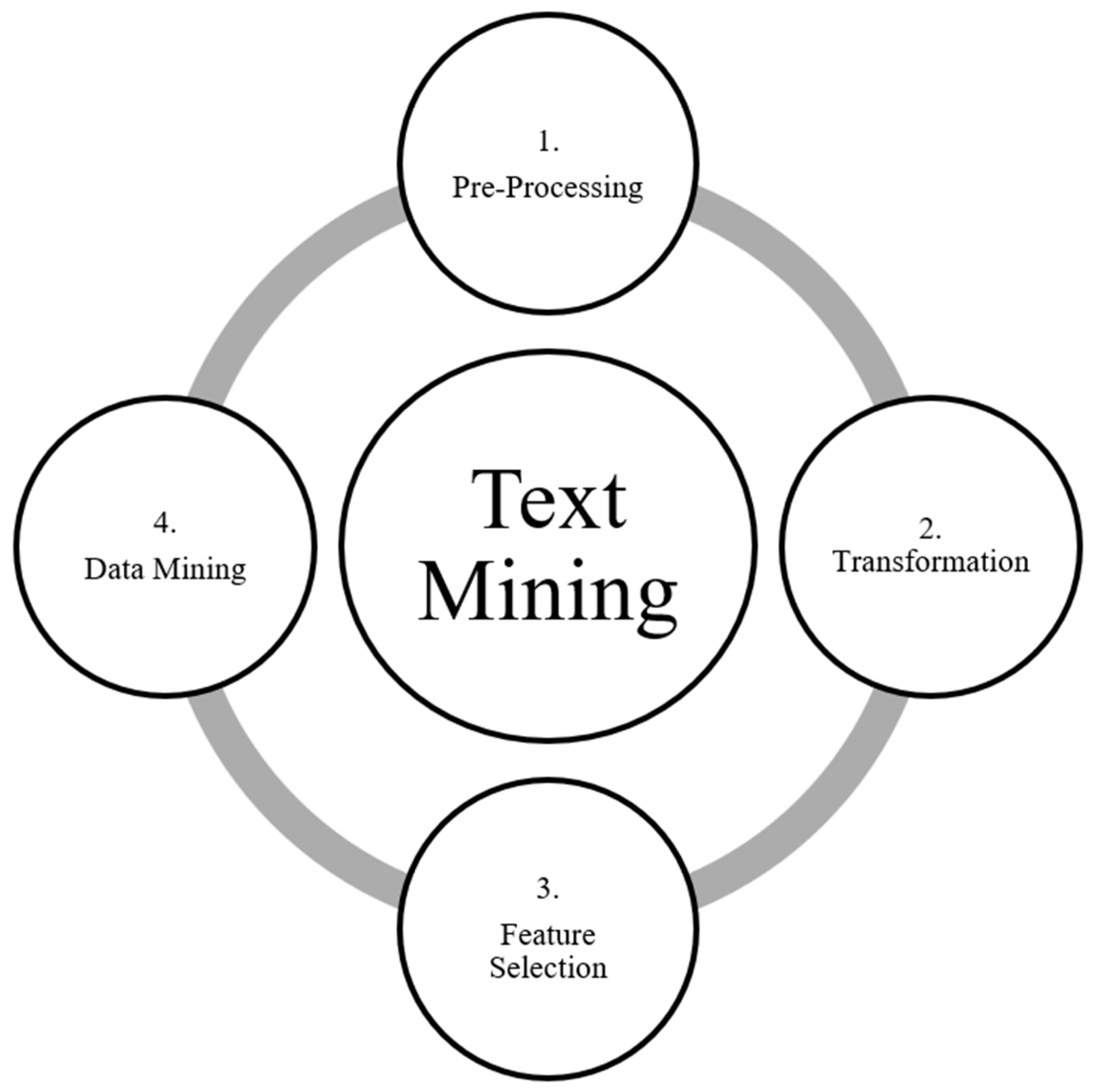
2. Process of Text Mining
2.1. Text Pre-Processing
2.2. Transformation
2.3. Feature Selection
2.4. Data Mining
3. Research Methodology
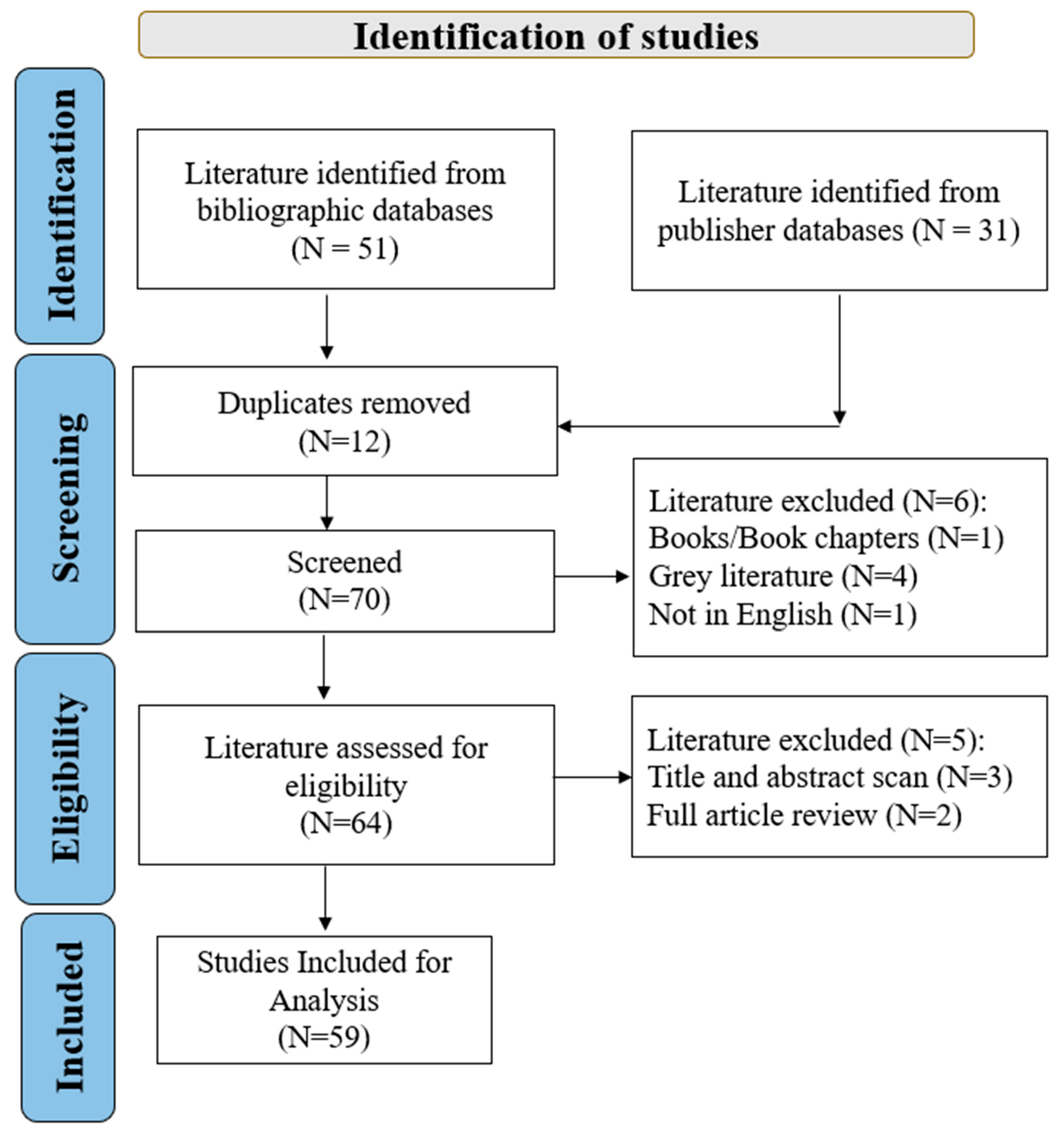
3.1. Information Sources and Search Strategy
3.2. Screening Criteria
3.3. Eligibility Criteria
3.4. Data Extraction, Storage, and Analysis
4. Text Mining and Transportation Infrastructures
4.1. Crashes and Accidents
4.1.1. Roadway
4.1.2. Rail
4.1.3. Other Sectors
4.2. Mobility Analysis
4.2.1. Social Media-Based Sentiment/Conception Analysis
4.2.2. Tourism
4.2.3. Travel and Traffic Behavior and Pattern Analysis
4.2.4. Trend Analysis
4.3. Supply Chain and Logistics
4.3.1. Sentiment/Perception Analysis
4.3.2. Trend Analysis
4.3.3. Risk and Resilience Analysis
4.4. Construction and Urban Infrastructure
4.4.1. New Information Generation
4.4.2. Sentiment/Perception Analysis
4.4.3. Trend Analysis
4.4.4. Others
4.5. Review of Literature
4.5.1. Industry 4.0 Applications Regarding the Supply Chain
4.5.2. Risk Management
4.5.3. Others
4.6. Innovation in Transportation Infrastructure Research
5. Conclusions and Future Research Directions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Alexakis, G.; Panagiotakis, S.; Fragkakis, A.; Markakis, E.; Vassilakis, K. Control of Smart Home Operations Using Natural Language Processing, Voice Recognition and IoT Technologies in a Multi-Tier Architecture. Designs 2019, 3, 32. [Google Scholar] [CrossRef] [Green Version]
- Chopra, A.; Prashar, A.; Sain, C. Natural Language Processing. Int. J. Technol. Enhanc. Emerg. Eng. Res. 2013, 1, 131–134. [Google Scholar]
- Goldberg, Y. A Primer on Neural Network Models for Natural Language Processing. J. Artif. Intell. Res. 2016, 57, 345–420. [Google Scholar] [CrossRef] [Green Version]
- Hirschberg, J.; Manning, C.D. Advances in natural language processing. Science 2015, 349, 261–266. [Google Scholar] [CrossRef]
- Hsiao, Y.-H.; Chen, M.-C.; Liao, W.-C. Logistics service design for cross-border E-commerce using Kansei engineering with text-mining-based online content analysis. Telemat. Inform. 2017, 34, 284–302. [Google Scholar] [CrossRef]
- Seo, Y.; Lim, D.; Son, W.; Kwon, Y.; Kim, J.; Kim, H. Deriving Mobility Service Policy Issues Based on Text Mining: A Case Study of Gyeonggi Province in South Korea. Sustainability 2020, 12, 10482. [Google Scholar] [CrossRef]
- Kamerkar, N.; Patil, K.; Kale, A. Text Mining Applied to Rail Accidents. Int. J. Future Revolut. Comput. Sci. Commun. Eng. 2018, 4, 383–386. [Google Scholar]
- VijayGaikwad, S.; Chaugule, A.; Patil, P. Text Mining Methods and Techniques. Int. J. Comput. Appl. 2014, 85, 42–45. [Google Scholar] [CrossRef]
- Zhu, F.; Patumcharoenpol, P.; Zhang, C.; Yang, Y.; Chan, J.; Meechai, A.; Vongsangnak, W.; Shen, B. Biomedical text mining and its applications in cancer research. J. Biomed. Inform. 2013, 46, 200–211. [Google Scholar] [CrossRef] [Green Version]
- Nassirtoussi, A.K.; Aghabozorgi, S.; Wah, T.Y.; Ngo, D.C.L. Text mining for market prediction: A systematic review. Expert Syst. Appl. 2014, 41, 7653–7670. [Google Scholar] [CrossRef]
- Rojas, C.V.; Reyes, E.R.; Hernández, F.A.Y.; Robles, G.C. Integration of a text mining approach in the strategic planning process of small and medium-sized enterprises. Ind. Manag. Data Syst. 2018, 118, 745–764. [Google Scholar] [CrossRef]
- Kim, Y.; Dwivedi, R.; Zhang, J.; Jeong, S. Competitive Intelligence in Social Media Twitter: IPhone 6 Vs. Galaxy S5. Online Inf. Rev. 2016, 40, 42–61. [Google Scholar] [CrossRef]
- Akundi, A.; Tseng, B.; Wu, J.; Smith, E.; Subbalakshmi, M.; Aguirre, F. Text Mining to Understand the Influence of Social Media Applications on Smartphone Supply Chain. Procedia Comput. Sci. 2018, 140, 87–94. [Google Scholar] [CrossRef]
- Leung, X.Y.; Sun, J.; Bai, B. Bibliometrics of social media research: A co-citation and co-word analysis. Int. J. Hosp. Manag. 2017, 66, 35–45. [Google Scholar] [CrossRef]
- Petrova, M.; Sutcliffe, P.; Fulford, K.W.M.; Dale, J. Search terms and a validated brief search filter to retrieve publications on health-related values in Medline: A word frequency analysis study. J. Am. Med. Inform. Assoc. 2012, 19, 479–488. [Google Scholar] [CrossRef] [Green Version]
- Mahgoub, H.; Rosner, D.; Ismail, N.; Torkey, F. A Text Mining Technique Using Association Rules Extraction. Int. J. Comput. Inf. Eng. 2008, 2, 2044–2051. [Google Scholar]
- Janetzko, D.; Cherfi, H.; Kennke, R.; Napoli, A.; Toussaint, Y. Knowledge-based Selection of Association Rules for Text Mining. In Proceedings of the 16h European Conference on Artificial Intelligence—ECAI’04, ECCAI, Valencia, Spain, 22–27 August 2004; pp. 485–489. [Google Scholar]
- Lai, S.; Xu, L.; Liu, K.; Zhao, J. Recurrent Convolutional Neural Networks for Text Classification. In Proceedings of the Twenty-Ninth AAAI Conference on Artificial Intelligence, Austin, TX, USA, 25–30 January 2015; pp. 2267–2273. [Google Scholar]
- Wang, Z.; Qu, Z. Research on Web text classification algorithm based on improved CNN and SVM. In Proceedings of the 2017 IEEE 17th International Conference on Communication Technology (ICCT), Chengdu, China, 27–30 October 2017; pp. 1958–1961. [Google Scholar] [CrossRef]
- Xu, S. Bayesian Naïve Bayes classifiers to text classification. J. Inf. Sci. 2016, 44, 48–59. [Google Scholar] [CrossRef]
- Ahmed, M.H.; Tiun, S.; Omar, N.; Sani, N.S. Short Text Clustering Algorithms, Application and Challenges: A Survey. Appl. Sci. 2022, 13, 342. [Google Scholar] [CrossRef]
- Rong, Y.; Liu, Y. Staged Text Clustering Algorithm Based on K-means and Hierarchical Agglomeration Clustering. In Proceedings of the IEEE International Conference on Artificial Intelligence and Computer Applications (ICAICA), Dalian, China, 27–29 June 2020; pp. 124–127. [Google Scholar]
- Xiong, H.; Xie, K.; Ma, L.; Yuan, F.; Shen, R. Exploring the Citywide Human Mobility Patterns of Taxi Trips through a Topic-Modeling Analysis. J. Adv. Transp. 2021, 2021, 6697827. [Google Scholar] [CrossRef]
- Kuhn, K.D. Using structural topic modeling to identify latent topics and trends in aviation incident reports. Transp. Res. Part C Emerg. Technol. 2018, 87, 105–122. [Google Scholar] [CrossRef]
- Sachin, S.; Tripathi, A.; Mahajan, N.; Aggarwal, S.; Nagrath, P. Sentiment Analysis Using Gated Recurrent Neural Networks. SN Comput. Sci. 2020, 1, 74. [Google Scholar] [CrossRef] [Green Version]
- Institute of Electrical and Electronics Engineers. Real Time Sentiment Analysis of Tweets Using Naive Bayes. In Proceedings of the 2nd International Conference on Next Generation Computing Technologies (NGCT), Dehradun, India, 14–16 October 2016; pp. 257–261.
- Zainuddin, N.; Selamat, A. Sentiment analysis using Support Vector Machine. In Proceedings of the 2014 International Conference on Computer, Communications, and Control Technology (I4CT), Langkawi, Malaysia, 2–4 September 2014; pp. 333–337. [Google Scholar] [CrossRef]
- Chowdhury, S.; Zhu, J. Investigation of Critical Factors for Future-Proofed Transportation Infrastructure Planning Using Topic Modeling and Association Rule Mining. J. Comput. Civ. Eng. 2023, 37, 04022044. [Google Scholar] [CrossRef]
- Brown, D.E. Text Mining the Contributors to Rail Accidents. IEEE Trans. Intell. Transp. Syst. 2015, 17, 346–355. [Google Scholar] [CrossRef]
- Zhang, X.; Green, E.; Chen, M.; Souleyrette, R.R. Identifying secondary crashes using text mining techniques. J. Transp. Saf. Secur. 2019, 12, 1338–1358. [Google Scholar] [CrossRef]
- So, J.; An, H.; Lee, C. Defining Smart Mobility Service Levels via Text Mining. Sustainability 2020, 12, 9293. [Google Scholar] [CrossRef]
- Lim, M.K.; Li, Y.; Song, X. Exploring customer satisfaction in cold chain logistics using a text mining approach. Ind. Manag. Data Syst. 2021, 121, 2426–2449. [Google Scholar] [CrossRef]
- Peixoto, B.; Pinto, R.; Melo, M.; Cabral, L.; Bessa, M. Immersive Virtual Reality for Foreign Language Education: A PRISMA Systematic Review. IEEE Access 2021, 9, 48952–48962. [Google Scholar] [CrossRef]
- Yusop, S.R.M.; Rasul, M.S.; Yasin, R.M.; Hashim, H.U.; Jalaludin, N.A. An Assessment Approaches and Learning Outcomes in Technical and Vocational Education: A Systematic Review Using PRISMA. Sustainability 2022, 14, 5225. [Google Scholar] [CrossRef]
- Krause, S.; Busch, F. New Insights into Road Accident Analysis through the Use of Text Mining Methods. In Proceedings of the 6th International Conference on Models and Technologies for Intelligent Transportation Systems (MT-ITS), Cracow, Poland, 5–7 June 2019. [Google Scholar]
- Chen, Z.; Huang, K.; Wu, L.; Zhong, Z.; Jiao, Z. Relational Graph Convolutional Network for Text-Mining-Based Accident Causal Classification. Appl. Sci. 2022, 12, 2482. [Google Scholar] [CrossRef]
- Hosseini, P.; Khoshsirat, S.; Jalayer, M.; Das, S.; Zhou, H. Application of Text Mining Techniques to Identify Actual Wrong-Way Driving (WWD) Crashes in Police Reports. Int. J. Transp. Sci. Technol. 2022. [Google Scholar] [CrossRef]
- Das, S.; Dutta, A.; Tsapakis, I. Topic Models from Crash Narrative Reports of Motorcycle Crash Causation Study. Transp. Res. Rec. J. Transp. Res. Board 2021, 2675, 449–462. [Google Scholar] [CrossRef]
- Kwayu, K.M.; Kwigizile, V.; Lee, K.; Oh, J.-S.; Nelson, T. Automatic topics extraction from crowdsourced cyclists near-miss and collision reports using text mining and Artificial Neural Networks. Int. J. Transp. Sci. Technol. 2022, 11, 767–779. [Google Scholar] [CrossRef]
- Kwayu, K.M.; Kwigizile, V.; Lee, K.; Oh, J.-S. Discovering latent themes in traffic fatal crash narratives using text mining analytics and network topology. Accid. Anal. Prev. 2020, 150, 105899. [Google Scholar] [CrossRef] [PubMed]
- Mehrotra, S.; Roberts, S.; Identification and Validation of Themes from Vehicle Owner Complaints and Fatality Reports Using Text Analysis. In Transportation Research Board; 2018. Available online: https://trid.trb.org/view/1496773 (accessed on 13 February 2023).
- Alambeigi, H.; McDonald, A.D.; Author, C.; Tankasala, S.R. Crash Themes in Automated Vehicles: A Topic Modeling Analysis of the California Department of Motor Vehicles Automated Vehicle Crash Database. arXiv 2020, arXiv:2001.11087. [Google Scholar]
- Kaviani, R.; Ahmadi, P.; Gholampour, I. A new method for traffic density estimation based on topic model. In Proceedings of the 2015 Signal Processing and Intelligent Systems Conference (SPIS), Tehran, Iran, 16–17 December 2015; pp. 114–118. [Google Scholar] [CrossRef]
- Arteaga, C.; Paz, A.; Park, J. Injury severity on traffic crashes: A text mining with an interpretable machine-learning approach. Saf. Sci. 2020, 132, 104988. [Google Scholar] [CrossRef]
- Wang, F.; Xu, T.; Tang, T.; Zhou, M.; Wang, H. Bilevel Feature Extraction-Based Text Mining for Fault Diagnosis of Railway Systems. IEEE Trans. Intell. Transp. Syst. 2016, 18, 49–58. [Google Scholar] [CrossRef]
- Zhao, Y.; Xu, T.H.; Hai-feng, W. Text Mining Based Fault Diagnosis of Vehicle On-board Equipment for High Speed Railway. In Proceedings of the IEEE 17th International Conference on Intelligent Transportation Systems (ITSC), Qingdao, China, 8–11 October 2014; pp. 900–905. [Google Scholar]
- Williams, T.P.; Betak, J.F. Identifying Themes in Railroad Equipment Accidents Using Text Mining and Text Visualization. In Proceedings of the 2016 International Conference on Transportation and Development, Houston, TX, USA, 26–29 June 2016. [Google Scholar]
- Soleimani, S.; Mohammadi, A.; Chen, J.; Leitner, M. Mining the Highway-Rail Grade Crossing Crash Data: A Text Mining Approach. In Proceedings of the 2019 18th IEEE International Conference on Machine Learning and Applications (ICMLA), Boca Raton, FL, USA, 16–19 December 2019; pp. 1063–1068. [Google Scholar] [CrossRef]
- Tirunagari, S. Data Mining of Causal Relations from Text: Analysing Maritime Accident Investigation Reports. arXiv 2015, arXiv:1507.02447. [Google Scholar]
- Zhong, B.; Pan, X.; Love, P.E.; Sun, J.; Tao, C. Hazard analysis: A deep learning and text mining framework for accident prevention. Adv. Eng. Inform. 2020, 46, 101152. [Google Scholar] [CrossRef]
- Sayed, A.; Qin, X.; Kate, R.J.; Anisuzzaman, D.; Yu, Z. Identification and analysis of misclassified work-zone crashes using text mining techniques. Accid. Anal. Prev. 2021, 159, 106211. [Google Scholar] [CrossRef]
- Grant-Muller, S.M.; Gal-Tzur, A.; Minkov, E.; Nocera, S.; Kuflik, T.; Shoor, I. Enhancing transport data collection through social media sources: Methods, challenges and opportunities for textual data. IET Intell. Transp. Syst. 2015, 9, 407–417. [Google Scholar] [CrossRef]
- Maghrebi, M.; Abbasi, A.; Rashidi, T.H.; Waller, S.T. Complementing Travel Diary Surveys with Twitter Data: Application of Text Mining Techniques on Activity Location, Type and Time. In Proceedings of the 2015 IEEE 18th International Conference on Intelligent Transportation Systems, Gran Canaria, Spain, 15–18 September 2015; pp. 208–213. [Google Scholar] [CrossRef]
- Gal-Tzur, A.; Grant-Muller, S.M.; Kuflik, T.; Minkov, E.; Nocera, S.; Shoor, I. The potential of social media in delivering transport policy goals. Transp. Policy 2014, 32, 115–123. [Google Scholar] [CrossRef]
- Ali, F.; El-Sappagh, S.; Kwak, D. Fuzzy Ontology and LSTM-Based Text Mining: A Transportation Network Monitoring System for Assisting Travel. Sensors 2019, 19, 234. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Hidayatullah, A.F.; Ma’Arif, M.R. Road traffic topic modeling on Twitter using latent dirichlet allocation. In Proceedings of the 2017 International Conference on Sustainable Information Engineering and Technology (SIET), Malang, Indonesia, 24–25 November 2017; pp. 47–52. [Google Scholar] [CrossRef]
- Ali, F.; Kwak, D.; Khan, P.; El-Sappagh, S.; Ali, A.; Ullah, S.; Kim, K.H.; Kwak, K.-S. Transportation sentiment analysis using word embedding and ontology-based topic modeling. Knowl. Based Syst. 2019, 174, 27–42. [Google Scholar] [CrossRef]
- Kim, N.R.; Hong, S.G. Text mining for the evaluation of public services: The case of a public bike-sharing system. Serv. Bus. 2020, 14, 315–331. [Google Scholar] [CrossRef]
- Kim, K.; Park, O.-J.; Yun, S.; Yun, H. What makes tourists feel negatively about tourism destinations? Application of hybrid text mining methodology to smart destination management. Technol. Forecast. Soc. Chang. 2017, 123, 362–369. [Google Scholar] [CrossRef]
- Park, S.-T.; Liu, C. A study on topic models using LDA and Word2Vec in travel route recommendation: Focus on convergence travel and tours reviews. Pers. Ubiquitous Comput. 2020, 26, 429–445. [Google Scholar] [CrossRef]
- Serna, A.; Gasparovic, S. Transport analysis approach based on big data and text mining analysis from social media. Transp. Res. Procedia 2018, 33, 291–298. [Google Scholar] [CrossRef]
- Niles, I.; Pease, A. Linking Lexicons and Ontologies: Mapping WordNet to the Suggested Upper Merged Ontology. In Ike; CSREA Press: Las Vegas, NV, USA, 2003; pp. 412–416. [Google Scholar]
- Liao, L.; Wu, J.; Zou, F.; Pan, J.; Li, T. Trajectory Topic Modelling to Characterize Driving Behaviors With GPS-based Trajectory Data. J. Internet Technol. 2018, 19, 815–824. [Google Scholar] [CrossRef]
- Qi, G.; Wu, J.; Zhou, Y.; Du, Y.; Jia, Y.; Hounsell, N.; Stanton, N.A. Recognizing driving styles based on topic models. Transp. Res. Part D Transp. Environ. 2018, 66, 13–22. [Google Scholar] [CrossRef]
- Zhao, Z.; Koutsopoulos, H.N.; Zhao, J. Discovering latent activity patterns from transit smart card data: A spatiotemporal topic model. Transp. Res. Part C Emerg. Technol. 2020, 116, 102627. [Google Scholar] [CrossRef]
- Gholampour, I.; Mirzahossein, H.; Chiu, Y.-C. Traffic pattern detection using topic modeling for speed cameras based on big data abstraction. Transp. Lett. 2020, 14, 339–346. [Google Scholar] [CrossRef]
- Huang, L.; Wen, Y.; Guo, W.; Zhu, X.; Zhou, C.; Zhang, F.; Zhu, M. Mobility pattern analysis of ship trajectories based on semantic transformation and topic model. Ocean Eng. 2020, 201, 107092. [Google Scholar] [CrossRef]
- Kutela, B.; Novat, N.; Adanu, E.K.; Kidando, E.; Langa, N. Analysis of residents’ stated preferences of shared micro-mobility devices using regression-text mining approach. Transp. Plan. Technol. 2022, 45, 159–178. [Google Scholar] [CrossRef]
- Manders, T.; Klaassen, E. Unpacking the Smart Mobility Concept in the Dutch Context Based on a Text Mining Approach. Sustainability 2019, 11, 6583. [Google Scholar] [CrossRef] [Green Version]
- Wang, Z.; Yin, J. Risk assessment of inland waterborne transportation using data mining. Marit. Policy Manag. 2020, 47, 633–648. [Google Scholar] [CrossRef]
- Kinra, A.; Mukkamala, R.R.; Vatrapu, R. Methodological Demonstration of a Text Analytics Approach to Country Logistics System Assessments. In Proceedings of the 5th International Conference LDIC, Bremen, Germany, 22–25 February 2016; pp. 119–129. [Google Scholar] [CrossRef]
- Treiblmaier, H.; Mair, P. Textual Data Science for Logistics and Supply Chain Management. Logistics 2021, 5, 56. [Google Scholar] [CrossRef]
- Chae, B. Insights from hashtag #supplychain and Twitter Analytics: Considering Twitter and Twitter data for supply chain practice and research. Int. J. Prod. Econ. 2015, 165, 247–259. [Google Scholar] [CrossRef]
- Singh, A.; Shukla, N.; Mishra, N. Social media data analytics to improve supply chain management in food industries. Transp. Res. Part E Logist. Transp. Rev. 2018, 114, 398–415. [Google Scholar] [CrossRef]
- Hong, W.; Zheng, C.; Wu, L.; Pu, X. Analyzing the Relationship between Consumer Satisfaction and Fresh E-Commerce Logistics Service Using Text Mining Techniques. Sustainability 2019, 11, 3570. [Google Scholar] [CrossRef] [Green Version]
- Meyer, A.; Walter, W.; Seuring, S. The Impact of the Coronavirus Pandemic on Supply Chains and Their Sustainability: A Text Mining Approach. Front. Sustain. 2021, 2, 631182. [Google Scholar] [CrossRef]
- Sai, F. Study on Green Logistics Initiatives through Text Mining. In Proceedings of the 2018 Conference on Technologies and Applications of Artificial Intelligence (TAAI), Taichung, Taiwan, 30 November–2 December 2018; pp. 110–115. [Google Scholar] [CrossRef]
- Sharma, A.; Adhikary, A.; Borah, S.B. Covid-19′s impact on supply chain decisions: Strategic insights from NASDAQ 100 firms using Twitter data. J. Bus. Res. 2020, 117, 443–449. [Google Scholar] [CrossRef] [PubMed]
- Kim, D.; Kim, S. Sustainable Supply Chain Based on News Articles and Sustainability Reports: Text Mining with Leximancer and DICTION. Sustainability 2017, 9, 1008. [Google Scholar] [CrossRef] [Green Version]
- Choi, D.; Song, B. Exploring Technological Trends in Logistics: Topic Modeling-Based Patent Analysis. Sustainability 2018, 10, 2810. [Google Scholar] [CrossRef] [Green Version]
- Chu, C.-Y.; Park, K.; Kremer, G.E. Applying Text-mining Techniques to Global Supply Chain Region Selection: Considering Regional Differences. Procedia Manuf. 2019, 39, 1691–1698. [Google Scholar] [CrossRef]
- Chu, C.-Y.; Park, K.; Kremer, G.E. A global supply chain risk management framework: An application of text-mining to identify region-specific supply chain risks. Adv. Eng. Inform. 2020, 45, 101053. [Google Scholar] [CrossRef]
- Wu, K.J.; Bin, Y.; Ren, M.; Tseng, M.-L.; Wang, Q.; Chiu, A.S. Reconfiguring a hierarchical supply chain model under pandemic using text mining and social media analysis. Ind. Manag. Data Syst. 2022, 122, 622–644. [Google Scholar] [CrossRef]
- Moon, S.; Lee, G.; Chi, S. Semantic text-pairing for relevant provision identification in construction specification reviews. Autom. Constr. 2021, 128, 103780. [Google Scholar] [CrossRef]
- Wen, Q.; Qiang, M.; Xia, B.; An, N. Discovering regulatory concerns on bridge management: An author-topic model based approach. Transp. Policy 2019, 75, 161–170. [Google Scholar] [CrossRef]
- Wu, L.; Ye, K.; Yan, H.; Yang, T. Identifying Chinese Government’s Concerns about Environmental Effects of Highway Construction: A Text Mining Approach. In ICCREM 2018: Sustainable Construction and Prefabrication; American Society of Civil Engineers: Reston, VA, USA, 2018; pp. 232–238. [Google Scholar]
- Park, S.H.; Synn, J.; Kwon, O.H.; Sung, Y. Apriori-based text mining method for the advancement of the transportation management plan in expressway work zones. J. Supercomput. 2017, 74, 1283–1298. [Google Scholar] [CrossRef]
- Chang, T.; Chi, S.; Im, S.-B. Understanding User Experience and Satisfaction with Urban Infrastructure through Text Mining of Civil Complaint Data. J. Constr. Eng. Manag. 2022, 148, 04022061. [Google Scholar] [CrossRef]
- Das, S.; Devkar, G. Harnessing social media data for analyzing public inconvenience in construction of Indian metro rail projects. CSI Trans. ICT 2022, 10, 107–120. [Google Scholar] [CrossRef]
- Chen, Y.; Lei, Z.; Ma, C. Research on the Evolution of the Competition Culture of Highway Construction Companies Based on Text Mining. Sustainability 2022, 14, 12351. [Google Scholar] [CrossRef]
- Williams, T.P.; Gong, J. Predicting construction cost overruns using text mining, numerical data and ensemble classifiers. Autom. Constr. 2014, 43, 23–29. [Google Scholar] [CrossRef]
- Abdirad, M.; Krishnan, K. Industry 4.0 in Logistics and Supply Chain Management Using Topic Modeling Method. In Proceedings of the 8th Annual World Conference of the Society for Industrial and Systems Engineering, Baltimore, MD, USA, 17–18 October 2019; pp. 001–006. [Google Scholar]
- Tavana, M.; Shaabani, A.; Vanani, I.R.; Gangadhari, R.K. A Review of Digital Transformation on Supply Chain Process Management Using Text Mining. Processes 2022, 10, 842. [Google Scholar] [CrossRef]
- Chen, M.-C.; Ho, P.H. Exploring technology opportunities and evolution of IoT-related logistics services with text mining. Complex Intell. Syst. 2021, 7, 2577–2595. [Google Scholar] [CrossRef]
- Bo, J. Research on Cold Chain Logistics Risk in E-commerce Using Text Mining Technology. In Proceedings of the ICCMB 2020: Proceedings of the 2020 the 3rd International Conference on Computers in Management and Business, Tokyo, Japan, 31 January–2 February 2020. [Google Scholar] [CrossRef] [Green Version]
- Shah, S.; Lütjen, M.; Freitag, M. Text Mining for Supply Chain Risk Management in the Apparel Industry. Appl. Sci. 2021, 11, 2323. [Google Scholar] [CrossRef]
- Kim, J.J.; Jang, H.; Roh, S. A systematic literature review on humanitarian logistics using network analysis and topic modeling. Asian J. Shipp. Logist. 2022, 38, 263–278. [Google Scholar] [CrossRef]
- Shin, S.-H.; Kwon, O.K.; Ruan, X.; Chhetri, P.; Lee, P.T.-W.; Shahparvari, S. Analyzing Sustainability Literature in Maritime Studies with Text Mining. Sustainability 2018, 10, 3522. [Google Scholar] [CrossRef] [Green Version]
- Hong, J.; Tamakloe, R.; Lee, G.; Park, D. Insight from Scientific Study in Logistics using Text Mining. Transp. Res. Rec. J. Transp. Res. Board 2019, 2673, 97–107. [Google Scholar] [CrossRef]
- Zondervan, N.A.; Tolentino-Zondervan, F.; Moeke, D. Logistics Trends and Innovations in Response to COVID-19 Pandemic: An Analysis Using Text Mining. Processes 2022, 10, 2667. [Google Scholar] [CrossRef]
- Fosu-Saah, B.; Hafez, M.; Ksaibati, K. A Review of Accelerated Pavement Testing Applications in Non-Pavement Research. Civileng 2021, 2, 612–631. [Google Scholar] [CrossRef]
- Atay, M.; Eroğlu, Y.; Seçkiner, S.U. Investigation of Breaking Points in the Airline Industry with Airline Optimization Studies Through Text Mining before the COVID-19 Pandemic. Transp. Res. Rec. J. Transp. Res. Board 2021, 2675, 301–313. [Google Scholar] [CrossRef]
- Das, S. Exploratory Analysis of Unmanned Aircraft Sightings using Text Mining. Transp. Res. Rec. J. Transp. Res. Board 2021, 2675, 291–300. [Google Scholar] [CrossRef]
- Çallı, L.; Çallı, F. Understanding Airline Passengers during Covid-19 Outbreak to Improve Service Quality: Topic Modeling Approach to Complaints with Latent Dirichlet Allocation Algorithm. Transp. Res. Rec. J. Transp. Res. Board 2022. [Google Scholar] [CrossRef]
- Park, J.Y.; Mistur, E.; Kim, D.; Mo, Y.; Hoefer, R. Toward human-centric urban infrastructure: Text mining for social media data to identify the public perception of COVID-19 policy in transportation hubs. Sustain. Cities Soc. 2021, 76, 103524. [Google Scholar] [CrossRef]
- Kwon, H.; Kim, J.; Park, Y. Applying LSA text mining technique in envisioning social impacts of emerging technologies: The case of drone technology. Technovation 2017, 60–61, 15–28. [Google Scholar] [CrossRef]
- Zhou, Y.; Wang, X.; Yuen, K.F. Sustainability disclosure for container shipping: A text-mining approach. Transp. Policy 2021, 110, 465–477. [Google Scholar] [CrossRef]
- Oliveira-Neto, F.M.; Han, L.D.; Jeong, M.K. Tracking Large Trucks in Real Time with License Plate Recognition and Text-Mining Techniques. Transp. Res. Rec. J. Transp. Res. Board 2009, 2121, 121–127. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
| Research Domain | Focus Area | Authors | Major Text Mining Techniques | Major Objective |
|---|---|---|---|---|
| Crashes and accidents | Roadways | [37] | BERT | Classify crash report narratives |
| [30] | GCV-LIME | Identify likely causal factors for injury severities | ||
| [39] | STM | Estimate the cyclist’s tendency to collide | ||
| [40] | STM | Examine the influence of different crash-causing topics on each other | ||
| [38] | LDA | Identify a potential of a dataset in crash analysis and generating insights into the dataset’s capabilities | ||
| [35] | LDA | Compare classical methods of accident analysis | ||
| [41] | LSA and LDA | Identify the emergent themes that captured the key issues faced by a vehicle owner | ||
| [42] | Probabilistic topic modeling | Identify safety concerns regarding automated vehicle crashes | ||
| [36] | BERT | Reduce the computational cost of text processing in crash investigation | ||
| [43] | PLSA, LDA, STC, and FSTM | Identify the occurrence of traffic accidents in traffic videos | ||
| Rail | [45,46] | PLDA | Improve the fault classification performance in railway maintenance sectors | |
| [48] | TF, TF-IDF | Identify the relationship between crash characteristics | ||
| [29] | PLS, LDA | Discover accident characteristics/features and effects | ||
| [47] | LDA | Identify major recurring accident topics | ||
| Others | [24] | STM | Find previously unreported connections or themes | |
| [50] | LDA | To analyze hazard records of construction sites automatically | ||
| Mobility Analysis | Social media-based sentiment/conception analysis | [57] | OLDA | Sentiment classification to examine traffic control and management systems |
| [58] | KoNLPy | Classify public perceptions of bike sharing | ||
| Tourism | [59] | Sentiment, co-occurrence analysis | Investigate visitors’ perceptions of destination services | |
| [60] | LDA, Word2Vec | Identify the best tour route for foreign tourists | ||
| [61] | SUMO ontology | Identify the positive and negative factors and their potential impact on tourism and transport needs | ||
| Travel and traffic behavior and pattern analysis | [63] | LDA | Identify latent driving patterns | |
| [64] | MLDA, MHLDA | Quantitatively extract and recognize different driving styles | ||
| [23] | LDA | Quantify human mobility using the travel displacement and time taken for each trip | ||
| [65] | LDA | Discover latent activity on the individual level based on spatiotemporal data | ||
| [66] | LDA | Find unusual traffic patterns | ||
| [43] | LDA | Traffic density forecasting | ||
| [67] | LDA | Explore hidden ship mobility patterns | ||
| Trend analysis | [68] | Hybrid, regression-text mining | Evaluate users’ perceptions of several micro-mobility devices | |
| [69] | Linguistic categorization-based text mining | Investigate the ambiguity of the concept of smart mobility and future trends | ||
| [6] | TF, TF-IDF | Identify key issues facing mobility services | ||
| [70] | TF, TF-IDF, association rule | Identify current and future risk factors | ||
| Supply chain and logistics | Trend analysis | [79] | Leximancer, dictionary-based text mining program DICTION | Explore sustainable supply chain management trends, and firms’ strategic positioning and execution |
| [80] | LDA | Explore technological trends in logistics | ||
| Sentiment/perception analysis | [76] | Sentiment Analysis | Identify topics of interest and the point of view of the media on supply chain management constructs | |
| [13] | LDA | Identify the topics that affect customer satisfaction in cold chain logistics | ||
| [74] | SVM-based pre-processing and text mining | Investigate the positive and negative sentiments of tweets related to the food industry | ||
| Risk and resilience analysis | [81,82] | TF, TF-IDF | Identify regional and generic risk factors | |
| Construction and Urban Infrastructure | New information generation | [84] | Doc2Vec model | Identify relevant provisions from different construction specifications |
| [85] | ATM | Identify the major aspects of bridge management (BM) | ||
| [86] | LDA | Realize governmental concerns over environmental effects of highway construction | ||
| [87] | Association rule | Analyze the associations among the type of work and lane closure in expressway construction work zone areas | ||
| Sentiment/perception analysis | [89] | LDA and VADER | Analyze the users’ inconveniences due to noise and dust pollution during construction | |
| Trend analysis | [90] | TF-IDF | Analyze the characteristics of the competition culture of highway construction enterprises and its evolution pattern | |
| Others | [91] | TF-IDF | Design a predictive model for a competitively bid construction projects’ expected cost overrun. | |
| Review of Literature | Industry 4.0 applications regarding the supply chain | [92] | NMF | Identify the trends, advances, and gaps in the Industry 4.0 applications |
| [93] | LDA | Identify the existing knowledge on digital transformation due to Industry 4.0 | ||
| [94] | TF-IDF and threshold analysis | Generate concept maps of important concepts and calculate similarity coefficients | ||
| Others | [97] | TF-IDF | Identify key topics in HRL | |
| [98] | LDA | Create a new intellectual structure for marine sustainability research | ||
| [101] | Voyant | Identify trends related to non-pavement research | ||
| [99] | LDA | Identify trends related to freight transportation and freight systems | ||
| Innovation in Transportation Infrastructure Research | Unmanned Aircraft Systems (UAS) | [103] | LDA | Determine the key topics relevant to UAS sighting incidents |
| Airline complaints | [104] | LDA | Understand the main reasons for complaints being triggered | |
| Airline passenger concerns | [105] | GSDMM | Identify representative topics of passenger concerns in airports | |
| Drone technology | [106] | LSA | Identify warning signs of potential social impacts and their specific consequences | |
| Container shipping | [107] | LDA | Provide structured evidence of sustainability disclosure content in the container shipping industry | |
| Truck plate identification | [108] | ED | Read large truck plates |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chowdhury, S.; Alzarrad, A. Applications of Text Mining in the Transportation Infrastructure Sector: A Review. Information 2023, 14, 201. https://doi.org/10.3390/info14040201
Chowdhury S, Alzarrad A. Applications of Text Mining in the Transportation Infrastructure Sector: A Review. Information. 2023; 14(4):201. https://doi.org/10.3390/info14040201
Chicago/Turabian StyleChowdhury, Sudipta, and Ammar Alzarrad. 2023. "Applications of Text Mining in the Transportation Infrastructure Sector: A Review" Information 14, no. 4: 201. https://doi.org/10.3390/info14040201
APA StyleChowdhury, S., & Alzarrad, A. (2023). Applications of Text Mining in the Transportation Infrastructure Sector: A Review. Information, 14(4), 201. https://doi.org/10.3390/info14040201